

Hallo zusammen! Wir haben großartige Neuigkeiten: Im Juni startet OTUS erneut einen Kurs , weshalb wir wie gewohnt nützliche Materialien mit Ihnen teilen.

Falls Sie auf all diese Geschichte mit Mikrodiensten ohne jeglichen Kontext gestoßen sind, können Sie es als verständlich ansehen, dass Sie es etwas merkwürdig finden. Die Aufspaltung einer Anwendung in Fragmente, die über ein Netzwerk verbunden sind, bedeutet unweigerlich, dass komplexe Ausfallsicherheitsmechanismen in das resultierende verteilte System integriert werden.
Obwohl dieser Ansatz die Zerlegung in zahlreiche unabhängige Dienste umfasst, geht das Endziel weit über die bloße Ausführung dieser Dienste auf unterschiedlichen Maschinen hinaus. Es geht um die Interaktion mit der umliegenden Welt, die von ihrer Natur aus ebenfalls verteilt ist. Nicht im technischen Sinne, sondern eher im Sinne eines Ökosystems, das aus vielen Menschen, Teams und Programmen besteht, wobei jeder dieser Teile auf die eine oder andere Weise seine Aufgaben erfüllen muss.
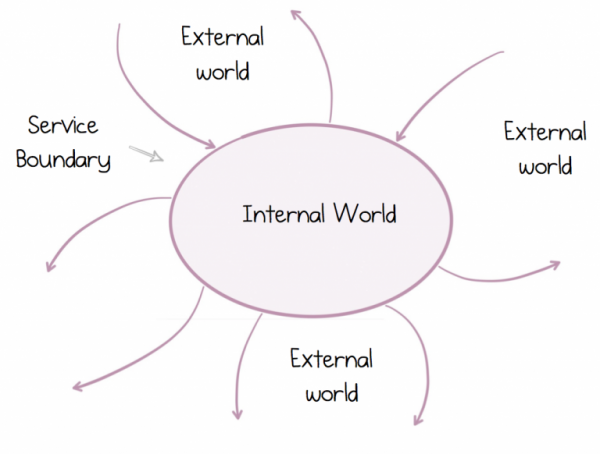
Unternehmen zum Beispiel bestehen aus einer Reihe von verteilten Systemen, die zusammen eine bestimmte Zielsetzung unterstützen. Diesen Fakt haben wir über Jahrzehnte ignoriert, indem wir versuchten, durch FTP-Dateiübertragungen oder mit Unternehmensintegrationswerkzeugen eine Einheit herzustellen, während wir uns auf unsere persönlichen, isolierten Ziele konzentrierten. Doch mit dem Aufkommen von Services änderte sich alles. Services ermöglichten es uns, über den Tellerrand hinauszuschauen und eine Welt von wechselseitigen Programmen zu erkennen, die zusammenarbeiten. Um jedoch erfolgreich zu sein, ist es notwendig, zwei grundlegend verschiedene Welten zu erkennen und zu konzipieren: die Außenwelt, in der wir in einem Ökosystem aus zahlreichen anderen Services leben, und unsere persönliche, innere Welt, in der wir allein herrschen.
Eine solche verteilte Welt unterscheidet sich von der, in der wir aufgewachsen sind und an die wir gewöhnt sind. Die Prinzipien traditioneller monolithischer Architektur sind nicht haltbar. Daher ist das richtige Verständnis solcher Systeme mehr als nur das Erstellen eines coolen Schemas auf einem Whiteboard oder einem beeindruckenden Proof of Concept. Es geht darum, dass ein solches System über einen langen Zeitraum hinweg erfolgreich funktioniert. Glücklicherweise existieren Services schon seit geraumer Zeit, auch wenn sie unterschiedlich aussehen. sind nach wie vor relevant, selbst wenn sie mit Docker, Kubernetes gewürzt und ein wenig von hipsterhaften Bärten gezeichnet sind.
Heute werden wir also betrachten, wie sich die Regeln verändert haben, warum wir unseren Ansatz für Services und die Daten, die sie austauschen, neu überdenken müssen und warum wir dafür ganz andere Werkzeuge benötigen.
Kapselung wird Ihnen nicht immerfreundlich sein.
Mikrodienste können unabhängig voneinander agieren. Diese Eigenschaft verleiht ihnen den größten Wert. Sie ermöglicht es den Diensten, zu skalieren und zu wachsen. Nicht nur in Bezug auf die Skalierung auf Quadrilliarden von Nutzern oder Petabytes an Daten (obwohl sie auch dabei helfen können), sondern in Bezug auf die Menschen, da Teams und Organisationen kontinuierlich wachsen.
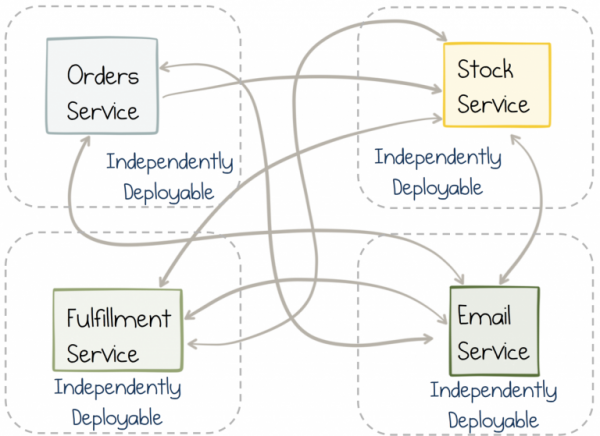
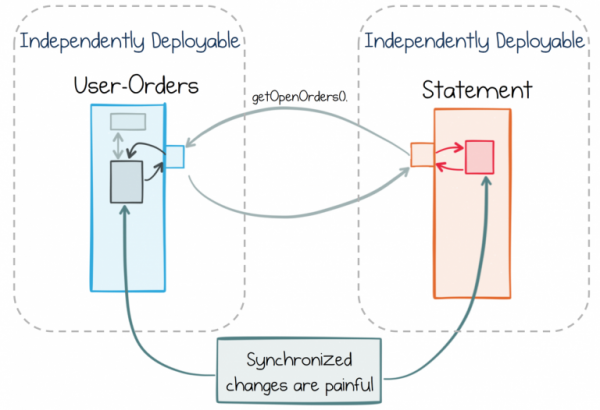
Unabhängigkeit ist jedoch ein zweischneidiges Schwert. Ein Dienst kann für sich allein leicht und unkompliziert sein. Doch wenn innerhalb eines Dienstes eine Funktion implementiert wird, die einen anderen Dienst benötigt, müssen wir letztendlich nahezu gleichzeitig an beiden Diensten Änderungen vornehmen. In einem Monolithen ist das einfach; man nimmt einfach eine Änderung vor und veröffentlicht sie. Im Fall von synchronisierten unabhängigen Diensten treten jedoch wesentlich mehr Probleme auf. Die Koordination zwischen den Teams und den Releasezyklen beeinträchtigt die Flexibilität.
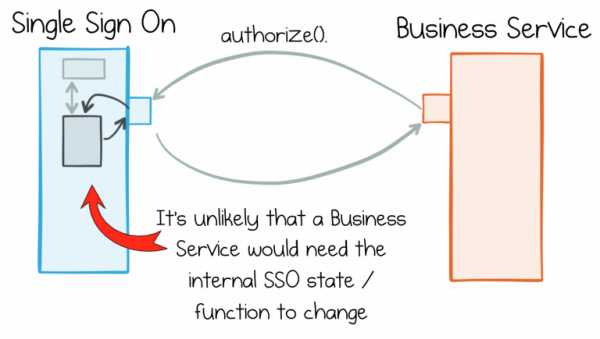
Im Rahmen des Standardansatzes wird versucht, unangenehme durchgehende Änderungen einfach zu vermeiden, indem die Funktionalität klar zwischen den Diensten aufgeteilt wird. Ein Service für den einheitlichen Zugang zum System kann hier ein gutes Beispiel sein. Er hat eine klar definierte Rolle, die ihn von anderen Diensten unterscheidet. Diese klare Trennung bedeutet, dass der einheitliche Zugang in einer Welt mit schnell wechselnden Anforderungen an die umgebenden Dienste wahrscheinlich nicht verändert wird. Er existiert in einem streng begrenzten Kontext.
Das Problem ist, dass in der realen Welt Geschäftsdienste nicht ständig eine so klare Trennung der Rollen aufrechterhalten können. Zum Beispiel arbeiten diese Geschäftsdienste überwiegend mit Daten, die von anderen ähnlichen Diensten geliefert werden. Wenn Sie im Online-Einzelhandel tätig sind, wird die Verarbeitung des Bestellstroms, des Produktkatalogs oder von Benutzerinformationen eine Anforderung für viele Ihrer Dienste darstellen. Jeder dieser Dienste benötigt Zugriff auf diese Daten, um effektiv arbeiten zu können.
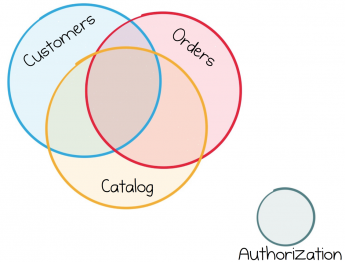
Die meisten Geschäftsdienste nutzen denselben Datenstrom, weshalb ihre Arbeit unweigerlich verflochten ist.
So sind wir zu einem wichtigen Punkt gekommen, über den es sich zu sprechen lohnt. Während die Dienste gut für Infrastrukturkomponenten funktionieren, die weitgehend isoliert arbeiten, sind die meisten Geschäftsdienste viel enger miteinander verwoben.
Daten-Dichotomie
Serviceorientierte Ansätze existieren möglicherweise bereits, jedoch gibt es immer noch wenig Informationen darüber, wie große Datenmengen zwischen den Diensten ausgetauscht werden können.
Das Hauptproblem ist, dass Daten und Dienste untrennbar sind. Einerseits fordert die Kapselung uns auf, Daten zu verbergen, damit die Dienste voneinander getrennt werden können und ihr Wachstum sowie weitere Änderungen erleichtert werden. Andererseits müssen wir die Möglichkeit haben, gemeinsame Daten genauso frei zu teilen und zu verwalten wie jede andere. Es geht darum, in der Lage zu sein, sofort loszulegen, ebenso unbeschwert wie in jedem anderen Informationssystem.
Informationssysteme haben jedoch wenig mit Kapselung gemein. Tatsächlich ist es sogar das Gegenteil. Datenbanken tun alles, was sie können, um den Zugriff auf die darin gespeicherten Daten zu ermöglichen. Sie bieten eine leistungsstarke deklarative Schnittstelle, die es ermöglicht, die Daten nach Bedarf zu transformieren. Diese Funktionalität ist in der Phase der Voruntersuchungen wichtig, jedoch nicht für das Management der wachsenden Komplexität eines ständig sich entwickelnden Dienstes.
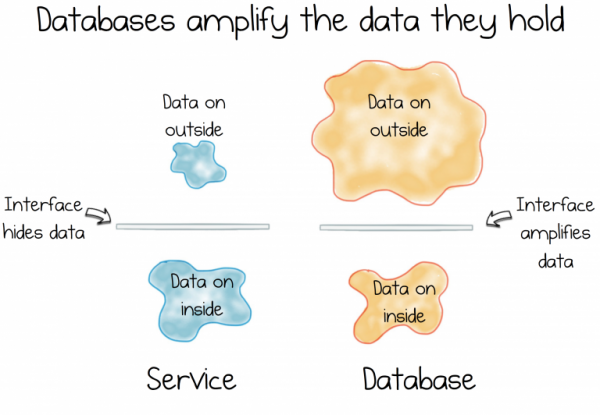
Hier entsteht ein Dilemma. Ein Widerspruch. Eine Dichotomie. Denn Informationssysteme stehen für die Bereitstellung von Daten, während Dienste für das Verbergen stehen.
Diese beiden Kräfte sind grundlegend. Sie bilden die Basis für den Großteil unserer Arbeit und kämpfen ständig um die Vorherrschaft in den Systemen, die wir schaffen.
Mit dem Wachstum und der Evolution von Service-Systemen beobachten wir verschiedene Auswirkungen der Datendichotomie. Entweder wächst die Benutzeroberfläche des Dienstes, bietet immer umfassendere Funktionen und beginnt, wie eine sehr merkwürdige Eigenbau-Datenbank auszusehen, oder wir sehen uns mit Enttäuschung konfrontiert und finden einen Weg, um ganze Datensätze massenhaft von einem Dienst in einen anderen zu extrahieren oder zu verschieben.
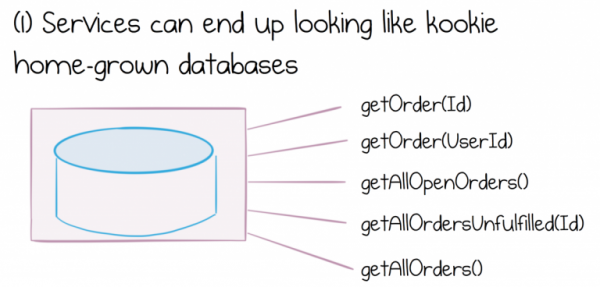
Die Schaffung von etwas, das wie eine merkwürdige Eigenbau-Datenbank aussieht, führt ihrerseits zu einer ganzen Reihe von Problemen. Wir werden nicht im Detail darauf eingehen, was gefährlich ist, shared database, aber wir sagen einfach, dass sie erhebliche kostenintensive Ingenieur- und Betriebsschwierigkeiten Schlimmer ist, dass die Datenmengen die Probleme an den Grenzen der Dienste multiplizieren. Je mehr gemeinsame Daten innerhalb eines Dienstes liegen, desto komplexer wird die Benutzeroberfläche und desto schwieriger wird es, Datensätze aus verschiedenen Diensten zu kombinieren.
Schlimmer ist, dass die Datenmengen die Probleme an den Schnittstellen verstärken. Je mehr gemeinsame Daten innerhalb des Dienstes liegen, desto komplexer wird die Benutzeroberfläche, und desto schwieriger wird es werden, Datensätze aus verschiedenen Diensten zu kombinieren.
Ein alternativer Ansatz, bei dem ganze Datensätze extrahiert und verschoben werden, hat ebenfalls seine Probleme. Der gängige Ansatz besteht darin, einen Datensatz vollständig zu extrahieren und dann lokal in jedem konsumierenden Dienst zu speichern.
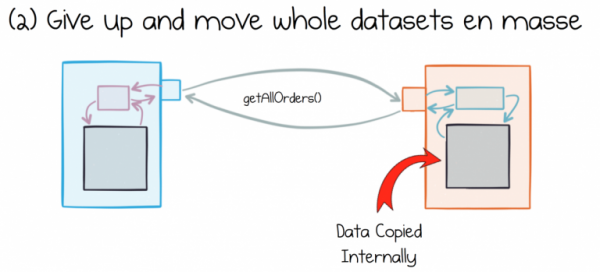
Das Problem ist, dass verschiedene Dienste die Daten, die sie konsumieren, unterschiedlich interpretieren. Diese Daten sind immer zur Hand. Sie werden lokal verändert und verarbeitet. Sehr schnell haben sie kaum noch etwas mit den Daten in der Quelle gemein.
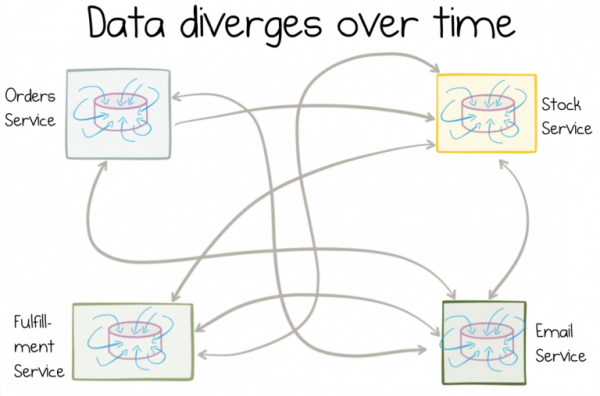
Je mehr veränderlich die Kopien sind, desto mehr werden die Daten im Laufe der Zeit voneinander abweichen.
Was noch schlimmer ist, solche Daten sind im Nachhinein schwer zu korrigieren ( hier kann es wirklich zur Hilfe kommen). Tatsächlich entstehen einige der schwer lösbaren technologischen Probleme, mit denen Unternehmen konfrontiert sind, aufgrund heterogener Daten, die sich von Anwendung zu Anwendung vervielfachen.
Um eine Lösung für dieses Problem mit gemeinsamen Daten zu finden, müssen wir anders denken. Sie sollten zu erstklassigen Objekten in den Architekturen werden, die wir bauen. nennt solche Daten "extern", und das ist eine sehr wichtige Eigenschaft. Wir benötigen Kapselung, um die interne Struktur des Services nicht offenzulegen, aber wir müssen den Services den Zugang zu gemeinsam genutzten Daten erleichtern, damit sie ihre Arbeit korrekt ausführen können.
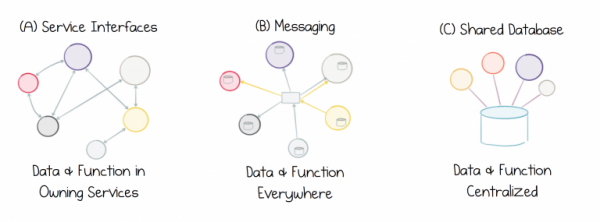
Das Problem ist, dass keiner der heutigen Ansätze mehr aktuell ist, da weder die Service-Schnittstellen, noch der Nachrichtenaustausch, noch die Shared Database eine gute Lösung für den Umgang mit externen Daten anbieten. Service-Schnittstellen eignen sich schlecht für den Datenaustausch in irgendeinem Maßstab. Der Nachrichtenaustausch bewegt Daten, speichert jedoch nicht ihre Historie, weshalb die Daten im Laufe der Zeit beschädigt werden. Shared Databases konzentrieren sich zu stark auf einen einzigen Punkt, was den Fortschritt behindert. Wir stecken unvermeidlich in einem Kreis von Dateninkonsistenzen fest:
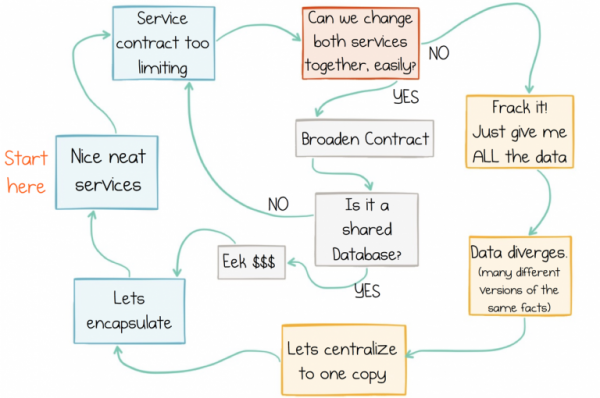
Kreis der Dateninkonsistenzen
Flüsse: dezentraler Ansatz für Daten und Services
Idealerweise müssen wir unseren Ansatz ändern, wie Dienste mit gemeinsamen Daten umgehen. Aktuell sieht sich jeder Ansatz der oben erwähnten Dichotomie gegenüber, da es kein Wundermittel gibt, mit dem man großzügig darüber streuen kann, um sie verschwinden zu lassen. Wir können jedoch das Problem neu überdenken und zu einem Kompromiss kommen.
Dieser Kompromiss erfordert einen gewissen Grad an Zentralisierung. Wir können einen Mechanismus für verteilte Protokolle nutzen, da er zuverlässige, skalierbare Datenströme bietet. Jetzt müssen die Dienste in der Lage sein, sich anzuschließen und mit diesen gemeinsamen Strömen zu arbeiten. Dabei möchten wir jedoch komplizierte zentrale God Services vermeiden, die solche Verarbeitungen durchführen. Daher ist der beste Ansatz, die Streaming-Verarbeitung in jeden konsumierenden Dienst einzubauen. So können die Dienste Datensätze aus verschiedenen Quellen kombinieren und damit so arbeiten, wie sie es benötigen.
Eine Möglichkeit, einen solchen Ansatz zu erreichen, ist die Verwendung einer Streaming-Plattform. Es gibt viele Optionen, aber heute konzentrieren wir uns auf Kafka, da ihre Stateful Stream Processing dazu beiträgt, das dargestellte Problem effizient zu lösen.
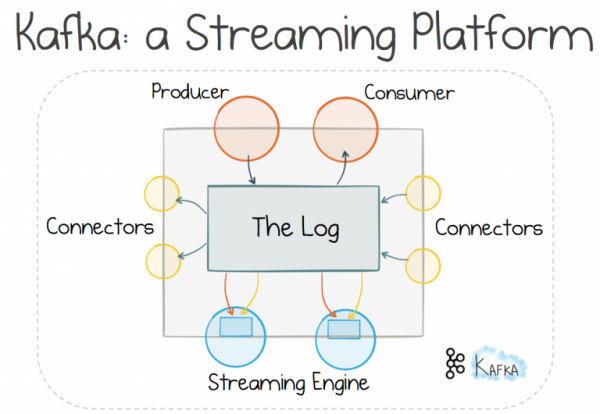
Die Nutzung eines verteilten Logging-Mechanismus ermöglicht es uns, den gewohnten Pfad zu beschreiten und Nachrichten zu verwenden, um mit . Man glaubt, dass dieser Ansatz eine bessere Skalierbarkeit und Trennung bietet als das „Request-Response“-Modell, da er die Kontrolle über den Datenfluss dem Empfänger und nicht dem Sender überlässt. Allerdings hat alles im Leben seinen Preis, und dafür benötigen Sie einen Broker. Aber für große Systeme ist dieser Kompromiss es wert (was man von Ihren durchschnittlichen Webanwendungen nicht sagen kann).
Wenn der Broker für das verteilte Logging verantwortlich ist und nicht das traditionelle Nachrichtensystem, können zusätzliche Funktionen genutzt werden. Der Transport lässt sich nahezu linear skalieren, ähnlich wie ein verteiltes Dateisystem. Daten können lange in Logs gespeichert werden, sodass wir nicht nur eine Nachrichtenübermittlung erhalten, sondern auch einen Informationsspeicher. Ein skalierbarer Speicher, ohne Sorge, einen veränderbaren Gesamtzustand zu empfangen.
Anschließend kann der Mechanismus der stateful stream processing (Zustandsbehaftete Stream-Verarbeitung) genutzt werden, um deklarative Datenbankwerkzeuge in Verbraucherdienste einzubinden. Das ist ein sehr wichtiger Gedanke. Solange die Daten in gemeinsamen Streams gespeichert sind, auf die alle Dienste Zugriff haben, sind die Zusammenführung und Verarbeitung, die der Dienst vornimmt, privat. Sie sind innerhalb eines streng begrenzten Kontextes isoliert.
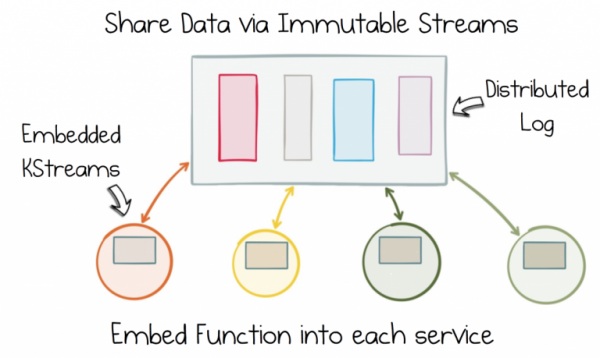
Befreien Sie sich von der Dichotomie der Daten, indem Sie den unveränderlichen Statusstream aufteilen. Fügen Sie diese Funktion dann jedem Dienst mithilfe von Stateful Stream Processing hinzu.
Wenn Ihr Service mit Bestellungen, einem Produktkatalog oder einem Lager arbeitet, haben Sie vollständigen Zugriff: Sie entscheiden allein, welche Daten zusammengeführt, wo sie verarbeitet und wie sie sich im Laufe der Zeit ändern sollen. Obwohl die Daten gemeinsam genutzt werden, bleibt die Arbeit mit ihnen völlig dezentralisiert. Sie erfolgt innerhalb jedes Services, in einer Welt, in der alles nach Ihren Regeln läuft.
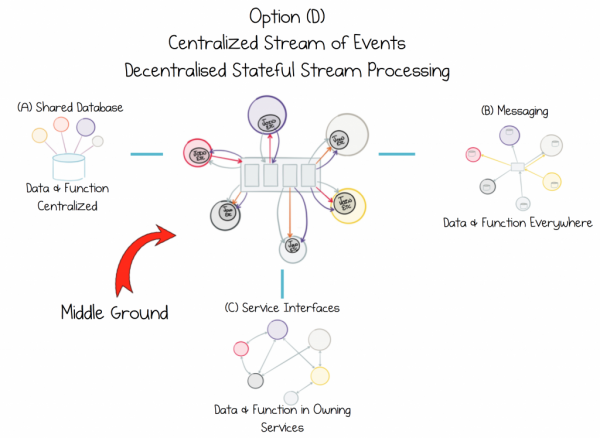
Teilen Sie Daten so, dass ihre Integrität nicht gefährdet wird. Kapseln Sie die Funktion, nicht die Quelle, in jedem Service, der sie benötigt.
Es kommt vor, dass Daten in großem Umfang verschoben werden müssen. Manchmal benötigt ein Service eine lokale historische Datensammlung in der gewählten Datenbank-Engine. Der Fokus liegt darauf, dass garantiert werden kann, dass bei Bedarf eine Kopie aus der Quelle mithilfe des verteilten Protokollmechanismus wiederhergestellt werden kann. Die Konnektoren in Kafka erledigen diese Aufgabe hervorragend.
Daher hat der heute betrachtete Ansatz mehrere Vorteile:
- Daten werden in Form von gemeinsamen Streams verwendet, die lange in Protokollen gespeichert werden können. Der Mechanismus zur Verarbeitung gemeinsamer Daten ist in jedem einzelnen Kontext eingebettet, was es den Diensten ermöglicht, einfach und schnell zu arbeiten. Auf diese Weise kann die Dichotomie der Daten ausgeglichen werden.
- Daten aus verschiedenen Diensten können problemlos zu Sets kombiniert werden. Dies vereinfacht die Interaktion mit gemeinsamen Daten und macht die Wartung lokaler Datensätze in der Datenbank überflüssig.
- Stateful Stream Processing speichert lediglich die Daten im Cache, während die gemeinsamen Protokolle die Quelle der Wahrheit bleiben. Daher ist das Problem der Datenbeschädigung im Laufe der Zeit nicht so akut.
- Im Grunde genommen werden Dienste von Daten gesteuert. Trotz des ständigen Wachstums der Datenmengen können die Dienste weiterhin schnell auf Geschäftsvorfälle reagieren.
- Skalierbarkeitsprobleme liegen beim Broker und nicht bei den Diensten. Dadurch wird die Komplexität des Schreibens von Diensten erheblich verringert, da keine Überlegungen zur Skalierbarkeit erforderlich sind.
- Das Hinzufügen neuer Dienste erfordert keine Änderungen an bestehenden, wodurch die Anbindung neuer Dienste einfacher wird.
Wie Sie sehen, ist das mehr als nur REST. Wir haben ein Toolkit erhalten, das es ermöglicht, mit gemeinsamen Daten dezentral zu arbeiten.
In dem heutigen Artikel wurden lange nicht alle Aspekte beleuchtet. Wir müssen noch klären, wie wir zwischen dem „Request-Response“-Paradigma und dem ereignisgesteuerten Paradigma balancieren. Damit werden wir uns beim nächsten Mal beschäftigen. Es gibt Themen, die wir besser kennenlernen sollten, wie z. B. die Vorteile der zustandsbehafteten Stream-Verarbeitung. Darüber werden wir im dritten Artikel sprechen. Außerdem gibt es andere leistungsstarke Konstruktionen, die wir nutzen können, wenn wir sie in Anspruch nehmen, wie . Damit ändern sich die Spielregeln für verteilte Geschäftssysteme, da diese Konstruktion transaktionale Garantien für in skalierbarer Form bietet. Darüber wird im vierten Artikel gesprochen. Schließlich müssen wir die Details der Umsetzung dieser Prinzipien durchgehen.
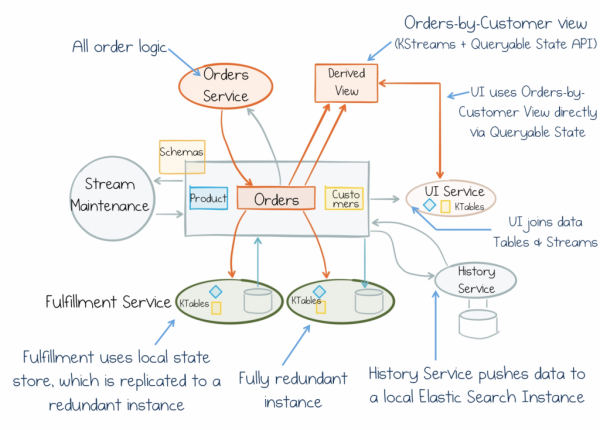
Aber merken Sie sich vorerst Folgendes: Die Daten-Dichotomie ist die Kraft, mit der wir bei der Erstellung von Geschäftsdiensten konfrontiert werden. Und wir müssen dies berücksichtigen. Der Fokus liegt darauf, alles auf den Kopf zu stellen und gesamte Daten als erstklassige Objekte zu betrachten. Stateful Stream Processing bietet hierfür einen einzigartigen Kompromiss. Es vermeidet zentralisierte „God Components“, die den Fortschritt behindern. Darüber hinaus gewährleistet es die Effizienz, Skalierbarkeit und Ausfallsicherheit von Datenstreaming-Pipelines und integriert diese in jeden Dienst. So können wir uns auf den gemeinsamen Fluss des Bewusstseins konzentrieren, an den sich jeder Dienst anschließen und mit seinen Daten arbeiten kann. Dadurch werden die Dienste skalierbarer, austauschbarer und autonomer. So sehen sie nicht nur gut aus auf den Boards und bei der Hypothesenprüfung, sondern funktionieren und entwickeln sich auch über Jahrzehnte.
Quelle: habr.com
