

Sehr geehrte Community, dieser Artikel widmet sich der effizienten Speicherung und Ausgabe von Hunderten Millionen kleiner Dateien. An dieser Stelle wird eine endgültige Lösung für POSIX-kompatible Dateisysteme mit vollständiger Unterstützung für Sperren, einschließlich Cluster-Sperren, und anscheinend sogar ohne Workarounds angeboten.
Für diesen Zweck habe ich meinen eigenen spezialisierten Server geschrieben.
Während der Umsetzung dieser Aufgabe gelang es mir, das Hauptproblem zu lösen und gleichzeitig Speicherplatz und RAM zu sparen, den unser clustergestütztes Dateisystem unbarmherzig beansprucht hat. Eine solche Menge an Dateien ist für jedes clustergestützte Dateisystem schädlich.
Die Idee ist folgende:
Einfach gesagt: Über den Server werden kleine Dateien hochgeladen, sie werden direkt in einem Archiv gespeichert und ebenso aus diesem gelesen, während große Dateien daneben abgelegt werden. Schema: 1 Ordner = 1 Archiv, somit haben wir mehrere Millionen Archive mit kleinen Dateien anstelle von mehreren Hundert Millionen Dateien. Und das alles wurde vollständig umgesetzt, ohne irgendwelche Skripte und das Ablegen von Dateien in tar/zip Archiven.
Ich werde versuchen, mich kurz zu fassen, und entschuldige mich im Voraus, falls der Beitrag umfangreich wird.
Alles begann damit, dass ich keinen geeigneten Server in der Welt finden konnte, der Daten, die über das HTTP-Protokoll empfangen wurden, direkt in Archive speichern kann, ohne die Mängel herkömmlicher Archive und Objektspeicher zu haben. Der Grund für die Suche war ein stark gewachsener Origin-Cluster aus 10 Servern, der bereits 250.000.000 kleine Dateien angesammelt hatte und dessen Wachstumstendenz nicht aufhören wollte.
Für diejenigen, die keine Artikel lesen mögen und kurze Dokumentationen bevorzugen:
und .
Und Docker gleichzeitig, derzeit gibt es nur die Option zusammen mit nginx, falls nötig:
docker run -d --restart=always -e host=localhost -e root=/var/storage
-v /var/storage:/var/storage --name wzd -p 80:80 eltaline/wzdWeiter:
Wenn es viele Dateien gibt, sind erhebliche Ressourcen erforderlich, und das Frustrierende ist, dass ein Teil davon sinnlos verloren geht. Bei der Verwendung eines verteilten Dateisystems (in diesem Fall MooseFS) benötigt eine Datei, unabhängig von ihrer tatsächlichen Größe, immer mindestens 64 KB. Das bedeutet, dass für Dateien mit einer Größe von 3, 10 oder 30 KB auf der Festplatte jeweils 64 KB benötigt werden. Wenn es sich um viertel Milliarden Dateien handelt, verlieren wir zwischen 2 und 10 Terabyte. Es wird nicht möglich sein, unendlich viele neue Dateien zu erstellen, da es auch in MooseFS eine Begrenzung gibt: nicht mehr als 1 Milliarde mit einer Kopie jeder Datei.
Mit steigender Anzahl an Dateien benötigt man viel RAM für Metadaten. Auch häufige große Dumps von Metadaten tragen zum Verschleiß von SSD-Laufwerken bei.
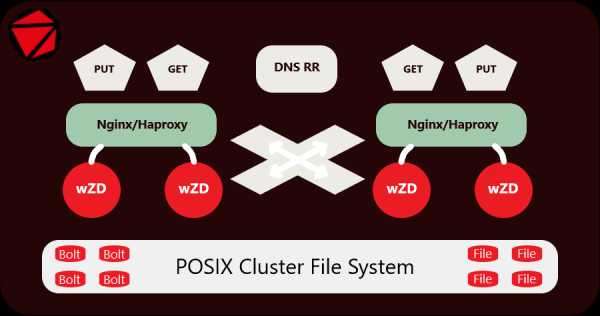
Server wZD. Wir bringen Ordnung auf die Festplatten.
Der Server ist in der Programmiersprache Go geschrieben. Zunächst musste ich die Anzahl der Dateien verringern. Wie macht man das? Durch Archivierung, aber in diesem Fall ohne Kompression, da meine Dateien durchgehend komprimierte Bilder sind. Dabei kam mir BoltDB zugute, die ich zudem von Mängeln befreien musste, was in der Dokumentation festgehalten ist.
Anstatt viertel Milliarde Dateien sind in meinem Fall nur noch 10 Millionen Bolt-Archive übrig geblieben. Hätte ich die Möglichkeit, die aktuelle Struktur der Verzeichnisse zu ändern, könnte die Anzahl möglicherweise auf etwa 1 Million Dateien reduziert werden.
Alle kleinen Dateien werden in Bolt-Archive gepackt, die automatisch die Namen der Verzeichnisse annehmen, in denen sie liegen, während alle großen Dateien neben den Archiven verbleiben, da es keinen Sinn macht, sie zu verpacken. Kleinere — archivieren wir, große — lassen wir unverändert. Der Server arbeitet transparent mit beiden.
Architektur und Besonderheiten des Servers wZD.

Der Server läuft unter den Betriebssystemen Linux, BSD, Solaris und OSX. Ich habe nur für die AMD64-Architektur unter Linux getestet, aber er sollte auch für ARM64, PPC64, MIPS64 geeignet sein.
Hauptmerkmale:
- Multithreading;
- Multiserver-Architektur, die Ausfallsicherheit und Lastenverteilung gewährleistet;
- Maximale Transparenz für den Nutzer oder Entwickler;
- Unterstützte HTTP-Methoden: GET, HEAD, PUT und DELETE;
- Steuerung des Verhaltens beim Lesen und Schreiben über Client-Header;
- Unterstützung von flexibel konfigurierbaren virtuellen Hosts;
- Unterstützung der CRC-Datenintegrität beim Schreiben/Lesen;
- Halb-dynamische Puffer für minimalen Speicherverbrauch und optimale Netzwerkanpassung;
- Verzögerte Datenkompaktierung;
- Zusätzlich wird der mehrläufige Archivator wZA für die Migration von Dateien ohne Dienstunterbrechung angeboten.
Echte Erfahrungen:
Ich habe den Server und den Archivierer über einen längeren Zeitraum hinweg mit Live-Daten entwickelt und getestet. Jetzt funktioniert er erfolgreich auf einem Cluster, das 250.000.000 kleine Dateien (Bilder) umfasst, die in 15.000.000 Verzeichnissen auf separaten SATA-Laufwerken gespeichert sind. Der Cluster aus 10 Servern stellt einen Origin-Server dar, der hinter einem CDN-Netzwerk eingerichtet ist. Für seine Wartung werden 2 Nginx-Server und 2 wZD-Server verwendet.
Für diejenigen, die diesen Server nutzen möchten, macht es Sinn, die Verzeichnisstruktur vor der Nutzung zu planen, wenn das zutrifft. Ich möchte gleich klarstellen, dass der Server nicht dafür vorgesehen ist, alles in ein einziges Bolt-Archiv zu packen.
Leistungstests:
Je kleiner die Größe der archivierten Datei, desto schneller werden die GET- und PUT-Operationen ausgeführt. Lassen Sie uns die gesamte Zeit, die ein HTTP-Client benötigt, um in normale Dateien und in Bolt-Archive zu schreiben, sowie das Lesen vergleichen. Die Arbeit mit Dateien der Größe 32 KB, 256 KB, 1024 KB, 4096 KB und 32768 KB wird verglichen.
Bei der Arbeit mit Bolt-Archiven wird die Integrität der Daten jeder Datei überprüft (es wird CRC verwendet). Vor und nach dem Schreiben erfolgt eine Echtzeitlektüre und Neuberechnung, was natürlich Verzögerungen mit sich bringt, aber das Wichtigste ist die Datensicherheit.
Ich habe Leistungstests auf SSD-Laufwerken durchgeführt, da die Tests auf SATA-Laufwerken keinen deutlichen Unterschied zeigen.
Grafiken zu den Testergebnissen:
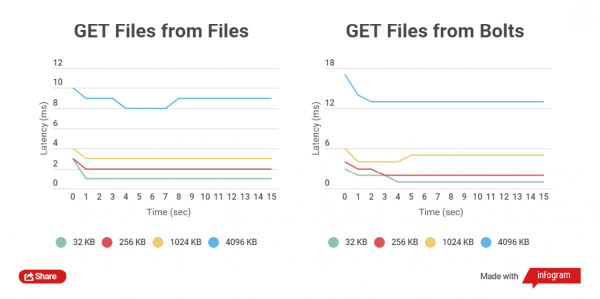
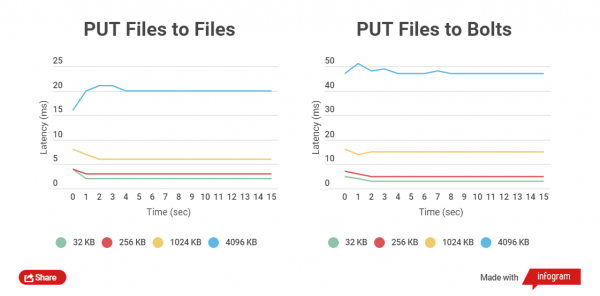
Wie zu sehen ist, ist der Zeitunterschied beim Lesen und Schreiben für kleine Dateien zwischen archiven und nicht archivierten Dateien gering.
Eine ganz andere Situation ergibt sich bei dem Test zum Lesen und Schreiben von Dateien mit einer Größe von 32 MB:
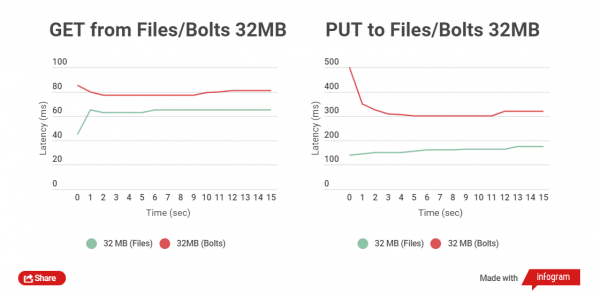
Der Zeitunterschied beim Lesen der Dateien liegt im Bereich von 5-25 ms. Beim Schreiben sieht es schlechter aus, der Unterschied beträgt etwa 150 ms. In diesem Fall ist es jedoch nicht erforderlich, große Dateien hochzuladen, das macht einfach keinen Sinn, sie können getrennt von den Archiven existieren.
*Technisch kann dieser Server auch für Aufgaben verwendet werden, die NoSQL erfordern.
Hauptmethoden zur Arbeit mit dem wZD-Server:
Hochladen einer gewöhnlichen Datei:
curl -X PUT --data-binary @test.jpg http://localhost/test/test.jpgHochladen einer Datei in das Bolt Archiv (sofern der Serverparameter fmaxsize, der die maximale Größe der Datei bestimmt, die in das Archiv aufgenommen werden kann, nicht überschritten wird; andernfalls wird die Datei wie gewohnt neben dem Archiv hochgeladen):
curl -X PUT -H "Archive: 1" --data-binary @test.jpg http://localhost/test/test.jpgHerunterladen der Datei (wenn auf der Festplatte und im Archiv Dateien mit demselben Namen vorhanden sind, erhält standardmäßig die nicht archivierte Datei Vorrang beim Herunterladen):
curl -o test.jpg http://localhost/test/test.jpgHerunterladen der Datei aus dem Bolt Archiv (zwangsweise):
curl -o test.jpg -H "FromArchive: 1" http://localhost/test/test.jpgEine Beschreibung der anderen Methoden finden Sie in der Dokumentation.
Der Server unterstützt derzeit nur das HTTP-Protokoll; HTTPS ist noch nicht verfügbar. Auch die POST-Methode wird nicht unterstützt (es wurde noch nicht entschieden, ob sie benötigt wird oder nicht).
Wer im Quellcode nachschaut, wird dort eine Überraschung finden; nicht jeder mag sie, aber ich habe den Hauptcode nicht an die Funktionen des Webframeworks gebunden, außer dem Interrupt-Handler, sodass ich ihn in Zukunft schnell auf fast jedem Framework umschreiben kann.
ToDo:
- Entwicklung eines eigenen Replikators und Distributors + Geo, um die Verwendung in großen Systemen ohne Cluster-FS zu ermöglichen (alles professionell)
- Die Möglichkeit der vollständigen reversiblen Wiederherstellung von Metadaten bei vollständigem Verlust (bei der Verwendung eines Distributors)
- Natives Protokoll zur Nutzung dauerhafter Netzwerkverbindungen und Treiber für verschiedene Programmiersprachen
- Erweiterte Nutzungsmöglichkeiten der NoSQL-Komponente
- Kompression verschiedener Typen (gzip, zstd, snappy) für Dateien oder Werte innerhalb von Bolt-Archiven und für normale Dateien
- Verschlüsselung verschiedener Typen für Dateien oder Werte innerhalb von Bolt-Archiven und für normale Dateien
- Verzögerte serverseitige Video-Konvertierung, einschließlich auf GPU
Ich habe alles, hoffe, dieser Server ist hilfreich für jemanden, Lizenz BSD-3, doppeltes Urheberrecht, denn ohne die Firma, in der ich arbeite, hätte ich auch keinen Server geschrieben. Ich bin der einzige Entwickler. Ich wäre dankbar für gefundene Bugs und Feature-Anfragen.
Quelle: habr.com
