


Da ClickHouse ein spezialisiertes System ist, ist es wichtig, bei seiner Verwendung die Besonderheiten seiner Architektur zu berücksichtigen. In diesem Bericht wird Alexey Beispiele für typische Fehler vorstellen, die bei der Nutzung von ClickHouse auftreten können und die zu ineffizientem Arbeiten führen. An praktischen Beispielen wird gezeigt, wie die Wahl eines bestimmten Datenverarbeitungsschemas die Leistung erheblich beeinflussen kann.
Hallo zusammen! Ich bin Alexey, und ich arbeite mit ClickHouse.

Zunächst möchte ich euch erfreuen, ich werde euch heute nicht erzählen, was ClickHouse ist. Ehrlich gesagt, ich habe genug davon. Ich erkläre das ständig, und wahrscheinlich weiß es mittlerweile jeder.

Stattdessen werde ich darüber sprechen, welche Stolpersteine es gibt, d. h. wie man ClickHouse falsch nutzen kann. Tatsächlich braucht man keine Angst zu haben, denn wir entwickeln ClickHouse als ein System, das einfach, benutzerfreundlich und sofort einsatzbereit ist. Einfach installiert und alles läuft, ohne Probleme.
Dennoch sollte man berücksichtigen, dass dieses System spezialisiert ist, und es ist leicht, auf ungewöhnliche Nutzungsszenarien zu stoßen, die das System aus seiner komfortablen Zone herausführen.
Also, was sind die Stolpersteine? Im Wesentlichen werde ich über die offensichtlichen Dinge sprechen. Jeder sieht es ein, alle verstehen es, und können sich freuen, dass sie so klug sind. Und wer es nicht versteht, wird etwas Neues lernen.

Das erste einfache Beispiel, das leider häufig vorkommt, ist eine große Anzahl von Inserts mit kleinen Batches, d.h. viele kleine Inserts.
Wenn man betrachtet, wie ClickHouse Inserts ausführt, können Sie mit einer einzigen Abfrage einen Datenstrom von einem Terabyte senden. Das ist kein Problem.
Schauen wir uns die typische Leistung an. Zum Beispiel haben wir eine Tabelle mit Daten von Yandex.Metrica. Hits. 105 Spalten. 700 Byte in unkomprimierter Form. Und wir werden ordentlich in Batches mit einer Million Zeilen einfügen.
Wir fügen in die MergeTree-Tabelle ein, es kommen eine halbe Million Zeilen pro Sekunde. Ausgezeichnet. In die replizierte Tabelle wird es etwas weniger, etwa 400.000 Zeilen pro Sekunde.
Wenn man die Quorum-Insertion aktiviert, erhält man etwas weniger, aber immer noch eine anständige Leistung, 250.000 Zeilen pro Sekunde. Die Quorum-Insertion ist eine undocumented feature in ClickHouse*.
* Stand 2020, .

Was passiert, wenn man es schlecht macht? Wir fügen Zeile für Zeile in die MergeTree-Tabelle ein und erreichen 59 Zeilen pro Sekunde. Das ist 10.000 Mal langsamer. Bei ReplicatedMergeTree sind es nur 6 Zeilen pro Sekunde. Und wenn dann auch noch ein Quorum aktiviert wird, sind es nur 2 Zeilen pro Sekunde. Meiner Meinung nach ist das ein echtes Desaster. Wie kann es sein, dass es so langsam ist? Ich habe sogar ein T-Shirt, auf dem steht, dass ClickHouse nicht langsam sein sollte. Und trotzdem passiert es manchmal.

Tatsächlich ist das unser Fehler. Wir hätten es so einrichten können, dass alles normal funktioniert, aber das haben wir nicht gemacht. Und wir haben es nicht getan, weil es für unser Szenario nicht nötig war. Wir hatten bereits Batch-Prozesse. Einfach gesagt, die Daten kamen in Batch-Form zu uns, und alles lief reibungslos. Aber natürlich gibt es verschiedene Szenarien. Zum Beispiel, wenn Sie eine Menge Server haben, auf denen Daten generiert werden. Diese fügen nicht so häufig Daten ein, aber es führt trotzdem zu häufigen Einfügungen. Das muss irgendwie vermieden werden.
Technisch gesehen besteht der Kern darin, dass bei einem Insert in ClickHouse die Daten nicht in eine Memtable gelangen. Wir haben nicht einmal einen echten log structure MergeTree, sondern nur einen MergeTree, da es weder ein Log noch eine Memtable gibt. Wir schreiben die Daten direkt ins Dateisystem, bereits in Spalten unterteilt. Wenn Sie 100 Spalten haben, müssen über 200 Dateien in ein separates Verzeichnis geschrieben werden. Das ist ziemlich umständlich.

Es stellt sich die Frage: „Wie macht man es richtig?“, wenn es notwendig ist, Daten auf irgendeine Weise in ClickHouse zu schreiben.
Steg 1. Dies ist die einfachste Methode. Verwenden Sie eine verteilte Warteschlange, wie zum Beispiel Kafka. Sie entnehmen einfach die Daten aus Kafka, batchen jede Sekunde. Und alles wird in Ordnung sein, Sie schreiben, es funktioniert alles einwandfrei.
Ein Nachteil ist, dass Kafka ein weiteres schwerfälliges verteiltes System ist. Ich verstehe, wenn Ihre Firma bereits Kafka hat, das ist gut und bequem. Aber wenn nicht, sollte man dreimal überlegen, bevor man ein weiteres verteiltes System in sein Projekt bringt. Daher sollten Alternativen in Betracht gezogen werden.

Methode 2. Hier ist eine altmodische, aber sehr einfache Alternative. Sie haben einen Server, der Ihre Protokolle erzeugt, und dieser schreibt Ihre Protokolle in eine Datei. Einmal pro Sekunde benennen wir diese Datei um und öffnen eine neue. Ein separiertes Skript, entweder über cron oder einen Daemon, nimmt die älteste Datei und speichert sie in ClickHouse. Wenn Sie die Protokolle einmal pro Sekunde speichern, wird alles hervorragend funktionieren.
Der Nachteil dieser Methode ist, dass, wenn der Server, auf dem die Protokolle erzeugt werden, irgendwo verschwindet, auch die Daten verloren gehen.

Methode 3. Es gibt noch einen weiteren interessanten Ansatz, der ganz ohne temporäre Dateien auskommt. Zum Beispiel haben Sie einen Werbe-Rotator oder einen anderen interessanten Daemon, der Daten generiert. Sie können eine Menge Daten direkt im Arbeitsspeicher, im Puffer, ansammeln. Wenn eine ausreichende Zeit vergangen ist, legen Sie diesen Puffer beiseite, erstellen einen neuen und fügen in einem separaten Thread das, was bereits angesammelt wurde, in ClickHouse ein.
Auf der anderen Seite verschwinden die Daten auch bei einem kill -9. Wenn Ihr Server abstürzt, verlieren Sie diese Daten. Ein weiteres Problem ist, dass, wenn Sie nicht in die Datenbank schreiben konnten, die Daten im RAM gespeichert werden. Entweder wird der RAM voll, oder Sie verlieren einfach die Daten.

Methode 4. Eine weitere interessante Methode. Wenn Sie einen Serverprozess haben, der Daten sofort an ClickHouse senden kann, sollte dies über eine einzige Verbindung geschehen. Zum Beispiel, indem Sie eine HTTP-Anfrage mit transfer-encoding: chunked und einem Insert absenden. Dabei werden nicht zu selten Chunks generiert; Sie können jede Zeile senden, obwohl es Overhead für das Framing dieser Daten gibt.
Dennoch werden in diesem Fall die Daten sofort an ClickHouse gesendet. ClickHouse wird sie selbst puffern.
Es treten jedoch auch Probleme auf. Sie werden Daten verlieren, insbesondere wenn Ihr Prozess abgestürzt ist, und auch wenn der ClickHouse-Prozess abstürzt, da dies ein unvollständiges Insert zur Folge hat. In ClickHouse sind Inserts bis zu einer bestimmten Zeilenanzahl atomar. Im Grunde ist dies eine interessante Methode. Sie kann ebenfalls genutzt werden.

Methode 5. Hier ist eine weitere interessante Möglichkeit. Dies ist ein von der Community entwickelter Server für das Batch-Processing von Daten. Ich habe selbst nicht darauf geschaut, daher kann ich nichts garantieren. Ebenso werden für ClickHouse keine Garantien gegeben. Es ist ebenfalls Open Source, aber Sie könnten an einem bestimmten Qualitätsstandard gewöhnt sein, den wir zu gewährleisten versuchen. Für dieses Tool – ich weiß es nicht, schauen Sie auf GitHub nach und werfen Sie einen Blick in den Code. Vielleicht wurde etwas Sinnvolles geschrieben.
* Stand 2020, sollte auch zur Diskussion hinzugefügt werden .

Methode 6. Eine weitere Möglichkeit ist die Verwendung von Buffer-Tabellen. Die Vorteile dieser Methode liegen darin, dass es sehr einfach ist, sie zu verwenden. Sie erstellen eine Buffer-Tabelle und fügen Daten hinzu.
Das Problem ist jedoch, dass es nicht vollständig gelöst wird. Wenn Sie bei einer MergeTree-Einfügung die Daten mit einem Batch pro Sekunde gruppieren müssen, sollten Sie bei der Puffer-Tabelle wenigstens einige Tausend pro Sekunde gruppieren. Wenn es mehr als 10.000 pro Sekunde sind, ist das immer noch schlecht. Wenn Sie in Batches einfügen, sehen Sie, dass dort Hunderttausende von Zeilen pro Sekunde verarbeitet werden, und das auch mit ziemlich schweren Daten.
Außerdem haben die Puffer-Tabellen kein Log. Wenn also mit Ihrem Server etwas nicht stimmt, gehen die Daten verloren.

Als Bonus haben wir kürzlich die Möglichkeit hinzugefügt, Daten aus Kafka in ClickHouse zu holen. Es gibt eine Tabellen-Engine namens Kafka. Sie erstellen einfach eine solche Tabelle, und Sie können materialisierte Ansichten darauf anwenden. In diesem Fall wird die Engine die Daten selbst aus Kafka entnehmen und in die gewünschten Tabellen einfügen.
Besonders erfreulich an dieser Möglichkeit ist, dass sie nicht von uns stammt. Es ist eine Funktion der Community. Und wenn ich "Community-Funktion" sage, dann ohne jegliche Herabsetzung. Wir haben den Code gelesen, überprüfen lassen, es sollte also normal funktionieren.
* Stand 2020, gab es eine ähnliche Unterstützung für .

Was könnte beim Einfügen von Daten noch unbequem oder unerwartet sein? Wenn Sie eine Anfrage "insert values" machen und in den "values" berechnete Ausdrücke schreiben. Zum Beispiel ist now() ebenfalls ein berechneter Ausdruck. In diesem Fall muss ClickHouse den Interpreter dieser Ausdrücke für jede Zeile aufrufen, was die Leistung erheblich beeinträchtigt. Es ist besser, dies zu vermeiden.
* Derzeit ist das Problem vollständig gelöst, es gibt keine Rückgänge in der Leistung mehr bei der Verwendung von Ausdrücken in VALUES.
Ein weiteres Beispiel für mögliche Probleme ist, wenn Ihre Daten in einem Batch zu mehreren Partitionen gehören. Standardmäßig hat ClickHouse Partitionen nach Monaten. Wenn Sie einen Batch aus einer Million Zeilen einfügen und die Daten über mehrere Jahre verteilt sind, haben Sie mehrere Dutzend Partitionen. Das entspricht dem Einfügen von Batches, die um ein Vielfaches kleiner sind, da sie zuerst nach Partitionen aufgeteilt werden.
* Kürzlich wurde in ClickHouse im experimentellen Modus die Unterstützung für kompaktes Format von Stücken und Stücken im Arbeitsspeicher mit Write-Ahead-Log hinzugefügt, was das Problem fast vollständig löst.

Lassen Sie uns nun die zweite Art von Problem betrachten – die Typisierung von Daten.
Die Typisierung von Daten kann streng oder als Stringtyp erfolgen. Stringtyp bedeutet, dass Sie einfach erklärt haben, dass alle Ihre Felder vom Typ string sind. Das ist nicht optimal. So sollte man es nicht machen.
Lassen Sie uns klären, wie man es richtig macht, wenn man sagen möchte, dass ein gewisses Feld ein String ist, und ClickHouse den Rest selbst regeln kann, ohne dass ich mir darum Gedanken machen muss. Dennoch ist es sinnvoll, gewisse Anstrengungen zu unternehmen.

Nehmen wir zum Beispiel eine IP-Adresse. In einem Fall haben wir sie als String gespeichert, etwa 192.168.1.1. Im anderen Fall wird sie als Zahl vom Typ UInt32* gespeichert. 32 Bit sind ausreichend für eine IPv4-Adresse.
Erstens, erstaunlicherweise werden die Daten ähnlich komprimiert. Es wird zwar Unterschiede geben, aber sie sind nicht allzu groß. Daher gibt es beim Datentransfer auf der Festplatte keine besonderen Probleme.
Es gibt jedoch einen signifikanten Unterschied in der CPU-Zeit und in der Ausführungszeit der Abfrage.
Wir berechnen die Anzahl der einzigartigen IP-Adressen, wenn sie als Zahlen gespeichert sind. Das ergibt 137 Millionen Zeilen pro Sekunde. Dasselbe in Form von Strings ergibt 37 Millionen Zeilen pro Sekunde. Ich weiß nicht, warum es eine solche Übereinstimmung gibt. Ich habe diese Abfragen selbst durchgeführt. Dennoch ist es ungefähr viermal langsamer.
Und wenn wir den Unterschied im Speicherplatz auf der Festplatte berücksichtigen, gibt es auch Unterschiede. Dieser liegt etwa bei einem Viertel, da es ziemlich viele einzigartige IP-Adressen gibt. Wären hier Zeilen mit einer kleinen Anzahl unterschiedlicher Werte, würden sie im Wörterbuch wahrscheinlich auf ein ähnliches Volumen komprimiert werden.
Und ein vierfacher Zeitunterschied liegt nicht einfach so auf der Straße. Vielleicht ist es Ihnen egal, aber wenn ich einen solchen Unterschied sehe, macht es mich traurig.

Betrachten wir verschiedene Fälle.
1. Ein Fall, wenn Sie nur wenige verschiedene einzigartige Werte haben. In diesem Fall verwenden wir eine einfache Praxis, die Sie wahrscheinlich kennen und für jede Datenbank verwenden können. Das macht nicht nur für ClickHouse Sinn. Sie speichern einfach numerische Identifikatoren in der Datenbank. Und die Umwandlung in Strings und zurück kann bereits auf der Seite Ihrer Anwendung erfolgen.
Nehmen wir zum Beispiel eine Region. Sie versuchen, sie als String zu speichern. Dort steht dann: Moskau und MO. Wenn ich nur "Moskau" sehe, ist das noch in Ordnung, aber wenn auch MO dazu kommt, wird es irgendwie traurig. Das sind schließlich viele Bytes.
Stattdessen schreiben wir einfach die Zahl Ulnt32 und 250. Bei uns sind es 250 in Yandex, bei Ihnen könnte es anders sein. Zur Sicherheit erwähne ich, dass ClickHouse eine integrierte Funktion zur Arbeit mit Geodatenbanken hat. Sie speichern einfach ein Verzeichnis mit Regionen, einschließlich hierarchischer Struktur, das heißt, dort wird auch Moskau und MO enthalten sein und alles, was Sie benötigen. Außerdem können Sie auf Abfrageebene konvertieren.

Die zweite Variante ist ähnlich, aber mit Unterstützung innerhalb von ClickHouse. Es handelt sich um den Datentyp Enum. Sie geben einfach innerhalb von Enum alle benötigten Werte an. Zum Beispiel den Gerätetyp und schreiben dort: Desktop, Mobilgerät, Tablet, Fernseher. Insgesamt gibt es 4 Varianten.
Der Nachteil besteht darin, dass gelegentlich ein Alter benötigt wird. Wir haben nur eine einzige Variante hinzugefügt. Wir führen Alter Tabelle durch. Tatsächlich ist das Alter Tabelle in ClickHouse kostenlos. Besonders kostenlos für Enum, da sich die Daten auf der Festplatte nicht ändern. Dennoch erfordert das Alter eine Sperrung* der Tabelle und muss warten, bis alle Selects abgeschlossen sind. Erst danach wird das Alter ausgeführt, also gibt es doch einige Unannehmlichkeiten.
* In den neuesten Versionen von ClickHouse ist ALTER vollständig nicht blockierend.

Eine weitere, recht einzigartige Möglichkeit für ClickHouse ist die Anbindung externer Dictionaries. Sie können Zahlen in ClickHouse schreiben, während Ihre Verzeichnisse in einem beliebigen Ihnen angenehmen System verwahrt werden. Beispielsweise können Sie MySQL, Mongo oder Postgres verwenden. Sie können sogar Ihren eigenen Microservice entwickeln, der diese Daten über HTTP bereitstellt. Auf der Ebene von ClickHouse schreiben Sie eine Funktion, die diese Daten von Zahlen in Zeichenfolgen umwandelt.
Dies ist eine spezialisierte, aber sehr effektive Methode, um einen Join mit einer externen Tabelle durchzuführen. Dabei gibt es zwei Varianten. In einer Variante werden die Daten vollständig im Cache gehalten, befinden sich komplett im Arbeitsspeicher und werden in regelmäßigen Abständen aktualisiert. In der anderen Variante, wenn diese Daten nicht in den Arbeitsspeicher passen, können sie teilweise im Cache gespeichert werden.
Hier ist ein Beispiel. Nehmen wir Yandex.Direct. Dort gibt es Werbekampagnen und Banner. Es gibt wahrscheinlich etwa zehn Millionen Werbekampagnen, die im Arbeitsspeicher Platz finden. Die Banner hingegen – Milliarden davon, die passen nicht. Wir verwenden ein speicherbares Dictionary aus MySQL.
Das einzige Problem ist, dass das speicherbare Dictionary nur gut funktioniert, wenn die Trefferquote nahe 100 % liegt. Ist sie niedriger, müssen beim Verarbeiten der Anfragen für jede Datenmenge tatsächlich die fehlenden Schlüssel abgerufen und die Daten aus MySQL geholt werden. Bei ClickHouse kann ich garantieren, dass es nicht stockt; über andere Systeme möchte ich jedoch keine Aussagen treffen.
Ein zusätzlicher Vorteil besteht darin, dass Dictionaries eine sehr einfache Möglichkeit bieten, Daten in ClickHouse rückwirkend zu aktualisieren. Das bedeutet, wenn Sie einen Bericht über Werbekampagnen hatten und der Benutzer die Werbekampagne ändert, ändern sich auch alle alten Daten und Berichte. Wenn man die Daten direkt in die Tabelle schreibt, wäre eine Aktualisierung nicht möglich.

Eine weitere Möglichkeit besteht darin, dass Sie nicht wissen, woher Sie die Identifikatoren für Ihre Zeilen bekommen. Sie können einfach hashieren. Der einfachste Weg ist, einen 64-Bit-Hash zu verwenden.
Das einzige Problem dabei ist, dass es bei einem 64-Bit-Hash fast sicher Kollisionen geben wird. Wenn es eine Milliarde Zeilen gibt, wird die Wahrscheinlichkeit erheblich.
Es wäre auch nicht ideal, die Namen der Werbekampagnen so zu hashen. Wenn die Werbekampagnen verschiedener Unternehmen durcheinander geraten, wird es unverständlich.
Es gibt einen einfachen Trick. Natürlich ist es für ernsthafte Daten nicht besonders geeignet, aber wenn es um weniger kritische Dinge geht, fügen Sie einfach eine Kunden-ID zum Dictionary-Schlüssel hinzu. Dann werden Kollisionen auftreten, aber nur innerhalb eines einzelnen Kunden. Diese Methode verwenden wir für die Link-Karte in Yandex.Metrica. Dort haben wir URLs, wir speichern Hashes. Und wir wissen, dass es Kollisionen gibt. Aber wenn die Seite angezeigt wird, ist die Wahrscheinlichkeit gering, dass auf einer Seite bei einem bestimmten Benutzer zwei URLs zusammenfallen und dies bemerkt wird, sodass wir das ignorieren können.
Als Bonus – für viele Operationen reichen tatsächlich Hashes aus und die Strings müssen nirgendwo gespeichert werden.

Ein anderes Beispiel: Wenn die Strings kurz sind, zum Beispiel die Domains von Websites. Sie können sie so speichern, wie sie sind. Oder, wie zum Beispiel, die Sprache des Browsers ru – 2 Bytes. Natürlich tut es mir leid um diese Bytes, aber keine Sorge, es sind nur 2 Bytes, da kann man sich nicht beschweren. Bitte speichern Sie sie so, wie sie sind, machen Sie sich keine Gedanken.

Ein weiteres Szenario, bei dem es sehr viele Strings gibt und diese wiederum sehr viele einzigartige Werte enthalten, ist die Verwendung von Suchanfragen oder URLs. Suchanfragen, auch aufgrund von Tippfehlern. Lassen Sie uns also sehen, wie viele einzigartige Suchanfragen in einem Tag vorkommen. Dabei zeigt sich, dass sie fast die Hälfte aller Ereignisse ausmachen. In diesem Fall könnten Sie denken, dass die Daten normalisiert werden müssen, indem Sie Identifikatoren zählen und in eine separate Tabelle speichern. Aber das sollten Sie nicht tun. Bewahren Sie diese Strings einfach in ihrer ursprünglichen Form auf.
Am besten ist es, wenn Sie sich keine neuen Strukturen ausdenken, denn wenn Sie sie separat speichern, müssen Sie Joins durchführen. Und dieser Join geht im besten Fall mit zufälligem Speicherzugriff einher, vorausgesetzt, es passt noch in den Speicher. Wenn nicht, wird es wirklich problematisch.
Wenn die Daten jedoch inplace gespeichert werden, werden sie einfach in der erforderlichen Reihenfolge aus dem Dateisystem abgerufen, und alles läuft reibungslos.

Wenn Sie URLs oder eine andere komplexe, lange Zeichenfolge haben, sollten Sie darüber nachdenken, ob Sie nicht im Voraus eine Zusammenfassung berechnen und in eine separate Spalte speichern können.
Für URLs können Sie beispielsweise die Domain separat speichern. Wenn Sie tatsächlich eine Domain benötigen, nutzen Sie einfach diese Spalte, während die URLs dort bleiben, ohne dass Sie sie berühren müssen.
Lassen Sie uns die Unterschiede betrachten. In ClickHouse gibt es eine spezialisierte Funktion zur Berechnung der Domain. Sie ist sehr schnell, wir haben sie optimiert. Und ehrlich gesagt, sie entspricht nicht einmal dem RFC, aber dennoch berechnet sie alles, was wir brauchen.
In einem Fall extrahieren wir einfach die URLs und berechnen die Domain. Das dauert 166 Millisekunden. Wenn wir jedoch die fertige Domain verwenden, sind es nur 67 Millisekunden, also fast dreimal schneller. Das liegt nicht daran, dass wir Berechnungen durchführen müssen, sondern daran, dass wir weniger Daten lesen.
Aus irgendeinem Grund hat eine langsamere Abfrage eine höhere Geschwindigkeit in Gigabyte pro Sekunde. Das liegt daran, dass sie mehr Gigabyte liest. Diese zusätzlichen Daten sind vollkommen überflüssig. Die Abfrage scheint schneller zu arbeiten, benötigt jedoch mehr Zeit für die Ausführung.
Wenn man den Datenumfang auf der Festplatte betrachtet, ergibt sich, dass die URL 126 Megabyte groß ist, während die Domain nur 5 Megabyte benötigt. Das ist 25 Mal weniger. Dennoch wird die Anfrage lediglich 4 Mal schneller ausgeführt. Das liegt daran, dass die Daten hot sind. Wären sie kalt, wäre es wahrscheinlich 25 Mal schneller aufgrund der Festplatten-I/O.
Übrigens, wenn man beurteilt, wie viel kleiner die Domain im Vergleich zur URL ist, stellt man fest, dass sie ungefähr 4 Mal kleiner ist. Merkwürdigerweise benötigen die Daten auf der Festplatte jedoch 25 Mal weniger Platz. Warum? Wegen der Kompression. Sowohl die URL als auch die Domain werden komprimiert. Oft enthält die URL auch viel unnötigen Ballast.

Es ist natürlich wichtig, die richtigen Datentypen zu verwenden, die speziell für die benötigten Werte bestimmt sind oder passend sind. Wenn Sie IPv4 verwenden, speichern Sie UInt32*. Bei IPv6 verwenden Sie FixedString(16), denn eine IPv6-Adresse ist 128 Bit, also speichern Sie sie direkt im Binärformat.
Was ist zu tun, wenn Sie manchmal IPv4-Adressen und manchmal IPv6-Adressen haben? Ja, Sie können beide speichern. Eine Spalte für IPv4, die andere für IPv6. Natürlich gibt es die Möglichkeit, IPv4 in IPv6 darzustellen. Das funktioniert ebenfalls, aber wenn Sie in Ihren Anfragen häufig genau die IPv4-Adresse benötigen, wäre es sinnvoll, sie in einer separaten Spalte zu speichern.
* Jetzt gibt es in ClickHouse separate Datentypen für IPv4 und IPv6, die Daten ebenso effizient speichern wie Zahlen, jedoch so benutzerfreundlich darstellen wie Strings.

Es ist auch wichtig zu beachten, dass die Daten im Voraus verarbeitet werden sollten. Zum Beispiel, wenn Ihnen rohe Logs vorliegen. Es mag verlockend sein, sie sofort in ClickHouse zu importieren, auch wenn es sehr verlockend ist, nichts zu tun und alles würde funktionieren. Aber es ist dennoch sinnvoll, die Berechnungen, die möglich sind, durchzuführen.
Zum Beispiel die Browserversion. In einer benachbarten Abteilung, auf die ich nicht zeigen möchte, wird die Browserversion so gespeichert, d.h. als String: 12.3. Und dann, um einen Bericht zu erstellen, nehmen sie diesen String und teilen ihn in ein Array auf, und dann den ersten Element des Arrays. Natürlich sorgt das für Verzögerungen. Ich habe gefragt, warum sie das so machen. Sie antworteten, dass sie voreilige Optimierungen nicht mögen. Ich hingegen mag voreilige Pessimierungen nicht.
In diesem Fall wäre es also besser, in 4 Spalten zu unterteilen. Scheuen Sie sich nicht, denn das ist ClickHouse. ClickHouse ist eine spaltenbasierte Datenbank. Und je mehr ordentliche, kleine Spalten, desto besser. Wenn es 5 BrowserVersionen gibt, erstellen Sie 5 Spalten. Das ist in Ordnung.

Betrachten wir nun, was zu tun ist, wenn Sie viele sehr lange Texte oder Arrays haben. Diese müssen überhaupt nicht in ClickHouse gespeichert werden. Stattdessen können Sie in ClickHouse nur eine Art Identifikator speichern. Die langen Texte sollten Sie in ein anderes System schieben.
Zum Beispiel haben wir in einem unserer Analyse-Services einige Ereignisparameter. Wenn bei den Ereignissen viele Parameter auftauchen, speichern wir einfach die ersten 512. Denn 512 ist es wert.

Wenn Sie sich nicht über Ihre Datentypen sicher sind, können Sie die Daten ebenfalls in ClickHouse speichern, jedoch in einer temporären Tabelle vom Typ Log, die speziell für temporäre Daten gedacht ist. Danach können Sie analysieren, wie Ihre Verteilung der Werte aussieht, was es überhaupt gibt und die richtigen Typen festlegen.
* Aktuell gibt es in ClickHouse einen Datentyp der es ermöglicht, Strings effizient mit geringeren Ressourcenaufwand zu speichern.

Lassen Sie uns einen weiteren interessanten Fall betrachten. Manchmal funktioniert alles bei den Leuten irgendwie seltsam. Ich logge mich ein und sehe das. Und sofort kommt mir in den Sinn, dass dies von einem sehr erfahrenen, klugen Administrator mit umfassender Erfahrung in der Konfiguration von MySQL Version 3.23 gemacht wurde.
Hier sehen wir tausend Tabellen, in denen jeweils der Rest einer unklaren Division durch tausend gespeichert ist.
Im Grunde respektiere ich die Erfahrung anderer, verstehe jedoch auch, welch große Mühen hinter dieser Erfahrung stecken können.

Die Gründe sind mehr oder weniger verständlich. Es sind alte Stereotypen, die sich aus der Arbeit mit anderen Systemen angesammelt haben könnten. Zum Beispiel gibt es in MyISAM-Tabellen keinen clusterweiten Primärschlüssel. Und diese Art der Datenaufteilung könnte ein verzweifelter Versuch sein, dieselbe Funktionalität zu erreichen.
Ein anderer Grund ist, dass verschiedene Operationen wie ALTER an großen Tabellen schwierig sind. Es kommt zu Sperrungen. Obwohl dieses Problem in modernen Versionen von MySQL nicht mehr so gravierend ist.
Oder zum Beispiel Mikroschardierung, aber darüber später mehr.

In ClickHouse ist das nicht notwendig, denn erstens ist der Primärschlüssel ein Cluster, und die Daten sind nach dem Primärschlüssel sortiert.
Manchmal werde ich gefragt: „Wie beeinflusst die Größe einer Tabelle die Leistung von Bereichsanfragen in ClickHouse?“ Ich antworte, dass es keinen Unterschied macht. Zum Beispiel, wenn Sie eine Tabelle mit einer Milliarde Zeilen haben und eine Million Zeilen abfragen, funktioniert alles einwandfrei. Wenn die Tabelle eine Billion Zeilen hat und Sie eine Million Zeilen abfragen, ist das nahezu identisch.
Zudem sind keine manuellen Partitionierungsmöglichkeiten erforderlich. Wenn Sie sich die Dateisystemstruktur ansehen, werden Sie feststellen, dass eine Tabelle eine bedeutende Struktur hat. Innerhalb dieser Struktur gibt es etwas Ähnliches wie Partitionen. ClickHouse erledigt dies alles automatisch für Sie, sodass Sie keine Schwierigkeiten haben müssen.

In ClickHouse ist der Befehl ALTER kostenfrei, wenn es um das Hinzufügen oder Entfernen von Spalten geht.
Es ist nicht sinnvoll, kleine Tabellen zu verwenden, denn ob Sie 10 oder 10.000 Zeilen in einer Tabelle haben, spielt keine Rolle. ClickHouse optimiert den Durchsatz und nicht die Latenz, weshalb es keinen Sinn macht, nur 10 Zeilen zu verarbeiten.

Es ist ratsam, eine große Tabelle zu nutzen. Lassen Sie die alten Vorurteile hinter sich, alles wird gut.
In der neuesten Version haben wir die Möglichkeit eingeführt, benutzerdefinierte Partitionierungsschlüssel zu erstellen, um verschiedene Wartungsoperationen an einzelnen Partitionen durchzuführen.
Wenn Sie viele kleine Tabellen benötigen, beispielsweise zur Verarbeitung von temporären Daten, die in Form von Chunks ankommen und vor dem Speichern in die endgültige Tabelle umgewandelt werden müssen. In diesem Fall gibt es eine hervorragende Tabellenengine – StripeLog. Es funktioniert ähnlich wie TinyLog, ist jedoch besser.
* Aktuell gibt es in ClickHouse auch .

Ein weiteres Antipattern ist das Mikroscharding. Wenn Sie Daten shardieren müssen und 5 Server haben, aber morgen 6 Server benötigen, stellen Sie sich die Frage, wie Sie die Daten umverteilen. Anstatt auf 5 Shards zu partitionieren, erstellen Sie 1.000 Shards. Danach ordnen Sie jeden dieser Mikroschards einem einzelnen Server zu. Das bedeutet, dass Sie auf einem Server beispielsweise 200 ClickHouse-Instanzen haben könnten, jeweils auf separaten Ports oder in separaten Datenbanken.

In ClickHouse ist das jedoch nicht optimal. Selbst ein einzelner ClickHouse-Instanz versucht, alle verfügbaren Serverressourcen für die Verarbeitung einer Anfrage zu nutzen. Angenommen, Sie haben einen Server mit 56 CPU-Kernen. Wenn Sie eine Anfrage ausführen, die eine Sekunde dauert, werden alle 56 Kerne verwendet. Wenn Sie jedoch 200 ClickHouse-Instanzen auf demselben Server hosten, werden 10.000 Threads gestartet. Das Ergebnis wird sehr ineffizient sein.
Ein weiterer Grund ist, dass die Arbeitsverteilung auf diesen Instanzen ungleichmäßig sein wird. Einige werden früher abgeschlossen, andere später. Wäre alles in einer einzigen Instanz, könnte ClickHouse selbst die Daten optimal auf die Threads verteilen.
Ein zusätzlicher Grund ist, dass es zu Inter-Prozess-Kommunikation über TCP kommen wird. Daten müssen serialisiert und deserialisiert werden, und dabei entstehen wesentlich mehr Mikroscharten. Das führt zu einer ineffizienten Arbeitsweise.

Ein weiteres Problem, obwohl es schwer als solches zu bezeichnen ist, ist die große Anzahl an Voraggregation.
Im Grunde genommen ist Prädaggregation vorteilhaft. Hatten Sie eine Milliarde Zeilen, haben Sie sie aggregiert, und es sind nur noch 1.000 Zeilen übrig, sodass die Abfrage jetzt blitzschnell ausgeführt wird. Alles ist wunderbar. So kann man das machen. Dafür gibt es sogar in ClickHouse einen speziellen Tabellentyp, den AggregatingMergeTree, der inkrementelle Aggregationen während des Datenimports durchführt.
Es gibt jedoch Situationen, in denen man denkt, dass wir die Daten so aggregieren werden und dann noch auf diese Weise. Und in einer benachbarten Abteilung, die ich lieber nicht benennen möchte, verwenden sie SummingMergeTree-Tabellen zur Summierung nach dem Primärschlüssel, wobei sie als Primärschlüssel etwa 20 verschiedene Spalten nutzen. Ich habe zur Sicherheit einige Spaltennamen für die Anonymität geändert, aber so in etwa ist es.

Hierbei entstehen bestimmte Probleme. Erstens verringert sich das Datenvolumen nicht signifikant. Beispielsweise reduziert es sich nur um das Dreifache. Dreimal wäre ein akzeptabler Preis, um sich unbegrenzte Analytik-Möglichkeiten leisten zu können, die entstehen, wenn die Daten unaggregiert sind. Wenn die Daten jedoch aggregiert sind, erhalten Sie statt einer Analyse lediglich mickrige Statistiken.
Und was besonders ärgerlich ist? Dass diese Leute aus der benachbarten Abteilung manchmal kommen und bitten, eine weitere Spalte zum Primärschlüssel hinzuzufügen. Das heißt, wir haben die Daten so aggregiert, und jetzt wollen wir etwas mehr. Aber in ClickHouse gibt es keinen Befehl zum Ändern des Primärschlüssels. Daher muss man irgendwelche Skripte in C++ schreiben. Und ich mag Skripte nicht, selbst wenn sie in C++ sind.
Wenn man sich anschaut, wofür ClickHouse entwickelt wurde, sind nicht aggregierte Daten genau das Szenario, für das es gedacht ist. Wenn Sie ClickHouse für nicht aggregierte Daten nutzen, machen Sie alles richtig. Aggregieren Sie jedoch, ist das manchmal verzeihlich.
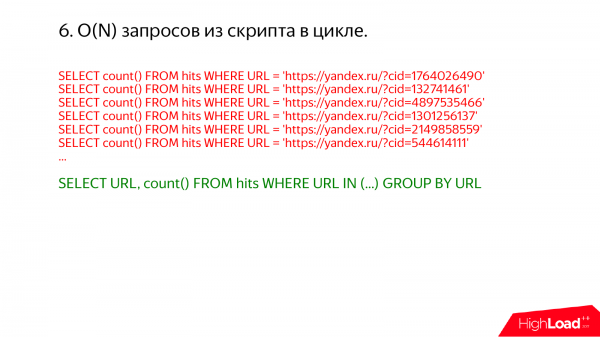
Ein weiterer interessanter Fall sind Anfragen in einer Endlosschleife. Manchmal gehe ich auf einen Produktionsserver und schaue mir dort die Prozessliste an. Und jedes Mal entdecke ich, dass etwas Schreckliches passiert.
Zum Beispiel so etwas. Hier ist sofort klar, dass alles in einer einzigen Anfrage hätte ausgeführt werden können. Einfach dort url in und die Liste schreiben.

Warum ist es schlecht, wenn viele solcher Anfragen in einer Endlosschleife auftreten? Wenn der Index nicht verwendet wird, durchlaufen Sie dieselben Daten viele Male. Aber wenn der Index verwendet wird, zum Beispiel wenn Sie einen Primärschlüssel für ru haben und url = irgendetwas schreiben. Und Sie denken, dass eine spezifische url aus der Tabelle abgerufen wird, wird alles gut sein. In Wirklichkeit ist das jedoch nicht der Fall. Denn ClickHouse macht alles in Chargen.
Wenn es notwendig ist, einen bestimmten Datenbereich zu lesen, wird etwas mehr gelesen, da der Index in ClickHouse spärlich ist. Dieser Index kann nicht eine einzelne Zeile in der Tabelle finden, sondern nur einen bestimmten Bereich. Die Daten werden blockweise komprimiert. Um eine einzige Zeile zu lesen, muss der gesamte Block genommen und dekomprimiert werden. Wenn Sie also viele Anfragen ausführen, wird es viele Überschneidungen geben und eine Menge Arbeit wird immer wiederholt.

Ein Bonus, den man erwähnen sollte, ist, dass man in ClickHouse keine Angst haben muss, sogar Megabytes und Hundert Megabytes in die IN-Klausel zu übergeben. Aus unserer Erfahrung weiß ich, dass MySQL, wenn wir viele Werte in die IN-Klausel übergeben, beispielsweise 100 Megabyte irgendwelcher Zahlen, 10 Gigabyte Arbeitsspeicher benötigt und dann nichts weiter passiert – alles funktioniert schlecht.
Und der zweite Punkt ist, dass in ClickHouse, wenn Ihre Abfragen einen Index verwenden, sie niemals langsamer sind als ein Full Scan, d. h. wenn nahezu die gesamte Tabelle gelesen werden muss, erfolgt dies sequentiell und es wird die gesamte Tabelle gelesen. ClickHouse organisiert das selbst.
Dennoch gibt es einige Herausforderungen. Zum Beispiel wird der IN-Befehl mit Unterabfragen keinen Index benutzen. Das ist unser Problem und wir müssen das beheben. Es gibt hier nichts Fundamentales. Wir werden es reparieren.
Und noch etwas Interessantes – wenn Sie eine sehr lange Abfrage haben und die Abfragedistribution auf mehreren Servern erfolgt, wird diese sehr lange Abfrage auf jeden Server ohne Kompression gesendet. Zum Beispiel 100 Megabyte und 500 Server. Somit werden über das Netzwerk 50 Gigabyte übertragen. Es wird übertragen und alles wird anschließend erfolgreich ausgeführt.
* nutzt bereits; alles wurde wie versprochen repariert.

Es ist durchaus häufig, dass Anfragen aus APIs kommen. Angenommen, Sie haben einen eigenen Dienst. Und wenn dieser Dienst benötigt wird, haben Sie eine API geöffnet und sehen bereits nach zwei Tagen, dass etwas Ungewöhnliches passiert. Alles ist überlastet und es kommen schreckliche Anfragen, die niemals gestellt werden sollten.
Die Lösung ist einfach. Wenn Sie eine API geöffnet haben, müssen Sie sie limitieren. Zum Beispiel, indem Sie Quoten einführen. Es gibt keine anderen vernünftigen Optionen. Andernfalls wird sofort ein Skript geschrieben, und es gibt Probleme.
In ClickHouse gibt es eine spezielle Funktion - die Quotenverwaltung. Sie können sogar Ihren eigenen Quoten-Schlüssel übergeben. Dies könnte beispielsweise eine interne Benutzer-ID sein. Die Quoten werden dann unabhängig für jeden einzelnen von ihnen gezählt.

Jetzt noch etwas Interessantes. Dies betrifft die manuelle Replikation.
Ich kenne viele Fälle, in denen, obwohl ClickHouse eine integrierte Unterstützung für Replikation bietet, die Leute ClickHouse manuell replizieren.
Welches Prinzip? Sie haben eine Datenverarbeitungspipeline, die unabhängig funktioniert, zum Beispiel in verschiedenen Rechenzentren. Sie zeichnen die gleichen Daten auf die gleiche Weise in ClickHouse auf. Allerdings zeigt die Praxis, dass die Daten aufgrund bestimmter Besonderheiten in Ihrem Code trotzdem voneinander abweichen werden. Ich hoffe, das ist bei Ihnen nicht der Fall.
Und hin und wieder müssen Sie trotzdem manuell synchronisieren. Beispielsweise führen die Administratoren einmal im Monat einen rsync durch.
Tatsächlich ist es viel einfacher, die eingebaute Replikation in ClickHouse zu verwenden. Es gibt jedoch einige Vorbehalte, denn dafür muss ZooKeeper verwendet werden. Ich werde nichts Schlechtes über ZooKeeper sagen; grundsätzlich ist das System funktional, aber manchmal vermeiden es die Leute aufgrund von Java-Phobie, weil ClickHouse ein tolles System ist, das in C++ geschrieben wurde und sehr gut funktioniert. ZooKeeper hingegen läuft auf Java. Und es ist irgendwie nicht angenehm, sich damit zu beschäftigen; dann können Sie auch die manuelle Replikation nutzen.

ClickHouse ist ein praktisches System, das auf Ihre Bedürfnisse zugeschnitten ist. Wenn Sie manuelle Replikation verwenden, können Sie eine verteilte Tabelle erstellen, die auf Ihre manuellen Replikate zugreift und automatisch zwischen ihnen Failover durchführt. Es gibt sogar eine spezielle Option, die es Ihnen ermöglicht, Flaps zu vermeiden, selbst wenn Ihre Replikate systematisch voneinander abweichen.

Es können Probleme auftreten, wenn Sie primitive Tabellen-Engines verwenden. ClickHouse ist ein Aufbau mit einer Vielzahl verschiedener Tabellengere, die Sie nutzen können. Für alle ernsthaften Anwendungsfälle, wie in der Dokumentation beschrieben, verwenden Sie Tabellen der MergeTree-Familie. Alle anderen sind für spezielle Fälle oder für Tests gedacht.
In einer MergeTree-Tabelle ist es nicht unbedingt erforderlich, dass Sie ein Datum und eine Uhrzeit haben. Sie können es dennoch verwenden. Wenn kein Datum und keine Uhrzeit vorhanden sind, geben Sie an, dass das Standarddatum das Jahr 2000 ist. Das funktioniert und erfordert keine zusätzlichen Ressourcen.
In der neuen Serverversion können Sie sogar angeben, dass Sie eine benutzerdefinierte Partitionierung ohne Partitionierungsschlüssel haben möchten. Es wird dasselbe sein.

Auf der anderen Seite können primitive Tabellen-Engines verwendet werden. Zum Beispiel, einmalige Datenzufuhr und dann analysieren, drehen und löschen. Sie können Log verwenden.
Oder die Speicherung kleiner Datenmengen für die Zwischenverarbeitung – das ist StripeLog oder TinyLog.
Memory kann genutzt werden, wenn nur eine kleine Datenmenge vorhanden ist und einfach etwas im RAM gedreht werden soll.

ClickHouse mag übernormalisierte Daten nicht besonders.
Hier ist ein typisches Beispiel. Das ist eine große Anzahl von URLs. Sie haben sie in eine benachbarte Tabelle gesteckt. Dann haben Sie entschieden, einen JOIN damit durchzuführen, aber das wird in der Regel nicht funktionieren, da ClickHouse nur Hash JOIN unterstützt. Wenn nicht genügend RAM vorhanden ist, um mit den vielen Daten, die verbunden werden müssen, umzugehen, kann der JOIN nicht durchgeführt werden*.
Wenn die Daten eine hohe Kardinalität haben, machen Sie sich keine Sorgen, speichern Sie sie in denormalisierter Form, URLs direkt inplace in der Haupttabelle.
* mittlerweile gibt es in ClickHouse auch den Merge-Join, der funktioniert, wenn die Zwischendaten nicht in den RAM passen. Aber es ist ineffizient und die Empfehlung bleibt bestehen.

Hier sind noch ein paar Beispiele, aber ich bin mir nicht mehr sicher, ob sie wirklich Antipattern sind oder nicht.
ClickHouse hat einen bekannten Nachteil: Es unterstützt keine Updates*. Das hat sogar seine Vorteile. Wenn Sie wichtige Daten haben, etwa aus der Buchhaltung, können diese nicht versendet werden, da keine Updates vorhanden sind.
* Unterstützung für Updates und Deletes im Batch-Modus wurde bereits lange hinzugefügt.
Es gibt jedoch einige spezielle Methoden, mit denen Updates quasi im Hintergrund durchgeführt werden können. Zum Beispiel Tabellen des Typs ReplaceMergeTree, die Updates während der Hintergrundmerges durchführen. Sie können dies mit dem Befehl optimize table forcieren. Aber machen Sie das nicht zu oft, denn das führt zur vollständigen Neubeschreibung der Partition.
Verteilte JOINS in ClickHouse werden vom Abfrageplaner ebenfalls schlecht behandelt.
Schlecht, aber manchmal in Ordnung.
Die Nutzung von ClickHouse nur, um Daten über select* wieder abzurufen.
Ich würde nicht empfehlen, ClickHouse für rechenintensive Berechnungen zu verwenden. Das ist jedoch nicht ganz richtig, weil wir von dieser Empfehlung abweichen. Neu hinzugekommen ist die Möglichkeit, Machine-Learning-Modelle in ClickHouse zu verwenden – Catboost. Das beunruhigt mich, denn ich frage mich: „Wie viele Taktzyklen pro Byte gibt es da?“ Es tut mir leid, Taktzyklen für Bytes zu verwenden.

Keine Sorge, installieren Sie ClickHouse, alles wird gut. Sollte es Probleme geben, haben wir eine Community. Übrigens, die Community sind Sie. Falls Sie Schwierigkeiten haben, können Sie gerne in unseren Chat kommen und ich hoffe, dass Ihnen geholfen wird.
Fragen
Danke für die Präsentation! Wo kann ich mich über einen Ausfall von ClickHouse beschweren?
Sie können sich direkt jetzt an mich wenden.
Ich habe vor kurzem angefangen, ClickHouse zu nutzen. Ich habe sofort die CLI-Oberfläche zum Absturz gebracht.
Sie haben Glück gehabt.
Ein wenig später habe ich den Server mit einer kleinen SELECT-Abfrage zum Absturz gebracht.
Sie haben Talent.
Ich habe einen Bug auf GitHub gemeldet, aber er wurde ignoriert.
Mal sehen.
Alexey hat mich unter falschem Vorwand zur Präsentation gebracht, indem er versprach, mir zu zeigen, wie Sie die Daten intern komprimieren.
Sehr einfach.
Das habe ich schon gestern verstanden. Mehr Details bitte.
Es gibt keine furchtbaren Tricks. Es handelt sich einfach um eine Blockkomprimierung. Standardmäßig wird LZ4 verwendet, ZSTD* kann jedoch aktiviert werden. Blöcke reichen von 64 Kilobyte bis 1 Megabyte.
* Es gibt auch Unterstützung für spezialisierte Komprimierungs-Codecs, die in Kombination mit anderen Algorithmen verwendet werden können.
Sind in den Blöcken einfach nur rohe Daten?
Nicht ganz roh. Es sind dort Arrays. Wenn Sie eine numerische Spalte haben, sind die Zahlen hintereinander in einem Array angeordnet.
Verstanden.
Alexej, ein Beispiel, das mit uniqExact bei IP-Adressen gezeigt wurde, d. h. dass uniqExact für Strings länger benötigt als für Zahlen usw. Aber was passiert, wenn wir einen Trick anwenden und beim Lesen casten? Sie haben anscheinend gesagt, dass sich das auf der Festplatte nicht wesentlich unterscheidet. Wenn wir beim Lesen von Strings von der Festplatte casten, werden unsere Aggregationen dann schneller oder nicht? Oder gewinnen wir hier doch nur minimal? Ich glaube, Sie haben das getestet, aber warum haben Sie es im Benchmark nicht angegeben?
Ich denke, es wird langsamer sein als ohne Casting. In diesem Fall müsste die IP-Adresse aus der Zeichenfolge geparst werden. Natürlich ist das Parsen von IP-Adressen in ClickHouse auch optimiert. Wir haben uns wirklich Mühe gegeben, aber die Zahlen sind bei Ihnen in einer Zehntausenderdarstellung gespeichert. Sehr unpraktisch. Andererseits wird die Funktion uniqExact bei Strings langsamer arbeiten, nicht nur weil es Strings sind, sondern auch weil eine andere Algorithmusspezialisierung ausgewählt wird. Strings werden einfach anders verarbeitet.
Und was ist, wenn wir einen primitiveren Datentyp nehmen? Zum Beispiel, wir haben die user id, die wir als String gespeichert haben, und dann gecastet, wird es interessanter oder nicht?
Ich habe Zweifel. Ich denke, es wird sogar noch trauriger, denn das Parsen von Zahlen ist ein ernstes Problem. Ich glaube, dieser Kollege hatte sogar einen Vortrag darüber gehalten, wie schwierig es ist, Zahlen im Zehntausenderformat zu parsen, oder vielleicht auch nicht.
Alexey, vielen Dank für den Vortrag! Und auch vielen Dank für ClickHouse! Ich habe eine Frage zu den Plänen. Ist eine Funktion für ein teilweises Update der Dictionate geplant?
Also eine partielle Neuinitialisierung?
Ja, genau. Eine Möglichkeit, ein MySQL-Feld anzugeben, um nur die Daten zu aktualisieren, die nach einem bestimmten Punkt geladen werden, wenn das Dictionary sehr groß ist.
Eine sehr interessante Funktion. Ich glaube, jemand hat das in unserem Chat vorgeschlagen. Vielleicht waren Sie das sogar.
Ich glaube nicht, dass ich das war.
Ausgezeichnet, jetzt haben wir also zwei Anfragen. Und wir können gemütlich damit anfangen. Aber ich möchte Sie gleich warnen, dass diese Funktion recht einfach zu implementieren ist. Man müsste theoretisch einfach die Versionsnummer in die Tabelle schreiben und dann angeben: Version ist kleiner als die bestimmte Zahl. Das bedeutet, dass wir wahrscheinlich den Enthusiasten vorschlagen werden, dies zu übernehmen. Sind Sie ein Enthusiast?
Ja, aber leider nicht in C++.
Können Ihre Kollegen in C++ programmieren?
Ich werde jemanden finden.
Ausgezeichnet.
* Die Möglichkeit wurde zwei Monate nach dem Vortrag hinzugefügt – sie wurde vom Autor der Frage entwickelt und sein .
Danke!
Hallo! Vielen Dank für den Vortrag! Sie haben erwähnt, dass ClickHouse alle ihm zur Verfügung stehenden Ressourcen sehr gut nutzt. Der Referent neben Luxoft sprach über seine Lösung für die russische Post. Er sagte, dass ihnen ClickHouse sehr gefallen hat, sie es aber nicht anstelle ihres Hauptkonkurrenten verwendet haben, weil es die gesamte CPU verschlang. Und sie konnten es nicht in ihre Architektur integrieren, in ihren ZooKeeper mit den Docker-Containern. Gibt es eine Möglichkeit, ClickHouse so zu beschränken, dass es nicht alles verbraucht, was ihm zur Verfügung steht?
Ja, das ist möglich und sehr einfach. Wenn Sie möchten, dass weniger Kerne verwendet werden, dann schreiben Sie einfach set max_threads = 1. Und dann wird die Anfrage auf einem Kern ausgeführt. Außerdem können verschiedenen Benutzern unterschiedliche Einstellungen zugewiesen werden. Das sind also überhaupt keine Probleme. Und bitte teilen Sie den Kollegen von Luxoft mit, dass es nicht gut ist, dass sie diese Einstellung nicht in der Dokumentation gefunden haben.
Hallo Alexey! Ich möchte eine Frage stellen. Ich habe schon öfter gehört, dass viele ClickHouse als Speichersystem für Logs verwenden. In Ihrem Vortrag haben Sie gesagt, dass man das nicht tun sollte, also dass man keine langen Zeilen speichern sollte. Wie stehen Sie dazu?
Zunächst einmal sind Logs in der Regel keine langen Zeilen. Es gibt natürlich Ausnahmen. Zum Beispiel, wenn ein Service, der in Java geschrieben ist, eine Ausnahme auslöst, wird dies protokolliert. Und das geschieht in einer Endlosschleife, wodurch der Speicherplatz auf der Festplatte knapp wird. Die Lösung ist ganz einfach: Wenn die Zeilen sehr lang sind, schneiden Sie sie ab. Aber was bedeutet 'lang'? Zehntausende von Bytes – das ist schlecht*.
* In den neuesten Versionen von ClickHouse gibt es die "adaptive granularity index", die das Problem der Speicherung langer Zeilen weitestgehend löst.
Ist ein Kilobyte normal?
Das ist normal.
Hallo! Danke für Ihren Vortrag! Ich habe dazu bereits im Chat gefragt, erinnere mich aber nicht, ob ich eine Antwort erhalten habe. Ist es geplant, die WITH-Sektion in der Art von CTE zu erweitern?
Momentan nicht. Die WITH-Sektion ist bei uns etwas unbedeutend. Sie ist eine kleine Funktion.
Ich verstehe. Danke!
Vielen Dank für den Vortrag! Sehr interessant! Eine globale Frage. Ist geplant, eventuell in Form von Platzhaltern eine Modifikation für die Datenlöschung zu erstellen?
Ja, unbedingt. Das ist unsere erste Aufgabe in der Warteschlange. Wir haben bereits aktiv überlegt, wie wir alles richtig umsetzen können. Und es ist Zeit, mit dem Tippen auf der Tastatur zu beginnen*.
* Wir haben die Tasten auf der Tastatur gedrückt und alles erledigt.
Wird sich das irgendwie auf die Systemleistung auswirken oder nicht? Wird die Einfügung genauso schnell sein wie bisher?
Möglicherweise werden die Lösch- und Aktualisierungsoperationen sehr aufwendig sein, aber das wird sich nicht auf die Leistung der Abfragen und Einfügungen auswirken.
Und noch eine kleine Frage. In der Präsentation sprachen Sie über den Primärschlüssel. Entsprechend haben wir eine Partitionierung, die standardmäßig monatlich ist, richtig? Und wenn wir einen Datumsbereich angeben, der in einen Monat fällt, wird nur diese Partition gelesen, korrekt?
Ja.
Eine solche Frage. Wenn wir keinen Primärschlüssel definieren können, ist es sinnvoll, ihn anhand des Feldes "Datum" zu erstellen, um eine geringere Umschichtung dieser Daten im Hintergrund zu ermöglichen, damit sie ordentlicher sortiert werden? Wenn Sie keine Bereichsanfragen haben und keinen Primärschlüssel auswählen können, sollte dann das Datum im Primärschlüssel enthalten sein?
Ja.
Vielleicht macht es Sinn, ein Feld im Primärschlüssel zu haben, nach dem die Daten besser komprimiert werden, wenn sie nach diesem Feld sortiert sind. Zum Beispiel die ID des Benutzers. Der Benutzer besucht häufig dieselbe Website. In diesem Fall fügen Sie die Benutzer-ID und die Zeit hinzu. Dann werden Ihre Daten besser komprimiert. Was das Datum betrifft: Wenn Sie wirklich keine und niemals Bereichsanfragen nach Daten haben, können Sie das Datum auch aus dem Primärschlüssel herauslassen.
Gut, vielen Dank!
Quelle: habr.com
