

Die Suche nach funktionalen Abhängigkeiten in Daten wird in verschiedenen Bereichen der Datenanalyse angewendet: Datenbankverwaltung, Datenbereinigung, Reverse Engineering von Datenbanken und Datenexploration. Zu den Abhängigkeiten selbst haben wir bereits publiziert. Anastasia Birillo und Nikita Bobrov. Diesmal teilt Anastasia, die in diesem Jahr ihren Abschluss am Computer Science Center gemacht hat, die Entwicklung dieser Arbeit im Rahmen ihrer Forschung, die sie im Zentrum verteidigt hat.

Aufgabenwahl
Während meiner Ausbildung im CS Center begann ich, mich intensiv mit Datenbanken und insbesondere mit der Suche nach funktionalen und differenziellen Abhängigkeiten zu beschäftigen. Dieses Thema war mit dem Thema meiner Abschlussarbeit an der Universität verbunden, weshalb ich während der Arbeit an meiner Abschlussarbeit anfing, Artikel über verschiedene Abhängigkeiten in Datenbanken zu lesen. Ich schrieb einen Überblick über dieses Gebiet – einen meiner ersten. in englischer Sprache und reichte ihn auf der Konferenz SEIM-2017 ein. Ich war sehr glücklich, als ich erfuhr, dass er tatsächlich angenommen wurde, und entschied mich, tiefer in das Thema einzutauchen. Das Konzept ist nicht neu – es wurde bereits in den 90er Jahren angewendet, findet aber auch heute noch in vielen Bereichen Anwendung.
Im zweiten Semester meines Studiums im Zentrum begann ich ein Forschungsprojekt zur Verbesserung von Algorithmen zur Suche nach funktionalen Abhängigkeiten. Dabei arbeitete ich mit dem Doktoranden Nikita Bobrov von der SPbGU an der JetBrains Research zusammen.
Rechenaufwand bei der Suche nach funktionalen Abhängigkeiten
Das Hauptproblem ist der Rechenaufwand. Die Anzahl möglicher minimaler und nicht-trivialer Abhängigkeiten ist nach oben durch die Anzahl der Attribute der Tabelle begrenzt.  , wobei
, wobei  Die Laufzeit der Algorithmen hängt nicht nur von der Anzahl der Attribute ab, sondern auch von der Anzahl der Zeilen. In den 90er Jahren konnten Algorithmen zur Suche nach FZ auf gewöhnlichen Desktop-PCs Datensätze verarbeiten, die bis zu 20 Attribute und Zehntausende von Zeilen enthielten, was mehrere Stunden in Anspruch nehmen konnte. Moderne Algorithmen, die auf Mehrkernprozessoren arbeiten, erkennen Abhängigkeiten für Datensätze mit Hunderten von Attributen (bis zu 200) und Hunderttausenden von Zeilen in etwa derselben Zeit. Dennoch ist das unzureichend: Diese Laufzeit ist für die meisten realen Anwendungen inakzeptabel. Daher entwickelten wir Ansätze zur Beschleunigung bestehender Algorithmen.
Die Laufzeit der Algorithmen hängt nicht nur von der Anzahl der Attribute ab, sondern auch von der Anzahl der Zeilen. In den 90er Jahren konnten Algorithmen zur Suche nach FZ auf gewöhnlichen Desktop-PCs Datensätze verarbeiten, die bis zu 20 Attribute und Zehntausende von Zeilen enthielten, was mehrere Stunden in Anspruch nehmen konnte. Moderne Algorithmen, die auf Mehrkernprozessoren arbeiten, erkennen Abhängigkeiten für Datensätze mit Hunderten von Attributen (bis zu 200) und Hunderttausenden von Zeilen in etwa derselben Zeit. Dennoch ist das unzureichend: Diese Laufzeit ist für die meisten realen Anwendungen inakzeptabel. Daher entwickelten wir Ansätze zur Beschleunigung bestehender Algorithmen.
Caching-Strategien für die Partitionierung
Im ersten Teil der Arbeit haben wir Caching-Strategien für den Algorithmusklasse entwickelt, die die Methode der Partitionierung verwendet. Eine Partition für ein Attribut stellt eine Menge von Listen dar, wobei jede Liste die Zeilenindizes mit gleichen Werten für das betreffende Attribut enthält. Jede dieser Listen wird als Cluster bezeichnet. Viele moderne Algorithmen nutzen Partitionen zur Feststellung, ob eine Abhängigkeit bestehen bleibt oder nicht, insbesondere unter Berücksichtigung des Lemmas: Eine Abhängigkeit  besteht, wenn
besteht, wenn  . Hier
. Hier  Eine Partition wird bezeichnet und das Konzept der Partitionsgröße – die Anzahl der Cluster darin – verwendet. Algorithmen, die Partitionen nutzen, fügen bei einer Verletzung der Abhängigkeit zusätzliche Attribute auf der linken Seite der Abhängigkeit hinzu und berechnen diese anschließend neu, indem sie eine Schnittoperation von Partitionen durchführen. Diese Operation wird in Artikeln als Spezialisierung bezeichnet. Es wurde jedoch festgestellt, dass Partitionen für Abhängigkeiten, die nur nach mehreren Runden der Spezialisierung gehalten werden, aktiv wiederverwendet werden können, was die Laufzeit der Algorithmen erheblich verkürzen kann, da die Schnittoperation kostspielig ist.
Eine Partition wird bezeichnet und das Konzept der Partitionsgröße – die Anzahl der Cluster darin – verwendet. Algorithmen, die Partitionen nutzen, fügen bei einer Verletzung der Abhängigkeit zusätzliche Attribute auf der linken Seite der Abhängigkeit hinzu und berechnen diese anschließend neu, indem sie eine Schnittoperation von Partitionen durchführen. Diese Operation wird in Artikeln als Spezialisierung bezeichnet. Es wurde jedoch festgestellt, dass Partitionen für Abhängigkeiten, die nur nach mehreren Runden der Spezialisierung gehalten werden, aktiv wiederverwendet werden können, was die Laufzeit der Algorithmen erheblich verkürzen kann, da die Schnittoperation kostspielig ist.
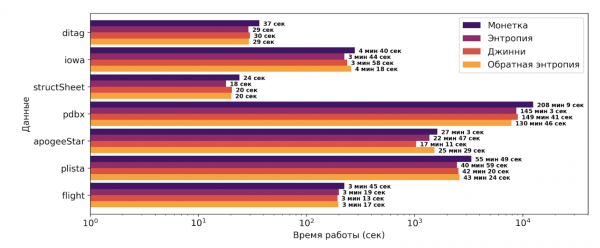
Daher haben wir eine Heuristik vorgeschlagen, die auf der Shannon-Entropie und der Gini-Unsicherheit sowie unserer Metrik basiert, die wir als Umgekehrte Entropie bezeichnet haben. Sie ist eine geringfügige Modifikation der Shannon-Entropie und wächst, während die Einzigartigkeit des Datensatzes zunimmt. Die vorgeschlagene Heuristik sieht folgendermaßen aus:

Hier  – der Grad der Einzigartigkeit der kürzlich berechneten Partition
– der Grad der Einzigartigkeit der kürzlich berechneten Partition  , und
, und  ist der Medianwert der Einzigartigkeit für einzelne Attribute. Alle drei oben beschriebenen Metriken für die Einzigartigkeit wurden als Messgröße getestet. Zudem gibt es zwei Modifikatoren in der Heuristik. Der erste Modifikator zeigt an, wie nah die aktuelle Partition am Primärschlüssel ist und ermöglicht eine bessere Zwischenspeicherung derjenigen Partitionen, die weit vom potenziellen Schlüssel entfernt sind. Der zweite Modifikator verfolgt die Cache-Auslastung und fördert somit die Hinzufügung weiterer Partitionen in den Cache, wenn ausreichend Platz vorhanden ist. Die erfolgreiche Lösung dieser Aufgabe hat den PYRO-Algorithmus um 10-40 % beschleunigt, abhängig vom Datensatz. Es ist zu beachten, dass der PYRO-Algorithmus in diesem Bereich die besten Ergebnisse erzielt.
ist der Medianwert der Einzigartigkeit für einzelne Attribute. Alle drei oben beschriebenen Metriken für die Einzigartigkeit wurden als Messgröße getestet. Zudem gibt es zwei Modifikatoren in der Heuristik. Der erste Modifikator zeigt an, wie nah die aktuelle Partition am Primärschlüssel ist und ermöglicht eine bessere Zwischenspeicherung derjenigen Partitionen, die weit vom potenziellen Schlüssel entfernt sind. Der zweite Modifikator verfolgt die Cache-Auslastung und fördert somit die Hinzufügung weiterer Partitionen in den Cache, wenn ausreichend Platz vorhanden ist. Die erfolgreiche Lösung dieser Aufgabe hat den PYRO-Algorithmus um 10-40 % beschleunigt, abhängig vom Datensatz. Es ist zu beachten, dass der PYRO-Algorithmus in diesem Bereich die besten Ergebnisse erzielt.
In der folgenden Abbildung sind die Ergebnisse der Anwendung der vorgeschlagenen Heuristik im Vergleich zu dem auf Münzwurf basierenden Ansatz zur Zwischenspeicherung zu sehen. Die X-Achse ist logarithmisch.
Alternative Methode zur Speicherung von Partitionen
Anschließend haben wir eine alternative Methode zur Speicherung von Partitionen vorgeschlagen. Partitionen bestehen aus einer Reihe von Clustern, in denen die Nummern von Tupeln mit gleichen Attributwerten gespeichert sind. Diese Cluster können lange Sequenzen von Tupelnummern enthalten, insbesondere wenn die Daten in der Tabelle geordnet sind. Daher haben wir ein Kompressionsschema zur Speicherung der Partitionen vorgeschlagen, nämlich die intervallweise Speicherung der Werte in den Partitionclustern:
$$display$$pi(X) = {{underbrace{1, 2, 3, 4, 5}_{Erster~Intervall}, underbrace{7, 8}_{Zweiter~Intervall}, 10}}\ downarrow{Kompression}\ pi(X) = {{underbrace{$, 1, 5}_{Erster~Intervall}, underbrace{7, 8}_{Zweiter~Intervall}, 10}}$$display$$
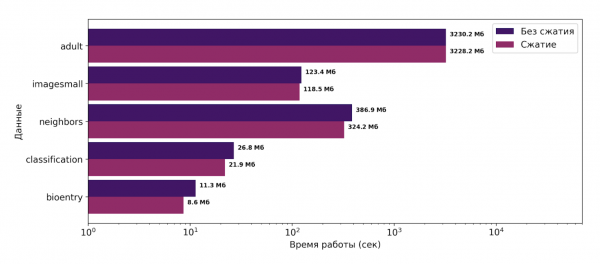
Diese Methode konnte den Speicherverbrauch während der Ausführung des TANE-Algorithmus um 1 bis 25 % reduzieren. Der TANE-Algorithmus ist ein klassischer Algorithmus zur Suche nach funktionalen Abhängigkeiten (FZ) und nutzt Partitionen während seiner Ausführung. Im Rahmen der Praxis wurde speziell der TANE-Algorithmus gewählt, da es wesentlich einfacher war, intervallweise Speicherung zu implementieren als beispielsweise im PYRO, um zu bewerten, ob der vorgeschlagene Ansatz funktioniert. Die erhaltenen Ergebnisse sind im folgenden Bild dargestellt. Die X-Achse ist logarithmisch.
Konferenz ADBIS-2019
Im September 2019 präsentierte ich einen Artikel auf der 23. Europäischen Konferenz über Fortschritte in Datenbanken und Informationssystemen (ADBIS-2019). Während der Präsentation erhielt die Arbeit Anerkennung von Bernhard Thalheim, einer bedeutenden Persönlichkeit im Bereich der Datenbanken. Die Ergebnisse dieser Forschung bildeten die Grundlage meiner Masterarbeit am Mathematisch-Mechanischen Institut der Universität St. Petersburg, in der beide vorgeschlagenen Ansätze (Caching und Kompression) in beide Algorithmen: TANE und PYRO implementiert wurden. Die Ergebnisse zeigten, dass die vorgeschlagenen Ansätze universell sind, da bei beiden Algorithmen unter beiden Ansätzen eine erhebliche Reduzierung des Speicherverbrauchs sowie eine signifikante Verkürzung der Laufzeit der Algorithmen beobachtet wurde.
Quelle: habr.com
