

Im Folgenden, in Anknüpfung an das Thema der Erfassung großer Datenströme, das in werden wir Methoden untersuchen, mit denen die 'physische' Größe der gespeicherten Daten in PostgreSQL verringert werden kann und deren Einfluss auf die Serverleistung.
Es geht um TOAST-Einstellungen und Datenausrichtung.Durchschnittlich werden diese Methoden nicht besonders viele Ressourcen sparen, aber sie erfordern keinerlei Änderungen am Anwendungscode.

Allerdings war unsere Erfahrung in dieser Hinsicht durchaus produktiv, da das Speicherformat nahezu aller Monitoring-Daten in der Regel append-only ist, was die geschriebenen Daten betrifft. Und falls Sie interessiert sind, wie man die Datenbank dazu bringen kann, mit einer Geschwindigkeit von 200 MB/s deutlich weniger zu schreiben – scrollen Sie weiter.
Kleine Geheimnisse großer Daten
Im Rahmen der , erhält er regelmäßig aus den Logs Textpakete..
Da dessen Datenbanken wir überwachen, ein komplexes Produkt mit komplizierten Datenstrukturen ist, sind die Abfragen zur Erreichung maximaler Leistung entsprechend gestaltet. . Daher ist das Volumen jeder einzelnen Anfrage oder des resultierenden Ausführungsplans in unserem eingehenden Protokoll „im Durchschnitt“ beträchtlich groß.
Schauen wir uns die Struktur einer der Tabellen an, in die wir „rohe“ Daten schreiben – also den originalen Text aus dem Protokolleintrag:
CREATE TABLE rawdata_orig(
pack -- PK
uuid NOT NULL
, recno -- PK
smallint NOT NULL
, dt -- Abschnittsschlüssel
date
, data -- das Wichtigste
text
, PRIMARY KEY(pack, recno)
);Eine typische solche Tabelle (bereits partitioniert, das ist klar, daher handelt es sich um eine Abschnittsvorlage), wobei der wichtigste Punkt der Text ist. Manchmal recht umfangreich.
Erinnern wir uns daran, dass die „physische“ Größe eines Eintrags in PG nicht mehr als eine Datenseite belegen kann, aber die „logische“ Größe – das ist eine ganz andere Sache. Um einen umfassenden Wert in ein Feld (varchar/text/bytea) zu speichern, wird :
PostgreSQL verwendet eine feste Seitengröße (in der Regel 8 KB) und erlaubt es nicht, dass Tupel mehrere Seiten einnehmen. Deshalb können sehr große Feldwerte nicht direkt gespeichert werden. Um diese Einschränkung zu überwinden, werden große Feldwerte komprimiert und/oder in mehrere physische Zeilen aufgeteilt. Dieser Vorgang geschieht für den Benutzer unsichtbar und hat nur geringe Auswirkungen auf den Großteil des Servercodes. Diese Methode ist als TOAST bekannt...
Tatsächlich wird für jede Tabelle mit „potenziell großen“ Feldern automatisch jeder „großen“ Datensatzsegmente von 2KB erstellt:
TOAST(
chunk_id
integer
, chunk_seq
integer
, chunk_data
bytea
, PRIMARY KEY(chunk_id, chunk_seq)
); Das bedeutet, dass wenn wir eine Zeile mit einem „großen“ Wert schreiben müssen, datadie tatsächliche Speicherung nicht nur in der Haupttabelle und ihrem PK erfolgt, sondern auch in TOAST und dessen PK. Reduzierung des TOAST-Einflusses.
Die meisten unserer Einträge sind jedoch nicht so groß,
sie sollten in 8KB passen — wie kann man hier sparen?.. Hier kommt uns das Attribut
STORAGE EXTENDED
- erlaubt sowohl Kompression als auch separate Speicherung. Dies ist die Standardvariante. Standardvariante für die meisten Datentypen, die mit TOAST kompatibel sind. Zuerst wird versucht, eine Kompression durchzuführen, dann erfolgt die Speicherung außerhalb der Tabelle, falls die Zeile immer noch zu groß ist.
- HAUPT erlaubt Kompression, jedoch keine separate Speicherung. (In der Tat wird eine separate Speicherung für solche Spalten dennoch durchgeführt, aber nur als letztes Mittel, wenn es keine andere Möglichkeit gibt, die Zeile zu reduzieren, damit sie auf die Seite passt.)
In der Tat ist das genau das, was wir für Text benötigen — maximal zu komprimieren, und falls es wirklich nicht passt — in TOAST auszulagern. Dies kann ganz einfach „on-the-fly“ mit einem Befehl gemacht werden:
ALTER TABLE rawdata_orig ALTER COLUMN data SET STORAGE MAIN;Wie man die Wirkung beurteilt
Da sich der Datenstrom täglich ändert, können wir keine absoluten Zahlen vergleichen, aber relativ heißt, je weniger wir in TOAST geschrieben haben — desto besser. Aber hier gibt es eine Gefahr — je größer unser „physischer“ Umfang jedes einzelnen Eintrags ist, desto „breiter“ wird der Index, da er mehr Seitenabdeckungen erfordert. vor den Änderungen
Abschnitt Heap = 37GB (39%) TOAST = 54GB (57%) PK = 4GB ( 4%):
nach den Änderungen
Abschnitt Heap = 37GB (67%) TOAST = 16GB (29%) PK = 2GB ( 4%):
Tatsächlich haben wirTatsächlich sind wir Wir haben in TOAST doppelt so selten geschrieben, was nicht nur die Festplatte, sondern auch die CPU entlastet hat:
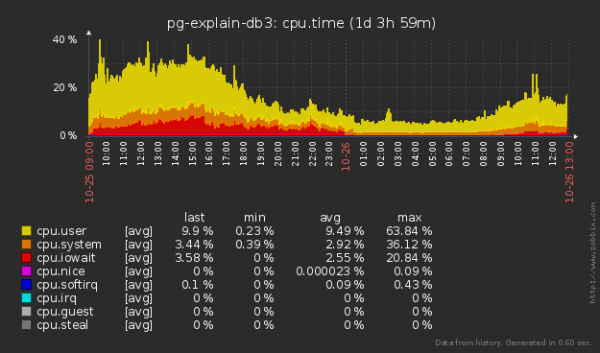
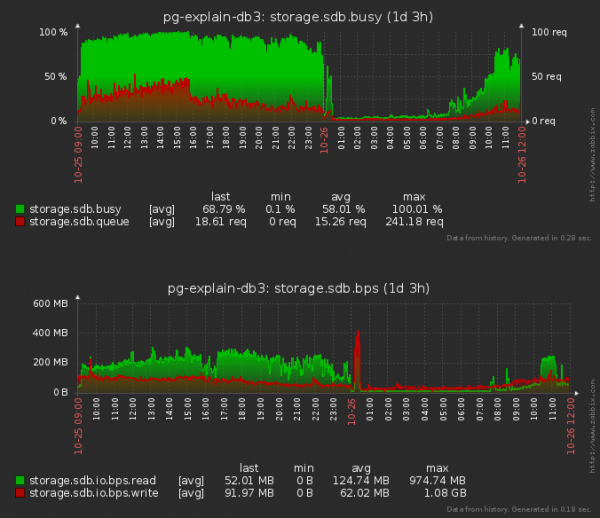
Ich möchte anmerken, dass wir auch weniger "lesen", nicht nur "schreiben" — da beim Einfügen eines Eintrags in eine Tabelle auch Teile des Baums jeder der Indizes "gelesen" werden müssen, um seine zukünftige Position darin zu bestimmen.
Wer mit PostgreSQL 11 gut leben kann
Nach dem Update auf PG11 haben wir beschlossen, das „Tuning“ von TOAST fortzusetzen und festgestellt, dass ab dieser Version ein konfigurierbarer Parameter verfügbar ist :
Der TOAST-Verarbeitungscode wird nur aktiviert, wenn der Zeichenfolgenwert, der in der Tabelle gespeichert werden soll, größer ist als TOAST_TUPLE_THRESHOLD Bytes (normalerweise 2 KB). Der TOAST-Code wird die Feldwerte komprimieren und/oder außerhalb der Tabelle verschieben, bis der Zeichenfolgenwert kleiner als TOAST_TUPLE_TARGET Bytes (eine variable Größe, ebenfalls normalerweise 2 KB) wird oder eine Verringerung nicht mehr möglich ist.
Wir haben entschieden, dass unsere Daten normalerweise entweder "sehr kurz" oder "sehr lang" sind, daher beschlossen wir, uns auf den minimal möglichen Wert zu beschränken:
ALTER TABLE rawplan_orig SET (toast_tuple_target = 128);Lassen Sie uns betrachten, wie sich die neuen Einstellungen auf die Festplattennutzung nach der Umstellung ausgewirkt haben:

Nicht schlecht! Der durchschnittliche Wartezeit auf die Festplatte hat sich ungefähr um das 1,5-Fache verringert, und die "Auslastung" der Festplatte ist um 20% gesunken! Aber könnte es sein, dass das auch Auswirkungen auf die CPU hat?

Auf jeden Fall ist es nicht schlechter geworden. Es ist jedoch schwierig zu urteilen, da selbst solche Volumina die durchschnittliche CPU-Auslastung nicht wirklich erhöhen können. 5%.
Von der Umstellung der Summanden ändert sich die Summe…!
Wie man weiß, spart der Cent den Rubel, und bei unseren Speichergrößen von etwa 10 TB/Monat kann sogar eine kleine Optimierung einen ordentlichen Gewinn bringen. Daher haben wir die physische Struktur unserer Daten in den Blick genommen – wie konkret die Felder innerhalb der Datensätze in jeder der Tabellen angeordnet sind.
Denn aufgrund des wirkt sich das direkt auf das resultierende Volumen aus. :
Viele Architekturen sehen die Ausrichtung von Daten an den Grenzen von Maschinenwörtern vor. Zum Beispiel werden auf einem 32-Bit-System x86 ganze Zahlen (Datentyp integer, benötigt 4 Bytes) an der Grenze zu 4-Byte-Wörtern ausgerichtet, ebenso wie Gleitkommazahlen doppelter Genauigkeit (Datentyp double precision, 8 Bytes). Auf einem 64-Bit-System werden die double-Werte an der Grenze von 8-Byte-Wörtern ausgerichtet. Dies ist ein weiterer Grund für Inkompatibilitäten.
Wegen der Ausrichtung hängt die Größe der Tabellenzeile von der Anordnung der Felder ab. In der Regel ist dieser Effekt nicht sehr auffällig, kann aber in manchen Fällen zu einer erheblichen Vergrößerung der Größe führen. Wenn man beispielsweise die Felder der Typen char(1) und integer mischt, gehen in der Regel 3 Bytes verloren.
Lassen Sie uns mit synthetischen Modellen beginnen:
SELECT pg_column_size(ROW(
'0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
, '2019-01-01'::date
));
-- 48 Bytes
SELECT pg_column_size(ROW(
'2019-01-01'::date
, '0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
));
-- 46 BytesWoher kommen die zusätzlichen Bytes im ersten Fall? Ganz einfach — ein 2-Byte-smallint wird an der 4-Byte-Grenze ausgerichtet vor dem nächsten Feld, und wenn es am Ende steht, gibt es nichts mehr, was ausgerichtet werden müsste.
In der Theorie ist alles gut und man kann die Felder beliebig umstellen. Lassen Sie uns das an realen Daten anhand eines der Tabellen überprüfen, deren täglicher Abschnitt jeweils 10-15 GB groß ist.
Ursprüngliche Struktur:
CREATE TABLE public.plan_20190220
(
-- Vererbt von der Tabelle plan: pack uuid NOT NULL,
-- Vererbt von der Tabelle plan: recno smallint NOT NULL,
-- Vererbt von der Tabelle plan: host uuid,
-- Vererbt von der Tabelle plan: ts timestamp with time zone,
-- Vererbt von der Tabelle plan: exectime numeric(32,3),
-- Vererbt von der Tabelle plan: duration numeric(32,3),
-- Vererbt von der Tabelle plan: bufint bigint,
-- Vererbt von der Tabelle plan: bufmem bigint,
-- Vererbt von der Tabelle plan: bufdsk bigint,
-- Vererbt von der Tabelle plan: apn uuid,
-- Vererbt von der Tabelle plan: ptr uuid,
-- Vererbt von der Tabelle plan: dt date,
CONSTRAINT plan_20190220_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190220_dt_check CHECK (dt = '2019-02-20'::date)
)
INHERITS (public.plan)Abschnitt nach Änderung der Spaltenreihenfolge — genau die gleichen Felder, nur in anderer Reihenfolge:
ERSTELLEN TABELLE public.plan_20190221
(
-- Abgeleitet von Tabelle plan: dt datum NICHT NULL,
-- Abgeleitet von Tabelle plan: ts zeitstempel mit zeitzone,
-- Abgeleitet von Tabelle plan: pack uuid NICHT NULL,
-- Abgeleitet von Tabelle plan: recno kleinint NICHT NULL,
-- Abgeleitet von Tabelle plan: host uuid,
-- Abgeleitet von Tabelle plan: apn uuid,
-- Abgeleitet von Tabelle plan: ptr uuid,
-- Abgeleitet von Tabelle plan: bufint bigint,
-- Abgeleitet von Tabelle plan: bufmem bigint,
-- Abgeleitet von Tabelle plan: bufdsk bigint,
-- Abgeleitet von Tabelle plan: exectime numerisch(32,3),
-- Abgeleitet von Tabelle plan: duration numerisch(32,3),
EINSCHRANKUNG plan_20190221_pkey PRIMARY KEY (pack, recno),
EINSCHRANKUNG chck_ptr ÜBERPRÜFEN (ptr IST NICHT NULL),
EINSCHRANKUNG plan_20190221_dt_check ÜBERPRÜFEN (dt = '2019-02-21'::datum)
)
ERBT (public.plan) Das Gesamtdatenvolumen des Abschnitts hängt von der Anzahl der „Fakten“ ab und ist nur von externen Prozessen abhängig, daher teilen wir die Größe des Heaps (pg_relation_size) durch die Anzahl der Einträge — das ergibt die durchschnittliche Größe eines tatsächlich gespeicherten Eintrags:
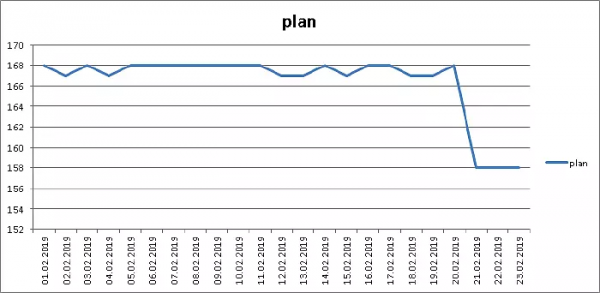
Minus 6% des Volumens, hervorragend!
Aber natürlich ist nicht alles so rosig — denn in den Indizes können wir die Reihenfolge der Felder nicht ändern, und deshalb haben wir „insgesamt“ (pg_total_relation_size)…
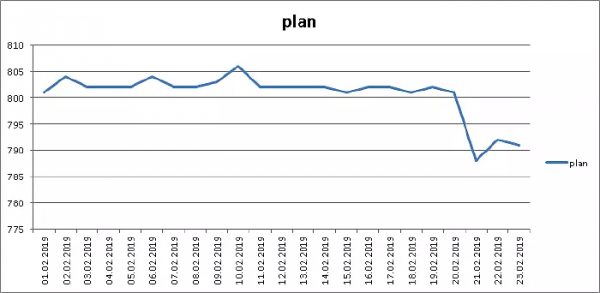
… dennoch auch hier 1,5% eingespart, ohne eine Zeile Code zu ändern. Aber ja!

Ich möchte darauf hinweisen, dass die oben angegebene Anordnung der Felder nicht unbedingt die optimale ist. Einige Blockfelder möchte man aus ästhetischen Gründen nicht 'trennen' – zum Beispiel ein Paar. (pack, recno), das der PK für diese Tabelle entspricht.
Im Allgemeinen ist die Bestimmung der 'minimalen' Felderanordnung eine recht einfache 'Aufzählungs'aufgabe. Daher können Sie mit Ihren Daten sogar bessere Ergebnisse erzielen als wir – probieren Sie es aus!
Quelle: habr.com
