

Der Artikel wurde im Vorfeld des Kurses erstellt .

Wie Sie Kosten für Cloud-Ressourcen bei der Nutzung von Kubernetes senken können? Es gibt nicht die eine richtige Lösung, aber in diesem Artikel werden mehrere Werkzeuge vorgestellt, die Ihnen helfen, Ressourcen effizienter zu verwalten und Ihre Ausgaben für Cloud-Computing zu reduzieren.
Ich habe diesen Artikel mit Blick auf Kubernetes für AWS geschrieben, aber er ist (fast) genauso auf andere Cloud-Anbieter übertragbar. Ich gehe davon aus, dass Ihre(n) Cluster bereits über eine konfigurierte automatische Skalierung verfügt.Die Entfernung von Ressourcen und das Runterfahren von Deployments sparen nur dann, wenn dies auch Ihren Bestand an Arbeitsknoten (EC2-Instanzen) verringert.
In diesem Artikel werden folgende Themen behandelt:
- Bereinigung ungenutzter Ressourcen ()
- Reduzierung der Skalierung außerhalb der Arbeitszeiten ()
- Nutzung der horizontalen automatischen Skalierung (HPA),
- Reduzierung von überflüssiger Ressourcenzuteilung (, VPA)
- Einsatz von Spot-Instanzen
Bereinigung ungenutzter Ressourcen
Arbeiten in einer sich schnell verändernden Umgebung ist großartig. Wir möchten, dass technische Organisationen . Schnellere Bereitstellung von Software bedeutet auch mehr PR-Bereitstellungen, mittlere Vorschau, Prototypen und Analyselösungen. Alles wird auf Kubernetes bereitgestellt. Wer hat schon Zeit, um Testbereitstellungen manuell zu bereinigen? Es ist leicht, das Löschen eines einwöchigen Experiments zu vergessen. Die Cloud-Rechnung wird letztendlich steigen, weil wir vergessen haben, es abzuschalten:
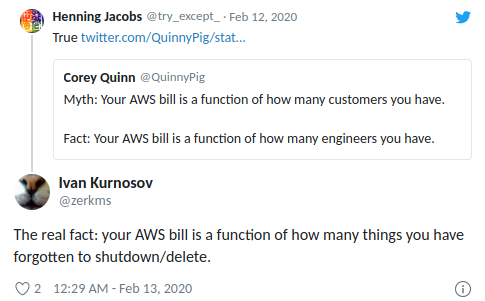
(Henning Jacobs:
Wahrhaftig:
(zitiert) Cory Quinn:
Mythos: Ihre AWS-Rechnung hängt von der Anzahl Ihrer Benutzer ab.
Fakt: Ihre AWS-Rechnung hängt von der Anzahl Ihrer Ingenieure ab.
Ivan Kurnosov (in Antwort):
Tatsächlicher Fakt: Ihre AWS-Rechnung hängt von der Anzahl der Dinge ab, die Sie vergessen haben, auszuschalten/zu löschen.)
(kube-janitor) hilft, Ihren Cluster zu bereinigen. Die Janitor-Konfiguration ist flexibel für globale und lokale Nutzung:
- Allgemeine Regeln für den gesamten Cluster können die maximale Lebensdauer (TTL – time-to-live) für PR/Testbereitstellungen festlegen.
- Ressourcen können mit janitor/ttl annotiert werden, um beispielsweise Spikes/Prototypen nach 7 Tagen automatisch zu entfernen.
Die allgemeinen Regeln werden in einer YAML-Datei definiert. Ihr Pfad wird über den Parameter --rules-file an kube-janitor übergeben. Hier ein Beispielregel, um alle Namensräume mit -pr- im Namen nach zwei Tagen zu löschen:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2dDas folgende Beispiel regelt die Verwendung des Labels application auf Deployments und StatefulSets für alle neuen Deployments/StatefulSets im Jahr 2020, erlaubt jedoch gleichzeitig die Durchführung von Tests ohne dieses Label für eine Woche:
- id: require-application-label
# lösche deployments und statefulsets ohne das Label "application"
resources:
- deployments
- statefulsets
# siehe http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dStarten einer zeitlich begrenzten Demo von 30 Minuten in einem Cluster, in dem kube-janitor läuft:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mEine weitere Quelle steigender Kosten sind die persistenten Volumes (AWS EBS). Beim Löschen eines Kubernetes StatefulSet werden die zugehörigen persistenten Volumes (PVC — PersistentVolumeClaim) nicht entfernt. Unbenutzte EBS-Volumes können leicht zu Kosten von Hunderte von Dollar pro Monat führen. Der Kubernetes Janitor verfügt über eine Funktion zur Bereinigung ungenutzter PVCs. Zum Beispiel entfernt diese Regel alle PVCs, die nicht vom Pod gemountet sind und auf die weder ein StatefulSet noch ein CronJob verweist.
# удалить все PVC, которые не смонтированы и на которые не ссылаются StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hDer Kubernetes Janitor kann Ihnen helfen, Ihren Cluster "sauber" zu halten und die langsam wachsenden Kosten für Cloud-Computing zu verhindern. Folgen Sie den Anweisungen zur Bereitstellung und Konfiguration in .
Reduzierung des Scale Down während der Nichtbetriebszeiten
Test- und Staging-Systeme sind in der Regel nur während der Betriebszeiten erforderlich. Einige Produktionsanwendungen, wie Backoffice- oder Administrationswerkzeuge, benötigen ebenfalls nur eine begrenzte Verfügbarkeit und können nachts abgeschaltet werden.
(kube-downscaler) ermöglicht es Benutzern und Betreibern, die Systemgröße außerhalb der Betriebszeiten zu reduzieren. Deployments und StatefulSets können auf null Replikate skaliert werden. CronJobs können pausiert werden. Der Kubernetes Downscaler kann für den gesamten Cluster, für ein oder mehrere Namespaces oder einzelne Ressourcen konfiguriert werden. Es kann entweder eine „Standby-Zeit“ oder eine „Betriebszeit“ festgelegt werden. Zum Beispiel, um die Skalierung in der Nacht und am Wochenende zu minimieren:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
# Infrastrukturkomponenten nicht deaktivieren
- --exclude-namespaces=kube-system,infra
# kube-downscaler nicht deaktivieren und Postgres Operator aktiv lassen, um die ausgeschlossen Datenbanken verwalten zu können
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-timeHier ist das Skalierungsschema der Arbeitsknoten des Clusters an den Wochenenden:
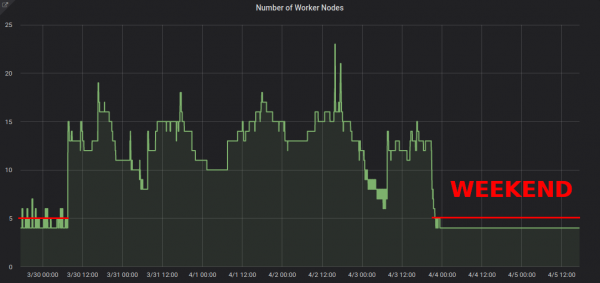
Die Reduzierung von ~13 auf 4 Arbeitsknoten erzielt definitiv eine spürbare Ersparnis in der AWS-Rechnung.
Aber was ist, wenn ich während der "Ausfallzeit" des Clusters arbeiten muss? Bestimmte Deployments können dauerhaft vom Scaling ausgeschlossen werden, indem man die Annotation downscaler/exclude: true hinzufügt. Deployments können vorübergehend durch die Annotation downscaler/exclude-until mit einem absoluten Zeitstempel im Format JJJJ-MM-TT HH:MM (UTC) ausgeschlossen werden. Bei Bedarf kann der gesamte Cluster wieder skaliert werden, indem ein Pod mit der Annotation downscaler/force-uptime, beispielsweise durch das Starten eines nginx Dummy-Containers:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h # Deploy innerhalb einer Stunde löschen
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueSiehe , wenn Sie Anweisungen zur Bereitstellung und zusätzliche Optionen interessieren.
Verwenden Sie horizontale Automatisierungsskalierung
Viele Anwendungen/Dienste haben es mit einem dynamischen Lastschema zu tun: Manchmal sind ihre Module im Leerlauf, manchmal laufen sie auf Hochtouren. Mit einem konstanten Pool von Pods zu arbeiten, um den maximalen Spitzenbedarf zu bewältigen, ist nicht wirtschaftlich. Kubernetes unterstützt die horizontale automatische Skalierung über die Ressource (HPA). Die Nutzung der CPU ist häufig ein guter Indikator für das Skalieren:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationZalando hat eine Komponente entwickelt, um benutzerdefinierte Metriken für die Skalierung einfach anzubinden: (kube-metrics-adapter) ist ein universeller Metrikadapter für Kubernetes, der benutzerdefinierte und externe Metriken für das horizontale Skalieren von Pods sammeln und bereitstellen kann. Er unterstützt die Skalierung basierend auf Prometheus-Metriken, SQS-Warteschlangen und anderen Einstellungen. Um beispielsweise ein Deployment für eine benutzerdefinierte Metrik zu skalieren, die von der Anwendung selbst als JSON unter /metrics bereitgestellt wird, verwenden Sie:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueDie Konfiguration der horizontalen Autoskalierung mit HPA sollte eine der Standardmaßnahmen zur Effizienzsteigerung für zustandslose Dienste sein. Spotify hat eine Präsentation über ihre Erfahrungen und Empfehlungen zur HPA veröffentlicht: .
Reduzierung von Ressourcenüberbuchungen
Kubernetes-Workloads definieren ihren Bedarf an CPU/Arbeitsspeicher über "Ressourcennachfragen". CPU-Ressourcen werden in virtuellen Kernen oder häufiger in "Millicores" gemessen; beispielsweise bedeutet 500m 50 % vCPU. Arbeitsspeicher-Ressourcen werden in Bytes gemessen und können übliche Suffixe verwenden, zum Beispiel 500Mi, was 500 Megabyte bedeutet. Ressourcennachfragen "reservieren" eine Menge auf den Worker-Knoten, das heißt, ein Modul mit einer CPU-Anfrage von 1000m auf einem Knoten mit 4 virtuellen CPUs lässt nur 3 virtuelle CPUs für andere Module verfügbar.
Slack (Übermaß an Reserven) ist die Differenz zwischen den angeforderten Ressourcen und der tatsächlichen Nutzung. Zum Beispiel hat ein Pod, der 2 GiB Speicher anfordert, aber nur 200 MiB verwendet, etwa 1,8 GiB "überschüssigen" Speicher. Überschuss kostet Geld. Man kann grob schätzen, dass 1 GiB überschüssiger Speicher etwa 10 Dollar pro Monat kostet.
(kube-resource-report) zeigt überschüssige Reserven an und kann Ihnen helfen, Einsparungspotenziale zu identifizieren:
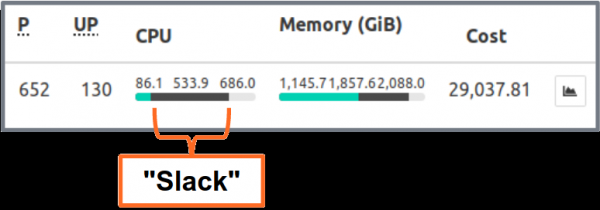
zeigt Überhänge an, die von der Anwendung und dem Team aggregiert werden. Dies hilft, Bereiche zu identifizieren, in denen der Ressourcenbedarf gesenkt werden kann. Der generierte HTML-Bericht bietet nur einen Snapshot der Ressourcennutzung. Es ist wichtig, die CPU-/Speichernutzung über die Zeit zu betrachten, um angemessene Ressourcennutzungen zu bestimmen. Hier ist ein Grafana-Diagramm für einen typischen Dienst mit hoher CPU-Auslastung: alle Pods nutzen deutlich weniger als 3 angeforderte CPU-Kerne.
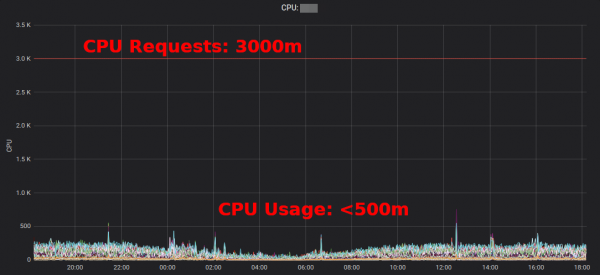
Die Reduzierung der CPU-Anforderung von 3000m auf etwa 400m gibt Ressourcen für andere Workloads frei und ermöglicht eine Verkleinerung des Clusters.
„Die durchschnittliche CPU-Nutzung von EC2-Instanzen schwankt häufig im einstelligen Prozentbereich“, . Während für EC2 ist es einfach, einige Kubernetes-Ressourcenzuweisungen in der YAML-Datei zu ändern, und das kann enorme Einsparungen bringen.
Aber möchten wir wirklich, dass Leute Werte in YAML-Dateien ändern? Nein, Maschinen können das viel besser! Kubernetes (VPA) kümmert sich genau darum: es passt die Ressourcenanforderungen und -beschränkungen entsprechend der Arbeitslast an. Hier ist ein Beispiel für den CPU-Anforderungsgraphen von Prometheus (dünne blaue Linie), die über die Zeit angepassten VPA:
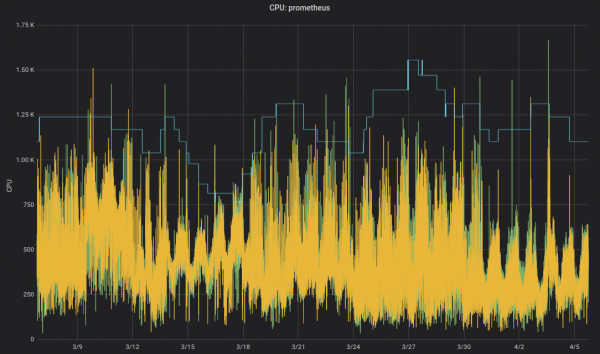
für Infrastrukturkomponenten. Auch nicht-kritische Anwendungen können VPA nutzen.
von Fairwinds ist ein Tool, das VPA für jedes Deployment im Namespace erstellt und dann die VPA-Empfehlung auf seinem Dashboard anzeigt. Es kann Entwicklern helfen, die richtigen CPU-/Speicheranforderungen für ihre Anwendungen festzulegen:
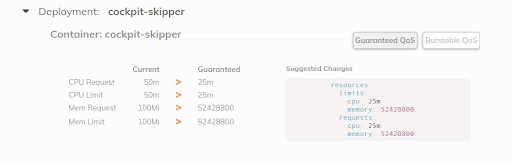
Ich habe einen kurzen im Jahr 2019 geschrieben, und kürzlich wurde im .
Verwendung von EC2 Spot-Instanzen
Schließlich, und nicht weniger wichtig, können die AWS EC2-Kosten gesenkt werden, indem Spot-Instanzen als Arbeitsknoten für Kubernetes verwendet werden. . Spot-Instanzen sind mit Rabatten von bis zu 90 % im Vergleich zu On-Demand-Preisen erhältlich. Die Nutzung von Kubernetes auf EC2 Spot ist eine hervorragende Kombination: Sie können verschiedene Instanstypen für höhere Verfügbarkeit angeben, was bedeutet, dass Sie einen größeren Knoten zu demselben oder einem niedrigeren Preis erhalten können, während die erhöhte Kapazität von Kubernetes-Container-Workloads genutzt werden kann.
Wie starten Sie Kubernetes auf EC2 Spot? Es gibt mehrere Optionen: Verwenden Sie einen Drittanbieterdienst wie SpotInst (jetzt nur „Spot“ genannt, fragen Sie mich nicht, warum), oder fügen Sie einfach eine Spot AutoScalingGroup (ASG) zu Ihrem Cluster hinzu. Hier ist beispielsweise ein CloudFormation-Snippet für eine „kapazitätsoptimierte“ Spot ASG mit mehreren Instanstypen:
MySpotAutoScalingGroup:
Eigenschaften:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"Einige Anmerkungen zur Verwendung von Spot mit Kubernetes:
- Sie müssen den Abschluss von Spot-Verbindungen verwalten, beispielsweise indem Sie den Knoten beim Stoppen der Instanz verdrängen.
- Zalando verwendet offizielle Autoskalierungs-Cluster mit Prioritäten für Poolknoten.
- Spot-Knoten "Registrierungen" von Arbeitslasten für den Betrieb in Spot anzunehmen.
Zusammenfassung
Ich hoffe, dass Sie einige der vorgestellten Tools nützlich finden, um Ihre Cloud-Computing-Rechnung zu senken. Sie können den Großteil des Inhalts des Artikels auch in finden .
Was sind Ihre besten Praktiken zur Senkung der Cloud-Kosten für Kubernetes? Lassen Sie es uns wissen auf .
Tatsächlich werden weniger als 3 virtuelle CPUs weiterhin nutzbar sein, da die Knotenbandbreite durch reservierte Systemressourcen sinkt. Kubernetes unterscheidet zwischen der physischen Kapazität eines Knotens und den "zugewiesenen" Ressourcen ().
Beispielrechnung: Eine m5.large Instanz mit 8 GiB RAM kostet etwa 84 USD pro Monat (eu-central-1, On-Demand), d.h. die Sperrung 1/8 des Knotens kostet ungefähr 10 USD pro Monat.
Es gibt viele weitere Möglichkeiten, Ihre EC2-Rechnung zu senken, wie z.B. reservierte Instanzen, Sparpläne usw. — ich werde diese Themen hier nicht behandeln, aber Sie sollten sich unbedingt darüber informieren!
Quelle: habr.com
