

Wie bekannt ist, bietet die Firma SAP eine umfassende Palette an Software für die Erfassung von Transaktionsdaten sowie für deren Verarbeitung in Analyse- und Berichtssystemen an. Insbesondere stellt die Plattform SAP Business Warehouse (SAP BW) ein Werkzeug zur Speicherung und Analyse von Daten dar, das über umfangreiche technische Möglichkeiten verfügt. Trotz all ihrer objektiven Vorteile hat das System SAP BW einen erheblichen Nachteil: die hohen Kosten für die Speicherung und Verarbeitung von Daten, insbesondere bei der Nutzung der Cloud-basierten SAP BW on HANA.
Was wäre, wenn wir ein non-SAP und vorzugsweise OpenSource-Produkt als Speicher nutzen? Bei der X5 Retail Group haben wir uns für GreenPlum entschieden. Dies löst sicherlich das Kostenproblem, wirft jedoch sofort Fragen auf, die beim Einsatz von SAP BW praktisch standardmäßig gelöst wurden.

Insbesondere stellt sich die Frage, wie Daten aus den Quellsystemen abgerufen werden, die in den meisten Fällen SAP-Lösungen sind?
«HR-Metriken» war das erste Projekt, bei dem es notwendig war, dieses Problem zu lösen. Unser Ziel war die Erstellung eines HR-Datenlagers und der Aufbau von analytischen Berichten zur Mitarbeiterverwaltung. Die Hauptdatenquelle stellt das transaktionale System SAP HCM dar, in dem alle Personal-, Organisations- und Gehaltsaktivitäten verwaltet werden.
Datenextraktion
In SAP BW für SAP-Systeme gibt es standardisierte Datenextraktoren. Diese Extraktoren können automatisch die erforderlichen Daten sammeln, deren Integrität überwachen und Änderungen erkennen. Hier ist zum Beispiel die Standarddatenquelle für die Mitarbeiterattribute 0EMPLOYEE_ATTR:
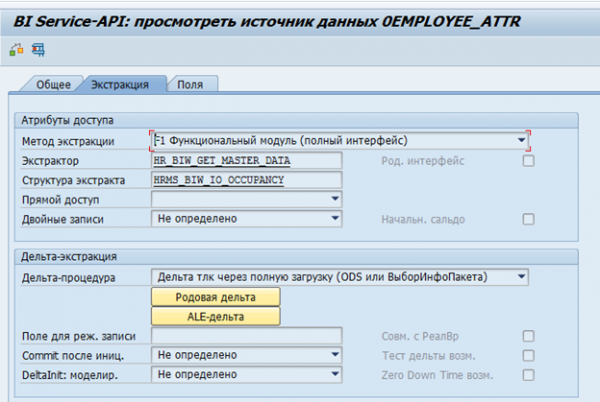
Das Ergebnis der Datenextraktion für einen einzelnen Mitarbeiter:
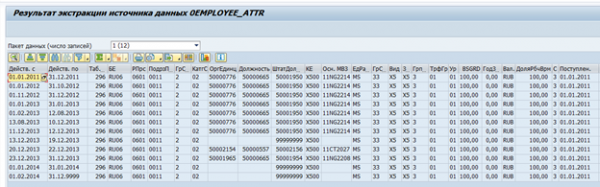
Wenn erforderlich, kann ein solcher Extraktor an eigene Anforderungen angepasst oder ein eigener Extraktor erstellt werden.
Das erste Konzept war die Möglichkeit ihrer Wiederverwendung. Leider stellte sich dies als nicht umsetzbar heraus. Ein großer Teil der Logik ist auf der Seite von SAP BW implementiert, und es war nicht möglich, den Extraktor schmerzfrei vom SAP BW zu trennen.
Es ist offensichtlich geworden, dass ein eigenes Datenauszugssystem aus den SAP-Systemen entwickelt werden muss.
Datenstruktur in SAP HCM
Um die Anforderungen an ein solches System zu verstehen, muss zunächst definiert werden, welche spezifischen Daten wir benötigen.
Die meisten Daten in SAP HCM werden in flachen SQL-Tabellen gespeichert. Basierend auf diesen Daten visualisieren die SAP-Anwendungen die Organisationsstrukturen, Mitarbeiter und andere HR-Informationen für den Benutzer. So sieht beispielsweise die Organisationsstruktur in SAP HCM aus:
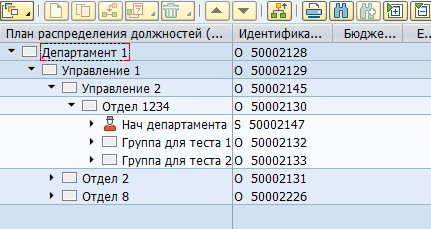
Physisch wird ein solches Baumdiagramm in zwei Tabellen gespeichert – in hrp1000 die Objekte und in hrp1001 die Beziehungen zwischen diesen Objekten.
Objekte "Abteilung 1" und "Verwaltung 1":

Beziehung zwischen den Objekten:

Es kann eine riesige Anzahl an sowohl Objekttypen als auch Beziehungstypen zwischen ihnen geben. Es gibt sowohl standardisierte Beziehungen als auch solche, die für spezifische eigene Bedürfnisse angepasst wurden. Zum Beispiel zeigt die standardisierte Beziehung B012 zwischen der Organisationseinheit und der Stellenbeschreibung auf den Leiter der Abteilung.
Anzeigen des Leiters in SAP:
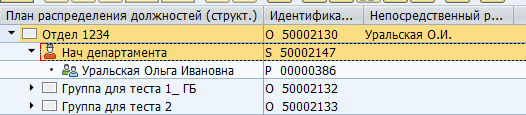
Speicherung in der Datenbanktabelle:

Mitarbeiterdaten werden in Tabellen pa* gespeichert. Beispielsweise werden die Daten zu Personalmaßnahmen eines Mitarbeiters in der Tabelle pa0000 gespeichert.
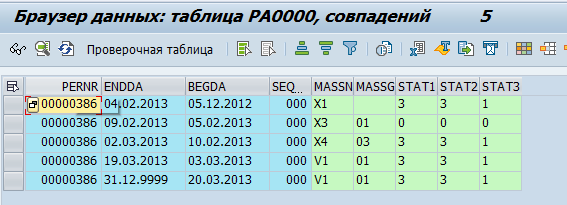
Wir haben beschlossen, dass GreenPlum die 'rohen' Daten abruft, d.h. sie einfach aus den SAP-Tabellen kopiert. Diese werden dann direkt in GreenPlum verarbeitet und in physische Objekte (z.B. Abteilung oder Mitarbeiter) sowie Kennzahlen (z.B. durchschnittliche Personenzahl) umgewandelt.
Es wurden ungefähr 70 Tabellen identifiziert, deren Daten an GreenPlum übermittelt werden müssen. Danach haben wir mit der Entwicklung einer Methode zur Datenübertragung begonnen.
SAP bietet eine Vielzahl von Integrationsmechanismen. Der einfachste Weg ist jedoch, dass der direkte Zugriff auf die Datenbank aufgrund von Lizenzbeschränkungen verboten ist. Daher müssen alle Integrationsströme auf Anwendungsebene realisiert werden. Server Die nächste Herausforderung war das Fehlen von Daten über gelöschte Datensätze in der SAP-Datenbank. Beim Löschen einer Zeile in der Datenbank wird sie physisch entfernt. Das bedeutet, dass die Bildung von Änderungsdeltas zum Zeitpunkt der Änderung nicht möglich war.
Ein weiteres Problem war das Fehlen von Informationen über entfernte Datensätze in der SAP-Datenbank. Wenn eine Zeile in der Datenbank gelöscht wird, erfolgt die physische Löschung. Das heißt, eine Änderung der Delta-Zeiten konnte nicht erstellt werden.
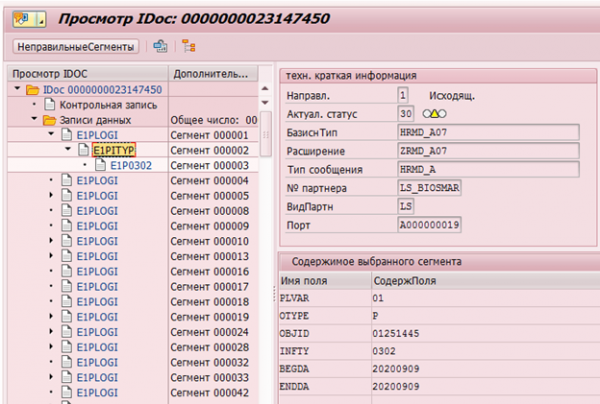
Natürlich gibt es in SAP HCM Mechanismen zur Erfassung von Datenänderungen. Beispielsweise existieren für die spätere Übertragung an Empfängersysteme Änderungszeiger (change pointer), die alle Änderungen protokollieren und auf deren Grundlage IDocs (Objekte zur Übertragung in externe Systeme) erstellt werden.
Beispiel eines IDocs zur Änderung des Infotyps 0302 für den Mitarbeiter mit der Personalnummer 1251445:
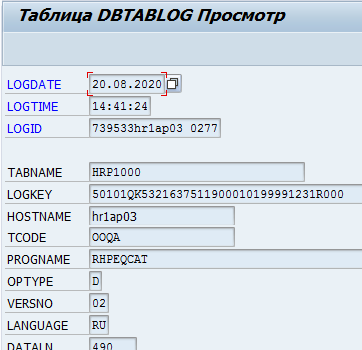
Oder die Führung von Änderungsprotokollen in der Tabelle DBTABLOG.
Beispiel eines Protokolls über die Löschung des Datensatzes mit dem Schlüssel QK53216375 aus der Tabelle hrp1000:
Diese Mechanismen sind jedoch nicht für alle erforderlichen Daten verfügbar, und deren Verarbeitung auf Anwendungsebene kann erhebliche Ressourcen verbrauchen. Daher kann das massenhafte Aktivieren des Loggings für alle notwendigen Tabellen zu einer spürbaren Leistungsminderung des Systems führen.
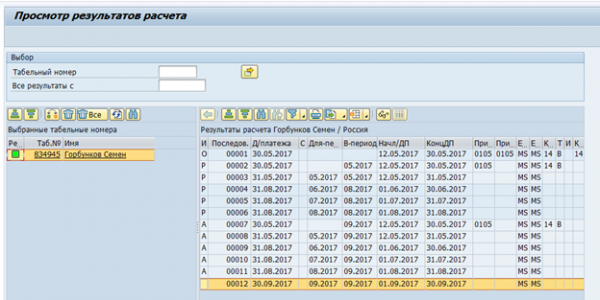
Ein weiteres ernsthaftes Problem waren die Cluster-Tabellen. Die Daten zur Zeitabschätzung und zur Gehaltsberechnung in der RDBMS-Version von SAP HCM werden als eine Menge logischer Tabellen für jeden Mitarbeiter pro Berechnung gespeichert. Diese logischen Tabellen werden als Binärdaten in der Tabelle pcl2 abgelegt.
Cluster zur Gehaltsabrechnung:
Daten aus Cluster-Tabellen können nicht mit SQL-Befehlen abgerufen werden; es erfordert die Nutzung von Makro-Kommandos in SAP HCM oder speziellen Funktionalmodulen. Infolgedessen wird die Abrufgeschwindigkeit solcher Tabellen relativ niedrig sein. Auf der anderen Seite enthalten diese Cluster Daten, die nur einmal im Monat benötigt werden – die endgültige Lohnberechnung und die Zeitevaluation. Daher ist die Geschwindigkeit in diesem Fall nicht so entscheidend.
Bei der Evaluierung der Optionen zur Erstellung einer Delta-Datenänderung haben wir auch die Möglichkeit eines vollständigen Exports in Betracht gezogen. Die tägliche Übertragung von Gigabytes unveränderter Daten zwischen Systemen wirkt nicht sonderlich attraktiv. Dennoch bietet sie einige Vorteile: Es besteht keine Notwendigkeit, das Delta auf der Quellseite zu implementieren, und auch keine auf der Empfängerseite. Dadurch reduzieren sich sowohl die Kosten als auch die Implementierungszeit und die Zuverlässigkeit der Integration wird erhöht. Es wurde festgestellt, dass praktisch alle Änderungen in SAP HR im Zeitraum von drei Monaten bis zum aktuellen Datum stattfinden. Daher wurde entschieden, den täglichen vollständigen Export von Daten aus SAP HR für N Monate vor dem aktuellen Datum und einen monatlichen vollständigen Export durchzuführen. Der Parameter N hängt von der spezifischen Tabelle ab.
und variiert zwischen 1 und 15.
Für die Datenextraktion wurde folgendes Schema vorgeschlagen:

Das externe System erstellt eine Anfrage und sendet sie an SAP HCM, wo die Anfrage auf Vollständigkeit der Daten und Zugriffsberechtigungen für die Tabellen überprüft wird. Bei erfolgreicher Überprüfung wird ein Programm in SAP HCM ausgeführt, das die erforderlichen Daten sammelt und an die Integrationslösung Fuse überträgt. Fuse bestimmt das benötigte Topic in Kafka und überträgt die Daten dorthin. Anschließend werden die Daten aus Kafka an den Stage Area GP weitergegeben.
In dieser Kette interessiert uns die Frage der Datenauszug aus SAP HCM. Lassen Sie uns näher darauf eingehen.
Schema der Interaktion zwischen SAP HCM und FUSE.
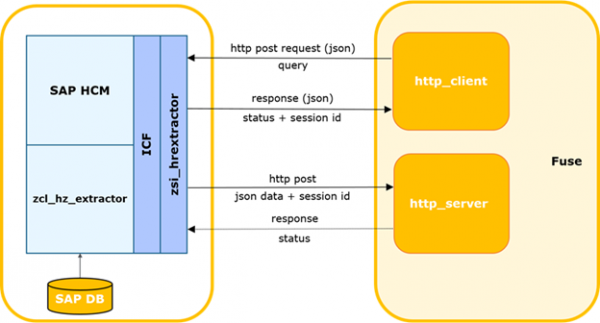
Das externe System bestimmt die Zeit der letzten erfolgreichen Anfrage an SAP.
Der Prozess kann durch einen Timer oder ein anderes Ereignis gestartet werden, einschließlich der Möglichkeit, eine Timeout-Wartezeit für die Antwortdaten von SAP festzulegen und die Anfrage erneut zu initiieren. Danach wird die Delta-Anfrage erstellt und an SAP gesendet.
Die Anfrage-Daten werden im Body im JSON-Format übermittelt.
HTTP-Methode: POST.
Beispielanfrage:

Der SAP-Service führt eine Überprüfung der Anfrage auf Vollständigkeit, Übereinstimmung mit der aktuellen SAP-Struktur und das Vorhandensein von Zugriffsrechten auf die angeforderte Tabelle durch.
Im Falle von Fehlern gibt der Service eine Antwort mit dem entsprechenden Code und einer Beschreibung zurück. Bei erfolgreicher Kontrolle wird ein Hintergrundprozess zur Erstellung der Auswahl gestartet, der einen einzigartigen Sitzungs-ID generiert und synchron zurückgibt.
Das externe System protokolliert im Fehlerfall diesen in einem Log. Bei erfolgreicher Antwort überträgt es die Sitzungs-ID und den Namen der Tabelle, für die die Anfrage gestellt wurde.
Das externe System registriert die aktuelle Sitzung als geöffnet. Falls es andere Sitzungen für diese Tabelle gibt, werden diese mit einer Warnung im Log geschlossen.
Der Hintergrundauftrag von SAP generiert einen Cursor anhand der festgelegten Parameter und ein Datenpaket der angegebenen Größe. Die Paketgröße stellt die maximale Anzahl von Datensätzen dar, die der Prozess aus der DB liest. Standardmäßig wird sie auf 2000 gesetzt. Wenn in der DB-Auswahl mehr Datensätze vorhanden sind als die verwendete Paketgröße, wird nach der Übertragung des ersten Pakets der nächste Block mit dem entsprechenden Offset und der inkrementierten Paketnummer erstellt. Die Nummern werden um 1 erhöht und streng in Folge gesendet.
Anschließend überträgt SAP das Paket an den Webservice eines externen Systems. Dieses System führt Kontrollen des eingehenden Pakets durch. In dem System muss eine Sitzung mit der erhaltenen ID registriert sein und sich im offenen Status befinden. Wenn die Paketnummer > 1 ist, muss der erfolgreiche Empfang des vorherigen Pakets (package_id-1) im System registriert sein.
Im Falle einer erfolgreichen Kontrolle analysiert und speichert das externe System die Daten in der Tabelle.
Zusätzlich, wenn im Paket das Flag 'final' vorhanden ist und die Serialisierung erfolgreich war, erfolgt eine Benachrichtigung des Integrationsmoduls über den erfolgreichen Abschluss der Sitzungsbearbeitung, und das Modul aktualisiert den Status der Sitzung.
Im Falle eines Fehlers bei den Kontrollen/der Analyse wird der Fehler protokolliert, und die Pakete für diese Sitzung werden vom externen System abgelehnt.
Ebenso im umgekehrten Fall, wenn das externe System einen Fehler zurückgibt, wird dieser protokolliert und die Übertragung der Pakete wird gestoppt.
Für die Abfrage von Daten auf der Seite von SAP HCM wurde ein Integrationsservice implementiert. Der Service wurde auf dem Framework ICF (SAP Internet Communication Framework — ). Es ermöglicht die Abfrage von Daten aus dem SAP HCM-System anhand bestimmter Tabellen. Bei der Erstellung der Datenabfrage kann eine Liste spezifischer Felder sowie Filterparameter definiert werden, um die benötigten Daten zu erhalten. Dabei enthält die Implementierung des Dienstes keine Geschäftslogik. Berechnungsalgorithmen für Delta, Abfrageparameter, Integritätskontrolle usw. werden ebenfalls auf der Seite des externen Systems realisiert.
Dieser Mechanismus ermöglicht das Sammeln und Übertragen aller benötigten Daten in nur wenigen Stunden. Diese Geschwindigkeit ist an der Grenze des Akzeptablen, weshalb wir diese Lösung als vorübergehend betrachten, um den Bedarf an einem Extraktionswerkzeug im Projekt zu decken.
In der Zielarchitektur zur Lösung der Datenextraktionsaufgabe werden Optionen zur Verwendung von CDC-Systemen wie Oracle Golden Gate oder ETL-Tools wie SAP DS untersucht.
Quelle: habr.com
