

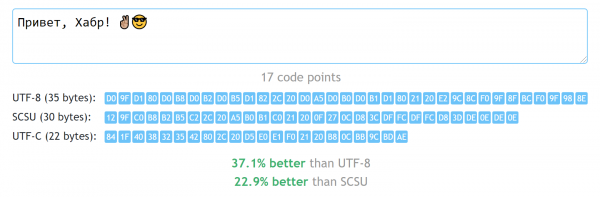
Wenn Sie ein Entwickler sind und die Aufgabe haben, eine Kodierung auszuwählen, ist Unicode fast immer die richtige Wahl. Die spezifische Darstellung hängt vom Kontext ab, aber oft gibt es auch hier eine universelle Antwort: UTF-8. Es hat den Vorteil, dass es alle Unicode-Zeichen verwenden kann, ohne zu viele Bytes zu verschwenden. Für die meisten Fälle sind das übrigens nicht mehr als zwei Bytes pro Zeichen.Gibt es eine bessere Möglichkeit, ohne zu den prähistorischen Kodierungen zurückzukehren, die uns auf nur 256 verfügbare Zeichen beschränken?
Im Folgenden finden Sie meinen Versuch, auf diese Frage zu antworten und eine relativ einfache Algorithmus-Implementierung zu präsentieren, die es ermöglicht, Zeichenfolgen in den meisten Sprachen der Welt zu speichern, ohne die Überflüssigkeit hinzuzufügen, die mit UTF-8 einhergeht.
Haftungsausschluss. Ich möchte gleich einige wichtige Vorbehalte anbringen: Die beschriebene Lösung wird nicht als universeller Ersatz für UTF-8 angeboten., es passt nur in einer engen Liste von Fällen (darüber später), und es darf auf keinen Fall für die Interaktion mit externen APIs verwendet werden (die davon nicht einmal erfahren). Am häufigsten sind Algorithmen zur allgemeinen Datenkompression (wie deflate) für die kompakte Speicherung großer Textdatenmengen geeignet. Außerdem habe ich bereits während der Erstellung meiner Lösung einen bestehenden Standard im Unicode gefunden, der dasselbe Problem löst – er ist etwas komplizierter (und oft schlechter), aber immer noch ein anerkannter Standard und nicht etwas, das improvisiert wurde. Auch darüber werde ich sprechen.
Über Unicode und UTF-8
Zunächst einige Worte zu dem, was das überhaupt ist Unicode und UTF-8.
Wie bekannt, waren früher 8-Bit-Codierungen populär. Damit war alles einfach: 256 Symbole können mit Zahlen von 0 bis 255 nummeriert werden, und die Zahlen von 0 bis 255 sind offensichtlich als ein Byte darstellbar. Wenn man zu den Ursprüngen zurückkehrt, beschränkt sich die ASCII-Codierung auf 7 Bits, weshalb das höchste Bit in ihrer Byte-Darstellung null ist, und die meisten 8-Bit-Codierungen sind damit kompatibel (sie unterscheiden sich nur im „obersten“ Teil, wo das höchste Bit eins ist).
Was unterscheidet Unicode von anderen Codierungen und warum sind damit gleich mehrere spezifische Darstellungen verbunden – UTF-8, UTF-16 (BE und LE), UTF-32? Lassen Sie uns der Reihe nach klären.
Der Hauptstandard von Unicode beschreibt nur die Zuordnung zwischen Zeichen (und in einigen Fällen – einzelnen Komponenten von Zeichen) und ihren Nummern. Es gibt eine Vielzahl möglicher Nummern in diesem Standard – von 0x00 bis zu 0x10FFFF (1.114.112 Stück). Wenn wir eine Zahl in einem solchen Bereich in einer Variablen speichern wollten, wären 1 oder 2 Byte nicht ausreichend. Und da unsere Prozessoren nicht für die Arbeit mit dreibyteigen Zahlen ausgelegt sind, müssten wir ganze 4 Byte für ein Zeichen verwenden! Das ist UTF-32, aber genau wegen dieser „Verschwendung“ wird dieses Format nicht oft verwendet.
Glücklicherweise sind die Zeichen innerhalb von Unicode nicht zufällig angeordnet. Ihre Vielzahl ist in 17 „Ebenen“ unterteilt, von denen jede 65.536 („0x10000) «Codepunkte“ enthält. Der Begriff „Codepunkt“ hier ist einfach die Nummer eines Zeichens., das ihm von Unicode zugewiesen wurde. Wie bereits erwähnt, werden im Unicode nicht nur einzelne Zeichen nummeriert, sondern auch deren Komponenten und Steuerzeichen (manchmal wird der Nummer sogar nichts zugeordnet — vielleicht vorübergehend, aber das ist für uns nicht so wichtig), daher ist es korrekter, immer über die Anzahl der Nummern zu sprechen, nicht über die Zeichen. Im Folgenden werde ich jedoch aus Gründen der Kürze oft das Wort „Zeichen“ verwenden, wobei ich den Begriff „Codepunkt“ meine.
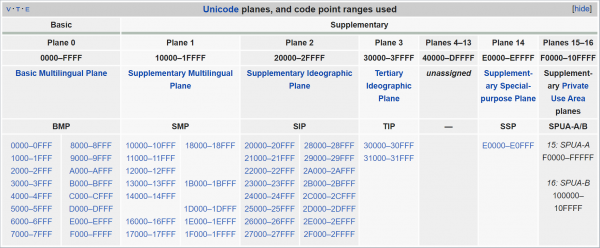
Unicode-Ebenen. Wie zu sehen ist, ist der größte Teil (Ebenen 4 bis 13) noch ungenutzt.
Was am bemerkenswertesten ist — der gesamte zentrale „Kern“ liegt in der Null-Ebene, die "Basic Multilingual Plane" genannt wird. Wenn die Zeile Text in einer der modernen Sprachen (einschließlich Chinesisch) enthält, werden Sie diese Ebene nicht verlassen. Aber auch den restlichen Teil von Unicode kann man nicht ausschneiden — zum Beispiel befinden sich die Emojis hauptsächlich am Ende der nächsten Ebene, "Supplementary Multilingual Plane" (sie erstreckt sich von 0x10000 bis zu 0x1FFFF). Daher funktioniert UTF-16 so: Alle Zeichen, die in Basic Multilingual Plane, wird "wie ist" kodiert, entsprechend ihrer zweibyter Zahl. Aber ein Teil der Zahlen in diesem Bereich repräsentiert überhaupt keine spezifischen Symbole, sondern weist darauf hin, dass nach diesem Byte-Paar ein weiteres betrachtet werden muss — kombiniert man die Werte dieser vier Bytes, erhält man eine Zahl, die den gesamten zulässigen Unicode-Bereich abdeckt. Diese Darstellung wird als "surrogates Paare" bezeichnet — vielleicht haben Sie schon von ihnen gehört.
Daher benötigt UTF-16 zwei oder (in sehr seltenen Fällen) vier Bytes für einen "Codepunkt". Das ist besser, als ständig vier Bytes zu verwenden, aber für lateinische Buchstaben (und andere ASCII-Zeichen) verbraucht diese Kodierung die Hälfte des belegten Raums für Nullen. UTF-8 wurde entwickelt, um dies zu beheben: ASCII belegt darin wie zuvor nur ein Byte; Codes von 0x80 bis zu 0x7FF — zwei Bytes; von 0x800 bis zu 0xFFFF — drei, und von 0x10000 bis zu 0x10FFFF — vier. Auf der einen Seite ist es für das Lateinische gut geworden: Es gibt wieder Kompatibilität mit ASCII, und die Verteilung ist gleichmäßiger "verteilt" von 1 bis 4 Byte. Aber die Alphabete, die sich vom Lateinischen unterscheiden, gewinnen leider überhaupt nicht im Vergleich zu UTF-16, und viele verlangen nun sogar drei Byte statt zwei — der Bereich, der durch die zweibyte Kodierung abgedeckt wird, hat sich um das 32-fache verengt, 0xFFFF bis zu 0x7FF, und er umfasst nun weder Chinesisch noch beispielsweise Georgisch. Das Kyrillische und fünf weitere Alphabete — Hurra — haben Glück gehabt, 2 Byte pro Zeichen.
Warum ist das so? Lassen Sie uns betrachten, wie UTF-8 Symbolcodes darstellt:

Direkt zur Darstellung der Zahlen werden hier Bits verwendet, die mit dem Symbol xmarkiert sind. Es ist zu sehen, dass es in der zweibyte Kodierung nur 11 solcher Bits (von 16) gibt. Die führenden Bits haben hier nur eine Hilfsfunktion. Im Fall der vierbyte Kodierung werden sogar 21 Bits von 32 für die Nummer des Codepunkts reserviert — es scheint, dass drei Bytes (die insgesamt 24 Bits ergeben) ausreichen würden, aber die Dienstmarkierungen verbrauchen zu viel.
Ist das schlecht? Eigentlich nicht. Einerseits — wenn wir großen Wert auf den benötigten Speicherplatz legen, gibt es Kompressionsalgorithmen, die einfach überflüssige Entropie und Redundanz beseitigen. Andererseits war das Ziel von Unicode, eine möglichst universelle Kodierung bereitzustellen. Zum Beispiel können wir eine in UTF-8 kodierte Zeichenkette einem Code anvertrauen, der zuvor nur mit ASCII gearbeitet hat, und müssen nicht befürchten, dass er ein Zeichen aus dem ASCII-Bereich sieht, das dort tatsächlich nicht vorhanden ist (denn in UTF-8 sind alle Bytes, die mit einem Nullbit beginnen, genau das ASCII). Und wenn wir plötzlich den kleinen Schwanz von einer großen Zeichenkette abschneiden möchten, ohne sie von Anfang an zu dekodieren (oder einen Teil der Informationen nach einem beschädigten Abschnitt wiederherzustellen) — ist es nicht schwierig, die Verschiebung zu finden, an der ein Zeichen beginnt (es reicht, die Bytes zu überspringen, die ein bit Präfix haben. 10).
Warum also etwas Neues erfinden?
Gleichzeitig gibt es gelegentlich Situationen, in denen Kompressionsalgorithmen wie deflate schwer anwendbar sind, aber man möchte eine kompakte Speicherung von Zeichenketten erreichen. Ich persönlich bin mit einer solchen Aufgabe konfrontiert worden, als ich über den Aufbau nachgedacht habe. für ein großes Wörterbuch, das Wörter in beliebigen Sprachen umfasst. Einerseits sind alle Wörter sehr kurz, sodass eine Kompression ineffektiv wäre. Andererseits wurde die Baumstruktur, die ich in Betracht gezogen habe, darauf ausgelegt, dass jedes Byte der gespeicherten Zeichenfolge einen separaten Knoten im Baum erzeugt, weshalb es sehr nützlich war, ihre Anzahl zu minimieren. In meiner Bibliothek (wie in , auf dem sie basiert) wird dieses Problem einfach gelöst — die in -Wörterbüchern gespeicherten Zeichenfolgen werden dort in . Aber wie man leicht erkennen kann, funktioniert das nur für ein eingeschränktes Alphabet – eine Zeile auf Chinesisch lässt sich nicht in ein solches Wörterbuch einfügen.
Ich möchte auch einen weiteren unangenehmen Aspekt hervorheben, der bei der Verwendung von UTF-8 in dieser Datenstruktur auftritt. Auf dem Bild oben ist zu sehen, dass die Bits, die zu seiner Nummer gehören, bei der Speicherung eines Zeichens in Form von zwei Bytes nicht aufeinander folgen, sondern durch ein paar Bits 10 in der Mitte unterbrochen sind: 110xxxxx 10xxxxxx. Dadurch ändert sich auch das erste Byte, wenn die unteren 6 Bits des zweiten Bytes im Codesymbol überlaufen (d.h. ein Übergang 10111111 → 10000000). Das bedeutet, dass der Buchstabe „п“ durch Bytes dargestellt wird 0xD0 0xBF, und das nächste Zeichen „r“ ist bereits 0xD1 0x80. Im Präfixbaum führt dies zur Spaltung des Elternknotens in zwei — einen für das Präfix 0xD0, und den anderen für 0xD1 (obwohl das gesamte Kyrillisch durchaus nur mit dem zweiten Byte codiert werden könnte).
Was ich erreicht habe
Angesichts dieser Aufgabe beschloss ich, ein wenig mit Bits zu spielen und dabei die Unicode-Struktur besser zu verstehen. Das Ergebnis war das Codierungsformat UTF-C („C“ für kompakt), das nicht mehr als 3 Bytes für einen Codepunkt verbraucht, häufig jedoch nur ein zusätzliches Byte für die gesamte kodierte Zeile. Das führt dazu, dass bei vielen Nicht-ASCII-Alphabets diese Kodierung 30-60% kompakter ist als UTF-8.
Ich habe Beispiele zur Implementierung von Codierungs- und Dekodierungsalgorithmen in Form von , die Sie in Ihrem Code frei verwenden können. Ich möchte jedoch betonen, dass dieses Format in gewisser Weise ein „Fahrrad“ bleibt, und ich empfehle nicht, es zu verwenden ohne zu verstehen, wofür es benötigt wird. Es ist letztlich mehr ein Experiment als eine ernsthafte "Verbesserung von UTF-8". Dennoch ist der Code sauber, prägnant geschrieben, mit vielen Kommentaren und Tests.
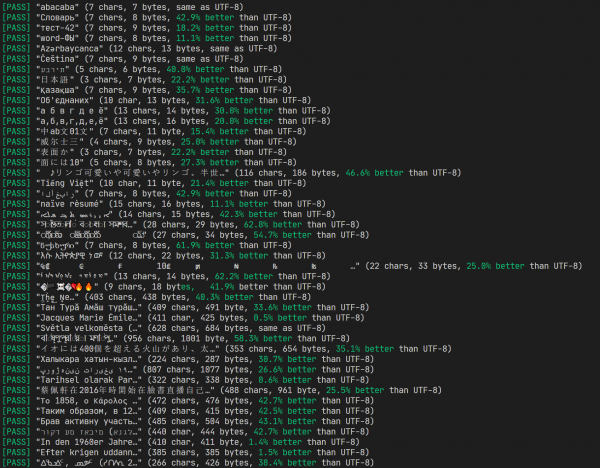
Testergebnisse und Vergleich mit UTF-8
Außerdem habe ich , auf der man die Funktionsweise des Algorithmus bewerten kann. Weiter unten werde ich die Prinzipien und den Entwicklungsprozess näher erläutern.
Überflüssige Bits entfernen
Ich habe natürlich UTF-8 als Grundlage genommen. Das erste und offensichtlichste, was man ändern kann, ist die Reduzierung der Kontrollbits in jedem Byte. Zum Beispiel beginnt das erste Byte in UTF-8 immer entweder mit 0, oder mit 11 — der Präfix 10 gibt es nur bei den folgenden Bytes. Ersetzen wir den Präfix 11 findet man 1, und entfernen wir die Präfixe ganz bei den folgenden Bytes. Was kommt dabei heraus?
0xxxxxxx — 1 Byte
10xxxxxx xxxxxxxx — 2 Bytes
110xxxxx xxxxxxxx xxxxxxxx — 3 Bytes
Halt, wo bleibt die vier-Byte-Darstellung? Die ist nicht mehr nötig — mit dreibyteiger Darstellung stehen uns jetzt 21 Bits zur Verfügung, was mehr als ausreichend ist für alle Zahlen bis 0x10FFFF.
Was haben wir hier geopfert? Das Wichtigste ist die Erkennung von Symbolgrenzen an einer beliebigen Stelle des Puffers. Wir können nicht einfach in ein beliebiges Byte greifen und von dort aus den Anfang des nächsten Symbols finden. Das ist eine Einschränkung unseres Formats, aber in der Praxis tritt die Notwendigkeit dafür nicht oft auf. Normalerweise können wir den Puffer von ganz vorne durchlaufen (besonders bei kurzen Zeichenfolgen).
Die Situation mit der Abdeckung von Sprachen in 2 Bytes hat sich ebenfalls verbessert: Jetzt bietet das zweibyte Format einen Bereich von 14 Bit, was Codes bis 0x3FFF. Die Chinesen haben Pech (ihre Schriftzeichen liegen hauptsächlich im Bereich von 0x4E00 bis zu 0x9FFF), aber für die Georgier und viele andere Völker ist es erfreulicher geworden – ihre Sprachen passen ebenfalls in 2 Bytes pro Zeichen.
Wir führen den Zustand des Encoders ein.
Lassen Sie uns nun über die Eigenschaften der Zeichenfolgen selbst nachdenken. Im Wörterbuch sind häufig Worte zu finden, die mit Symbolen eines Alphabets geschrieben sind, und das gilt auch für viele andere Texte. Es wäre gut, einmal dieses Alphabet anzugeben und dann nur die Nummer des Buchstabens innerhalb davon zu nennen. Mal sehen, ob uns die Anordnung der Zeichen in der Unicode-Tabelle hilft.
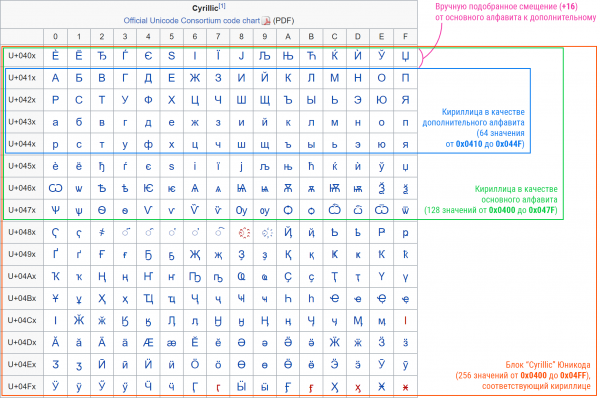
Wie oben erwähnt, ist Unicode in Ebenen unterteilt. jeweils 65536 Codes. Aber diese Einteilung ist nicht sehr hilfreich (wie bereits erwähnt, befinden wir uns meistens in der Nullebene). Interessanter ist die Unterteilung in Blöcke. Diese Bereiche haben keine feste Länge mehr und sind bedeutungsvoller — in der Regel vereint jeder von ihnen Zeichen eines Alphabets.
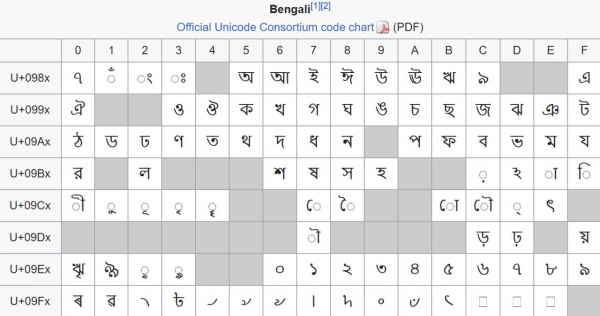
Ein Block, der Zeichen des bengalischen Alphabets enthält. Leider ist dies aus historischen Gründen ein Beispiel für eine nicht sehr dichte Verpackung — 96 Zeichen sind chaotisch über 128 Codepunkte des Blocks verteilt.
Die Anfangspositionen der Blöcke und deren Größen sind stets ein Vielfaches von 16 — dies erleichtert die Handhabung. Darüber hinaus beginnen und enden viele Blöcke auf Werten, die ein Vielfaches von 128 oder sogar 256 sind — zum Beispiel nimmt die Basis-Kyrillik 256 Byte von 0x0400 bis zu 0x04FF. Das ist ziemlich praktisch: Wenn wir einmal das Präfix speichern, 0x04, kann jedes kyrillische Zeichen mit einem Byte geschrieben werden. Allerdings verlieren wir dadurch die Möglichkeit, zu ASCII (und zu allen anderen Zeichen überhaupt) zurückzukehren. Daher machen wir es so:
- Zwei Bytes
10yyyyyy yxxxxxxxbezeichnen nicht nur das Zeichen mit der Nummeryyyyyy yxxxxxxx, sondern ändern auch das aktuelle Alphabet findet manyyyyyy y0000000d.h. wir merken uns alle Bits, außer den niedrigsten 7 Bits); - Ein Byte
0xxxxxxxdies ist das Symbol des aktuellen Alphabets. Es muss einfach mit der Verschiebung addiert werden, die wir in Schritt 1 gespeichert haben. Da wir das Alphabet bisher nicht geändert haben, ist die Verschiebung null, sodass wir mit ASCII kompatibel geblieben sind.
Ähnlich für Codes, die 3 Byte benötigen:
- Drei Bytes
110yyyyy yxxxxxxx xxxxxxxxbezeichnen ein Zeichen mit der Nummeryyyyyy yxxxxxxx xxxxxxxx, verändert das aktuelle Alphabet findet manyyyyyy y0000000 00000000(wir haben alles außer den niederwertigen 15 Bit), und setzen ein Flag, dass wir uns jetzt im langen Modus befinden (bei einem Wechsel des Alphabets zurück in den zweibyteiger Modus setzen wir dieses Flag zurück); - Zwei Bytes
0xxxxxxx xxxxxxxxim langen Modus ist dies das Zeichen des aktuellen Alphabets. Ähnlich addieren wir es zur Verschiebung aus Schritt 1. Der einzige Unterschied besteht darin, dass wir jetzt zwei Bytes lesen (weil wir in diesen Modus gewechselt haben).
Klingt gut: Solange wir Zeichen aus dem gleichen 7-Bit-Bereich von Unicode kodieren müssen, verwenden wir 1 zusätzliches Byte am Anfang und nur 1 Byte pro Zeichen.
Arbeit einer der früheren Versionen. Überholt oft UTF-8, aber es gibt noch Verbesserungsbedarf.
Was ist schlimmer geworden? Erstens haben wir jetzt einen Zustand, nämlich die Verschiebung des aktuellen Alphabets und das Flag des langen Modus. Das schränkt uns zusätzlich ein: Nun können dieselben Zeichen in verschiedenen Kontexten unterschiedlich kodiert werden. Beispielsweise müssen wir beim Suchen nach Teilstrings dies berücksichtigen und nicht einfach Bytes vergleichen. Zweitens, sobald wir das Alphabet gewechselt haben, gibt es Probleme mit der Kodierung von ASCII-Zeichen (und das umfasst nicht nur das lateinische Alphabet, sondern auch die grundlegende Interpunktion, einschließlich Leerzeichen) — sie erfordern einen erneuten Alphabetwechsel in 0, also wieder ein zusätzliches Byte (und dann noch eines, um zu unserem Hauptalphabet zurückzukehren).
Ein Alphabet ist gut, zwei sind besser.
Lassen Sie uns versuchen, unsere Bit-Präfixe ein wenig zu ändern, indem wir noch einen zu den drei oben beschriebenen hinzufügen:
0xxxxxxx — 1 Byte im Normalmodus, 2 im langen Modus.
11xxxxxx — 1 Byte
100xxxxx xxxxxxxx — 2 Bytes
101xxxxx xxxxxxxx xxxxxxxx — 3 Bytes
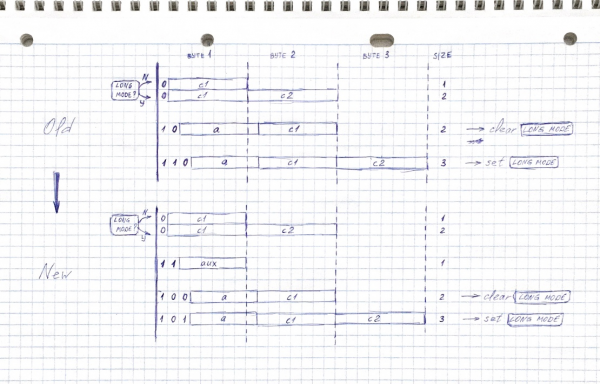
Jetzt gibt es in der zweibyte Kodierung ein verfügbares Bit weniger — es werden Codepunkte bis zu 0x1FFF, und nicht 0x3FFF. Dennoch ist das immer noch spürbar mehr als in zweibyte UTF-8-Codes, die meisten verbreiteten Sprachen passen immer noch hinein, der auffälligste Verlust — ist weggefallen. und , die Japaner sind traurig.
Was ist der neue Code 11xxxxxx? Это небольшой «загашник» размером в 64 символа, он дополняет наш основной алфавит, поэтому я назвал его вспомогательным (auxiliary) Alphabet. Wenn wir das aktuelle Alphabet umschalten, wird ein Stück des alten Alphabets zum Hilfsalphabet. Zum Beispiel, wenn wir von ASCII auf Kyrillisch umschalten, haben wir nun 64 Zeichen im „Cache“, die enthalten sind Latein, Ziffern, Leerzeichen und Komma (die häufigsten Einfügungen in Nicht-ASCII-Texten). Wenn wir wieder auf ASCII umschalten, wird der Hauptteil des Kyrillischen zum Hilfsalphabet.
Dank des Zugriffs auf zwei Alphabete können wir mit einer großen Anzahl von Texten umgehen, ohne nennenswerte Kosten für das Umschalten der Alphabete (die Interpunktion führt meist dazu, dass wir zu ASCII zurückkehren, aber danach ziehen wir viele Nicht-ASCII-Zeichen bereits aus dem zusätzlichen Alphabet, ohne erneut umzuschalten).
Bonus: Wenn wir das Hilfsalphabet mit einem Präfix kennzeichnen 11xxxxxx und seinen Anfangsversatz auf 0xC0setzen, erhalten wir teilweise Kompatibilität mit CP1252. Mit anderen Worten, viele (aber nicht alle) westeuropäische Texte, die in CP1252 kodiert sind, werden auch in UTF-C gleich aussehen.
Hier stellt sich tatsächlich die Frage: Wie erhält man aus dem Hauptalphabet ein Hilfsalphabet? Man könnte die gleiche Verschiebung beibehalten, aber leider spielt hier die Unicode-Struktur gegen uns. Häufig befindet sich der Hauptteil des Alphabets nicht am Anfang des Blocks (zum Beispiel hat der russische Großbuchstabe „А“ den Code 0x0410, während der kyrillische Block mit 0x0400beginnt). Wenn wir also die ersten 64 Zeichen in den „Speicher“ nehmen, könnten wir möglicherweise den Zugang zum Schwanzteil des Alphabets verlieren.
Um dieses Problem zu beheben, habe ich manuell einige Blöcke durchgearbeitet, die verschiedenen Sprachen entsprechen, und für sie die Verschiebung des Hilfsalphabets innerhalb des Hauptalphabets angegeben. Die lateinischen Buchstaben habe ich ausnahmsweise ganz umsortiert, ähnlich wie bei base64.
Letzte Anpassungen
Lass uns zum Schluss überlegen, wo wir noch etwas verbessern können.
Beachten wir, dass das Format 101xxxxx xxxxxxxx xxxxxxxx es ermöglicht, Zahlen bis zu 0x1FFFFFzu kodieren, während Unicode früher endet, bei 0x10FFFF. Mit anderen Worten, der letzte Codepunkt wird dargestellt als 10110000 11111111 11111111. Das heißt, wir können sagen, dass, wenn das erste Byte wie folgt aussieht 1011xxxx (wo xxxx mehr als 0), was etwas anderes bedeutet. Zum Beispiel könnte man dort noch 15 Zeichen hinzufügen, die ständig mit einem Byte kodiert werden können, aber ich habe mich entschieden, es anders zu machen.
Schauen wir uns die Unicode-Blöcke an, die jetzt drei Bytes erfordern. In erster Linie sind dies, wie bereits erwähnt, chinesische Schriftzeichen — aber damit lässt sich schwer etwas machen, es gibt 21.000. Aber auch Hiragana und Katakana haben es dorthin geschafft — und davon gibt es nicht mehr so viele, weniger als zweihundert. Und da wir gerade die Japaner erwähnt haben — dort liegen auch Emojis (tatsächlich sind sie überall im Unicode verteilt, aber die Hauptblöcke liegen im Bereich 0x1F300 – 0x1FBFF). Wenn man bedenkt, dass es jetzt Emojis gibt, die aus mehreren Codepunkten bestehen (zum Beispiel das Emoji besteht aus insgesamt 7 Codes!), dann wird es wirklich schade, für jedes drei Bytes auszugeben (7×3 = 21 Bytes für ein Symbol, das ist der Wahnsinn).
Deshalb wählen wir einige ausgewählte Bereiche, die den Emojis, Hiragana und Katakana entsprechen, nummerieren sie in eine durchgehende Liste um und kodieren sie in zwei Bytes statt drei:
1011xxxx xxxxxxxx
Super: das oben genannte Emoji , das aus 7 Codepunkten besteht, benötigt in UTF-8 25 Bytes, und wir haben es untergebracht in 14 (genau zwei Bytes für jedes Codepunkt). Übrigens hat Habr sich geweigert, es zu verarbeiten (weder im alten noch im neuen Editor), also musste ich es als Bild einfügen.
Lassen Sie uns ein weiteres Problem versuchen zu beheben. Wie wir wissen, ist das Hauptalphabet im Grunde die oberen 6 Bit, die wir im Kopf behalten und an den Code jedes nächsten decodierten Zeichens anheften. Im Fall von chinesischen Schriftzeichen, die sich im Block 0x4E00 – 0x9FFF, handelt es sich entweder um Bit 0 oder 1. Das ist nicht sehr praktisch: Wir müssen das Alphabet ständig zwischen diesen beiden Werten umschalten (d.h. jeweils drei Bytes verbrauchen). Aber wir beachten, dass wir im langen Modus aus dem Code die Anzahl der Zeichen abziehen können, die wir im kurzen Modus codieren (nach all den oben beschriebenen Tricks sind das 10240) — dann verschiebt sich der Bereich der Schriftzeichen zu 0x2600 – 0x77FF, und in diesem Fall werden in diesem gesamten Bereich die oberen 6 Bits (von 21) 0 sein. Somit werden die Sequenzen der Schriftzeichen zwei Bytes pro Schriftzeichen verwenden (was für einen so großen Bereich optimal ist), ohne dass ein Wechsel des Alphabets erforderlich ist.
Alternative Lösungen: SCSU, BOCU-1
Unicode-Experten werden, allein beim Lesen des Titels des Artikels, wahrscheinlich schnell daran erinnern, dass es unter den Unicode-Standards (SCSU) gibt, das beschreibt, wie Daten kodiert werden, was dem in diesem Artikel beschriebenen Ansatz sehr ähnlich ist.
Ich muss ehrlich zugeben: Ich habe erst sehr spät, als ich schon tief in die Entwicklung meiner eigenen Lösung eingetaucht war, von seiner Existenz erfahren. Hätte ich von ihm zu Beginn gewusst, hätte ich wahrscheinlich versucht, seine Implementierung statt meiner eigenen Herangehensweise zu entwickeln.
Was interessant ist, SCSU nutzt Ideen, die sehr ähnlich sind wie die, zu denen ich selbst gekommen bin (statt des Begriffs „Alphabete” spricht man dort von „Fenstern”, und es gibt mehr davon als bei mir). Gleichzeitig hat dieses Format jedoch auch Nachteile: Es ist näher an Kompressionsalgorithmen als an Kodierungsalgorithmen. Insbesondere bietet der Standard viele Darstellungsmöglichkeiten, sagt aber nicht, wie man die beste auswählt — dafür muss der Encoder einige Heuristiken anwenden. Ein SCSU-Encoder, der eine gute Komprimierung erzielt, wird komplexer und schwerfälliger sein als mein Algorithmus.
Zum Vergleich habe ich eine relativ einfache SCSU-Implementierung in JavaScript übertragen — der Codeumfang ist mit meinem UTF-C vergleichbar, aber in einigen Fällen fiel das Ergebnis um mehrere Prozentpunkte schlechter aus (manchmal kann es auch leicht besser abschneiden, aber nicht viel). Beispielsweise hat mein UTF-C Texte in Hebräisch und Griechisch um 60 % besser kodiert als SCSU (wahrscheinlich wegen ihrer kompakten Alphabete).
Ich füge hinzu, dass es neben SCSU auch eine andere Methode zur kompakten Darstellung von Unicode gibt — , die jedoch die Kompatibilität mit MIME (was mir nicht erforderlich war) zum Ziel hat und einen etwas anderen Ansatz zur Kodierung verwendet. Ich habe seine Effektivität nicht bewertet, aber ich denke, dass sie wahrscheinlich nicht höher als die von SCSU sein wird.
Mögliche Verbesserungen
Der Algorithmus, den ich angegeben habe, ist von Design aus nicht universell (in dieser Hinsicht divergieren meine Ziele wahrscheinlich am stärksten von den Zielen des Unicode-Konsortiums). Ich habe bereits erwähnt, dass er hauptsächlich für eine Aufgabe (das Speichern eines mehrsprachigen Wörterbuchs in einem Präfixbaum) entwickelt wurde, und einige seiner Eigenschaften möglicherweise für andere Aufgaben nicht gut geeignet sind. Aber die Tatsache, dass er kein Standard ist, könnte auch ein Vorteil sein — Sie können ihn leicht an Ihre Bedürfnisse anpassen..
Zum Beispiel kann offensichtlich der Zustand entfernt und die Kodierung stateless gemacht werden — einfach die Variablen nicht aktualisieren. Aus, off und ist21Bit Im Encoder und Decoder. In diesem Fall wird es nicht möglich sein, effektive Packungen von Symbolfolgen eines Alphabets zu erstellen, während die Garantie besteht, dass dasselbe Zeichen immer mit denselben Bytes codiert wird, unabhängig vom Kontext.
Darüber hinaus kann der Encoder auf eine bestimmte Sprache abgestimmt werden, indem der Standardzustand geändert wird — beispielsweise, indem man sich auf russische Texte orientiert und zu Beginn des Encoders und Decoders einrichtet. offs = 0x0400 und auxOffs = 0. Dies macht insbesondere im stateless Modus Sinn. Insgesamt wird es ähnlich sein wie die Verwendung einer alten 8-Bit-Kodierung, jedoch ohne die Möglichkeit, bei Bedarf Zeichen aus dem gesamten Unicode einzufügen.
Ein weiterer Nachteil, der bereits erwähnt wurde, ist, dass es im umfangreichen Text, der in UTF-C codiert ist, keine schnelle Möglichkeit gibt, die Grenzmarkierung eines Zeichens zu finden, das sich am nächsten zu einem beliebigen Byte befindet. Wenn Sie die letzten, sagen wir, 100 Bytes aus dem codierten Puffer abschneiden, riskieren Sie, Müll zu erhalten, mit dem nichts anzufangen ist. Die Kodierung ist nicht für die Speicherung mehrgigagroßer Protokolldateien ausgelegt, aber insgesamt kann dies behoben werden. Byte 0xBF sollte niemals als erstes Byte auftreten (kann aber das zweite oder dritte sein). Daher kann beim Kodieren eine Sequenz eingefügt werden. 0xBF 0xBF 0xBF alle, sagen wir, 10 Kb — dann reicht es aus, einen gewählten Abschnitt zu scannen, um die Grenze zu finden, bis ein solcher Marker gefunden wird. Hinter dem letzten 0xBF wird garantiert der Beginn des Zeichens sein. (Beim Dekodieren muss diese Sequenz aus drei Bytes natürlich ignoriert werden.)
Zusammenfassend
Wenn Sie es bis hierher gelesen haben — herzlichen Glückwunsch! Ich hoffe, Sie haben, wie ich, etwas Neues gelernt (oder Erinnerungen an altes Wissen aufgefrischt) über den Aufbau von Unicode.
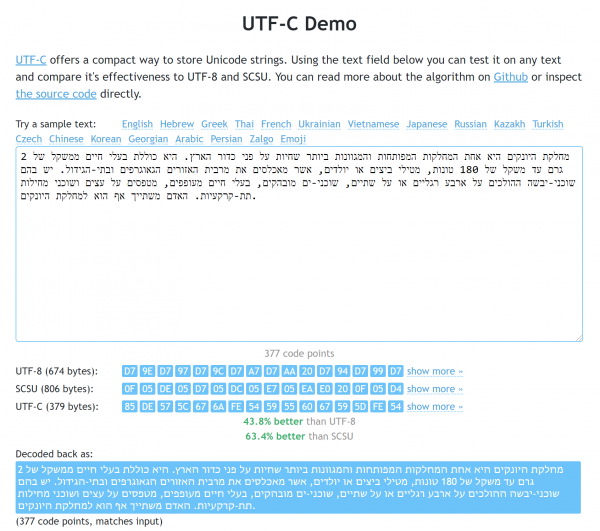
Demonstrationsseite. Am Beispiel Hebräisch sind die Vorteile sowohl gegenüber UTF-8 als auch gegenüber SCSU zu erkennen.
Die oben beschriebenen Überlegungen sollten nicht als Eingriff in Standards angesehen werden. Insgesamt bin ich jedoch mit den Ergebnissen meiner Arbeit zufrieden und teile sie gerne. : Beispielsweise hat die JS-Bibliothek in minifizierter Form nur 1710 Bytes (und natürlich keine Abhängigkeiten). Wie bereits erwähnt, kann ihre Funktionsweise auf der eingesehen werden (dort gibt es auch eine Sammlung von Texten, mit denen sie mit UTF-8 und SCSU verglichen werden kann).
Zum Schluss möchte ich noch einmal auf die Fälle hinweisen, in denen UTF-C verwendet werden sollte. nicht:
- Wenn Ihre Zeichenfolgen lang genug sind (von 100-200 Zeichen). In diesem Fall sollten Sie über den Einsatz von Komprimierungsalgorithmen wie deflate nachdenken.
- Falls Sie ASCII-Transparenzbenötigen, das heißt, es ist Ihnen wichtig, dass in den codierten Sequenzen keine ASCII-Codes auftreten, die in der ursprünglichen Zeichenfolge nicht vorhanden waren. Diese Anforderung kann vermieden werden, wenn Sie bei der Interaktion mit externen APIs (zum Beispiel bei der Arbeit mit Datenbanken) das Ergebnis der Codierung als abstrakte Bytefolge und nicht als Zeichenfolgen übergeben. Andernfalls riskieren Sie unerwartete Sicherheitsanfälligkeiten.
- Wenn Sie in der Lage sein möchten, die Grenzen von Zeichen bei beliebigen Offsets schnell zu finden (z. B. wenn ein Teil der Zeichenfolge beschädigt ist). Dies ist möglich, erfordert jedoch, dass die Zeichenfolge von Anfang an gescannt wird (oder dass die zuvor beschriebene Modifikation angewendet wird).
- Wenn Sie schnell Operationen auf den Inhalten von Zeichenfolgen durchführen müssen (wie sie sortieren, Teilzeichenfolgen suchen oder verketten). Dafür müssen die Zeichenfolgen zuerst dekodiert werden, daher ist UTF-C in diesen Fällen langsamer als UTF-8 (aber schneller als Komprimierungsalgorithmen). Da dieselbe Zeichenfolge immer gleich codiert wird, erfordert der genaue Vergleich der Dekodierung keine spezielle Behandlung; dies kann byteweise durchgeführt werden.
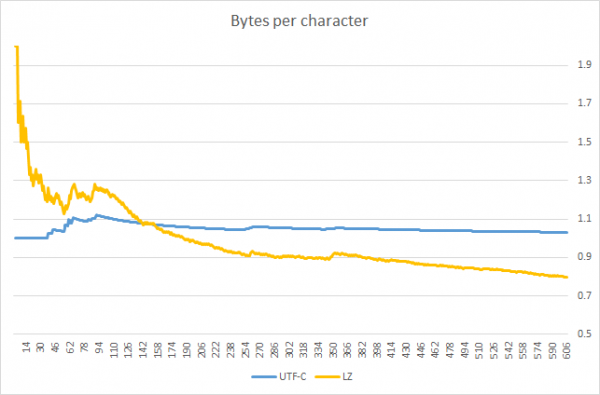
Update: Benutzer Ich habe ein Diagramm veröffentlicht, das die Anwendbarkeitsgrenze von UTF-C hervorhebt. Es zeigt, dass UTF-C effizienter ist als allgemeine Komprimierungsalgorithmen (Varianten von LZW), solange die zu packende Zeichenfolge kürzer ist. ~140 Zeichen (ich möchte jedoch anmerken, dass der Vergleich an demselben Text durchgeführt wurde; für andere Sprachen kann das Ergebnis abweichen).
Quelle: habr.com
