

Egal wie sehr sich die Technologie entwickelt, immer gibt es eine Reihe überholter Ansätze, die hinterherhinken. Dies kann durch einen sanften Übergang, menschliche Faktoren, technologische Notwendigkeiten oder etwas anderes bedingt sein. Im Bereich der Datenverarbeitung sind die Datenquellen besonders prägnant. So sehr wir auch hoffen, davon loszukommen, werden immer noch Teile der Daten über Messenger und E-Mails versendet, ganz zu schweigen von noch archaïscheren Formaten. Lassen Sie uns unter dem Beitrag einen der Ansätze für Apache Airflow untersuchen, der veranschaulicht, wie man Daten aus E-Mails abrufen kann.
Hintergrund
Viele Daten werden nach wie vor über E-Mail übertragen, von zwischenmenschlicher Kommunikation bis hin zu Standards für die Interaktion zwischen Unternehmen. Es ist vorteilhaft, wenn man eine Schnittstelle zum Abrufen von Daten entwickeln oder Mitarbeiter im Büro haben kann, die diese Informationen in leichter zugängliche Quellen eingeben. Oftmals besteht jedoch einfach nicht die Möglichkeit dazu. Eine spezifische Herausforderung, der ich begegnete, war der Anschluss eines bekannten CRM-Systems an ein Datenspeicher und anschließend an ein OLAP-System. Historisch ist es so gekommen, dass der Einsatz dieses Systems für unser Unternehmen in einem bestimmten Geschäftsfeld vorteilhaft war. Daher wünschte sich jeder, Daten auch aus diesem externen System nutzen zu können. Zunächst wurde die Möglichkeit untersucht, Daten über die offene API abzurufen. Leider bot die API nicht alle benötigten Daten an und war, um es einfach auszudrücken, in vielerlei Hinsicht fehlerhaft, während der technische Support nicht bereit oder nicht in der Lage war, ein umfassenderes Funktionsspektrum bereitzustellen. Diese System hingegen bot die Möglichkeit, fehlende Daten periodisch per E-Mail in Form eines Links zum Herunterladen des Archivs zu erhalten.
Es ist wichtig zu erwähnen, dass dies nicht der einzige Fall war, in dem ein Unternehmen Daten aus E-Mails oder Messengern sammeln wollte. In diesem Fall konnten wir jedoch keinen Einfluss auf das Drittunternehmen nehmen, das einen Teil der Daten nur auf diese Weise bereitstellt.
Apache Airflow
Zur Erstellung von ETL-Prozessen verwenden wir am häufigsten Apache Airflow. Um dem Leser, der mit dieser Technologie nicht vertraut ist, ein besseres Verständnis für den Kontext zu geben, werde ich einige grundlegende Informationen bereitstellen.
Apache Airflow ist eine Open-Source-Plattform, die für die Erstellung, Ausführung und Überwachung von ETL (Extract-Transform-Loading)-Prozessen in Python verwendet wird. Das zentrale Konzept von Airflow ist ein gerichteter azyklischer Graph, in dem die Knoten des Graphen spezifische Prozesse darstellen und die Kanten des Graphen den Fluss von Steuerung oder Informationen beispielsweise zwischen verschiedenen Prozessen zeigen. Ein Prozess kann einfach jede Python-Funktion aufrufen oder eine komplexere Logik durch aufeinanderfolgende Aufrufe mehrerer Funktionen im Kontext einer Klasse enthalten. Für die häufigsten Operationen gibt es bereits viele vorgefertigte Module, die als Prozesse verwendet werden können. Zu diesen Modulen gehören:
- Operatoren – zum Verschieben von Daten von einem Ort zum anderen, beispielsweise von einer Datenbanktabelle in ein Data Warehouse;
- Sensoren – zur Überwachung bestimmter Ereignisse und zur Steuerung des Datenflusses zu den nachfolgenden Knoten im Graph;
- Hooks – für niedrigere Systemoperationen, wie das Abrufen von Daten aus einer Datenbanktabelle (werden in Operatoren verwendet);
- usw.
Eine detaillierte Beschreibung von Apache Airflow wäre in diesem Artikel nicht sinnvoll. Kurze Einführungen finden Sie hier. oder .
Hook zum Abrufen von Daten
Um die Aufgabe zu lösen, müssen wir zunächst einen Hook schreiben, mit dem wir:
- uns mit E-Mails verbinden;
- die benötigte E-Mail finden;
- Daten aus der E-Mail abrufen.
from airflow.hooks.base_hook import BaseHook
import imaplib
import logging
class IMAPHook(BaseHook):
def __init__(self, imap_conn_id):
"""
IMAP-Hook zum Abrufen von Daten aus E-Mails
:param imap_conn_id: E-Mail-Verbindungs-ID
:type imap_conn_id: string
"""
self.connection = self.get_connection(imap_conn_id)
self.mail = None
def authenticate(self):
"""
Verbindung zur E-Mail herstellen
"""
mail = imaplib.IMAP4_SSL(self.connection.host)
response, detail = mail.login(user=self.connection.login, password=self.connection.password)
if response != "OK":
raise AirflowException("Anmeldung fehlgeschlagen")
else:
self.mail = mail
def get_last_mail(self, check_seen=True, box="INBOX", condition="(UNSEEN)"):
"""
Methode zum Abrufen der ID der letzten E-Mail,
die den Suchkriterien entspricht
:param check_seen: Letzte E-Mail als gelesen markieren
:type check_seen: bool
:param box: Name des Postfachs
:type box: string
:param condition: Suchkriterien für E-Mails
:type condition: string
"""
self.authenticate()
self.mail.select(mailbox=box)
response, data = self.mail.search(None, condition)
mail_ids = data[0].split()
logging.info("Die folgenden E-Mails wurden im Postfach gefunden: " + str(mail_ids))
if not mail_ids:
logging.info("Keine neuen E-Mails gefunden")
return None
mail_id = mail_ids[0]
# falls mehrere solche E-Mails vorhanden sind
if len(mail_ids) > 1:
# markiere die anderen als gelesen
for id in mail_ids:
self.mail.store(id, "+FLAGS", "\Seen")
# die letzte zurückgeben
mail_id = mail_ids[-1]
# soll die letzte als gelesen markiert werden?
if not check_seen:
self.mail.store(mail_id, "-FLAGS", "\Seen")
return mail_idDie Logik ist folgende: Wir verbinden uns, finden die letzte aktuelle E-Mail; andere E-Mails werden ignoriert. Diese Funktion wird verwendet, weil spätere E-Mails alle Daten der früheren enthalten. Falls das nicht der Fall ist, kann man ein Array aller E-Mails zurückgeben oder die erste verarbeiten und die übrigen beim nächsten Durchlauf. Kurz gesagt, alles hängt wie immer von der Aufgabe ab.
Wir fügen dem Hook zwei Hilfsfunktionen hinzu: eine zum Herunterladen einer Datei und eine zum Herunterladen einer Datei über den Link in der E-Mail. Übrigens können diese in einen Operator ausgelagert werden, das hängt von der Häufigkeit der Nutzung dieser Funktionalität ab. Was sonst noch zum Hook hinzugefügt werden sollte, hängt, wie gesagt, von der Aufgabe ab: Wenn in der E-Mail Dateien ankommen, können die Anhänge heruntergeladen werden; wenn Daten in der E-Mail ankommen, müssen wir die E-Mail parsen usw. In meinem Fall kommt die E-Mail mit einem Link zu einem Archiv, das ich an einem bestimmten Ort ablegen und den weiteren Verarbeitungsprozess starten muss.
def download_from_url(self, url, path, chunk_size=128):
"""
Methode zum Herunterladen einer Datei
:param url: Downloadadresse
:type url: string
:param path: Zielverzeichnis für die Datei
:type path: string
:param chunk_size: Anzahl der Bytes, die geschrieben werden
:type chunk_size: int
"""
r = requests.get(url, stream=True)
with open(path, "wb") as fd:
for chunk in r.iter_content(chunk_size=chunk_size):
fd.write(chunk)
def download_mail_href_attachment(self, mail_id, path):
"""
Methode zum Herunterladen einer Datei über einen Link aus einer E-Mail
:param mail_id: E-Mail-Identifikator
:type mail_id: string
:param path: Zielverzeichnis für die Datei
:type path: string
"""
response, data = self.mail.fetch(mail_id, "(RFC822)")
raw_email = data[0][1]
raw_soup = raw_email.decode().replace("r", "").replace("n", "")
parse_soup = BeautifulSoup(raw_soup, "html.parser")
link_text = ""
for a in parse_soup.find_all("a", href=True, text=True):
link_text = a["href"]
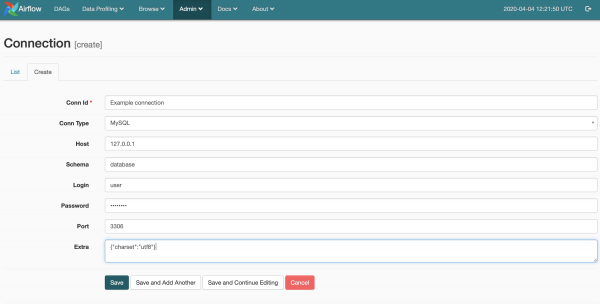
self.download_from_url(link_text, path)Der Code ist einfach, weshalb er wahrscheinlich keiner weiteren Erklärung bedarf. Ich möchte nur auf die magische Zeile imap_conn_id hinweisen. Apache Airflow speichert Verbindungsparameter (Benutzername, Passwort, Adresse und weitere Parameter), auf die über eine Zeichenfolgen-ID zugegriffen werden kann. Visuell sieht die Verwaltung der Verbindungen so aus.
Sensor zum Warten auf Daten
Da wir bereits lernen, uns zu verbinden und Daten aus der E-Mail abzurufen, können wir nun einen Sensor erstellen, um auf diese Daten zu warten. Es war mir nicht möglich, sofort einen Operator zu schreiben, der die Daten verarbeitet, da auf Basis der erhaltenen Informationen aus der E-Mail auch andere Prozesse laufen, die verwandte Daten aus unterschiedlichen Quellen abrufen (wie API, Telefonie, Web-Metriken usw.). Ein Beispiel: In unserem CRM-System erscheint ein neuer Nutzer, und wir kennen noch nicht seine UUID. Wenn wir also versuchen, Daten von der SIP-Telefonie abzurufen, erhalten wir Anrufe, die mit seiner UUID verknüpft sind, können sie aber nicht korrekt speichern oder nutzen. In solchen Fällen ist es wichtig, die Abhängigkeit der Daten zu berücksichtigen, insbesondere wenn sie aus verschiedenen Quellen stammen. Das sind zwar nicht ausreichende Maßnahmen zur Sicherstellung der Datenintegrität, aber in manchen Fällen notwendig. Es ist auch nicht sinnvoll, Ressourcen unnötig zu beschäftigen.
Somit wird unser Sensor die nachfolgenden Knoten im Graphen aktivieren, wenn frische Informationen in der E-Mail verfügbar sind, und auch die vorherigen Informationen als veraltet kennzeichnen.
from airflow.sensors.base_sensor_operator import BaseSensorOperator
from airflow.utils.decorators import apply_defaults
from my_plugin.hooks.imap_hook import IMAPHook
class MailSensor(BaseSensorOperator):
@apply_defaults
def __init__(self, conn_id, check_seen=True, box="Posteingang", condition="(UNSEEN)", *args, **kwargs):
super().__init__(*args, **kwargs)
self.conn_id = conn_id
self.check_seen = check_seen
self.box = box
self.condition = condition
def poke(self, context):
conn = IMAPHook(self.conn_id)
mail_id = conn.get_last_mail(check_seen=self.check_seen, box=self.box, condition=self.condition)
if mail_id is None:
return False
else:
return TrueDaten abrufen und verwenden
Um Daten abzurufen und zu verarbeiten, kann ein separater Operator erstellt oder bereits bestehende verwendet werden. Da die Logik derzeit trivial ist — einfach Daten aus einer E-Mail abzurufen — schlage ich zur Veranschaulichung den standardmäßigen PythonOperator vor.
from airflow.models import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.sensors.my_plugin import MailSensor
from my_plugin.hooks.imap_hook import IMAPHook
start_date = datetime(2020, 4, 4)
# Standardkonfiguration des DAG
args = {
"owner": "example",
"start_date": start_date,
"email": ["home@home.de"],
"email_on_failure": False,
"email_on_retry": False,
"retry_delay": timedelta(minutes=15),
"provide_context": False,
}
dag = DAG(
dag_id="test_etl",
default_args=args,
schedule_interval="@hourly",
)
# Sensor definieren
mail_check_sensor = MailSensor(
task_id="check_new_emails",
poke_interval=10,
conn_id="mail_conn_id",
timeout=10,
soft_fail=True,
box="my_box",
dag=dag,
mode="poke",
)
# Funktion zum Abrufen von Daten aus der E-Mail
def prepare_mail():
imap_hook = IMAPHook("mail_conn_id")
mail_id = imap_hook.get_last_mail(check_seen=True, box="my_box")
if mail_id is None:
raise AirflowException("Leerer Posteingang")
conn.download_mail_href_attachment(mail_id, ".\/path.zip")
prepare_mail_data = PythonOperator(task_id="prepare_mail_data", default_args=args, dag=dag, python_callable= prepare_mail)
# Beschreibung der restlichen Knoten des DAGs
...
# Verknüpfung im DAG festlegen
mail_check_sensor >> prepare_mail_data
prepare_data >> ...
# Beschreibung der restlichen SteuerflüsseÜbrigens, wenn Ihre Firmen-E-Mail ebenfalls bei mail.ru ist, steht Ihnen die Suche nach E-Mails zu Themen, Absendern usw. nicht zur Verfügung. Sie hatten bereits im Jahr 2016 versprochen, das einzuführen, aber offenbar haben sie es sich anders überlegt. Ich habe dieses Problem gelöst, indem ich einen speziellen Ordner für die benötigten E-Mails erstellt und im Web-Interface der E-Mail einen Filter für die relevanten E-Mails eingerichtet habe. So gelangen nur die gewünschten E-Mails in diesen Ordner, und die Suchbedingungen in meinem Fall sind einfach (UNSEEN).
Zusammenfassend haben wir die folgende Abfolge: Wir prüfen, ob neue E-Mails vorhanden sind, die den Bedingungen entsprechen. Wenn ja, laden wir das Archiv über den Link aus der letzten E-Mail herunter.
Unter den letzten Auslassungen wurde weggelassen, dass dieses Archiv entpackt, die Daten aus dem Archiv bereinigt und verarbeitet werden, und letztendlich wird das Ganze an die nächste Stufe des ETL-Prozesses weitergeleitet. Aber das geht bereits über den Rahmen des Artikels hinaus. Wenn es interessant und nützlich war, beschreibe ich gerne weiterhin ETL-Lösungen und deren Teile für Apache Airflow.
Quelle: habr.com
