


Der Befehl bietet Ingenieur Rahul Bhati von Clairvoyant erklärt, welche Dateiformate in Big Data existieren, welche Funktionen von Hadoop-Formaten am häufigsten sind und welches Format am besten verwendet werden sollte.
Warum gibt es verschiedene Dateiformate?
Ein ernsthaftes Engpassproblem in der Leistung von HDFS-unterstützenden Anwendungen wie MapReduce und Spark ist die Zeit für das Suchen, Lesen und Schreiben von Daten. Diese Probleme werden durch Schwierigkeiten im Umgang mit großen Datensätzen verschärft, wenn wir kein festes, sondern ein sich entwickelndes Schema haben oder wenn es Einschränkungen für die Speicherung gibt.
Die Verarbeitung von Big Data erhöht die Belastung des Speichersystems — Hadoop speichert Daten redundant, um Ausfallsicherheit zu gewährleisten. Neben den Festplatten werden auch Prozessor, Netzwerk, Ein- und Ausgabesystem und weitere Komponenten belastet. Mit dem Wachstum des Datenvolumens steigen auch die Kosten für deren Verarbeitung und Speicherung.
Verschiedene Dateiformate in wurden entwickelt, um genau diese Probleme zu lösen. Die Wahl des richtigen Dateiformats kann erhebliche Vorteile bringen:
- Schnelleres Lesezeiten.
- Schnelleres Schreibzeiten.
- Teilebare Dateien.
- Unterstützung der Evolution von Schemata.
- Erweiterte Unterstützung für Komprimierung.
Einige Dateiformate sind für den allgemeinen Gebrauch gedacht, andere für spezifischere Varianten, und einige sind für spezielle Dateneigenschaften entwickelt worden. Die Auswahl ist also tatsächlich ziemlich groß.
Avro-Dateiformat
Für Datenserialisierung Avro wird weit verbreitet genutzt — es handelt sich um ein zeilenbasiertes, also zeilenorientiertes, Datenformat für die Speicherung in Hadoop. Es speichert das Schema im JSON-Format, was das Lesen und Interpretieren durch jede Software erleichtert. Die Daten selbst liegen im binären Format vor, kompakt und effizient.
Das Avro-Serialisierungssystem ist sprachneutral. Dateien können in verschiedenen Programmiersprachen verarbeitet werden, derzeit C, C++, C#, Java, Python und Ruby.
Ein Schlüsselmerkmal von Avro ist die zuverlässige Unterstützung von Datenschemata, die sich im Laufe der Zeit ändern, also evolvieren. Avro versteht die Schemaänderungen — das Entfernen, Hinzufügen oder Ändern von Feldern.
Avro unterstützt eine Vielzahl von Datenstrukturen. Beispielsweise kann man einen Datensatz erstellen, der ein Array, einen enumerierten Typ und ein Sublayout enthält.
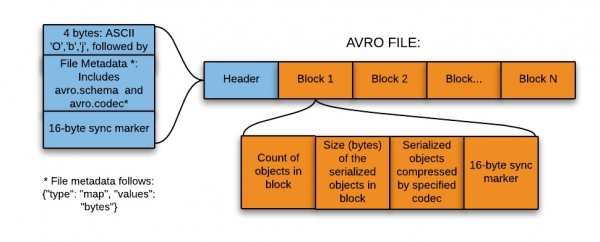
Dieses Format eignet sich hervorragend zur Speicherung im Landing (Staging) Bereich eines Data Lakes (, eine Sammlung von Instanzen zur Speicherung verschiedener Datentypen zusätzlich zu den tatsächlichen Datenquellen).
Für die Speicherung im Staging-Bereich eines Data Lakes ist dieses Format aus folgenden Gründen am besten geeignet:
- Daten aus diesem Bereich werden in der Regel vollständig für die weitere Verarbeitung durch nachgelagerte Systeme gelesen, und in diesem Fall ist das zeilenbasierte Format effizienter.
- Nachgelagerte Systeme können Schematabellen problemlos aus Dateien extrahieren – es ist nicht nötig, Schemas separat in einem externen Metastore zu speichern.
- Änderungen am ursprünglichen Schema lassen sich leicht verarbeiten (Schema-Evolution).
Das Parquet-Format
Parquet ist ein Open-Source-Dateiformat für Hadoop, das v verschachtelte Datenstrukturen in einem flachen Spaltenformat speichert..
Im Vergleich zum traditionellen zeilenbasierten Ansatz ist Parquet in Bezug auf Speicherplatz und Leistung effizienter.
Dies ist besonders nützlich für Abfragen, die bestimmte Spalten aus einer breiten Tabelle mit vielen Spalten auslesen. Dank des Dateiformats werden nur die benötigten Spalten gelesen, sodass Ein- und Ausgabe minimiert werden.
Eine kleine Exkurs-Erklärung: Um das Parquet-Dateiformat in Hadoop besser zu verstehen, schauen wir uns an, was ein spaltenbasierter, also columnar, Format ist. In diesem Format werden homogener Werte jeder Spalte zusammen gespeichert.
, der Datensatz umfasst die Felder ID, Name und Abteilung. In diesem Fall werden alle Werte der Spalte ID zusammen gespeichert, ebenso die Werte der Spalte Name und so weiter. Die Tabelle sieht etwa so aus:
ID
Name
Abteilung
1
Mitarbeiter1
d1
2
Mitarbeiter2
d2
3
Mitarbeiter3
d3
Im Zeilenformat werden die Daten folgendermaßen gespeichert:
1
Mitarbeiter1
d1
2
Mitarbeiter2
d2
3
Mitarbeiter3
d3
Im spaltenbasierten Format werden dieselben Daten so gespeichert:
1
2
3
Mitarbeiter1
Mitarbeiter2
Mitarbeiter3
d1
d2
d3
Das spaltenbasierte Format ist effizienter, wenn Sie mehrere Spalten aus einer Tabelle anfragen müssen. Es werden nur die benötigten Spalten gelesen, da sie sich nahe beieinander befinden. So werden Ein- und Ausgabe minimiert.
Zum Beispiel benötigen Sie nur die Spalte NAME. Im Jeder Datensatz im Dataset muss geladen, in Felder zerlegt und dann die NAME-Daten extrahiert werden. Das Spaltenformat ermöglicht den direkten Zugriff auf die Spalte Name, da alle Werte für diese Spalte zusammen gespeichert werden. Es ist nicht erforderlich, den gesamten Datensatz zu durchsuchen.
Das Spaltenformat erhöht somit die Abfrageleistung, da weniger Zeit für die Suche nach den benötigten Spalten erforderlich ist und die Anzahl der Ein- und Ausgabeoperationen reduziert wird, da nur die erforderlichen Spalten gelesen werden.
Eine der einzigartigen Eigenschaften ist, dass dieses Format Daten mit verschachtelten Strukturenspeichern kann. Das bedeutet, dass in einer Parquet-Datei auch verschachtelte Felder einzeln gelesen werden können, ohne dass alle Felder in der verschachtelten Struktur gelesen werden müssen. Für die Speicherung verschachtelter Strukturen verwendet Parquet den Algorithmus für Zerschlagung und Zusammenbau (shredding and assembly).
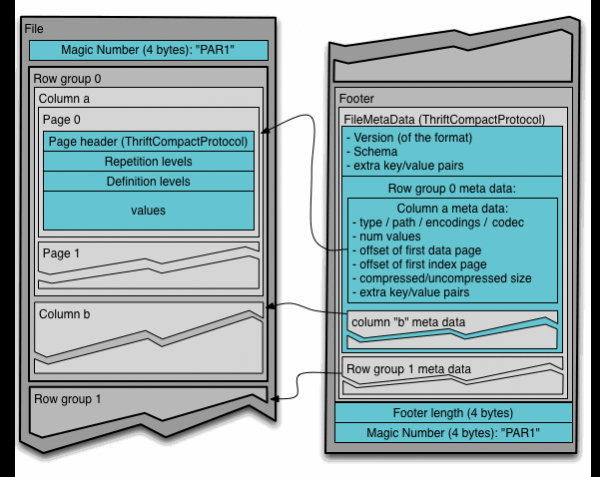
Um das Parquet-Dateiformat in Hadoop zu verstehen, müssen die folgenden Begriffe bekannt sein:
- Zeilengruppe (row group): eine logische horizontale Unterteilung der Daten in Zeilen. Eine Zeilengruppe besteht aus einem Fragment jeder Spalte im Dataset.
- Spaltenfragment (column chunk): ein spezifischer Spaltenausschnitt. Diese Spaltenfragmente leben in einer bestimmten Gruppe von Zeilen und sind im Datei garantiert benachbart.
- Seite (page): Spaltenfragmente sind auf Seiten aufgeteilt, die nacheinander aufgezeichnet sind. Seiten haben einen gemeinsamen Header, sodass beim Lesen Unnötiges übersprungen werden kann.
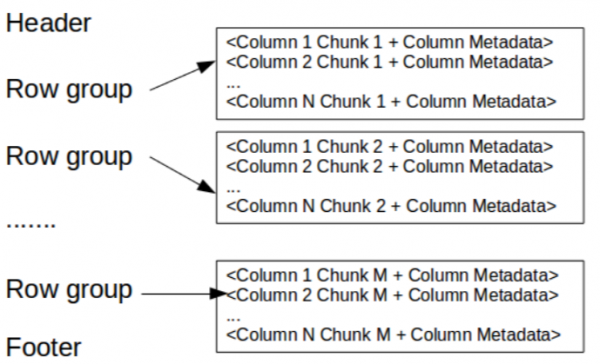
Hier enthält der Header einfach eine magische Zahl PAR1 (4 Bytes), die die Datei als eine Parquet-Datei identifizieren.
Im Footer steht Folgendes:
- Metadaten der Datei, die die Startkoordinaten der Metadaten jeder Spalte enthalten. Beim Lesen müssen zuerst die Metadaten der Datei gelesen werden, um alle interessanten Spaltenfragmente zu finden. Dann sollten die Spaltenfragmente nacheinander gelesen werden. Die Metadaten umfassen auch die Formatversion, das Schema und beliebige zusätzliche Schlüssel-Wert-Paare.
- Länge der Metadaten (4 Bytes).
- Die magische Zahl PAR1 (4 Bytes).
ORC-Dateiformate
Optimiertes zeilen- und spaltenbasiertes Dateiformat (Optimized Row Columnar, ) bietet eine sehr effiziente Möglichkeit zur Datenspeicherung und wurde entwickelt, um die Einschränkungen anderer Formate zu überwinden. Es speichert Daten in perfekt kompakter Form und lässt überflüssige Details weg, ohne dass enorme, komplexe oder wartungsintensive Indizes erstellt werden müssen.
Vorteile des ORC-Formats:
- Eine Datei pro Aufgabe, was die Last auf den NameNode (Namenszentrum) verringert.
- Unterstützung von Hive-Datentypen, einschließlich DateTime, Dezimal- und komplexen Datentypen (Struct, List, Map und Union).
- Gleichzeitiges Lesen derselben Datei durch verschiedene RecordReader-Prozesse.
- Möglichkeit der Trennung von Dateien ohne Scannen auf Marker.
- Einschätzung des maximalen Heap-Speicherplatzes für Lese-/Schreibprozesse anhand der Informationen im Footer der Datei.
- Metadaten werden im binären Format der Protocol Buffers-Serialisierung gespeichert, das das Hinzufügen und Entfernen von Feldern ermöglicht.
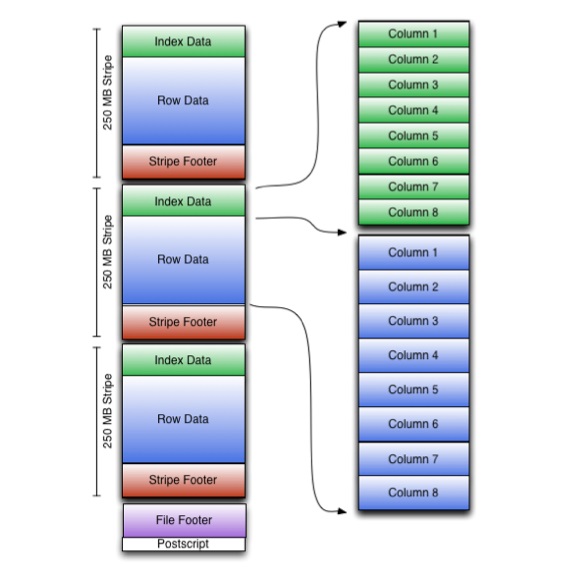
ORC speichert Sammlungen von Zeilen in einer Datei, wobei die Zeilendaten innerhalb der Sammlung im spaltenbasierten Format gespeichert werden.
Die ORC-Datei speichert Gruppen von Zeilen, die Streifen (stripes) genannt werden, sowie ergänzende Informationen im Fußbereich der Datei. Der Postscript am Ende der Datei enthält Komprimierungsparameter und die Größe des komprimierten Fußbereichs.
Standardmäßig beträgt die Größe eines Streifens 250 MB. Durch Streifen dieser Größe erfolgt das Lesen aus HDFS effizienter: in großen, kontinuierlichen Blöcken.
Im Fußbereich der Datei ist eine Liste der Streifen, die Anzahl der Zeilen pro Streifen und der Datentyp jeder Spalte aufgezeichnet. Dort sind auch die resultierenden Werte für count, min, max und sum für jede Spalte aufgeführt.
Der Fußbereich des Streifens enthält ein Verzeichnis von Standorten des Streams.
Zeilendaten werden beim Scannen von Tabellen verwendet.
Indizes enthalten die minimalen und maximalen Werte für jede Spalte sowie die Position der Zeilen in jeder Spalte. ORC-Indizes werden ausschließlich zur Auswahl von Streifen und Zeilengruppen verwendet, nicht zur Beantwortung von Abfragen.
Vergleich verschiedener Dateiformate
Avro im Vergleich zu Parquet
- Avro ist ein zeilenbasiertes Speicherformat, während Parquet Daten spaltenweise speichert.
- Parquet eignet sich besser für analytische Abfragen, das heißt, Lese- und Datenabfrageoperationen sind wesentlich effizienter als Schreibvorgänge.
- Die Schreibvorgänge in Avro sind effizienter als in Parquet.
- Avro funktioniert reifer mit der Schema-Evolution. Parquet unterstützt nur das Hinzufügen von Schemas, während Avro eine vielseitige Evolution ermöglicht, d.h. das Hinzufügen oder Ändern von Spalten.
- Parquet eignet sich ideal für die Abfrage einer Teilmenge von Spalten in einer mehrspaltigen Tabelle. Avro hingegen ist für ETL-Vorgänge geeignet, bei denen wir alle Spalten abfragen.
ORC im Vergleich zu Parquet
- Parquet speichert verschachtelte Daten besser.
- ORC ist besser geeignet für Predicate Pushdown.
- ORC unterstützt ACID-Eigenschaften.
- ORC komprimiert Daten besser.
Weitere Lesetipps zu diesem Thema:
- .
- .
- .
Quelle: habr.com
