


Hallo, Leser von Habr. Mit diesem Artikel beginnen wir eine Serie, die von unserem hyperkonvergenten System AERODISK vAIR erzählt. Ursprünglich wollten wir in unserem ersten Artikel alles im Detail erklären, doch das System ist recht komplex, daher werden wir den Elefanten Stück für Stück essen.
Wir beginnen die Geschichte mit der Entstehung des Systems, vertiefen uns in das ARDFS-Dateisystem, das die Grundlage von vAIR bildet, und diskutieren auch kurz die Positionierung dieser Lösung auf dem russischen Markt.
In den kommenden Artikeln werden wir ausführlicher über die verschiedenen architektonischen Komponenten (Cluster, Hypervisor, Lastenausgleich, Überwachungssystem usw.), den Einrichtungsprozess berichten, Lizenzierungsfragen ansprechen, Crash-Tests separat präsentieren und natürlich über Lasttests und Sizing schreiben. Zudem werden wir einen eigenen Artikel der Community-Version von vAIR widmen.
AERODISK – ist das etwa eine Geschichte über Speichersysteme? Oder warum haben wir überhaupt mit hyperkonvergenten Lösungen begonnen?
Die ursprüngliche Idee, unsere eigene hyperkonvergente Lösung zu entwickeln, entstand etwa im Jahr 2010. Zu diesem Zeitpunkt gab es weder Aerodisk noch ähnliche Lösungen (kommerzielle, verpackte hyperkonvergente Systeme) auf dem Markt. Unsere Aufgabe war es, aus einer Gruppe von Servern mit lokalen Festplatten, die über Ethernet-Protokoll miteinander verbunden waren, ein verteiltes Speicher-Array zu schaffen und darauf virtuelle Maschinen und ein Software-Netzwerk laufen zu lassen. All dies musste ohne ein SAN realisiert werden (da wir einfach kein Geld für ein SAN und dessen Anbindung hatten und unser eigenes SAN damals noch nicht erfunden war).
Wir haben viele Open-Source-Lösungen ausprobiert und schließlich diese Aufgabe gelöst, aber die Lösung war sehr komplex und schwer zu reproduzieren. Darüber hinaus war diese Lösung mehr oder weniger ein „Es funktioniert? Fass es nicht an!“. Daher haben wir, nachdem wir diese Aufgabe gelöst hatten, die Idee, das Ergebnis unserer Arbeit in ein vollwertiges Produkt zu verwandeln, nicht weiter verfolgt.
Nach diesem Vorfall haben wir von dieser Idee Abstand genommen, aber uns blieb das Gefühl, dass diese Aufgabe durchaus lösbar ist und der Nutzen einer solchen Lösung mehr als offensichtlich ist. Später bestätigten die auf den Markt kommenden HCI-Produkte ausländischer Unternehmen dieses Gefühl nur noch.
Daher haben wir Mitte 2016 an dieser Aufgabe gearbeitet, um ein vollwertiges Produkt zu schaffen. Zu diesem Zeitpunkt hatten wir noch keine Beziehungen zu Investoren, weshalb wir den Entwicklungststand aus eigenen geringen Mitteln finanzieren mussten. Wir kauften gebrauchte Server und Switches über Avito und legten los.

Die Hauptanfangsaufgabe bestand darin, ein einfaches, aber eigenes Dateisystem zu entwickeln, das Daten automatisch und gleichmäßig in Form von virtuellen Blöcken auf einer beliebigen Anzahl von Knoten im Cluster verteilt, die über Ethernet miteinander verbunden sind. Dabei sollte das Dateisystem gut und einfach skalierbar sein und unabhängig von benachbarten Systemen, d.h. von vAIR als bloßer Speicherlösung abtrennbar sein.
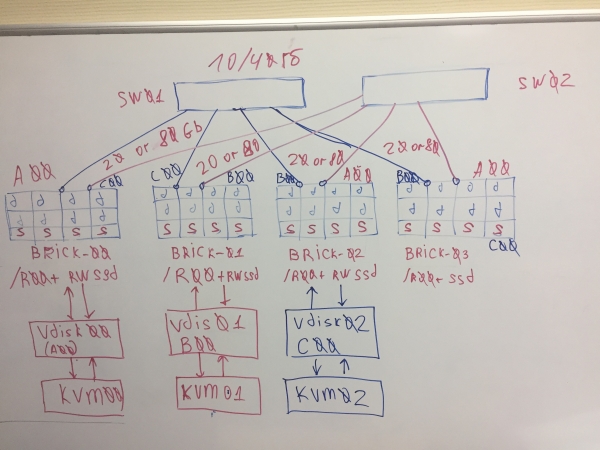
Das erste Konzept von vAIR

Wir haben absichtlich darauf verzichtet, fertige Open-Source-Lösungen für den Aufbau eines verteilten Speichers (wie Ceph, Gluster, Lustre und ähnliches) zu verwenden, und stattdessen auf unsere eigene Entwicklung gesetzt, da wir bereits viel Projekterfahrung damit hatten. Diese Lösungen sind zweifellos an sich hervorragend, und wir haben vor der Arbeit an Aerodisc mehrere Integrationsprojekte damit umgesetzt. Aber es ist ein Unterschied, eine spezifische Aufgabe eines Kunden zu lösen, das Personal zu schulen und möglicherweise den Support eines großen Anbieters einzukaufen, und eine leicht reproduzierbare Lösung zu schaffen, die für verschiedene Aufgaben verwendet wird, von denen wir als Anbieter möglicherweise nicht einmal Kenntnis haben. Für dieses zweite Ziel waren bestehende Open-Source-Produkte für uns nicht geeignet, weshalb wir uns entschlossen haben, ein verteiltes Dateisystem selbst zu entwickeln.
Nach zwei Jahren harter Arbeit mehrerer Entwickler (die die Arbeiten an vAIR mit der Entwicklung der klassischen Storage Engine kombinierten) wurden bestimmte Ergebnisse erzielt.
Bis 2018 hatten wir ein einfaches Dateisystem entwickelt und mit den notwendigen Bindings ergänzt. Das System verband über interne Interconnects physische (lokale) Festplatten von verschiedenen Servern zu einem flachen Pool und "schnitt" sie in virtuelle Blöcke, aus denen dann blockbasierte Geräte mit unterschiedlich hohem Fehlerschutz erstellt wurden, auf denen mit dem Hypervisor KVM virtuelle Maschinen erstellt und betrieben wurden.
Bei der Benennung des Dateisystems haben wir uns nicht großartig angestrengt und haben es schlicht ARDFS genannt (erraten Sie, wofür das steht))
Dieser Prototyp sah gut aus (nicht visuell, natürlich gab es damals noch keine visuelle Gestaltung) und zeigte eine gute Leistung sowie Skalierbarkeit. Nach den ersten realen Ergebnissen gaben wir diesem Projekt grünes Licht, organisierten eine vollwertige Entwicklungsumgebung und ein separates Team, das sich nur um vAIR kümmerte.
Zu dieser Zeit reifte die allgemeine Architektur der Lösung, die bis heute keine nennenswerten Änderungen erfahren hat.
Lasst uns in das Dateisystem ARDFS eintauchen.
ARDFS ist die Grundlage von vAIR, das eine verteilte fehlertolerante Datenspeicherung für das gesamte Cluster bietet. Eines der (aber nicht das einzige) Unterscheidungsmerkmale von ARDFS ist, dass es keine zusätzlichen dedizierte Server Metadaten oder Verwaltung verwendet. Dies wurde ursprünglich zur Vereinfachung der Konfiguration der Lösung und zur Zuverlässigkeit konzipiert.
Speicherstruktur
Im Rahmen aller Knoten des Clusters organisiert ARDFS einen logischen Pool des gesamten verfügbaren Speicherplatzes. Es ist wichtig zu verstehen, dass der Pool noch keine Daten und keinen formatierten Speicher darstellt, sondern lediglich eine Markierung. Das bedeutet, dass alle Knoten mit installiertem vAIR beim Hinzufügen zum Cluster automatisch zum gemeinsamen Pool von ARDFS hinzugefügt werden und die Speicherkapazitäten automatisch für das gesamte Cluster gemeinsam genutzt werden (und für die zukünftige Datenspeicherung verfügbar sind). Dieser Ansatz ermöglicht es, Knoten im laufenden Betrieb ohne nennenswerte Auswirkungen auf das bereits laufende System hinzuzufügen oder zu entfernen. Das heißt, das System ist sehr einfach in „Ziegeln“ skalierbar, indem Knoten bei Bedarf zum Cluster hinzugefügt oder entfernt werden.
Über dem ARDFS-Pool werden virtuelle Festplatten (Speicherobjekte für virtuelle Maschinen) hinzugefügt, die aus virtuellen Blöcken mit einer Größe von 4 Megabyte bestehen. Die Daten werden direkt auf den virtuellen Festplatten gespeichert. Auf der Ebene der virtuellen Festplatten wird auch das Konzept der Fehlertoleranz festgelegt.
Wie bereits vermutet, verwenden wir für die Fehlertoleranz des Festplattensystems nicht das Konzept von RAID (Redundant Array of Independent Disks), sondern RAIN (Redundant Array of Independent Nodes). Das bedeutet, dass die Fehlertoleranz anhand der Knoten und nicht der Festplatten gemessen, automatisiert und verwaltet wird. Festplatten sind natürlich auch Speicherobjekte, sie werden wie alles andere überwacht, und es können alle Standardoperationen durchgeführt werden, einschließlich der Erstellung eines lokalen Hardware-RAID, aber der Cluster operiert genau mit Knoten.
In Situationen, in denen RAID sehr begehrt ist (zum Beispiel ein Szenario, das multiple Ausfälle in kleinen Clustern unterstützt), steht der Nutzung von lokalen RAID-Controllern nichts im Weg. Darüber hinaus kann ein verteiltes Speicher- und RAIN-Architektur verwendet werden. Solche Szenarien sind durchaus praktikabel und werden von uns unterstützt, weshalb wir in einem Artikel über typische Anwendungsszenarien von vAIR darüber berichten werden.
Schemen der Ausfallsicherheit für Speicher
Es können zwei Schemen der Ausfallsicherheit virtueller Festplatten in vAIR vorkommen:
1) Replikationsfaktor oder einfach Replikation – diese Methode der Ausfallsicherheit ist so einfach "wie Stock und Schnur". Es findet eine synchrone Replikation zwischen den Nodes mit einem Faktor von 2 (2 Kopien im Cluster) oder 3 (3 Kopien) statt. RF-2 ermöglicht es dem virtuellen Disk, den Ausfall eines Nodes im Cluster zu überstehen, beansprucht jedoch die Hälfte des nutzbaren Volumens. RF-3 hingegen kann den Ausfall von 2 Nodes im Cluster überstehen, reserviert jedoch 2/3 des nützlichen Volumens für sich selbst. Dieses Schema ähnelt stark RAID-1, was bedeutet, dass ein virtueller Disk, der auf RF-2 konfiguriert ist, gegenüber dem Ausfall eines beliebigen Nodes im Cluster resistent ist. In diesem Fall sind die Daten sicher, und auch der Ein- und Ausgang werden nicht gestoppt. Sobald der ausgefallene Node wieder online ist, beginnt die automatische Wiederherstellung/Synchronisation der Daten.
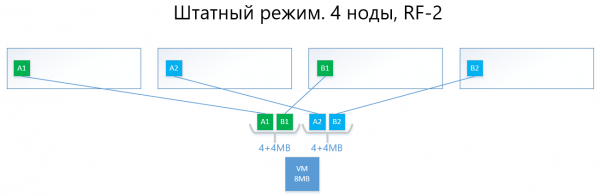
Im Folgenden sind Beispiele für die Verteilung von Daten in RF-2 und RF-3 sowohl im Normalbetrieb als auch im Falle von Ausfällen aufgeführt.
Wir haben eine virtuelle Maschine mit 8 MB einzigartigen (nützlichen) Daten, die auf 4 vAIR-Knoten läuft. Es ist klar, dass in der Realität so wenig Speicher kaum vorkommen wird, aber für ein Schema, das die Funktionsweise von ARDFS widerspiegelt, ist dieses Beispiel am besten verständlich. AB sind virtuelle Blöcke mit je 4 MB, die einzigartige Daten der virtuellen Maschine enthalten. Bei RF-2 werden zwei Kopien dieser Blöcke A1+A2 und B1+B2 erstellt. Diese Blöcke werden auf die Knoten verteilt, um zu vermeiden, dass dieselben Daten auf einem Knoten liegen, d.h. die Kopie A1 wird nicht auf demselben Knoten wie die Kopie A2 sein. Das Gleiche gilt für B1 und B2.
Im Falle eines Ausfalls eines der Knoten (zum Beispiel Knoten Nr. 3, wo die Kopie B1 gespeichert ist), wird diese Kopie automatisch auf dem Knoten aktiviert, auf dem keine Kopie ihrer Kopie (d.h. der Kopie B2) vorhanden ist.
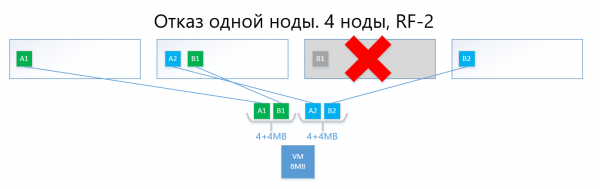
Somit übersteht die virtuelle Festplatte (und die VM dementsprechend) den Ausfall eines Knotens im RF-2-Schema problemlos.
Das Schema mit Replikation leidet trotz seiner Einfachheit und Zuverlässigkeit an demselben Problem wie RAID1 – es bietet wenig nutzbaren Speicherplatz.
2) Erasure Coding oder Löschkodierung (auch bekannt als „Redundanzkodierung“, „löschen Kodierung“ oder „Redundanzcode“) existiert genau zur Lösung des oben genannten Problems. EC ist ein Redundanzschema, das eine hohe Datenverfügbarkeit bei geringeren Speicherplatzkosten im Vergleich zur Replikation gewährleistet. Das Funktionsprinzip dieses Mechanismus ähnelt RAID 5, 6, 6P.
Bei der Kodierung teilt der EC-Prozess einen virtuellen Block (standardmäßig 4 MB) in mehrere kleinere „Datenstücke“ auf, abhängig vom EC-Schema (zum Beispiel teilt das 2+1-Schema jeden 4 MB Block in 2 Stücke von je 2 MB). Anschließend generiert dieser Prozess für die „Datenstücke“ „Paritätsstücke“, die nicht größer sind als eines der zuvor geteilten Teile. Bei der Dekodierung generiert EC die fehlenden Stücke, indem es die „überlebenden“ Daten im gesamten Cluster liest.
Zum Beispiel kann ein virtueller Datenträger mit dem EC-Schema 2 + 1, das auf 4 Knoten eines Clusters implementiert ist, den Ausfall eines Knotens im Cluster problemlos verkraften, genauso wie RF-2. Dabei sind die Kosten geringer, insbesondere liegt der Nutzungsgrad bei RF-2 bei 2, während er bei EC 2+1 bei 1,5 liegt.
Einfacher ausgedrückt, besteht das Prinzip darin, dass der virtuelle Block in 2 bis 8 (warum 2 bis 8, wird weiter unten erklärt) "Stücke" unterteilt wird, für die Paritätsstücke ähnlicher Größe berechnet werden.
Die Daten und die Parität werden gleichmäßig auf alle Knoten des Clusters verteilt. Dabei verteilt ARDFS die Daten automatisch auf die Knoten, ähnlich wie bei der Replikation, so dass identische Daten (Datenkopien und deren Parität) auf einem Knoten nicht gespeichert werden, um das Risiko zu vermeiden, Daten zu verlieren, weil sowohl die Daten als auch deren Parität unerwartet auf demselben Speicherknoten gespeichert werden, der ausfällt.
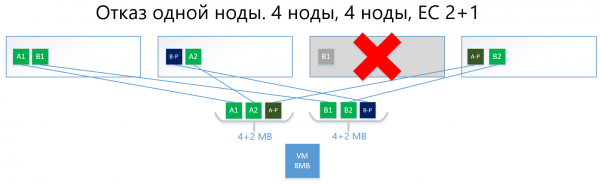
Im Folgenden ein Beispiel mit demselben Virtual Machine von 8 MB und 4 Knoten, jedoch bereits mit dem EC-Schema 2+1.
Die Blöcke A und B werden in zwei Stücke von jeweils 2 MB aufgeteilt (auf zwei, weil 2+1), d.h. in A1+A2 und B1+B2. Im Gegensatz zur Replik ist A1 keine Kopie von A2, sondern ein virtueller Block A, der in zwei Teile getrennt wurde, ebenso wie Block B. Insgesamt erhalten wir zwei Sätze zu je 4 MB, in denen sich jeweils zwei 2-MB-Stücke befinden. Außerdem wird für jeden dieser Sätze die Parität mit einem Volumen von nicht mehr als einem Stück (d.h. 2 MB) berechnet, was zusätzlich + 2 Paritätsstücke (A-P und B-P) ergibt. Damit haben wir insgesamt 4×2 Daten + 2×2 Parität.
Die Stücke werden dann so auf die Knoten verteilt, dass die Daten nicht mit ihrer Parität überlappen. Das heißt, A1 und A2 werden nicht auf demselben Knoten mit A-P liegen.
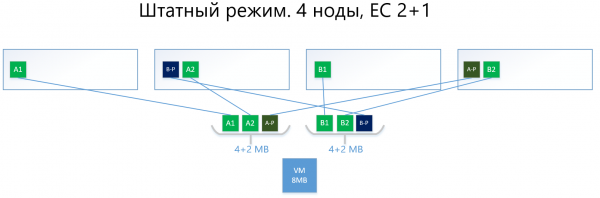
Im Falle eines Ausfalls eines Knotens (nehmen wir an, des dritten) wird der ausgefallene Block B1 automatisch aus der Parität B-P wiederhergestellt, die auf Knoten Nr. 2 gespeichert ist, und auf dem Knoten aktiviert, wo es keine B-Parität, d.h. kein Stück B-P gibt. In diesem Beispiel ist das Knoten Nr. 1.
Ich bin mir sicher, dass der Leser die Frage hat:
„Alles, was Sie beschrieben haben, wurde bereits von Mitbewerbern und in Open-Source-Lösungen umgesetzt. Was unterscheidet Ihre Implementierung von EC in ARDFS?“
Und nun werden interessante Funktionen von ARDFS folgen.
Erasure Coding mit dem Fokus auf Flexibilität.
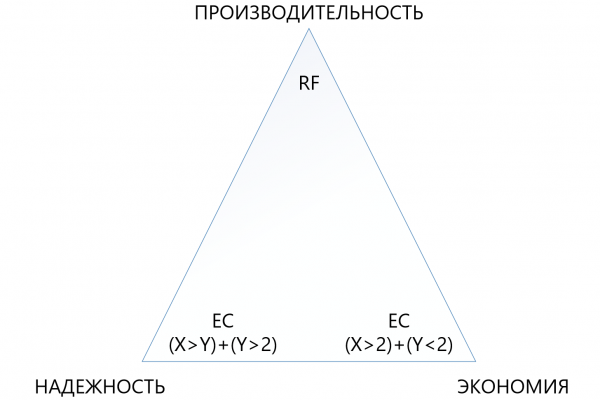
Ursprünglich haben wir ein recht flexibles EC X+Y-Schema vorgesehen, wobei X eine Zahl von 2 bis 8 und Y eine Zahl von 1 bis 8 entspricht, jedoch stets kleiner oder gleich X ist. Dieses Schema ist für Flexibilität konzipiert. Die Erhöhung der Datenstückzahlen (X), in die der virtuelle Block unterteilt wird, führt zu geringeren Overheadkosten, was bedeutet, dass der nutzbare Speicherplatz steigt.
Die Erhöhung der Paritätsstückzahlen (Y) verbessert die Zuverlässigkeit des virtuellen Laufwerks. Je höher der Wert von Y ist, desto mehr Knoten im Cluster können ausfallen. Natürlich reduziert die Erhöhung des Paritätsvolumens die nutzbare Kapazität, aber das ist der Preis für Zuverlässigkeit.
Die Abhängigkeit der Leistung von den EC-Schemata ist fast linear: Je mehr „Stücke“ vorhanden sind, desto niedriger ist die Leistung, hier ist ein ausgewogenes Urteil erforderlich.
Dieser Ansatz ermöglicht es Administratoren, den verteilten Speicher maximal flexibel zu konfigurieren. Innerhalb des ARDFS-Pools können beliebige Hochverfügbarkeits-Schemata und deren Kombinationen verwendet werden, was wir ebenfalls als sehr nützlich erachten.
Nachfolgend finden Sie eine Vergleichstabelle mehrerer (nicht aller möglichen) RF- und EC-Schemata.
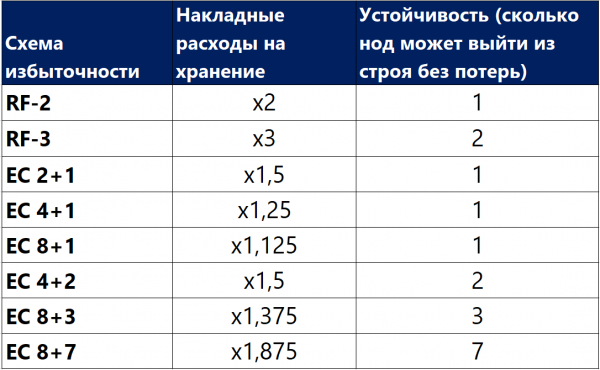
Die Tabelle zeigt, dass selbst die "extremste" Kombination EC 8+7, die den gleichzeitigen Verlust von bis zu 7 Knoten im Cluster zulässt, weniger nützlichen Raum beansprucht (1,875 gegenüber 2) als die Standardreplikation und gleichzeitig siebenmal besser schützt. Dies macht diesen Schutzmechanismus zwar komplexer, aber deutlich attraktiver in Situationen, in denen maximale Zuverlässigkeit bei begrenztem Speicherplatz erforderlich ist. Dabei ist zu beachten, dass jeder „Pluspunkt“ für X oder Y zusätzliche Leistungskosten verursacht, sodass zwischen Zuverlässigkeit, Sparsamkeit und Leistung sehr sorgfältig abgewogen werden muss. Aus diesem Grund widmen wir einen separaten Artikel dem Sizing der Löschcodierung.
Zuverlässigkeit und Autonomie des Dateisystems
ARDFS wird lokal auf allen Knoten des Clusters gestartet und synchronisiert sie eigenständig über dedizierte Ethernet-Schnittstellen. Ein wichtiger Punkt ist, dass ARDFS nicht nur die Daten, sondern auch die Metadaten, die mit der Speicherung verbunden sind, selbstständig synchronisiert. Während der Entwicklung von ARDFS haben wir parallel eine Reihe bestehender Lösungen untersucht und festgestellt, dass viele die Synchronisierung der Metadaten des Dateisystems mithilfe externer verteilten Datenbankmanagementsysteme durchführen. Diese verwenden wir ebenfalls für die Synchronisierung, aber nur für Konfigurationen und nicht für die Metadaten des Dateisystems (über dieses und andere verwandte Subsysteme wird im nächsten Artikel berichtet).
Die Synchronisierung der Metadaten des Dateisystems mit einer externen Datenbankmanagementsystem ist selbstverständlich eine funktionierende Lösung, jedoch würde dadurch die Konsistenz der auf ARDFS gespeicherten Daten von der externen Datenbank und ihrem Verhalten abhängen (und die ist, um es vorsichtig auszudrücken, eine launische Dame), was unserer Meinung nach schlecht ist. Warum? Wenn die Metadaten des Dateisystems beschädigt werden, können wir uns auch von den eigentlichen Daten des Dateisystems verabschieden. Deshalb haben wir uns entschieden, einen komplexeren, aber zuverlässigeren Weg zu gehen.
Das Metadaten-Synchronisationssystem für ARDFS haben wir selbst entwickelt, und es funktioniert völlig unabhängig von angrenzenden Subsystemen. Das heißt, kein anderes Subsystem kann die ARDFS-Daten gefährden. Nach unserer Ansicht ist dies der zuverlässigste und richtige Weg, ob es tatsächlich so ist, wird die Zukunft zeigen. Zusätzlich bringt dieser Ansatz einen weiteren Vorteil mit sich. ARDFS kann unabhängig von vAIR verwendet werden, einfach als erweiterbarer Speicher, was wir definitiv in zukünftigen Produkten nutzen werden.
Durch die Entwicklung von ARDFS haben wir ein flexibles und zuverlässiges Dateisystem geschaffen, das die Wahl bietet, ob man bei der Speicherkapazität sparen oder die gesamte Leistung aufdrehen möchte, oder ein extrem zuverlässiges Speichermedium zu einem moderaten Preis anstreben kann, jedoch mit reduzierten Leistungsanforderungen.
Zusammen mit einer einfachen Lizenzpolitik und einem flexiblen Bereitstellungsmodell (um es vorwegzunehmen, vAIR wird nach Knoten lizenziert und entweder als Software oder als PAK bereitgestellt) ermöglicht dies, die Lösung sehr genau auf die unterschiedlichsten Anforderungen der Kunden zuzuschneiden und dieses Gleichgewicht künftig leicht zu halten.
Wer braucht dieses Wunder?
Einerseits kann man sagen, dass es auf dem Markt bereits Akteure gibt, die ernsthafte Lösungen im Bereich Hyperkonvergenz anbieten, und dass wir uns daher in einem wettbewerbsintensiven Umfeld bewegen. Diese Aussage scheint zutreffend zu sein, ABER…
Andererseits, wenn wir „ins Feld“ gehen und mit Kunden sprechen, sehen wir und unsere Partner, dass das ganz anders ist. Es gibt viele Aufgaben für Hyperkonvergenz, wobei manchen Menschen schlicht nicht bekannt ist, dass solche Lösungen existieren, andere glauben, dass sie zu teuer sind, wieder andere hatten negative Erfahrungen mit alternativen Lösungen, und in einigen Fällen sind Käufe aufgrund von Sanktionen ganz verboten. Insgesamt stellte sich das Feld als ungenutzt heraus, weshalb wir uns entschieden haben, die Pionierarbeit zu leisten.)
Wann ist eine SAN besser als eine HCI?
Während unserer Arbeit mit dem Markt werden wir häufig gefragt, wann man das klassische SAN-Modell und wann die Hyperkonvergenz anwenden sollte. Viele Unternehmen, die HCI-Produkte herstellen (insbesondere diejenigen, die keine SAN-Lösungen im Portfolio haben), behaupten: „SAN hat ausgedient, nur Hyperkonvergenz!“. Diese gewagte Aussage spiegelt jedoch nicht ganz die Realität wider.
Ehrlich gesagt, bewegt sich der SAN-Markt tatsächlich in Richtung Hyperkonvergenz und ähnlicher Lösungen, aber es gibt immer ein „aber“.
Erstens lassen sich die aufgebauten Rechenzentren und IT-Infrastrukturen nach dem klassischen Schema mit SAN nicht einfach umstellen, deshalb ist die Modernisierung und der Ausbau solcher Infrastrukturen ein Erbe von etwa 5 bis 7 Jahren.
Zweitens werden derzeit die meisten Infrastrukturen (gemeint ist Russland) nach dem klassischen Schema mit Einsatz von SAN gebaut, und nicht weil die Leute nichts von hyperkonvergenten Lösungen wissen, sondern weil der Markt für hyperkonvergente Systeme neu ist, die Lösungen und Standards noch nicht fest etabliert sind, IT-Fachleute noch nicht geschult sind und wenig Erfahrung vorhanden ist; Rechenzentren müssen hier und jetzt gebaut werden. Dieser Trend wird noch 3 bis 5 Jahre anhalten (und danach bleibt erneut ein Erbe, siehe Punkt 1).
Drittens gibt es rein technische Einschränkungen durch zusätzliche kleine Latenzen von 2 Millisekunden beim Schreiben (ohne lokalen Cache, versteht sich), die den Preis für verteiltes Speichern darstellen.
Und vergessen wir nicht den Einsatz großer physischer Server, die vertikale Skalierung des Speichersystems bevorzugen.
Es gibt viele relevante und beliebte Aufgaben, in denen HCI besser funktioniert als die traditionelle Infrastruktur. Natürlich werden die Hersteller, die keine HCI in ihrem Produktportfolio haben, dem nicht zustimmen, aber wir sind bereit, dies fundiert zu diskutieren. Selbstverständlich werden wir als Entwickler beider Produkte in einer zukünftigen Veröffentlichung einen Vergleich zwischen HCI und traditioneller Infrastruktur durchführen, in dem wir anschaulich demonstrieren, unter welchen Bedingungen was besser ist.
In welchen Bereichen werden hyperkonvergente Lösungen besser funktionieren als HCI?
Basierend auf den obigen Thesen lassen sich drei offensichtliche Schlussfolgerungen ziehen:
- Dort, wo zusätzliche 2 Millisekunden Schreibverzögerung, die in jeder produktiven Umgebung konstant auftreten (hier geht es nicht um synthetische Tests, denn in synthetischen Tests können auch Nanosekunden gezeigt werden), nicht kritisch sind, ist HCI geeignet.
- Dort, wo die Last von großen physischen Servern in viele kleine virtuelle Server umgewandelt und auf Knoten verteilt werden kann, funktioniert HCI ebenfalls gut.
- Dort, wo horizontale Skalierung wichtiger ist als vertikale, wird HCI ebenfalls hervorragend eingesetzt.
Was sind diese Lösungen?
- Alle Standard-Infrastruktur-Dienste (Verzeichnisdienste, E-Mail, Dokumentenmanagement, Dateiserver, kleine oder mittlere ERP- und BI-Systeme usw.). Wir nennen das "gemeinsame Berechnungen".
- Infrastruktur von Cloud-Anbietern, wo eine schnelle und standardisierte horizontale Skalierung erforderlich ist und eine große Anzahl von virtuellen Maschinen für Kunden einfach "bereitgestellt" werden kann.
- Infrastruktur virtuellen Arbeitsflächen (VDI), wo viele kleine Benutzer-Virtualisierungen gestartet werden und ruhig innerhalb eines einheitlichen Clusters "schwimmen".
- Filialnetzwerke, bei denen in jeder Filiale eine standardisierte, ausfallsichere, aber dennoch kostengünstige Infrastruktur aus 15-20 virtuellen Maschinen benötigt wird.
- Alle verteilten Berechnungen (z. B. Big Data-Dienste). Dort, wo die Last nicht "vertikal", sondern "horizontal" geht.
- Testumgebungen, in denen zusätzliche kleine Verzögerungen toleriert werden können, aber Budgetbeschränkungen bestehen, da es sich um Tests handelt.
Aktuell haben wir AERODISK vAIR speziell für diese Aufgaben entwickelt und konzentrieren uns darauf (bislang erfolgreich). Möglicherweise wird sich das bald ändern, da die Welt sich nicht stillsteht.
Also…
Der erste Teil des umfangreichen Artikelzyklus ist hiermit abgeschlossen. Im nächsten Artikel werden wir über die Architektur der Lösung und die verwendeten Komponenten berichten.
Wir freuen uns über Fragen, Vorschläge und konstruktive Diskussionen.
Quelle: habr.com
