

Hallo Hubber. Wie gewohnt teilen wir spannende Inhalte in der Vorfreude auf die neuen Kurse. Heute haben wir speziell für Sie einen Artikel über Google Cloud Spanner übersetzt, der die Einführung unseres Kurses begleitet. .

Ursprünglich veröffentlicht in .
Als Unternehmen, das eine Vielzahl von Cloud-POS-Lösungen für Einzelhändler, Gastronomen und Online-Verkäufer weltweit anbietet, verwendet Lightspeed verschiedene Arten von Datenbankplattformen für zahlreiche transaktionale, analytische und Suchanwendungen. Jede dieser Datenbankplattformen hat ihre eigenen Stärken und Schwächen. Als Google Cloud Spanner mit vielversprechenden Funktionen auf den Markt kam, die in der Welt relationaler Datenbanken bislang unbekannt waren – wie nahezu unbegrenzte horizontale Skalierbarkeit und ein SLA von 99,999 % – konnten wir uns die Gelegenheit nicht entgehen lassen, es in unsere Hände zu bekommen!
Um Ihnen einen umfassenden Überblick über unsere Erfahrungen mit Cloud Spanner sowie die Bewertungsmaßstäbe, die wir verwendet haben, zu geben, betrachten wir die folgenden Themen:
- Unsere Bewertungsmaßstäbe
- Cloud Spanner in Kürze
- Unsere Bewertung
- Unsere Schlussfolgerungen

1. Unsere Bewertungsmaßstäbe
Bevor wir uns mit den Besonderheiten von Cloud Spanner sowie deren Gemeinsamkeiten und Unterschieden zu anderen Lösungen auf dem Markt befassen, lassen Sie uns zunächst die Hauptanwendungsfälle besprechen, die wir im Zusammenhang mit der Bereitstellung von Cloud Spanner in unserer Infrastruktur betrachtet haben:
- Als Ersatz für (das dominante) traditionelle SQL-Datenbanklösungen
- Als OLTP-Lösung mit OLAP-Unterstützung
Hinweis: Zur Vereinfachung und besseren Vergleichbarkeit vergleicht dieser Artikel Cloud Spanner mit MySQL-Varianten aus den GCP Cloud SQL-Familien und Amazon AWS RDS.
Einsatz von Cloud Spanner als Ersatz für traditionelle SQL-Datenbanklösungen
In einer Umgebung traditioneller Datenbanken, wenn die Antwortzeiten auf Datenbankanfragen die festgelegten Schwellenwerte der Anwendung erreichen oder sogar überschreiten (hauptsächlich aufgrund einer steigenden Anzahl von Benutzern und/oder Anfragen), gibt es verschiedene Ansätze, um die Antwortzeiten auf ein akzeptables Niveau zu senken. Die meisten dieser Lösungen erfordern jedoch manuelles Eingreifen.
Ein erster Schritt besteht darin, die verschiedenen Leistungsparameter der Datenbank zu überprüfen und sie so anzupassen, dass sie optimal zu den Anwendungsszenarien passen. Wenn dies nicht ausreicht, kann man sich für vertikales oder horizontales Scaling der Datenbank entscheiden.
Beim vertikalen Skalieren einer Anwendung wird die Serverinstanz normalerweise durch das Hinzufügen von mehr Prozessoren/Kernen, mehr RAM, schnellerem Speicher usw. aktualisiert. Durch die Hinzufügung weiterer Hardware-Ressourcen wird die Datenbankleistung erhöht, typischerweise gemessen an der Anzahl der Transaktionen pro Sekunde sowie der Transaktionslatenz für OLTP-Systeme. Relationale Datenbanksysteme, die einen Multi-Threading-Ansatz verwenden, wie MySQL, skalieren gut vertikal.
Dieser Ansatz hat einige Nachteile, aber der offensichtlichste ist die maximale Servergröße auf dem Markt. Sobald die Grenze des größten Server-Instances erreicht ist, bleibt nur noch der Weg des horizontalen Skalierens.
Horizontales Skalieren ist ein Ansatz, bei dem weitere Server zum Cluster hinzugefügt werden, um idealerweise die Leistung linear mit der Anzahl der Server zu steigern. Die meisten traditioneller Datenbanksysteme skalieren schlecht horizontal oder gar nicht. Zum Beispiel kann MySQL für Leseoperationen horizontal skalieren, indem slave-Reader hinzugefügt werden, aber nicht für Schreiboperationen.
Auf der anderen Seite kann Cloud Spanner aufgrund seiner Natur problemlos horizontal mit minimalem Aufwand skalieren.
Vollwertige Datenbank als Dienst sollte aus verschiedenen Perspektiven bewertet werden. Als Grundlage haben wir die beliebteste Cloud-Datenbank genommen – Google, GCP Cloud SQL und für Amazon, AWS RDS. In unserer Bewertung haben wir uns auf folgende Kategorien konzentriert:
- Feature-Vergleich: SQL-Extent, DDL, DML; Verbindungsbibliotheken/Kontaktoren, Unterstützung für Transaktionen und mehr.
- Entwicklungsunterstützung: Einfachheit in der Entwicklung und im Testen.
- Administrationsunterstützung: Verwaltung von Instanzen – etwa Hoch- und Herunterskalierung sowie Upgrade von Instanzen; SLA, Backup und Wiederherstellung; Sicherheit/Zugriffskontrolle.
Nutzung von Cloud Spanner als OLTP-Lösung mit OLAP-Unterstützung
Obwohl Google nicht ausdrücklich behauptet, dass Cloud Spanner für analytische Verarbeitung gedacht ist, teilt es einige Attribute mit anderen Mechanismen wie Apache Impala & Kudu und YugaByte, die für OLAP-Workloads konzipiert sind.
Selbst wenn es nur eine geringe Wahrscheinlichkeit gäbe, dass Cloud Spanner eine konsistente, horizontal skalierbare HTAP-Engine (Hybrid Transactional/Analytical Processing) mit einem (mehr oder weniger) brauchbaren Funktionsset für OLAP integriert hat, glauben wir, dass dies unsere Aufmerksamkeit verdient.
In diesem Sinne haben wir die folgenden Kategorien betrachtet:
- Datenladen, Indizes und Unterstützung für Partitionierung
- Abfrageleistung und DML
2. Cloud Spanner in Kürze
Google Spanner ist ein verteiltes relationales Datenbankmanagementsystem (RDBMS), das Google für mehrere seiner eigenen Dienste verwendet. Google hat es Anfang 2017 für Nutzer der Google Cloud Platform öffentlich zugänglich gemacht.
Hier sind einige der Eigenschaften von Cloud Spanner:
- Stark konsistente, skalierbare RDBMS-Cluster: Nutzt hardwarebasierte Zeitsynchronisation zur Gewährleistung der Datenkonsistenz.
- Unterstützung für transaktionale Operationen über mehrere Tabellen hinweg: Transaktionen können mehrere Tabellen einbeziehen und sind nicht auf eine einzige Tabelle beschränkt (im Gegensatz zu Apache HBase oder Apache Kudu).
- Tabellen basierend auf Primärschlüsseln: Alle Tabellen müssen einen definierten Primärschlüssel (PK) aufweisen, der aus mehreren Spalten bestehen kann. Tabellendaten werden in der Reihenfolge des PK gespeichert, was die Suche nach dem PK sehr effizient und schnell macht. Wie bei anderen PK-basierten Systemen sollte die Implementierung mit Bedacht auf vordefinierte Anwendungsfälle geplant werden, um .
- Wechselnde Tabellen: Tabellen können physische Abhängigkeiten zueinander aufweisen. Die Zeilen der Kindertabelle können den Zeilen der Elterntabelle zugeordnet werden. Dieser Ansatz beschleunigt die Suche nach Beziehungen, die bereits in der Datenmodellierungsphase definiert werden können, zum Beispiel bei der gemeinsamen Abrechnung von Kunden und deren Rechnungen.
- Indizes: Cloud Spanner unterstützt sekundäre Indizes. Ein Index besteht aus indexierten Spalten sowie allen PK-Spalten. optional kann der Index auch andere nicht indexierte Spalten enthalten. Der Index kann mit der Elterntabelle wechseln, um die Abfragen zu beschleunigen. Für Indizes gelten einige Einschränkungen, wie beispielsweise die maximale Anzahl zusätzlicher Spalten, die im Index gespeichert werden dürfen. Auch können Abfragen über Indizes komplexer sein als bei anderen RDBMS.
„Cloud Spanner wählt Indizes automatisch nur in seltenen Fällen aus. Insbesondere wählt Cloud Spanner keinen sekundären Index automatisch aus, wenn die Abfrage nach Spalten fragt, die nicht im ».
- Service Level Agreement (SLA): Bereitstellung in einer Region mit 99,99% SLA; multiregionale Bereitstellungen mit 99,999% SLA. Obwohl das SLA lediglich eine Vereinbarung ist und keine Garantie darstellt, gehe ich davon aus, dass die Mitarbeiter von Google über genaue Daten verfügen, um eine so ernsthafte Behauptung aufzustellen. (Zum Verständnis: 99,999% bedeutet 26,3 Sekunden Ausfallzeit im Monat.)
- Mehr:
Hinweis: Das Apache Tephra-Projekt fügt erweiterte Transaktionsunterstützung in Apache HBase hinzu (nun auch in Apache Phoenix als Beta-Version umgesetzt).
3. Unsere Bewertung
Wir haben alle die Aussagen von Google über die Vorteile von Cloud Spanner gelesen - nahezu unbegrenzte horizontale Skalierung bei gleichbleibend hoher Konsistenz und sehr hohem SLA. Auch wenn diese Anforderungen extrem schwer zu erreichen sind, war es nicht unser Ziel, sie zu widerlegen. Stattdessen konzentrieren wir uns auf andere Aspekte, die für die meisten Datenbanknutzer wichtig sind: Zuverlässigkeit und Benutzerfreundlichkeit.
Wir haben Cloud Spanner als Ersatz für Sharded MySQL bewertet.
Google Cloud SQL und Amazon AWS RDS, die beiden bekanntesten OLTP-Datenbanken auf dem Cloud-Markt, bieten eine umfangreiche Funktionalität. Um diese Datenbanken jedoch über die Größe eines einzelnen Knotens hinaus zu skalieren, müssen Sie eine Anwendungssplittung durchführen. Dieser Ansatz führt zu zusätzlicher Komplexität für sowohl Anwendungen als auch die Verwaltung. Wir haben untersucht, wie Spanner in das Szenario integriert werden kann, in dem mehrere Segmente zu einer Instanz zusammengeführt werden und welche Funktionen (falls vorhanden) möglicherweise geopfert werden müssen.
SQL-, DML- und DDL-Unterstützung sowie Connector und Bibliotheken?
Zunächst müssen Sie beim Arbeiten mit einer Datenbank ein Datenmodell erstellen. Wenn Sie denken, dass Sie den JDBC Spanner an Ihr bevorzugtes SQL-Tool anschließen können, werden Sie feststellen, dass Sie damit auf Ihre Daten zugreifen können, jedoch nicht in der Lage sind, Tabellen zu erstellen oder Strukturänderungen (DDL) sowie Einfüge-/Aktualisierungs-/Löschoperationen (DML) durchzuführen. Der offizielle JDBC von Google unterstützt weder das eine noch das andere.
„Derzeit unterstützen die Treiber keine DML- oder DDL-Operationen.“
Spanner-Dokumentation
Mit der GCP-Konsole sieht die Situation nicht besser aus – Sie können nur SELECT-Anfragen senden. Glücklicherweise gibt es einen JDBC-Treiber mit Unterstützung für DML und DDL von der Community, einschließlich Transaktionen. . Obwohl dieser Treiber äußerst nützlich ist, ist das Fehlen eines eigenen JDBC-Treibers von Google überraschend. Glücklicherweise bietet Google jedoch recht umfassende Unterstützung für Client-Bibliotheken (basierend auf gRPC): C#, Go, Java, node.js, PHP, Python und Ruby.
Die weitgehende Nutzung benutzerdefinierter APIs von Cloud Spanner (aufgrund des Fehlens von DDL und DML in JDBC) führt zu einigen Einschränkungen für verwandte Codebereiche, wie Connection Pools oder Datenbankbindungsframeworks (z. B. Spring MVC). In der Regel kann man bei der Verwendung von JDBC seinen bevorzugten Connection Pool (z. B. HikariCP, DBCP, C3PO usw.) frei wählen, der getestet und gut funktioniert. Bei benutzerdefinierten Spanner APIs müssen wir uns auf die Frameworks/Pools von Bindungen/Sitzungen verlassen, die wir selbst erstellt haben.
Die schlüsselbasierte Struktur ermöglicht es Cloud Spanner, sehr schnell auf Daten über den Primärschlüssel (PK) zuzugreifen, sorgt jedoch auch für einige Probleme bei Abfragen.
- Sie können den Wert des Primärschlüssels nicht aktualisieren; Sie müssen zuerst den Datensatz mit dem ursprünglichen PK löschen und ihn mit dem neuen Wert erneut einfügen. (Dies ähnelt anderen PK-orientierten Datenbanken/Speichermechanismen.)
- Alle UPDATE- und DELETE-Anweisungen müssen den PK in der WHERE-Klausel angeben, daher kann es keine leeren DELETE ALL-Anweisungen geben – es muss immer eine Unterabfrage vorhanden sein, zum Beispiel: UPDATE xxx WHERE id IN (SELECT id FROM table1).
- Es gibt keine Auto-Inkrement-Option oder Ähnliches, das eine Sequenz für das PK-Feld festlegt. Damit das funktioniert, muss der entsprechende Wert auf der Anwendungsebene erstellt werden.
Sekundäre Indizes?
Google Cloud Spanner unterstützt von Haus aus sekundäre Indizes. Dies ist ein sehr angenehmes Feature, das nicht immer in anderen Technologien vorhanden ist. Apache Kudu unterstützt derzeit überhaupt keine sekundären Indizes, während Apache HBase Indizes nicht direkt unterstützt, sie jedoch über Apache Phoenix hinzufügen kann.
Indizes in Kudu und HBase können als separate Tabellen mit unterschiedlichen Zusammensetzungen der Primärschlüssel modelliert werden, jedoch muss die Atomarität der Operationen, die mit der übergeordneten Tabelle und den verwandten Indextabellen ausgeführt werden, auf Anwendungsebene gewährleistet sein und ist in der richtigen Implementierung nicht trivial.
Wie im Überblick über Cloud Spanner erwähnt, können seine Indizes von den Indizes von MySQL abweichen. Daher sollte besondere Vorsicht beim Erstellen von Abfragen und beim Profiling walten, um sicherzustellen, dass der ordnungsgemäße Index dort verwendet wird, wo er benötigt wird.
Sichten?
Ein sehr beliebtes und nützliches Objekt in einer Datenbank sind Sichten. Sie können für eine Vielzahl von Anwendungsfällen nützlich sein; zwei meiner Favoriten sind die logische Abstraktionsebene und die Sicherheitsebene. Leider unterstützt Cloud Spanner keine Sichten. Dies schränkt uns jedoch nur teilweise ein, da es keine Detailierungsstufen für Berechtigungen auf Spaltenebene gibt, bei denen Sichten eine akzeptable Lösung darstellen könnten.
In der Cloud Spanner-Dokumentation im Abschnitt, der Quoten und Einschränkungen detailliert beschreibt (), gibt es eine, die für einige Anwendungen problematisch sein kann: Cloud Spanner hat von Haus aus eine Beschränkung von maximal 100 Datenbanken pro Instanz. Offensichtlich kann dies ein erhebliches Hindernis für eine Datenbank darstellen, die für eine Skalierung auf mehr als 100 Datenbanken ausgelegt ist. Glücklicherweise haben wir nach einem Gespräch mit unserem technischen Ansprechpartner bei Google herausgefunden, dass dieses Limit praktisch auf jeden Wert über den Google-Support erhöht werden kann.
Unterstützung für die Entwicklung?
Cloud Spanner bietet eine ziemlich gute Unterstützung für Programmiersprachen zur Arbeit mit seiner API. Offiziell unterstützte Bibliotheken sind in den Bereichen C#, Go, Java, node.js, PHP, Python und Ruby verfügbar. Die Dokumentation ist recht detailliert, jedoch ist die Gemeinschaft, wie bei anderen fortschrittlichen Technologien, im Vergleich zu den populärsten Datenbanktechnologien recht klein, was die Zeit erhöhen kann, die benötigt wird, um weniger verbreitete Anwendungsfälle oder Probleme zu lösen.
Wie steht es also um die Unterstützung für die lokale Entwicklung?
Wir konnten keine Möglichkeit finden, eine Cloud Spanner-Instanz in einer lokalen Umgebung zu erstellen. Das Nächste, was wir erhalten haben, ist ein Docker-Image, , das im Prinzip ähnlich ist, sich jedoch in der Praxis stark unterscheidet. Zum Beispiel kann CockroachDB PostgreSQL JDBC verwenden. Da die Entwicklungsumgebung so nah wie möglich an der Produktionsumgebung sein sollte, ist Cloud Spanner nicht ideal, da man auf eine vollständige Spanner-Instanz angewiesen sein muss. Um Kosten zu sparen, können Sie eine Instanz für eine Region auswählen.
Unterstützung für die Administration?
Eine Cloud Spanner-Instanz zu erstellen ist sehr einfach. Sie müssen lediglich zwischen der Erstellung einer Multi-Region- oder einer Single-Region-Instanz wählen, die Region(en) angeben und die Anzahl der Knoten festlegen. Weniger als eine Minute später wird die Instanz gestartet und betriebsbereit sein.
Einige grundlegende Metriken sind direkt auf der Spanner-Seite in der Google-Konsole verfügbar. Detailliertere Ansichten sind über Stackdriver verfügbar, wo Sie auch Schwellenwerte für Metriken und Benachrichtigungspolitiken festlegen können.
Zugriff auf Ressourcen?
MySQL bietet umfassende und sehr detaillierte Einstellungen für Benutzerberechtigungen und -rollen. Der Zugriff auf eine bestimmte Tabelle oder sogar auf eine Teilmenge ihrer Spalten lässt sich einfach konfigurieren. Cloud Spanner hingegen verwendet das Google Identity & Access Management (IAM) Werkzeug, das es ermöglicht, Richtlinien und Berechtigungen nur auf einer sehr hohen Ebene festzulegen. Die detaillierteste Option ist die Datenbankberechtigung, die jedoch in den meisten Produktionsszenarien nicht anwendbar ist. Diese Einschränkung zwingt dazu, zusätzliche Sicherheitsmaßnahmen in Ihren Code, Ihre Infrastruktur oder beides hinzuzufügen, um unbefugte Nutzung der Spanner-Ressourcen zu verhindern.
Backups?
Einfach ausgedrückt, gibt es bei Cloud Spanner keine Backups. Obwohl die hohen Anforderungen des Google SLA garantieren können, dass Sie keine Daten durch Hardware- oder Datenbankausfälle verlieren, sichern sie nicht gegen menschliche Fehler, Anwendungsfehler usw. Wir alle kennen die Regel: Hohe Verfügbarkeit ersetzt nicht eine vernünftige Backup-Strategie. Derzeit besteht die einzige Möglichkeit, Daten zu sichern, darin, sie programmgesteuert aus der Datenbank in eine separate Speicherumgebung zu streamen.
Anfrageleistung?
Für das Laden von Daten und das Testen von Anfragen verwendeten wir das Yahoo! Cloud Serving Benchmark. In der folgenden Tabelle ist die B YCSB-Last mit einem Leseanteil von 95 % und einem Schreibanteil von 5 % dargestellt.
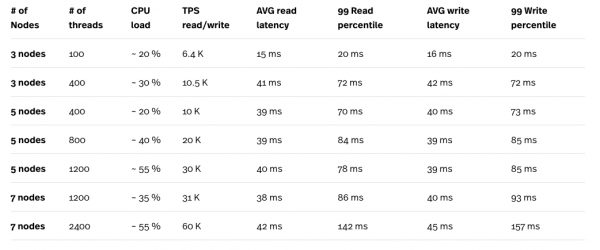
*Der Lasttest wurde auf dem Compute Engine (CE) n1-standard-32 (32 vCPUs, 120 GB RAM) durchgeführt, und die Testinstanz war bei den Tests niemals der Engpass.
**Die maximale Anzahl an Threads in einer YCSB-Instanz beträgt 400. Insgesamt mussten sechs parallele YCSB-Testinstanzen gestartet werden, um insgesamt 2400 Threads zu erhalten.
In Anbetracht der Testergebnisse, insbesondere der Kombination von CPU-Auslastung und TPS, wird deutlich, dass Cloud Spanner gut skalierbar ist. Die hohe Last, die durch eine große Anzahl an Threads erzeugt wird, wird durch die Vielzahl der Knoten im Cloud Spanner-Cluster ausgeglichen. Obwohl die Latenz relativ hoch erscheint, insbesondere bei 2400 Threads, könnte es notwendig sein, die Tests mit 6 kleineren Instanzen des Compute Engines zu wiederholen, um genauere Werte zu erhalten. Jede Instanz würde einen YCSB-Test ausführen, anstatt eine große CE-Instanz mit 6 parallelen Tests zu verwenden. Auf diese Weise wird es einfacher, zwischen den Latenzen der Cloud Spanner-Anfragen und den durch die Netzwerkverbindung zur CE-Instanz eingeführten Latenzen zu unterscheiden, auf der der Test durchgeführt wird.
Wie schneidet Cloud Spanner als OLAP ab?
Partitionierung?
Die Aufteilung von Daten in physisch und/oder logisch unabhängige Segmente, die als Partitionen bezeichnet werden, ist ein sehr populäres Konzept, das in den meisten OLAP-Mechanismen vorkommt. Partitionen können die Abfrageleistung und die Wartbarkeit der Datenbank erheblich verbessern. Eine tiefere Auseinandersetzung mit Partitionen würde einen eigenen Artikel (Artikel) erfordern; daher sei nur auf die Wichtigkeit eines Partitionierungs- und Sub-Partitionierungsschemas hingewiesen. Die Möglichkeit, Daten in Partitionen und sogar in Subpartitionen zu unterteilen, ist entscheidend für die Leistung analytischer Abfragen.
Cloud Spanner unterstützt Partitionen nicht in dem Sinne. Es teilt die Daten intern in sogenannte Splits- basierend auf dem Bereich des Primärschlüssels. Die Aufteilung erfolgt automatisch zur Lastenverteilung im Cloud Spanner-Cluster. Eine sehr nützliche Funktion von Cloud Spanner ist die Aufteilung der Basislast der übergeordneten Tabelle (der Tabelle, die nicht mit einer anderen wechselt). Spanner erkennt automatisch, ob Splits Daten enthalten sind, die häufiger gelesen werden als Daten in anderen Splits-en und kann über eine weitere Teilung entscheiden. Dadurch können mehr Knoten in der Anfrage eingebunden werden, was ebenfalls die Bandbreite effektiv erhöht.
Daten hochladen?
Die Methode Cloud Spanner für große Datenmengen ist die gleiche wie bei einem normalen Upload. Um eine maximale Leistung zu erzielen, sollten Sie einige Empfehlungen beachten, einschließlich:
- Sortieren Sie Ihre Daten nach dem Primärschlüssel.
- Teilen Sie sie in 10*Anzahl der Knoten separater Abschnitte.
- Erstellen Sie einen Satz von Arbeitsaufträgen, die Daten parallel hochladen.
Bei einem solchen Daten-Upload werden alle Knoten von Cloud Spanner verwendet.
Wir haben die Arbeitslast A YCSB verwendet, um einen Datensatz mit 10 Millionen Zeilen zu generieren.
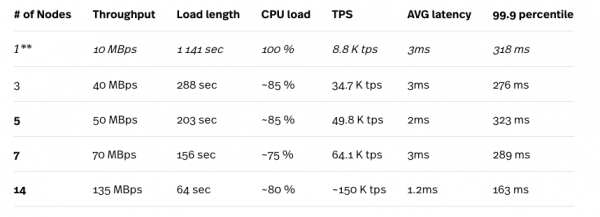
* Der Lasttest wurde auf der Rechenmaschine n1-standard-32 (32 vCPU, 120 GB RAM) durchgeführt, und die Testinstanz war während der Tests niemals der Flaschenhals.
** Eine Konfiguration mit 1 Knoten wird für keine Produktionslast empfohlen.
Wie bereits erwähnt, verarbeitet Cloud Spanner automatisch Splits basierend auf ihrer Last, sodass die Ergebnisse nach mehreren aufeinanderfolgenden Testwiederholungen besser werden. Die hier präsentierten Ergebnisse sind die besten, die wir erzielt haben. Anhand der oben genannten Zahlen können wir erkennen, wie gut Cloud Spanner mit der Zunahme der Knoten im Cluster skaliert. Die hervorgehobenen Zahlen zeigen äußerst niedrige durchschnittliche Latenzen, die im Gegensatz zu den Ergebnissen gemischter Workloads (95 % Lese- und 5 % Schreiblast) stehen, wie im obigen Abschnitt beschrieben.
Skalierung?
Das Erhöhen und Verringern der Anzahl der Cloud Spanner-Knoten ist eine Aufgabe, die mit einem Klick erledigt werden kann. Wenn Sie Daten schnell laden möchten, können Sie in Betracht ziehen, die Instanz auf das Maximum (in unserem Fall waren das 25 Knoten in der Region US-EAST) zu steigern und anschließend die Anzahl der Knoten entsprechend Ihrer regulären Last zu reduzieren, nachdem alle Daten in der Datenbank sind, wobei zu beachten ist, dass die Grenze bei 2 TB pro Knoten liegt.
Wir wurden auch bei einer deutlich kleineren Datenbank an diese Grenze erinnert. Nach mehreren Durchläufen von Lasttests hatte unsere Datenbank eine Größe von etwa 155 GB, und beim Herunterstufen auf eine Konfiguration mit 1 Knoten erhielten wir folgenden Fehler:
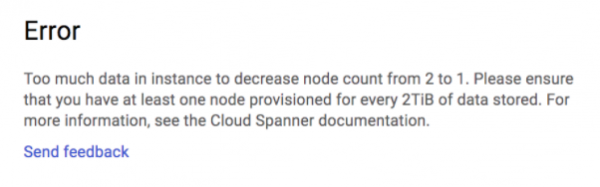
Es gelang uns, die Skalierung von 25 auf 2 Instanzen zu reduzieren, aber wir steckten bei zwei Knoten fest.
Die Erhöhung und Reduzierung der Anzahl von Knoten im Cloud Spanner Cluster kann automatisiert werden, indem das REST API verwendet wird. Dies kann besonders nützlich sein, um die erhöhte Last während der Spitzenzeiten zu verringern.
Wie ist die Leistung von OLAP-Abfragen?
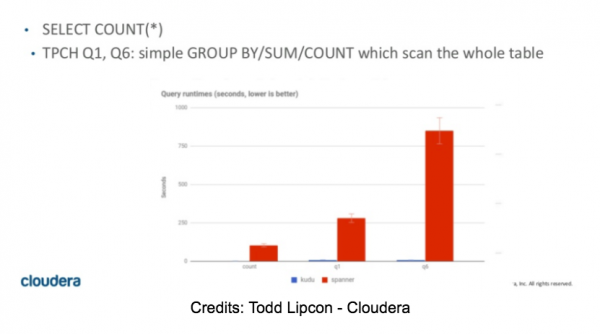
Ursprünglich planten wir, unserer Bewertung von Spanner in diesem Bereich erheblich Zeit zu widmen. Nach mehreren SELECT COUNT erkannten wir sofort, dass das Testing kurz sein würde und dass Spanner NICHT als OLAP-Engine geeignet sein würde. Unabhängig von der Anzahl der Knoten im Cluster dauerte die einfache Abfrage der Anzahl der Zeilen in einer Tabelle mit 10 Millionen Zeilen zwischen 55 und 60 Sekunden. Darüber hinaus endeten alle Abfragen, die mehr Speicher für die Speicherung von Zwischenergebnissen benötigten, mit einem OOM-Fehler.
SELECT COUNT(DISTINCT(field0)) FROM usertable; — (10M distinct values) -> SpoolingHashAggregateIterator ist während des Einfügens neuer Zeilen an den Speichergrenzen gescheitert.
Einige Zahlen für TPC-H-Abfragen finden Sie im Artikel von Todd Lipkon. , Folien 42 und 43. Diese Zahlen stimmen leider mit unseren eigenen Ergebnissen überein.
4. Unsere Erkenntnisse
Angesichts des aktuellen Stands der Funktionen von Cloud Spanner ist es schwer vorstellbar, dass er eine einfache Lösung für bestehende OLTP-Anforderungen ersetzen kann, insbesondere wenn Ihre Bedürfnisse über seine Möglichkeiten hinauswachsen. Es wäre notwendig, viel Zeit zu investieren, um eine auf die Schwächen von Cloud Spanner abgestimmte Lösung zu entwickeln.
Als wir anfingen, Cloud Spanner zu bewerten, erwarteten wir, dass seine Verwaltungsfunktionen auf dem Niveau anderer Google SQL-Lösungen oder zumindest nicht viel darunter liegen würden. Aber wir waren überrascht über das völlige Fehlen von Backups und die sehr eingeschränkte Zugriffskontrolle auf Ressourcen. Ganz zu schweigen von dem Fehlen von Ansichten, keiner lokalen Entwicklungsumgebung, nicht unterstützten Sequenzen, JDBC ohne DML- und DDL-Unterstützung und so weiter.
Was ist also mit denen, die ihre transaktionale Datenbank skalieren müssen? Derzeit scheint es auf dem Markt keine einheitliche Lösung zu geben, die für alle Anwendungsfälle geeignet ist. Es gibt eine Vielzahl von Lösungen, sowohl mit offenem als auch mit geschlossenem Quellcode (von denen einige in diesem Artikel erwähnt werden), jede mit ihren eigenen Vor- und Nachteilen. Aber keine bietet ein SaaS mit einer SLA von 99,999 % und einer hohen Konsistenz. Wenn eine hohe SLA Ihr Hauptziel ist und Sie nicht gewillt sind, eigene Lösungen für mehrere Cloud-Umgebungen zu entwickeln, könnte Cloud Spanner die Antwort sein, die Sie suchen. Dennoch sollten Sie sich bewusst sein, dass es auch Einschränkungen gibt.
Um fair zu sein, sollte erwähnt werden, dass Cloud Spanner erst im Frühling 2017 für die Öffentlichkeit freigegeben wurde. Daher ist es vernünftig zu erwarten, dass einige der aktuellen Mängel letztendlich behoben werden (hoffentlich). Wenn das geschieht, könnte es die Situation grundlegend verändern. Schließlich ist Cloud Spanner kein bloßes Nebenprojekt bei Google. Google nutzt es als Basis für andere Produkte. Als Google kürzlich Megastore in Google Cloud Storage durch Cloud Spanner ersetzt hat, ermöglichte dies, Google Cloud Storage streng konsistent für Objektlisten weltweit zu machen (was nach wie vor nicht der Fall ist für ).
Die Hoffnung bleibt also… unsere Hoffnung besteht weiterhin.
Das ist alles. Wie der Autor des Artikels hoffen wir auch weiter. Was denken Sie darüber? Hinterlassen Sie einen Kommentar.
Wir laden alle Interessierten ein, an unserem teilzunehmen, in dem wir den Kurs detailliert vorstellen werden von OTUS.
Quelle: habr.com
