

Wir werden die Funktionsweise von Zabbix mit der TimescaleDB-Datenbank als Backend untersuchen. Wir zeigen, wie man von Grund auf startet und wie man von PostgreSQL migriert. Auch werden wir Vergleichstests der Leistung beider Konfigurationen durchführen.

HighLoad++ Sibirien 2019. Saal „Tomsk“. 24. Juni, 16:00. Thesen und . Die nächste Konferenz von HighLoad++ findet am 6. und 7. April 2020 in Sankt Petersburg statt. Details und Tickets .
Andrej Guschin (im Folgenden – AG): – Ich bin Ingenieur im technischen Support von ZABBIX (im Folgenden – „Zabbix“), Trainer. Ich arbeite seit über 6 Jahren im technischen Support und habe direkt mit Leistungsfragen zu tun. Heute werde ich über die Leistung sprechen, die TimescaleDB im Vergleich zu herkömmlichem PostgreSQL 10 bieten kann. Auch ein gewisser Einführungsteil – wie alles funktioniert.
Die Hauptleistungsherausforderungen: von der Datensammlung bis zur Datenbereinigung
Lassen Sie uns damit beginnen, dass es bestimmte Leistungsherausforderungen gibt, mit denen jedes Überwachungssystem konfrontiert ist. Die erste Leistungsherausforderung besteht darin, Daten schnell zu sammeln und zu verarbeiten.

Ein effektives Überwachungssystem muss schnell und zeitgerecht alle Daten empfangen, sie gemäß Trigger-Ausdrücken verarbeiten, das heißt, sie nach bestimmten Kriterien (die in verschiedenen Systemen unterschiedlich sein können) bearbeiten und in einer Datenbank speichern, um die Daten später nutzen zu können.

Die zweite Herausforderung für die Leistung ist die Speicherung der Historie. In einer Datenbank Daten zu speichern und schnellen sowie bequemen Zugriff auf diese Metriken zu haben, die über einen bestimmten Zeitraum gesammelt wurden, ist von großer Bedeutung. Wichtig ist, dass man diese Daten leicht abrufen kann, um sie in Berichten, Grafiken, Triggern oder bei bestimmten Schwellenwerten für Benachrichtigungen usw. zu verwenden.

Die dritte Herausforderung für die Leistung besteht darin, die Historie zu bereinigen, d.h. an einem bestimmten Tag müssen Sie keine detaillierten Metriken mehr speichern, die über 5 Jahre gesammelt wurden (sogar über Monate oder zwei Monate). Einige Netzwerk-Knoten wurden entfernt, oder einige Hosts sind nicht mehr erforderlich, da die Metriken veraltet sind und nicht mehr gesammelt werden. All dies muss gelöscht werden, um zu verhindern, dass Ihre Datenbank unkontrolliert wächst. Die Bereinigung der Historie ist zudem oft eine ernsthafte Herausforderung für den Speicher – sie hat häufig einen erheblichen Einfluss auf die Leistung.
Wie können Cache-Probleme gelöst werden?
Ich werde jetzt konkret über Zabbix sprechen. In Zabbix werden die ersten beiden Herausforderungen durch Caching gelöst.

Datensammlung und -verarbeitung – wir verwenden den Arbeitsspeicher, um all diese Daten zu speichern. Im Folgenden wird näher auf diese Daten eingegangen.
Außerdem gibt es auf der Datenbankseite ein gewisses Caching für Hauptabfragen – für Grafiken und andere Dinge.
Caching auf der Seite des Zabbix-Servers: Wir haben ConfigurationCache, ValueCache, HistoryCache und TrendsCache. Was ist das?

ConfigurationCache ist der zentrale Cache, in dem wir Metriken, Hosts, Datenelemente und Trigger speichern; alles, was für die Verarbeitung von Preprocessing, Datensammlung, welche Hosts abgerufen werden sollen und mit welcher Frequenz erforderlich ist. All dies wird im ConfigurationCache gespeichert, um nicht die Datenbank zu belasten und unnötige Anfragen zu erstellen. Nach dem Start des Servers aktualisieren wir diesen Cache (erstellen ihn) und aktualisieren ihn regelmäßig (je nach den Konfigurationseinstellungen).
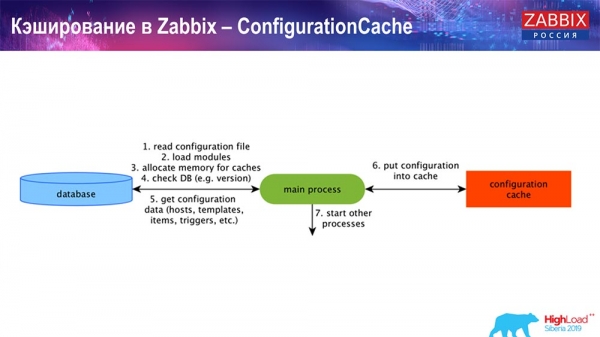
Caching in Zabbix. Datensammlung
Hier ist das Schema ziemlich groß:
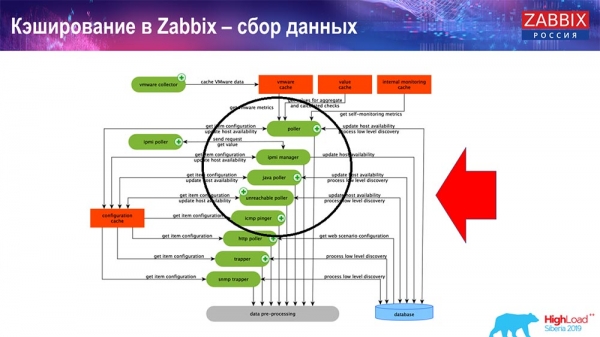
Die Hauptakteure im Schema sind diese Sammler:
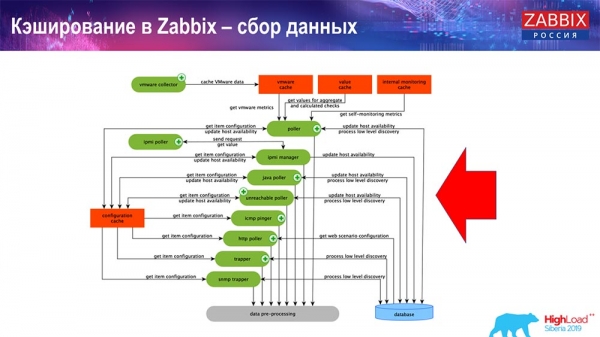
Das sind die eigentlichen Sammelprozesse, verschiedene „Poller“, die für unterschiedliche Arten von Abfragen zuständig sind. Sie sammeln Daten über ICMP, IPMI, verschiedene Protokolle und leiten all dies an das Preprocessing weiter.
PreProcessing HistoryCache
Außerdem, wenn wir berechnete Datenelemente haben (wer mit „Zabbix“ vertraut ist, weiß das), also berechnete, aggregierte Datenelemente, – holen wir diese direkt aus dem ValueCache. Wie dieser gefüllt wird, werde ich später besprechen. Alle diese Sammler nutzen den ConfigurationCache, um ihre Aufgaben abzurufen und leiten diese dann zum Preprocessing weiter.
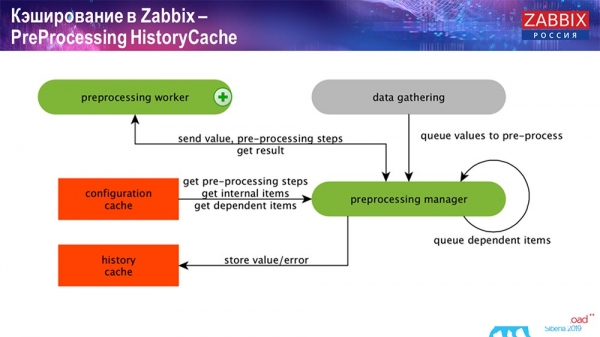
Die Vorverarbeitung nutzt ebenfalls den ConfigurationCache, um Vorverarbeitungsschritte zu erhalten und verarbeitet diese Daten auf verschiedene Weise. Seit Version 4.2 haben wir das auf einen Proxy ausge lagert. Das ist sehr praktisch, denn die eigentliche Vorverarbeitung ist ein recht ressourcenintensiver Vorgang. Wenn Sie also ein sehr großes "Zabbix" mit einer großen Anzahl von Datenelementen und einer hohen Erfassungsfrequenz haben, erleichtert das die Arbeit erheblich.
Nachdem wir diese Daten also irgendwie mit Hilfe der Vorverarbeitung verarbeitet haben, speichern wir sie im HistoryCache, um sie später weiter zu verarbeiten. Damit endet die Datenerfassung. Wir gehen zum Hauptprozess über.
Arbeit des History Syncers
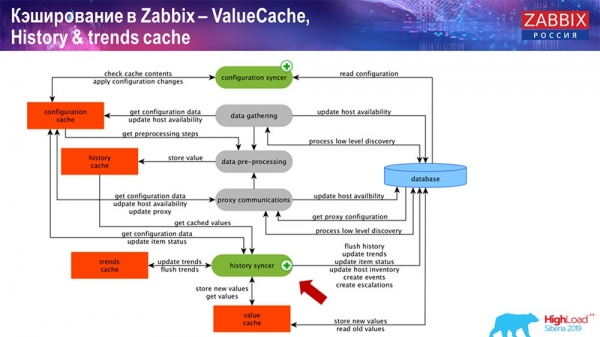
Der zentrale Prozess in "Zabbix" (da es eine monolithische Architektur ist) ist der History Syncer. Dies ist der Hauptprozess, der sich mit der atomaren Verarbeitung jedes Datenelements beschäftigt, also mit jedem Wert:
- Ein Wert kommt an (er holt ihn aus dem HistoryCache);
- Überprüft im Configuration Syncer: Gibt es Trigger zur Berechnung? – Wenn ja, berechnet er sie;
Wenn es welche gibt, erstellt er Ereignisse und eine Eskalation, um eine Benachrichtigung zu erstellen, falls dies gemäß der Konfiguration erforderlich ist; - Es zeichnet Trigger zur späteren Verarbeitung und Aggregation auf. Wenn Sie die letzten Stunden aggregieren und so weiter, speichert dieser Wert den ValueCache, um nicht auf die Historientabelle zugreifen zu müssen. Somit wird der ValueCache mit den notwendigen Daten gefüllt, die für die Berechnung von Triggern, berechneten Elementen usw. erforderlich sind.
- Der History-Synchronisierer schreibt dann alle Daten in die Datenbank.
- Die Datenbank schreibt sie auf die Festplatte – damit endet der Verarbeitungsprozess.
Datenbanken. Caching
Auf der DB-Seite, wenn Sie Grafiken oder Berichte zu Ereignissen ansehen möchten, gibt es verschiedene Caches. Aber ich werde in diesem Bericht nicht darüber sprechen.
Für MySQL gibt es den Innodb_buffer_pool und viele andere Caches, die ebenfalls konfiguriert werden können.
Aber das sind die Hauptpunkte:
- shared_buffers;
- effective_cache_size;
- shared_pool.

Ich habe für alle Datenbanken aufgeführt, dass es bestimmte Caches gibt, die es ermöglichen, die Daten, die häufig für Abfragen benötigt werden, im Arbeitsspeicher zu halten. Dort haben sie ihre eigenen Technologien dafür.
Zur Leistungsfähigkeit der Datenbank
Dementsprechend gibt es ein wettbewerbsintensives Umfeld, das heißt, der «Zabbix»-Server sammelt Daten und protokolliert sie. Bei einem Neustart liest er auch aus der Historie, um den ValueCache zu füllen und so weiter. Darüber hinaus können Sie Skripte und Berichte haben, die die «Zabbix»-API verwenden, die auf der Webschnittstelle basiert. Die «Zabbix»-API greift auf die Datenbank zu und erhält die benötigten Daten für Diagramme, Berichte oder eine Liste von Ereignissen und letzten Problemen.
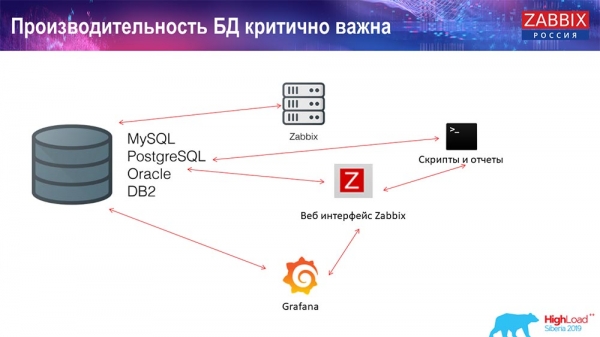
Ein ebenfalls sehr beliebtes Tool zur Visualisierung ist Grafana, das von unseren Nutzern verwendet wird. Es kann sowohl direkt über die «Zabbix»-API als auch über die Datenbank verbunden werden. Auch es schafft eine gewisse Konkurrenz in der Datenbeschaffung: Eine feinere, gut konfigurierte Datenbank ist erforderlich, um schnelle Ergebnisse und Tests zu gewährleisten.

Historienbereinigung. In Zabbix gibt es den Housekeeper.
Der dritte Aufruf, der in «Zabbix» verwendet wird, ist die Historienbereinigung mithilfe des Housekeepers. Der «Housekeeper» hält alle Einstellungen ein, das heißt, in unseren Datenelementen ist angegeben, wie lange (in Tagen) Daten aufbewahrt werden sollen, wie lange Trends und die Dynamik von Änderungen gespeichert werden.
Ich habe nicht über TrendCash gesprochen, das wir in Echtzeit berechnen: Daten kommen herein, wir aggregieren sie über eine Stunde (hauptsächlich handelt es sich um Zahlen der letzten Stunde), das Durchschnitts- / Minimalwert wird ermittelt und einmal pro Stunde in die Tabelle der Änderungstrends („Trends“) записывается. „Hausmeister“ wird gestartet und entfernt übliche Daten mit Selects aus der Datenbank, was nicht immer effizient ist.
Wie erkennt man, dass dies ineffizient ist? Sie können auf den Leistungsdiagrammen der internen Prozesse folgendes Szenario sehen:
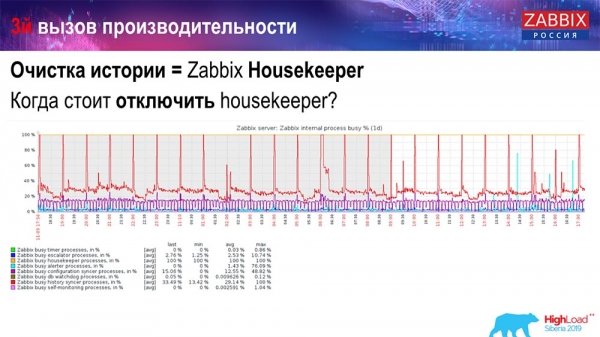
Ihr History-Syncer ist ständig beschäftigt (rotes Diagramm). Und das „orange“ Diagramm, das oben verläuft. Das ist der „Hausmeister“, der gestartet wird und auf die Datenbank wartet, um alle Zeilen zu löschen, die er festgelegt hat.
Nehmen wir eine beliebige Item-ID: Es müssen die letzten 5.000 gelöscht werden; natürlich anhand der Indizes. Doch normalerweise ist der Datensatz recht groß – die Datenbank liest das trotzdem von der Festplatte und lädt es in den Cache, was eine sehr kostspielige Operation für die Datenbank ist. Je nach ihrer Größe kann das zu bestimmten Leistungsproblemen führen.
Das Deaktivieren von „Hauskeeper“ ist ganz einfach – wir haben die vertraute Web-Oberfläche. In den allgemeinen Einstellungen (Administration general) deaktivieren wir die interne Hauswirtschaft für interne Berichte und Trends. Entsprechend verwaltet „Hauskeeper“ dies nicht mehr:

Was können Sie als Nächstes tun? Sie haben deaktiviert, Ihre Grafiken sind nun ausgerichtet... Welche Probleme können in diesem Fall auftreten? Was könnte helfen?
Partitionierung
Normalerweise wird dies auf jeder relationalen Datenbank, die ich aufgelistet habe, auf unterschiedliche Weise konfiguriert. MySQL hat seine eigene Technologie. Aber insgesamt sind sie sehr ähnlich, wenn wir über PostgreSQL 10 und MySQL sprechen. Natürlich gibt es viele interne Unterschiede, wie alles umgesetzt wird und wie sich das auf die Leistung auswirkt. Aber insgesamt führt das Erstellen einer neuen Partition oft auch zu bestimmten Problemen.

Je nach Ihrer Konfiguration (wie viele Daten an einem Tag erzeugt werden), wird normalerweise das Minimum eingestellt – das ist 1 Tag/Partition, und für „Trends“, dynamische Änderungen – 1 Monat/neue Partition. Dies kann variieren, wenn Sie eine sehr große Konfiguration haben.
Lassen Sie mich gleich über die Größen des Setups sprechen: Bis zu 5.000 neue Werte pro Sekunde (sogenannte nvps) gelten als ein kleines Setup. Ein mittleres Setup liegt zwischen 5 und 25 Tausend Werten pro Sekunde. Alles, was darüber hinausgeht, sind bereits große bis sehr große Installationen, die eine sehr sorgfältige Datenbankkonfiguration erfordern.
Bei sehr großen Installationen kann ein Tag möglicherweise nicht optimal sein. Ich habe persönlich MySQL-Partitionen mit 40 Gigabyte pro Tag gesehen (und es können noch mehr sein). Das ist eine sehr große Datenmenge, die zu Problemen führen kann. Diese muss reduziert werden.
Warum ist Partitionierung notwendig?
Was Partitionierung bewirkt, weiß ich denke ich, jeder – es handelt sich um die Sektorisierung von Tabellen. Oft sind dies separate Dateien auf der Festplatte und span-abfragen. Es wählt in der Regel eine Partition optimierter aus, wenn dies im normalen Partitionierungsprozess enthalten ist.
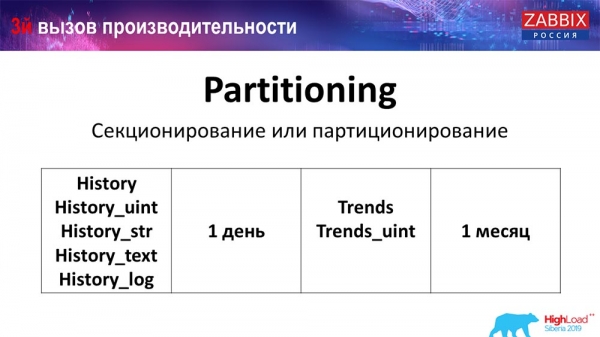
Für «Zabbix» wird das Datenmanagement im Laufe eines Zeitraums, d.h. wir verwenden einen Zeitstempel (eine reguläre Zahl, die die Zeit seit dem Beginn der Epoche angibt). Sie definieren den Beginn und das Ende des Tages, was dann als Partition dient. Demzufolge, wenn Sie auf Daten von vor zwei Tagen zugreifen, werden diese schneller aus der Datenbank abgerufen, da nur eine Datei in den Cache geladen und bereitgestellt werden muss (statt einer großen Tabelle).

Viele Datenbanken beschleunigen auch das Einfügen (Insert) in eine Kindtabelle. Ich spreche zwar abstrakt, aber das ist ebenfalls möglich. Partitionierung hilft oft.
Elasticsearch für NoSQL
Kürzlich, in Version 3.4, haben wir eine Lösung für NoSQL implementiert. Wir haben die Möglichkeit hinzugefügt, in Elasticsearch zu schreiben. Sie können verschiedene Typen auswählen: entweder Zahlen schreiben oder bestimmte Zeichen; wir haben строкen-текст, Sie können Protokolle in Elasticsearch schreiben… Daher wird auch die Weboberfläche auf Elasticsearch zugreifen. Das funktioniert in bestimmten Fällen hervorragend, ist aber momentan auch nur bedingt nutzbar.

TimescaleDB. Hypertabellen
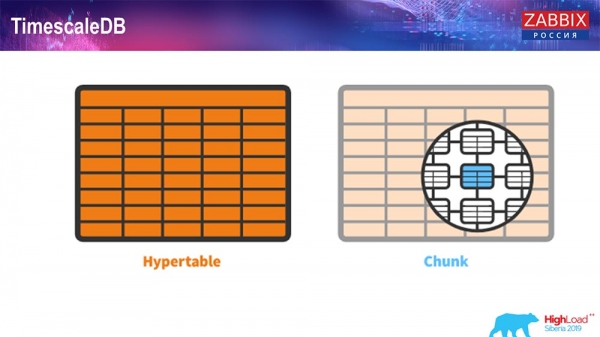
Für 4.4.2 haben wir auf eine Sache geachtet, und zwar auf TimescaleDB. Was ist das? Es handelt sich um eine Erweiterung für PostgreSQL, also hat es eine native PostgreSQL-Schnittstelle. Außerdem ermöglicht diese Erweiterung eine deutlich effizientere Verarbeitung von Zeitreihendaten und bietet automatisches Partionieren. So sieht das aus:

Das ist ein Hypertable – ein Begriff, der in Timescale verwendet wird. Es handelt sich um eine Hypertabelle, die Sie erstellen, und darin befinden sich Chunks. Chunks sind Partitions, also Kindtabellen, wenn ich mich nicht irre. Das ist wirklich effizient.
TimescaleDB und PostgreSQL
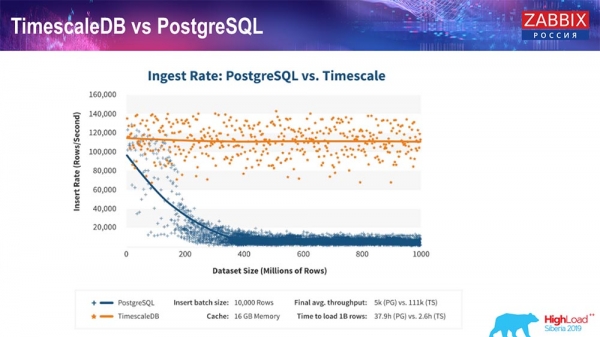
Wie die Entwickler von TimescaleDB versichern, verwenden sie einen optimierten Algorithmus zur Verarbeitung von Anfragen, insbesondere bei Inserts, der es ermöglicht, eine nahezu konstante Leistung bei wachsender Datensatzgröße beizubehalten. Das bedeutet, dass nach 200 Millionen Zeilen PostgreSQL gewöhnlich erhebliche Leistungsprobleme bekommt und die Performance praktisch bis auf Null sinkt, während Timescale es ermöglicht, Inserts so effizient wie möglich bei beliebiger Datenmenge einzufügen.
Wie installiert man TimescaleDB? Ganz einfach!
In der Dokumentation ist beschrieben, dass man Pakete für beliebige… installieren kann. Es hängt von den offiziellen Paketen von „PostgreSQL“ ab. Man kann es auch manuell kompilieren. So kam es, dass ich für die Datenbank kompilieren musste.
Für „Zabbix“ aktivieren wir einfach die Erweiterung. Ich denke, diejenigen, die die Erweiterung in „PostgreSQL“ genutzt haben, wissen… Sie aktivieren einfach die Erweiterung und erstellen sie für die „Zabbix“-Datenbank, die Sie verwenden.
Und der letzte Schritt…
TimescaleDB. Migration der Verlaufstabellen
Sie müssen eine hypertable erstellen. Dafür gibt es eine spezielle Funktion – Create hypertable. Der erste Parameter ist die Tabelle, für die in dieser DB eine hypertable benötigt wird.

Das Feld, nach dem die Erstellung erfolgen soll, sowie chunk_time_interval (das ist das Intervall der Chunks (Partitionen), die verwendet werden sollen). 86 400 – das ist ein Tag.
Parameter migrate_data: Wenn Sie ihn auf true setzen, werden alle aktuellen Daten in die im Voraus erstellten Chunks übertragen.
Ich habe migrate_data selbst verwendet – es dauert eine angemessene Zeit, abhängig von der Größe Ihrer Datenbank. Ich hatte über ein Terabyte – die Erstellung dauerte mehr als eine Stunde. In einigen Fällen habe ich während der Tests historische Daten für den Text (history_text) und die Zeichenkette (history_str) gelöscht, um sie nicht zu migrieren – sie waren für mich tatsächlich nicht interessant.
Und das letzte Update, das wir in unserer db_extension machen, ist die Installation von timescaledb, damit die Datenbank und insbesondere unser 'Zabbix' verstehen, dass es eine db_extension gibt. Es aktiviert sie und verwendet die Syntax und Abfragen zur Datenbank korrekt, wobei es bereits die 'Features' nutzt, die für TimescaleDB erforderlich sind.
Serverkonfiguration
Ich habe zwei Server verwendet. Der erste Server ist eine relativ kleine virtuelle Maschine, 20 Prozessoren, 16 Gigabyte RAM. Ich habe darauf PostgreSQL 10.8 eingerichtet:

Das Betriebssystem war Debian, das Dateisystem – xfs. Ich habe minimale Einstellungen vorgenommen, um genau diese Datenbank zu verwenden, abgesehen davon, dass Zabbix selbst verwendet wird. Auf demselben Rechner waren der Zabbix-Server, PostgreSQL und Lastagenten installiert.

Ich habe 50 aktive Agenten verwendet, die LoadableModule nutzen, um schnell verschiedene Ergebnisse zu generieren. Sie haben Zeilen, Zahlen und so weiter erstellt. Ich habe die Datenbank mit einer großen Menge an Daten gefüllt. Ursprünglich enthielt die Konfiguration 5.000 Datenelemente pro Host, wobei jedes Datenelement einen Trigger hatte – um sicherzustellen, dass es sich um ein echtes Setup handelt. Manchmal sind sogar mehr als ein Trigger erforderlich.

Ich habe das Aktualisierungsintervall und die Last dadurch reguliert, dass ich nicht nur 50 Agenten verwendet habe (sondern weitere hinzugefügt habe), sondern auch durch dynamische Datenelemente und das Herabsetzen des Aktualisierungsintervalls auf 4 Sekunden.
Leistungstest. PostgreSQL: 36.000 NVPs
Der erste Start, das erste Setup war auf einem frischen PostgreSQL 10 auf dieser Hardware (35.000 Werte pro Sekunde). Insgesamt, wie auf dem Bildschirm zu sehen ist, dauert das Einfügen von Daten Bruchteile von Sekunden – alles ist gut und schnell, SSDs (200 Gigabyte). Einziger Nachteil ist, dass 20 GB recht schnell gefüllt sind.
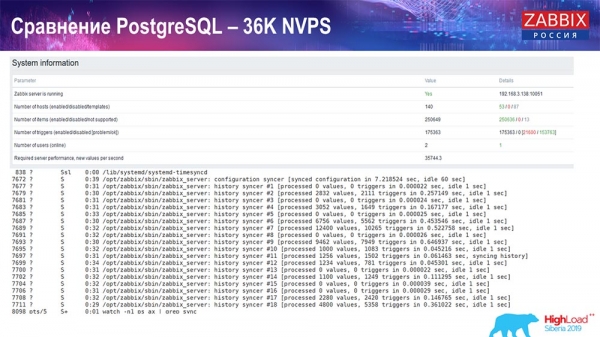
Es wird noch viele solcher Diagramme geben. Das ist das Standard-Performance-Dashboard des Zabbix-Servers.
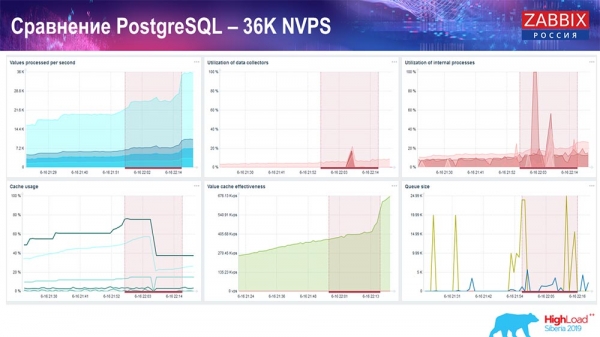
Das erste Diagramm zeigt die Anzahl der Werte pro Sekunde (blau, oben links), in diesem Fall 35.000 Werte. Oben in der Mitte sehen Sie die Auslastung der Build-Prozesse, und oben rechts die Auslastung der internen Prozesse: history syncers und der housekeeper, der hier (unten in der Mitte) eine angemessene Zeit lang durchgeführt wurde.
Dieses Diagramm (unten in der Mitte) zeigt die Nutzung von ValueCache – wie viele Hits ValueCache für Trigger generiert (einige Tausend Werte pro Sekunde). Ein weiterer wichtiger Graph ist der vierte (unten links), der die Nutzung des HistoryCache zeigt, den ich bereits erwähnt habe; dies ist ein Puffer vor der Einspeisung in die Datenbank.
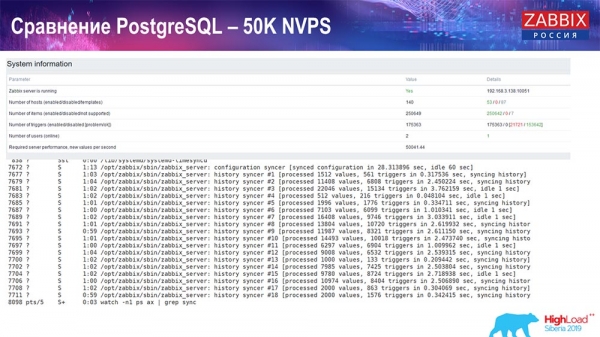
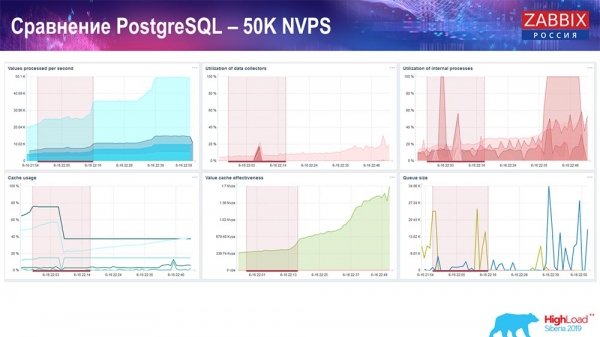
Leistungstest. PostgreSQL: 50.000 NVPs
Anschließend habe ich die Last auf 50.000 Werte pro Sekunde auf derselben Hardware erhöht. Bei der Auslastung durch den 'Housekeeper' wurden 10.000 Werte bereits in 2-3 Sekunden geschrieben, einschließlich der Berechnung. Dies wird im nächsten Screenshot angezeigt:
Der «Housekeeper» beginnt bereits, die Arbeit zu stören, aber insgesamt liegt die Auslastung der History-Synchronisierer noch bei 60 % (drittes Diagramm, oben rechts). Der HistoryCache wird bereits während des Betriebs des «Housekeepers» aktiv gefüllt (unten links). Er betrug etwa ein halbes Gigabyte und wurde zu 20 % gefüllt.
Leistungstest. PostgreSQL: 80.000 NVPs
Ich habe auf 80.000 Werte pro Sekunde erhöht:
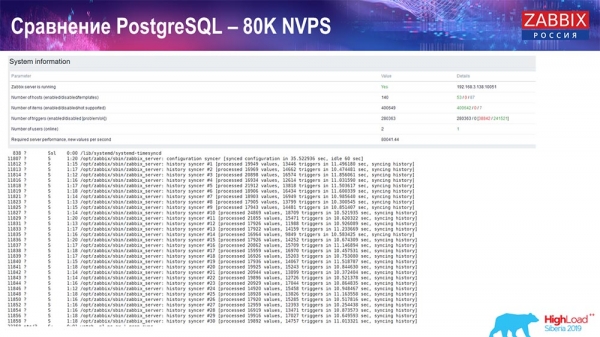
Es waren etwa 400.000 Datenelemente und 280.000 Trigger. Die Einfügeoperation hatte, wie Sie sehen, eine ziemlich hohe Auslastung der History-Synchronisierer (es waren 30 Stück). Danach habe ich verschiedene Parameter erhöht: History-Synchronisierer, Cache… Auf dieser Hardware begann die Auslastung der History-Synchronisierer, nahezu das Maximum zu erreichen – entsprechend war der HistoryCache sehr hoch ausgelastet:
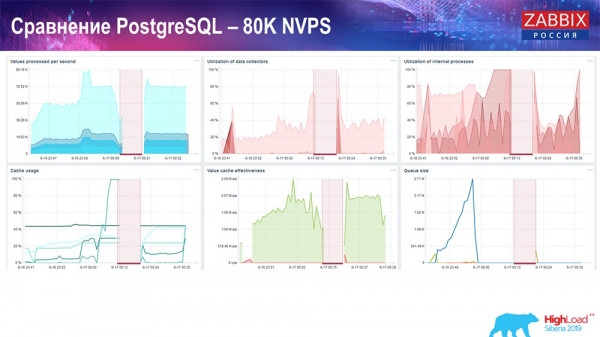
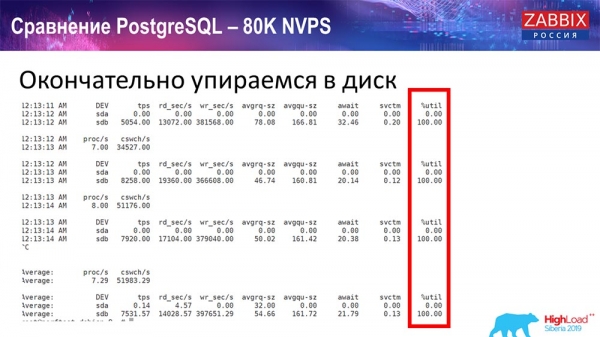
Während dieser Zeit habe ich alle Systemeinstellungen überwacht (wie die Nutzung des Prozessors und des Arbeitsspeichers) und festgestellt, dass die Festplattenauslastung maximal war – ich habe die maximalen Möglichkeiten dieser Festplatte auf dieser Hardware und dieser virtuellen Maschine erreicht. Bei dieser Intensität begann PostgreSQL, Daten sehr aktiv zu speichern, und die Festplatte konnte mit dem Schreiben und Lesen nicht mithalten...
Ich habe einen anderen Server verwendet, der bereits über 48 CPUs und 128 Gigabyte RAM verfügte:
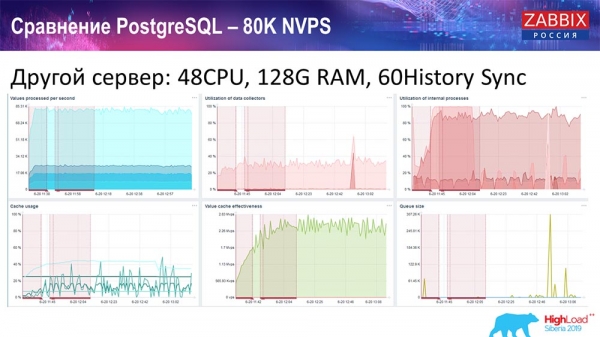
Auch habe ich ihn aufgerüstet – ich habe 60 History Syncer installiert und konnte eine akzeptable Leistung erreichen. Faktisch sind wir nicht 'in der Reserve', aber das ist wahrscheinlich das Limit der Leistung, wo man etwas unternehmen muss.
Leistungstest. TimescaleDB: 80.000 NVPs
Meine Hauptaufgabe war die Nutzung von TimescaleDB. Auf jedem Diagramm ist ein Rückgang zu sehen:
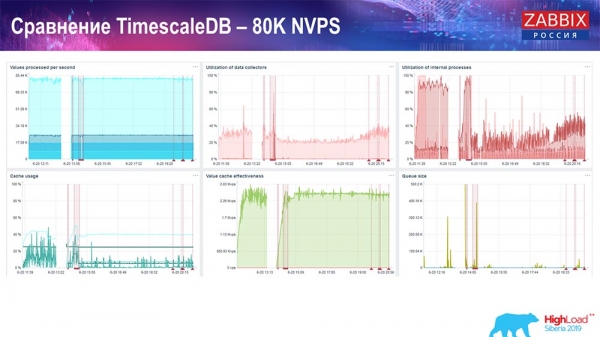
Diese Ausfälle betreffen die Datenmigration. Danach hat sich im Zabbix-Server das Profil für den Datenlademodus der History-Synchronisierer, wie Sie sehen, erheblich verändert. Es ermöglicht, Daten fast dreimal schneller einzufügen und erfordert weniger HistoryCache – folglich werden Ihre Daten zeitgerecht bereitgestellt. Wiederum 80.000 Werte pro Sekunde sind eine recht hohe Rate (natürlich nicht für Yandex). Insgesamt ist das ein recht umfangreiches Setup mit einem Server.
Leistungstest von PostgreSQL: 120.000 NVPs
Danach habe ich die Anzahl der Datenelemente auf eine halbe Million erhöht und einen geschätzten Wert von 125.000 pro Sekunde erreicht:
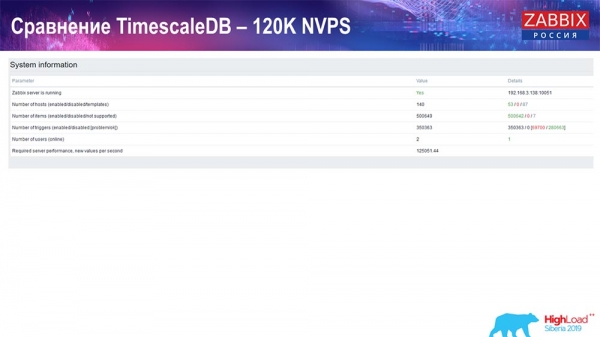
Und ich erhielt solche Grafiken:
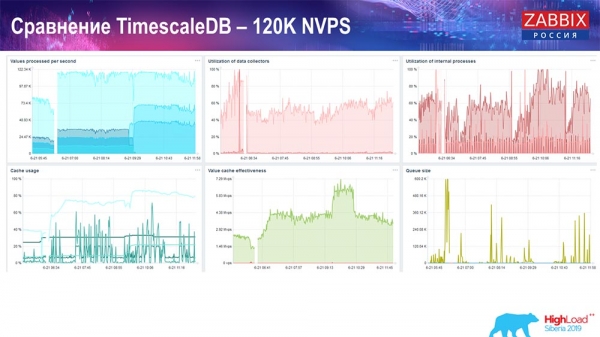
Im Prinzip ist dies ein funktionsfähiges Setup, das relativ lange betrieben werden kann. Da ich jedoch nur eine Festplatte mit 1,5 Terabyte hatte, war diese in ein paar Tagen aufgebraucht. Am wichtigsten ist, dass gleichzeitig neue Partitionen in TimescaleDB erstellt wurden, und das geschah für die Leistung vollkommen unmerklich, was man von MySQL nicht sagen kann.
In der Regel werden Partitionen nachts erstellt, da dies das Einfügen und Arbeiten mit Tabellen blockiert und zu einer Serviceverschlechterung führen kann. In diesem Fall ist das jedoch nicht so! Die Hauptaufgabe war es, die Möglichkeiten von TimescaleDB zu überprüfen. Das Ergebnis war beeindruckend: 120 Tausend Werte pro Sekunde.
Es gibt auch Beispiele in der «Community»:
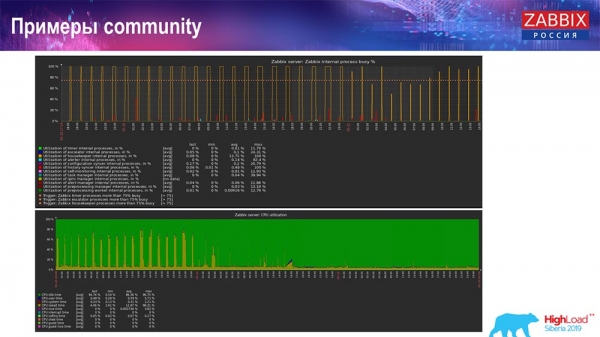
Eine Person aktivierte ebenfalls TimescaleDB, und die IO-Nutzung fiel auf der CPU; auch die Nutzung interner Prozesse wurde verringert, dank der Aktivierung von TimescaleDB. Dabei handelt es sich um gewöhnliche Festplatten, das heißt, eine normale virtuelle Maschine auf herkömmlichen Festplatten (keine SSD)!
Für kleinere Setups, die an die Diskleistung stoßen, scheint mir TimescaleDB eine sehr gute Lösung zu sein. Es erlaubt, weiterhin zu arbeiten, bevor auf leistungsstärkere Hardware für die Datenbank migriert wird.
Ich lade euch alle zu unseren Veranstaltungen ein: Conference – in Moskau, Summit – in Riga. Nutzt unsere Kanäle – «Telegram», Forum, IRC. Wenn ihr Fragen habt – kommt zu unserem Stand, wir können über alles sprechen.
Fragen aus dem Publikum
Frage aus dem Publikum (im Folgenden – A): – Wenn TimescaleDB so einfach einzurichten ist und einen so großen Leistungsschub bietet, wäre es dann vielleicht sinnvoll, dies als Best Practice für die Konfiguration von Zabbix mit PostgreSQL zu verwenden? Gibt es versteckte Fallstricke oder Nachteile bei dieser Lösung, oder kann ich, wenn ich Zabbix einrichten möchte, einfach PostgreSQL verwenden, Timescale sofort installieren, es nutzen und mir keine Sorgen um irgendwelche Probleme machen?

AG: – Ja, ich würde sagen, das ist eine gute Empfehlung: Verwenden Sie PostgreSQL sofort mit der Erweiterung TimescaleDB. Wie bereits erwähnt, gibt es zahlreiche positive Rückmeldungen, obwohl dieses „Feature“ experimentell ist. Tatsächlich zeigen die Tests, dass dies eine hervorragende Lösung (mit TimescaleDB) ist, und ich glaube, dass es sich weiterentwickeln wird! Wir beobachten die Entwicklung dieser Erweiterung und werden nötige Anpassungen vornehmen.
Selbst während der Entwicklung haben wir uns auf eine ihrer bekannten "Funktionen" verlassen: Man konnte mit Chunks etwas anders umgehen. Aber dann haben sie das im nächsten Release entfernt, und wir mussten uns nicht mehr auf diesen Code stützen. Ich würde empfehlen, diese Lösung in vielen Setups zu verwenden. Wenn Sie MySQL benutzen... Funktioniert bei mittleren Setups jede Lösung ziemlich gut.
A: – Auf den letzten Diagrammen, die von der Community stammen, gab es ein Diagramm mit dem "Hausmeister":
Er hat weitergearbeitet. Was macht der "Hausmeister" im Falle von TimescaleDB?
AG: – Im Moment kann ich nicht genau sagen – ich werde mir den Code ansehen und ausführlicher berichten. Er verwendet Anfragen speziell von TimescaleDB nicht zum Entfernen von Chunks, sondern aggregiert sie auf eine andere Weise. Bis jetzt bin ich nicht bereit, diese technische Frage zu beantworten. Am Stand klären wir das heute oder morgen.
A: – Ich habe eine ähnliche Frage – zur Leistungsfähigkeit der Löschoperation in "Timescale".
A (Antwort aus dem Publikum): – Wenn Sie Daten aus einer Tabelle löschen, müssen Sie, wenn Sie dies über delete tun, die Tabelle durchgehen – löschen, bereinigen, alles für zukünftiges Vakuum kennzeichnen. In „Timescale“, da Sie Chunks haben, können Sie sie einfach abwerfen. Grob gesagt, sagen Sie einfach zu der Datei, die in den Big Data liegt: „Löschen!“
„Timescale“ versteht einfach, dass es diesen Chunk nicht mehr gibt. Und da es in den Abfrageplaner integriert ist, erkennt es Ihre Bedingungen in SELECT oder anderen Operationen und versteht sofort, dass dieser Chunk nicht mehr existiert – „Ich gehe da nicht mehr hin!“ (Daten sind nicht vorhanden). Das heißt, der Scan der Tabelle wird durch das Löschen der Binärdatei ersetzt, weshalb es schnell ist.
A: – Wir hatten bereits das Thema NoSQL angesprochen. Soweit ich verstehe, muss „Zabbix“ nicht wirklich Daten modifizieren, sondern es handelt sich eher um eine Art Protokoll. Kann man spezialisierte Datenbanken verwenden, die ihre Daten nicht ändern können, aber viel schneller speichern, sammeln und bereitstellen – Clickhouse, zum Beispiel, oder etwas Kafka-artiges?.. Kafka – das ist ja auch ein Protokoll! Kann man diese irgendwie integrieren?
AG: – Es gibt eine Möglichkeit, Daten zu exportieren. Ab Version 3.4 haben wir eine spezielle Funktion: Sie können alle historischen Dateien, Events und alles andere in Dateien schreiben und anschließend mit einem bestimmten Verarbeiter in jede andere Datenbank senden. Tatsächlich machen viele das und schreiben direkt in die Datenbank. Die History-Synchronisierungen schreiben all dies in Echtzeit in Dateien, rotieren diese Dateien und so weiter, und das können Sie in "ClickHouse" übertragen. Ich kann nichts zu den Plänen sagen, aber möglicherweise wird die Unterstützung von NoSQL-Lösungen wie "ClickHouse" weitergehen.
A: – Im Grunde genommen kann man Postgres komplett loswerden?
AG: – Natürlich, der schwierigste Teil in "Zabbix" sind die historischen Tabellen, die die meisten Probleme verursachen und die Events. Wenn Sie in diesem Fall die Events nicht lange speichern und die historische Trenddaten in einem anderen schnellen Speicher aufbewahren, sollten insgesamt keine Probleme auftreten.
A: – Können Sie einschätzen, wie viel schneller alles funktioniert, wenn man auf "ClickHouse" umsteigt, sagen wir?
AG: – Ich habe das nicht getestet. Ich denke, dass man zumindest vergleichbare Ergebnisse relativ einfach erzielen kann, da ClickHouse seine eigene Oberfläche hat. Eine definitive Aussage kann ich jedoch nicht treffen. Besser wäre es, einen Test durchzuführen. Alles hängt von der Konfiguration ab: wie viele Hosts Sie haben und so weiter. Einfügen ist die eine Sache, aber die Daten müssen auch abgerufen werden – sei es mit Grafana oder einem anderen Tool.
A: – Geht es also um einen fairen Wettkampf und nicht um einen großen Vorteil dieser schnellen Datenbanken?
AG: – Ich denke, wenn wir integriert haben, werden die Tests genauer sein.
A: – Und wo ist das gute alte RRD geblieben? Was hat dazu geführt, dass wir auf SQL-Datenbanken umgestiegen sind? Ursprünglich wurden doch alle Metriken auf RRD gesammelt.
AG: – In Zabbix gab es RRD, vielleicht in einer sehr alten Version. SQL-Datenbanken waren immer der klassische Ansatz. Der klassische Ansatz sind MySQL und PostgreSQL (die gibt es schon seit sehr langer Zeit). Wir haben praktisch nie die gemeinsame Schnittstelle für SQL-Datenbanken und RRD verwendet.


Ein wenig Werbung 🙂
Danke, dass Sie bei uns bleiben. Gefallen Ihnen unsere Artikel? Möchten Sie mehr interessante Inhalte sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder uns Ihren Freunden empfehlen. , eine einzigartige Alternative zu Einsteiger-Servern, die wir für Sie entwickelt haben: (Verfügbar sind Optionen mit RAID1 und RAID10, bis zu 24 Kerne und bis zu 40GB DDR4).
Dell R730xd im Equinix Tier IV Rechenzentrum in Amsterdam zum halben Preis? Nur bei uns in den Niederlanden! Dell R420 — 2x E5-2430 2.2GHz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — ab 99 $! Lesen Sie darüber
Quelle: habr.com
