

Alle sprechen über Entwicklungs- und Testprozesse, Schulung des Personals, Steigerung der Motivation, aber diese Prozesse sind von geringer Bedeutung, wenn eine Minute Ausfallzeit des Dienstes astronomische Kosten verursacht. Was tun, wenn Sie finanzielle Transaktionen unter einem strengen SLA durchführen? Wie können Sie die Zuverlässigkeit und Fehlertoleranz Ihrer Systeme erhöhen, ohne Entwicklung und Test in Betracht zu ziehen?

Die nächste Konferenz HighLoad++ findet am 6. und 7. April 2020 in St. Petersburg statt. Details und Tickets unter . 9. November, 18:00 Uhr. HighLoad++ Moskau 2018, Saal „Delhi + Kalkutta“. Abstracts und .
Evgeny Kuzovlev (im Folgenden – EK): – Freunde, hallo! Ich bin Kuzovlev Evgeny. Ich arbeite bei EcommPay, genauer gesagt bei der Abteilung EcommPay IT, der IT-Abteilung der Unternehmensgruppe. Heute werden wir über Ausfallzeiten sprechen – darüber, wie man sie vermeidet und wie man ihre Folgen minimiert, wenn sie nicht vermeidbar sind. Das Thema lautet: „Was tun, wenn eine Minute Ausfallzeit 100.000 Dollar kostet?“ Wir können vorwegnehmen, dass die Zahlen vergleichbar sind.
Womit beschäftigt sich EcommPay IT?
Wer sind wir? Warum stehe ich hier vor Ihnen? Warum habe ich das Recht, Ihnen hier etwas zu erzählen? Und worüber werden wir hier detaillierter sprechen?
Die EcommPay-Gruppe ist ein internationaler Zahlungsdienstleister. Wir bearbeiten Zahlungen weltweit – in Russland, Europa und Südostasien (All Around the World). Wir haben 9 Büros, insgesamt 500 Mitarbeiter, und ungefähr etwas weniger als die Hälfte davon sind IT-Spezialisten. Alles, was wir tun und wovon wir leben, haben wir selbst entwickelt.
Alle unsere Produkte (und davon haben wir eine ganze Menge – in unserer Reihe großer IT-Produkte gibt es etwa 16 verschiedene Komponenten) haben wir selbst geschrieben; wir entwickeln alles in Eigenregie. Aktuell führen wir etwa eine Million Transaktionen pro Tag durch (meistens sind es sogar Millionen, so könnte man es korrekt ausdrücken). Wir sind ein relativ junges Unternehmen – wir sind erst etwa sechs Jahre alt.
Vor 6 Jahren starteten wir als kleines Unternehmensprojekt, als eine Gruppe Jungs mit einer Geschäftsidee zu uns kam. Sie waren ausschließlich von dieser Idee geleitet (es gab nichts weiter als die Idee) und dann gingen wir los. Wie bei jedem Start-up ging es uns darum, schneller zu sein… Geschwindigkeit war uns wichtiger als Qualität.
Irgendwann hielten wir inne: Wir erkannten, dass wir mit der bisherigen Geschwindigkeit und Qualität nicht länger leben konnten und dass wir in erster Linie auf die Qualität setzen mussten. In diesem Moment trafen wir die Entscheidung, eine neue Plattform zu entwickeln, die richtig, skalierbar und zuverlässig sein wird. Wir begannen mit der Entwicklung der Plattform (starteten Investitionen, entwickelten die Software und führten Tests durch), aber irgendwann stellten wir fest, dass die Entwicklung und die Tests uns nicht auf ein neues Qualitätsniveau bringen konnten.
Sie entwickeln ein neues Produkt, bringen es in die Produktion, aber trotzdem wird irgendwo etwas schiefgehen. Heute werden wir darüber sprechen, wie wir ein neues Qualitätsniveau erreichen können (unsere Erfahrungen dazu, wie wir das geschafft haben), wobei wir die Entwicklung und die Tests außen vor lassen; wir werden darüber sprechen, was der Betrieb selbst leisten kann, was er dem Testen anbieten kann, um die Qualität zu beeinflussen.
Ausfallzeiten. Gesetze des Betriebs.
Ein zentraler Aspekt, über den wir heute sprechen werden, ist die Betriebsunterbrechung. Ein furchtbares Wort. Wenn wir eine Betriebsunterbrechung haben, läuft alles schief. Wir müssen schnell reagieren, die Administratoren halten die Server am Laufen – Gott sei Dank stürzt nichts ab, wie es in dem Lied heißt. Darüber werden wir heute sprechen.

Als wir anfingen, unsere Ansätze zu ändern, haben wir 4 Gebote aufgestellt. Diese sind auf den Folien dargestellt:
Diese Gebote sind recht einfach:

- Schnell das Problem identifizieren.
- Noch schneller es beseitigen.
- Den Grund verstehen helfen (später, für die Entwickler).
- Und die Ansätze standardisieren.
Ich möchte Ihre Aufmerksamkeit auf Punkt Nr. 2 lenken. Wir beseitigen das Problem, anstatt es zu lösen. Es ist nachrangig, es zu lösen. Für uns ist es vorrangig, dass der Benutzer von diesem Problem ausgeschlossen ist. Es wird in einer isolierten Umgebung existieren, aber diese Umgebung wird nicht mit ihm in Kontakt treten. Tatsächlich werden wir uns mit diesen vier Gruppen von Problemen beschäftigen (mit einigen ausführlicher, mit anderen weniger ausführlich), ich werde Ihnen erzählen, was wir verwenden und welche Erfahrungen wir mit den Lösungen gemacht haben.
Problemlösung: Wann treten sie auf und was ist zu tun?
Aber lass uns nicht der Reihenfolge nach beginnen, sondern mit Punkt Nr. 2 – wie entfernen wir das Problem schnell? Es gibt ein Problem – wir müssen es lösen. "Was sollen wir damit machen?" – die zentrale Frage. Und als wir anfingen, darüber nachzudenken, wie wir das Problem beheben könnten, entwickelten wir einige Anforderungen, denen die Problemlösung folgen sollte.

Um diese Anforderungen zu formulieren, stellten wir uns die Frage: "Wann treten bei uns Probleme auf?" Und es stellte sich heraus, dass Probleme in vier Fällen auftreten:

- Hardwarefehler.
- Fehler externer Dienste.
- Änderung der Softwareversion (das eigentliche Deployment).
- Sprunghafter Anstieg der Last.
Über die ersten beiden werden wir nicht sprechen. Hardwarefehler sind relativ einfach zu beheben: Sie sollten alles redundant haben. Wenn es sich um Festplatten handelt, sollten diese im RAID-Verbund zusammengestellt sein; wenn es sich um Server handelt, sollten diese dupliziert werden; wenn Sie eine Netzwerk-Infrastruktur haben, sollten Sie eine zweite Kopie der Netzwerk-Infrastruktur bereitstellen, das heißt, Sie nehmen und duplizieren. Und wenn bei Ihnen etwas ausfällt, schalten Sie auf die Backup-Kapazitäten um. Hier gibt es nicht viel mehr zu sagen.
Der zweite Grund sind Ausfälle externer Dienste. Für die meisten Systeme stellt das überhaupt kein Problem dar, aber nicht für uns. Da wir Zahlungen verarbeiten, fungieren wir als Aggregator, der zwischen dem Nutzer (der seine Kartendaten eingibt) und den Banken sowie den Zahlungssystemen (wie „Visa“, „MasterCard“, „Mir“) steht. Es kommt häufig vor, dass externe Dienste (Zahlungssysteme, Banken) ausfallen. Darauf haben weder wir noch Sie (sofern Sie solche Dienste haben) Einfluss.
Was ist also zu tun? Es gibt zwei Möglichkeiten. Erstens, wenn möglich, sollten Sie diesen Dienst irgendwie duplizieren. Zum Beispiel leiten wir, wenn wir können, den Traffic von einem Dienst auf einen anderen um: Wir haben zum Beispiel Karten über die „Sberbank“ verarbeitet, falls es bei der „Sberbank“ Probleme gibt, leiten wir den Traffic [verhältnismäßig] auf die „Raiffeisen“ um. Zweitens können wir Ausfälle externer Dienste sehr schnell erkennen, und daher werden wir in der nächsten Sektion unseres Berichts über die Reaktionsgeschwindigkeit sprechen.
In Bezug auf diese vier Punkte können wir konkret Einfluss auf die Softwareversionen nehmen – Maßnahmen ergreifen, die die Situation im Kontext von Deployments und dem explosiven Anstieg der Last verbessern. Genau das haben wir getan. Hier wiederum eine kleine Anmerkung…
Einige dieser vier Probleme lassen sich sofort lösen, wenn Sie Cloud-Dienste nutzen. Wenn Sie in den Clouds von 'Microsoft Azure', 'Ozon' sind oder unsere Cloud-Services von 'Yandex' oder 'Mail.ru' verwenden, dann wird mindestens ein Hardwarefehler zu deren Problem, und es geht Ihnen sofort besser in Bezug auf Hardwareprobleme.
Wir sind ein etwas unkonventionelles Unternehmen. Hier dreht sich alles um 'Kubernetes' und Clouds – wir haben weder 'Kubernetes' noch Clouds. Stattdessen haben wir Server in vielen Rechenzentren, und auf dieser Hardware müssen wir leben, wir müssen dafür verantwortlich sein. Daher werden wir in diesem Kontext sprechen. Lassen Sie uns über die Probleme sprechen. Die ersten beiden lassen wir außen vor.
Änderung der Softwareversion. Datenbanken
Unsere Entwickler haben keinen Zugang zur Produktionsumgebung. Warum? Ganz einfach, wir sind nach PCI DSS zertifiziert und unsere Entwickler haben einfach kein Recht, auf die Produktion zuzugreifen. Punkt. Ganz und gar. Daher endet die Verantwortung der Entwicklung genau in dem Moment, in dem der Build an die Veröffentlichung übergeben wird.

Unsere zweite Basis, die uns ebenfalls stark unterstützt, ist das Fehlen einzigartiger, nicht dokumentierter Kenntnisse. Ich hoffe, das ist bei Ihnen ebenso. Denn wenn dem nicht so ist, werden Sie Probleme bekommen. Probleme entstehen dann, wenn diese einzigartigen, nicht dokumentierten Kenntnisse zur richtigen Zeit am richtigen Ort fehlen. Angenommen, eine Person weiß, wie man eine bestimmte Komponente deployt – wenn diese Person nicht da ist, weil sie im Urlaub oder krank ist – haben Sie sofort Probleme.
Und die dritte Basis, zu der wir gekommen sind. Wir sind durch Schmerz, Blut und Tränen zu der Erkenntnis gelangt, dass jeder unserer Builds Fehler enthält, selbst wenn er fehlerfrei erscheint. Wir haben für uns beschlossen: Wenn wir etwas deployen, wenn wir etwas in die Produktion bringen – hat unser Build Fehler. Wir haben Anforderungen formuliert, die unser System erfüllen muss.
Anforderungen an die Versionsänderung der Software
Diese Anforderungen sind drei:

- Wir müssen die Bereitstellung schnell zurücksetzen.
- Wir müssen die Auswirkungen einer fehlgeschlagenen Bereitstellung minimieren.
- Und wir müssen in der Lage sein, schnell parallel bereitzustellen.
Genau in dieser Reihenfolge! Warum? Weil bei der Bereitstellung einer neuen Version die Geschwindigkeit zunächst unwichtig ist, aber Ihnen wichtig ist, schnell zurückzusetzen, falls etwas schiefgeht, und minimale Auswirkungen zu haben. Wenn Sie jedoch eine Versionsreihe in der Produktion haben, in der sich ein Fehler herausgestellt hat (wie aus heiterem Himmel, es gab keine Bereitstellung, aber der Fehler ist vorhanden) – dann ist die Geschwindigkeit der nachfolgenden Bereitstellung für Sie wichtig. Was haben wir getan, um diese Anforderungen zu erfüllen? Wir haben eine solche Methodologie angewendet:
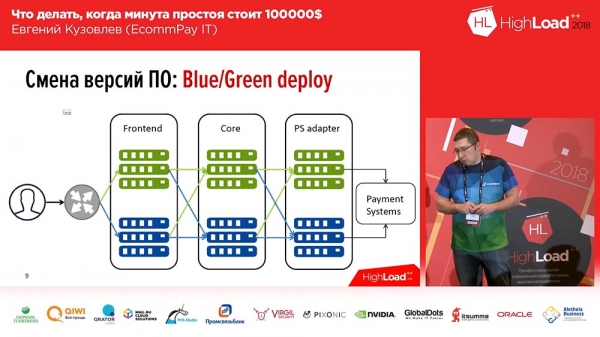
Es ist hinlänglich bekannt, wir haben es nicht erfunden – es handelt sich um Blue/Green Deployments. Was ist das? Für jede Gruppe von Servern, auf denen Ihre Anwendungen laufen, sollten Sie eine Kopie Ihrer Applikationen haben. Eine "kalte" Kopie: darauf gibt es keinen Traffic, aber jederzeit kann dieser Traffic auf diese Kopie geleitet werden. Diese Kopie enthält die vorherige Version. Und zum Zeitpunkt des Deployments setzen Sie den Code auf die inaktive Kopie ein. Anschließend leiten Sie einen Teil des Traffics (oder den gesamten) auf die neue Version um. Somit müssen Sie, um den Traffic von der alten Version auf die neue umzuleiten, nur eine Maßnahme ergreifen: Sie müssen im Upstream den Load Balancer ändern, die Richtung ändern – von einem Upstream zum anderen. Das ist sehr praktisch und löst das Problem eines schnellen Wechsels sowie eines schnellen Rollbacks.Hier ist auch die Lösung für die zweite Frage – Minimierung: Sie können nur einen Teil Ihres Traffics (zum Beispiel 2 %) auf eine neue Linie, mit einem neuen Code, umleiten. Und diese 2 % sind nicht 100%! Wenn Sie bei einem misslungenen Deployment 100 % Traffic verloren haben, ist das beängstigend; wenn Sie jedoch 2 % Traffic verloren haben, ist es unangenehm, aber nicht schlimm. Ganz zu schweigen davon, dass die Benutzer das wahrscheinlich nicht einmal bemerken, denn in einigen Fällen (nicht in allen) wird derselbe Benutzer, wenn er F5 drückt, auf eine andere, funktionierende Version gelangen.
Blue/Green Deployment. Routing
Dabei ist nicht alles so einfach wie "Blue/Green Deployment"... Alle unsere Komponenten können in drei Gruppen unterteilt werden:
- das Frontend (Zahlungsseiten, die unsere Kunden sehen);
- der Kern der Verarbeitung;
- der Adapter für die Zusammenarbeit mit Zahlungssystemen (Banken, "MasterCard", "Visa"…).
Hier gibt es einen Punkt – der Punkt betrifft das Routing zwischen den Leitungen. Wenn Sie 100 % des Verkehrs einfach umschalten, haben Sie diese Probleme nicht. Wenn Sie jedoch 2 % umschalten möchten, stellen sich Fragen: „Wie mache ich das?“ Am einfachsten ist es direkt: Sie können per Zufall, Round Robin in Nginx einstellen, und Sie haben 2 % nach links, 98 % nach rechts. Aber das passt nicht immer.
Bei uns interagiert der Benutzer beispielsweise nicht nur mit einem einzigen Request. Das ist normal: 2, 3, 4, 5 Requests – Ihre Systeme können ebenso sein. Und wenn es wichtig ist, dass alle Anfragen des Benutzers an dieselbe Leitung gesendet werden, an die die erste Anfrage gesendet wurde, oder (zweiter Punkt) dass alle Anfragen des Benutzers nach dem Umschalten an die neue Leitung gesendet werden (er könnte früher mit dem System begonnen haben, bevor das Umschalten erfolgte) – dann ist diese zufällige Verteilung nicht geeignet. In diesem Fall gibt es folgende Optionen:
Die erste Variante, die einfachste, basiert auf den grundlegenden Parametern des Clients (IP Hash). Sie haben eine IP, und basierend auf der IP teilen Sie nach links und rechts auf. In diesem Fall wird die zweite von mir beschriebene Möglichkeit wirksam, wenn das Deployment erfolgt ist und der Benutzer bereits mit Ihrem System arbeiten konnte. Ab dem Zeitpunkt des Deployments werden alle Anfragen auf die neue Linie (auf die gleiche, sagen wir) weitergeleitet.Wenn das aus bestimmten Gründen nicht für Sie geeignet ist und Sie unbedingt Anfragen an die Linie senden müssen, von der die ursprüngliche, initiale Anfrage des Benutzers kam, dann haben Sie zwei Optionen...
Die erste Option: Sie können ein kostenpflichtiges nginx+ verwenden. Dort gibt es einen Mechanismus für Sticky Sessions, der bei der initialen Anfrage des Benutzers eine Sitzung für diesen bindet und sie an den entsprechenden Upstream bindet. Alle nachfolgenden Anfragen des Benutzers innerhalb der Lebensdauer der Sitzung werden an den gleichen Upstream gesendet, an den die Sitzung gebunden wurde.Das hat für uns nicht funktioniert, weil wir bereits nginx in der Standardversion hatten. Der Übergang zu nginx+ war nicht unbedingt teuer, es war einfach für uns etwas schmerzhaft und nicht ganz richtig. Zum Beispiel haben die "Sticky Sessions" für uns nicht funktioniert, weil sie keine Möglichkeit bieten, nach dem "Oder-Oder"-Kriterium zu routen. Man kann zwar festlegen, dass wir "Sticky Sessions" zum Beispiel nach IP-Adresse oder nach IP-Adresse und Cookies oder nach POST-Parametern machen, aber das "Oder-Oder" — das ist komplizierter.
Daher sind wir auf die vierte Option gekommen. Wir haben nginx auf „Steroiden“ (das ist openresty) verwendet — das ist das gleiche nginx, das zusätzlich die Verwendung von last-Skripten unterstützt. Sie können ein last-Skript schreiben, dieses „openresty“ übergeben, und dieses Last-Skript wird ausgeführt, wenn eine Anfrage vom Benutzer eingeht.
Wir haben also ein solches Skript geschrieben, uns „openresty“ eingerichtet und in diesem Skript durchlaufen wir 6 verschiedene Parameter in der Konkatentation von „Oder“. Je nachdem, ob der jeweilige Parameter vorhanden ist oder nicht, wissen wir, ob der Benutzer auf eine Seite oder eine andere, auf eine Linie oder eine andere gekommen ist.
Blue/Green Deployment. Vorteile und Nachteile
Natürlich hätte man es vielleicht einfacher gestalten können (zum Beispiel dieselben "Sticky Sessions" verwenden), aber es gibt noch einen weiteren Aspekt: Mit uns interagiert nicht nur der Benutzer im Rahmen einer einzelnen Transaktionsverarbeitung… Es interagieren auch die Zahlungssysteme mit uns: Nachdem wir die Transaktion bearbeitet haben (indem wir eine Anfrage an das Zahlungssystem gesendet haben), erhalten wir ein Callback.
Und nehmen wir einmal an, dass wir innerhalb unseres Konturs die IP-Adresse des Benutzers in allen Anfragen durchreichen können und basierend darauf die Benutzer IPs unterscheiden können, dann würden wir nicht zu denselben "Visa" sagen: „Leute, wir sind so eine Retro-Firma, wir sind angeblich international (auf der Website und in Russland)… Könnt ihr uns bitte die IP-Adresse des Benutzers zusätzlich in ein zusätzliches Feld übermitteln? Euer Protokoll ist standardisiert!“ Verständlicherweise werden sie nicht zustimmen.
Deshalb war das für uns nicht geeignet – wir haben OpenResty gemacht. Entsprechend sieht unser Routing so aus:Der "Blue/Green Deployment" hat, wie gesagt, Vorzüge, die ich erwähnt habe, und Nachteile.
Es gibt zwei Nachteile:
- Sie müssen sich mit dem Routing beschäftigen;
- der zweite Hauptnachteil sind die Kosten.
Sie benötigen doppelt so viele Server, doppelt so viele Betriebsmittel und müssen doppelt so viel Energie aufwenden, um diesen gesamten Zoo zu verwalten.
Übrigens gibt es unter den Vorteilen noch eine andere Sache, die ich zuvor nicht erwähnt habe: Sie haben einen Puffer für steigende Lasten. Wenn Ihre Last sprunghaft ansteigt und viele Benutzer auf Sie zukommen, können Sie einfach die zweite Linie im 50-50-Verhältnis aktivieren – und schon haben Sie das doppelte Serverangebot in Ihrem Cluster, bis Sie das Serverproblem gelöst haben.
Wie macht man ein schnelles Deployment?
Wir haben besprochen, wie das Problem der Minimierung und des schnellen Rollbacks gelöst werden kann, aber die Frage bleibt: „Wie kann man schnell deployen?“
Hier ist es kurz und einfach.- Sie sollten ein CD-System (Continuous Delivery) haben – ohne das geht es nicht. Wenn Sie einen Server haben, können Sie manuell deployen. Wir haben etwa eintausendfünfhundert Server und können nicht von Hand arbeiten. Offensichtlich könnten wir eine Abteilung von der Größe dieses Raums einstellen, nur um zu deployen.
- Das Deployment sollte parallel erfolgen. Wenn Ihr Deployment sequenziell ist, wird es problematisch. Ein Server ist in Ordnung, aber bei eintausendfünfhundert Servern werden Sie den ganzen Tag mit dem Deployment beschäftigt sein.
- Auch hier ist es zur Beschleunigung wahrscheinlich nicht mehr zwingend notwendig. Bei einem Deployment wird normalerweise ein Build des Projekts durchgeführt. Sie haben ein Webprojekt, es gibt den Frontend-Bereich (dort erstellen Sie Webpack, npm wird ausgeführt – so etwas), und dieser Prozess dauert grundsätzlich nicht lange – etwa 5 Minuten, aber diese 5 Minuten können kritisch sein. Deshalb machen wir das beispielsweise nicht so: Wir haben diese 5 Minuten eliminiert und deployen die Artefakte.
Was ist ein Artefakt? Ein Artefakt ist ein erstellter Build, in dem bereits der gesamte Build-Prozess abgeschlossen ist. Dieses Artefakt speichern wir in einem Artefakt-Repository. In der Vergangenheit haben wir zwei solcher Repositories verwendet – Nexus und derzeit jFrog Artifactory. "Nexus" haben wir ursprünglich genutzt, weil wir diesen Ansatz in Java-Anwendungen praktiziert haben (es war gut dafür geeignet). Danach haben wir auch Teile von Anwendungen, die in PHP geschrieben sind, dort abgelegt; und "Nexus" war dafür nicht mehr geeignet, weshalb wir uns für jFrog Artifactory entschieden haben, das praktisch alles artefaktieren kann. Tatsächlich speichern wir in diesem Artefakt-Repository sogar unsere eigenen Binärpakete, die wir für die Server erstellen.
Explosion des Datenverkehrs
Wir haben über den Wechsel der Softwareversion gesprochen. Das Nächste, was wir haben, ist die Explosion des Datenverkehrs. Hier verstehe ich wahrscheinlich unter einer Explosion des Datenverkehrs etwas nicht ganz Richtiges...
Wir haben ein neues System entwickelt – es ist serviceorientiert, modern und ansprechend, überall Worker, überall Warteschlangen, überall Asynchronität. In solchen Systemen können die Daten unterschiedliche Flows durchlaufen. Für die erste Transaktion können der 1., 3. und 10. Worker involviert sein, für die zweite Transaktion der 2., 4. und 5. Und heute, sagen wir, am Morgen läuft ein Datenstrom, der die ersten drei Worker nutzt, aber am Abend ändert sich das plötzlich, und es werden stattdessen andere drei Worker genutzt.
Und hier ist es so, dass Sie die Worker irgendwie skalieren müssen, Ihre Services skalieren müssen, aber dabei nicht zulassen dürfen, dass die Ressourcen aufgebläht werden.
Wir haben unsere Anforderungen definiert. Diese Anforderungen sind recht einfach: Es muss ein Service-Discovery vorhanden sein, Parametrisierung – alles Standard für den Aufbau solcher skalierbaren Systeme, abgesehen von einem Punkt – der Amortisierung der Ressourcen. Wir haben gesagt, dass wir nicht bereit sind, Ressourcen zu amortisieren, nur damit die Server „Luft aufheizen“. Wir haben „Consul“ und „Nomad“ verwendet, die unsere Worker verwalten.Warum ist das für uns ein Problem? Lassen Sie mich kurz zurückblicken. Momentan haben wir etwa 70 Zahlungssysteme. Morgens läuft der Traffic über die "Sberbank", dann fällt zum Beispiel die "Sberbank" aus, und wir schalten auf ein anderes Zahlungssystem um. Wir hatten 100 Worker für die "Sberbank" im Einsatz, und danach müssen wir schnell 100 Worker für ein anderes Zahlungssystem hochfahren. Und das alles sollte idealerweise ohne menschliches Eingreifen geschehen. Denn wenn menschliches Eingreifen erforderlich ist, muss rund um die Uhr ein Ingenieur bereitstehen, der sich ausschließlich damit beschäftigt, da solche Ausfälle, wenn 70 Systeme hinter einem stehen, regelmäßig vorkommen.
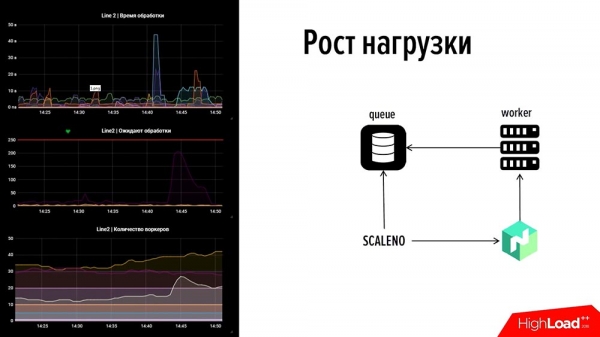
Deshalb haben wir uns "Nomad" angesehen, das eine offene IP hat, und haben unser eigenes Tool Scale-Nomad – ScaleNo, entwickelt, das ungefähr Folgendes macht: Es überwacht das Wachstum der Warteschlange und passt die Anzahl der Worker je nach Dynamik der Warteschlangenänderung an. Als wir es fertiggestellt hatten, dachten wir: "Vielleicht sollten wir es open-source machen?" Doch dann schauten wir darauf – es ist so einfach wie zwei Groschen.
Bis jetzt haben wir es nicht open-sourced, aber wenn Sie nach dem Vortrag, nachdem Sie erkannt haben, dass Sie so etwas benötigen, Bedarf daran haben, finden Sie meine Kontaktdaten auf der letzten Folie – schreiben Sie mir bitte. Wenn sich mindestens 3-5 Personen melden, werden wir es open-sourcen.
Wie funktioniert das? Lassen Sie uns einen Blick darauf werfen! Vorweg: Auf der linken Seite sehen Sie einen Teil unseres Monitorings: Eine Linie, oben – die Verarbeitungszeit von Ereignissen, in der Mitte – die Anzahl der Transaktionen, unten – die Anzahl der Worker.Wenn wir uns das Bild ansehen, sehen wir einen Ausfall. Im oberen Diagramm hat eine der Linien bei 45 Sekunden versagt – eines der Zahlungssysteme war ausgefallen. Gleichzeitig wurde der Traffic über 2 Minuten dargestellt, und die Warteschlange bei einem anderen Zahlungssystem, wo es keine Worker gab, begann zu wachsen (wir haben die Ressourcen nicht falsch genutzt – im Gegenteil, wir haben die Ressourcen korrekt verwendet). Wir wollten die Ressourcen nicht überlasten – dort waren es nur 5-10 Worker, aber die konnten nicht aufkommen.
Im letzten Diagramm ist der "Buckel" zu sehen, der zeigt, dass "Skaleno" diese Zahl verdoppelt hat. Und dann, als das Diagramm etwas sank, wurde die Anzahl der Arbeiter automatisch reduziert. So funktioniert das System.
Überwachung. Wie erkennt man Probleme schnell?
Jetzt kommen wir zum ersten Punkt – „Wie erkennt man Probleme schnell?“ Überwachung! Wir müssen bestimmte Dinge schnell verstehen. Welche Dinge müssen wir schnell verstehen?
Drei Dinge!- Wir müssen schnell die Funktionsfähigkeit unserer eigenen Ressourcen erkennen.
- Wir müssen schnell Ausfälle erkennen und die Funktionsfähigkeit der Systeme überwachen, die für uns extern sind.
- Der dritte Punkt – das Erkennen logischer Fehler. Das ist, wenn das System bei Ihnen funktioniert, alles normal scheint, aber etwas nicht stimmt.
Hier habe ich wahrscheinlich wenig Aufregendes zu erzählen. Ich werde zum Kapitän Offensichtlich. Wir haben uns angesehen, was es auf dem Markt gibt. Bei uns hat sich ein "fröhlicher Zoo" entwickelt. So sieht unser Zoo jetzt aus:
Wir verwenden "Zabbix" zur Überwachung von Hardware und zur Überwachung der wichtigsten Serverkennzahlen. "Okmeter" nutzen wir für Datenbanken. "Grafana" und "Prometheus" setzen wir für alle anderen Kennzahlen ein, die nicht in die ersten beiden Kategorien passen. Dabei verwenden wir teilweise "Grafana" und "Prometheus" zusammen, teilweise "Grafana" mit "Influx" und Telegraf.Vor einem Jahr wollten wir New Relic einsetzen. Ein wirklich tolles Tool, das alles kann. Aber so viel es kann, so teuer ist es auch. Als wir auf 1.500 Server gewachsen sind, kam ein Anbieter zu uns und sagte: "Lass uns einen Vertrag für das nächste Jahr abschließen." Wir schauten uns den Preis an und sagten: "Nein, das werden wir nicht tun." Jetzt steigen wir von "New Relic" ab; wir haben nur noch etwa 15 Server, die von "New Relic" überwacht werden. Der Preis war völlig überzogen.
Es gibt ein Werkzeug, das wir selbst entwickelt haben – den Debugger. Zuerst nannten wir ihn "Bagger", aber nachdem ein Englischlehrer bei uns war und herzlich gelacht hat, haben wir ihn in "Debugger" umbenannt. Was ist das? Es ist ein Tool, das in 15-30 Sekunden für jede Komponente, wie ein "Schwarzschild" des Systems, Tests zur allgemeinen Funktionsfähigkeit der Komponente durchführt.
Wenn es sich beispielsweise um eine externe Seite (Zahlungsseite) handelt – öffnet es diese einfach und prüft, wie sie aussehen sollte. Wenn es sich um den Zahlungsprozess handelt, führt es einen Test-"Transaction" durch – und sieht, ob diese "Transaction" ankommt. Wenn es die Verbindung zu den Zahlungssystemen betrifft, senden wir einen Test-Anruf, wenn es möglich ist, und prüfen, ob alles gut ist.
Welche Kennzahlen sind wichtig für das Monitoring?
Was überwachen wir hauptsächlich? Welche Kennzahlen sind für uns wichtig?
- Antwortzeit / RPS an den Frontends – eine sehr wichtige Kennzahl. Sie zeigt sofort an, dass etwas nicht stimmt.
- Anzahl der verarbeiteten Nachrichten in allen Warteschlangen.
- Anzahl der Worker.
- Hauptmetriken der Korrektheit.
Der letzte Punkt ist die „Business“-Metrik. Wenn Sie das Gleiche überwachen möchten, müssen Sie ein oder zwei Metriken festlegen, die für Sie die Hauptindikatoren darstellen. Bei uns ist eine solche Metrik die Durchsatzrate (das Verhältnis der Anzahl der erfolgreichen Transaktionen zum gesamten Transaktionsfluss). Wenn sich in diesem Bereich über einen Zeitraum von 5-10-15 Minuten etwas ändert – dann haben wir Probleme (insbesondere wenn es sich um eine drastische Veränderung handelt).
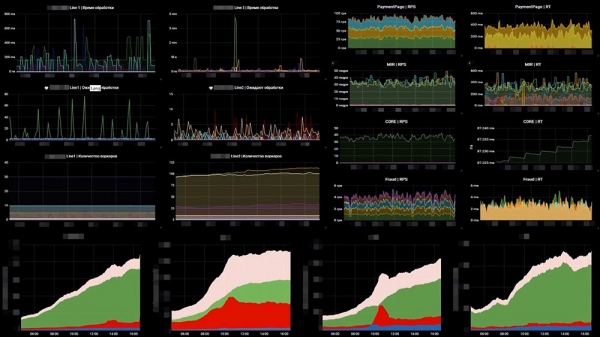
So sieht das bei uns aus – ein Beispiel für eines unserer Dashboards:
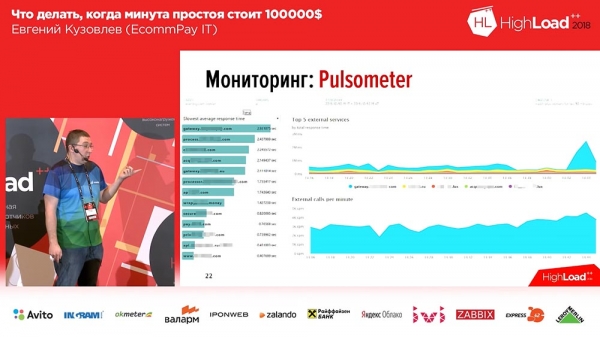
Links befinden sich 6 Diagramme, die sich auf die Linien beziehen – die Anzahl der Arbeiter und die Anzahl der Nachrichten in den Warteschlangen. Rechts – RPS, RTS. Unten – die besagte „Business“-Metrik. Und an der „Business“-Metrik sehen wir sofort, dass bei zwei der mittleren Diagramme etwas schiefgelaufen ist… Das ist genau, weil ein weiteres System, das hinter uns steht, ausgefallen ist.Der zweite Schritt, den wir unternehmen mussten, bestand darin, die Ausfälle externer Zahlungssysteme zu überwachen. Hierfür haben wir OpenTracing verwendet – ein Mechanismus, ein Standard, ein Paradigma, das es ermöglicht, verteilte Systeme zu tracen; und wir haben es ein wenig angepasst. Das Standard-OpenTracing-Paradigma besagt, dass wir das Tracking jeder einzelnen Anfrage aufbauen. Das benötigten wir nicht, und deshalb haben wir es in eine aggregierte, summative Trace umgewandelt. Wir haben ein Tool entwickelt, das uns ermöglicht, die Geschwindigkeit der Systeme, die hinter uns stehen, zu überwachen.
Das Diagramm zeigt uns, dass eines der Zahlungssysteme eine Antwortzeit von 3 Sekunden hatte – wir hatten Probleme. Gleichzeitig reagiert dieses Tool, wenn die Probleme beginnen, innerhalb eines Zeitrahmens von 20-30 Sekunden.Die dritte Klasse von Monitoring-Fehlern, die es gibt, ist das logische Monitoring.
Ehrlich gesagt wusste ich nicht, was ich auf dieser Folie zeichnen sollte, da wir lange auf dem Markt nach etwas gesucht haben, das zu uns passt. Wir haben nichts gefunden, also mussten wir es selbst erstellen.
Was meine ich mit logischem Monitoring? Stellen Sie sich vor: Sie erstellen ein System (zum Beispiel einen Klon von Tinder); Sie haben es entwickelt und gestartet. Der erfolgreiche Manager Vasja Pupkin hat es sich auf sein Handy installiert, sieht ein Mädchen, liked es... aber das Like geht nicht an das Mädchen – es geht an den Sicherheitspersonal Michalitsch aus demselben Geschäftscenter. Der Manager geht nach unten und fragt sich dann: „Warum lächelt dieser Sicherheitsmann Michalitsch so freundlich?“In solchen Situationen… Für uns klingt diese Situation etwas anders, denn (wie ich schrieb) handelt es sich um einen Reputationsverlust, der indirekt zu finanziellen Verlusten führt. Bei uns ist die Situation umgekehrt: Wir können direkte finanzielle Verluste erleiden – beispielsweise, wenn wir eine Transaktion als erfolgreich verbuchen, die aber tatsächlich nicht erfolgreich war (oder umgekehrt). Wir mussten ein eigenes Tool schreiben, das anhand der Geschäftszahlen die Anzahl der erfolgreichen Transaktionen dynamisch im Zeitverlauf überwacht. Auf dem Markt haben wir nichts gefunden! Genau diesen Gedanken wollte ich vermitteln. Für die Lösung solcher Aufgaben gibt es auf dem Markt nichts.
Das bezog sich auf die Frage, wie man ein Problem schnell identifizieren kann.
Wie man die Gründe für das Deployment bestimmt
Die dritte Gruppe von Aufgaben, die wir angehen, besteht darin, nachdem wir das Problem identifiziert und behoben haben, die Ursachen zu verstehen, um sie für die Entwicklung und das Testing zu dokumentieren und Maßnahmen zu ergreifen. Daher müssen wir forschen und die Logs analysieren.
Wenn wir über Logs sprechen (der Hauptgrund sind die Logs), dann haben die meisten von uns den ELK Stack als Hauptteil der Logs – praktisch jeder. Bei manchen ist es vielleicht nicht ELK, aber wenn Sie Logs in Gigabytes schreiben, kommen Sie früher oder später zu ELK. Wir schreiben sie in Terabytes.
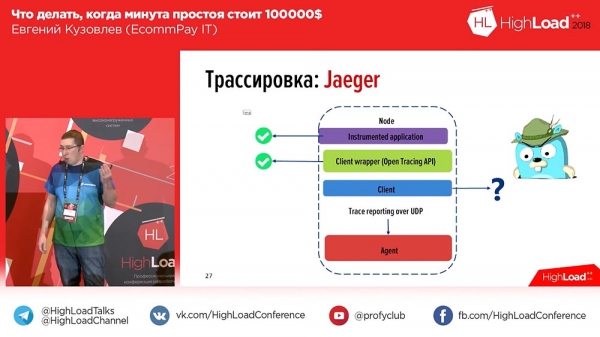
Hier gibt es ein Problem. Wir haben den Fehler für den Benutzer behoben und begonnen zu graben, was genau passiert ist, haben Kibana aufgerufen, die Transaktions-ID eingegeben und eine solche lange Liste erhalten (zeigt viel). Und in dieser Liste ist rein gar nichts verständlich. Warum? Weil nicht klar ist, welcher Teil zu welchem Worker gehört und welcher Teil zu welchem Component. In diesem Moment haben wir erkannt, dass wir eine Traceability benötigen – das besagte OpenTracing, von dem ich gesprochen habe.Vor einem Jahr haben wir darüber nachgedacht und unseren Blick auf den Markt gerichtet, wo wir zwei Werkzeuge fanden – «Zipkin» und «Jaeger». «Jaeger» ist im Grunde genommen der ideologische Nachfolger, die ideologische Fortsetzung von «Zipkin». Bei «Zipkin» ist alles gut, außer dass es nicht aggregieren kann und keine Logs in die Trace einfügen kann, sondern nur Zeit-Tracking. «Jaeger» hat diese Funktion unterstützt.
Wir haben uns «Jaeger» angesehen: Man kann Anwendungen instrumentieren und in die API (die PHP-Standard-API war zu diesem Zeitpunkt, vor einem Jahr, noch nicht genehmigt – jetzt ist sie genehmigt) schreiben, hatte aber absolut keinen Client. „Okay“, dachten wir, und haben unseren eigenen Client geschrieben. So sieht es ungefähr aus:
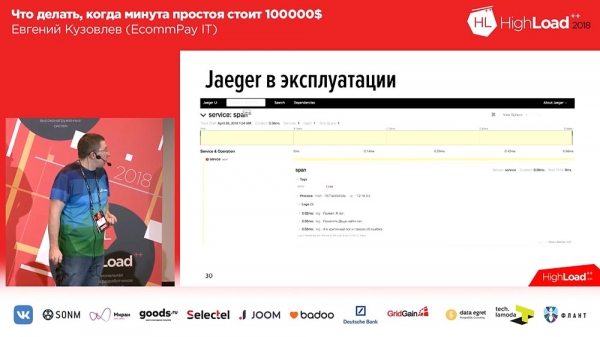
In 'Eger' werden für jede Nachricht Spans erstellt. Das bedeutet, wenn der Benutzer das System öffnet, sieht er einen oder zwei Blöcke für jede eingehende Anfrage (1-2-3 – so viele eingehende Anfragen vom Benutzer waren, so viele Blöcke gibt es). Um es den Benutzern zu erleichtern, haben wir Tags zu den Logs und der zeitlichen Nachverfolgung hinzugefügt. Im Falle eines Fehlers wird unser Anwendung das Log mit dem entsprechenden Tag 'Error' markieren. Man kann nach dem Tag 'Error' filtern und nur die Spans anzeigen, die diesen Block mit dem Fehler enthalten. So sieht es aus, wenn wir den Span aufklappen:
Innerhalb des Spans gibt es eine Reihe von Traces. In diesem Fall sind es drei Test-Traces, und der dritte Trace zeigt uns, dass ein Fehler aufgetreten ist. Gleichzeitig sehen wir hier die zeitliche Nachverfolgung: Oben haben wir eine Zeitachse, und wir sehen, in welchem Zeitintervall das jeweilige Log aufgezeichnet wurde.Entsprechend lief es hervorragend. Wir haben eine eigene Erweiterung geschrieben und sie Open Source gestellt. Wenn Sie mit der Nachverfolgung arbeiten möchten und 'Eger' in PHP nutzen wollen – hier ist unsere Erweiterung, willkommen zur Nutzung, wie man so schön sagt:
Diese Erweiterung ist ein Client für die Nutzung der OpenTracing API und wurde als PHP-Erweiterung entwickelt, das heißt, Sie müssen sie selbst kompilieren und in das System integrieren. Vor einem Jahr gab es nichts anderes. Jetzt sind noch andere Clients aufgetaucht, die als Komponenten fungieren. Hier haben Sie die Wahl: Entweder Sie laden die Komponenten über Composer herunter oder Sie verwenden die Erweiterung — ganz wie Sie möchten.Unternehmensstandards
Wir haben über die drei Gebote gesprochen. Das vierte Gebot ist die Standardisierung von Ansätzen. Worum geht es dabei?
Warum hier das Wort „unternehmerisch“? Nicht weil wir ein großes oder bürokratisches Unternehmen sind, nein! Das Wort „unternehmen“ wollte ich hier im Sinne verwenden, dass jede Firma, jedes Produkt seine eigenen Standards haben sollte, und das gilt auch für Sie. Welche Standards haben wir?- Wir haben eine Regelung für Deployments. Ohne diese kommen wir nicht voran, wir können nicht. Wir deployen etwa 60 Mal pro Woche, das heißt, unsere Deployments finden praktisch ständig statt. Dabei gibt es in unserer Regelung beispielsweise ein tabu für Deployments am Freitag – grundsätzlich, wir deployen nicht.
- Dokumentation ist bei uns zwingend erforderlich. Kein neues Element gelangt in die Produktion, wenn es keine Dokumentation hat, selbst wenn es von unseren RnD-Teams entwickelt wurde. Wir verlangen von ihnen eine Bereitstellungsanleitung, eine Monitoring-Karte und eine grobe Beschreibung (nun, so wie Programmierer es formulieren können), wie dieses Element funktioniert und wie man es debuggen kann.
- Wir beheben nicht die Ursache des Problems, sondern das Problem selbst – das habe ich bereits erwähnt. Es ist uns wichtig, die Benutzer vor Problemen zu schützen.
- Wir haben Toleranzen. Zum Beispiel betrachten wir es nicht als Ausfall, wenn wir für zwei Minuten 2 % des Traffics verloren haben. Das fließt grundsätzlich nicht in unsere Statistik ein. Wenn es im prozentualen oder zeitlichen Verhältnis mehr ist, zählen wir es bereits.
- Und wir schreiben stets Post-Mortems. Was auch immer bei uns passiert, jede Situation, die im Produktionsbetrieb nicht ordnungsgemäß funktioniert hat, wird in einem Post-Mortem festgehalten. Ein Post-Mortem ist ein Dokument, in dem Sie beschreiben, was passiert ist, mit einer detaillierten Zeitachse, was Sie unternommen haben, um das Problem zu beheben, und (das ist ein obligatorischer Block!) was Sie tun werden, um zu verhindern, dass so etwas in Zukunft erneut geschieht. Das ist zwingend erforderlich und notwendig für die anschließende Analyse.
Was gilt als Ausfallzeit?
Worauf hat das alles geführt?Dies führte dazu, dass wir in den letzten 6 Monaten eine Stabilitätsrate von 99,97 hatten (wir hatten bestimmte Stabilitätsprobleme, die sowohl für unsere Kunden als auch für uns unbefriedigend waren). Man könnte sagen, dass das nicht besonders viel ist. Ja, wir haben Spielraum für Verbesserungen. Ungefähr die Hälfte dieser Rate stammt von der Stabilität des Webanwendungsfirewalls, der vor uns steht und als Dienst verwendet wird, aber das ist unseren Kunden egal.
Wir haben gelernt, nachts zu schlafen. Endlich! Vor einem halben Jahr konnten wir das nicht. Und an dieser Stelle möchte ich einen Kommentar zu den Ergebnissen machen. Gestern Abend gab es einen großartigen Vortrag über das Managementsystem für Kernreaktoren. Wenn ich Menschen anspreche, die dieses System entwickelt haben – bitte vergessen Sie, was ich über '2% sind kein Ausfall' gesagt habe. Für Sie sind 2% Ausfall, selbst wenn es nur zwei Minuten sind!
Das ist alles! Ihre Fragen.
Über Load-Balancer und Migration aus der Datenbank
Frage aus dem Publikum (im Folgenden – F): – Guten Abend. Vielen Dank für Ihren informativen Bericht! Eine kurze Frage zu Ihren Lastverteilern. Sie erwähnten, dass Sie eine WAF haben, also nutzen Sie, wie ich verstehe, einen externen Lastverteiler…
EK: – Nein, wir verwenden unsere eigenen Dienste als Lastverteiler. In diesem Fall ist die WAF für uns ein reines Schutzmittel gegen DDoS-Attacken.
Frage: – Kann ich ein paar Worte über die Lastverteiler hören?
EK: – Wie bereits erwähnt, besteht diese Gruppe aus Servern in openresty. Wir haben derzeit 5 Gruppen von reservierten Servern, die ausschließlich… das heißt, der Server, auf dem nur openresty läuft, leitet lediglich den Verkehr weiter. Um zu verdeutlichen, wie viel wir verarbeiten: Unser aktueller regelmäßiger Datenstrom beträgt mehrere Hundert Megabit. Sie bewältigen das gut, sie haben keine Probleme, sogar ohne sich anzustrengen.
Frage: – Auch eine einfache Frage. Es gibt Blue/Green Deployments. Was machen Sie beispielsweise mit Datenbankmigrationen?
EK: – Gute Frage! Schauen Sie, im Blue/Green-Deployment haben wir separate Warteschlangen für jede Linie. Das bedeutet, wenn wir über die Ereigniswarteschlangen sprechen, die von Worker zu Worker übertragen werden, gibt es separate Warteschlangen für die Blue-Linie und die Green-Linie. Wenn wir über die Datenbank selbst sprechen, haben wir sie absichtlich so weit wie möglich eingeengt und fast alles in Warteschlangen umgelagert, in der Datenbank speichern wir nur den Transaktionsstapel. Und der Transaktionsstapel ist für alle Linien einheitlich. In diesem Kontext teilen wir die Datenbank nicht zwischen Blue und Green, da beide Codevarianten wissen müssen, was mit der Transaktion passiert.
Freunde, ich habe noch einen kleinen Anreiz für euch – ein Buch. Und ich möchte es für die beste Frage überreichen.
Frage: – Guten Tag. Danke für den Vortrag. Ich habe eine Frage. Sie überwachen Zahlungen, Sie überwachen die Dienste, mit denen Sie interagieren... Aber wie überwachen Sie, dass eine Person auf Ihre Zahlungsseite gekommen ist, die Zahlung ausgeführt hat und das Projekt ihr das Geld gutgeschrieben hat? Also, wie überwachen Sie, dass der Händler verfügbar ist und Ihren Callback akzeptiert hat?
EK: – Der »Merchant« wird in diesem Fall als ein externes System betrachtet, genau wie das Zahlungssystem. Wir überwachen die Antwortzeit des »Merchants«.
Über die Datenbankverschlüsselung
Frage: – Guten Tag. Ich habe eine kurze Frage dazu. Sie haben sensible Daten gemäß PCI DSS. Ich wollte wissen, wie Sie PANs, die Sie durchleiten müssen, in den Warteschlangen speichern? Nutzen Sie irgendeine Verschlüsselung? Und hieraus ergibt sich die zweite Frage: Laut PCI DSS müssen Sie die Datenbank regelmäßig neu verschlüsseln bei Änderungen (z.B. im Falle von Entlassungen von Administratoren) – wie wirkt sich das auf die Verfügbarkeit aus?
EK: – Eine hervorragende Frage! Erstens speichern wir keine PANs in den Warteschlangen. Wir sind grundsätzlich nicht berechtigt, PANs irgendwo unverschlüsselt zu speichern, weshalb wir einen speziellen Dienst verwenden (wir nennen ihn »Keydaemon«) – dieser Dienst macht nur eines: er nimmt eine Nachricht entgegen und gibt die Nachricht verschlüsselt zurück. Und wir speichern alles mit dieser verschlüsselten Nachricht. Dementsprechend haben wir eine Schlüssellänge von etwa einem Kilobyte, um es wirklich ernsthaft und sicher zu machen.Frage: – Braucht man jetzt schon 2 Kilobyte?
EK: – Gestern waren es noch 256… Wie viel mehr noch?!
Das ist also das erste. Und zweitens, die vorhandene Lösung unterstützt das Verfahren zur Neucodierung – es gibt zwei Paare von "Keys" (Schlüsseln), die "DEKs" (Datenverschlüsselungsschlüssel) erzeugen, die die Daten verschlüsseln (Key – das sind die Schlüssel, DEK – das sind Abkömmlinge der Schlüssel, die die Daten verschlüsseln). Im Falle der Initiierung des Verfahrens (das regelmäßig alle 3 Monate bis ± etwas erfolgt) laden wir ein neues Paar "Keys" hoch, und wir führen eine Neucodierung der Daten durch. Wir haben separate Dienste, die alle Daten extrahieren, neu verschlüsseln; neben den Daten wird der Schlüssel-Identifikator gespeichert, mit dem sie verschlüsselt wurden. Sobald die Daten mit den neuen Schlüsseln verschlüsselt sind, löschen wir die alten Schlüssel.
Manchmal müssen Zahlungen manuell bearbeitet werden…
Frage: – Das heißt, wenn eine Rückerstattung für eine bestimmte Transaktion eingeht, entschlüsseln Sie sie mit dem alten Schlüssel?
EK: – Ja.
Frage: – Dann habe ich noch eine kleine Frage. Wenn ein Fehler, ein Ausfall oder ein Vorfall auftritt, muss die Transaktion manuell durchgedrückt werden. So eine Situation kann auftreten.
EK: – Ja, das kommt vor.
Frage: – Woher haben Sie diese Daten? Oder gehen Sie selbst manuell in dieses Speicher?
EK: – Nein, das ist klar – wir haben ein Backoffice-System, das eine Schnittstelle für unseren Support enthält. Wenn wir den Status einer Transaktion nicht kennen (zum Beispiel, wenn das Zahlungssystem mit einem Timeout nicht geantwortet hat) – wissen wir im Voraus nichts, das heißt, wir weisen den endgültigen Status nur zu, wenn wir vollständig sicher sind. In diesem Fall werfen wir die Transaktion in einen speziellen Status zur manuellen Bearbeitung. Am Morgen des nächsten Tages, sobald der Support Informationen erhält, dass im Zahlungssystem solche Transaktionen übrig geblieben sind, bearbeiten sie diese manuell in dieser Schnittstelle.
Frage: – Ich habe ein paar Fragen. Eine davon betrifft die PCI DSS-Zone: Wie erfassen Sie die Protokolle aus ihrem Umfang? Diese Frage stellt sich, weil der Entwickler in die Protokolle alles Mögliche geschrieben haben könnte! Die zweite Frage: Wie spielen Sie Hotfixes aus? Manuell in der Datenbank – das ist eine Möglichkeit, aber es könnten auch kostenlose Hotfixes geben – wie ist da das Verfahren? Und die dritte Frage, die wahrscheinlich mit RTO und RPO zu tun hat. Ihre Verfügbarkeit lag bei 99,97, fast vier Neun, aber ich verstehe, dass Sie auch ein zweites Rechenzentrum, ein drittes und ein fünftes Rechenzentrum haben... Wie synchronisieren Sie diese, replizieren Sie sie und kümmern sich um alles andere?EK: – Lassen Sie uns mit der ersten Frage beginnen. War die erste Frage zu den Protokollen? Wenn wir Protokolle erstellen, gibt es eine Schicht, die alle sensiblen Daten maskiert. Sie schaut anhand von Masken und zusätzlichen Feldern. Dementsprechend werden bei uns die Protokolle bereits mit maskierten Daten und gemäß dem PCI DSS-Rahmen ausgegeben. Dies ist eine regelmäßige Aufgabe, die der Testabteilung zugewiesen ist. Sie müssen jede Aufgabe auch hinsichtlich der Protokolle, die sie erstellen, überprüfen, und dies ist eine der regelmäßigen Aufgaben bei der Code-Überprüfung, um sicherzustellen, dass der Entwickler nichts Aufzeichnendes vergessen hat. Eine regelmäßige Überprüfung erfolgt durch die Abteilung für Informationssicherheit etwa einmal pro Woche: Ausgewählte Protokolle vom letzten Tag werden genommen und durch einen speziellen Scanner-Analyzer von den Testservern verarbeitet, um alles zu überprüfen.
Zu Hotfixes. Diese sind in unseren Deployment-Vorgaben enthalten. Wir haben einen separaten Punkt zu Hotfixes. Wir sind der Ansicht, dass wir Hotfixes rund um die Uhr deployen, wann immer wir es für nötig halten. Sobald die Version erstellt, getestet und der Artefakt vorhanden ist, wird der diensthabende Systemadministrator auf Anruf aus dem Support hin gerufen und deployt dies, wenn es notwendig ist.Zu den »vier Neunen«. Die Zahl, die wir derzeit haben, wurde tatsächlich erreicht, und wir strebten sie bereits bei einem anderen Rechenzentrum an. Jetzt haben wir ein zweites Rechenzentrum, und wir beginnen, zwischen diesen zu routen. Die Frage der übergreifenden Replikation zwischen den Rechenzentren ist in der Tat eine nicht triviale Angelegenheit. Wir haben versucht, dies damals mit verschiedenen Mitteln zu lösen: Wir haben versucht, den gleichen 'Tarantel' zu verwenden – das hat bei uns nicht funktioniert, das sage ich gleich. Daher sind wir zu dem Schluss gekommen, dass wir 'Sense' manuell bestellen. Jedes unserer Anwendungen synchronisiert im Grunde im asynchronen Modus die erforderliche 'Change – Done'-Synchronisation zwischen den Rechenzentren.
Frage: – Wenn Sie ein zweites haben, warum dann nicht ein drittes? Weil Split-Brain noch niemand…
EK: – Bei uns gibt es kein "Split-Brain". Da jede Anwendung bei uns Multimaster verwendet, ist es uns egal, in welches Rechenzentrum die Anfrage kommt. Wir sind darauf eingestellt, dass, falls ein Rechenzentrum ausfällt (darauf haben wir uns vorbereitet) und während einer Benutzeranfrage auf ein zweites Rechenzentrum umgeschaltet wird, wir bereit sind, diesen Benutzer zu verlieren; das werden in der Tat nur absolute Einzelfälle sein.
Frage: – Guten Abend. Vielen Dank für den Vortrag. Sie haben von Ihrem Debugger erzählt, der in der Produktion bestimmte Testtransaktionen durchführt. Können Sie uns mehr über die Testtransaktionen erzählen? Wie tief geht das?
EK: – Es durchläuft den vollständigen Zyklus des gesamten Components. Für die Komponente gibt es keinen Unterschied zwischen Testtransaktionen und echten. Aus logischer Sicht ist es einfach ein separates Projekt im System, in dem nur Testtransaktionen durchgeführt werden.
Frage: – Und wo schneiden Sie sie ab? Hier hat Core gesendet…
EK: – Wir folgen in diesem Fall dem "Core" für Testtransaktionen… Wir haben ein Konzept namens Routing: "Core" weiß, an welches Zahlungssystem gesendet werden muss – wir senden an ein gefälschtes Zahlungssystem, das einfach eine HTTP-Abweisung liefert und das war's.
Frage: – Sagen Sie mir bitte, ist Ihre Anwendung als ein großes Monolith geschrieben oder haben Sie sie in Dienste oder sogar Mikrodienste unterteilt?
EK: – Wir haben natürlich kein Monolith, unser Ansatz ist serviceorientiert. Wir machen den Scherz, dass wir Dienste aus Monolithen haben – sie sind wirklich ziemlich groß. Man könnte sie nicht als Mikrodienste bezeichnen, aber sie sind immerhin Dienste, in denen verteilte Maschinen arbeiten.
Wenn der Dienst auf dem Server kompromittiert ist…
Frage: – Dann habe ich die nächste Frage. Selbst wenn es ein Monolith wäre, haben Sie gesagt, dass Sie viele dieser Instant-Server haben, die prinzipiell Daten verarbeiten. Die Frage ist: „Im Falle einer Kompromittierung eines der Instant-Server oder einer Anwendung, eines einzelnen Moduls, haben sie irgendeine Art von Zugriffskontrolle? Wer kann was tun? An wen kann man sich wenden, um welche Daten zu erhalten?
EK: – Ja, definitiv. Die Sicherheitsanforderungen sind ziemlich ernst. Zunächst einmal haben wir offene Datenkommunikationen, und es werden nur die Ports geöffnet, über die wir im Voraus den Datenverkehr erwarten. Wenn ein Bestandteil mit der Datenbank (zum Beispiel mit MySQL) über Port 5-4-3-2 kommuniziert, werden nur 5-4-3-2 geöffnet, und andere Ports sowie andere Verkehrsrichtungen werden nicht verfügbar sein. Darüber hinaus muss man verstehen, dass es in unserer Produktionsumgebung etwa 10 verschiedene Sicherheitskonturen gibt. Und selbst wenn die Anwendung auf irgendeine Weise kompromittiert wird, Gott bewahre, kann der Angreifer nicht auf die Serververwaltungskonsole zugreifen, da dies eine andere Sicherheitszone ist.Frage: – Mich interessiert in diesem Zusammenhang vor allem der Punkt, dass Sie bestimmte Verträge mit Diensten haben – was diese tun können, über welche "Aktionen" sie miteinander kommunizieren können… In einem normalen Ablauf fragen bestimmte Dienste bestimmte "Aktionen" von einem anderen Dienst an. Zu anderen wenden sie sich in der Regel nicht an, da sie andere Verantwortungsbereiche haben. Wenn jedoch einer von ihnen kompromittiert wird, kann er dann die "Aktionen" dieses Dienstes anfordern?...
EK: – Ich verstehe. Wenn die Kommunikation mit einem anderen Server im Normalfall überhaupt erlaubt war, dann – ja. Laut SLA-Vertrag überwachen wir nicht, dass dir nur die ersten 3 "Aktionen" erlaubt sind, während die 4. "Aktion" dir nicht erlaubt ist. Das wäre für uns wahrscheinlich überflüssig, da wir ohnehin ein 4-stufiges Schutzsystem für unsere Konturen haben. Wir ziehen es vor, uns durch Konturen zu schützen, anstatt auf der Ebene der inneren Struktur.
Wie Visa, MasterCard und "Sberbank" funktionieren
Frage: – Ich möchte einen Punkt in Bezug auf den Wechsel des Nutzers von einem Rechenzentrum zu einem anderen klären. Soweit ich weiß, arbeiten Visa und MasterCard mit dem binären Synchronprotokoll 8583, dort sind Mischungen vorhanden. Ich wollte wissen, ob es sich jetzt um den Wechsel handelt - sind das direkt Visa und MasterCard oder zu den Zahlungssystemen, zu den Prozessoren?
EK: – Das betrifft die Mischungen. Unsere Mischungen befinden sich in einem Rechenzentrum.
Frage: – Grob gesagt, haben Sie einen Verbindungspunkt?
EK: – Ja, bei Visa und MasterCard. Einfach, weil Visa und MasterCard erhebliche Investitionen in die Infrastruktur erfordern, um separate Verträge für den Erhalt eines zweiten Satzes von Mischungen abzuschließen, zum Beispiel. Sie sind innerhalb eines Rechenzentrums reserviert, aber falls, Gott bewahre, das Rechenzentrum, in dem die Mischungen für die Verbindung zu Visa und MasterCard stehen, ausfällt, dann wird die Verbindung zu Visa und MasterCard verloren sein...
Frage: – Wie können sie reserviert sein? Ich weiß, dass Visa grundsätzlich nur einen Anschluss zulässt!
EK: – Sie liefern die Hardware selbst. Auf jeden Fall kam die Hardware, die wir erhalten haben, mit einer internen redundanten Sicherung.
Frage: – Also, ist das der Stand von deren Connects Orange?..
EK: – Ja.
Frage: – Und wie ist es in diesem Fall: wenn Ihr Rechenzentrum ausfällt, wie nutzen Sie dann weiter? Oder stoppt einfach der Traffic?
EK: – Nein. In diesem Fall würden wir den Traffic einfach auf einen anderen Kanal umschalten, der natürlich teurer für uns und die Kunden wäre. Aber der Traffic würde nicht durch unsere direkte Verbindung zu 'Visa' oder 'MasterCard' laufen, sondern über die hypothetische 'Sberbank' (sehr vereinfacht gesagt).
Ich entschuldige mich aufrichtig, wenn ich die Mitarbeiter der 'Sberbank' getroffen habe. Aber laut unseren Statistiken fällt die 'Sberbank' am häufigsten unter den russischen Banken aus. Es vergeht kein Monat, in dem bei der 'Sberbank' nicht irgendetwas nicht funktioniert.

Ein wenig Werbung 🙂
Danke, dass Sie bei uns bleiben. Gefallen Ihnen unsere Artikel? Möchten Sie mehr interessante Inhalte sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder uns Ihren Freunden empfehlen. , eine einzigartige Alternative zu Einsteiger-Servern, die wir für Sie entwickelt haben: (Verfügbar sind Optionen mit RAID1 und RAID10, bis zu 24 Kerne und bis zu 40GB DDR4).
Dell R730xd im Equinix Tier IV Rechenzentrum in Amsterdam zum halben Preis? Nur bei uns in den Niederlanden! Dell R420 — 2x E5-2430 2.2GHz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — ab 99 $! Lesen Sie darüber



















Quelle: habr.com
