

HighLoad++ Moskau 2018, Kongresshalle. 9. November, 15:00 Uhr
Abstracts und Präsentation:
Yuri Nasretdinov (VKontakte): Der Bericht wird über die Erfahrungen mit der Implementierung von ClickHouse in unserem Unternehmen sprechen – warum wir es brauchen, wie viele Daten wir speichern, wie wir sie schreiben und so weiter.

Zusätzliche Materialien:
Yuri Nasretdinov: - Hallo zusammen! Mein Name ist Yuri Nasretdinov, wie ich bereits vorgestellt wurde. Ich arbeite bei VKontakte. Ich werde darüber sprechen, wie wir Daten aus unserer Serverflotte (Zehntausende) in ClickHouse einfügen.
Was sind Protokolle und warum werden sie gesammelt?
Was wir Ihnen sagen: Was wir gemacht haben, warum wir „ClickHouse“ brauchten bzw. warum wir es ausgewählt haben, welche Leistung Sie ungefähr erhalten können, ohne etwas speziell zu konfigurieren. Ich erzähle Ihnen weiter über Puffertabellen, über die Probleme, die wir damit hatten, und über unsere Lösungen, die wir aus Open Source entwickelt haben – KittenHouse und Lighthouse.
Warum mussten wir überhaupt etwas tun (auf VKontakte ist doch immer alles gut, oder?). Wir wollten Debug-Protokolle sammeln (und da waren Hunderte von Terabyte an Daten), vielleicht wäre es irgendwie bequemer, Statistiken zu berechnen; Und wir verfügen über eine Flotte von Zehntausenden Servern, von denen aus all dies erledigt werden muss.
Warum haben wir uns entschieden? Wir hatten wahrscheinlich Lösungen zum Speichern von Protokollen. Hier gibt es so ein öffentliches „Backend VK“. Ich empfehle dringend, es zu abonnieren.
Was sind Protokolle? Dies ist eine Engine, die leere Arrays zurückgibt. Engines in VK werden von anderen als Microservices bezeichnet. Und hier ist ein lächelnder Aufkleber (ziemlich viele Likes). Wie so? Nun, hören Sie weiter!

Womit können Protokolle gespeichert werden? Es ist unmöglich, Hadup nicht zu erwähnen. Dann zum Beispiel Rsyslog (Speichern dieser Protokolle in Dateien). LSD. Wer weiß, was LSD ist? Nein, nicht dieses LSD. Speichern Sie auch Dateien. Nun, ClickHouse ist eine seltsame Option.
Clickhouse und Wettbewerber: Anforderungen und Chancen
Was wollen wir? Wir möchten sicherstellen, dass wir uns nicht zu viele Gedanken über die Bedienung machen müssen, sodass es sofort funktioniert, vorzugsweise mit minimaler Konfiguration. Wir wollen viel schreiben, und zwar schnell. Und wir wollen es für alle möglichen Monate, Jahre, also für lange Zeit, behalten. Wir möchten vielleicht ein Problem verstehen, mit dem sie zu uns kamen und sagten: „Hier funktioniert etwas nicht“, und das war vor drei Monaten), und wir möchten sehen, was vor drei Monaten passiert ist. Datenkomprimierung – es ist klar, warum sie von Vorteil wäre – denn sie reduziert den Platzbedarf.

Und wir haben eine so interessante Anforderung: Manchmal schreiben wir die Ausgabe einiger Befehle (z. B. Protokolle), sie kann problemlos mehr als 4 Kilobyte groß sein. Und wenn das Ding über UDP funktioniert, dann muss es nichts ausgeben... es entsteht kein „Overhead“ für die Verbindung, und für eine große Anzahl von Servern ist das ein Plus.

Mal sehen, was Open Source uns bietet. Erstens haben wir die Logs Engine – das ist unsere Engine; Im Prinzip kann er alles, er kann sogar lange Zeilen schreiben. Nun, es komprimiert Daten nicht transparent – wir können große Spalten selbst komprimieren, wenn wir wollen ... wir wollen das natürlich nicht (wenn möglich). Das einzige Problem ist, dass er nur das preisgeben kann, was in seine Erinnerung passt; Um den Rest zu lesen, muss man sich das Binlog dieser Engine besorgen und dementsprechend dauert es ziemlich lange.

Welche anderen Möglichkeiten gibt es? Zum Beispiel „Hadup“. Einfache Bedienung... Wer glaubt, dass Hadup einfach einzurichten ist? Bei der Aufnahme gibt es natürlich keine Probleme. Beim Lesen tauchen manchmal Fragen auf. Im Prinzip würde ich sagen, wahrscheinlich nicht, insbesondere bei Protokollen. Langzeitspeicherung – natürlich ja, Datenkomprimierung – ja, lange Strings – klar ist, dass man aufzeichnen kann. Aber die Aufnahme von einer großen Anzahl von Servern... Sie müssen noch etwas selbst tun!
Rsyslog. Tatsächlich haben wir es als Backup-Option verwendet, damit wir es lesen konnten, ohne das Binlog zu sichern, aber es kann keine langen Zeilen schreiben; im Prinzip kann es nicht mehr als 4 Kilobyte schreiben. Sie müssen die Datenkomprimierung auf die gleiche Weise selbst durchführen. Das Lesen erfolgt aus Dateien.

Dann gibt es noch die „Badushka“-Entwicklung von LSD. Im Wesentlichen dasselbe wie „Rsyslog“: Es unterstützt lange Strings, kann aber nicht über UDP funktionieren und aus diesem Grund muss dort leider einiges umgeschrieben werden. LSD muss neu gestaltet werden, um von Zehntausenden Servern aufzeichnen zu können.

Und hier! Eine lustige Option ist ElasticSearch. Wie sagt man? Er kann gut lesen, das heißt, er liest schnell, aber nicht sehr gut im Schreiben. Erstens ist es sehr schwach, wenn es Daten komprimiert. Höchstwahrscheinlich erfordert eine vollständige Suche größere Datenstrukturen als das ursprüngliche Volumen. Die Bedienung ist schwierig und es treten häufig Probleme auf. Und noch einmal, die Aufnahme in Elastic – wir müssen alles selbst machen.

Hier ist ClickHouse natürlich eine ideale Option. Das Einzige ist, dass die Aufzeichnung von Zehntausenden Servern ein Problem darstellt. Aber zumindest gibt es ein Problem, wir können versuchen, es irgendwie zu lösen. Und der Rest des Berichts befasst sich mit diesem Problem. Welche Leistung können Sie von ClickHouse erwarten?
Wie werden wir es einfügen? MergeTree
Wer von Ihnen hat noch nichts von „ClickHouse“ gehört oder kennt es? Ich muss es dir sagen, nicht wahr? Sehr schnell. Die Einfügung dort - 1-2 Gigabit pro Sekunde, Bursts von bis zu 10 Gigabit pro Sekunde halten dieser Konfiguration tatsächlich stand - es gibt zwei 6-Kern-Xeons (also nicht einmal die leistungsstärksten), 256 Gigabyte RAM, 20 Terabyte im RAID (niemand konfiguriert, Standardeinstellungen). Alexey Milovidov, ClickHouse-Entwickler, sitzt wahrscheinlich da und weint, weil wir nichts konfiguriert haben (bei uns hat alles so funktioniert). Dementsprechend kann eine Abtastgeschwindigkeit von beispielsweise etwa 6 Milliarden Zeilen pro Sekunde erreicht werden, wenn die Daten gut komprimiert sind. Wenn Sie % in einer Textzeichenfolge mögen – 100 Millionen Zeilen pro Sekunde, dann scheint es ziemlich schnell zu sein.

Wie werden wir es einfügen? Nun, Sie wissen, dass VK PHP verwendet. Wir werden von jedem PHP-Worker über HTTP in „ClickHouse“ und in die MergeTree-Tabelle für jeden Datensatz einfügen. Wer sieht in diesem Schema ein Problem? Aus irgendeinem Grund hoben nicht alle die Hand. Lass mich dir sagen.
Erstens gibt es viele Server – dementsprechend wird es viele (schlechte) Verbindungen geben. Dann ist es besser, Daten nicht öfter als einmal pro Sekunde in MergeTree einzufügen. Und wer weiß warum? Okay okay. Ich erzähle Ihnen etwas mehr darüber. Eine weitere interessante Frage ist, dass wir keine Analysen durchführen, wir müssen die Daten nicht anreichern, wir brauchen keine Zwischenserver, wir wollen sie direkt in „ClickHouse“ einfügen (vorzugsweise – je direkter, desto besser).

Wie erfolgt dementsprechend das Einfügen in MergeTree? Warum ist es besser, nicht öfter als einmal pro Sekunde oder seltener hineinzustecken? Tatsache ist, dass „ClickHouse“ eine spaltenbasierte Datenbank ist und die Daten in aufsteigender Reihenfolge des Primärschlüssels sortiert. Wenn Sie eine Einfügung durchführen, wird eine Anzahl von Dateien erstellt, die mindestens der Anzahl der Spalten entspricht, in denen die Daten sortiert sind in aufsteigender Reihenfolge des Primärschlüssels (für jede Einfügung wird ein separates Verzeichnis erstellt, eine Reihe von Dateien auf der Festplatte). Dann erfolgt die nächste Einfügung und im Hintergrund werden sie zu größeren „Partitionen“ zusammengefasst. Da die Daten sortiert sind, ist es möglich, zwei sortierte Dateien „zusammenzuführen“, ohne viel Speicher zu verbrauchen.
Wenn Sie jedoch 10 Dateien für jede Einfügung schreiben, wird ClickHouse (oder Ihr Server) schnell beendet. Es wird daher empfohlen, in großen Stapeln einzufügen. Dementsprechend haben wir das erste Projekt nie in Produktion genommen. Wir haben sofort eines auf den Markt gebracht, das hier Nr. 2 hat:

Stellen Sie sich hier vor, dass es ungefähr tausend Server gibt, auf denen wir gestartet sind, es gibt nur PHP. Und auf jedem Server gibt es unseren lokalen Agenten, den wir „Kittenhouse“ nennen, der eine Verbindung mit „ClickHouse“ aufrechterhält und alle paar Sekunden Daten einfügt. Fügt Daten nicht in MergeTree, sondern in eine Puffertabelle ein, was genau dazu dient, ein direktes Einfügen in MergeTree zu vermeiden.
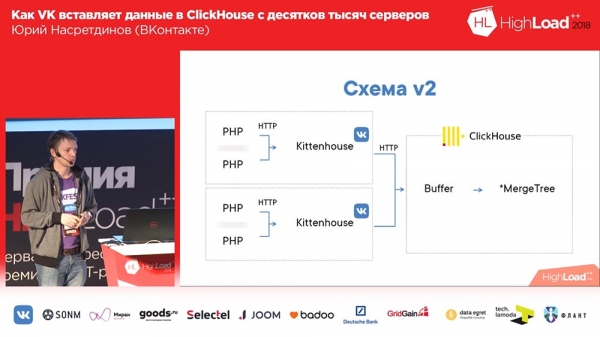
Arbeiten mit Puffertabellen
Was ist das? Puffertabellen sind ein Teil des Speichers, der geteilt ist (d. h. er kann häufig in ihn eingefügt werden). Sie bestehen aus mehreren Teilen, und jedes dieser Teile fungiert als unabhängiger Puffer und wird unabhängig geleert (wenn sich viele Teile im Puffer befinden, werden viele Einfügungen pro Sekunde vorgenommen). Es ist möglich, aus diesen Tabellen zu lesen – dann lesen Sie die Vereinigung des Inhalts des Puffers und der übergeordneten Tabelle, aber in diesem Moment ist das Schreiben blockiert, daher ist es besser, nicht von dort zu lesen. Und Puffertabellen zeigen sehr gute QPS, das heißt, bis zu 3 QPS werden Sie beim Einfügen überhaupt keine Probleme haben. Es ist klar, dass bei einem Stromausfall des Servers die Daten verloren gehen können, da sie nur im Speicher gespeichert waren.

Gleichzeitig erschwert das Schema mit einem Puffer ALTER, da Sie zuerst die alte Puffertabelle mit dem alten Schema löschen müssen (die Daten verschwinden nirgendwo, da sie geleert werden, bevor die Tabelle gelöscht wird). Anschließend „ändern“ Sie die benötigte Tabelle und erstellen die Puffertabelle erneut. Obwohl es keine Puffertabelle gibt, fließen Ihre Daten daher nirgendwo hin, aber Sie können sie zumindest lokal auf der Festplatte haben.

Was ist Kittenhouse und wie funktioniert es?
Was ist KittenHouse? Dies ist ein Proxy. Ratet mal, welche Sprache? Die angesagtesten Themen habe ich in meinem Bericht gesammelt – „Clickhouse“, Go, vielleicht fällt mir noch etwas anderes ein. Ja, das ist in Go geschrieben, weil ich nicht wirklich weiß, wie man in C schreibt, das möchte ich auch nicht.

Dementsprechend unterhält es eine Verbindung mit jedem Server und kann in den Speicher schreiben. Wenn wir beispielsweise Fehlerprotokolle in Clickhouse schreiben und Clickhouse keine Zeit zum Einfügen von Daten hat (wenn schließlich zu viel geschrieben wird), erhöhen wir den Speicher nicht, sondern werfen den Rest einfach weg. Denn wenn wir mehrere Gigabit pro Sekunde an Fehlern schreiben, können wir wahrscheinlich einige davon wegwerfen. Kittenhouse kann das tun. Darüber hinaus kann es eine zuverlässige Zustellung durchführen, d. h. auf die Festplatte des lokalen Computers schreiben und jedes Mal (dort alle paar Sekunden) versuchen, Daten aus dieser Datei zu übermitteln. Und zuerst haben wir das reguläre Werteformat verwendet – kein Binärformat, ein Textformat (wie in regulärem SQL).
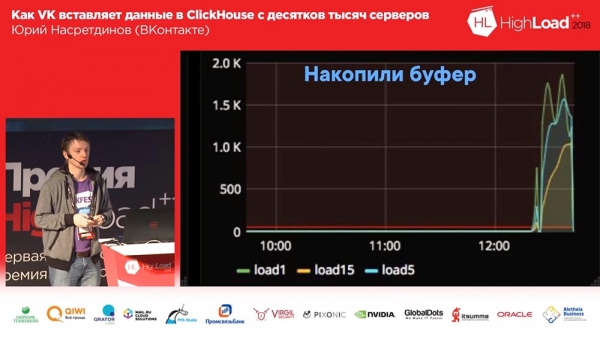
Aber dann passierte das. Wir nutzten die zuverlässige Zustellung, schrieben Protokolle und entschieden dann (es war ein bedingter Testcluster) ... Es wurde mehrere Stunden lang ausgesetzt und wieder hochgefahren, und eine Einfügung begann von tausend Servern – es stellte sich heraus, dass Clickhouse immer noch einen hatte „Thread on Connection“ – dementsprechend führt ein aktives Einfügen bei tausend Verbindungen zu einer durchschnittlichen Auslastung des Servers von etwa eineinhalbtausend. Überraschenderweise akzeptierte der Server zwar Anfragen, die Daten wurden aber nach einiger Zeit trotzdem eingefügt; aber es war sehr schwierig für den Kellner, es zu servieren...
Nginx hinzufügen
Eine solche Lösung für das Thread-pro-Verbindungsmodell ist Nginx. Wir haben nginx vor Clickhouse installiert, gleichzeitig den Ausgleich für zwei Replikate eingerichtet (unsere Einfügungsgeschwindigkeit hat sich um das Zweifache erhöht, obwohl dies nicht der Fall sein sollte) und die Anzahl der Verbindungen zu Clickhouse auf begrenzt Upstream und dementsprechend mehr , als in 2 Verbindungen scheint es keinen Sinn zu machen, einzufügen.
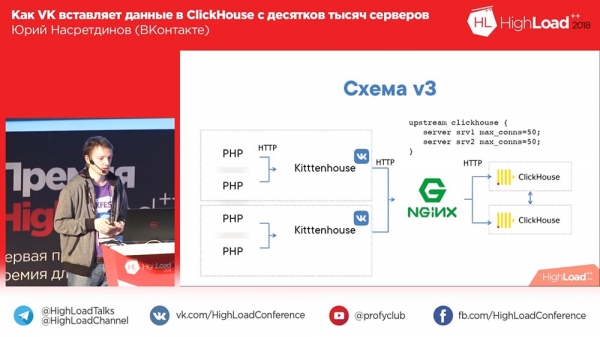
Dann wurde uns klar, dass dieses Schema grundsätzlich Nachteile hat, da wir hier nur einen Nginx haben. Wenn dieser Nginx trotz vorhandener Replikate abstürzt, verlieren wir dementsprechend Daten oder schreiben zumindest nirgendwo hin. Aus diesem Grund haben wir unseren eigenen Lastausgleich erstellt. Wir stellten auch fest, dass „Clickhouse“ immer noch für Protokolle geeignet ist, und der „Dämon“ begann auch, seine Protokolle in „Clickhouse“ zu schreiben – sehr praktisch, um ehrlich zu sein. Wir verwenden es immer noch für andere „Dämonen“.

Dann haben wir dieses interessante Problem entdeckt: Wenn Sie im SQL-Modus eine nicht standardmäßige Einfügemethode verwenden, wird ein vollwertiger AST-basierter SQL-Parser erzwungen, der ziemlich langsam ist. Dementsprechend haben wir Einstellungen hinzugefügt, um sicherzustellen, dass dies nie passiert. Wir haben einen Lastausgleich und Gesundheitsprüfungen durchgeführt, damit wir die Daten auch dann behalten, wenn einer ausfällt. Wir haben jetzt ziemlich viele Tabellen, die wir für verschiedene Clickhouse-Cluster benötigen. Und wir haben auch angefangen, über andere Verwendungsmöglichkeiten nachzudenken – zum Beispiel wollten wir Protokolle von Nginx-Modulen schreiben, aber sie wissen nicht, wie sie mit unserem RPC kommunizieren sollen. Nun, ich würde ihnen gerne beibringen, wie man zumindest irgendwie sendet – zum Beispiel, Ereignisse auf localhost über UDP zu empfangen und sie dann an Clickhouse weiterzuleiten.
Einen Schritt von der Lösung entfernt
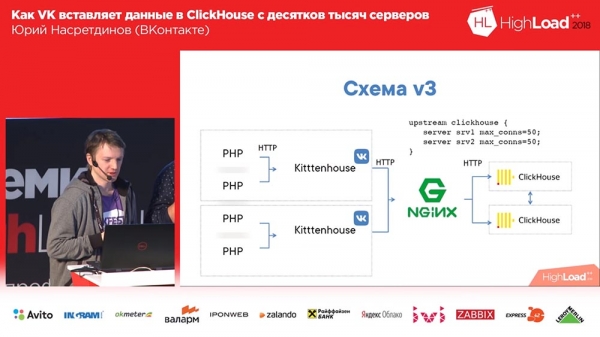
Das endgültige Schema sah folgendermaßen aus (die vierte Version dieses Schemas): Auf jedem Server vor Clickhouse befindet sich Nginx (auf demselben Server) und es leitet Anfragen einfach an Localhost weiter, wobei die Anzahl der Verbindungen auf 50 begrenzt ist Stücke. Und dieses Schema hat bereits ganz gut funktioniert, alles war ziemlich gut damit.
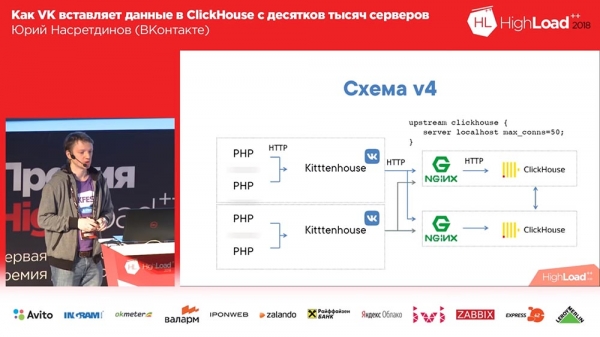
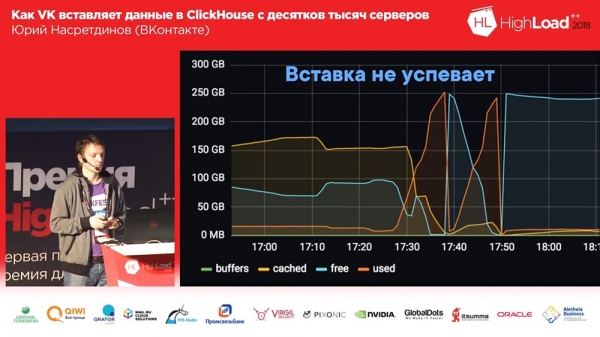
So lebten wir etwa einen Monat lang. Alle waren zufrieden, sie fügten Tabellen hinzu, sie fügten hinzu, sie fügten hinzu ... Generell stellte sich heraus, dass die Art und Weise, wie wir Puffertabellen hinzugefügt haben, nicht sehr optimal war (sagen wir mal so). Wir haben 16 Stücke in jeder Tabelle und ein Flash-Intervall von ein paar Sekunden gemacht; Wir hatten 20 Tische und jeder Tisch erhielt 8 Einfügungen pro Sekunde – und an diesem Punkt begann „Clickhouse“ ... die Aufzeichnungen begannen langsamer zu werden. Sie gingen nicht einmal durch ... Nginx hatte standardmäßig eine so interessante Sache, dass, wenn Verbindungen im Upstream endeten, bei allen neuen Anfragen einfach „502“ zurückgegeben wurde.

Und hier haben wir (ich habe mir gerade die Protokolle in Clickhouse selbst angesehen) etwa ein halbes Prozent der Anfragen fehlgeschlagen. Dementsprechend hoch war die Festplattenauslastung, es kam zu vielen Zusammenführungen. Nun, was habe ich getan? Natürlich habe ich mich nicht darum gekümmert, herauszufinden, warum genau die Verbindung und der Upstream beendet wurden.
Ersetzen von Nginx durch einen Reverse-Proxy
Ich entschied, dass wir das selbst verwalten müssen, wir müssen es nicht Nginx überlassen – Nginx weiß nicht, welche Tabellen es in Clickhouse gibt, und ich habe Nginx durch einen Reverse-Proxy ersetzt, den ich auch selbst geschrieben habe.
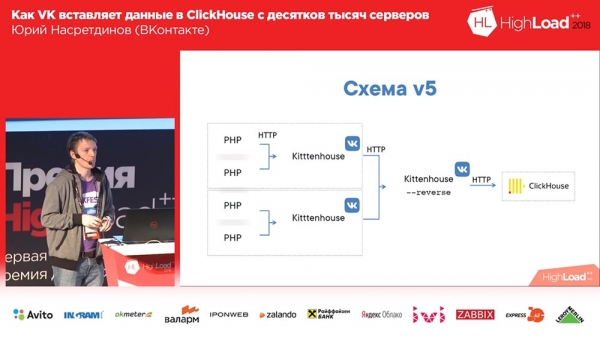
Was macht er? Es funktioniert auf Basis der fasthttp-Bibliothek „goshnoy“, also schnell, fast so schnell wie Nginx. Tut mir leid, Igor, falls Sie hier anwesend sind (Hinweis: Igor Sysoev ist ein russischer Programmierer, der den Nginx-Webserver erstellt hat). Es kann verstehen, um welche Art von Abfragen es sich handelt – INSERT oder SELECT – und hält dementsprechend unterschiedliche Verbindungspools für verschiedene Arten von Abfragen bereit.

Selbst wenn wir keine Zeit haben, die Einfügungsanfragen abzuschließen, werden die „Auswahlen“ daher bestanden und umgekehrt. Und es gruppiert die Daten in Puffertabellen – mit einem kleinen Puffer: Wenn es irgendwelche Fehler, Syntaxfehler usw. gab – so dass sie den Rest der Daten nicht stark beeinträchtigen würden, denn wenn wir sie einfach in Puffertabellen einfügten, würden wir hatte ein kleines „bachi“, und alle Syntaxfehler betrafen nur dieses kleine Stück; und hier wirken sie sich bereits auf einen großen Puffer aus. Klein ist 1 Megabyte, also nicht so klein.
Das Einfügen einer Synchronisierung und das Ersetzen von Nginx bewirkt im Wesentlichen dasselbe wie Nginx zuvor – Sie müssen dafür das lokale „Kittenhouse“ nicht ändern. Und da fasthttp verwendet wird, ist es sehr schnell – Sie können über einen Reverse-Proxy mehr als 100 Anfragen pro Sekunde für einzelne Einfügungen stellen. Theoretisch können Sie jeweils eine Zeile in den Kittenhouse-Reverse-Proxy einfügen, aber das machen wir natürlich nicht.
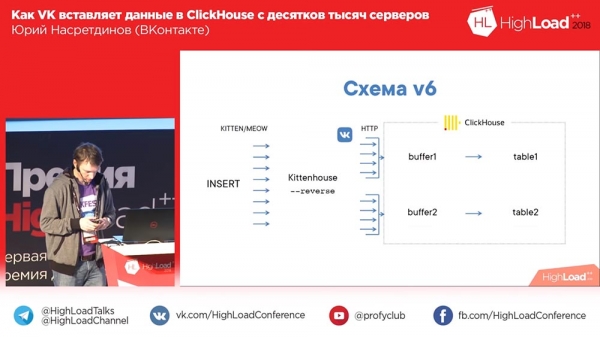
Das Schema begann so auszusehen: „Kittenhouse“, der Reverse-Proxy gruppiert viele Anfragen in Tabellen und die Puffertabellen fügen sie wiederum in die Haupttabellen ein.
Killer ist eine vorübergehende Lösung, Kitten ist dauerhaft
Das ist ein interessantes Problem ... Hat jemand von euch fasthttp verwendet? Wer hat fasthttp mit POST-Anfragen verwendet? Wahrscheinlich hätte dies wirklich nicht geschehen sollen, da der Anforderungstext standardmäßig gepuffert wird und unsere Puffergröße auf 16 Megabyte eingestellt war. Das Einfügen hörte irgendwann auf, und es trafen 16-Megabyte-Blöcke von allen Zehntausenden von Servern ein, die alle im Speicher zwischengespeichert wurden, bevor sie an Clickhouse gesendet wurden. Dementsprechend ging der Speicher zur Neige, der Out-Of-Memory-Killer kam und tötete den Reverse-Proxy (oder „Clickhouse“, der theoretisch mehr „fressen“ könnte als der Reverse-Proxy). Der Zyklus wiederholte sich. Kein sehr angenehmes Problem. Allerdings sind wir erst nach mehreren Monaten Betrieb darauf gestoßen.
Was ich getan habe? Auch hier möchte ich nicht wirklich verstehen, was genau passiert ist. Ich denke, es ist ziemlich offensichtlich, dass Sie nicht in den Speicher puffern sollten. Ich konnte fasthttp nicht patchen, obwohl ich es versucht habe. Aber ich habe einen Weg gefunden, es so zu gestalten, dass nichts gepatcht werden muss, und habe meine eigene Methode in HTTP entwickelt – ich habe sie KITTEN genannt. Nun, es ist logisch – „VK“, „Kitten“... Was sonst?...

Kommt mit der Kitten-Methode eine Anfrage an den Server, dann sollte der Server logischerweise mit „miau“ antworten. Wenn er darauf antwortet, wird davon ausgegangen, dass er dieses Protokoll versteht, und dann fange ich die Verbindung ab (Fasthttp verfügt über eine solche Methode) und die Verbindung wechselt in den „Roh“-Modus. Warum brauche ich es? Ich möchte steuern, wie das Lesen von TCP-Verbindungen erfolgt. TCP hat eine wunderbare Eigenschaft: Wenn niemand von der anderen Seite liest, beginnt der Schreibvorgang zu warten, und der Speicher wird dafür nicht besonders aufgewendet.
Und so lese ich jeweils von etwa 50 Kunden (von fünfzig, denn fünfzig sollten auf jeden Fall ausreichen, auch wenn der Tarif von einem anderen DC kommt) ... Der Verbrauch ist mit diesem Ansatz mindestens um das Zwanzigfache gesunken, aber ich, um ehrlich zu sein , ich konnte nicht genau messen, wie spät es ist, weil es bereits sinnlos ist (es hat bereits die Fehlergrenze erreicht). Das Protokoll ist binär, das heißt, es enthält den Tabellennamen und die Daten. Es gibt keine http-Header, daher habe ich keinen Web-Socket verwendet (ich muss nicht mit Browsern kommunizieren – ich habe ein Protokoll erstellt, das unseren Anforderungen entspricht). Und alles wurde gut mit ihm.
Die Puffertabelle ist traurig
Kürzlich sind wir auf ein weiteres interessantes Feature von Puffertabellen gestoßen. Und dieses Problem ist bereits viel schmerzhafter als die anderen. Stellen wir uns folgende Situation vor: Sie nutzen Clickhouse bereits aktiv, Sie haben Dutzende von Clickhouse-Servern und Sie haben einige Anfragen, deren Lesen sehr lange dauert (sagen wir mehr als 60 Sekunden); und Sie kommen und machen in diesem Moment Alter ... In der Zwischenzeit werden „Selects“, die vor „Alter“ begonnen haben, nicht in dieser Tabelle enthalten sein, „Alter“ wird nicht gestartet – wahrscheinlich einige Funktionen der Funktionsweise von „Clickhouse“. dieser Ort. Vielleicht lässt sich das beheben? Oder ist es unmöglich?

Im Allgemeinen ist klar, dass dies in Wirklichkeit kein so großes Problem darstellt, aber bei Puffertabellen wird es schmerzhafter. Denn wenn, sagen wir, Ihre „Alter“-Zeitüberschreitungen auftreten (und es möglicherweise auf einem anderen Host zu Zeitüberschreitungen kommt – nicht auf Ihrem, sondern beispielsweise auf einem Replikat), dann … Sie haben die Puffertabelle, Ihre „Alter“ ( (oder ein anderer Host) ist abgelaufen. Dann ist ein „Alter“-Fehler aufgetreten) – Sie müssen dennoch sicherstellen, dass die Daten weiterhin geschrieben werden: Sie erstellen dann die Puffertabellen wieder (nach dem gleichen Schema wie die übergeordnete Tabelle). „Alter“ geht durch, endet schließlich, und der Puffer der Tabelle beginnt sich im Schema vom übergeordneten zu unterscheiden. Je nachdem, was der „Alter“ war, geht die Einfügung möglicherweise nicht mehr in diese Puffertabelle – das ist sehr traurig.

Es gibt auch ein solches Zeichen (vielleicht ist es jemandem aufgefallen) – es heißt in neuen Versionen von Clickhouse query_thread_log. In einigen Versionen gab es standardmäßig eine. Hier haben wir in wenigen Monaten 840 Millionen Datensätze (100 Gigabyte) angesammelt. Dies liegt daran, dass dort „Einfügungen“ geschrieben wurden (vielleicht sind sie jetzt übrigens nicht geschrieben). Wie ich Ihnen bereits sagte, sind unsere „Einfügungen“ klein – wir hatten viele „Einfügungen“ in den Puffertabellen. Es ist klar, dass dies deaktiviert ist – ich erzähle Ihnen nur, was ich auf unserem Server gesehen habe. Warum? Dies ist ein weiteres Argument gegen die Verwendung von Puffertabellen! Spotty ist sehr traurig.

Wer wusste, dass der Name dieses Kerls Spotty war? VK-Mitarbeiter hoben die Hände. Okay.
Über die Pläne für „KitttenHouse“
Pläne werden normalerweise nicht geteilt, oder? Plötzlich werden Sie diese nicht mehr erfüllen und in den Augen anderer Menschen nicht besonders gut aussehen. Aber ich gehe das Risiko ein! Wir wollen Folgendes tun: Puffertabellen sind meiner Meinung nach immer noch eine Krücke und wir müssen die Einfügung selbst puffern. Aber wir möchten es immer noch nicht auf der Festplatte puffern, also puffern wir die Einfügung im Speicher.

Dementsprechend ist eine „Einfügung“ nicht mehr synchron – sie funktioniert bereits als Puffertabelle, fügt (naja, irgendwann später) in die übergeordnete Tabelle ein und meldet über einen separaten Kanal, welche Einfügungen stattgefunden haben und welche nicht haben.

Warum kann ich den Synchroneinsatz nicht verlassen? Es ist viel bequemer. Tatsache ist, dass, wenn Sie von 10 Hosts einfügen, alles in Ordnung ist – Sie erhalten von jedem Host ein wenig, wenn Sie dort einmal pro Sekunde einfügen, ist alles in Ordnung. Aber ich möchte, dass dieses Schema beispielsweise von zwei Maschinen aus funktioniert, sodass Sie mit hoher Geschwindigkeit herunterladen können – vielleicht nicht das Maximum aus Clickhouse herausholen, aber mindestens 100 Megabyte pro Sekunde von einer Maschine über einen Reverse-Proxy schreiben – Dabei muss das Schema sowohl auf große als auch auf kleine Mengen skaliert werden, sodass wir nicht eine Sekunde auf jede Einfügung warten können, es muss also asynchron sein. Und auf die gleiche Weise sollten asynchrone Bestätigungen erfolgen, nachdem die Einfügung abgeschlossen ist. Wir werden wissen, ob es bestanden hat oder nicht.
Das Wichtigste ist, dass wir bei diesem Schema sicher wissen, ob die Einfügung stattgefunden hat oder nicht. Stellen Sie sich folgende Situation vor: Sie haben eine Puffertabelle, Sie haben etwas hineingeschrieben, und dann ging die Tabelle, sagen wir, in den schreibgeschützten Modus über und versuchte, den Puffer zu leeren. Wohin gehen die Daten? Sie bleiben im Puffer. Aber wir können uns dessen nicht sicher sein – was ist, wenn ein anderer Fehler auftritt, aufgrund dessen die Daten nicht im Puffer verbleiben... (Ansprachen an Alexey Milovidov, Yandex, ClickHouse-Entwickler) Oder bleiben sie bestehen? Stets? Alexey überzeugt uns, dass alles gut wird. Wir haben keinen Grund, ihm nicht zu glauben. Aber egal: Wenn wir keine Puffertabellen verwenden, wird es damit keine Probleme geben. Auch das Erstellen doppelt so vieler Tabellen ist umständlich, obwohl es im Prinzip keine großen Probleme gibt. Das ist der Plan.
Reden wir über das Lesen
Lassen Sie uns nun über das Lesen sprechen. Wir haben hier auch unser eigenes Tool geschrieben. Es scheint, warum sollte man hier sein eigenes Instrument schreiben? Und wer hat Tabix verwendet? Irgendwie hoben nur wenige die Hand... Und wer ist mit der Leistung von Tabix zufrieden? Nun, wir sind damit nicht zufrieden und es ist nicht sehr praktisch, um Daten anzuzeigen. Für Analysen ist es in Ordnung, aber nur für die Anzeige ist es eindeutig nicht optimiert. Also habe ich mein eigenes Interface geschrieben.

Es ist ganz einfach: Es können nur Daten gelesen werden. Er weiß nicht, wie man Grafiken zeigt, er weiß nicht, wie man irgendetwas macht. Aber es kann zeigen, was wir brauchen: zum Beispiel, wie viele Zeilen die Tabelle hat, wie viel Platz sie einnimmt (ohne sie in Spalten aufzuteilen), das heißt, wir brauchen eine sehr einfache Schnittstelle.
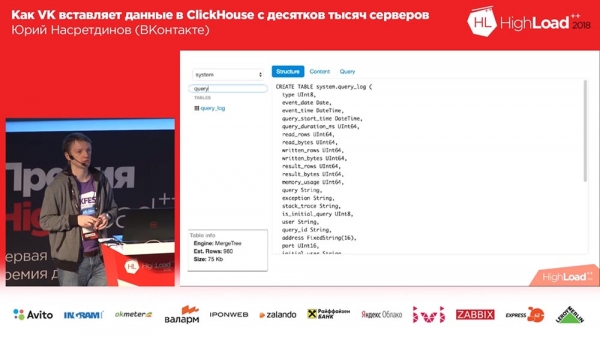
Und es sieht Sequel Pro sehr ähnlich, wurde aber nur auf Twitters Bootstrap und der zweiten Version erstellt. Sie fragen: „Yuri, warum in der zweiten Version?“ Welches Jahr? 2018? Im Allgemeinen habe ich das vor ziemlich langer Zeit für „Muscle“ (MySQL) gemacht und dort nur ein paar Zeilen in den Abfragen geändert, und schon hat es für „Clickhouse“ angefangen zu funktionieren, wofür ich mich besonders bedanke! Weil der Parser dem „Muskel“-Parser sehr ähnlich ist und die Abfragen sehr ähnlich sind – sehr praktisch, besonders auf den ersten Blick.
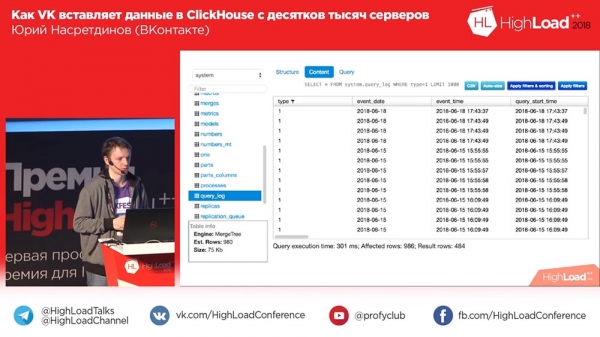
Nun, es kann Tabellen filtern, die Struktur und den Inhalt der Tabelle anzeigen, das Sortieren und Filtern nach Spalten ermöglichen, die Abfrage anzeigen, die zum Ergebnis geführt hat, die betroffenen Zeilen (wie viele als Ergebnis), d. h Grundlegende Dinge zum Anzeigen von Daten. Sehr schnell.
Es gibt auch einen Redakteur. Ich habe ehrlich gesagt versucht, den gesamten Editor von Tabix zu stehlen, aber es ist mir nicht gelungen. Aber irgendwie funktioniert es. Im Prinzip ist das alles.
„Clickhouse“ ist für Höhlen geeignet
Ich möchte Ihnen sagen, dass Clickhouse trotz aller beschriebenen Probleme sehr gut für Protokolle geeignet ist. Am wichtigsten ist, dass es unser Problem löst – es ist sehr schnell und ermöglicht das Filtern von Protokollen nach Spalten. Grundsätzlich haben Puffertabellen keine gute Leistung erbracht, aber normalerweise weiß niemand, warum ... Vielleicht wissen Sie jetzt besser, wo Sie Probleme haben werden.

TCP? Im Allgemeinen ist es in VK üblich, UDP zu verwenden. Und als ich TCP benutzte... Natürlich sagte mir niemand: „Juri, wovon redest du!“ Das geht nicht, du brauchst UDP.“ Es stellte sich heraus, dass TCP nicht so beängstigend ist. Das Einzige ist: Wenn Sie Zehntausende Wirkstoffe schreiben, müssen Sie diese etwas sorgfältiger vorbereiten; aber es ist möglich und ganz einfach.
Ich habe versprochen, „Kittenhouse“ und „Lighthouse“ auf HighLoad Siberia zu posten, wenn jeder unser öffentliches „VK-Backend“ abonniert ... Und wissen Sie, nicht jeder hat sich angemeldet ... Natürlich verlange ich nicht, dass Sie unser abonnieren öffentlich. Es sind immer noch zu viele von euch, vielleicht ist jemand sogar beleidigt, aber trotzdem bitte abonnieren (und hier muss ich Augen machen wie die einer Katze). Das ist . Herzlichen Dank! Github gehört uns . Mit Clickhouse werden Ihre Haare weich und seidig.

Moderator: - Freunde, jetzt für Fragen. Gleich im Anschluss überreichen wir Ihnen die Dankesurkunde und Ihren Bericht auf VHS.
Yuri Nasretdinov (im Folgenden als YN bezeichnet): – Wie konnten Sie meinen Bericht auf VHS aufnehmen, wenn er gerade zu Ende war?

Moderator: – Sie können auch nicht vollständig bestimmen, wie „Clickhouse“ funktionieren wird oder nicht! Freunde, 5 Minuten für Fragen!
Fragen
Frage aus dem Publikum (im Folgenden als Q bezeichnet): - Guten Tag. Vielen Dank für den Bericht. Ich habe zwei Fragen. Ich beginne mit etwas Frivolem: Hat die Anzahl der Buchstaben t im Namen „Kittenhouse“ in den Diagrammen (3, 4, 7...) einen Einfluss auf die Zufriedenheit der Katzen?
YN: - Menge wovon?
Z: – Buchstabe t. Es gibt drei Ts, ungefähr drei Ts.
YN: - Habe ich es nicht repariert? Nun, natürlich tut es das! Das sind verschiedene Produkte – ich habe Sie die ganze Zeit nur getäuscht. Okay, ich mache Witze – es spielt keine Rolle. Ah, genau hier! Nein, es ist dasselbe, ich habe einen Tippfehler gemacht.
Z: - Danke. Die zweite Frage ist ernst. Soweit ich weiß, befinden sich Puffertabellen in Clickhouse ausschließlich im Speicher, werden nicht auf der Festplatte gepuffert und sind dementsprechend nicht persistent.
YN: - Ja.
Z: – Und gleichzeitig puffert Ihr Client auf der Festplatte, was eine gewisse Garantie für die Lieferung dieser Protokolle bedeutet. Dies ist bei Clickhouse jedoch keineswegs garantiert. Erklären Sie, wie und aus welchem Grund die Garantie gewährt wird. Hier wird dieser Mechanismus im Detail beschrieben
YN: – Ja, theoretisch gibt es hier keine Widersprüche, denn wenn Clickhouse fällt, kann man es tatsächlich auf millionenfache Weise erkennen. Wenn Clickhouse abstürzt (wenn es falsch endet), können Sie, grob gesagt, ein wenig von Ihrem Protokoll zurückspulen, das Sie aufgeschrieben haben, und von dem Moment an beginnen, in dem alles in Ordnung war. Nehmen wir an, Sie spulen eine Minute zurück, das heißt, es wird davon ausgegangen, dass Sie in einer Minute alles gelöscht haben.
Z: – Das heißt, „Kittenhouse“ hält das Fenster länger und kann es im Falle eines Sturzes erkennen und zurückziehen?
YN: – Aber das ist nur Theorie. In der Praxis machen wir das nicht und die zuverlässige Lieferung reicht von Null bis Unendlich. Aber im Durchschnitt eins. Wir sind davon überzeugt, dass wir ein wenig verlieren, wenn Clickhouse aus irgendeinem Grund abstürzt oder die Server „neu starten“. In allen anderen Fällen passiert nichts.
Z: - Guten Tag. Von Anfang an hatte ich den Eindruck, dass Sie tatsächlich von Beginn des Berichts an UDP verwenden würden. Sie haben http, all das ... Und die meisten der von Ihnen beschriebenen Probleme wurden meines Wissens durch diese spezielle Lösung verursacht ...
YN: – Wofür verwenden wir TCP?
Z: - Im Wesentlichen ja.
YN: - Nein.
Z: – Mit fasthttp hatte man Probleme, mit der Verbindung hatte man Probleme. Wenn Sie nur UDP verwendet hätten, hätten Sie sich einiges an Zeit gespart. Nun, es würde Probleme mit langen Nachrichten oder etwas anderem geben ...
YN: - Mit was?

Z: – Bei langen Nachrichten, da sie möglicherweise nicht in die MTU passen, etwas anderes ... Nun, es kann eigene Probleme geben. Die Frage ist: Warum nicht UDP?
YN: – Ich glaube, dass die Autoren, die entwickelt haben TCP/IPAndere sind deutlich intelligenter als ich und können Pakete besser serialisieren (damit sie ankommen), gleichzeitig das Sendefenster anpassen, das Netzwerk nicht überlasten, Feedback darüber geben, was nicht gelesen wird, und die Gegenseite nicht mitzählen. All diese Probleme gäbe es meiner Meinung nach auch bei UDP, nur müsste ich noch mehr Code schreiben, um es selbst zu implementieren, und das höchstwahrscheinlich auch noch schlecht. Ich programmiere nicht mal gerne in C, geschweige denn dort…
Z: - Einfach praktisch! Der Versand ist in Ordnung und Sie müssen nicht auf irgendetwas warten – es ist völlig asynchron. Es kam eine Benachrichtigung zurück, dass alles in Ordnung sei – das heißt, es ist angekommen; Wenn es nicht kommt, bedeutet das, dass es schlecht ist.
YN: – Ich brauche beides – ich muss beides mit Liefergarantie und ohne Liefergarantie versenden können. Das sind zwei verschiedene Szenarien. Ich muss einige Protokolle nicht verlieren oder sie nicht in einem angemessenen Rahmen verlieren.
Z: – Ich werde keine Zeit verschwenden. Darüber muss noch mehr diskutiert werden. Danke.
Moderator: – Wer hat Fragen – Hände hoch!

Z: - Hallo, ich bin Sasha. Irgendwann in der Mitte des Berichts entstand das Gefühl, dass es zusätzlich zu TCP möglich sei, eine vorgefertigte Lösung zu verwenden – eine Art Kafka.
YN: – Nun ja... ich habe Ihnen gesagt, dass ich keine Zwischenserver verwenden möchte, denn... in Kafka stellt sich heraus, dass wir zehntausend Hosts haben; Tatsächlich haben wir mehr – Zehntausende von Hosts. Es kann auch schmerzhaft sein, mit Kafka ohne Proxys zu arbeiten. Darüber hinaus, was am wichtigsten ist, sorgt es immer noch für „Latenz“, es stellt zusätzliche Hosts zur Verfügung, die Sie benötigen. Aber ich will sie nicht haben – ich will...
Z: „Aber am Ende kam es trotzdem so.“
YN: – Nein, es gibt keine Gastgeber! Dies alles funktioniert auf Clickhouse-Hosts.
Z: - Na ja, und „Kittenhouse“, also das Gegenteil – wo wohnt er?

YN: – Auf dem Clickhouse-Host wird nichts auf die Festplatte geschrieben.
Z: - Nehmen wir mal an.
Moderator: - Sind Sie zufrieden? Können wir Ihnen ein Gehalt geben?
Z: - Ja, du kannst. Tatsächlich gibt es viele Krücken, um dasselbe zu erreichen, und nun widerspricht die vorherige Antwort zum Thema TCP meiner Meinung nach dieser Situation. Es kommt mir einfach so vor, als hätte ich alles in viel kürzerer Zeit auf den Knien erledigen können.
YN: – Und auch, warum ich Kafka nicht nutzen wollte, denn im Clickhouse-Telegram-Chat gab es ziemlich viele Beschwerden, dass beispielsweise Nachrichten von Kafka verloren gingen. Nicht von Kafka selbst, sondern in der Integration von Kafka und Clickhaus; oder irgendetwas hat dort keine Verbindung hergestellt. Grob gesagt wäre es dann notwendig, einen Mandanten für Kafka zu schreiben. Ich glaube nicht, dass es eine einfachere oder zuverlässigere Lösung geben könnte.
Z: – Sag mir, warum hast du es nicht mit Warteschlangen oder einer Art Sammelbus versucht? Da Sie sagen, dass Sie mit Asynchronität die Protokolle selbst über die Warteschlange senden und die Antwort asynchron über die Warteschlange empfangen könnten?

YN: – Bitte schlagen Sie vor, welche Warteschlangen verwendet werden könnten.
Z: – Alle, auch ohne Garantie, dass sie in Ordnung sind. Eine Art Redis, RMQ ...
YN: – Ich habe das Gefühl, dass Redis höchstwahrscheinlich nicht in der Lage sein wird, ein solches Einfügungsvolumen selbst auf einem Host (im Sinne mehrerer Server) abzurufen, der Clickhouse abruft. Ich kann dies nicht mit Beweisen untermauern (ich habe es nicht einem Benchmarking unterzogen), aber es scheint mir, dass Redis hier nicht die beste Lösung ist. Im Prinzip kann dieses System als improvisierte Nachrichtenwarteschlange betrachtet werden, die jedoch nur auf „Clickhouse“ zugeschnitten ist.
Moderator: – Yuri, vielen Dank. Ich schlage vor, die Fragen und Antworten hier zu beenden und zu sagen, wem wir das Buch geben werden.
YN: – Ich möchte der ersten Person, die eine Frage gestellt hat, ein Buch schenken.
Moderator: - Wunderbar! Großartig! Fabelhaft! Vielen Dank!

Einige Anzeigen 🙂
Vielen Dank, dass Sie bei uns geblieben sind. Gefallen Ihnen unsere Artikel? Möchten Sie weitere interessante Inhalte sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder an Freunde weiterempfehlen. , ein einzigartiges Analogon von Einstiegsservern, das von uns für Sie erfunden wurde: (verfügbar mit RAID1 und RAID10, bis zu 24 Kerne und bis zu 40 GB DDR4).
Dell R730xd 2-mal günstiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur hier in den Niederlanden! Dell R420 – 2x E5-2430 2.2 GHz 6C 128 GB DDR3 2 x 960 GB SSD 1 Gbit/s 100 TB – ab 99 $! Lesen über
Source: habr.com
