


Ich hatte die Aufgabe, einen Datenspeicher-Container zu implementieren, der folgende Funktionen bietet:
- ein neues Element einfügen
- ein Element nach seiner Reihenfolge entfernen
- ein Element nach seiner Reihenfolge abrufen
- die Daten werden sortiert gespeichert
Daten werden ständig hinzugefügt und entfernt, die Struktur muss eine schnelle Verarbeitungsgeschwindigkeit gewährleisten. Zunächst versuchte ich, etwas mit den Standardcontainern aus stdzu realisieren. Dieser Weg war jedoch nicht erfolgreich, und ich erkannte, dass ich etwas Eigenes entwickeln musste. Das einzige, was mir in den Sinn kam, war die Verwendung eines binären Suchbaums, da er die Anforderungen an schnelles Einfügen, Entfernen und die Speicherung von Daten in sortierter Form erfüllt. Jetzt muss ich nur noch überlegen, wie ich alle Elemente indizieren und die Indizes aktualisieren kann, wenn sich der Baum ändert.
struct node_s {
data_t data;
uint64_t weight; // Gewicht des Knotens
node_t *left;
node_t *right;
node_t *parent;
};Der Artikel wird mehr Bilder und Theorie als Code enthalten. Den Code können Sie über den Link unten einsehen.
Gewicht
Für diesen Zweck wurde der Baum leicht modifiziert, es wurde zusätzliche Information über das Gewicht hinzugefügt Knoten. Das Gewicht des Knotens beträgt die Anzahl der Nachfahren dieses Knotens + 1 (Gewicht eines einzelnen Elements).
Funktion zur Ermittlung des Knotengewichts:
uint64_t bntree::get_child_weight(node_t *node) {
if (node) {
return node->weight;
}
return 0;
}Bei einem Blatt beträgt das Gewicht entsprechend 0.
Lassen Sie uns nun ein anschauliches Beispiel für einen solchen Baum betrachten. Schwarz zeigt den Schlüssel des Knotens an (der Wert wird nicht angezeigt, da dies nicht notwendig ist), Rot zeigt das Gewicht des Knotens an, Grün zeigt den Index des Knotens an.
Wenn der Baum leer ist, beträgt sein Gewicht 0. Fügen wir ihm das Wurzelelement hinzu:
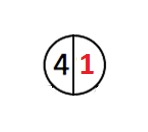
Das Gewicht des Baumes wird 1, das Gewicht des Wurzelelements beträgt 1. Das Gewicht des Wurzelelements ist das Gewicht des Baumes.
Fügen wir noch einige Elemente hinzu:
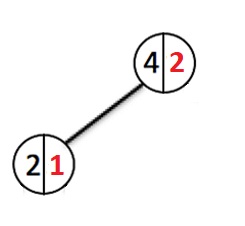
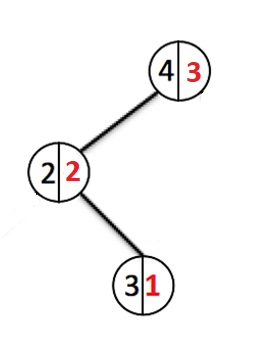
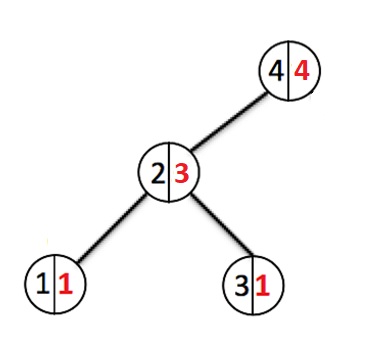
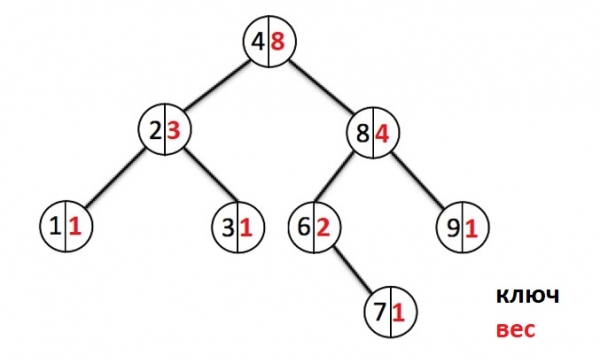
Jedes Mal, wenn ein neues Element hinzugefügt wird, gehen wir die Knoten nach unten und erhöhen den Gewichtszähler jedes durchlaufenen Knotens. Bei der Erstellung eines neuen Knotens wird ihm ein Gewicht zugewiesen 1. Wenn ein Knoten mit diesem Schlüssel bereits existiert, überschreiben wir den Wert und gehen zurück bis zur Wurzel, während wir die Gewichtungen aller Knoten, die wir durchlaufen haben, zurücksetzen.
Wenn ein Knoten gelöscht wird, gehen wir nach unten und dekrementieren die Gewichte der durchlaufenen Knoten.
Indizes
Kommen wir nun dazu, wie wir die Knoten indexieren. Knoten speichern ihren Index nicht, sondern dieser wird anhand des Gewichts der Knoten berechnet. Wenn sie ihren Index speichern würden, wäre es notwendig, O(n) Zeit aufzuwenden, um die Indizes aller Knoten nach jeder Änderung des Baums zu aktualisieren.
Sehen wir uns eine anschauliche Darstellung an. Unser Baum ist leer, wir fügen den ersten Knoten hinzu:
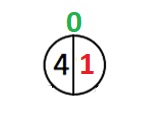
Der erste Knoten hat den Index 0, und nun gibt es zwei Möglichkeiten. Im ersten Fall ändert sich der Index des Wurzelelements, im zweiten Fall bleibt er unverändert.
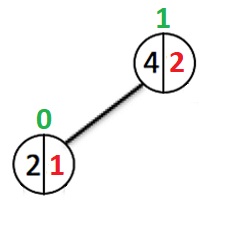
Das linke Teilbaumgewicht des Wurzelknotens beträgt 1.
Zweiter Fall:
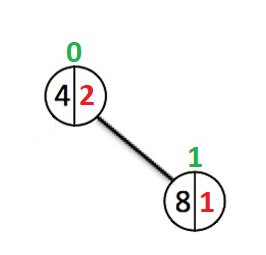
Der Index der Wurzel hat sich nicht geändert, da das Gewicht seines linken Teilbaums bei 0 geblieben ist.
Wie der Index eines Knotens berechnet wird, ist das Gewicht seines linken Teilbaums plus die Zahl, die vom Elternknoten weitergegeben wird. Was ist diese Zahl? Es ist der Zähler der Indizes, der anfangs gleich 0ist, da der Wurzelknoten keinen Elternknoten hat. Danach hängt alles davon ab, ob wir zum linken Kind oder zum rechten gehen. Wenn wir zum linken gehen, wird nichts zum Zähler hinzugefügt. Wenn wir zum rechten gehen, addieren wir den Index des aktuellen Knotens.
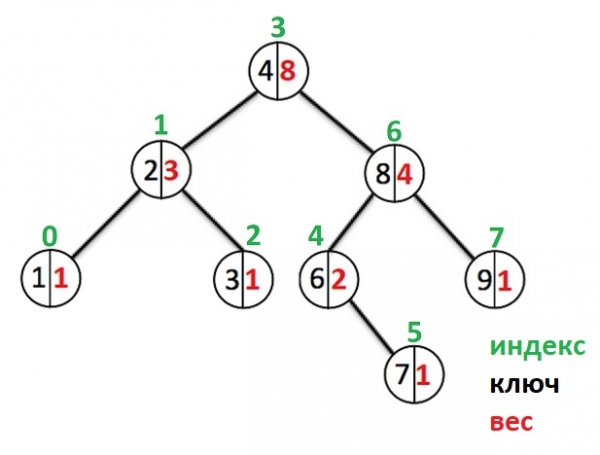
Zum Beispiel, wie der Index des Elements mit dem Schlüssel 8 (rechtes Kind des Wurzelknotens) berechnet wird. Das ist „Index der Wurzel“ + „Gewicht des linken Teilbaums des Knotens mit dem Schlüssel 8“ + „1“ == 3 + 2 + 1 == 6
Der Index des Elements mit dem Schlüssel 6 ist "Wurzelindex" + 1 == 3 + 1 == 4
Um also ein Element nach Index zu erhalten oder zu löschen, ist Zeit erforderlich. O(log n), da wir den benötigten Zugriff zuerst finden müssen (von der Wurzel bis zu diesem Element hinuntersteigen).
Tiefe
Anhand des Gewichts lässt sich auch die Tiefe des Baumes berechnen, die für die Balance erforderlich ist.
Dazu muss das Gewicht des aktuellen Knotens auf die nächstgrößere Zweierpotenz gerundet werden, die größer oder gleich dem gegebenen Gewicht ist, und dann wird der binäre Logarithmus davon genommen. So erhalten wir die Tiefe des Baumes, vorausgesetzt, er ist ausgewogen. Der Baum wird nach dem Einfügen eines neuen Elements balanciert. Ich werde die Theorie zur Balancierung von Bäumen nicht anführen. Die Quellcodes enthalten eine Funktion zur Balancierung.
Der Code zur Umschaltung des Gewichts auf die Tiefe.
/*
* Возвращает первое число в степени 2, которое больше или ровно x
*/
uint64_t bntree::cpl2(uint64_t x) {
x = x - 1;
x = x | (x >> 1);
x = x | (x >> 2);
x = x | (x >> 4);
x = x | (x >> 8);
x = x | (x >> 16);
x = x | (x >> 32);
return x + 1;
}
/*
* Двоичный логарифм от числа
*/
long bntree::ilog2(long d) {
int result;
std::frexp(d, &result);
return result - 1;
}
/*
* Вес к глубине
*/
uint64_t bntree::weight_to_depth(node_t *p) {
if (p == NULL) {
return 0;
}
if (p->weight == 1) {
return 1;
} else if (p->weight == 2) {
return 2;
}
return this->ilog2(this->cpl2(p->weight));
}Ergebnisse
- Das Einfügen eines neuen Elements erfolgt in O(log n)
- Das Löschen eines Elements nach der Reihenfolge erfolgt in O(log n)
- Der Zugriff auf ein Element nach der Reihenfolge erfolgt in O(log n)
Geschwindigkeit O(log n) Wir zahlen dafür, dass alle Daten in sortierter Form gespeichert werden.
Ich weiß nicht, wo eine solche Struktur nützlich sein könnte. Es ist einfach eine Aufgabe, um noch einmal zu verstehen, wie Bäume funktionieren. Danke für Ihre Aufmerksamkeit.
Links
Im Projekt befinden sich Testdaten zur Überprüfung der Arbeitsgeschwindigkeit. Der Baum wird gefüllt 1000000 Elementen. Und es erfolgen sequentielles Entfernen, Einfügen und Abrufen von Elementen 1000000 mal. Das bedeutet 3000000 Operationen. Das Ergebnis war durchaus anständig – ca. 8 Sekunden.
Quelle: habr.com
