


Die industrielle Entwicklung von Softwaresystemen erfordert große Aufmerksamkeit für die Ausfallsicherheit des Endprodukts sowie eine schnelle Reaktion auf Fehler und Störungen, wenn sie auftreten. Monitoring hilft zwar, effektiver und schneller auf Ausfälle zu reagieren, ist jedoch nicht ausreichend. Erstens ist es sehr schwierig, eine große Anzahl von Servern im Auge zu behalten – dafür wird eine Vielzahl von Personen benötigt. Zweitens muss man gut verstehen, wie die Anwendung funktioniert, um ihren Status prognostizieren zu können. Das bedeutet, dass viele Personen benötigt werden, die die von uns entwickelten Systeme sowie ihre Leistungskennzahlen und Besonderheiten gut verstehen. Angenommen, sogar wenn es gelingt, genügend Personen zu finden, die daran arbeiten möchten, benötigt es zudem viel Zeit, um sie auszubilden.
Was tun? Hier kommt uns die künstliche Intelligenz zu Hilfe. In diesem Artikel geht es um (predictive maintenance). Dieser Ansatz gewinnt zunehmend an Beliebtheit. Zahlreiche Artikel wurden darüber verfasst, auch auf Plattformen wie Habr. Große Unternehmen setzen diesen Ansatz intensiv ein, um die Betriebsfähigkeit ihrer Server zu gewährleisten. Nach einer gründlichen Analyse vieler Artikel haben wir beschlossen, diesen Ansatz auszuprobieren. Was dabei herausgekommen ist?
Einführung
Jedes entwickelte Softwaresystem wird früher oder später in Betrieb genommen. Für den Benutzer ist es wichtig, dass das System reibungslos funktioniert. Sollte dennoch eine Fehlfunktion auftreten, muss diese mit minimalen Verzögerungen behoben werden.
Um den technischen Support des Softwaresystems zu erleichtern, insbesondere wenn viele Server im Einsatz sind, werden in der Regel Überwachungsprogramme eingesetzt. Diese erfassen die Metriken des laufenden Systems, ermöglichen die Diagnose seines Zustands und helfen dabei festzustellen, was genau den Fehler verursacht hat. Dieser Prozess wird als Systemüberwachung bezeichnet.
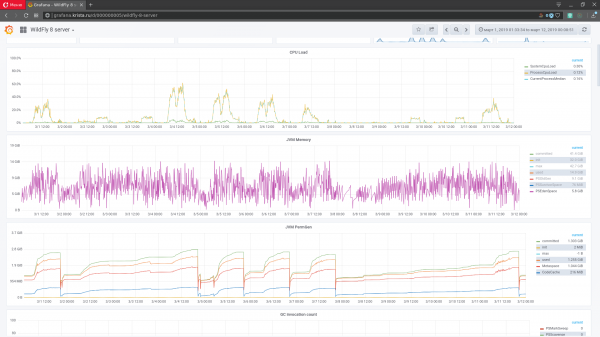
Abbildung 1. Schnittstelle zur Überwachung mit Grafana
Metriken sind verschiedene Kennzahlen eines Softwaresystems, seiner Ausführungsumgebung oder der physikalischen Rechenmaschine, auf der das System läuft, mit einem Zeitstempel, der den Moment angibt, in dem die Metriken erfasst wurden. In der statischen Analyse werden die Metrikdaten als Zeitreihen bezeichnet. Um den Zustand des Softwaresystems zu überwachen, werden die Metriken in Form von Diagrammen dargestellt: auf der X-Achse die Zeit und auf der Y-Achse die Werte (Abbildung 1). Aus einem laufenden Softwaresystem können mehrere Tausend Metriken (von jedem Knoten) erfasst werden. Sie bilden den Raum der Metriken (mehrdimensionale Zeitreihen).
Da komplexe Softwaresysteme eine Vielzahl von Metriken erfassen, wird die manuelle Überwachung zu einer anspruchsvollen Aufgabe. Um die von Administrators zu analysierenden Datenmengen zu reduzieren, bieten Monitoring-Tools Funktionen zur automatischen Erkennung möglicher Probleme. Beispielsweise kann ein Trigger eingerichtet werden, der auslöst, wenn der freie Speicherplatz die festgelegte Grenze erreicht. Auch das automatische Diagnostizieren eines Serverausfalls oder einer kritischen Verlangsamung der Dienstgeschwindigkeit ist möglich. In der Praxis bewältigen Monitoring-Tools die Erkennung bereits eingetretener Ausfälle oder das Aufspüren einfacher Symptome zukünftiger Ausfälle recht gut, jedoch bleibt die Vorhersage möglicher Störungen eine große Herausforderung. Die Prognose mittels manueller Analyse der Metriken erfordert den Einsatz qualifizierter Fachkräfte und ist ineffizient. Viele potenzielle Ausfälle könnten unentdeckt bleiben.
In letzter Zeit gewinnt das sogenannte prädiktive Wartung von Softwaresystemen unter großen IT-Unternehmen zunehmend an Bedeutung. Bei diesem Ansatz geht es darum, Störungen, die zur Degradation des Systems führen, frühzeitig zu identifizieren, bevor es zum Ausfall kommt, und zwar unter Verwendung von künstlicher Intelligenz. Dieser Ansatz schließt manuelle Systemüberwachung nicht vollständig aus, sondern dient als unterstützende Maßnahme für den Überwachungsprozess insgesamt.
Das Hauptinstrument zur Umsetzung der prädiktiven Wartung ist die Anomalieerkennung in Zeitreihen, da bei Auftreten einer Anomalie in den Daten eine hohe Wahrscheinlichkeit besteht, dass es nach einiger Zeit zu einem Fehler oder Ausfall kommt. Eine Anomalie ist eine Abweichung von den Kennzahlen eines Softwaresystems, wie die Feststellung einer Verschlechterung der Antwortgeschwindigkeit einer bestimmten Anfragetyp oder die Abnahme der durchschnittlichen Anzahl bearbeiteter Anfragen bei konstantem Client-Sitzungsniveau.
Die Identifizierung von Anomalien in Softwaresystemen hat ihre eigenen Besonderheiten. Grundsätzlich ist es notwendig, für jedes Softwaresystem bestehende Methoden zu entwickeln oder anzupassen, da die Anomalieerkennung stark von den Daten abhängt, in denen sie durchgeführt wird, und diese Daten in Abhängigkeit von den eingesetzten Implementierungstools stark variieren – bis hin zu der Hardware, auf der das System läuft.
Methoden zur Anomalieerkennung bei der Vorhersage von Ausfällen von Softwaresystemen
Zunächst sei angemerkt, dass die Idee der Ausfallvorhersage von einem Artikel inspiriert wurde . Zur Überprüfung der Effektivität des Ansatzes zur automatischen Anomalieerkennung wurde das Software-System „Web-Konsolidierung“ ausgewählt, das eines der Projekte der Firma NPO „Krista“ ist. Zuvor wurden manuelle Überwachungen basierend auf den erhaltenen Metriken durchgeführt. Da das System recht komplex ist, werden eine Vielzahl von Metriken erfasst: JVM-Werte (Last des Garbage Collectors), Kennzahlen des Betriebssystems, auf dem der Code ausgeführt wird (virtueller Speicher, % der CPU-Auslastung), Netzwerkmetriken (Netzwerklast), Servermetriken (CPU-Last, Arbeitsspeicher), Wildfly-Metriken und eigene Metriken der Anwendung für alle kritischen Teilsysteme.
Alle Metriken werden mithilfe von Graphite aus dem System abgerufen. Ursprünglich wurde die Whisper-Datenbank als Standardlösung für Grafana verwendet, aber mit dem Wachstum der Kundenbasis konnte Graphite die Anforderungen nicht mehr erfüllen und erschöpfte die Speicherkapazität der Festplattensubsysteme im Rechenzentrum. Daraufhin wurde entschieden, nach einer effizienteren Lösung zu suchen. Die Wahl fiel auf , was die Belastung des Disk-Subsystems erheblich verringerte und den belegten Speicherplatz um das Fünf- bis Sechsfache reduzierte. Nachfolgend ist das Schema des Mechanismus zur Erfassung von Metriken mit Graphite+ClickHouse dargestellt (Abbildung 2).
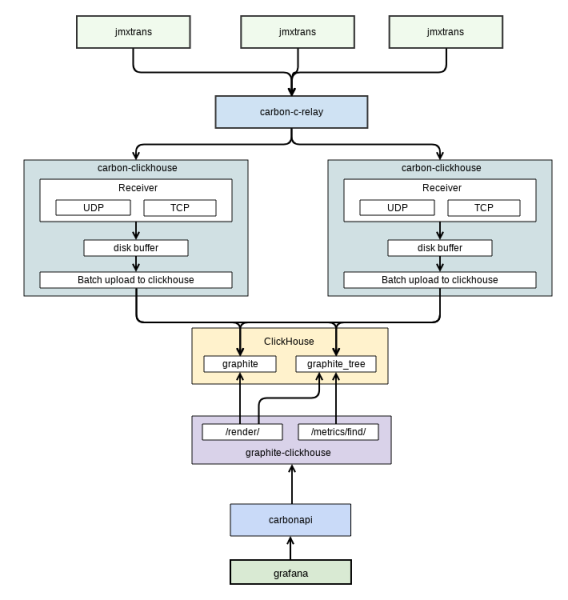
Abbildung 2. Schema zur Erfassung von Metriken
Das Schema stammt aus der internen Dokumentation. Es zeigt den Datenaustausch zwischen Grafana (der Benutzeroberfläche für das Monitoring, die wir verwenden) und Graphite. Die Erfassung der Metriken von der Anwendung erfolgt durch eine separate Software – . Diese speichert sie in Graphite.
Das System „Web-Konsolidierung“ weist eine Reihe von Besonderheiten auf, die Probleme bei der Vorhersage von Ausfällen verursachen:
- Es kommt häufig zu einem Trendwechsel. Für dieses Software-System werden verschiedene Versionen veröffentlicht. Jede von ihnen bringt Änderungen in der Software der Systemkomponenten mit sich. Somit beeinflussen die Entwickler direkt die Metriken dieses Systems und können einen Trendwechsel auslösen;
- Die Art der Implementierung sowie die Ziele, die die Kunden mit diesem System verfolgen, führen häufig zu Anomalien, ohne dass zuvor eine Degeneration stattfindet;
- Der Anteil der Anomalien im Verhältnis zum gesamten Datensatz ist gering (< 5%);
- Es können Unterbrechungen bei der Erfassung von Kennzahlen durch das System auftreten. In bestimmten kurzen Zeitspannen ist es dem Überwachungssystem nicht möglich, Metriken zu erhalten, beispielsweise wenn der Server überlastet ist. Für das Training des neuronalen Netzwerks ist dies entscheidend. Daher besteht die Notwendigkeit, die Lücken synthetisch zu füllen;
- Fälle mit Anomalien sind oft nur für eine bestimmte Anzahl/Monat/Zeit (Saisonabhängigkeit) relevant. Dieses System hat klare Richtlinien für die Nutzung durch seine Benutzer. Dementsprechend sind die Metriken nur für spezifische Zeiträume relevant. Das System kann nicht ständig genutzt werden, sondern nur in bestimmten Monaten, je nach Jahr. Es gibt Situationen, in denen das gleiche Verhalten der Metriken in einem Fall zum Ausfall des Programmsystems führen kann, in einem anderen jedoch nicht.
Zunächst wurden die Methoden zur Erkennung von Anomalien in den Überwachungsdaten von Softwaresystemen analysiert. In Artikeln zu diesem Thema wird bei niedrigen Prozentsätzen an Anomalien im Vergleich zum Rest der Daten häufig empfohlen, neuronale Netzwerke einzusetzen.
Die grundlegende Logik zur Auffindung von Anomalien mithilfe von Daten neuronaler Netze ist in Abbildung 3 dargestellt:

Abbildung 3. Anomaliefindung mithilfe eines neuronalen Netzes
Das Abweichungsverhältnis zwischen den Prognosen oder Rekonstruktionen des aktuellen Metricsflusses wird im Vergleich zu den Werten aus dem laufenden Softwaresystem berechnet. Bei einer signifikanten Differenz zwischen den erhaltenen Metriken aus dem Softwaresystem und dem neuronalen Netz kann auf die Anomalität des aktuellen Datenausschnitts geschlossen werden. Hier ergeben sich verschiedene Herausforderungen bei der Verwendung neuronaler Netze:
- Für einen korrekten Betrieb im Stream-Modus sollten die Daten zum Trainieren der neuronalen Modelle ausschließlich 'normale' Daten enthalten;
- Es ist notwendig, ein aktuelles Modell zur ordnungsgemäßen Erkennung zu haben. Veränderungen in Trends und Saisonalität der Metriken können eine Vielzahl von falsch-positiven Alarme auslösen. Um das Modell zu aktualisieren, muss genau festgelegt werden, wann das Modell veraltet ist. Wenn das Modell zu spät oder zu früh aktualisiert wird, ist es wahrscheinlich, dass es zu einer hohen Anzahl von falsch-positiven Alarmen kommt.
Es ist ebenso wichtig, die Suche nach und die Verhinderung häufiger Fehlalarme nicht zu vergessen. Diese treten meist in Ausnahmefällen auf. Sie können jedoch auch auf einen Fehler im neuronalen Netzwerk zurückzuführen sein, der durch unzureichendes Training verursacht wird. Die Anzahl der Fehlalarme des Modells muss minimiert werden. Andernfalls werden falsche Vorhersagen viel Zeit des Administrators in Anspruch nehmen, die eigentlich für die Systemüberprüfung eingeplant ist. Irgendwann wird der Administrator einfach aufhören, auf das "paranoide" Überwachungssystem zu reagieren.
Recurrent Neural Network
Zur Erkennung von Anomalien in Zeitreihen kann man mit LSTM-Speicher anwenden. Das Problem besteht jedoch darin, dass es nur für vorhersagbare Zeitreihen eingesetzt werden kann. In unserem Fall sind nicht alle Metriken vorhersagbar. Ein Versuch, RNN LSTM für die Zeitreihe anzuwenden, ist in Abbildung 4 dargestellt.
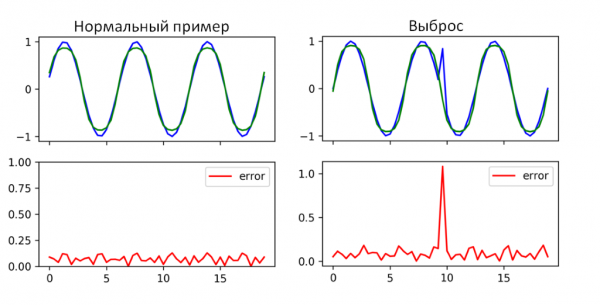
Abbildung 4. Beispiel für die Funktionsweise eines rekurrenten neuronalen Netzwerks mit LSTM-Speichereinheiten.
Wie aus Abbildung 4 ersichtlich, konnte das RNN LSTM Anomalien in diesem Zeitabschnitt identifizieren. Dort, wo das Ergebnis eine hohe Prognosefehlerquote (mittelmäßiger Fehler) aufweist, traten tatsächlich Anomalien auf. Die Verwendung eines einzigen RNN LSTM wird offensichtlich nicht ausreichen, da es auf eine begrenzte Anzahl von Metriken anwendbar ist. Es kann als unterstützende Methode zur Anomalieerkennung genutzt werden.
Autoencoder zur Vorhersage von Ausfällen
– im Grunde ein künstliches neuronales Netzwerk. Der Eingabeschicht fungiert als Encoder, die Ausgabeschicht als Decoder. Ein Nachteil aller neuronalen Netzwerke dieses Typs ist die schlechte Lokalisierung von Anomalien. Es wurde die Architektur eines synchronen Autoencoders ausgewählt.
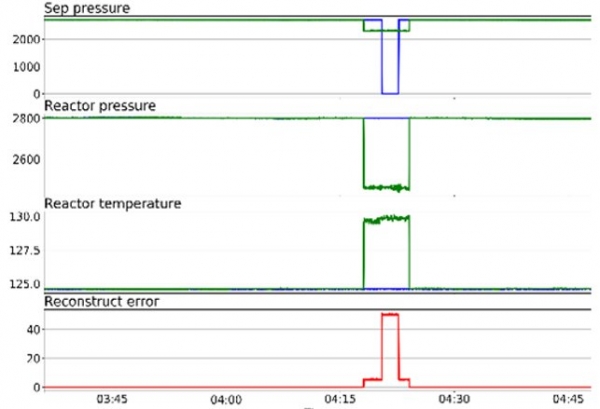
Abbildung 5. Beispiel für die Funktionsweise eines Autoencoders
Autoencoder werden mit Normaldaten trainiert und finden anschließend Anomalien in den der Modellierung zugeführten Daten. Genau das, was für diese Aufgabe benötigt wird. Es bleibt nur noch zu entscheiden, welcher der Autoencoder am besten für diese Aufgabe geeignet ist. Die architektonisch einfachste Form eines Autoencoders ist ein direktes, nicht rückführbares neuronales Netzwerk, das sehr ähnlich ist wie (Multilayer-Perzeptron, MLP), mit einer Eingabeschicht, einer Ausgabeschicht und einer oder mehreren verborgenen Schichten, die sie verbinden.
Die Unterschiede zwischen Autoencodern und MLP liegen jedoch darin, dass der Ausgabeschicht die gleiche Anzahl von Neuronen wie der Eingabeschicht hat und dass der Autoencoder nicht darauf trainiert wird, einen Zielwert Y, der durch die Eingabe X bestimmt wird, vorherzusagen. Stattdessen lernt der Autoencoder, seine eigenen X zu rekonstruieren. Daher sind Autoencoder unüberwachte Lernmodelle.
Die Aufgabe des Autoencoders besteht darin, die Zeitindizes r0 … rn zu finden, die den anomalien Elementen im Eingangsvektor X entsprechen. Dieser Effekt wird durch die Suche nach dem quadratischen Fehler erreicht.
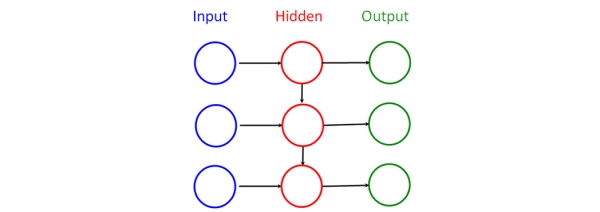
Abbildung 6. Synchroner Autoencoder
Für den Autoencoder wurde eine ausgewählt. Ihre Vorteile liegen in der Möglichkeit der Verwendung eines Streaming-Verarbeitungsmodus und einer relativ geringen Anzahl von Parametern im Vergleich zu anderen Architekturen.
Mechanismus zur Minimierung von Fehlalarmen
Da in verschiedenen Situationen unerwartete Ereignisse auftreten können und die Schulung des neuronalen Netzwerks möglicherweise unzureichend sein kann, wurde für das zu entwickelnde Anomalieerkennungsmodell die Notwendigkeit eines Mechanismus zur Minimierung von Fehlalarmen beschlossen. Dieser Mechanismus basiert auf einer Vorlagenbasis, die vom Administrator klassifiziert wird.
(DTW-Algorithmus, abgeleitet von dynamic time warping) ermöglicht es, die optimale Übereinstimmung zwischen zeitlichen Sequenzen zu finden. Er wurde erstmals in der Spracherkennung eingesetzt: dabei wurde bestimmt, wie zwei Sprachsignale denselben ursprünglich ausgesprochenen Satz repräsentieren. Später fand er auch in anderen Bereichen Anwendung.
Das Hauptprinzip zur Minimierung von Fehlalarmen besteht darin, eine Basis von Referenzen mit Hilfe eines Operators zu sammeln, der verdächtige Fälle, die durch neuronale Netze entdeckt wurden, klassifiziert. Anschließend erfolgt der Vergleich des klassifizierten Referenzfalls mit dem Fall, den das System entdeckt hat, und es wird entschieden, ob der Fall zu einem Fehlalarm oder zu einem tatsächlichen Fehler gehört. Genau dafür wird der DTW-Algorithmus verwendet, um zwei Zeitreihen zu vergleichen. Das Hauptinstrument zur Minimierung bleibt jedoch die Klassifikation. Es wird angenommen, dass das System, nach der Sammlung einer großen Anzahl von Referenzfällen, weniger oft den Operator konsultieren wird, da die meisten Fälle ähnlich sind und ähnliche Muster aufweisen.
Auf der Grundlage der oben beschriebenen Methoden der neuronalen Netze wurde ein experimentelles Programm zur Vorhersage von Systemausfällen für die "Web-Konsolidierung" erstellt. Ziel dieses Programms war es, unter Verwendung des bestehenden Archivs von Überwachungsdaten und Informationen über bereits aufgetretene Ausfälle die Wirksamkeit dieses Ansatzes für unsere Softwaresysteme zu bewerten. Das Arbeitsdiagramm des Programms ist unten in Abbildung 7 dargestellt.
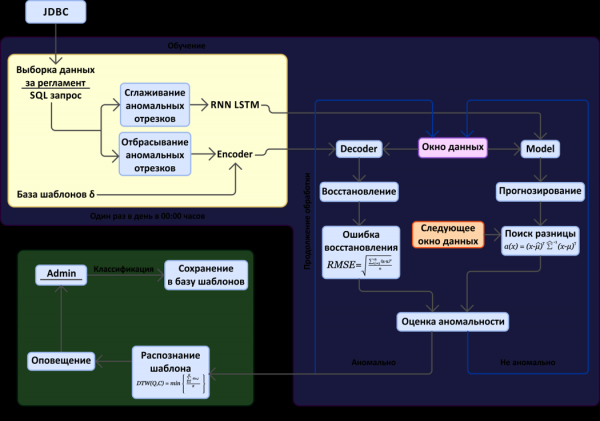
Abbildung 7. Schema zur Vorhersage von Ausfällen basierend auf der Analyse des Metrikraums
Im Diagramm lassen sich zwei Hauptblöcke unterscheiden: die Suche nach anomalen Zeitabschnitten im Datenstrom der Überwachung (Metriken) und den Mechanismus zur Minimierung von Fehlalarmen. Hinweis: Zu experimentellen Zwecken werden die Daten über eine JDBC-Verbindung aus einer Datenbank abgerufen, in der sie in Graphite gespeichert werden.
Im Folgenden wird die Benutzeroberfläche des entwickelten Überwachungssystems dargestellt (Abbildung 8).
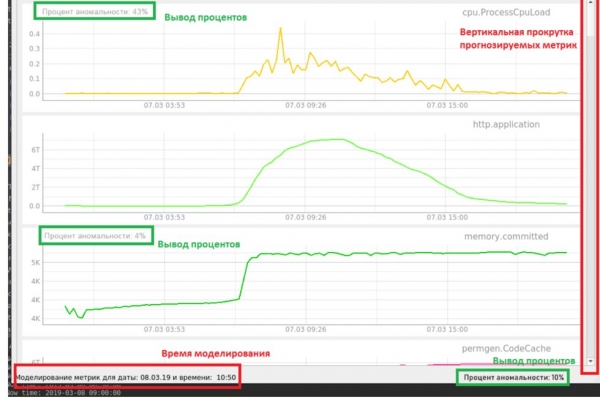
Abbildung 8. Benutzeroberfläche des experimentellen Überwachungssystems
In der Benutzeroberfläche wird der Anomalieprozentsatz der empfangenen Metriken angezeigt. In unserem Fall wird der Erhalt simuliert. Wir haben bereits alle Daten der letzten Wochen gesammelt und laden sie schrittweise hoch, um den Fall einer Anomalie zu überprüfen, die zu einem Ausfall führt. In der unteren Statusleiste wird der allgemeine Prozentsatz der Anomalie der Daten zu einem bestimmten Zeitpunkt angezeigt, der mithilfe des Autoencoders bestimmt wird. Zusätzlich wird für die prognostizierten Metriken ein separater Prozentsatz angezeigt, der von einem RNN LSTM berechnet wird.
Beispiel für die Erkennung von Anomalien anhand der CPU-Leistung mithilfe des RNN LSTM-Netzes (Abbildung 9).
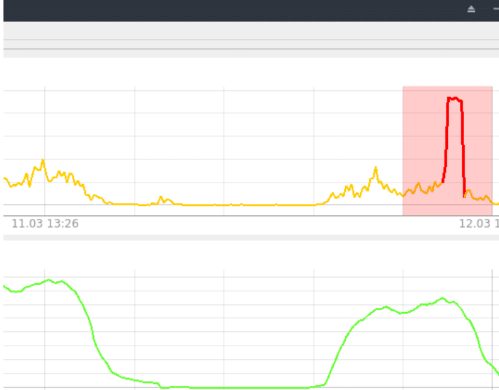
Abbildung 9. Erkennung von RNN LSTM
Ein recht einfacher Fall, im Grunde ein gewöhnlicher Ausreißer, der jedoch zu einem Systemausfall führte, wurde erfolgreich mit Hilfe von RNN LSTM erfasst. Der Anomaliewert in diesem Zeitabschnitt liegt zwischen 85 und 95 %, alles über 80 % (der Schwellenwert wurde experimentell festgelegt) gilt als Anomalie.
Beispiel einer Anomalieerkennung, als das System nach einem Update nicht mehr hochfahren konnte. Diese Situation wird durch den Autoencoder erkannt (Abbildung 10).
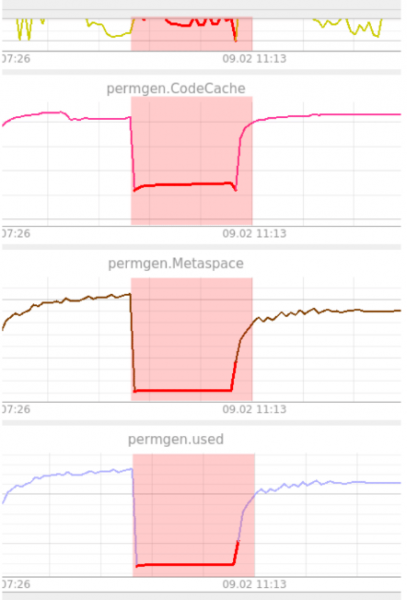
Abbildung 10. Beispiel der Erkennung durch den Autoencoder
Wie aus der Abbildung ersichtlich ist, hat PermGen auf einem Niveau festgehangen. Der Autoencoder hielt das für merkwürdig, da er zuvor nichts Vergleichbares gesehen hatte. Hier liegt die Anomalie konstant bei 100 %, bis das System wieder einsatzbereit ist. Die Anomalie zeigt sich in allen Metriken. Wie bereits erwähnt, kann der Autoencoder Anomalien nicht lokalisieren. Der Operator ist in solchen Situationen dafür verantwortlich.
Fazit
Das System „Web-Konsolidierung“ wird seit mehreren Jahren entwickelt. Es befindet sich in einem stabilen Zustand, und die Anzahl der registrierten Vorfälle ist gering. Dennoch konnten Anomalien identifiziert werden, die zu einem Ausfall 5 bis 10 Minuten vor dessen Eintreten führen. In einigen Fällen hätte eine frühzeitige Warnung vor dem Ausfall geholfen, die für Wartungsarbeiten festgelegte Zeit zu sparen.
In Bezug auf die durchgeführten Experimente ist es noch zu früh, endgültige Schlussfolgerungen zu ziehen. Die Ergebnisse sind momentan widersprüchlich. Einerseits ist erkennbar, dass neuronale Netzalgorithmen in der Lage sind, „nützliche“ Anomalien zu identifizieren. Andererseits gibt es eine hohe Rate an Fehlalarmen, und nicht alle Anomalien, die von qualifizierten Spezialisten entdeckt werden, sind für die neuronalen Netzwerke erkennbar. Ein Nachteil ist zudem, dass das neuronale Netzwerk derzeit eine Beaufsichtigung zum Lernen benötigt, um ordnungsgemäß zu funktionieren.
Um die Entwicklung des Ausfallvorhersagesystems voranzutreiben und es in einen zufriedenstellenden Zustand zu bringen, gibt es mehrere Ansätze. Dazu gehört eine detailliertere Analyse der anomalies betreffenden Fälle, die zu Ausfällen führen, durch eine Erweiterung der Liste wichtiger Metriken, die einen erheblichen Einfluss auf den Systemzustand haben, während unwichtige Metriken ausgeschlossen werden. Wenn wir in diese Richtung weiterarbeiten, können wir auch versuchen, die Algorithmen speziell auf unsere Fälle von Anomalien, die zu Ausfällen führen, zuzuschneiden. Ein weiterer Ansatz wäre die Verbesserung der Architektur von neuronalen Netzen, wodurch die Genauigkeit der Erkennungen erhöht und die Trainingszeit verkürzt wird.
Ich möchte meinen Kollegen danken, die mir beim Verfassen und der Aktualisierung dieses Artikels geholfen haben: und Sergej Finogenow.
Quelle: habr.com
