

Die Feiertage sind vorbei, und wir sind zurück mit unserem zweiten Beitrag in der Reihe über Istio Service Mesh.

Das heutige Thema – Circuit Breaker, was auf Deutsch „automatischer Schalter“ bedeutet, umgangssprachlich auch als „Schutzschalter“ bekannt. In Istio schaltet dieser Schalter jedoch keine überlastete oder kurzgeschlossene Leitung ab, sondern deaktiviert defekte Container.
So sollte es idealerweise funktionieren
Wenn Microservices von Kubernetes verwaltet werden, zum Beispiel im Rahmen der OpenShift-Plattform, skalieren sie automatisch je nach Last nach oben oder unten. Da Microservices in Pods arbeiten, kann es an einem Endpunkt mehrere Instanzen eines containerisierten Microservices geben, und Kubernetes routet die Anfragen und balanciert die Last zwischen ihnen. Und – im Idealfall – sollte alles perfekt funktionieren.
Wir wissen, dass Mikrodienste klein und flüchtig sind. Diese Flüchtigkeit, die hier bedeutet, dass sie einfach entstehen und verschwinden, wird oft unterschätzt. Die Geburt und der Tod eines Mikrodienstes in einem Pod sind ganz normale Vorgänge. OpenShift und Kubernetes meistern dies gut, und alles funktioniert wunderbar – zumindest in der Theorie.
Wie funktioniert das wirklich?
Stellen Sie sich jetzt vor, dass ein konkreter Mikrodienst, sprich ein Container, ausgefallen ist: Entweder antwortet er nicht (Fehler 503) oder – was schlimmer ist – er reagiert, jedoch viel zu langsam. Mit anderen Worten, er hat kleine Störungen oder antwortet nicht auf Anfragen, wird aber nicht automatisch aus dem Pool entfernt. Was sollten Sie in diesem Fall tun? Den Versuch wiederholen? Ihn aus dem Routing-Schema entfernen? Und was bedeutet "zu langsam" – wie viel ist das in Zahlen und wer legt diese fest? Vielleicht sollten wir ihm einfach eine Pause geben und es später erneut versuchen? Wenn ja, wie viel später?
Was ist Pool Ejection in Istio?
Und hier kommt Istio ins Spiel mit seinen Circuit Breaker-Schutzmechanismen, die fehlerhafte Container vorübergehend aus dem Ressourcenpool für Routing und Lastverteilung entfernen und somit die Pool Ejection-Prozedur umsetzen.
Durch die Anwendung einer Outlier-Detection-Strategie erkennt Istio pod-Instanzen, die aus der Reihe fallen, und entfernt sie für eine festgelegte Zeitspanne aus dem Ressourcenpool, die als 'Sleep Window' bezeichnet wird.
Um zu demonstrieren, wie dies in Kubernetes auf der OpenShift-Plattform funktioniert, beginnen wir mit einem Screenshot von normal laufenden Microservices aus einem Beispiel im Repository . Hier haben wir zwei Pods, v1 und v2, in denen jeweils ein Container läuft. Wenn die Routingregeln von Istio nicht angewendet werden, nutzt Kubernetes standardmäßig eine gleichmäßig verteilte zyklische Routingstrategie:
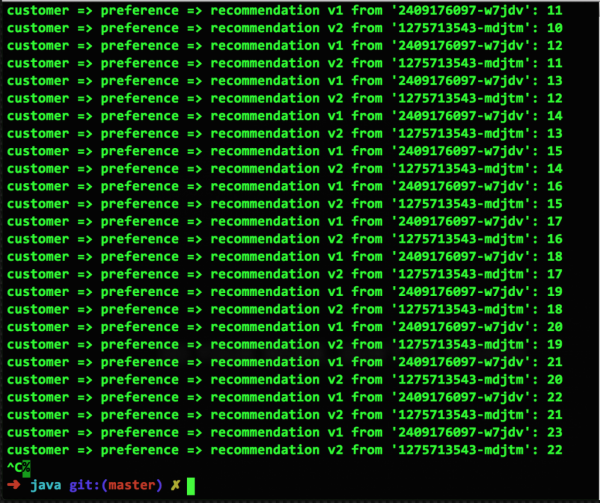
Bereiten wir uns auf einen Ausfall vor
Bevor wir die Pool Ejection durchführen, müssen wir eine Routingregel für Istio erstellen. Angenommen, wir möchten die Anfragen im Verhältnis 50/50 zwischen den Pods verteilen. Außerdem erhöhen wir die Anzahl der Container in v2 von einem auf zwei, so:
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
Jetzt erstellen wir eine Routing-Regel, damit der Verkehr im Verhältnis 50/50 zwischen den Pods verteilt wird.

So sieht das Ergebnis dieser Regel aus:
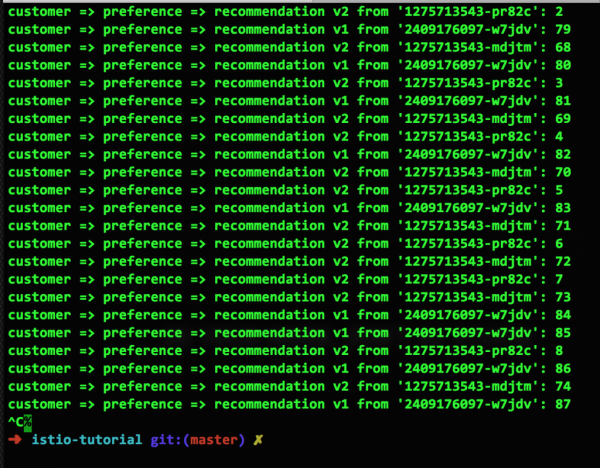
Man könnte anmerken, dass auf diesem Screenshot nicht 50/50, sondern 14:9 zu sehen ist, aber im Laufe der Zeit wird sich die Situation ausgleichen.
Wir verursachen einen Fehler.
Jetzt bringen wir einen der beiden v2-Container außer Gefecht, sodass wir einen funktionierenden v1-Container, einen funktionierenden v2-Container und einen defekten v2-Container haben:
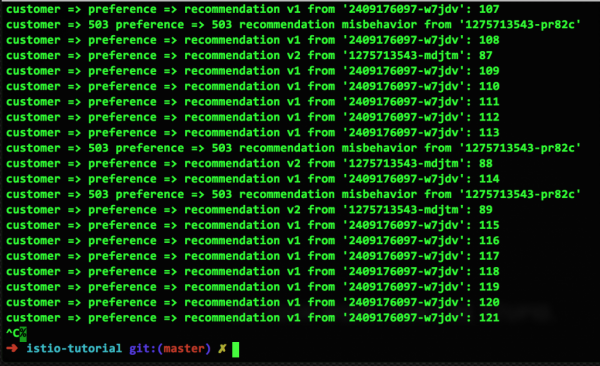
Wir beheben den Fehler.
Also, wir haben einen defekten Container, und es ist Zeit für die Poolausstoßung. Mit einer sehr einfachen Konfiguration werden wir diesen fehlerhaften Container für 15 Sekunden aus allen Routing-Schemata ausschließen, in der Hoffnung, dass er sich entweder selbst repariert (oder neu gestartet wird oder die Leistung wiederherstellt). So sieht diese Konfiguration aus und die Ergebnisse ihrer Ausführung:

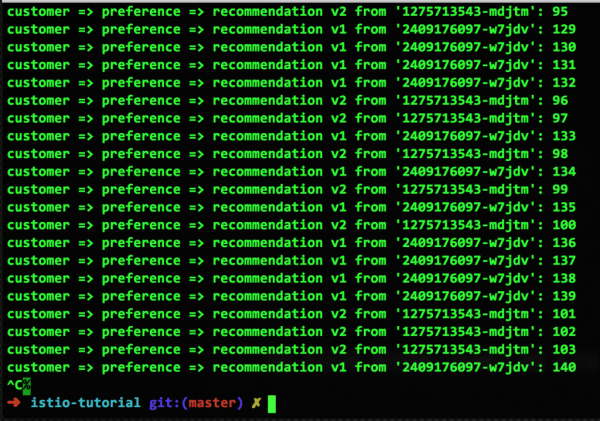
Wie man sehen kann, wird der defekte v2-Container bei der Anfrage-Routing nicht mehr verwendet, da er aus dem Pool entfernt wurde. Nach 15 Sekunden kehrt er jedoch automatisch in den Pool zurück. Tatsächlich haben wir gerade gezeigt, wie die Poolausstoßung funktioniert.
Beginnen wir mit dem Aufbau der Architektur.
Die Pool-Ejektion in Verbindung mit den Überwachungsmöglichkeiten von Istio ermöglicht den Aufbau eines Frameworks zur automatischen Ersetzung defekter Container, um Ausfallzeiten und Störungen zu minimieren oder sogar ganz zu vermeiden.
NASA hat ein bekanntes Motto – Failure Is Not an Option, das von Flight Director verbreitet wurde. Auf Deutsch lässt es sich mit „Misserfolg ist keine Option“ übersetzen. Der Sinn dahinter ist, dass alles zum Funktionieren gebracht werden kann, solange genügend Entschlossenheit vorhanden ist. In der Realität jedoch sind Ausfälle nicht nur wahrscheinlich, sie sind unvermeidlich, überall und in allem. Wie geht man also mit ihnen um, wenn es um Mikrodienste geht? Unserer Meinung nach sollte man besser nicht auf Willenskraft setzen, sondern auf die Möglichkeiten von Containern. , , und .
Istio implementiert, wie bereits erwähnt, das sich im physischen Bereich bestens bewährte Konzept von automatischen Schutzschaltern. Während ein elektrischer Schutzschalter den fehlerhaften Teil eines Stromkreises trennt, unterbricht der Software-Circuit Breaker in Istio die Verbindung zwischen dem Anfragefluss und dem problematischen Container, wenn mit dem Endpunkt etwas nicht stimmt, z. B. wenn der Server ausfällt oder anfängt zu stottern.
Im zweiten Fall gibt es nur noch mehr Probleme, da die Verzögerungen eines Containers nicht nur Kaskadeneffekte in den damit verbundenen Diensten verursachen und so die Gesamtleistung des Systems beeinträchtigen, sondern auch Wiederholungsanfragen an den bereits langsam laufenden Dienst hervorrufen, was die Situation weiter verschärft.
Circuit Breaker in der Theorie
Circuit Breaker – ist ein Proxy, der den Datenfluss zu einem Endpunkt überwacht. Wenn dieser Endpunkt nicht mehr funktioniert oder – je nach den festgelegten Einstellungen – anfängt, langsam zu reagieren, trennt der Proxy die Verbindung zum Container. Der Datenverkehr wird anschließend auf andere Container umgeleitet, ganz einfach zur Lastverteilung. Die Verbindung bleibt für ein gegebenes Zeitfenster, sagen wir zwei Minuten, offen (open) und wird dann als halb-offen (half-open) betrachtet. Ein Versuch, die nächste Anfrage zu senden, bestimmt den weiteren Zustand der Verbindung. Wenn mit dem Dienst alles in Ordnung ist, wird die Verbindung wieder aktiv und geschlossen (closed). Sollte jedoch weiterhin ein Problem mit dem Dienst bestehen, wird die Verbindung erneut getrennt und das Zeitfenster beginnt von vorn. So sieht ein vereinfachtes Diagramm des Zustandswechsels eines Circuit Breaker aus:
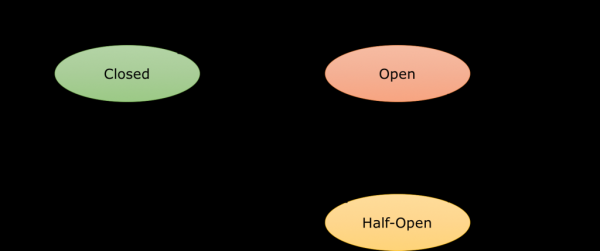
Es ist wichtig zu beachten, dass dies alles auf der Ebene der sogenannten Systemarchitektur geschieht. Daher müssen Sie irgendwann Ihre Anwendungen anweisen, mit dem Circuit Breaker zu arbeiten. Dies kann bedeuten, dass sie im Falle eines Fehlers einen Standardwert zurückgeben oder, wenn möglich, die Existenz des Dienstes ignorieren. Dafür wird das Bulkhead-Muster verwendet, aber das würde den Rahmen dieses Artikels sprengen.
Circuit Breaker in der Praxis
Zum Beispiel werden wir auf OpenShift zwei Versionen unseres Mikrodienstes für Empfehlungen starten. Version 1 wird normal funktionieren, während wir in v2 eine Verzögerung einbauen, um Verzögerungen auf dem Server zu simulieren. Zur Anzeige der Ergebnisse verwenden wir das Tool :
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io
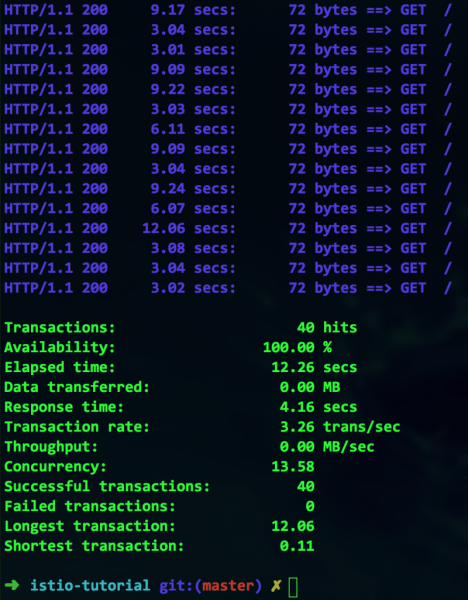
Alles scheint zu funktionieren, aber zu welchem Preis? Auf den ersten Blick haben wir eine Verfügbarkeit von 100 %, aber beachten Sie – die maximale Transaktionsdauer beträgt ganze 12 Sekunden. Das ist offensichtlich ein Engpass, den wir beheben müssen.
Um das zu erreichen, werden wir mit Hilfe von Istio die Anfragen an langsame Container ausschließen. So sieht die entsprechende Konfiguration mit dem Circuit Breaker aus:

Die letzte Zeile mit dem Parameter httpMaxRequestsPerConnection signalisiert, dass die Verbindung getrennt werden sollte, wenn versucht wird, eine weitere – zweite – Verbindung zusätzlich zu der bereits bestehenden herzustellen. Da unser Container einen throttling Service simuliert, werden solche Situationen gelegentlich auftreten, und dann wird Istio einen Fehler 503 zurückgeben, während siege Folgendes anzeigen wird:
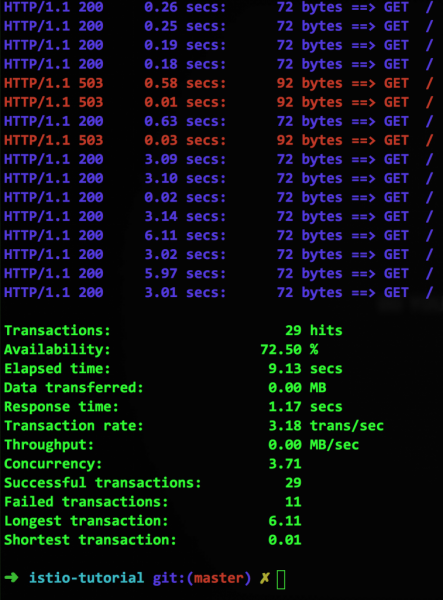
Okay, wir haben einen Circuit Breaker, und was nun?
Also haben wir eine automatische Deaktivierung implementiert, ohne den Quellcode der Dienste selbst zu berühren. Mit dem Circuit Breaker und dem oben beschriebenen Verfahren zur Pool-Auswurfung können wir leistungsstarke Container aus dem Ressourcenpool entfernen, bis sie wieder einsatzbereit sind, und deren Zustand in regelmäßigen Abständen überprüfen – in unserem Beispiel alle zwei Minuten (Parameter sleepWindow).
Bitte beachten Sie, dass die Fähigkeit der Anwendung, auf den Fehler 503 zu reagieren, weiterhin im Quellcode der Anwendung festgelegt ist. Es gibt viele Strategien zur Arbeit mit einem Circuit Breaker, die je nach Situation angewandt werden.
Im nächsten Beitrag: Wir sprechen über die Traceroute- und Überwachungsfunktionen, die bereits in Istio integriert sind oder einfach hinzugefügt werden können, sowie darüber, wie man absichtlich Fehler in das System einführt.
Quelle: habr.com
