

Habr verändert die Welt. Seit mehr als einem Jahr führen wir unseren Blog. Vor etwa einem halben Jahr erhielten wir ein recht naheliegendes Feedback von den Habr-Nutzern: „Dodo, ihr sagt überall, dass ihr euer eigenes System habt. Was ist das für ein System? Und warum ist es für ein Pizzanetzer notwendig?“
Wir haben darüber nachgedacht und festgestellt, dass ihr recht habt. Wir versuchen alles einfach zu erklären, aber es kommt oft in Teilen und es gibt kein vollständiges Systembeschreibung. So begann der lange Weg der Informationssammlung, der Suche nach Autoren und dem Schreiben einer Artikelserie über Dodo IS. Lass uns loslegen!
Dankeschön: Danke, dass ihr euer Feedback mit uns teilt. Dank euch haben wir endlich das System beschrieben, einen Technologieradar erstellt und werden bald eine umfassende Beschreibung unserer Prozesse veröffentlichen. Sonst würden wir wahrscheinlich noch weitere 5 Jahre ohne euch sitzen.
Die Artikelserie „Was ist Dodo IS?“ wird erzählen über:
- Früher Monolith in Dodo IS (2011-2015). (In Bearbeitung…)
- Der Weg des Backends: separate Datenbanken und Bus. (Sie sind hier)
- Der Weg des Kundenbereichs: Fassade über der Datenbank (2016-2017). (In Bearbeitung…)
- Die Geschichte echter Mikrodienste. (2018-2019). (In Bearbeitung…)
- Abgeschlossene Zerlegung des Monolithen und Stabilisierung der Architektur. (In Bearbeitung…)
Wenn ihr noch etwas wissen möchtet – schreibt in die Kommentare.
Meinung zum chronologischen Bericht des Autors
Ich halte regelmäßig ein Treffen für neue Mitarbeiter zum Thema „Systemarchitektur“. Bei uns heißt es „Einführung in die Dodo IS-Architektur“ und ist Teil des Onboarding-Prozesses neuer Entwickler. Während ich in unterschiedlicher Weise über unsere Architektur und ihre Besonderheiten spreche, entwickelte sich ein gewisser historischer Ansatz zur Beschreibung.
Traditionell betrachten wir das System als eine Ansammlung von Komponenten (technischen oder höherwertigen) und Geschäftsmodulen, die miteinander interagieren, um ein Ziel zu erreichen. Während dieser Blickwinkel für die Planung gerechtfertigt ist, eignet er sich weniger gut für die Beschreibung und das Verständnis. Es gibt mehrere Gründe dafür:
- Die Realität unterscheidet sich von dem, was auf Papier steht. Nicht alles, was geplant ist, klappt auch. Uns interessiert, wie alles tatsächlich aussieht und funktioniert.
- Eine schrittweise Darlegung der Informationen. Man könnte im Grunde chronologisch vom Anfang bis zum aktuellen Zustand vorgehen.
- Von einfach zu komplex. Nicht universell, aber in unserem Fall genau so. Von einfacheren Ansätzen hat sich die Architektur zu komplexeren entwickelt. Oft wurden durch Komplexität Probleme in Bezug auf Geschwindigkeit und Stabilität gelöst, sowie Dutzende anderer Eigenschaften aus der Liste der nicht-funktionalen Anforderungen. gut erklärt im Hinblick auf die Abwägung der Komplexität gegenüber anderen Anforderungen.
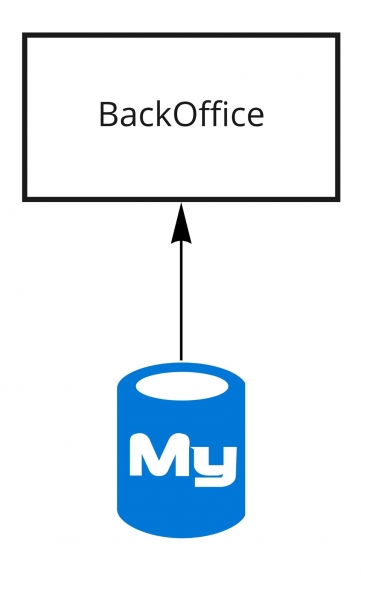
Im Jahr 2011 sah die Architektur von Dodo IS so aus:
Bis 2020 hat sie sich etwas verändert und sieht jetzt so aus:
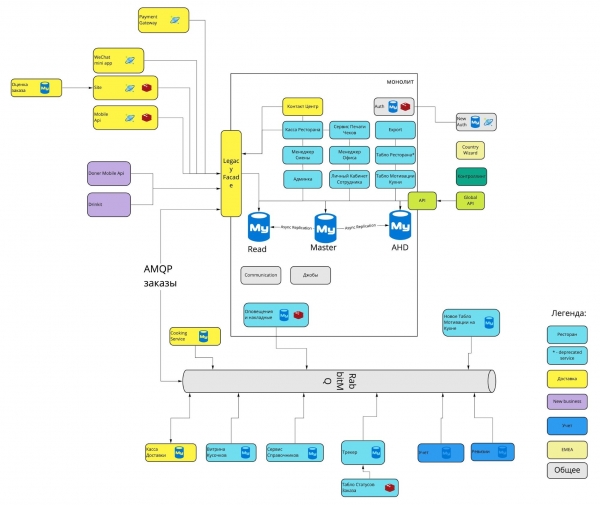
Wie kam es zu dieser Evolution? Warum sind verschiedene Teile des Systems notwendig? Welche architektonischen Entscheidungen wurden getroffen und warum? Lassen Sie uns dies in dieser Artikelreihe klären.
Die ersten Probleme des Jahres 2016: Warum müssen Dienste aus dem Monolithen herauslösen?
Die ersten Artikel dieser Reihe werden sich mit den Diensten beschäftigen, die sich zuerst vom Monolithen abgelöst haben. Um Sie in den Kontext einzuführen, möchte ich erläutern, welche Probleme wir zu Beginn des Jahres 2016 in unserem System hatten und warum wir uns mit der Trennung der Dienste beschäftigen mussten.
Eine zentrale MySql-Datenbank, in die alle zum damaligen Zeitpunkt existierenden Anwendungen ihre Daten schrieben. Die Konsequenzen waren folgende:
- Hohe Last (wobei 85 % der Anfragen auf Lesevorgänge entfielen).
- Die Datenbank wuchs. Dadurch wurde die Kosten- und Supportfrage problematisch.
- Einzelner Ausfallpunkt. Wenn eine Anwendung, die in die Datenbank schreibt, plötzlich aktiver wird, spüren dies die anderen Anwendungen.
- Ineffizienz bei Speicherung und Abfragen. Oft wurden Daten in einer Struktur gespeichert, die für einige Szenarien geeignet war, jedoch für andere nicht. Indizes beschleunigten bestimmte Operationen, konnten jedoch andere verlangsamen.
- Einige Probleme wurden durch hastig erstellte Caches und Read-Replikate der Datenbanken gemildert (darüber wird in einem separaten Artikel berichtet), doch sie verschafften nur Zeit und lösten das grundsätzliche Problem nicht.
Das Problem war das Vorhandensein des Monolithen.Die Folgen waren folgende:
- Einheitliche und seltene Releases.
- Komplexität bei der Zusammenarbeit vieler Personen.
- Unmöglichkeit, neue Technologien, neue Frameworks und Bibliotheken einzuführen.
Probleme mit der Datenbank und dem Monolithen wurden oft beschrieben, beispielsweise im Kontext von Ausfällen Anfang 2018 (, und ), daher werde ich nicht lange pausieren. Ich möchte nur erwähnen, dass wir mehr Flexibilität bei der Entwicklung von Diensten bieten wollten. Dies betraf insbesondere die am stärksten beanspruchten und zentralen Systeme — Auth und Tracker.
Backoffice-Weg: getrennte Datenbanken und Bus
Kapitelnavigation
Monolith-Diagramm aus dem Jahr 2016
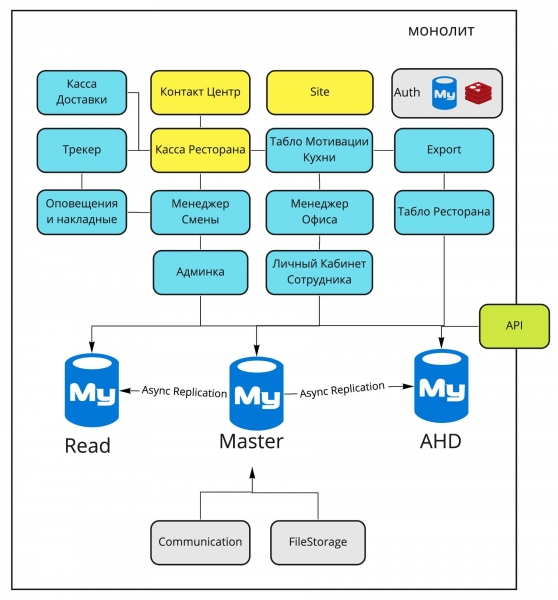
Vor Ihnen liegen die Hauptkomponenten des Monolithen Dodo IS aus dem Jahr 2016, und etwas weiter unten finden Sie eine Erklärung ihrer Hauptaufgaben.
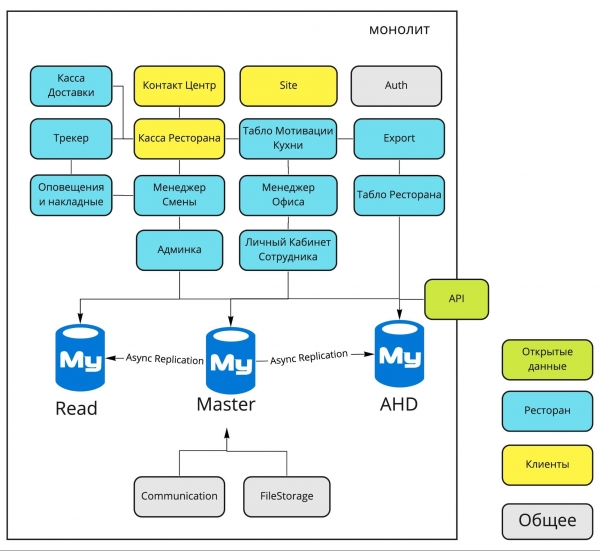
Lieferkasse. Verwaltung der Kuriere, Ausgabe von Bestellungen an Kuriere.
Kontaktzentrum. Entgegennahme von Bestellungen über den Operator.
Website. Unsere Webseiten (dodopizza.ru, dodopizza.co.uk, dodopizza.by usw.).
Auth. Authentifizierungs- und Autorisierungsdienst für das Backoffice.
Tracker. Bestellverfolgung in der Küche. Dienst zur Statusmarkierung bei der Zubereitung von Bestellungen.
Restaurantkasse. Entgegennahme von Bestellungen im Restaurant, Kassenschnittstellen.
Export. Erstellung von Berichten für die Buchhaltung in 1C.
Benachrichtigungen und Lieferscheine. Sprachbefehle in der Küche (zum Beispiel „Neue Pizza eingetroffen“) + Druck von Lieferscheinen für Kuriere.
Schichtmanager. Schnittstellen für das Management der Schichtleiter: Auftragsliste, Leistungsstatistiken, Mitarbeiterwechsel anzeigen.
Büroleiter. Schnittstellen für Franchise-Nehmer und Manager: Annahme von Mitarbeitern, Berichte zur Pizzastation.
Restaurantdisplay. Anzeige des Menüs auf Bildschirmen in Pizzerien.
Admin-Bereich. Einstellungen in der jeweiligen Pizzeria: Menü, Preise, Buchhaltung, Rabattcodes, Aktionen, Banner für die Website usw.
Mitarbeiter-Bereich. Arbeitspläne der Mitarbeiter, Informationen über die Mitarbeiter.
Motivationsanzeige Küche. Ein separater Bildschirm, der in der Küche hängt und die Arbeitsgeschwindigkeit der Pizzabäcker anzeigt.
Kommunikation. Versand von SMS und E-Mail.
FileStorage. Eigener Dienst zum Empfangen und Bereitstellen von statischen Dateien.
. Die ersten Versuche zur Lösung der Probleme halfen uns, waren jedoch nur eine vorübergehende Entlastung. Sie wurden nicht zu systematischen Lösungen, daher wurde klar, dass mit den Datenbanken etwas geschehen musste. Beispielsweise sollte die allgemeine Datenbank in mehrere spezialisierte unterteilt werden.
Wir beginnen mit der Entlastung des Monolithen: Trennung von Auth und Tracker
Die wichtigsten Dienste, die damals mehr als andere Datenbankzugriffe hatten:
- Auth. Authentifizierungs- und Autorisierungsdienst für das Backoffice.
- Tracker. Bestellsystem in der Küche. Dienst zur Statusmarkierung der Fertigstellung während der Zubereitung von Bestellungen.
Womit beschäftigt sich Auth
Auth ist der Dienst, über den sich Benutzer im Backend anmelden (es gibt einen separaten, unabhängigen Zugang im Frontend). Außerdem wird er genutzt, um sicherzustellen, dass die richtigen Zugriffsrechte vorhanden sind und dass sich diese seit dem letzten Login nicht geändert haben. Über diesen Dienst erfolgt auch der Zugang von Geräten in der Pizzeria.
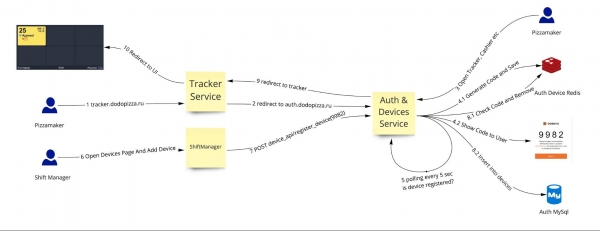
Zum Beispiel möchten wir auf dem Fernseher im Bereich ein Display mit den Status von fertiggestellten Bestellungen öffnen. Dazu rufen wir auth.dodopizza.ru auf, wählen „Zugang als Gerät“ aus, es erscheint ein Code, den wir auf einer speziellen Seite am Computer des Schichtleiters eingeben, einschließlich des Gerätetyps. Der Fernseher wechselt automatisch zur richtigen Benutzeroberfläche seiner Pizzeria und beginnt, die Namen der Kunden anzuzeigen, deren Bestellungen bereit sind.

Woher kommen die Lasten?
Jeder eingeloggte Benutzer im Backend fragt mit jeder Anfrage die Benutzerdaten aus der Datenbank ab, zieht über einen SQL-Befehl den Benutzer heraus und überprüft, ob er die notwendigen Zugriffsrechte und Berechtigungen für diese Seite hat.
Jedes Gerät führt das Gleiche aus, jedoch mit einer Gerätetabelle, überprüft seine Rolle und Zugriffsrechte. Eine Vielzahl von Anfragen an die Hauptdatenbank führt zu ihrer Überlastung und belastet die Ressourcen der gemeinsamen Datenbank für diese Vorgänge.
Entlastung von Auth
Bei Auth handelt es sich um eine isolierte Domain, das heißt, dass Daten über Benutzer, Logins oder Geräte an den Service (zukunftsorientiert) übermittelt werden und dort verbleiben. Wenn jemand diese Daten benötigt, wird er diesen Service aufsuchen.
WAR. Das ursprüngliche Funktionsschema war folgendermaßen:
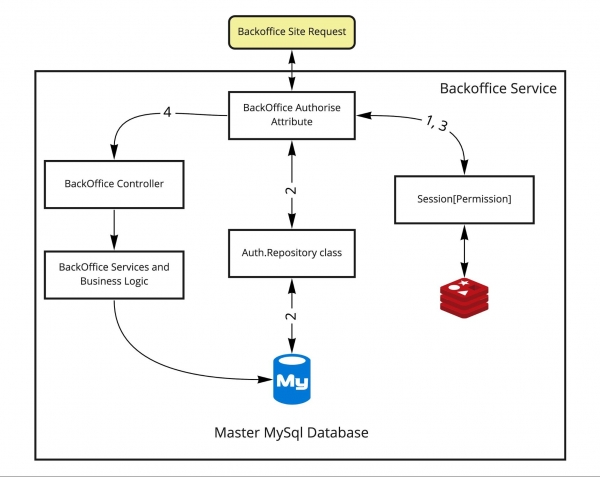
Ich möchte kurz erklären, wie das funktionierte:
- Eine Anfrage von außen gelangt an das Backend (hier Asp.Net MVC), bringt ein Session-Cookie mit, das zur Abfrage der Sitzungsdaten aus Redis(1) verwendet wird. Entweder sind die Zugriffsrechte vorhanden, und der Zugang zum Controller ist gewährt (3,4), oder sie fehlen.
- Wenn kein Zugang besteht, muss der Authentifizierungsprozess durchlaufen werden. Hier wird zur Vereinfachung dieser Prozess als Teil des Weges im gleichen Attribut dargestellt, obwohl es sich um eine Weiterleitung zur Login-Seite handelt. Im positiven Szenario erhalten wir eine korrekt ausgefüllte Sitzung und gelangen zum Backoffice-Controller.
- Wenn Daten vorhanden sind, müssen diese auf Aktualität in der Benutzerdatenbank überprüft werden. Hat sich die Rolle des Benutzers geändert, sollte er möglicherweise keinen Zugriff mehr auf die Seite haben. In diesem Fall sollte man nach dem Erhalt der Sitzung (1) direkt in die Datenbank gehen und die Zugriffsrechte des Benutzers über das Authentifizierungslogikschicht (2) überprüfen. Danach erfolgt entweder die Weiterleitung zur Anmeldeseite oder der Übergang zum Controller. Ein einfaches System, aber nicht ganz standardisiert.
- Wenn alle Verfahren abgeschlossen sind, setzen wir die Logik in den Controllern und Methoden fort.
Benutzerdaten sind von allen anderen Daten getrennt und werden in einer separaten Tabelle für Mitgliedschaften gespeichert. Funktionen aus der AuthService-Logik können durchaus zu API-Methoden werden. Die Grenzen des Domänenbereichs sind klar definiert: Benutzer, ihre Rollen, Zugriffsrechte, Erteilung und Widerruf von Zugriffsrechten. Es sieht alles so aus, dass es zu einem separaten Dienst ausgegliedert werden könnte.
ES IST GESCHEHEN. Genau das haben wir getan:
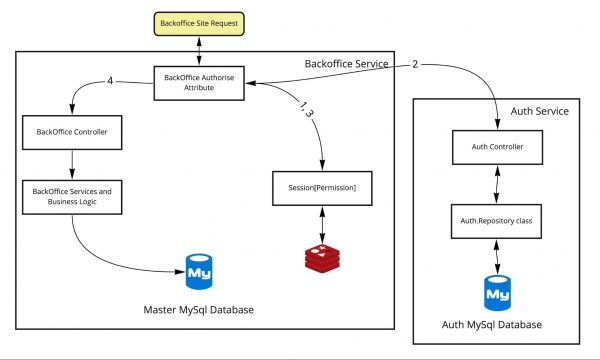
Dieser Ansatz birgt eine Reihe von Problemen. Zum Beispiel ist der Methodenaufruf innerhalb eines Prozesses nicht dasselbe wie der Aufruf eines externen Dienstes über HTTP. Latenz, Zuverlässigkeit, Wartbarkeit und Transparenz der Operationen sind völlig unterschiedlich. André Morevsky sprach in seinem Vortrag ausführlich über diese Probleme. .
Der Authentifizierungsdienst und der dazugehörige Geräteservice werden für das Backoffice verwendet, das heißt für die Dienste und Schnittstellen, die in der Produktion genutzt werden. Die Authentifizierung für Kundenservices (wie die Website oder die mobile App) erfolgt separat ohne Auth. Die Trennung dauerte etwa ein Jahr, und jetzt widmen wir uns erneut diesem Thema, indem wir das System auf neue Authentifizierungsdienste (mit standardisierten Protokollen) umstellen.
Warum hat die Trennung so lange gedauert?
Auf dem Weg gab es viele Probleme, die die Dinge verlangsamt haben:
- Wir wollten die Daten über Benutzer, Geräte und Authentifizierung aus den Datenbanken im Land in eine zentrale Datenbank übertragen. Dazu mussten wir alle Tabellen und die Verwendung von int-IDs auf globale UUID-IDs umstellen (diesen Code haben wir kürzlich überarbeitet). und Open-Source-Projekt ). Die Speicherung von Benutzerdaten (da es sich um persönliche Informationen handelt) hat ihre Einschränkungen, und in einigen Ländern müssen sie separat aufbewahrt werden. Aber der globale Benutzer-Identifikator sollte vorhanden sein.
- Viele Tabellen in der Datenbank haben Audit-Informationen darüber, welcher Benutzer die Aktion durchgeführt hat. Dies erforderte einen zusätzlichen Mechanismus, um Konsistenz zu gewährleisten.
- Nach der Erstellung von API-Diensten gab es eine lange und schrittweise Phase des Wechsels zu einem anderen System. Die Umstellungen mussten nahtlos für die Benutzer erfolgen und erforderten manuelle Arbeit.
Das Schema zur Registrierung von Geräten in der Pizzeria:
Die allgemeine Architektur nach der Abtrennung des Auth- und Devices-Services:
Hinweis. Im Jahr 2020 arbeiten wir an einer neuen Version von Auth, die auf dem Autorisierungsstandard OAuth 2.0 basiert. Dieser Standard ist recht komplex, wird jedoch für die Entwicklung eines End-to-End-Authentifizierungsdienstes nützlich sein. Im Artikel „“ hat Alexey Chernyayev versucht, den Standard so einfach und verständlich wie möglich zu erklären, damit Sie Zeit beim Lernen sparen.
Womit beschäftigt sich der Tracker
Jetzt zum zweiten der stark beanspruchten Dienste. Der Tracker erfüllt eine doppelte Rolle:
- Einerseits hat er die Aufgabe, den Mitarbeitern in der Küche zu zeigen, welche Bestellungen gerade bearbeitet werden und welche Zutaten aktuell zubereitet werden müssen.
- Andererseits digitalisiert er alle Prozesse in der Küche.

Wenn in einer Bestellung ein neues Produkt auftaucht (zum Beispiel eine Pizza), wird es zur Zyklusstation „Ausrollen“ geleitet. An dieser Station steht der Pizzabäcker, der den Teig in der benötigten Größe ausrollt, anschließend auf dem Tablet des Trackers vermerkt, dass er seine Aufgabe abgeschlossen hat, und übergibt den ausgerollten Teig an die nächste Station – „Füllung“.
Hier bereitet der nächste Pizzabäcker die Pizza zu und vermerkt dann auf dem Tablet, dass er seine Aufgabe erledigt hat, und schiebt die Pizza in den Ofen (dies ist ebenfalls eine separate Station, die im Tablet vermerkt werden muss). Dieses System existiert seit den Anfängen von Dodo und der Gründung von Dodo IS. Es ermöglicht die vollständige Nachverfolgung und Digitalisierung aller Abläufe. Darüber hinaus gibt der Tracker Hinweise zur Zubereitung der jeweiligen Produkte, leitet jedes Produkt gemäß seinen Herstellungsschemata und speichert die optimalen Garzeiten sowie alle Vorgänge rund um das Produkt.
 So sieht der Bildschirm des Tablets an der Station des Trackers 'Ausrollen' aus.
So sieht der Bildschirm des Tablets an der Station des Trackers 'Ausrollen' aus.
Woher kommen die Lasten?
In jeder Pizzeria stehen etwa fünf Tablets mit einem Tracker zur Verfügung. Im Jahr 2016 hatten wir mehr als 100 Pizzerien (jetzt sind es über 600). Jedes Tablet sendet alle 10 Sekunden eine Anfrage an das Backend und ruft Daten aus der Bestelltabelle ab (Verbindung mit dem Kunden und der Adresse), der Bestellzusammensetzung (Verbindung mit dem Produkt und Angabe der Menge) sowie der Motivationstabelle (hier wird die Zeit der Betätigung erfasst). Wenn der Pizzabäcker auf das Produkt im Tracker klickt, werden die Einträge in all diesen Tabellen aktualisiert. Die Bestelltabelle ist gemeinsam, und es erfolgen gleichzeitig Einfügungen bei der Annahme der Bestellung, Aktualisierungen von anderen Teilen des Systems sowie zahlreiche Auslesungen, beispielsweise auf dem Fernseher, der in der Pizzeria hängt und den Kunden die fertigen Bestellungen anzeigt.
Während der Hochlastzeit, als alles und jeder zwischengespeichert und auf eine asynchrone Datenbankreplik umgestellt wurde, gingen diese Operationen mit dem Tracker weiterhin an die Master-Datenbank. Hier darf es keine Verzögerungen geben, die Daten müssen aktuell sein, eine Desynchronisation ist nicht erlaubt.
Das Fehlen eigener Tabellen und Indizes erlaubte es nicht, spezifischere Abfragen zu erstellen, die auf den eigenen Bedarf zugeschnitten sind. Zum Beispiel könnte es für das Tracking-System sinnvoll sein, einen Index auf die Pizzaservice-Tabelle in der Bestelltabelle zu haben. Wir ziehen immer die Bestellungen vom Pizzaservice aus der Datenbank des Trackers. Dabei ist es für die Annahme der Bestellung nicht so wichtig, in welches Pizzarestaurant sie fällt; entscheidend ist, welcher Kunde diese Bestellung aufgegeben hat. Daher wird ein Index für den Kunden benötigt. Außerdem ist es für den Tracker in der Bestelltabelle nicht notwendig, die ID des gedruckten Belegs oder die mit der Bestellung verbundenen Bonusaktionen zu speichern. Diese Informationen interessieren unseren Tracking-Service nicht. In einer zentralen Monolith-Datenbank könnten die Tabellen lediglich einen Kompromiss unter allen Nutzern darstellen. Das war eines der ursprünglichen Probleme.
WAR. Ursprünglich war die Architektur so:
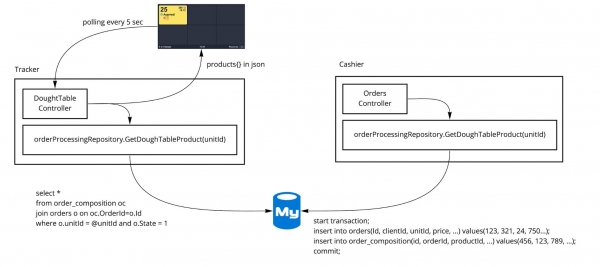
Selbst nach der Auslagerung in separate Prozesse blieb der größte Teil des Codes gemeinschaftlich für verschiedene Dienste. Alles unterhalb der Controller war einheitlich und lebte in einem Repository. Es wurden gemeinsame Methoden für Dienste, Repositories und eine gemeinsame Datenbank verwendet, in der sich die gemeinsamen Tabellen befanden.
Entlastung des Trackers
Das Hauptproblem mit dem Tracker besteht darin, dass die Daten zwischen verschiedenen Datenbanken synchronisiert werden müssen. Dies ist auch der Hauptunterschied zum Auth-Service, da Bestellungen und deren Status sich ändern können und in verschiedenen Diensten angezeigt werden müssen.
Wir nehmen Bestellungen über die Kasse des Restaurants (das ist der Service) entgegen, diese werden in der Datenbank als „Akzeptiert“ gespeichert. Danach müssen sie zum Tracker gelangen, wo sich ihr Status mehrmals ändern wird: von „Küche“ bis „Verpackt“. Dabei können bei der Bestellung externe Einflüsse von der Kasse oder der Benutzeroberfläche des Schichtmanagers auftreten. Ich führe in einer Tabelle die Bestellstatus mit ihren Beschreibungen auf:
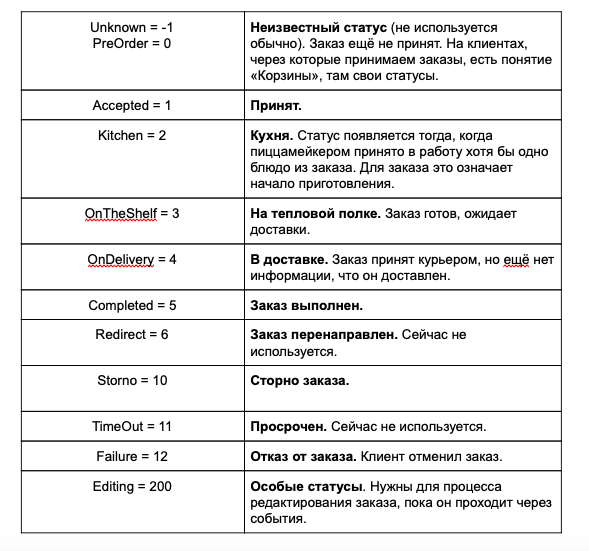
Das Schema zur Änderung der Bestellstatus sieht folgendermaßen aus:
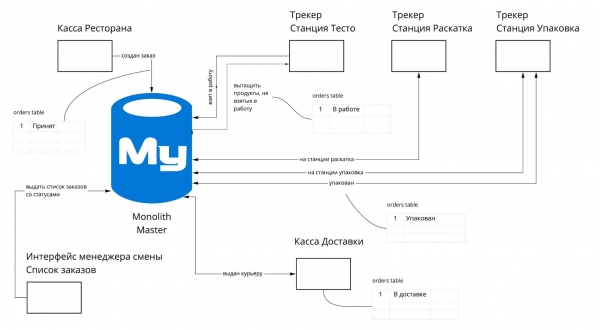
Die Statuswechsel erfolgen zwischen verschiedenen Systemen. Hierbei ist der Tracker nicht das endgültige System, in dem die Daten abgeschlossen werden. Wir haben mehrere mögliche Ansätze zur Trennung in einem solchen Fall gesehen:
- Alle Aktionen einer Bestellung in einem einzigen Service konzentrieren. In unserem Fall erfordert diese Option jedoch einen zu großen Service zur Bearbeitung von Bestellungen. Wenn wir uns dafür entscheiden würden, hätten wir ein zweites Monolith-System geschaffen. So würden wir die Probleme nicht lösen.
- Ein System ruft das andere auf. Die zweite Variante ist bereits interessanter. Allerdings können dabei Aufrufketten auftreten (), die Komponenten sind stärker miteinander verbunden, was die Verwaltung komplizierter macht.
- Wir organisieren Ereignisse, bei denen jeder Dienst mit einem anderen über diese Ereignisse kommuniziert. Letztendlich wurde die dritte Variante gewählt, bei der alle Dienste beginnen, Ereignisse miteinander auszutauschen.
Die Wahl der dritten Variante bedeutete, dass der Tracker eine eigene Datenbank hat, und bei jeder Änderung der Bestellung ein Ereignis darüber sendet, auf das andere Dienste abonnieren und das auch in der Master-Datenbank landet. Dafür benötigten wir einen Dienst, der die Nachrichtenübermittlung zwischen den Diensten gewährleistet.
Zu diesem Zeitpunkt hatten wir bereits RabbitMQ in unserem Stack, weshalb die endgültige Entscheidung fiel, es als Nachrichtenbroker zu verwenden. In der Abbildung ist der Übergang der Bestellung von der Restaurantkasse über den Tracker dargestellt, wo sich ihr Status ändert und sie im Manager-Interface angezeigt wird. WURDE:
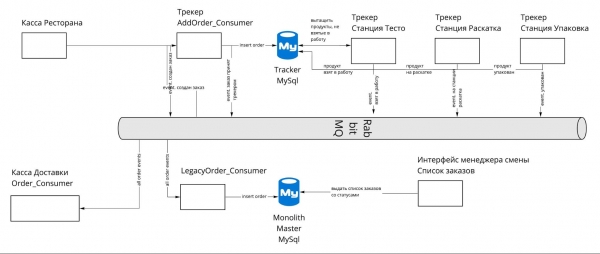
Der Bestellprozess in Schritten
Der Bestellprozess beginnt bei einem der Quellendienste für Bestellungen. Hier ist es die Restaurantkasse:
- An der Kasse ist die Bestellung vollständig vorbereitet und kann an den Tracker gesendet werden. Ein Ereignis wird ausgelöst, auf das der Tracker abonniert ist.
- Der Tracker speichert die Bestellung in seiner eigenen Datenbank, während er das Ereignis „BestellungVomTrackerAkzeptiert“ erstellt und es an RMQ sendet.
- Im Event-Bus sind bereits mehrere Handler für die Bestellung abonniert. Für uns ist derjenige wichtig, der die Synchronisierung mit der monolithischen Datenbank durchführt.
- Der Handler empfängt das Ereignis, wählt relevante Informationen daraus aus: in unserem Fall den Status der Bestellung „VomTrackerAkzeptiert“ und aktualisiert seinen Bestellentität in der Hauptdatenbank.
Wenn jemand die Bestellung genau aus der monolithischen Tabelle orders benötigt, kann er diese auch dort abfragen. Zum Beispiel ist dies für die Schnittstelle Bestellungen im Schichtmanager notwendig:
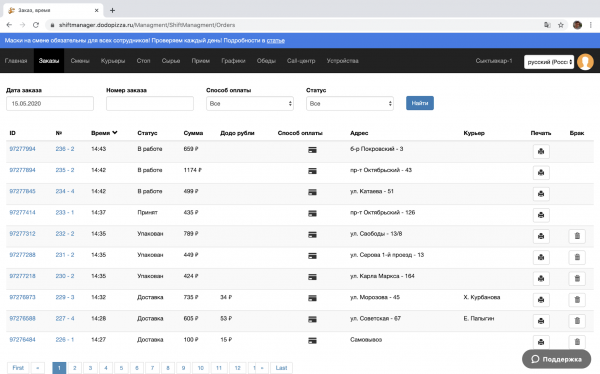
Alle anderen Dienste können sich ebenfalls auf die Bestellereignisse des Trackers abonnieren, um sie für sich zu nutzen.
Wenn eine Bestellung nach einer gewissen Zeit in Bearbeitung genommen wird, ändert sich ihr Status zunächst in der Datenbank (Tracker-Datenbank), und dann wird sofort das Ereignis „BestellungInBearbeitung“ generiert. Dieses gelangt ebenfalls in die RMQ, von wo es in die monolithische Datenbank synchronisiert und an andere Dienste geliefert wird. Auf diesem Weg können verschiedene Probleme auftreten, die näher im Bericht von Jewgeni Peschkow betrachtet werden können. .
Die endgültige Architektur nach den Änderungen in Auth und Tracker
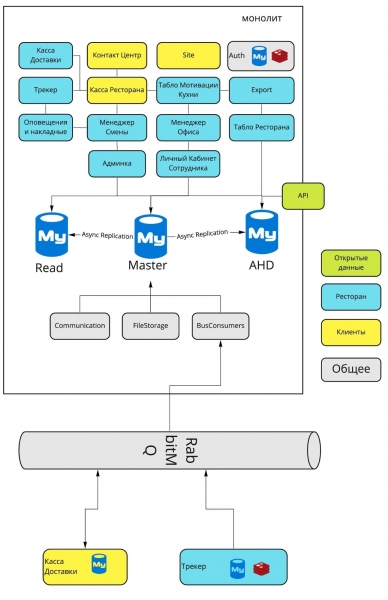
Zusammenfassend lässt sich sagen: Ursprünglich hatte ich die Idee, die neunjährige Geschichte des Dodo IS-Systems in einem einzigen Artikel zusammenzufassen. Ich wollte schnell und einfach über die Evolution der verschiedenen Etappen berichten. Doch als ich mit dem Material begann, wurde mir klar, dass alles viel komplexer und interessanter ist, als es scheint.
Während ich über den Nutzen (oder dessen Fehlen) solcher Materialien nachdachte, kam ich zu dem Schluss, dass eine kontinuierliche Weiterentwicklung ohne vollständige Chroniken von Ereignissen, ausführlichen Retrospektiven und Analysen vergangener Entscheidungen nicht möglich ist.
Ich hoffe, es war für Sie interessant und hilfreich, mehr über unseren Weg zu erfahren. Momentan stehe ich vor der Entscheidung, welchen Teil des Dodo IS-Systems ich im nächsten Artikel beschreiben soll: Schreiben Sie einen Kommentar oder stimmen Sie ab.
Nur registrierte Benutzer können an der Umfrage teilnehmen. Sind Sie an Contour interessiert?
Welchen Teil von Dodo IS möchten Sie im nächsten Artikel kennenlernen?
24,1%Der frühe Monolith in Dodo IS (2011-2015)14
24,1%Die ersten Probleme und ihre Lösungen (2015-2016)14
20,7%Der Weg des Clientbereichs: Die Fassade über der Datenbank (2016-2017)12
36,2%Die Geschichte der echten Mikrodienste (2018-2019)21
44,8%Der vollständige Zerschlag des Monolithen und die Stabilisierung der Architektur26
29,3%Über die zukünftigen Entwicklungspläne des Systems17
19,0%Ich möchte nichts über Dodo IS wissen11
58 Benutzer haben abgestimmt. 6 Benutzer haben sich enthalten.
Quelle: habr.com
