

Der Inhalt dieses Artikels stammt von meinem .

Datenverschiebungsmechanismus
- Datenblock dblk_t
- Nachricht mblk_t
- Funktionen zur Verarbeitung von Nachrichten mblk_t
- Warteschlange queue_t
- Funktionen zur Verarbeitung von Warteschlangen queue_t
- Filterverbindung
- Signalpunkt des Datenverarbeitungsgrafen
- Hintergrundaktivitäten des Tickers
- Puffer (MSBufferizer)
- Funktionen zur Verarbeitung mit MSBufferizer
Im letzten Wir haben unseren eigenen Filter entwickelt. In diesem Artikel widmen wir uns dem internen Mechanismus der Datenverschiebung zwischen den Medienstreamern. Dies wird es in Zukunft ermöglichen, raffinierte Filter mit geringerem Aufwand zu schreiben.
Datenverschiebungsmechanismus
Die Datenverschiebung im Medienstreamer erfolgt über Warteschlangen, die durch die Struktur queue_tbeschrieben werden. Über die Warteschlangen werden Sequenzen von Nachrichten des Typs mblk_tverschoben, die selbst keine Signaldaten enthalten, sondern lediglich Verweise auf die vorherige, nächste Nachricht und auf den Datenblock. Darüber hinaus möchte ich besonders betonen, dass es auch ein Feld für einen Verweis auf eine Nachricht desselben Typs gibt, das es ermöglicht, eine verkettete Liste von Nachrichten zu organisieren. Die Gruppe von Nachrichten, die durch eine solche Liste verbunden sind, nennen wir ein Tuple. Somit kann jedes Element der Warteschlange eine einzelne Nachricht sein. mblk_t, und vielleicht auch als Nachrichten-Tuple. mblk_t. Jedes Nachrichtentuple kann sein eigenes Datenblock haben. Warum Tuples benötigt werden, werden wir etwas später besprechen.
Wie bereits erwähnt, enthält die Nachricht selbst keinen Datenblock; sie enthält nur einen Verweis auf den Speicherbereich, in dem der Block gespeichert ist. In diesem Teil ähnelt das Gesamtbild der Funktionsweise des Media Streamers einem Lagerhaus voller Türen aus dem Cartoon "Die Monster AG", in dem die Türen (Datenverlinkungen – Räume) mit einer verrückten Geschwindigkeit über Förderbänder bewegt werden, während die Räume selbst unbeweglich bleiben.
Nun gehen wir die Hierarchie von unten nach oben durch und betrachten die genannten Entitäten des Datenübertragungsmechanismus im Media Streamer im Detail.
Datenblock dblk_t
Ein Datenblock besteht aus einem Header und einem Datenpuffer. Der Header wird durch die folgende Struktur beschrieben,
typedef struct datab
{
unsigned char *db_base; // Zeiger auf den Beginn des Datenpuffers.
unsigned char *db_lim; // Zeiger auf das Ende des Datenpuffers.
void (*db_freefn)(void*); // Funktion zur Freigabe des Speichers bei Löschung des Blocks.
int db_ref; // Zähler für Verweise.
} dblk_t;Die Felder der Struktur enthalten Verweise auf den Anfang des Puffers, das Ende des Puffers und die Funktion zum Löschen des Datenpuffers. Das letzte Element im Header db_ref – ein Referenzzähler, der, wenn er null erreicht, ein Signal zum Löschen dieses Blocks aus dem Speicher gibt. Wenn der Datenblock durch die Funktion datab_alloc() erstellt wurde, wird der Datenpuffer direkt hinter dem Header im Speicher platziert. In allen anderen Fällen kann der Puffer an einem anderen Ort liegen. Im Datenpuffer werden die Signalwerte oder andere Daten gespeichert, die wir durch Filter bearbeiten möchten.
Ein neuer Datenblock wird durch die Funktion erstellt:
dblk_t *datab_alloc(int size);Der Eingabeparameter ist die Größe der Daten, die der Block speichern wird. Es wird zusätzlicher Speicher zugewiesen, um am Anfang des zugewiesenen Speichers den Header – die Struktur datab– unterzubringen. Aber bei der Verwendung anderer Funktionen kommt das nicht immer vor; in einigen Fällen kann der Datenpuffer vom Header des Datenblocks getrennt sein. Die Felder der Struktur werden beim Erstellen so konfiguriert, dass das Feld db_base auf den Anfang des Datenbereichs verweist, und db_lim auf dessen Ende. Der Referenzzähler db_ref wird in die Einheit gesetzt. Der Zeiger für die Datenbereinigung wird auf Null gesetzt.
Nachricht mblk_t
Wie bereits erwähnt, haben die Warteschlangenelemente den Typ mblk_t, er ist wie folgt definiert:
typedef struct msgb
{
struct msgb *b_prev; // Zeiger auf das vorherige Listenelement.
struct msgb *b_next; // Zeiger auf das nächste Listenelement.
struct msgb *b_cont; // Zeiger zum Anhängen anderer Nachrichten an die Nachricht, um ein Nachrichten-Tuple zu erstellen.
struct datab *b_datap; // Zeiger auf die Datenblockstruktur.
unsigned char *b_rptr; // Zeiger auf den Beginn des Datenbereichs zur Lesung von Daten aus dem Puffer b_datap.
unsigned char *b_wptr; // Zeiger auf den Beginn des Datenbereichs zur Schreibung von Daten in den Puffer b_datap.
uint32_t reserved1; // Reserviertes Feld 1, der Medienstremer platziert dort Verwaltungsinformationen.
uint32_t reserved2; // Reserviertes Feld 2, der Medienstremer platziert dort Verwaltungsinformationen.
#if defined(ORTP_TIMESTAMP)
struct timeval timestamp;
#endif
ortp_recv_addr_t recv_addr;
} mblk_t;Struktur mblk_t enthält am Anfang die Zeiger b_prev, b_next, die erforderlich sind, um eine doppelt verkettete Liste (die Warteschlange ist) zu organisieren. queue_t).
Dann folgt der Zeiger b_cont, der nur verwendet wird, wenn die Nachricht in das Tuple eintritt. Für die letzte Nachricht im Tuple bleibt dieser Zeiger null。
Als nächstes sehen wir einen Zeiger auf einen Datenblock b_datap, der das zugrunde liegende Nachrichtenobjekt repräsentiert. Danach folgen Zeiger auf den Bereich innerhalb des Datenpuffers des Blocks. Das Feld b_rptr weist auf die Stelle hin, von der aus Daten aus dem Puffer gelesen werden. Das Feld b_wptr bezeichnet den Ort, an dem Daten in den Puffer geschrieben werden.
Die verbleibenden Felder sind administrativen Charakters und betreffen nicht den Betrieb des Datenübertragungsmechanismus.
Unten ist eine einzelne Nachricht mit dem Namen m1 und einem Datenblock dargestellt d1.
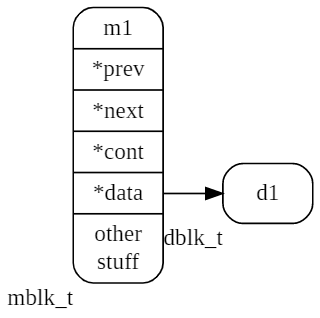
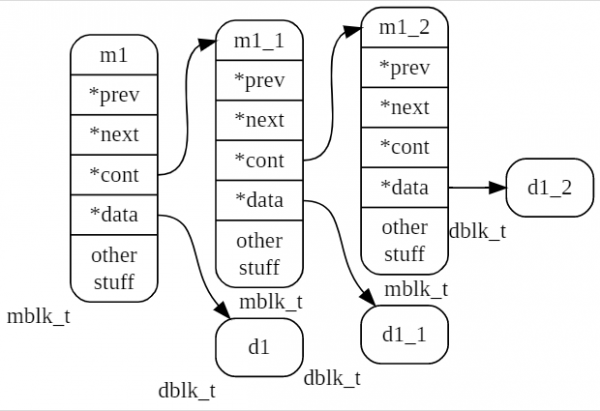
Im nächsten Bild sehen wir ein Tuple aus drei Nachrichten m1, m1_1, m1_2.
Die Funktionen zur Verarbeitung von Nachrichten mblk_t
Eine neue Nachricht mblk_t wird erstellt durch die Funktion:
mblk_t *allocb(int size, int pri); dies reserviert im Speicher eine neue Nachricht mblk_t mit einem Datenblock der angegebenen Größe Größe, das zweite Argument — pri wird in dieser Version der Bibliothek nicht verwendet. Es sollte null bleiben. Während der Ausführung der Funktion wird Speicher für die Struktur der neuen Nachricht reserviert und die Funktion mblk_init(), die alle Felder des erstellten Strukturbeispiels zurücksetzt und dann mit Hilfe des oben genannten datab_alloc(), einen Datenpuffer erstellt. Danach werden die Felder in der Struktur konfiguriert:
mp->b_datap=datab;
mp->b_rptr=mp->b_wptr=datab->db_base;
mp->b_next=mp->b_prev=mp->b_cont=NULL;Am Ende erhalten wir eine neue Nachricht mit initialisierten Feldern und einem leeren Datenpuffer. Um Daten zur Nachricht hinzuzufügen, müssen diese in den Datenblockpuffer kopiert werden:
memcpy(msg->b_rptr, data, size);wobei data — der Zeiger auf die Datenquelle, und Größe — deren Größe.
danach muss der Schreibzeiger aktualisiert werden, sodass er wieder auf den Anfang des freien Bereichs im Puffer zeigt:
msg->b_wptr = msg->b_wptr + sizeSoll eine Nachricht aus einem bereits vorhandenen Puffer erstellt werden, ohne Kopieren, wird dafür die Funktion verwendet:
mblk_t *esballoc(uint8_t *buf, int size, int pri, void (*freefn)(void*)); Die Funktion wird nach der Erstellung der Nachricht und der Struktur des Datenblocks die Zeiger auf die Daten an der Adresse buf. Das heißt, in diesem Fall befindet sich der Datenpuffer nicht hinter den Feldern des Datenblock-Headers, wie es bei der Erstellung des Datenblocks durch die Funktion war. datab_alloc(). Der an die Funktion übergebene Datenpuffer bleibt an seiner Stelle, wird jedoch mit Hilfe von Zeigern auf den neu erstellten Datenblockheader gelenkt, der wiederum auf die Nachricht zeigt.
Zu einer Nachricht mblk_t können mehrere Datenblöcke nacheinander angehängt werden. Dies geschieht durch die Funktion:
mblk_t * appendb(mblk_t *mp, const char *data, int size, bool_t pad); mp – die Nachricht, zu der ein weiterer Datenblock hinzugefügt wird;
data – ein Zeiger auf den Block, dessen Kopie in die Nachricht eingefügt wird;
Größe – die Größe der Daten;
pad – ein Flag, das angibt, dass die Größe des reservierten Speichers auf 4 Bytes ausgerichtet werden soll (die Auffüllung erfolgt mit Nullen).
Wenn im vorhandenen Datenpuffer der Nachricht ausreichend Platz vorhanden ist, werden die neuen Daten hinter den bereits dort befindlichen Daten eingefügt. Ist der freie Platz im Datenpuffer der Nachricht jedoch geringer als Größe, dann wird eine neue Nachricht mit ausreichender Pufferspeichergröße erstellt und die Daten werden in ihren Puffer kopiert. Diese neue Nachricht wird über einen Zeiger b_contan die ursprüngliche angehängt. In diesem Fall wird die Nachricht zu einem Tuple.
Wenn ein weiterer Datenblock zum Tuple hinzugefügt werden soll, muss die Funktion verwendet werden:
void msgappend(mblk_t *mp, const char *data, int size, bool_t pad);es wird die letzte Nachricht im Tuple gefunden (die ist b_cont null) und dafür wird die Funktion appendb() aufgerufen..
Um die Größe der Daten in einer Nachricht oder Tuple zu ermitteln, kann die Funktion verwendet werden:
int msgdsize(const mblk_t *mp);Diese durchläuft alle Nachrichten des Tuples und gibt die Gesamtdatenmenge in den Datenpuffern dieser Nachrichten zurück. Für jede Nachricht wird die Datenmenge wie folgt berechnet:
mp->b_wptr - mp->b_rptrUm zwei Tuples zu verbinden, wird die Funktion verwendet:
mblk_t *concatb(mblk_t *mp, mblk_t *newm);Diese fügt das Tuple newm ans Ende des Tuples an mp und gibt einen Zeiger auf die letzte Nachricht des resultierenden Tuples zurück.
Falls erforderlich, kann das Tuple in eine einzige Nachricht mit einem einzigen Datenblock umgewandelt werden, dies geschieht durch die Funktion:
void msgpullup(mblk_t *mp,int len);wenn das Argument len gleich -1 ist, wird die Größe des reservierten Puffers automatisch bestimmt. Wenn len Wenn es sich um eine positive Zahl handelt, wird ein Puffer dieser Größe erstellt, in den die Daten der Tuple-Nachrichten kopiert werden. Wenn der Puffer voll ist, wird das Kopieren gestoppt. Die erste Nachricht des Tuples erhält einen neuen Puffer mit den kopierten Daten. Die übrigen Nachrichten werden gelöscht und der Speicher wird wieder in den Heap zurückgegeben.
Beim Löschen der Struktur mblk_t wird der Referenzzähler des Datenblocks berücksichtigt. Wenn beim Aufruf von freeb() dieser gleich null ist, wird der Datenpuffer zusammen mit dem Exemplar gelöscht, mblk_tauf das verwiesen wird.
Initialisierung der Felder der neuen Nachricht:
void mblk_init(mblk_t *mp);Hinzufügen eines weiteren Datenabschnitts zur Nachricht:
mblk_t * appendb(mblk_t *mp, const char *data, size_t size, bool_t pad);Wenn die neuen Daten nicht in den freien Speicher des Datenpuffers der Nachricht passen, wird der Nachricht ein separat erstelltes Nachricht mit dem benötigten Puffer angehängt (im ersten Nachricht wird ein Zeiger auf die hinzugefügte Nachricht gesetzt), die Nachricht wird zu einem Tuple.
Hinzufügen eines Datenabschnitts zum Tuple:
void msgappend(mblk_t *mp, const char *data, size_t size, bool_t pad); Die Funktion ruft appendb() in einer Schleife auf.
Zusammenführen von zwei Tuples zu einem:
mblk_t *concatb(mblk_t *mp, mblk_t *newm);Nachricht newm wird angehängt an mp.
Erstellen einer Kopie eines einzelnen Nachrichtenblocks:
mblk_t *copyb(const mblk_t *mp);Vollständige Kopie eines Tupels mit allen Datenblöcken:
mblk_t *copymsg(const mblk_t *mp);Die Elemente des Tupels werden durch die Funktion copyb().
Erstellen einer leichten Kopie der Nachricht mblk_t. Dabei wird der Datenblock nicht kopiert, sondern nur der Zähler seiner Verweise erhöht. db_ref:
mblk_t *dupb(mblk_t *mp);Erstellen einer leichten Kopie des Tupels. Die Datenblöcke werden nicht kopiert, nur ihre Zähler für Verweise erhöht. db_ref:
mblk_t *dupmsg(mblk_t* m);Zusammenfügen aller Nachrichten des Tupels zu einer einzigen Nachricht:
void msgpullup(mblk_t *mp, size_t len);Wenn das Argument len gleich -1 ist, wird die Größe des reservierten Puffers automatisch bestimmt.
Löschen einer Nachricht oder eines Tupels:
void freemsg(mblk_t *mp);Der Zähler der Verweise des Datenblocks wird um eins verringert. Erreicht dieser dabei null, wird der Datenblock ebenfalls gelöscht.
Berechnung der Gesamtgröße der Daten in einer Nachricht oder einem Tupel.
size_t msgdsize(const mblk_t *mp);Abrufen einer Nachricht aus dem Ende der Warteschlange:
mblk_t *ms_queue_peek_last (q);Kopieren des Inhalts der reservierten Felder einer Nachricht in eine andere Nachricht (tatsächlich befinden sich in diesen Feldern Flags, die vom Mediastreamer verwendet werden):
mblk_meta_copy(const mblk_t *source, mblk *dest);Queue queue_t
Die Nachrichtenwarteschlange im Media-Streamer ist als zirkuläre doppelt verkettete Liste implementiert. Jeder Listeneintrag enthält einen Zeiger auf einen Datenblock mit Signalwerten. Das bedeutet, dass nur die Zeiger auf die Datenblöcke bewegt werden, während die tatsächlichen Daten unverändert bleiben. Mit anderen Worten, es werden nur die Referenzen auf die Daten verschoben.
Die Struktur, die die Warteschlange beschreibt queue_t, ist unten dargestellt:
typedef struct _queue
{
mblk_t _q_stopper; /* "Leeres" Element der Warteschlange, zeigt nicht auf Daten, wird nur zur Verwaltung der Warteschlange verwendet. Bei der Initialisierung der Warteschlange (qinit()) werden seine Zeiger so eingestellt, dass sie auf sich selbst zeigen. */
int q_mcount; // Anzahl der Elemente in der Warteschlange.
} queue_t;Die Struktur enthält ein Feld – einen Zeiger _q_stopper vom Typ *mblk_t, der auf das erste Element (Nachricht) in der Warteschlange zeigt. Das zweite Feld der Struktur ist ein Zähler für die in der Warteschlange befindlichen Nachrichten.
Im folgenden Bild ist die Warteschlange mit dem Namen q1 zu sehen, die 4 Nachrichten m1, m2, m3, m4 enthält.
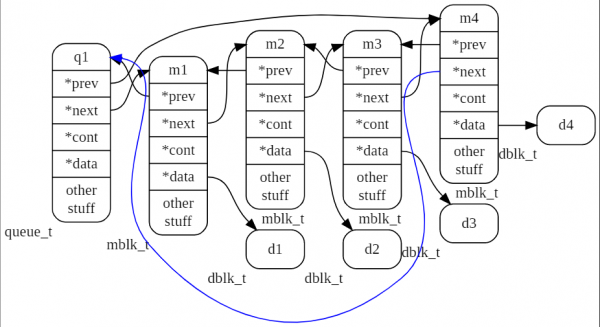
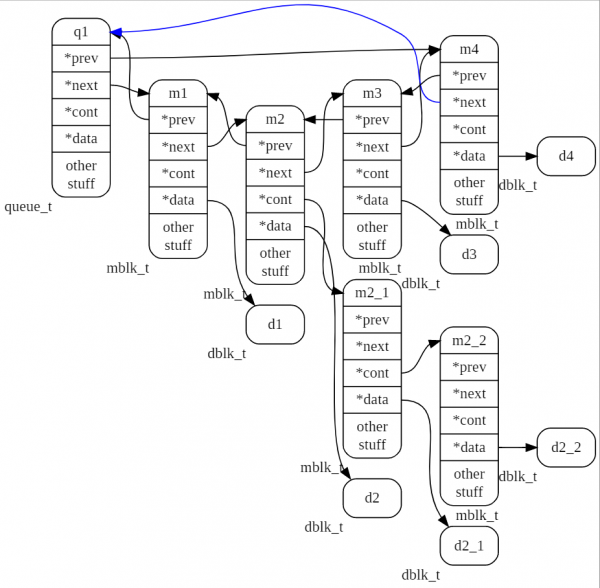
Im nächsten Bild ist die Warteschlange mit dem Namen q1 zu sehen, die 4 Nachrichten m1, m2, m3, m4 enthält. Die Nachricht m2 ist der Kopf eines Tupels, zu dem noch zwei Nachrichten m2_1 und m2_2 führen.
Funktionen zur Verarbeitung von Warteschlangen queue_t
Initialisierung der Warteschlange:
void qinit(queue_t *q);Feld _q_stopper (weiterhin als "Stopp" bezeichnet) wird durch eine Funktion initialisiert. mblk_init(), sein Zeiger auf das vorherige und das nächste Element wird so eingestellt, dass sie auf ihn selbst zeigen. Der Elementzähler der Warteschlange wird auf null zurückgesetzt.
Hinzufügen eines neuen Elements (Nachricht):
void putq(queue_t *q, mblk_t *m);Das neue Element m wird am Ende der Liste hinzugefügt, die Zeiger des Elements werden so eingestellt, dass der Stopp das nächste Element für es wird, und es wird für den Stopp das vorherige. Der Zähler der Elemente der Warteschlange wird inkrementiert.
Entziehen eines Elements aus der Warteschlange:
mblk_t * getq(queue_t *q); es wird die Nachricht abgeholt, die nach dem Stopp steht, der Elementzähler wird dekrementiert. Wenn es in der Warteschlange außer dem Stopp keine Elemente mehr gibt, wird 0 zurückgegeben.
Einfügen einer Nachricht in die Warteschlange:
void insq(queue_t *q, mblk_t *emp, mblk_t *mp); Das Element mp es wird vor dem Element empuseString emp=0, dann wird die Nachricht am Ende der Warteschlange hinzugefügt.
Entziehen einer Nachricht vom Kopf der Warteschlange:
void remq(queue_t *q, mblk_t *mp); Der Elementzähler wird dekrementiert.
Lesen des Zeigers auf das erste Element in der Warteschlange:
mblk_t * peekq(queue_t *q); Entfernen aller Elemente aus der Warteschlange mit Entfernen der eigentlichen Elemente:
void flushq(queue_t *q, int how);Das Argument wie wird nicht verwendet. Der Zähler für die Elemente in der Warteschlange wird auf null gesetzt.
Makro zum Lesen des Zeigers auf das letzte Element der Warteschlange:
mblk_t * qlast(queue_t *q);Beim Arbeiten mit Nachrichtenwarteschlangen sollte beachtet werden, dass bei einem Aufruf von ms_queue_put(q, m) mit einem null-Zeiger auf die Nachricht, die Funktion in eine Endlosschleife gerät. Ihr Programm wird hängen bleiben. Dasselbe Verhalten zeigt sich bei ms_queue_next(q, m).
Filterverbindung
Die oben beschriebene Warteschlange wird verwendet, um Nachrichten von einem Filter zu einem anderen oder von einem zu mehreren Filtern zu übertragen. Filter und ihre Verbindungen bilden einen gerichteten Graph. Den Eingang oder Ausgang eines Filters nennen wir allgemein "Pin". Zur Beschreibung der Verbindungsreihenfolge zwischen den Filtern wird im Media-Streamer das Konzept des "Signalpunkts" verwendet. Ein Signalpunkt ist eine Struktur _MSCPoint, die einen Zeiger auf den Filter und die Nummer eines seiner Pins enthält; damit beschreibt sie die Verbindung eines der Eingänge oder Ausgänge des Filters.
Signalpunkt des Datenverarbeitungsgrafen
typedef struct _MSCPoint{
struct _MSFilter *filter; // Zeiger auf den Media-Streamer-Filter.
int pin; // Nummer eines der Eingänge oder Ausgänge des Filters, d.h. Pin.
} MSCPoint;
Die Pins der Filter sind nummeriert, beginnend bei null.
Die Verbindung zweier Pins über eine Nachrichtenwarteschlange wird durch die Struktur _MSQueue, die eine Nachrichtenwarteschlange und Zeiger auf zwei Signalenpunkte enthält, die sie verbindet:
typedef struct _MSQueue
{
queue_t q;
MSCPoint prev;
MSCPoint next;
}MSQueue;
Wir nennen diese Struktur Signallink. Jeder Medienstream-Filter enthält eine Tabelle der Eingangslinks und eine Tabelle der Ausgangslinks (MSQueue). Die Größe der Tabellen wird bei der Erstellung des Filters festgelegt, dies haben wir bereits mit der exportierten Variablen vom Typ MSFilterDesc, als wir unseren eigenen Filter entwickelt haben. Im Folgenden wird die Struktur gezeigt, die jeden Filter im Medienstream beschreibt, MSFilter:
struct _MSFilter{
MSFilterDesc *desc; /* Zeiger auf die Filterbeschreibung. */
/* Geschützte Attribute, die dürfen nicht verschoben oder entfernt werden, andernfalls funktioniert die Interaktion mit Plugins nicht mehr. */
ms_mutex_t lock; /* Semaphore. */
MSQueue **inputs; /* Eingangslinktabelle. */
MSQueue **outputs; /* Ausgangslinktabelle. */
struct _MSFactory *factory; /* Zeiger auf die Fabrik, die diese Filterinstanz erstellt hat. */
void *padding; /* Wird nicht verwendet und wird aktiviert, wenn geschützte Felder hinzugefügt werden. */
void *data; /* Zeiger auf eine beliebige Struktur zur Speicherung der internen Zustandsdaten des Filters und für zwischengerechnete Berechnungen. */
struct _MSTicker *ticker; /* Zeiger auf das Ticker-Objekt, das nicht null sein darf, wenn die Funktion process() aufgerufen wird. */
/*private attributes, they can be moved and changed at any time*/
MSList *notify_callbacks; /* Liste von Rückruffunktionen, die zur Verarbeitung von Filterereignissen verwendet werden. */
uint32_t last_tick; /* Nummer des letzten Taktes, in dem die Funktion process() aufgerufen wurde. */
MSFilterStats *stats; /* Statistiken zur Filterverarbeitung. */
int postponed_task; /* Anzahl der verschobenen Aufgaben. Einige Filter können die Datenverarbeitung (Aufruf von process()) um mehrere Takte verzögern. */
bool_t seen; /* Flag, das der Ticker verwendet, um zu kennzeichnen, dass diese Filterinstanz in diesem Takt bereits bedient wurde. */
};
typedef struct _MSFilter MSFilter;
Nachdem wir die Filter in unserem C-Programm gemäß unserem Konzept verbunden haben (aber den Ticker nicht angeschlossen haben), haben wir damit einen gerichteten Graphen geschaffen, dessen Knoten Instanzen der Struktur sind. MSFilter, während die Kanten Instanzen der Links sind. MSQueue.
Hintergrundaktivitäten des Tickers
Als ich Ihnen sagte, dass der Ticker ein Filter für Taktsignale ist, war das nicht die ganze Wahrheit. Der Ticker ist ein Objekt, das Funktionen gemäß einem Zeitgeber aktiviert. process() für alle Filter des Schemas (Graphen), an das er angeschlossen ist. Wenn wir im C-Programm den Ticker mit einem Filter des Graphen verbinden, zeigen wir dem Ticker den Graphen, den er von nun an verwalten wird, bis wir ihn wieder trennen. Nach dem Anschluss beginnt der Ticker, den ihm anvertrauten Graphen zu durchforsten und eine Liste der Filter zu erstellen, in die er eintritt. Um nicht denselben Filter zweimal zu "zählen", kennzeichnet er die entdeckten Filter, indem er ein Häkchen setzt. seen. Die Suche erfolgt anhand der Linktabellen, die jeder Filter hat.
Während seiner Einführungsrunde prüft der Ticker, ob unter den Filtern mindestens einer als Datenblockquelle fungiert. Wenn dies nicht der Fall ist, gilt der Graph als ungültig und der Ticker wird sofort beendet.
Wenn der Graph "gültig" ist, wird für jeden gefundenen Filter zur Initialisierung die Funktion preprocess()aufgerufen. Sobald der Zeitpunkt für den nächsten Verarbeitungstakt erreicht ist (standardmäßig alle 10 Millisekunden), ruft der Ticker die Funktion process() für alle zuvor gefundenen Quellfilter und anschließend für die restlichen Filter in der Liste auf. Wenn ein Filter Eingangslinks hat, wird die Funktion process() so lange wiederholt, bis die Warteschlangen der Eingangslinks leer sind. Danach geht er zum nächsten Filter in der Liste über und "scrollt" ihn bis die Eingangslinks von Nachrichten befreit sind. Der Ticker wechselt von Filter zu Filter, bis die Liste abgearbeitet ist. Damit endet die Verarbeitung des Taktes.
Nun kehren wir zu den Tuples zurück und besprechen, aus welchem Grund eine solche Entität im Medienstreamer hinzugefügt wurde. Generell stimmt das Volumen der Daten, das der Algorithmus innerhalb des Filters benötigt, nicht mit der Größe der Datenpuffer überein, die am Eingang ankommen, und ist nicht unbedingt ein Vielfaches davon. Nehmen wir an, wir schreiben einen Filter, der eine schnelle Fourier-Transformation durchführt, die definitionsgemäß nur Datenblöcke verarbeiten kann, deren Größe einer Potenz von zwei entspricht. Setzen wir dies auf 512 Abtastwerte. Wenn die Daten über einen Telefonkanal generiert werden, wird der Datenpuffer jeder Nachricht bei Eingang 160 Abtastwerte des Signals liefern. Es besteht die Versuchung, die Daten am Eingang nicht abzurufen, bis die erforderliche Menge an Daten vorhanden ist. In diesem Fall würde jedoch eine Kollision mit dem Ticker entstehen, der vergeblich versucht, den Filter zu leeren, bis der Eingangslink aufgebraucht ist. Früher haben wir diese Regel als das dritte Prinzip der Filterfunktion bezeichnet. Gemäß diesem Prinzip sollte die Funktion process() des Filters alle Daten aus den Eingangswarteschlangen abholen.
Darüber hinaus können von der Eingangsseite nur 512 Messungen nicht abgerufen werden, da diese nur in ganzen Blöcken abgerufen werden können. Das bedeutet, dass der Filter 640 Messungen abholen muss und von diesen 512 verwendet werden, während der Rest bis zur Ansammlung neuer Datenpools gespeichert wird. Unser Filter muss neben seiner Hauptaufgabe auch unterstützende Maßnahmen zur Zwischenlagerung der Eingangsdaten gewährleisten. Die Entwickler des Media-Streamers haben für diese gemeinsame Herausforderung ein spezielles Objekt entwickelt – den MSBufferizer (Puffer), der diese Aufgabe mithilfe von Tupeln löst.
Puffer (MSBufferizer)
Dieses Objekt wird die Eingangsdaten innerhalb des Filters sammeln und beginnt, sie zur Verarbeitung freizugeben, sobald die Informationsmenge ausreicht, um den Filteralgorithmus auszuführen. Solange der Puffer Daten speichert, arbeitet der Filter im Leerlaufmodus, ohne Rechenleistung des Prozessors zu verbrauchen. Doch sobald die Leseoperation vom Puffer ein Ergebnis ungleich null zurückgibt, beginnt die Funktion process() des Filters, Daten in passenden Portionen aus dem Puffer abzurufen und zu verarbeiten, bis diese erschöpft sind.
Nicht verwendete Daten bleiben im Puffer als erstes Element eines Tupels, an das die nachfolgenden Eingabedaten angehängt werden.
Die Struktur, die den Puffer beschreibt:
struct _MSBufferizer{
queue_t q; /* Nachrichtenwarteschlange. */
int size; /* Gesamtgröße der derzeit im Puffer befindlichen Daten. */
};
typedef struct _MSBufferizer MSBufferizer;Funktionen zur Verarbeitung mit MSBufferizer
Erstellen eines neuen Pufferexemplars:
MSBufferizer * ms_bufferizer_new(void);Speicher wird reserviert, initiiert in ms_bufferizer_init() und gibt einen Zeiger zurück.
Initialisierungsfunktion:
void ms_bufferizer_init(MSBufferizer *obj); Die Warteschlange q, Feld Größe wird auf null gesetzt.
Nachricht hinzufügen:
void ms_bufferizer_put(MSBufferizer *obj, mblk_t *m); Die Nachricht m wird in die Warteschlange eingefügt. Die berechnete Größe der Datenblöcke wird zu Größe.
Übertragung aller Nachrichten aus der Datenwarteschlange in den Puffer q:
void ms_bufferizer_put_from_queue(MSBufferizer *obj, MSQueue *q); Nachrichtentransfer vom Link q in den Puffer erfolgt mit der Funktion ms_bufferizer_put().
Lesen aus dem Puffer:
int ms_bufferizer_read(MSBufferizer *obj, uint8_t *data, int datalen); Wenn die Größe der im Puffer angesammelten Daten kleiner ist als angefordert (datalen), die Funktion gibt null zurück, die Daten werden nicht in den Datenbereich kopiert. Andernfalls erfolgt eine sequenzielle Kopie der Daten aus den im Puffer befindlichen Tupeln. Nach der Kopie wird das Tupel gelöscht und der Speicher freigegeben. Der Kopiervorgang endet, wenn datalen Bytes kopiert wurden. Wenn der Speicherplatz während eines Datenblocks ausgeht, wird in dieser Nachricht der Datenblock auf den verbleibenden nicht kopierten Teil verkürzt. Beim nächsten Aufruf wird die Kopie an dieser Stelle fortgesetzt.
Lesen der Menge an Daten, die derzeit im Puffer verfügbar sind:
int ms_bufferizer_get_avail(MSBufferizer *obj); Gibt das Feld zurück Größe desPuffers zurück.
Übertragung eines Teils der im Puffer befindlichen Daten:
void ms_bufferizer_skip_bytes(MSBufferizer *obj, int bytes);Die angegebene Anzahl von Bytes wird extrahiert und verworfen. Die ältesten Daten werden verworfen.
Löschen aller Nachrichten im Puffer:
void ms_bufferizer_flush(MSBufferizer *obj); Der Datenzähler wird auf null zurückgesetzt.
Löschen aller Nachrichten im Puffer:
void ms_bufferizer_uninit(MSBufferizer *obj); Der Zähler wird nicht zurückgesetzt.
Löschen des Puffers und Freigabe des Speichers:
void ms_bufferizer_destroy(MSBufferizer *obj); Beispiele für die Verwendung des Puffers finden Sie im Quellcode mehrerer Media-Streamer-Filter. Zum Beispiel im Filter MS_L16_ENC, der die Byte-Reihenfolge von Netzwerk- in Hostreihenfolge umstellt:
Im nächsten Artikel werden wir die Lastbewertung auf dem Ticker und Möglichkeiten zur Bekämpfung einer übermäßigen Rechenlast im Mediastreamer behandeln.
Quelle: habr.com
