

Hallo alle. In diesem Artikel erzähle ich Ihnen, warum wir uns vor neun Monaten in Avito für Kafka entschieden haben und was es ist. Ich werde einen der Anwendungsfälle vorstellen – einen Nachrichtenbroker. Lassen Sie uns abschließend darüber sprechen, welche Vorteile uns der Einsatz des Kafka-as-a-Service-Ansatzes bietet.
Problem

Beginnen wir mit etwas Kontext. Vor einiger Zeit haben wir begonnen, uns von einer monolithischen Architektur zu entfernen, und mittlerweile gibt es in Avito bereits mehrere hundert verschiedene Dienste. Sie verfügen über eigene Repositories, ihren eigenen Technologie-Stack und sind für ihren eigenen Teil der Geschäftslogik verantwortlich.
Ein Problem bei einer Vielzahl von Diensten ist die Kommunikation. Dienst A möchte häufig wissen, über welche Informationen Dienst B verfügt. In diesem Fall greift Dienst A über eine synchrone API auf Dienst B zu. Dienst C möchte wissen, was bei den Diensten D und D passiert, und dieser wiederum ist an den Diensten A und B interessiert. Wenn es viele solcher „merkwürdigen“ Dienste gibt, werden die Verbindungen zwischen ihnen zu einem Wirrwarr.
Gleichzeitig kann Dienst A jederzeit nicht mehr verfügbar sein. Und was soll in diesem Fall Dienst B und alle anderen damit verbundenen Dienste tun? Und wenn zum Abschließen eines Geschäftsvorgangs eine Kette aufeinanderfolgender synchroner Aufrufe erforderlich ist, wird die Wahrscheinlichkeit des Scheiterns des gesamten Vorgangs noch höher (und zwar umso höher, je länger die Kette ist).
Technologiewahl

Okay, die Probleme sind klar. Sie können sie beseitigen, indem Sie ein zentrales Nachrichtensystem zwischen den Diensten einrichten. Jetzt reicht es aus, dass jeder der Dienste nur über dieses Nachrichtensystem Bescheid weiß. Darüber hinaus muss das System selbst fehlertolerant und horizontal skalierbar sein und im Fehlerfall einen Aufrufpuffer für die anschließende Verarbeitung ansammeln.
Wählen wir nun die Technologie aus, auf der die Nachrichtenzustellung implementiert wird. Dazu verstehen wir zunächst, was wir von ihr erwarten:
- Nachrichten zwischen Diensten sollten nicht verloren gehen;
- Nachrichten können dupliziert werden;
- Nachrichten können bis zu einer Tiefe von mehreren Tagen gespeichert und gelesen werden (persistenter Puffer);
- Dienste können die Daten abonnieren, an denen sie interessiert sind;
- mehrere Dienste können dieselben Daten lesen;
- Nachrichten können eine detaillierte, umfangreiche Nutzlast enthalten (ereignisgesteuerte Zustandsübertragung);
- Manchmal benötigen Sie eine Garantie für die Nachrichtenreihenfolge.
Für uns war es außerdem von entscheidender Bedeutung, das skalierbarste und zuverlässigste System mit hohem Durchsatz (mindestens 100 Nachrichten mit mehreren Kilobyte pro Sekunde) auszuwählen.
Zu diesem Zeitpunkt haben wir uns von RabbitMQ (bei hohen RPMs schwer stabil zu halten), PGQ von SkyTools (nicht schnell genug und schlecht skalierbar) und NSQ (nicht persistent) verabschiedet. Alle diese Technologien werden in unserem Unternehmen eingesetzt, sie passten jedoch nicht zur zu lösenden Aufgabe.
Als nächstes begannen wir, nach neuen Technologien für uns zu suchen – Apache Kafka, Apache Pulsar und NATS Streaming.
Pulsar war der erste, der zurückgeworfen wurde. Wir kamen zu dem Schluss, dass Kafka und Pulsar ziemlich ähnliche Lösungen sind. Und trotz der Tatsache, dass Pulsar von großen Unternehmen getestet wird, neuer ist und (theoretisch) eine geringere Latenz bietet, haben wir uns entschieden, Kafka als De-facto-Standard für solche Aufgaben dieser beiden zu belassen. Wir werden wahrscheinlich in Zukunft zu Apache Pulsar zurückkehren.
Und jetzt sind noch zwei Kandidaten übrig: NATS Streaming und Apache Kafka. Wir haben beide Lösungen eingehend untersucht und beide sind für die Aufgabe geeignet. Aber am Ende hatten wir Angst vor der relativen Jugend von NATS Streaming (und vor der Tatsache, dass einer der Hauptentwickler, Tyler Treat, beschloss, das Projekt zu verlassen und sein eigenes Projekt zu starten – Liftbridge). Gleichzeitig erlaubte der Clustering-Modus des NATS-Streamings keine starke horizontale Skalierung (vermutlich ist dies seit der Hinzufügung des Partitionierungsmodus im Jahr 2017 kein Problem mehr).
Allerdings ist NATS Streaming eine coole Technologie, die in Go geschrieben und von der Cloud Native Computing Foundation unterstützt wird. Im Gegensatz zu Apache Kafka benötigt es (wahrscheinlich) keinen Zookeeper, um zu funktionieren ), da es intern RAFT implementiert. Gleichzeitig ist NATS-Streaming einfacher zu verwalten. Wir schließen nicht aus, dass wir in Zukunft zu dieser Technologie zurückkehren werden.
Und doch ist Apache Kafka bisher unser Gewinner geworden. In unseren Tests erwies es sich als recht schnell (mehr als eine Million Nachrichten pro Sekunde beim Lesen und Schreiben bei einem Nachrichtenvolumen von 1 Kilobyte), recht zuverlässig, gut skalierbar und durch Erfahrungen in der Produktion großer Unternehmen nachgewiesen. Darüber hinaus wird Kafka von mindestens einigen großen kommerziellen Unternehmen unterstützt (wir verwenden beispielsweise die Confluent-Version) und Kafka verfügt auch über ein entwickeltes Ökosystem.
Überblick über Kafka
Bevor ich anfange, werde ich Ihnen sofort ein ausgezeichnetes Buch empfehlen - Kafka: Der endgültige Leitfaden (Es gibt auch eine russische Übersetzung, aber die Begriffe brechen ein wenig das Gehirn). Darin finden Sie die Informationen, die Sie für ein grundlegendes Verständnis von Kafka benötigen, und noch ein bisschen mehr. Auch die Dokumentation selbst von Apache und der Blog von Confluent sind gut geschrieben und leicht zu lesen.
Schauen wir uns also die Funktionsweise von Kafka aus der Vogelperspektive an. Die grundlegende Kafka-Topologie besteht aus Produzent, Verbraucher, Broker und Zookeeper.
Makler
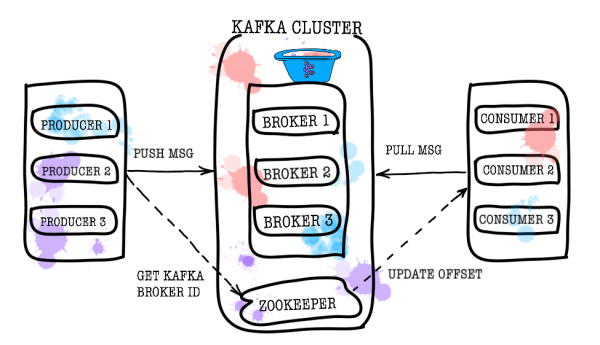
Für die Speicherung Ihrer Daten ist der Broker verantwortlich. Alle Daten werden in binärer Form gespeichert und der Broker weiß wenig darüber, was sie sind und wie ihre Struktur ist.
Jeder logische Ereignistyp befindet sich normalerweise in einem eigenen Thema (Topic). Beispielsweise kann das Anzeigenerstellungsereignis zum Thema „item.created“ gehen und das Anzeigenänderungsereignis kann zu „item.changed“ gehen. Themen können als Ereignisklassifikatoren betrachtet werden. Auf Themenebene können Sie Konfigurationsparameter festlegen wie:
- die Menge der gespeicherten Daten und/oder deren Alter (retention.bytes, retention.ms);
- Datenredundanzfaktor (Replikationsfaktor);
- maximale Größe einer Nachricht (max.message.bytes);
- die Mindestanzahl konsistenter Replikate, mit denen Daten in das Thema geschrieben werden können (min.insync.replicas);
- die Möglichkeit eines Failovers auf ein nicht synchrones, verzögertes Replikat mit potenziellem Datenverlust (unclean.leader.election.enable);
- und viele mehr ().
Jedes Thema ist wiederum in einen oder mehrere Abschnitte unterteilt. In der Partition enden die Ereignisse. Wenn es mehr als einen Broker im Cluster gibt, werden die Partitionen (soweit möglich) gleichmäßig auf alle Broker verteilt, wodurch die Last beim Schreiben und Lesen in einem Thema auf mehrere Broker gleichzeitig skaliert werden kann.
Auf der Festplatte werden die Daten für jede Partition als Segmentdateien gespeichert, die standardmäßig einem Gigabyte entsprechen (gesteuert über log.segment.bytes). Eine wichtige Funktion besteht darin, dass das Löschen von Daten aus Partitionen (wenn die Aufbewahrung ausgelöst wird) nur in Segmenten erfolgt (Sie können nicht ein Ereignis aus einer Partition löschen, Sie können nur ein gesamtes Segment und nur ein inaktives Segment löschen).
Tierpfleger
Zookeeper fungiert als Metadatenspeicher und Koordinator. Er ist es, der feststellen kann, ob Makler am Leben sind (Sie können dies mit den Augen eines Tierpflegers betrachten, indem Sie den Befehl zookeeper-shell verwenden). ls /brokers/ids), welcher Broker der Controller ist (get /controller), ob sich Partitionen im synchronen Zustand mit ihren Replikaten befinden (get /brokers/topics/topic_name/partitions/partition_number/state). Außerdem werden der Produzent und der Verbraucher zunächst zum Zookeeper gehen, um herauszufinden, auf welchem Broker welche Themen und Partitionen gespeichert sind. In Fällen, in denen für ein Thema ein Replikationsfaktor größer als 1 festgelegt ist, zeigt zookeeper an, welche Partitionen führend sind (auf sie wird geschrieben und aus ihnen gelesen). Im Falle eines Broker-Absturzes werden Informationen über neue Leader-Partitionen in zookeeper geschrieben (ab Version 1.1.0 asynchron). ).
In älteren Versionen von Kafka war der Zookeeper auch für die Speicherung von Offsets verantwortlich, jetzt werden sie jedoch in einem speziellen Topic gespeichert __consumer_offsets auf einem Broker (obwohl Sie für diesen Zweck immer noch zookeeper verwenden können).
Der einfachste Weg, Ihre Daten in einen Kürbis zu verwandeln, besteht einfach darin, Informationen mit zookeeper zu verlieren. In einem solchen Szenario wird es sehr schwierig sein zu verstehen, was und wo man lesen soll.
Produzent
Der Produzent ist meist ein Dienst, der Daten direkt in Apache Kafka schreibt. Der Produzent wählt ein Thema zum Speichern seiner Themennachrichten aus und beginnt, Informationen dazu zu schreiben. Ein Produzent könnte beispielsweise ein Werbedienst sein. In diesem Fall werden Ereignisse wie „Anzeige erstellt“, „Anzeige aktualisiert“, „Anzeige gelöscht“ usw. zu thematischen Themen gesendet. Jedes Ereignis ist ein Schlüssel-Wert-Paar.
Standardmäßig werden alle Ereignisse per Round-Robin über Themenpartitionen verteilt, wenn der Schlüssel nicht festgelegt ist (Reihenfolge verlieren), und über MurmurHash (Schlüssel), wenn der Schlüssel vorhanden ist (Reihenfolge innerhalb einer Partition).
Hier ist sofort anzumerken, dass Kafka die Reihenfolge der Ereignisse nur innerhalb einer Partition garantiert. Doch in der Realität stellt dies oft kein Problem dar. Beispielsweise ist es möglich, sicherzustellen, dass alle Änderungen an derselben Deklaration derselben Partition hinzugefügt werden (wodurch die Reihenfolge dieser Änderungen innerhalb der Deklaration beibehalten wird). Sie können auch eine Sequenznummer in einem der Ereignisfelder übergeben.
Privatkunden
Der Verbraucher ist dafür verantwortlich, Daten von Apache Kafka zu erhalten. Um auf das obige Beispiel zurückzukommen: Der Verbraucher könnte ein Moderationsdienst sein. Dieser Dienst abonniert das Thema des Anzeigendienstes. Wenn eine neue Anzeige erscheint, empfängt er diese und analysiert sie auf die Einhaltung bestimmter Richtlinien.
Apache Kafka merkt sich die letzten vom Verbraucher empfangenen Ereignisse (hierfür wird ein Service-Topic verwendet). __consumer__offsets), wodurch sichergestellt wird, dass der Verbraucher bei einem erfolgreichen Lesevorgang nicht zweimal dieselbe Nachricht erhält. Wenn Sie jedoch die Option „enable.auto.commit = true“ verwenden und Kafka die Aufgabe überlassen, die Position des Verbrauchers im Thema zu verfolgen, ist dies möglich . Im Produktionscode wird die Position des Verbrauchers meist manuell gesteuert (der Entwickler steuert den Zeitpunkt, zu dem die Festschreibung des Leseereignisses erfolgen muss).
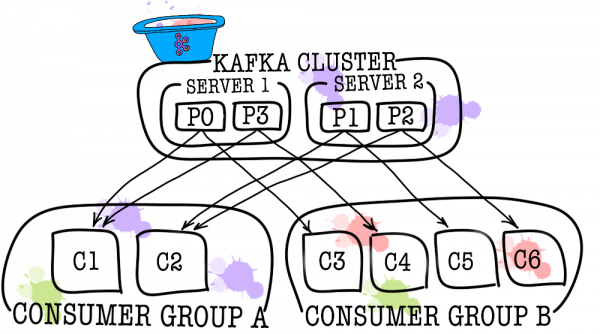
In Fällen, in denen ein Verbraucher nicht ausreicht (z. B. wenn der Strom neuer Ereignisse sehr groß ist), können Sie mehrere weitere Verbraucher hinzufügen, indem Sie sie in einer Verbrauchergruppe zusammenfassen. Eine Verbrauchergruppe ist logischerweise genau derselbe Verbraucher, jedoch mit der Verteilung der Daten zwischen den Gruppenmitgliedern. Dies ermöglicht es jedem Teilnehmer, seinen Anteil an Nachrichten zu erhalten, wodurch die Lesegeschwindigkeit skaliert wird.
Testergebnisse

Ich werde hier nicht viel erklärenden Text schreiben, sondern nur die Ergebnisse teilen. Die Tests wurden auf 3 physischen Maschinen (12 CPU, 384 GB RAM, 15 SAS-Festplatte, 10 GBit/s Netz) durchgeführt, Broker und Zookeeper wurden in lxc bereitgestellt.
Leistungstest
Während des Tests wurden die folgenden Ergebnisse erzielt.
- Die Geschwindigkeit der gleichzeitigen Aufzeichnung von Nachrichten mit einer Größe von 1 KB durch 9 Produzenten beträgt 1300000 Ereignisse pro Sekunde.
- Die Geschwindigkeit beim gleichzeitigen Lesen von 1-KB-Nachrichten durch 9 Verbraucher beträgt 1500000 Ereignisse pro Sekunde.
Fehlertoleranzprüfung
Beim Testen wurden folgende Ergebnisse erzielt (3 Makler, 3 Tierpfleger).
- Eine abnormale Beendigung eines der Broker führt nicht dazu, dass der Cluster gestoppt wird oder nicht verfügbar ist. Die Arbeit geht wie gewohnt weiter, die restlichen Makler haben jedoch eine hohe Belastung.
- Eine abnormale Beendigung von zwei Brokern führt bei einem Cluster aus drei Brokern und min.isr = 2 dazu, dass der Cluster nicht zum Schreiben, aber zum Lesen verfügbar ist. Wenn min.isr = 1, steht der Cluster weiterhin sowohl zum Lesen als auch zum Schreiben zur Verfügung. Allerdings widerspricht dieser Modus der Forderung nach hoher Datenintegrität.
- Ein abnormales Herunterfahren eines der Zookeeper-Server führt nicht dazu, dass der Cluster stoppt oder nicht mehr verfügbar ist. Die Arbeit läuft wie gewohnt weiter.
- Durch ein abnormales Herunterfahren von zwei Zookeeper-Servern ist der Cluster nicht verfügbar, bis mindestens einer der Zookeeper-Server wiederhergestellt ist. Diese Aussage gilt für einen Zookeeper-Cluster mit 3 Servern. Aus diesem Grund wurde nach Recherchen beschlossen, den Zookeeper-Cluster auf 5 Server zu erweitern, um die Fehlertoleranz zu erhöhen.
Kafka als Dienstleistung

Wir haben dafür gesorgt, dass Kafka eine hervorragende Technologie ist, die es uns ermöglicht, die vor uns liegende Aufgabe (die Implementierung eines Nachrichtenbrokers) zu lösen. Dennoch haben wir beschlossen, den direkten Zugriff von Diensten auf Kafka zu verhindern und es von oben mit dem Datenbus-Dienst zu schließen. Warum haben wir es getan? Tatsächlich gibt es einige Gründe.
Data-bus übernahm alle Aufgaben im Zusammenhang mit der Integration mit Kafka (Implementierung und Konfiguration von Consumern und Producern, Monitoring, Alerting, Logging, Skalierung etc.). Somit ist die Integration mit dem Message Broker so einfach wie möglich.
Der Datenbus ermöglichte es, für die Arbeit mit Kafka von einer bestimmten Sprache oder Bibliothek zu abstrahieren.
Der Datenbus ermöglichte es anderen Diensten, von der Speicherschicht zu abstrahieren. Vielleicht werden wir Kafka irgendwann auf Pulsar umstellen, und niemand wird etwas davon merken (alle Dienste kennen nur die Datenbus-API).
Der Datenbus übernahm die Validierung von Ereignismustern.
Die Authentifizierung wird über den Datenbus implementiert.
Unter dem Deckmantel des Datenbusses können wir Kafka-Versionen leise und ohne Ausfallzeiten aktualisieren und die Konfigurationen von Produzenten, Konsumenten, Brokern usw. zentral verwalten.
Durch den Datenbus konnten wir die von uns benötigten Funktionen hinzufügen, die nicht in Kafka enthalten sind (z. B. Themenprüfung, Anomaliekontrolle im Cluster, Erstellung von DLQs usw.).
Mit dem Datenbus können Sie ein Failover für alle Dienste zentral implementieren.
Um mit dem Senden von Ereignissen an den Nachrichtenbroker zu beginnen, reicht es derzeit aus, eine kleine Bibliothek in den Code Ihres Dienstes aufzunehmen. Das ist alles. Sie haben die Möglichkeit, mit einer Codezeile zu schreiben, zu lesen und zu skalieren. Die gesamte Implementierung bleibt Ihnen verborgen, nur ein paar Griffe wie die Batchgröße ragen heraus. Unter der Haube erhöht der Datenbusdienst die erforderliche Anzahl von Produzenten- und Verbraucherinstanzen in Kubernetes und fügt ihnen die erforderliche Konfiguration hinzu, aber all dies ist für Ihren Dienst transparent.
Natürlich gibt es kein Allheilmittel und dieser Ansatz hat seine Grenzen.
- Im Gegensatz zu Bibliotheken von Drittanbietern muss der Datenbus eigenständig unterstützt werden.
- Der Datenbus erhöht die Anzahl der Interaktionen zwischen Diensten und dem Nachrichtenbroker, was zu Leistungseinbußen im Vergleich zu reinem Kafka führt.
- Nicht alles lässt sich so einfach vor Diensten verbergen. Wir möchten nicht die Funktionalität von KSQL oder Kafka Streams im Datenbus duplizieren, daher müssen wir manchmal zulassen, dass Dienste direkt ausgeführt werden.
In unserem Fall überwogen die Vorteile die Nachteile und die Entscheidung, den Nachrichtenbroker durch einen separaten Dienst abzudecken, war gerechtfertigt. Während des Betriebsjahres hatten wir keine schwerwiegenden Unfälle und Probleme.
PS: Danke an meine Freundin Ekaterina Obaliaeva für die coolen Bilder zu diesem Artikel. Wenn sie Ihnen gefallen haben es gibt noch mehr Abbildungen.
Source: habr.com
