

Hallo, Habr! Der neue Kurs bei OTUS ist jetzt geöffnet. Zur Vorbereitung auf den Kursstart haben wir traditionell interessante Inhalte für Sie übersetzt.
Jeden Tag besuchen über hundert Millionen Menschen Twitter, um zu erfahren, was in der Welt passiert und um darüber zu diskutieren. Jeder Tweet und jede andere Benutzeraktion erzeugt ein Ereignis, das für die interne Datenanalyse bei Twitter verfügbar ist. Hunderte Mitarbeiter analysieren und visualisieren diese Daten, und die Verbesserung ihrer Erfahrung hat für das Twitter Data Platform-Team höchste Priorität.
Wir glauben, dass Benutzer mit einem breiten Spektrum an technischen Fähigkeiten in der Lage sein sollten, Daten zu finden und Zugang zu gut funktionierenden Analyse- und Visualisierungstools auf SQL-Basis zu haben. Dies würde es einer ganz neuen Gruppe von Benutzern mit weniger technischem Hintergrund, einschließlich Datenanalytikern und Produktmanagern, ermöglichen, Informationen aus den Daten zu extrahieren, sodass sie die Möglichkeiten von Twitter besser verstehen und nutzen können. So demokratisieren wir die Datenanalyse bei Twitter.
Mit der Verbesserung unserer Tools und Möglichkeiten zur internen Datenanalyse haben wir eine Steigerung der Twitter-Dienste erlebt. Dennoch gibt es noch viel Raum für Wachstum. Die aktuellen Tools wie Scalding erfordern Programmierkenntnisse. SQL-basierte Analysetools wie Presto und Vertica weisen bei großem Umfang Leistungsprobleme auf. Außerdem haben wir ein Problem mit der Verteilung von Daten über mehrere Systeme ohne ständigen Zugriff darauf.
Im letzten Jahr haben wir bekannt gegeben, im Rahmen derer wir Teile unserer auf die Google Cloud Platform (GCP) verlagern. Wir sind zu dem Schluss gekommen, dass die Tools von Google Cloud uns in unseren Bemühungen zur Demokratisierung von Analyse, Visualisierung und maschinellem Lernen bei Twitter unterstützen können:
- : ein unternehmensweites Datenlager mit einer SQL-Engine basierend auf , die für ihre Schnelligkeit, Einfachheit bekannt ist und die .
- ein Tool zur Visualisierung großer Datenmengen mit Funktionen zur Zusammenarbeit, ähnlich wie in Google Docs.
In diesem Artikel erfahren Sie von unseren Erfahrungen mit diesen Werkzeugen: was wir getan haben, was wir gelernt haben und was wir als Nächstes tun werden. Momentan konzentrieren wir uns auf Batch- und interaktive Analytik. Die Echtzeitanalyse werden wir im nächsten Artikel besprechen.
Die Geschichte der Data Warehouses bei Twitter
Bevor wir uns näher mit BigQuery beschäftigen, ist es sinnvoll, die Geschichte der Data Warehouses bei Twitter kurz zusammenzufassen. Im Jahr 2011 wurde die Datenanalyse bei Twitter mit Vertica und Hadoop durchgeführt. Um MapReduce-Jobs in Hadoop zu erstellen, verwendeten wir Pig. 2012 haben wir Pig durch Scalding ersetzt, das eine Scala-API mit Vorteilen wie der Möglichkeit, komplexe Pipelines zu erstellen, und einer einfacheren Testbarkeit bot. Dennoch war dies für viele Datenanalysten und Produktmanager, die es gewohnt waren, mit SQL zu arbeiten, eine steile Lernkurve. Etwa 2016 begannen wir, Presto als SQL-Interface für Hadoop-Daten zu verwenden. Spark bot eine Python-API, die es zu einer guten Wahl für ad-hoc Datenanalysen und maschinelles Lernen machte.
Seit 2018 nutzen wir folgende Werkzeuge zur Analyse und Visualisierung von Daten:
- Scalding für Produktionspipelines
- Scalding und Spark für ad-hoc Datenanalyse und maschinelles Lernen
- Vertica und Presto für ad-hoc und interaktive SQL-Analyse
- Druid für kleine interaktive, explorative und latenzarme Zugriffe auf Zeitreihenmetriken
- Tableau, Zeppelin und Pivot zur Datenvisualisierung
Wir haben festgestellt, dass diese Werkzeuge zwar sehr leistungsstarke Funktionen bieten, wir jedoch Schwierigkeiten hatten, diese Funktionen einem breiteren Publikum in Twitter zugänglich zu machen. Durch die Erweiterung unserer Plattform mit Google Cloud konzentrieren wir uns darauf, unsere Analysetools für alle bei Twitter zu vereinfachen.
Google BigQuery-Datenlager
Einige Teams bei Twitter haben bereits BigQuery in einige ihrer Produktionsabläufe integriert. Basierend auf ihren Erfahrungen haben wir begonnen, die Möglichkeiten von BigQuery für alle Anwendungsszenarien bei Twitter zu bewerten. Unser Ziel war es, BigQuery im gesamten Unternehmen anzubieten sowie es innerhalb des Data Platform-Toolkit zu standardisieren und zu unterstützen. Dies war aus vielen Gründen herausfordernd. Wir mussten eine Infrastruktur entwickeln, die eine zuverlässige Verarbeitung großer Datenmengen ermöglicht, das Datenmanagement im gesamten Unternehmen unterstützt, angemessene Zugriffssteuerungen gewährleistet und die Vertraulichkeit der Kunden sicherstellt. Zudem mussten wir Systeme entwickeln, um Ressourcen zu verteilen, Monitoring und Abrechnung zu gewährleisten, damit die Teams BigQuery effizient nutzen können.
Im November 2018 haben wir die Alpha-Version von BigQuery und Data Studio für das gesamte Unternehmen veröffentlicht. Wir haben Twitter-Mitarbeitern einige unserer am häufigsten verwendeten Tabellen mit bereinigten persönlichen Daten angeboten. Über 250 Nutzer aus verschiedenen Teams, darunter Ingenieurwesen, Finanzen und Marketing, haben BigQuery genutzt. Kürzlich führten sie etwa 8.000 Abfragen aus und verarbeiteten dabei rund 100 PB pro Monat, ohne die geplanten Abfragen zu berücksichtigen. Aufgrund des sehr positiven Feedbacks haben wir beschlossen, BigQuery als primäre Ressource für die Dateninteraktion bei Twitter anzubieten.
Hier ist das Schema der hochgradigen Architektur unseres Google BigQuery-Datenlagers.
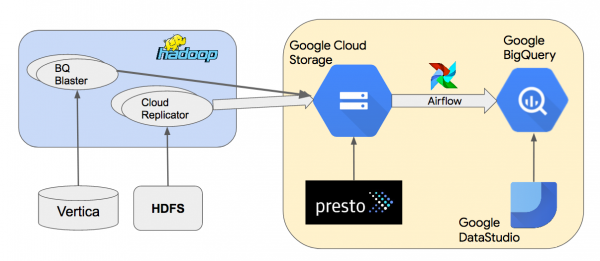
Wir kopieren Daten von lokalen Hadoop-Clustern in den Google Cloud Storage (GCS) mithilfe eines internen Tools, dem Cloud Replicator. Anschließend verwenden wir Apache Airflow, um Pipelines zu erstellen, die „“ nutzen, um Daten aus GCS in BigQuery zu laden. Wir verwenden Presto, um Datensätze im Parquet- oder Thrift-LZO-Format in GCS abzufragen. BQ Blaster ist ein internes Scalding-Tool zum Laden von Datensätzen aus HDFS Vertica und Thrift-LZO in BigQuery.
In den folgenden Abschnitten werden wir unseren Ansatz und unser Wissen in Bezug auf Benutzerfreundlichkeit, Leistung, Datenmanagement, Systemzuverlässigkeit und Kosten besprechen.
Benutzerfreundlichkeit
Wir haben festgestellt, dass es für Benutzer einfach war, mit BigQuery zu beginnen, da keine Softwareinstallation erforderlich war und die Benutzer über eine benutzerfreundliche Weboberfläche darauf zugreifen konnten. Allerdings mussten sich die Benutzer mit einigen Funktionen und Konzepten von GCP vertrautmachen, einschließlich Ressourcen wie Projekten, Datensätzen und Tabellen. Wir haben Schulungsmaterialien und Tutorials entwickelt, um den Benutzern den Einstieg zu erleichtern. Mit einem grundlegenden Verständnis konnten die Benutzer problemlos durch Datensätze navigieren, das Schema und die Daten der Tabellen anzeigen, einfache Abfragen durchführen und die Ergebnisse in Data Studio visualisieren.
Unser Ziel bezüglich der Dateneingabe in BigQuery bestand darin, einen nahtlosen Upload von Datensätzen aus HDFS oder GCS mit einem einzigen Klick zu ermöglichen. Wir haben angesehen (verwaltetes Airflow), aber wir konnten es aufgrund unseres Sicherheitsmodells „Domain Restricted Sharing“ nicht verwenden (näheres dazu im Abschnitt „Datenmanagement“ unten). Wir haben mit dem Google Data Transfer Service (DTS) experimentiert, um Lastenaufgaben in BigQuery zu organisieren. Während DTS schnell eingerichtet werden konnte, war es nicht flexibel genug, um Pipelines mit Abhängigkeiten zu erstellen. Für unsere Alpha-Version haben wir unsere eigene Apache Airflow-Umgebung in GCE erstellt und bereiten sie für den Produktionsbetrieb vor, um mehr Datenquellen wie Vertica zu unterstützen.
Um Daten in BigQuery zu transformieren, erstellen Benutzer einfache SQL-Datenpipelines mit geplanten Abfragen. Für komplexe mehrstufige Pipelines mit Abhängigkeiten planen wir, entweder unsere eigene Airflow-Infrastruktur oder Cloud Composer zusammen mit .
Leistung
BigQuery ist für allgemeine SQL-Abfragen konzipiert, die große Datenmengen verarbeiten. Es ist nicht für Abfragen mit niedriger Latenz und hoher Durchsatzleistung, die für transaktionale Datenbanken erforderlich sind, oder für die Analyse von Zeitreihen mit niedriger Latenz ausgelegt. . Für interaktive Analyseanfragen erwarten unsere Nutzer eine Antwortzeit von weniger als einer Minute. Wir mussten BigQuery so gestalten, dass es diesen Erwartungen entspricht. Um eine vorhersehbare Leistung für unsere Nutzer zu gewährleisten, haben wir die BigQuery-Funktionalität genutzt, die für zahlende Kunden verfügbar ist und es Projektinhabern ermöglicht, minimale Slots für ihre Anfragen zu reservieren. BigQuery ist eine Einheit an Rechenleistung, die erforderlich ist, um SQL-Abfragen auszuführen.
Wir haben über 800 Anfragen analysiert, die jeweils etwa 1 TB Daten verarbeiten, und festgestellt, dass die durchschnittliche Laufzeit 30 Sekunden betrug. Zudem haben wir herausgefunden, dass die Leistung stark von der Nutzung unseres Slots in verschiedenen Projekten und Aufgaben abhängt. Daher mussten wir unsere Produktions- und ad-hoc Slot-Reservierungen klar voneinander abgrenzen, um die Leistung für produktive Nutzungsszenarien und interaktive Analysen aufrechtzuerhalten. Dies hatte starken Einfluss auf unser Design für die Slot-Reservierung und die Projekt-Hierarchie.
Über Datenmanagement, Funktionalität und Kosten der Systeme sprechen wir in den kommenden Tagen in Teil zwei der Übersetzung, und momentan laden wir alle Interessierten ein zu , in dem Sie ausführlich über den Kurs erfahren und unserem Experten — Egor Mateshchuk (Senior Data Engineer, MaximaTelecom) — Fragen stellen können.
Weiterlesen:
Quelle: habr.com
