

Hallo zusammen! Mein Name ist Sascha, ich bin CTO und Mitgründer von LoyaltyLab. Vor zwei Jahren ging ich abends mit Freunden, wie es für alle armen Studenten üblich ist, in den nächsten Laden, um Bier zu kaufen. Es hat uns sehr gestört, dass der Einzelhändler, obwohl er wusste, dass wir Bier kaufen würden, keinen Rabatt auf Chips oder Cracker angeboten hat, obwohl das so logisch ist! Wir haben nicht verstanden, warum so eine Situation passiert und haben beschlossen, unser eigenes Unternehmen zu gründen. Und als Bonus haben wir uns selbst jeden Freitag Rabatte auf genau diese Chips gegeben.

Es kam so weit, dass ich mit dem Material zur technischen Seite des Produkts auf der aufgetreten bin. Wir freuen uns, unsere Entwicklungen mit der Community zu teilen, daher veröffentliche ich meinen Vortrag in Form eines Artikels.
Einführung
Wie alle am Anfang, haben wir mit einem Überblick darüber begonnen, wie Empfehlungssysteme erstellt werden. Und die beliebteste Architektur war vom folgenden Typ:

Sie besteht aus zwei Teilen:
- Das Sampling von Kandidaten für Empfehlungen erfolgt durch ein einfaches und schnelles Modell, üblicherweise kollaborativ.
- Das Ranking der Kandidaten erfolgt durch ein komplexeres und langsameres Inhaltsmodell unter Berücksichtigung aller möglichen Merkmale in den Daten.
Hier und im Folgenden verwende ich die folgenden Begriffe:
- candidate/кандидат для рекомендаций — ein Benutzer-Produkt-Paar, das potenziell für Empfehlungen in die Produktion aufgenommen werden kann.
- Kandidatenextraktion/Extraktor/Methode zur Extraktion von Kandidaten — der Prozess oder die Methode zur Extraktion von "Kandidaten für Empfehlungen" basierend auf vorhandenen Daten.
In der ersten Phase werden normalerweise verschiedene Variationen der kollaborativen Filterung verwendet. Die beliebteste ist . Erstaunlicherweise behandeln die meisten Artikel über Empfehlungssysteme nur verschiedene Verbesserungen der kollaborativen Modelle in der ersten Phase, während über andere Sampling-Methoden kaum gesprochen wird. Unser Ansatz, der sich ausschließlich auf kollaborative Modelle und verschiedene Optimierungen konzentrierte, hat nicht die Qualität erreicht, die wir erwartet hatten, weshalb wir in spezifischen Forschungen in diesem Bereich tiefer eingetaucht sind. Am Ende des Artikels zeige ich, wie sehr wir ALS verbessern konnten, das für uns das Baseline-Modell war.
Bevor ich zu unserem Ansatz komme, ist es wichtig zu erwähnen, dass es bei Echtzeitempfehlungen, bei denen wir Daten berücksichtigen müssen, die vor 30 Minuten aufgetreten sind, tatsächlich nicht viele Ansätze gibt, die in der erforderlichen Zeit arbeiten können. In unserem Fall müssen Empfehlungen jedoch nicht häufiger als einmal am Tag, und in den meisten Fällen einmal pro Woche gesammelt werden, was es uns ermöglicht, komplexe Modelle zu nutzen und die Qualität erheblich zu steigern.
Nehmen wir als Basis, welche Metriken nur ALS bei der Aufgabe der Kandidatenauswahl zeigt. Die Schlüsselmetriken, die wir im Auge behalten, sind folgende:
- Precision — der Anteil der korrekt ausgewählten Kandidaten aus den beprobten.
- Recall — der Anteil der aufgetretenen Kandidaten aus denen, die tatsächlich im Zielintervall waren.
- F1-score — F-Maß, das auf den vorherigen beiden Punkten basiert.
Wir werden auch die Metriken des endgültigen Modells nach dem Training des Gradientenboostings mit zusätzlichen Inhaltseigenschaften betrachten. Hier gibt es ebenfalls 3 Hauptmetriken:
- precision@5 — der durchschnittliche Anteil der Produkte aus den Top-5 nach Wahrscheinlichkeit für jeden Käufer.
- response-rate@5 — die Conversion-Rate von Geschäftsvorfällen in den Kauf mindestens eines personalisierten Angebots (in einem Angebot sind 5 Produkte).
- avg roc-auc per user — Durchschnitt pro Kunde.
Es ist wichtig zu beachten, dass alle genannten Metriken auf , das heißt, das Training erfolgt in den ersten k Wochen und die Testdaten stammen aus der k+1 Woche. Auf diese Weise werden saisonale Anstiege/Fälle minimal auf die Interpretation der Modellqualität übertragen. Anschließend wird in allen Grafiken die x-Achse die Wochnummer in der Kreuzvalidierung darstellen und die y-Achse den Wert der angegebenen Metrik. Alle Grafiken basieren auf Transaktionsdaten eines einzelnen Kunden, um einen korrekten Vergleich zu gewährleisten.
Bevor wir beginnen, unseren Ansatz zu beschreiben, schauen wir uns zunächst die Basislinie an, die das trainierte ALS-Modell darstellt.
Metriken zur Extraktion von Kandidaten:
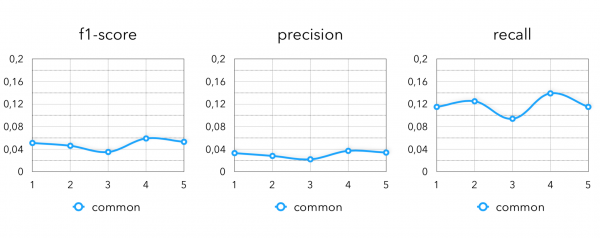
Endmetriken:
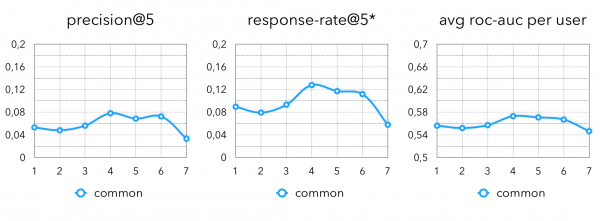
Ich betrachte alle Implementierungen von Algorithmen als eine Art Geschäftshypothese. Grob gesagt können alle kollaborativen Modelle als Hypothese betrachtet werden, dass "Menschen dazu neigen, das zu kaufen, was ähnliche Personen kaufen." Wie ich bereits erwähnt habe, haben wir uns nicht nur auf diese Semantik beschränkt, und hier sind weitere Hypothesen, die ebenfalls gut mit Daten im Offline-Einzelhandel funktionieren:
- Was bereits zuvor gekauft wurde.
- Ähnliches zu dem, was zuvor gekauft wurde.
- Zeitraum des seit längerer Zeit erfolgten Kaufs.
- Beliebte Artikel nach Kategorien/Marken.
- Wechselnde Käufe verschiedener Produkte von Woche zu Woche (Markov-Ketten).
- Ähnliche Produkte für Käufer, basierend auf Merkmalen, die aus verschiedenen Modellen abgeleitet wurden (Word2Vec, DSSM usw.).
Was früher gekauft wurde.
Die offensichtlichste Heuristik, die im Produktverkauf sehr gut funktioniert. Hier betrachten wir alle Produkte, die der Inhaber der Kundenkarte in den letzten K Tagen (gewöhnlich 1-3 Wochen) gekauft hat, oder K Tage im letzten Jahr. Mit dieser Methode erhalten wir folgende Kennzahlen:
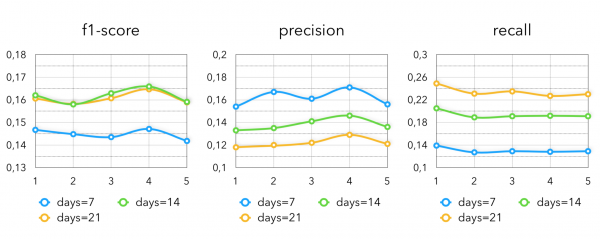
Hier ist ganz offensichtlich, dass je länger der Zeitraum, den wir wählen, desto höher unser Rückruf ist und desto geringer die Präzision und umgekehrt. Die besten Ergebnisse im Durchschnitt für unsere Kunden liefert der Zeitraum "die letzten 2 Wochen".
Ähnlich wie das, was ich vorher gekauft habe
Es ist nicht überraschend, dass für den Einzelhandel „was ich zuvor gekauft habe“ gut funktioniert, aber nur Kandidaten aus dem, was der Benutzer bereits gekauft hat, abzuleiten, ist nicht besonders effektiv, da man den Käufer mit einem neuen Produkt kaum überraschen kann. Daher schlagen wir vor, diese Heuristik mithilfe der gleichen kollaborativen Modelle etwas zu verbessern. Aus den Vektoren, die wir während des ALS-Trainings erhalten haben, können ähnliche Produkte zu dem, was der Benutzer bereits gekauft hat, herausgearbeitet werden. Diese Idee ähnelt sehr den „ähnlichen Videos“ in Video-Streaming-Diensten. Da wir jedoch nicht wissen, was der Benutzer zu einem bestimmten Zeitpunkt isst/kauft, bleibt uns nur, nach ähnlichen Angeboten zu suchen, die er bereits gekauft hat, zumal wir bereits wissen, wie gut das funktioniert. Wenn wir diese Methode auf den Transaktionen der letzten 2 Wochen anwenden, erhalten wir folgende Kennzahlen:
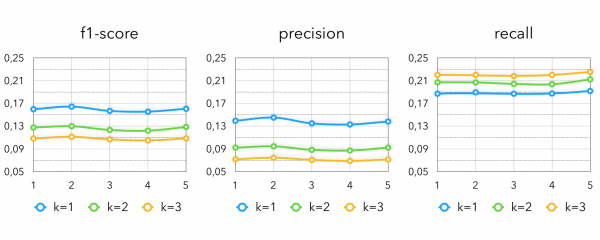
Hier k — die Anzahl ähnlicher Produkte, die für jedes vom Kunden gekaufte Produkt der letzten 14 Tage abgerufen werden.
Dieser Ansatz hat bei einem Kunden besonders gut funktioniert, bei dem es entscheidend war, nichts zu empfehlen, was bereits in der Kaufhistorie des Benutzers war.
Zeitraum des längst zurückliegenden Kaufs
Wie wir bereits festgestellt haben, funktioniert der erste Ansatz aufgrund der hohen Kaufhäufigkeit von Produkten in unserer speziellen Situation gut. Aber wie verfahren wir mit Produkten wie Waschmittel/Shampoo usw.? Das heißt mit Produkten, die wahrscheinlich nicht jede Woche oder zwei benötigt werden und die von den vorherigen Methoden nicht erfasst werden können. Daraus ergibt sich die folgende Idee — wir schlagen vor, den durchschnittlichen Kaufzeitraum jedes Produkts basierend auf Kunden zu berechnen, die das Produkt mehr als einmal gekauft haben. k Die berechneten Zeiträume der Produkte können visuell auf Angemessenheit überprüft werden:
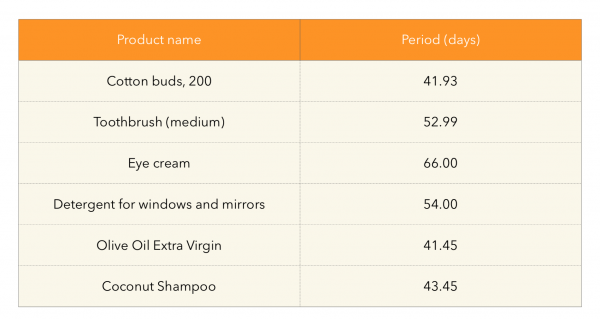
Und dann werden wir überprüfen, ob das Ende des Zeitraums des Produkts in den Zeitraum fällt, in dem die Empfehlungen in Produktion gehen, und die Produkte auswählen, die passen. Der Ansatz kann wie folgt veranschaulicht werden:
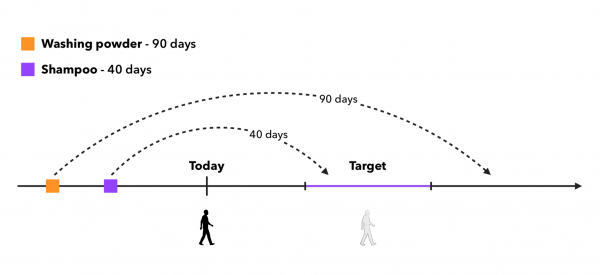
Hier haben wir 2 Hauptfälle, die wir betrachten können:
- Muss man Produkte für Käufer sampeln, die weniger als K Mal ein Produkt gekauft haben?
- Muss man ein Produkt sampeln, wenn das Ende seines Zeitraums vor Beginn des Zielintervalls liegt?
Im nächsten Diagramm sehen Sie, welche Ergebnisse diese Methode mit verschiedenen Hyperparametern erzielt:
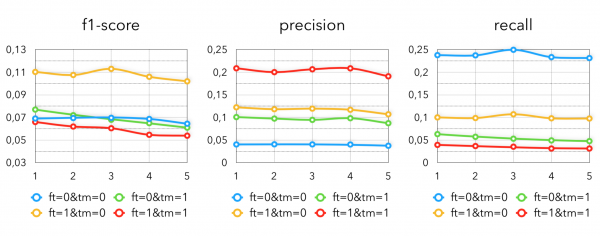
ft — Nur Käufer einbeziehen, die das Produkt mindestens K Mal (hier K=5) gekauft haben
tm — Nur Kandidaten einbeziehen, die in das Zielintervall fallen
Es ist nicht überraschend, dass im Zustand (0, 0) die größte Recall und die kleinste Precision, da unter dieser Bedingung die meisten Kandidaten extrahiert werden. Die besten Ergebnisse werden jedoch erzielt, wenn wir keine Produkte für Käufer sampeln, die ein bestimmtes Produkt weniger als k Mal gekauft haben, und auch Produkte extrahieren, deren Zeitraum vor das Zielintervall fällt.
Beliebt innerhalb der Kategorie
Eine weitere recht offensichtliche Idee ist es, beliebte Produkte nach verschiedenen Kategorien oder Marken zu sampeln. Hier berechnen wir für jeden Käufer Top-k Wir extrahieren die „beliebtesten“ Artikel aus diesen „beliebten“ Kategorien/Marken. In unserem Fall definieren wir „beliebt“ und „populär“ anhand der Anzahl der Käufe eines Produkts. Ein zusätzlicher Vorteil dieses Ansatzes ist die Anwendbarkeit im Fall eines kalten Starts. Das heißt, für Käufer, die entweder sehr wenige Käufe getätigt haben, schon lange nicht mehr im Geschäft waren oder sogar nur eine Kundenkarte beantragt haben. Für sie ist es einfacher, Produkte aus den beliebtesten bei Käufern mit vorhandener Kaufhistorie zu empfehlen. Die Metriken ergeben sich wie folgt:
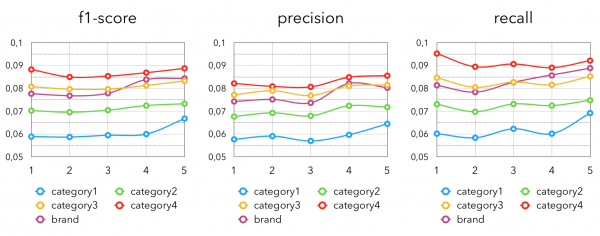
Hier steht die Zahl nach dem Wort „category“ für die Kategorieebene.
Es ist insgesamt auch nicht überraschend, dass engere Kategorien die besten Ergebnisse erzielen, da sie genauere „beliebte“ Produkte für Käufer extrahieren.
Wechselnde Käufe verschiedener Produkte von Woche zu Woche
Ein interessanter Ansatz, den ich in Artikeln über Empfehlungssysteme noch nicht gesehen habe — eine ziemlich einfache und zugleich effektive statistische Methode der Markov-Ketten. Dabei nehmen wir 2 verschiedene Wochen und erstellen dann für jeden Käufer Paarungen von Produkten. [gekauft in Woche i]-[gekauft in Woche j], wo j > i, und von hier aus berechnen wir für jedes Produkt die Wahrscheinlichkeit, in der nächsten Woche zu einem anderen Produkt zu wechseln. Das heißt für jedes Produktpaar produkti-produktj berechnen wir deren Anzahl in den gefundenen Paaren und teilen sie durch die Anzahl der Paare, in denen produkti in der ersten Woche war. Um die Kandidaten zu extrahieren, nehmen wir den letzten Kassenbon des Kunden und ziehen die Top-k wahrscheinlichsten folgenden Produkte aus der Übergangsmatrix, die wir erstellt haben. Der Prozess des Aufbaus der Übergangsmatrix sieht so aus:
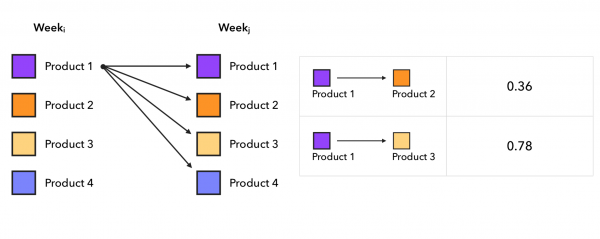
Aus realen Beispielen in der Übergangswahrscheinlichkeitsmatrix sehen wir folgende interessante Phänomene:
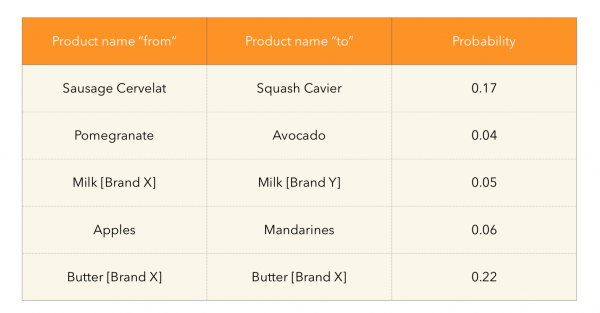
Hier können interessante Abhängigkeiten festgestellt werden, die im Konsumverhalten sichtbar werden: Zum Beispiel Liebhaber von Zitrusfrüchten oder eine Milchmarke, von der mit hoher Wahrscheinlichkeit zu einem anderen gewechselt wird. Es ist auch nicht verwunderlich, dass Produkte mit einer hohen Wiederkaufrate, wie Öl, ebenfalls hier erscheinen.
Die Metriken in der Methode mit Markov-Ketten ergeben Folgendes:
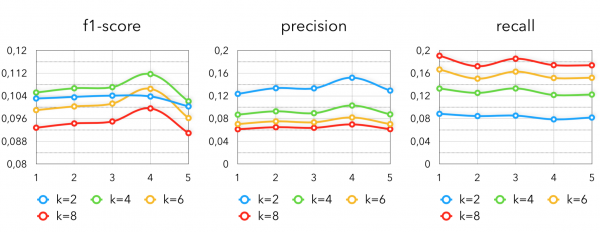
k — die Anzahl der Produkte, die für jedes gekaufte Produkt aus der letzten Transaktion des Käufers extrahiert wird.
Wie wir sehen, zeigt die Konfiguration mit k=4 die besten Ergebnisse. Der Anstieg in der vierten Woche kann durch saisonales Verhalten während der Feiertage erklärt werden.
Ähnliche Produkte für Käufer basierend auf Merkmalen, die von verschiedenen Modellen erstellt wurden.
Hier sind wir nun beim spannendsten und komplexesten Teil angekommen — der Suche nach den nächstgelegenen Nachbarn anhand der Vektoren von Käufern und Produkten, die durch verschiedene Modelle erstellt wurden. In unserer Arbeit verwenden wir dafür 3 Modelle:
- ALS
- Word2Vec (Item2Vec für solche Aufgaben)
- DSSM
Mit ALS haben wir bereits gearbeitet, mehr darüber, wie es trainiert wird, kann man nachlesen. Im Fall von Word2Vec nutzen wir die bekannte Implementierung des Modells aus gensim.Analog zu Texten definieren wir einen Kaufbeleg als Satz. So lernt das Modell beim Erstellen des Produktvektors, den 'Kontext' des Artikels im Beleg (die anderen Artikel im Beleg) vorherzusagen. In Ecommerce-Daten sollten statt des Belegs besser die Käufer-Sitzungen verwendet werden; darüber haben die Jungs von toll geschrieben. Das Zerlegen von DSSM ist interessanter. Es wurde ursprünglich von Microsoft-Entwicklern als Suchmodell erstellt, Die Architektur des Modells sieht folgendermaßen aus:
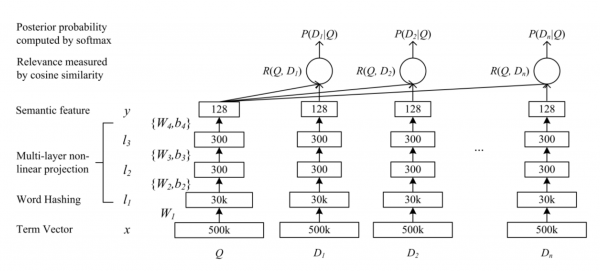
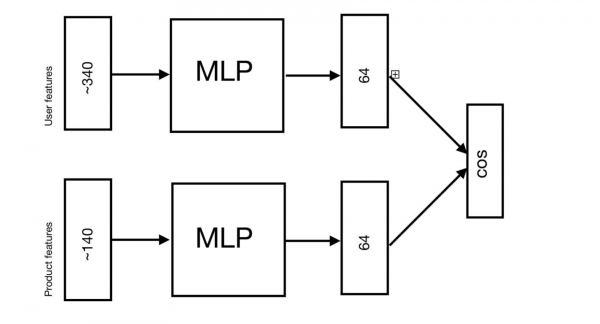
Hier Q — query, die Suchanfrage des Benutzers, D[i] — Dokument, Internetseite. Die Eingaben der Modelle sind die Merkmale der Anfragen und der Seiten. Nach jeder Eingangsschicht folgen einige vollständig verbundene Schichten (Multilayer-Perzeptron). Anschließend lernt das Modell, den Kosinus zwischen den Vektoren, die in den letzten Schichten des Modells entstanden sind, zu minimieren.
Bei Empfehlungsproblemen wird genau dieselbe Architektur verwendet, nur dass anstelle der Anfrage der Benutzer und anstelle der Seiten die Produkte kommen. In unserem Fall transformiert sich diese Architektur folgendermaßen:
Jetzt bleibt nur noch der letzte Punkt zu überprüfen — wenn bei ALS und DSSM die Vektoren der Benutzer klar definiert sind, haben wir bei Word2Vec nur die Vektoren der Produkte. Hier haben wir drei Hauptansätze zur Erstellung des Benutzervektors definiert:
- Einfaches Addieren der Vektoren, sodass für den kosinusähnlichen Abstand herauskommt, dass wir die Produkte in der Kaufhistorie einfach gemittelt haben.
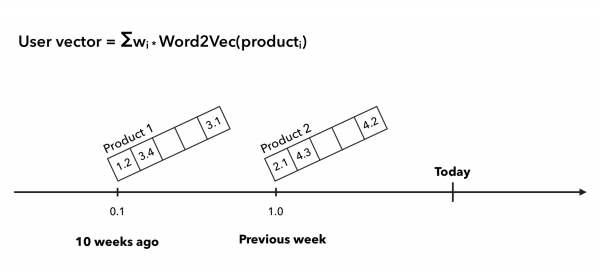
- Summierung der Vektoren mit einer zeitbasierten Gewichtung.
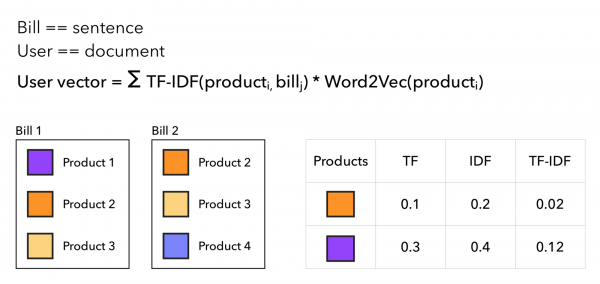
- Gewichtung der Produkte mit dem TF-IDF Koeffizienten.
Bei der linienhaften Gewichtung des Käufervektors gehen wir davon aus, dass das Produkt, das der Benutzer gestern gekauft hat, einen größeren Einfluss auf sein Verhalten hat als das Produkt, das er vor einem halben Jahr gekauft hat. Daher betrachten wir die vorherige Woche des Käufers mit einem Koeffizienten von 1 und alles, was weiter zurückliegt, mit Koeffizienten von ½, ⅓ usw.:
Für die TF-IDF-Koeffizienten machen wir genau das gleiche wie bei TF-IDF für Texte, lediglich dass wir den Käufer als Dokument und den Beleg als Angebot betrachten, entsprechend ist das Wort — das Produkt. So wird der Vektor des Benutzers stärker in Richtung seltener Produkte verschoben, während häufige und gewohnte Produkte das Ergebnis weniger stark beeinflussen. Man könnte den Ansatz so veranschaulichen:
Nun schauen wir uns die Metriken an. So sehen die Ergebnisse von ALS aus:
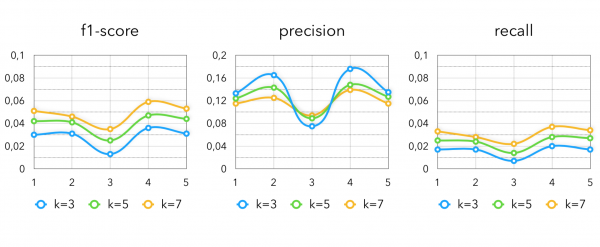
Metriken von Item2Vec mit verschiedenen Varianten des Käufervektoraufbaus:
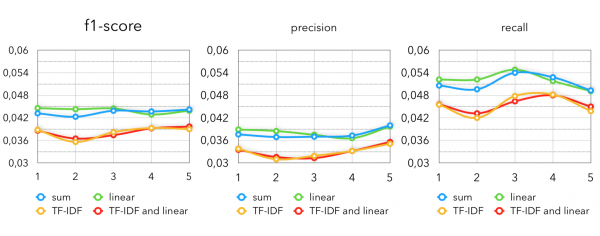
In diesem Fall wird genau dasselbe Modell verwendet wie in unserem Baseline. Der Unterschied besteht nur darin, welches k wir verwenden werden. Um nur kollaborative Modelle zu verwenden, müssen wir etwa 50-70 nächste Produkte für jeden Käufer heranziehen.
Und die Metriken von DSSM:
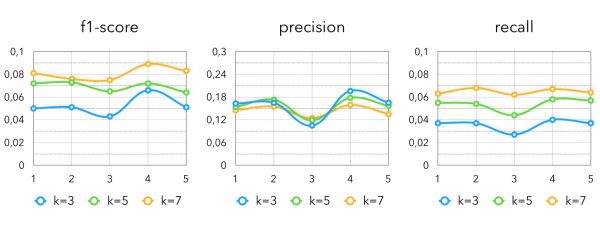
Wie kann man alle Methoden kombinieren?
Das klingt gut, sagen Sie, aber was machen wir mit einem so umfangreichen Set an Werkzeugen zur Kandidatenauswahl? Wie finden wir die optimale Konfiguration für unsere Daten? Dabei stellen sich uns mehrere Aufgaben:
- Wir müssen den Suchraum der Hyperparameter in jeder Methode irgendwie einschränken. Er ist überall natürlich diskret, aber die Anzahl der möglichen Punkte ist sehr groß.
- Wie finden wir die beste Konfiguration für unsere Metrik aus einer kleinen, begrenzten Stichprobe spezifischer Methoden mit bestimmten Hyperparametern?
Eine eindeutig richtige Antwort auf die erste Frage haben wir bisher nicht gefunden, daher gehen wir von Folgendem aus: Für jede Methode wurde ein Suchraumsender für Hyperparameter basierend auf bestimmten Statistiken zu den Daten, die wir haben, erstellt. So können wir, wenn wir den durchschnittlichen Zeitraum zwischen Käufen der Nutzer kennen, annehmen, mit welchem Zeitraum wir die Methode „was wurde bereits gekauft“ und „Zeitraum seit dem letzten Kauf“ verwenden können.
Nachdem wir verschiedene Ansätze ausführlich betrachtet haben, stellen wir fest, dass jede Implementierung eine bestimmte Anzahl von Kandidaten extrahiert und eine wichtige Kennzahl (Recall) liefert. Wir möchten insgesamt eine bestimmte Anzahl von Kandidaten erhalten, abhängig von unseren verfügbaren Rechenressourcen, mit der bestmöglichen Kennzahl. Hier wird das Problem elegant auf das Rucksackproblem reduziert.
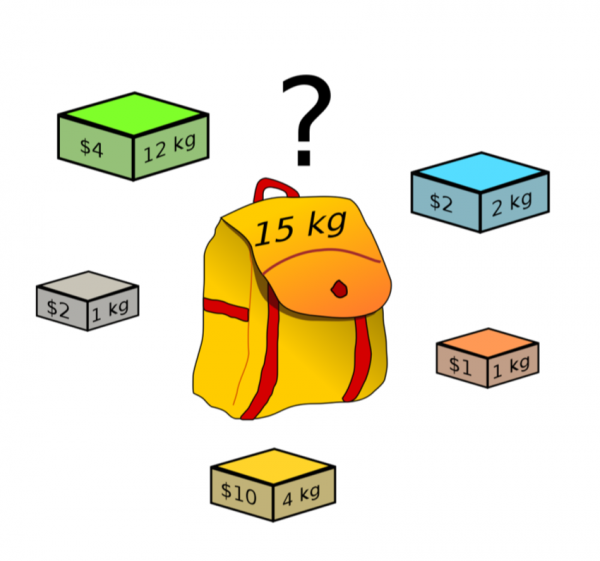
Hierbei entspricht die Anzahl der Kandidaten dem Gewicht des Rucksacks, während der Recall der Methode dessen Wert ist. Es gibt jedoch noch zwei Aspekte, die bei der Implementierung des Algorithmus berücksichtigt werden sollten:
- Die Methoden können Überschneidungen bei den Kandidaten aufweisen, die sie extrahieren.
- In einigen Fällen kann es korrekt sein, eine Methode zweimal mit unterschiedlichen Parametern zu verwenden, wobei die Kandidaten aus der ersten Auswahl kein Teilmengenbeziehung zur zweiten haben.
Wenn wir zum Beispiel die Implementierung der Methode "was bereits gekauft wurde" mit unterschiedlichen Intervallen für das Sampling betrachten, werden ihre Mengen an Kandidaten ineinander verschachtelt. Gleichzeitig geben verschiedene Parameter in den "periodischen Käufen" am Ausgang keine vollständige Überschneidung. Daher unterteilen wir die Sampling-Methoden mit unterschiedlichen Parametern in Blöcke, sodass wir aus jedem Block nicht mehr als einen Ansatz zur Extraktion mit spezifischen Hyperparametern verwenden möchten. Dazu ist es notwendig, bei der Lösung des Rucksackproblems etwas kreativ zu sein, aber die Asymptotik und das Ergebnis werden dadurch nicht beeinträchtigt.
Diese intelligente Kombination ermöglicht uns, die folgenden Metriken im Vergleich zu reinen kollaborativen Modellen zu erhalten:
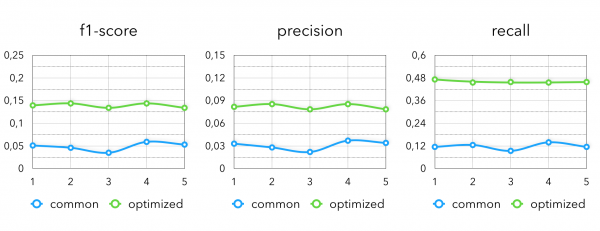
Bei den abschließenden Metriken sehen wir folgendes Bild:
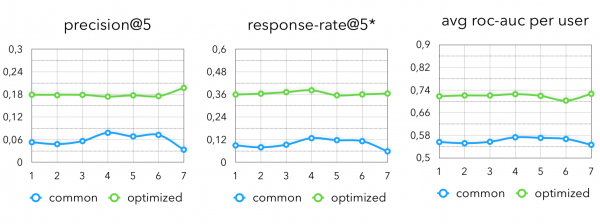
Hier kann jedoch festgestellt werden, dass ein unberücksichtigter Punkt für Empfehlungen bleibt, die für das Geschäft nützlich sind. Derzeit haben wir einfach gelernt, großartig vorherzusagen, was der Benutzer beispielsweise in der nächsten Woche kaufen wird. Es ist jedoch nicht besonders spannend, einen Rabatt auf das zu geben, was er ohnehin kaufen wird. Stattdessen ist es großartig, die mathematische Erwartung der folgenden Metriken zu maximieren:
- Marge/Umsatz durch persönliche Empfehlungen.
- Durchschnittlicher Warenkorb der Kunden.
- Besuchshäufigkeit.
So multiplizieren wir die erhaltenen Wahrscheinlichkeiten mit verschiedenen Faktoren und sortieren sie um, sodass die Produkte in den Vordergrund kommen, die die höheren Metriken beeinflussen. Es gibt keine fertige Lösung, welcher Ansatz besser ist. Selbst wir experimentieren mit diesen Koeffizienten direkt in der Produktion. Hier sind jedoch interessante Techniken, die bei uns häufig die besten Ergebnisse liefern:
- Mit dem Preis/der Marge des Produkts multiplizieren.
- Mit dem Durchschnittswarenkorb multiplizieren, in dem das Produkt vorkommt. So steigen die Produkte nach oben, die normalerweise zusammen mit anderen gekauft werden.
- Mit der durchschnittlichen Besuchshäufigkeit der Kunden für dieses Produkt multiplizieren, basierend auf der Hypothese, dass dieses Produkt dazu führt, dass sie häufiger zurückkommen.
Nach den Experimenten mit den Koeffizienten haben wir folgende Metriken in der Produktion erhalten:
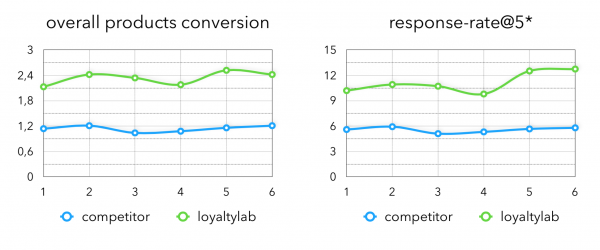
Hier Gesamtprodukten-Konversion – Anteil der gekauften Produkte an allen Produkten in den Empfehlungen, die wir generiert haben.
Aufmerksame Leser werden einen erheblichen Unterschied zwischen Offline- und Online-Metriken feststellen. Dieses Verhalten lässt sich dadurch erklären, dass nicht alle dynamischen Produktfilter, die empfohlen werden können, bei der Modellschulung berücksichtigt werden können. Für uns ist es normal, dass die Hälfte der extrahierten Kandidaten gefiltert werden kann; dieses Phänomen ist in unserer Branche typisch.
Die Einnahmen ergeben folgendes Bild: Es ist deutlich zu erkennen, dass nach der Einführung der Empfehlungen die Einnahmen der Testgruppe stark steigen. Der durchschnittliche Anstieg der Einnahmen mit unseren Empfehlungen liegt jetzt bei 3-4%.
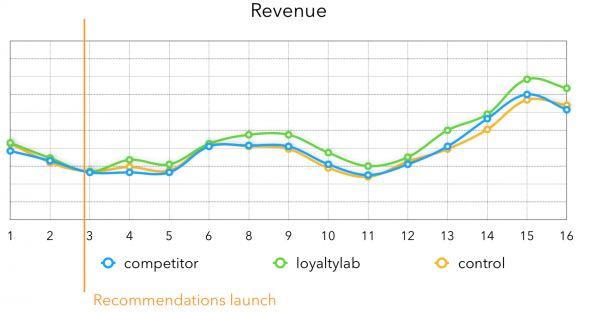
Abschließend möchte ich sagen, dass, wenn Sie keine Echtzeit-Empfehlungen benötigen, der größte Qualitätszuwachs bei Experimenten zur Auswahl von Kandidaten für Empfehlungen zu finden ist. Eine große Menge an Zeit für deren Generierung ermöglicht es, viele gute Methoden zu kombinieren, was insgesamt großartige Ergebnisse für das Geschäft liefert.
Ich freue mich darauf, in den Kommentaren mit allen zu sprechen, die das Material interessant finden. Fragen können Sie mir persönlich in . Außerdem teile ich meine Gedanken zu AI/Startups in meinem — willkommen 🙂
Quelle: habr.com
