

Wir leben in einer erstaunlichen Zeit, in der man schnell und einfach mehrere bereitgestellte Open-Source-Tools kombinieren kann, sie mit 'ausgeschaltetem Bewusstsein' gemäß den Ratschlägen von StackOverflow einrichten kann, ohne sich um 'viele Buchstaben' kümmern zu müssen, und sie in den kommerziellen Betrieb übernehmen kann. Und wenn es nötig wird, sich zu aktualisieren/erweitern oder jemand aus Versehen ein paar Maschinen neu startet — wird man erkennen, dass man in einen aufdringlichen, schlechten Traum aufgewacht ist, alles hat sich plötzlich unkenntlich kompliziert und ein Zurück gibt es nicht, die Zukunft ist ungewiss und sicherer, anstatt zu programmieren, Bienen zu züchten und Käse herzustellen.
Nicht ohne Grund lächeln die erfahreneren Kollegen mit grauen Haaren, die schon viele Bugs gesehen haben, während sie das unglaublich schnelle Deployment von Container-Paketen in „Cubes“ auf Dutzenden von Servern in modernen Programmiersprachen mit integrierter Unterstützung für asynchrones, nicht blockierendes I/O betrachten. Sie lesen still das „man ps“ nach, vertiefen sich bis zum Augenbluten in den Quellcode von „nginx“ und schreiben, schreiben, schreiben Unit-Tests. Die Kollegen wissen, dass das Interessanteste noch bevorsteht, wenn „all das“ eines Nachts zu Silvester zum Stillstand kommt. Nur ein tiefes Verständnis der Unix-Natur, die auswendig gelernten TCP/IP-Zustandsdiagramme und grundlegenden Sortier- und Suchalgorithmen können helfen, das System beim Glockenläuten wieder zum Leben zu erwecken.
Ach ja, ich bin ein wenig abgekommen, aber ich hoffe, ich konnte den Zustand der Vorfreude vermitteln.
Heute möchte ich unsere Erfahrungen mit dem Deployment eines benutzerfreundlichen und kostengünstigen Stacks für DataLake teilen, der die meisten analytischen Aufgaben im Unternehmen für ganz unterschiedliche Abteilungen löst.
Vor einiger Zeit erkannten wir, dass Unternehmen zunehmend auf die Ergebnisse sowohl der Produkt- als auch der technischen Analytik angewiesen sind – ganz zu schweigen von den „Sahnehäubchen“ in Form von Machine Learning. Um Trends und Risiken besser zu verstehen, müssen immer mehr Kennzahlen gesammelt und analysiert werden.
Grundlegende technische Analytik in „Bitrix24“
Vor einigen Jahren, gemeinsam mit dem Start des Dienstes „Bitrix24“, investierten wir aktiv Zeit und Ressourcen in die Entwicklung einer einfachen und zuverlässigen Analyseplattform, die es ermöglicht, Probleme in der Infrastruktur schnell zu erkennen und die nächsten Schritte zu planen. Natürlich wollten wir möglichst einfache und verständliche, fertige Tools verwenden. Schließlich fiel die Wahl auf Nagios für das Monitoring und Munin für die Analyse und Visualisierung. Jetzt haben wir tausende von Checks in Nagios, Hunderte von Grafiken in Munin und unsere Kollegen verwenden diese täglich und erfolgreich. Die Kennzahlen sind klar, die Grafiken sind verständlich, und das System arbeitet zuverlässig seit mehreren Jahren und wird regelmäßig um neue Tests und Grafiken erweitert: Bei der Inbetriebnahme eines neuen Dienstes – fügen wir einige Tests und Grafiken hinzu. Gute Reise.
Immer am Puls — erweiterte technische Analyse
Der Wunsch, Informationen über Probleme "so schnell wie möglich" zu erhalten, hat uns zu aktiven Experimenten mit einfachen und verständlichen Werkzeugen geführt — Pinba und XHProf.
Pinba sendete uns in UDP-Paketen Statistiken über die Geschwindigkeit der PHP-Webseitenteile, und man konnte in Echtzeit im MySQL-Speicher (Pinba ist mit einer eigenen MySQL-Engine für schnelle Ereignisanalysen ausgestattet) eine kurze Liste von Problemen sehen und darauf reagieren. XHProf ermöglichte es uns zudem automatisch, die Ausführungsgraphen der langsamsten PHP-Seiten der Kunden zu sammeln und zu analysieren, was dazu geführt haben könnte — gemütlich bei einer Tasse Tee oder etwas Stärkerem.
Vor einiger Zeit wurde das Toolset um eine weitere recht einfache und verständliche Engine auf Basis des Algorithmus zur inversen Indizierung erweitert, die hervorragend in der legendären Bibliothek Lucene umgesetzt wurde — Elastic/Kibana. Die einfache Idee, mehrschichtige Dokumente in den inversen Lucene-Index auf Basis von Log-Ereignissen aufzunehmen und schnell nach diesen zu suchen, stellte sich als wirklich nützlich heraus.
Trotz der eher technischen Darstellung in Kibana mit den "nach oben durchdringenden" niedrigstufigen Konzepten wie "Bucket" und einer neu erfundenen Sprache der längst vergessenen relationalen Algebra hilft uns das Tool gut bei den folgenden Aufgaben:
- Wie viele PHP-Fehler hatte der Bitrix24-Kunde im Portal p1 in der letzten Stunde und welche? Verstehen, verzeihen und schnell beheben.
- Wie viele Videoanrufe wurden in den letzten 24 Stunden in den Portalen in Deutschland getätigt, mit welcher Qualität und gab es Probleme mit dem Kanal/netzwerk?
- Wie gut funktioniert die systemeigene Funktionalität (unser C-Erweiterung für PHP), die aus den Quellcodes in der letzten Aktualisierung des Dienstes kompiliert und an die Kunden verteilt wurde? Gibt es segfaults?
- Werden die Kundendaten im PHP-Speicher untergebracht? Gibt es keine Fehler aufgrund von Speicherüberlastung: "out of memory"? Finden und entschärfen.
Hier ein konkretes Beispiel. Trotz sorgfältiger und mehrstufiger Tests trat bei einem Kunden, bei einem sehr untypischen Anwendungsfall und beschädigten Eingangsdaten, ein ärgerlicher und unerwarteter Fehler auf, die Sirene ertönte und der Prozess zur schnellen Behebung begann:
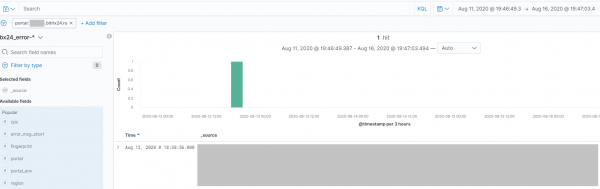
Zusätzlich ermöglicht Kibana die Einrichtung von Benachrichtigungen für bestimmte Ereignisse, und in kurzer Zeit nutzen Dutzende von Mitarbeitern aus verschiedenen Abteilungen — von der technischen Unterstützung über die Entwicklung bis hin zu QA — das Tool im Unternehmen.
Die Aktivität jeder Abteilung innerhalb des Unternehmens lässt sich bequem verfolgen und messen — anstelle einer manuell vorgenommenen Analyse der Protokolle auf den Servern genügt es, einmal das Parsing der Protokolle einzurichten und sie an den Elastic-Cluster zu senden, um beispielsweise die Anzahl der verkauften 3D-gedruckten zweiköpfigen Kätzchen im Dashboard von Kibana für den letzten Mondmonat zu betrachten.
Basisgeschäftsanalyse
Alle wissen, dass die Geschäftsanalyse in Unternehmen oft mit einer extrem aktiven Nutzung von, ja, Excel beginnt. Aber das Wichtigste ist, dass sie nicht damit endet. Die Cloud-basierte Google Analytics trägt zusätzlich zur Schärfe bei — an das Gute gewöhnt man sich schnell.
In unserem harmonisch wachsenden Unternehmen begannen überall „Propheten“ für intensivere Arbeiten mit größeren Datenmengen aufzutauchen. Regelmäßig traten Bedürfnisse nach tiefergehenden und vielseitigeren Berichten auf, und durch die Bemühungen der Kollegen aus verschiedenen Abteilungen wurde vor einiger Zeit eine einfache und praktische Lösung organisiert — die Kombination von ClickHouse und PowerBI.
Eine ziemlich lange Zeit hat diese flexible Lösung hervorragend geholfen, aber allmählich wurde klar, dass ClickHouse nicht elastisch ist und man damit nicht so umgehen kann.
Es ist wichtig zu verstehen, dass ClickHouse, wie auch Druid, Vertica und Amazon RedShift (das auf Postgres basiert), analytische Engines sind, die für eine recht komfortable Analyse optimiert sind (Summen, Aggregationen, Minimum-Maximum nach Spalte und ein wenig Joins), da sie für die effiziente Speicherung von Spalten relationaler Tabellen organisiert sind, im Gegensatz zu den uns bekannten MySQL und anderen (row-oriented) Datenbanken.
Im Grunde genommen ist ClickHouse lediglich eine umfangreichere Datenbank mit einer nicht ganz benutzerfreundlichen punktuellen Einfügung (so ist es nun mal gedacht, alles in Ordnung), aber mit angenehmer Analyse und einer Reihe interessanter, leistungsstarker Funktionen zur Datenbearbeitung. Ja, man kann sogar einen Cluster erstellen — aber Sie verstehen, dass man Nägel nicht mit einem Mikroskop einschlagen sollte, und wir haben begonnen, nach anderen Lösungen zu suchen.
Die Nachfrage nach Python und Analysten
In unserem Unternehmen gibt es viele Entwickler, die fast täglich seit 10-20 Jahren Code in PHP, JavaScript, C#, C/C++, Java, Go, Rust, Python und Bash schreiben. Es gibt auch viele erfahrene Systemadministratoren, die schon einige unglaublich unglückliche Katastrophen überstanden haben, die statistischen Gesetzen nicht gehorchen (zum Beispiel wenn die meisten Festplatten in einem RAID-10 durch einen starken Blitzeinschlag zerstört werden). Unter solchen Bedingungen war lange Zeit unklar, was ein „Analyst in Python“ eigentlich ist. Python ist wie PHP, nur mit einem etwas längeren Namen und weniger Spuren von bewusstseinserweiternden Substanzen im Quellcode des Interpreters. Doch mit der Erstellung immer neuer analytischer Berichte begannen erfahrene Entwickler, die Bedeutung einer engen Spezialisierung auf Tools wie numpy, pandas, matplotlib und seaborn immer mehr zu erkennen.
Die entscheidende Rolle spielten wahrscheinlich die plötzlichen Ohnmachtsanfälle der Mitarbeiter bei der Kombination der Worte „logistische Regression“ und der Demonstration des effizienten Aufbaus von Berichten über große Datenmengen mit ja, ja, pyspark.
Apache Spark, dessen funktionale Paradigmen perfekt zur relationalen Algebra und den Möglichkeiten passen, haben einen solchen Eindruck bei Entwicklern hinterlassen, die mit MySQL vertraut sind, dass die Notwendigkeit, die Reihen der erfahrenen Analysten zu stärken, so klar wie der Tag wurde.
Weitere Versuche, dass Apache Spark/Hadoop durchstarten und was nicht ganz nach Plan lief.
Bald wurde jedoch klar, dass mit Spark offenbar etwas systematisch nicht stimmte oder man einfach besser die Hände waschen sollte. Wenn der Hadoop/MapReduce/Lucene-Stack von erfahrenen Programmierern entwickelt wurde, was offensichtlich ist, wenn man sich die Quellcodes auf Java oder die Ideen von Doug Cutting in Lucene ansieht, ist Spark überraschend in einer sehr umstrittenen, aus praktischer Sicht nicht weiterentwickelten exotischen Sprache, Scala, geschrieben. Das regelmäßige Versagen von Berechnungen im Spark-Cluster aufgrund der unlogischen und nicht sehr transparenten Handhabung der Speicherzuteilung für Reduce-Operationen (es kommen gleich viele Schlüssel auf einmal) hat um ihn herum eine Aura geschaffen, die darauf hinweist, dass es viel Spielraum für Verbesserungen gibt. Zudem verschärfte eine große Anzahl seltsamer offener Ports, temporärer Dateien, die an den unerwartetsten Orten wuchsen, und zahlreiche jar-Abhängigkeiten die Situation – was bei den Systemadministratoren ein bekanntes Gefühl hervorrief: reine Wut (vielleicht hätte man die Hände mit Seife waschen sollen).
Im Laufe der Zeit haben wir mehrere interne Analyseprojekte „überlebt“, die intensiv Apache Spark (einschließlich Spark Streaming, Spark SQL) und das Hadoop-Ökosystem nutzen. Obwohl wir gelernt haben, es gut vorzubereiten und zu überwachen, und es fast nicht mehr wegen der sich ändernden Datenmuster und der Ungleichgewichtsproblematik bei der gleichmäßigen Hashing von RDDs ausfällt, wurde das Verlangen nach einer bereits vorgefertigten, aktualisierbaren und verwaltbaren Lösung in der Cloud immer stärker. In dieser Zeit haben wir versucht, die fertige Cloud-Lösung von Amazon Web Services zu nutzen — und haben anschließend versucht, unsere Aufgaben dort zu lösen. EMR ist Amazons vorkonfigurierte Version von Apache Spark mit zusätzlicher Software aus dem Ökosystem, ähnlich wie die Cloudera/Hortonworks-Distributionen.
Ein „flexibles“ Dateispeicher für Analysen — ein dringender Bedarf
Die Erfahrung mit der "Zubereitung" von Hadoop/Spark, einschließlich der dabei erlittenen Verletzungen, war nicht umsonst. Es wurde zunehmend klarer, dass die Schaffung eines kostengünstigen und zuverlässigen Dateispeichers notwendig ist, der gegen Hardwareausfälle resistent ist und in dem Dateien aus verschiedenen Systemen in unterschiedlichen Formaten gespeichert werden können, um auf diesen Daten effektive Abfragen für Berichte in angemessener Zeit durchführen zu können.
Außerdem wäre es wünschenswert, dass die Softwareaktualisierung dieser Plattform nicht in einen nächtlichen Albtraum an Neujahr mündet, mit dem Lesen von 20-seitigen Java-Tracebacks und der Analyse von kilometerlangen detaillierten Protokollen der Clusterarbeit mithilfe des Spark History Servers und einer Lupe mit Beleuchtung. Ich würde mir ein einfaches und transparentes Werkzeug wünschen, das keine regelmäßigen technischen Eingriffe erfordert, wenn der Entwickler bei der Ausführung einer Standard-MapReduce-Anfrage auf Probleme stößt, weil beim Speichern der Reduce-Daten im Arbeitsspeicher des Workers ein nicht optimal gewählter Partitionierungsalgorithmus für die Quelldaten verwendet wurde.
Ist Amazon S3 ein Kandidat für DataLake?
Die Erfahrung mit Hadoop/MapReduce hat mich gelehrt, dass ein zuverlässiges und skalierbares Dateisystem sowie skalierbare Worker notwendig sind, die näher an den Daten »kommen«, um Daten nicht über das Netzwerk zu übertragen. Die Worker sollten in der Lage sein, Daten in verschiedenen Formaten zu lesen, aber idealerweise nicht unnötige Informationen einzulesen, und es sollte möglich sein, die Daten im Vorfeld in für die Worker geeigneten Formaten zu speichern.
Nochmal — die Grundidee. Es besteht kein Wunsch, große Daten in eine einzige Cluster-Analyse-Engine zu »laden«, die ohnehin früher oder später überlastet sein wird und die man dann unschön sharden muss. Ich möchte Dateien, einfach Dateien, in einem verständlichen Format speichern und effiziente analytische Abfragen mit verschiedenen, aber verständlichen Tools durchführen. Und die Anzahl der Dateien in unterschiedlichen Formaten wird immer größer. Es ist besser, nicht die Engine zu sharden, sondern die Rohdaten. Wir brauchen einen skalierbaren und universellen DataLake, haben wir beschlossen...
Was wäre, wenn wir Dateien in einem vertrauten und vielen bekannten skalierbaren Cloud-Speicher wie Amazon S3 speichern, ohne eigene »Schweinemedaillons« aus Hadoop zubereiten zu müssen?
Klar, personenbezogene Daten sind »verboten«, aber was ist mit anderen Daten, wenn wir diese dort speichern und »effizient verarbeiten«?
Die clusterbasierte Big-Data-Analyse-Umgebung von Amazon Web Services – ganz einfach erklärt.
Nach unseren Erfahrungen mit AWS wird dort seit langem und intensiv unter verschiedenen Aspekten Apache Hadoop/MapReduce eingesetzt, zum Beispiel im DataPipeline-Service (ich beneide die Kollegen, sie haben es wirklich geschafft, es richtig zu handhaben). Hier haben wir Backups von verschiedenen Diensten aus DynamoDB-Tabellen eingerichtet:
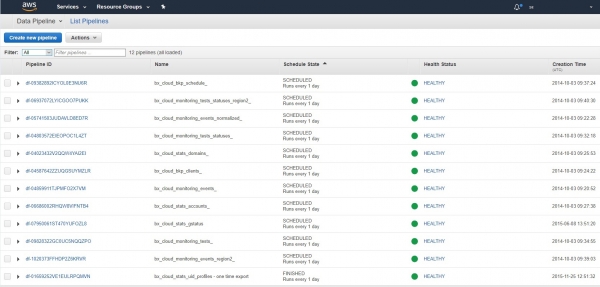
Und diese laufen regelmäßig auf integrierten Hadoop/MapReduce-Clustern seit mehreren Jahren wie am Schnürchen. „Einmal eingestellt und vergessen“:
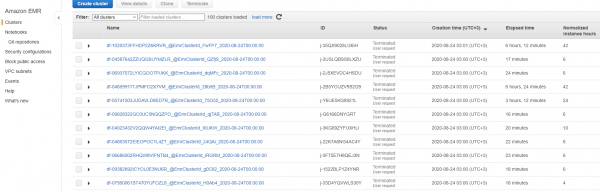
Außerdem kann man effektiv Datenmanagement betreiben, indem man Jupiter-Notebooks für Analysten in der Cloud hochzieht und AWS SageMaker für das Training und den Einsatz von KI-Modellen nutzt. So sieht das bei uns aus:
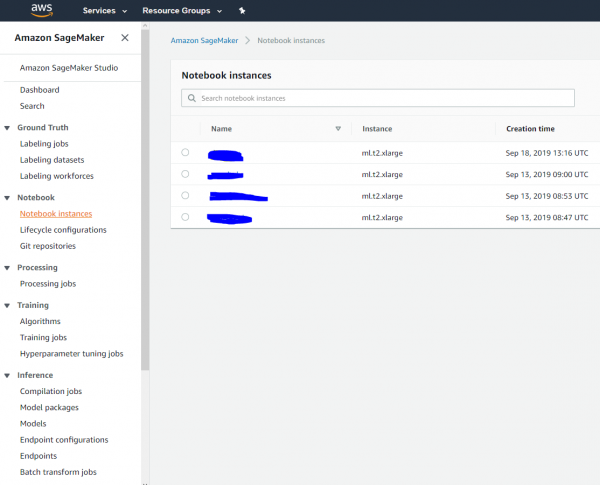
Und ja, man kann sich oder den Analysten ein Notebook in der Cloud einrichten und an ein Hadoop/Spark-Cluster anschließen, rechnen und alles dann „beenden“:
Es ist wirklich praktisch für einzelne Analyseprojekte, und für einige von ihnen haben wir erfolgreich den EMR-Service für groß angelegte Berechnungen und Analysen genutzt. Aber was ist mit einer systematischen Lösung für DataLake, wird das funktionieren? In diesem Moment waren wir am Rande der Hoffnung und Verzweiflung und setzten unsere Suche fort.
AWS Glue – sauber verpacktes Apache Spark "auf Steroiden".
Es stellt sich heraus, dass AWS eine „eigene“ Version des Stacks „Hive/Pig/Spark“ hat. Die Rolle von Hive, also das Verzeichnis von Dateien und ihren Typen im DataLake, wird durch den Dienst „Data catalog“ erfüllt, der auch offen über seine Kompatibilität mit dem Apache Hive-Format kommuniziert. In diesen Dienst müssen Informationen darüber eingetragen werden, wo sich Ihre Dateien befinden und in welchem Format sie vorliegen. Die Daten können sich nicht nur in S3, sondern auch in einer Datenbank befinden, aber das ist nicht Thema dieses Beitrags. So ist der Datenkatalog im DataLake bei uns organisiert:
Die Dateien sind registriert, ausgezeichnet. Wenn die Dateien aktualisiert werden, starten wir entweder manuell oder nach Plan die Crawler, die Informationen aus dem See aktualisieren und speichern. Anschließend können die Daten aus dem See bearbeitet und die Ergebnisse irgendwohin exportiert werden. Im einfachsten Fall exportieren wir auch in S3. Die Datenverarbeitung kann überall erfolgen, aber es wird empfohlen, den Verarbeitungsprozess auf einem Apache Spark-Cluster mit erweiterten Funktionen über die AWS Glue-API einzurichten. Im Grunde genommen kann man den alten, vertrauten Code in Python mit der Bibliothek PySpark verwenden und dessen Ausführung auf N Knoten eines Clusters mit einer bestimmten Leistung einstellen, inklusive Monitoring, ohne sich mit Hadoop intern zu beschäftigen oder Docker-Container zu schleppen und Abhängigkeitskonflikte zu lösen.
Noch einmal – eine einfache Idee. Es ist nicht notwendig, Apache Spark einzurichten; man muss lediglich Code in Python für PySpark schreiben, diesen lokal auf dem Desktop testen und dann auf einem großen Cluster in der Cloud ausführen, wobei man angibt, wo die Quelldaten liegen und wo das Ergebnis abgelegt werden soll. Manchmal ist das notwendig und nützlich, und so ist es bei uns eingerichtet:
Wenn etwas auf einem Spark-Cluster mit Daten in S3 berechnet werden muss, schreiben wir den Code in Python/PySpark, testen ihn und auf geht’s in die Cloud.
Was ist mit der Orchestrierung? Und wenn eine Aufgabe fehlschlägt und verloren geht? Ja, es wird vorgeschlagen, eine schöne Pipeline im Stil von Apache Pig zu erstellen, und wir haben es sogar ausprobiert, aber wir haben uns entschieden, vorerst unsere tiefgehend angepasste Orchestrierung mit PHP und JavaScript zu verwenden (ich verstehe, dass es kognitiven Dissonanz erzeugt, aber es funktioniert seit Jahren und fehlerfrei).
Das Format der im See gespeicherten Dateien ist der Schlüssel zur Leistung.
Es ist sehr, sehr wichtig, noch zwei weitere Schlüsselpunkte zu verstehen. Damit die Anfragen an die Datei-Daten im See so schnell wie möglich ausgeführt werden und die Leistung nicht beim Hinzufügen neuer Informationen abnimmt, müssen folgende Punkte beachtet werden:
- Die Spalten der Dateien müssen separat gespeichert werden (um nicht alle Zeilen lesen zu müssen, um zu verstehen, was in den Spalten ist). Dazu haben wir das Parquet-Format mit Kompression gewählt.
- Es ist sehr wichtig, die Dateien nach Kategorien wie: Sprache, Jahr, Monat, Tag, Woche zu sharden. Engines, die diesen Sharding-Typ verstehen, werden nur in die benötigten Ordner schauen, ohne die gesamten Daten durchzusehen.
Im Wesentlichen stellen Sie auf diese Weise die Ausgangsdaten für oben aufgesetzte Analyse-Engines am effizientesten zur Verfügung, die auch selektiv auf geschlossene Ordner zugreifen und nur die benötigten Spalten aus den Dateien lesen können. Es ist nicht nötig, Daten irgendwohin „hochzuladen“ (der Speicherplatz würde einfach platzen) — legen Sie sie einfach direkt in der richtigen Form in das Dateisystem ab. Natürlich sollte klar sein, dass es nicht sehr sinnvoll ist, eine riesige CSV-Datei im DataLake zu speichern, die zuerst zeilenweise vom Cluster gelesen werden muss, um die Spalten herauszuziehen. Überdenken Sie die beiden oben genannten Punkte noch einmal, falls Ihnen bisher unklar ist, warum das alles notwendig ist.
AWS Athena — der „Teufel“ aus der Kiste
Und hier, beim Erstellen eines Sees, stießen wir irgendwie zufällig auf Amazon Athena. Plötzlich stellte sich heraus, dass wir, indem wir unsere umfangreichen Protokolldateien sorgfältig im richtigen (Parquet) spaltenbasierten Format in Scharden-Ordner ablegten, sehr schnell äußerst informative Abfragen durchführen und Berichte erstellen konnten, OHNE einen Apache Spark/Glue-Cluster zu nutzen.
Die Athena-Engine, die auf Daten in S3 basiert, basiert auf dem legendären — Vertreter des MPP (Massive Parallel Processing)-Ansatzes zur Datenverarbeitung, der Daten dort abruft, wo sie liegen, von S3 und Hadoop bis hin zu Cassandra und einfachen Textdateien. Man muss nur Athena bitten, eine SQL-Abfrage auszuführen, und dann läuft alles „schnell und selbstständig“. Es ist wichtig zu erwähnen, dass Athena „intelligent“ ist, nur in die benötigten shardierten Ordner geht und nur die benötigten Spalten aus der Anfrage liest.
Die Abfragen an Athena sind ebenfalls interessant tarifiert. Wir zahlen für . Das heißt, nicht für die Anzahl der Maschinen im Cluster pro Minute, sondern… für die tatsächlich gescannten Daten, die auf 100-500 Maschinen benötigt werden, um die Abfrage auszuführen.
Und wenn man nur die benötigten Spalten aus richtig shardierten Ordnern abfragt, stellt sich heraus, dass der Dienst Athena uns nur einige Dutzend Dollar im Monat kostet. Nun, das ist doch fast kostenlos im Vergleich zur Analyse in Clustern!
Hier ist übrigens, wie wir unsere Daten in S3 shardieren:
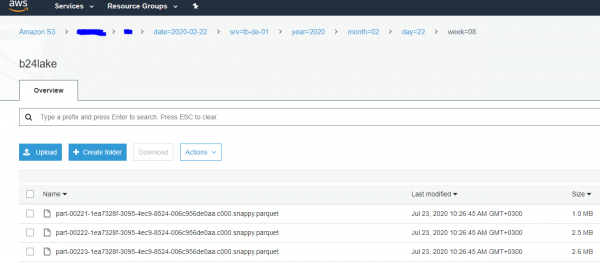
In kurzer Zeit begannen in der Firma völlig unterschiedliche Abteilungen, von der Informationssicherheit bis zur Analyse, aktiv Anfragen an Athena zu stellen und schnell, innerhalb von Sekunden, nützliche Antworten aus den „großen“ Daten über längere Zeiträume hinweg zu erhalten: Monate, Halbjahre usw.
Aber wir sind weitergegangen und haben Antworten in die Cloud geholt. : Ein Analyst schreibt in der gewohnten Konsole eine SQL-Anfrage, die auf 100-500 Maschinen „zu geringen Kosten“ die Daten in S3 durchsucht und die Antwort normalerweise innerhalb von Sekunden zurückgibt. Praktisch. Und schnell. Es ist schwer zu glauben.
Nachdem wir beschlossen haben, die Daten in S3 zu speichern, in einem effizienten, spaltenbasierten Format und mit sinnvoller Datenpartitionierung... haben wir einen DataLake und eine schnelle, kostengünstige Analytik-Engine erhalten — kostenlos. Und sie ist im Unternehmen sehr populär geworden, da sie SQL versteht und um ein Vielfaches schneller arbeitet als bei Start/Stopp/Einstellungen von Clustern. "Wenn das Ergebnis dasselbe ist, warum mehr bezahlen?"
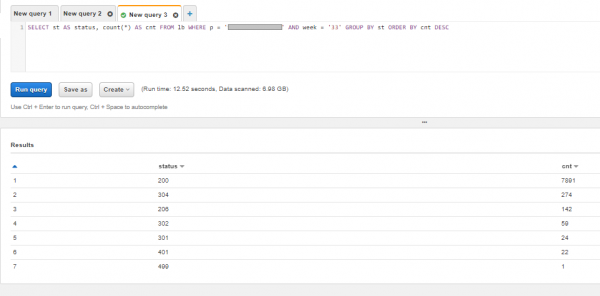
Eine Abfrage an Athena sieht ungefähr so aus. Wenn gewünscht, kann man natürlich auch eine ausreichend , aber wir beschränken uns auf eine einfache Gruppierung. Lassen Sie uns sehen, welche Antwortcodes der Kunde vor einigen Wochen in den Protokollen des Webservers hatte und sicherstellen, dass es keine Fehler gibt:
Fazit
Nachdem wir einen nicht gerade langen, aber schmerzhaften Weg zurückgelegt haben, in dem wir ständig die Risiken, die Komplexität und die Kosten der Unterstützung angemessen bewertet haben, haben wir eine Lösung für DataLake und Analytik gefunden, die uns sowohl in Bezug auf Geschwindigkeit als auch in Bezug auf die Kosten des Eigentums begeistert.
Es stellte sich heraus, dass es für erfahrene Entwickler, die nie als Architekten gearbeitet haben und nicht wissen, wie man Quadrate auf Quadrate mit Pfeilen zeichnet und 50 Begriffe aus dem Hadoop-Ökosystem kennt, durchaus möglich ist, ein effektives, schnelles und kostengünstiges DataLake für die Bedürfnisse völlig unterschiedlicher Abteilungen des Unternehmens zu erstellen.
Zu Beginn war es überwältigend, sich mit der Vielzahl an offenen und geschlossenen Softwarelösungen sowie der Verantwortung gegenüber künftigen Generationen auseinanderzusetzen. Starten Sie einfach mit dem Aufbau Ihres Data Lakes mit einfachen Werkzeugen: nagios/munin -> elastic/kibana -> Hadoop/Spark/s3 …, sammeln Sie Feedback und verstehen Sie tiefgehend die physikalischen Prozesse, die ablaufen. Alles Komplizierte und Unklare sollten Sie Ihren Rivalen überlassen.
Wenn Sie nicht in die Cloud möchten und gerne offene Projekte unterstützen, aktualisieren und patchen, können Sie ein ähnliches System lokal auf günstigen Bürocomputern mit Hadoop und Presto aufbauen. Das Wichtigste ist, nicht stehenzubleiben, voranzukommen, nach einfachen und klaren Lösungen zu suchen, und alles wird bestimmt klappen! Viel Erfolg an alle und bis zum nächsten Mal!
Quelle: habr.com
