

Ich heiße Pavel Parchomenko und bin ML-Entwickler. In diesem Artikel möchte ich über die Architektur des Yandex Zen-Dienstes berichten und technische Verbesserungen teilen, die die Qualität der Empfehlungen erhöht haben. Sie erfahren, wie es in nur wenigen Millisekunden möglich ist, unter Millionen von Dokumenten die relevantesten für den Nutzer zu finden; wie man eine kontinuierliche Zerlegung einer großen Matrix (bestehend aus Millionen von Spalten und zig Millionen Zeilen) durchführt, sodass neue Dokumente ihren Vektor innerhalb von Minuten erhalten; und wie man die Zerlegung der Benutzer-Artikeldatenmatrix wiederverwendet, um gute vektorielle Darstellungen für Videos zu erhalten.
Unsere Empfehlungsdatenbank enthält Millionen von Dokumenten unterschiedlicher Formate: Textartikel, die auf unserer Plattform erstellt oder von externen Websites übernommen wurden, Videos, Narrative und kurze Beiträge. Die Entwicklung eines solchen Dienstes ist mit einer Vielzahl technischer Herausforderungen verbunden. Hier sind einige davon:
- Rechenaufgaben aufteilen: Alle rechenintensiven Operationen offline durchführen und in Echtzeit nur schnelle Modellanwendungen ausführen, um innerhalb von 100 bis 200 ms zu reagieren.
- Benutzeraktionen schnell erfassen. Dazu ist es notwendig, dass alle Ereignisse sofort an das Empfehlungssystem übermittelt werden und die Ergebnisse der Modelle beeinflussen.
- Den Feed so gestalten, dass er sich schnell an das Verhalten neuer Benutzer anpasst. Neuankömmlinge im System sollten das Gefühl haben, dass ihr Feedback die Empfehlungen beeinflusst.
- Schnell verstehen, wem eine neue Artikel empfohlen werden sollte.
- Prompt auf die ständige Veröffentlichung neuer Inhalte reagieren. Täglich erscheinen Zehntausende Artikel, von denen viele eine begrenzte Lebensdauer haben (zum Beispiel Nachrichten). Das unterscheidet sie von Filmen, Musik und anderen langfristigen und kostenintensiven Inhalten.
- Wissen von einem Anwendungsgebiet auf ein anderes übertragen. Wenn im Empfehlungssystem trainierte Modelle für Textartikel existieren und wir Videos hinzufügen, können bestehende Modelle wiederverwendet werden, um die Sichtbarkeit des neuen Inhalts zu verbessern.
Ich werde erläutern, wie wir diese Herausforderungen gemeistert haben.
Auswahl der Kandidaten
Wie kann man in wenigen Millisekunden die Anzahl der zu überprüfenden Dokumente um ein Vielfaches reduzieren, ohne die Qualität der Einstufung erheblich zu beeinträchtigen?
Angenommen, wir haben viele ML-Modelle trainiert, daraus Merkmale generiert und ein weiteres Modell trainiert, das Dokumente für den Benutzer einstuft. Alles wäre gut, aber man kann nicht einfach alle Merkmale für Millionen von Dokumenten in Echtzeit berechnen, wenn die Empfehlungen in 100-200 ms bereitgestellt werden müssen. Die Aufgabe besteht darin, aus Millionen von Dokumenten eine Teilmenge auszuwählen, die für die Benutzerbewertung verwendet wird. Dieser Schritt wird in der Regel als Auswahl der Kandidaten bezeichnet. Es gibt dafür mehrere Anforderungen. Erstens muss die Auswahl sehr schnell erfolgen, damit für die tatsächliche Einstufung so viel Zeit wie möglich bleibt. Zweitens, obwohl wir die Anzahl der zu bewertenden Dokumente erheblich reduzieren, sollten wir so viele relevante Dokumente wie möglich für den Benutzer erhalten.
Unser Auswahlprinzip hat sich evolutionär entwickelt, und mittlerweile sind wir zu einem mehrstufigen Schema gelangt:
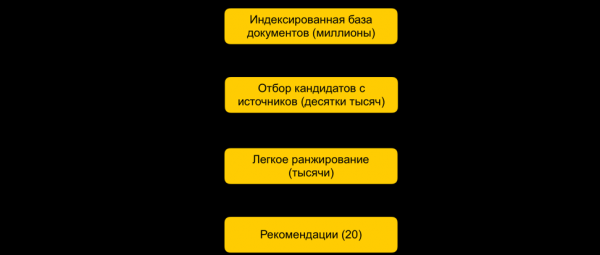
Zunächst werden alle Dokumente in Gruppen eingeteilt, aus denen die beliebtesten Dokumente ausgewählt werden. Die Gruppen können Webseiten, Themen oder Cluster sein. Für jeden Nutzer werden basierend auf seiner Historie die am besten passenden Gruppen ausgewählt, aus denen die besten Dokumente entnommen werden. Zudem verwenden wir den kNN-Index, um in Echtzeit die am nächsten liegenden Dokumente für den Nutzer auszuwählen. Es gibt verschiedene Methoden zur Erstellung des kNN-Indexes, bei uns hat die folgende am besten funktioniert: (Hierarchische Navigierbare Kleinstadtgrafen). Dies ist ein hierarchisches Modell, das es ermöglicht, innerhalb von wenigen Millisekunden die N nächstgelegenen Vektoren für den Nutzer aus einer Millionen-Datenbank zu finden. Vorab indizieren wir unsere gesamte Dokumentendatenbank offline. Da die Suche im Index recht schnell ist, können wir bei Vorhandensein mehrerer starker Einbettungen mehrere Indizes erstellen (je einen für jede Einbettung) und in Echtzeit auf jeden von ihnen zugreifen.
Wir verfügen über Zehntausende von Dokumenten für jeden Benutzer. Das ist immer noch eine große Menge, um sämtliche Merkmale zu zählen, daher wenden wir in diesem Schritt ein leichtes Ranking an – ein vereinfachtes Modell eines schweren Rankings mit weniger Merkmalen. Die Aufgabe besteht darin, vorherzusagen, welche Dokumente bei dem schwereren Modell in der Spitze landen werden. Die Dokumente mit den höchsten Vorhersagen werden in dem schweren Modell verwendet, das heißt in der finalen Ranking-Phase. Dieser Ansatz ermöglicht es, die Anzahl der für den Benutzer betrachteten Dokumente in nur wenigen Millisekunden von Millionen auf Tausende zu reduzieren.
ALS-Schritt zur Laufzeit
Wie berücksichtigt man das Benutzer-Feedback sofort nach dem Klick?
Ein wichtiger Faktor in Empfehlungen ist die Reaktionszeit auf das Feedback des Nutzers. Dies ist besonders wichtig für neue Nutzer: Wenn jemand anfängt, das Empfehlungssystem zu nutzen, erhält er einen nicht personalisierten Feed mit einer Vielzahl von Dokumenten zu unterschiedlichen Themen. Sobald er seinen ersten Klick macht, ist es wichtig, sofort darauf zu reagieren und sich an seinen Interessen zu orientieren. Wenn alle Faktoren offline berechnet werden, wird eine schnelle Reaktion des Systems aufgrund von Verzögerungen unmöglich. Daher ist es notwendig, die Aktionen der Nutzer in Echtzeit zu verarbeiten. Zu diesem Zweck verwenden wir den ALS-Schritt zur Laufzeit, um die Vektorrepräsentation des Nutzers zu erstellen.
Angenommen, wir haben für alle Dokumente eine Vektorrepräsentation. Zum Beispiel können wir offline aus dem Text eines Artikels Embeddings mit ELMo, BERT oder anderen Modellen des maschinellen Lernens erstellen. Wie können wir die Vektorrepräsentation der Nutzer im selben Raum basierend auf ihren Interaktionen im System erhalten?
Der allgemeine Grundsatz zur Bildung und Zerlegung der Nutzer-Dokument-MatrixAngenommen, wir haben m Nutzer und n Dokumente. Für einige Nutzer ist ihre Beziehung zu bestimmten Dokumenten bekannt. Diese Informationen können wir in einer m x n-Matrix darstellen: Die Zeilen entsprechen den Nutzern und die Spalten den Dokumenten. Da die meisten Dokumente von einer Person nicht gesehen wurden, bleiben viele Zellen der Matrix leer, während andere ausgefüllt sind. Für jedes Ereignis (Gefällt mir, gefällt mir nicht, Klicken) sieht die Matrix einen bestimmten Wert vor – in unserem vereinfachten Modell entspricht ein "Gefällt mir" der 1 und ein "Gefällt mir nicht" der -1.
Wir zerlegen die Matrix in zwei Matrizen: P (m x d) und Q (d x n), wobei d die Dimension der Vektordarstellung ist (in der Regel eine kleine Zahl). Daher hat jedes Objekt einen d-dimensionalen Vektor (für den Nutzer ist das die Zeile in der Matrix P, für das Dokument die Spalte in der Matrix Q). Diese Vektoren sind die Embeddings der entsprechenden Objekte. Um vorherzusagen, ob einem Nutzer ein Dokument gefallen wird, multiplizieren wir einfach ihre Embeddings.

Eine mögliche Methode zur Zerlegung der Matrix ist ALS (Alternating Least Squares). Wir optimieren die folgende Verlustfunktion:

Hier ist rui - die Interaktion des Benutzers u mit dem Dokument i, qi - der Vektor des Dokuments i, pu - der Vektor des Benutzers u.
Der optimale Vektor des Benutzers aus Sicht des mittleren quadratischen Fehlers (bei festen Dokumentvektoren) wird analytisch durch die Lösung der entsprechenden linearen Regression ermittelt.
Dies wird als "ALS-Schritt" bezeichnet. Der Algorithmus selbst besteht darin, dass wir abwechselnd eine der Matrizen (Benutzer und Artikel) fixieren und die andere aktualisieren, um die optimale Lösung zu finden.
Glücklicherweise ist das Finden der Vektor-Darstellung des Benutzers eine ziemlich schnelle Operation, die zur Laufzeit unter Verwendung von Vektor-Befehlen durchgeführt werden kann. Dieser Trick ermöglicht es, das Benutzer-Feedback sofort in die Rangfolge einzubeziehen. Das gleiche Embedding kann auch im kNN-Index verwendet werden, um die Auswahl der Kandidaten zu verbessern.
Verteilte kollaborative Filterung
Wie kann man inkrementelle verteilte Matrixfaktorisierung durchführen und schnell die Vektor-Darstellung neuer Artikel finden?
Inhalte sind nicht die einzige Quelle für Empfehlungsdaten. Eine weitere wichtige Quelle ist die kollaborative Information. Gute Hinweise für das Ranking können traditionell aus der Zerlegung der Nutzer-Dokument-Matrix gewonnen werden. Bei dem Versuch, eine solche Zerlegung durchzuführen, sind wir jedoch auf Probleme gestoßen:
1. Wir haben Millionen von Dokumenten und zehn Millionen Nutzer. Die Matrix passt nicht vollständig auf eine einzige Maschine, und die Zerlegung würde sehr lange dauern.
2. Bei den meisten Inhalten in unserem System ist die Lebensdauer kurz: Dokumente sind nur wenige Stunden relevant. Daher ist es notwendig, ihre vektorielle Darstellung möglichst schnell zu erstellen.
3. Wenn die Zerlegung direkt nach der Veröffentlichung eines Dokuments erfolgt, haben wahrscheinlich nicht ausreichend viele Nutzer das Dokument bewertet. Daher wird die vektorielle Darstellung sehr wahrscheinlich nicht besonders gut sein.
4. Wenn ein Nutzer ein Dokument positiv oder negativ bewertet, können wir dies in der Zerlegung nicht sofort berücksichtigen.
Um die genannten Probleme zu lösen, haben wir eine verteilte Matrixfaktorierung benutzer-dokument mit häufigen, inkrementellen Updates umgesetzt. Wie funktioniert das genau?
Angenommen, wir haben einen Cluster aus N Maschinen (N in den Hunderten) und wollen eine verteilte Faktorierung einer Matrix durchführen, die nicht auf einer Maschine Platz hat. Die Frage ist, wie wir diese Faktorisierung so ausführen, dass eine ausreichende Datenmenge auf jeder Maschine vorhanden ist und die Berechnungen unabhängig voneinander stattfinden können.
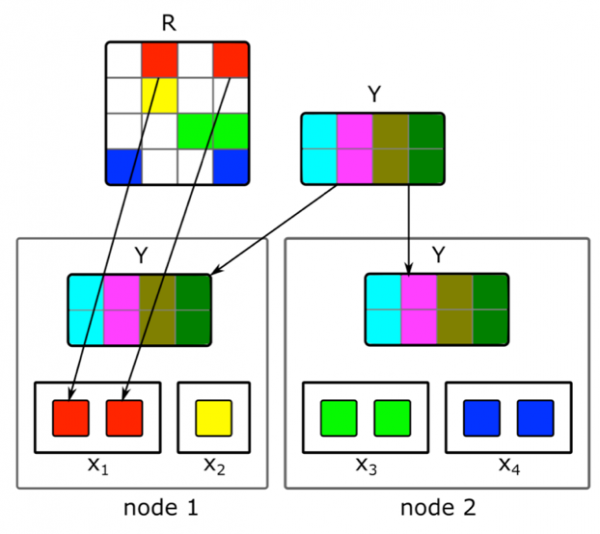
Wir werden den oben beschriebenen ALS-Faktorierungsalgorithmus verwenden. Lassen Sie uns betrachten, wie wir einen Schritt der ALS-Faktorisierung verteilt ausführen — die anderen Schritte werden ähnlich sein. Angenommen, wir haben die Dokumentmatrix fixiert und wollen die Benutzermatrix erstellen. Zu diesem Zweck teilen wir sie in N Teile nach Zeilen auf, wobei jeder Teil ungefähr die gleiche Anzahl von Zeilen enthält. Wir senden an jede Maschine die nicht leeren Zellen der entsprechenden Zeilen sowie die gesamte Dokumenteinbettungsmatrix. Da sie nicht sehr groß ist und die Benutzer-Dokument-Matrix normalerweise sehr dünn besetzt ist, passen diese Daten auf eine gewöhnliche Maschine.
Dieser Trick kann über mehrere Epochen hinweg zur Konvergenz des Modells wiederholt werden, indem abwechselnd die feste Matrix verändert wird. Doch selbst dann kann die Zerlegung der Matrix mehrere Stunden in Anspruch nehmen. Und das löst nicht das Problem, dass man schnell die Embeddings neuer Dokumente erhalten und die Embeddings derjenigen aktualisieren muss, zu denen während des Modelltrainings nur begrenzte Informationen vorlagen.
Die Implementierung eines schnellen inkrementellen Updates des Modells hat uns geholfen. Angenommen, wir haben ein aktuelles trainiertes Modell. Seit seiner Schulung sind neue Artikel erschienen, mit denen unsere Benutzer interagiert haben, sowie Artikel, die während des Trainings nur geringfügig genutzt wurden. Um schnell die Embeddings solcher Artikel zu erhalten, verwenden wir die Benutzer-Embeddings, die während des ersten großen Trainings des Modells generiert wurden, und führen einen Schritt ALS (Alternating Least Squares) durch, um die Dokumentmatrix bei konstanter Benutzermatrix zu berechnen. Dadurch können wir die Embeddings ziemlich schnell erhalten – innerhalb von Minuten nach der Veröffentlichung eines Dokuments – und die Embeddings neuer Dokumente häufig aktualisieren.
Um Empfehlungen sofort in Echtzeit auf die Handlungen der Benutzer abzustimmen, verwenden wir keine Offline-Benutzer-Embeddings. Stattdessen setzen wir den ALS-Schritt ein und erhalten den aktuellsten Benutzervektor.
Übertragung auf ein anderes Domaingebiet
Wie kann man das Nutzerfeedback zu Textartikeln nutzen, um eine Vektordarstellung von Videos zu erstellen?
Ursprünglich haben wir nur Textartikel empfohlen, weshalb viele unserer Algorithmen auf diese Art von Inhalten optimiert sind. Bei der Einführung von Inhalten anderer Typen stießen wir jedoch auf die Notwendigkeit, die Modelle anzupassen. Wie haben wir diese Herausforderung am Beispiel von Videos gelöst? Eine Möglichkeit wäre, alle Modelle von Grund auf neu zu trainieren. Das dauert jedoch lange und einige Algorithmen sind auf eine große Menge an Trainingsdaten angewiesen, die für neue Inhaltstypen in den ersten Phasen seiner Nutzung auf dem Dienst noch nicht in ausreichendem Maße vorhanden sind.
Wir haben einen anderen Weg eingeschlagen und Textmodelle für Videos wiederverwendet. Bei der Erstellung von Vektorrepräsentationen für Videos haben wir denselben ALS-Trick verwendet. Wir haben die Vektorrepräsentation der Nutzer basierend auf Textartikeln genommen und einen ALS-Schritt unternommen, indem wir Informationen über Videoansichten eingesetzt haben. So erhielten wir mühelos die Vektorrepräsentation des Videos. Zur Laufzeit berechnen wir einfach die Ähnlichkeit zwischen dem Benutzervektor, der auf Textartikeln basiert, und dem Video-Vektor.
Fazit
Die Entwicklung des Kernsystems für Echtzeitempfehlungen ist mit vielen Herausforderungen verbunden. Es ist erforderlich, Daten schnell zu verarbeiten und ML-Methoden anzuwenden, um diese Daten effektiv zu nutzen; komplexe verteilte Systeme zu bauen, die in der Lage sind, Nutzerinformationen und neue Inhalte in minimaler Zeit zu verarbeiten; und viele weitere Aufgaben.
In dem aktuellen System, dessen Gerät ich beschrieben habe, wächst die Qualität der Empfehlungen für den Nutzer mit seiner Aktivität und Verweildauer im Dienst. Doch hier liegt auch die größte Herausforderung: Es fällt dem System schwer, sofort die Interessen eines Menschen zu erkennen, der wenig mit den Inhalten interagiert hat. Die Verbesserung der Empfehlungen für neue Nutzer ist unser zentrales Anliegen. Wir werden weiterhin die Algorithmen optimieren, damit relevante Inhalte schneller in den Feed gelangen und irrelevante nicht angezeigt werden.
Quelle: habr.com
