

Mein Name ist Anton Baderin. Ich arbeite im Zentrum für Hochtechnologien und beschäftige mich mit Systemadministration. Vor einem Monat fand unsere Unternehmenskonferenz statt, auf der wir unsere gesammelten Erfahrungen mit der IT-Community unserer Stadt teilten. Ich sprach über das Monitoring von Webanwendungen. Das Material war für Fachkräfte auf Junior- oder Mittelstufe gedacht, die diesen Prozess nicht von Grund auf aufgebaut haben.

Der Grundpfeiler jeder Monitoring-Lösung ist die Erfüllung der Geschäftsziele. Monitoring ohne einen klaren Zweck interessiert niemanden. Was möchte das Geschäft? Dass alles schnell und fehlerfrei funktioniert. Das Geschäft verlangt nach Proaktivität, damit wir selbst Probleme im Service feststellen und schnellstmöglich beheben. Das sind im Wesentlichen die Herausforderungen, die ich im vergangenen Jahr in einem Projekt eines unserer Kunden angegangen bin.
Über das Projekt
Das Projekt ist eines der größten Loyalty-Programme im Land. Wir helfen Einzelhandelsketten, die Verkaufsfrequenz durch verschiedene Marketinginstrumente wie Bonuskarten zu erhöhen. Insgesamt umfasst das Projekt 14 Anwendungen, die auf zehn Servern laufen.
Während meiner Vorstellungsgespräche habe ich immer wieder festgestellt, dass Administratoren nicht immer die richtige Herangehensweise an das Monitoring von Webanwendungen haben: Viele fokussieren sich weiterhin auf die Betriebssystemmetriken und überwachen gelegentlich die Dienste.
In meinem Fall basierte das Monitoring-System des Kunden auf Icinga. Diese Lösung erfüllte jedoch nicht die oben genannten Anforderungen. Oft informierte uns der Kunde selbst über Probleme, und es fehlte uns häufig an Daten, um die Ursachen zu ermitteln.
Darüber hinaus war uns klar, dass eine weitere Entwicklung nicht vielversprechend wäre. Ich denke, diejenigen, die mit Icinga vertraut sind, werden mich verstehen. Also haben wir beschlossen, das Monitoring-System für Webanwendungen im Projekt komplett neu zu gestalten.
Prometheus
Wir haben uns für Prometheus entschieden, basierend auf drei Hauptkriterien:
- Eine riesige Anzahl an verfügbaren Metriken. In unserem Fall sind es 60.000. Natürlich muss erwähnt werden, dass die überwiegende Mehrheit davon nicht genutzt wird (wahrscheinlich etwa 95%). Auf der anderen Seite sind sie alle relativ günstig. Für uns ist dies eine andere Extreme im Vergleich zu dem zuvor verwendeten Icinga. Dort war das Hinzufügen von Metriken besonders schmerzhaft: die verfügbaren waren teuer (man muss nur den Quellcode eines beliebigen Plugins ansehen). Jedes Plugin war ein Skript in Bash oder Python, dessen Ausführung in Bezug auf die benötigten Ressourcen nicht günstig war.
- Dieses System verbraucht relativ wenig Ressourcen. Für all unsere Metriken genügen 600 MB RAM, 15 % eines Kerns und ein paar Dutzend IOPS. Natürlich müssen Metrik-Exporteure laufen, aber alle sind in Go geschrieben und ebenfalls nicht ressourcenhungrig. Ich denke nicht, dass das in der heutigen Zeit ein Problem ist.
- Ermöglicht den Übergang zu Kubernetes. Angesichts der Pläne des Kunden ist die Wahl offensichtlich.
ELK
Früher haben wir keine Logs gesammelt oder verarbeitet. Die Mängel sind allen bekannt. Wir haben uns für ELK entschieden, da wir bereits Erfahrung mit diesem System hatten. Dort speichern wir nur die Anwendungsprotokolle. Die Hauptkriterien für die Auswahl waren die Volltextsuche und ihre Geschwindigkeit.
Clickhouse
Zunächst fiel die Wahl auf InfluxDB. Wir wussten, dass wir Logs von Nginx, Statistiken aus pg_stat_statements und historische Daten von Prometheus sammeln mussten. Influx gefiel uns nicht, da es manchmal viel Speicher verbrauchte und abstürzte. Außerdem wollten wir Anfragen nach remote_addr gruppieren, aber in dieser DB war die Gruppierung nur nach Tags möglich. Tags sind teuer (Speicher), ihre Anzahl ist begrenzt.
Wir begannen die Suche von neuem. Wir benötigten eine analytische Basis mit minimalem Ressourcenverbrauch, idealerweise mit Datenkompression auf der Festplatte.
Clickhouse erfüllt all diese Kriterien, und wir haben unsere Wahl nie bereut. Wir schreiben keine außergewöhnlich großen Datenmengen in ihn (die Anzahl der Einfügungen liegt bei etwa fünftausend pro Minute).
NewRelic
NewRelic war historisch gesehen immer bei uns, da es die Wahl des Kunden war. Bei uns wird es als APM eingesetzt.
Zabbix
Wir verwenden Zabbix ausschließlich zur Überwachung verschiedener API-Blackboxen.
Ansatz zur Überwachung definieren
Wir wollten die Aufgabe aufschlüsseln und dadurch unseren Ansatz zur Überwachung systematisieren.
Dafür habe ich unser System in folgende Ebenen unterteilt:
- „Hardware“ und VMS;
- Betriebssystem;
- Systemdienste, Software-Stack;
- Anwendung;
- Geschäftslogik.
Der Vorteil eines solchen Ansatzes ist:
- Wir wissen, wer für die Funktion jeder Ebene verantwortlich ist und können dementsprechend Alarme versenden;
- Wir können die Struktur bei der Unterdrückung von Alarmen nutzen – es wäre seltsam, einen Alarm für die Nichtverfügbarkeit der Datenbank zu senden, wenn die gesamte virtuelle Maschine nicht erreichbar ist.
Da unsere Aufgabe darin besteht, Fehlfunktionen im System zu identifizieren, müssen wir auf jeder Ebene eine bestimmte Menge an Metriken festlegen, auf die wir bei der Erstellung von Alarmregeln achten sollten. Lassen Sie uns die Ebenen „VMS“, „Betriebssystem“ und „Systemdienste, Software-Stack“ durchgehen.
Virtuelle Maschinen
Hosting weisen uns Prozessor, Festplatte, Speicher und Netzwerk zu. Mit den ersten beiden hatten wir Probleme. Hier sind die Metriken:
CPU gestohlene Zeit — wenn Sie eine virtuelle Maschine bei Amazon (z. B. t2.micro) kaufen, sollten Sie verstehen, dass Ihnen nicht ein ganzes CPU-Kern zugewiesen wird, sondern lediglich ein Kontingent seiner Zeit. Und wenn Sie dieses aufbrauchen, wird Ihnen die Prozessorleistung entzogen.
Diese Metrik ermöglicht es, solche Momente zu überwachen und Entscheidungen zu treffen. Zum Beispiel, ob es notwendig ist, einen umfangreicheren Tarif zu wählen oder die Verarbeitung von Hintergrundaufgaben und API-Anfragen getrennt durchzuführen. Server.
IOPS + CPU iowait-Zeit — aus irgendeinem Grund haben viele Cloud-Hosting-Anbieter das Problem, dass sie nicht genügend IOPS bereitstellen. Darüber hinaus ist ein Diagramm mit niedrigen IOPS für sie kein Argument. Daher ist es sinnvoll, auch CPU iowait zu erfassen. Mit diesem Paar von Diagrammen — niedrige IOPS und hohe Eingabe-/Ausgabewartezeit — kann bereits mit dem Hosting-Anbieter gesprochen werden, um das Problem zu lösen.
Das Betriebssystem
Metriken des Betriebssystems:
- verfügbarer Speicher in %;
- Aktivität der Nutzung von Swap: vmstat swapin, swapout;
- Anzahl der verfügbaren Inodes und freier Speicherplatz im Dateisystem in %
- Durchschnittliche Last;
- Anzahl der Verbindungen im Status tw;
- Füllstand der conntrack-Tabelle;
- Die Netzwerkqualität kann mit dem Tool ss überwacht werden, und das Paket iproute2 — um den RTT-Wert von Verbindungen aus dessen Ausgabe zu erhalten und nach destinierter Portnummer zu gruppieren.
Auf Betriebssystemebene gibt es auch eine Entität wie Prozesse. Es ist wichtig, eine Gruppe von Prozessen im System zu identifizieren, die eine entscheidende Rolle für dessen Funktionalität spielen. Wenn Sie beispielsweise mehrere pgpool-Instanzen haben, ist es notwendig, Informationen zu jeder von ihnen zu sammeln.
Die Kennzahlen sind wie folgt:
- CPU;
- Speicher – zunächst der residente;
- IO – vorzugsweise in IOPS;
- FileFd – offene und Limits;
- wesentliche Seitenfehler – damit können Sie erkennen, welcher Prozess in den Swap geht.
Die gesamte Überwachung wird bei uns in Docker durchgeführt, zur Datensammlung der Metriken nutzen wir Cadvisor. Auf den anderen Maschinen verwenden wir process-exporter.
Systemdienste, Software-Stack
Jede Anwendung hat ihre eigene Spezifik, und es ist schwierig, eine einheitliche Kennzahlenbasis festzulegen.
Ein universelles Set umfasst:
- Anfragerate;
- Anzahl der Fehler;
- Latenz;
- Saturation.
Die auffälligsten Beispiele für Monitoring auf dieser Ebene sind Nginx und PostgreSQL.
Der am stärksten beanspruchte Dienst in unserem System ist die Datenbank. Früher hatten wir häufig Probleme damit, herauszufinden, was die Datenbank gerade macht.
Wir haben eine hohe Belastung der Festplatten festgestellt, aber die Slow-Logs zeigten nichts Aufschlussreiches. Dieses Problem haben wir mit pg_stat_statements gelöst, einer Ansicht, die Statistiken zu Abfragen sammelt.
Das ist alles, was ein Administrator braucht.
Wir erstellen Graphen zur Aktivität von Lese- und Schreibanfragen:
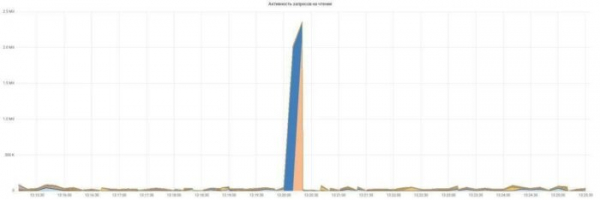
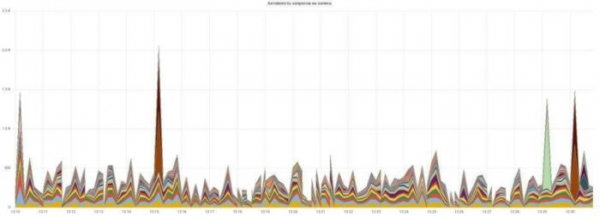
Alles ist einfach und verständlich, jede Anfrage hat ihre eigene Farbe.
Ein nicht weniger augenfälliges Beispiel sind die Nginx-Logs. Es ist nicht überraschend, dass sie von wenigen geparsed oder in die Liste der Notwendigkeiten aufgenommen werden. Das Standardformat ist nicht sehr informativ und muss erweitert werden.
Persönlich habe ich request_time, upstream_response_time, body_bytes_sent, request_length, request_id hinzugefügt. Wir erstellen Graphen für die Antwortzeiten und die Anzahl der Fehler:
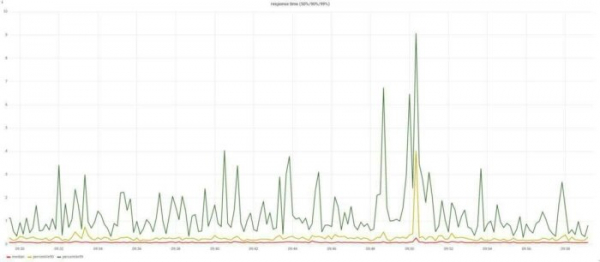
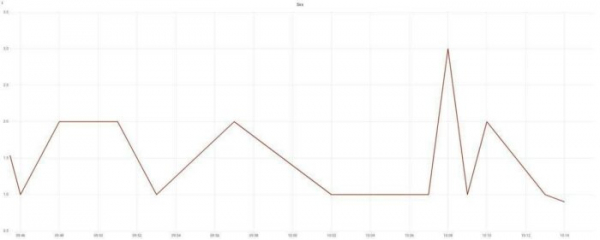
Wir erstellen Graphen für die Antwortzeiten und die Anzahl der Fehler. Erinnern Sie sich? Ich sprach über die Anforderungen des Unternehmens? Schnell und fehlerfrei? Mit zwei Graphen haben wir diese Fragen bereits geklärt. Anhand dieser kann bereits der diensthabende Administrator kontaktiert werden.
Es bleibt jedoch ein weiteres Problem – die schnelle Beseitigung der Ursachen des Vorfalls sicherzustellen.
Vorfallbehebung
Der gesamte Prozess von der Diagnose bis zur Lösung des Problems lässt sich in mehrere Schritte unterteilen:
- Problemerkennung;
- Benachrichtigung des diensthabenden Administrators;
- Reaktion auf den Vorfall;
- Beseitigung der Ursachen.
Es ist wichtig, dass wir dies so schnell wie möglich tun. Auch wenn wir in den Phasen der Problemidentifizierung und der Benachrichtigung wenig Zeit gewinnen können – dafür benötigen wir in jedem Fall zwei Minuten, so ist der nachfolgende Schritt ein völlig ungenutztes Feld für Verbesserungen.
Stellen wir uns einfach vor, das Telefon des Bereitschaftsdienstes klingelt. Was wird er tun? Antworten auf Fragen suchen – was ist kaputt, wo ist es kaputt, wie reagiert man? So beantworten wir diese Fragen:
Wir fügen einfach all diese Informationen in den Text der Benachrichtigung ein und geben darin einen Link zu der Wiki-Seite, auf der erklärt wird, wie man auf dieses Problem reagieren, es lösen und eskalieren kann.
Ich habe bisher nichts über die Anwendungs- und Geschäftsebene gesagt. Leider ist in unseren Anwendungen das Sammeln von Metriken noch nicht umgesetzt. Die einzige Quelle für einige Informationen auf diesen Ebenen sind die Logs.
Ein paar Punkte.
Erstens, schreiben Sie strukturierte Logs. Vermeiden Sie es, den Kontext in den Nachrichtentext zu integrieren. Das erschwert deren Gruppierung und Analyse. Logstash benötigt viel Zeit, um das alles zu normalisieren.
Zweitens, verwenden Sie die Severity-Level korrekt. Jede Sprache hat ihren eigenen Standard. Persönlich unterscheide ich vier Ebenen:
- keine Fehler;
- Fehler auf Seiten des Kunden;
- Fehler auf unserer Seite, wir verlieren kein Geld und tragen kein Risiko;
- Fehler auf unserer Seite, wir verlieren Geld.
Zusammenfassend. Es ist wichtig, das Monitoring an der Geschäftslogik auszurichten. Wir sollten das eigentliche Anwendung überwachen und Kennzahlen wie Verkaufszahlen, neue Nutzeranmeldungen, aktive Benutzer zu einem bestimmten Zeitpunkt und ähnliches verfolgen.
Wenn Ihr gesamtes Geschäft nur ein Knopf im Browser ist, müssen Sie überwachen, ob dieser gedrückt wird und ordnungsgemäß funktioniert. Alles andere ist unwichtig.
Wenn Sie das nicht haben, können Sie versuchen, es in den Anwendungsprotokollen, Nginx-Protokollen usw. nachzuvollziehen, wie wir es gemacht haben. Sie müssen so nah wie möglich an der Anwendung sein.
Die Metriken des Betriebssystems sind natürlich wichtig, aber für das Geschäft sind sie nicht von Interesse, wir werden dafür nicht bezahlt.
Quelle: habr.com
