

Hallo! Ich bin Alexey Pjankov, ein Entwickler bei Sportmaster. In diesem Bericht habe ich erzählt, wie die Arbeit an der Sportmaster-Website im Jahr 2012 begann, welche Initiativen wir erfolgreich durchsetzen konnten und welche Herausforderungen wir bewältigt haben.
Heute möchte ich meine Gedanken zu einem anderen Thema teilen – der Auswahl eines Caching-Systems für das Java-Backend im Admin-Bereich der Website. Dieses Thema liegt mir besonders am Herzen – obwohl die Geschichte nur 2 Monate dauerte, haben wir in diesen 60 Tagen 12-16 Stunden am Tag ohne einen einzigen freien Tag gearbeitet. Ich hätte nie gedacht, dass man so viel arbeiten kann.
Deshalb teile ich den Text in 2 Teile auf, um es nicht zu überladen. Im Gegenteil, der erste Teil wird sehr leicht sein – eine Vorbereitung, eine Einführung und einige Überlegungen zum Thema Caching. Wenn Sie bereits ein erfahrener Entwickler sind oder mit Caches gearbeitet haben, wird es in diesem Artikel aus technischer Sicht wahrscheinlich nichts Neues geben. Für einen Junior könnte jedoch eine kleine Übersicht hilfreich sein, in welche Richtung man schauen sollte, falls man an einem solchen Scheideweg steht.
Als die neue Version der Sportmaster-Website in die Produktion ging, war der Datenfluss, um es vorsichtig auszudrücken, alles andere als ideal. Die Grundlage bildeten Tabellen, die für die vorherige Website-Version (Bitrix) erstellt wurden. Diese mussten in das ETL-System integriert, an das neue Format angepasst und mit verschiedenen zusätzlichen Informationen aus einer Handvoll anderer Systeme angereichert werden. Um sicherzustellen, dass ein neues Bild oder eine Produktbeschreibung auf der Website erscheint, musste man bis zum nächsten Tag warten — die Aktualisierungen fanden nur nachts einmal täglich statt.
Anfangs gab es in den ersten Wochen nach dem Produktionsstart so viele Herausforderungen, dass die Unannehmlichkeiten der Content-Manager eher nebensächlich waren. Doch sobald sich alles stabilisierte, entwickelte sich das Projekt weiter – Anfang 2015 begannen wir aktiv an der Administrationsoberfläche zu arbeiten. In den Jahren 2015 und 2016 lief alles gut, wir veröffentlichten regelmäßig Updates, die Admin-Oberfläche umfasste zunehmend mehr Bereiche der Datenaufbereitung, und wir bereiteten uns darauf vor, bald das Wichtigste und Schwierigste zu übernehmen – die Produktlinie (komplette Vorbereitung und Verwaltung der Daten für alle Produkte). Doch im Sommer 2017, kurz vor dem Start der Produktlinie, befand sich das Projekt in einer sehr schwierigen Lage – gerade wegen Problemen mit dem Caching. Über diesen Vorfall möchte ich im zweiten Teil dieser zweiteiligen Veröffentlichung berichten.
In diesem Beitrag möchte ich jedoch von ganz hinten anfangen und einige Gedanken zur Vorstellung vom Caching zusammenfassen, die vor einem großen Projekt im Voraus hilfreich gewesen wären.
Wenn die Aufgabe des Cachings entsteht
Caching-Probleme tauchen nicht einfach so auf. Wir sind Entwickler, die Softwareprodukte erstellen, und wir möchten, dass diese gefragt sind. Wenn das Produkt gefragt und erfolgreich ist, kommen die Nutzer. Immer mehr Nutzer. Und wenn die Nutzerzahl stark ansteigt, wird das Produkt hochbelastet.
In den frühen Phasen denken wir nicht über Code-Optimierung und Leistung nach. Das Wichtigste ist die Funktionalität, das schnelle Bereitstellen eines Prototyps und die Überprüfung von Hypothesen. Wenn die Last steigt, verbessern wir die Hardware. Wir verdoppeln, verdreifachen, verzehnfachen die Ressourcen. Irgendwo hier wird das Budget nicht mehr mitspielen. Und um wie viel wird die Anzahl der Nutzer steigen? Es wird nicht nur 2-5-10 sein, sondern im Erfolgsfall von 100 bis 1000 und bis zu 100.000. Das heißt, irgendwann wird es unumgänglich sein, sich intensiv mit der Optimierung zu befassen.
Nehmen wir an, ein bestimmter Teil des Codes (wir nennen ihn Funktion) benötigt unverhältnismäßig lange, und wir möchten die Ausführungszeit verkürzen. Eine Funktion kann der Datenbankzugriff sein oder die Ausführung komplexer Logik – entscheidend ist, dass die Ausführung lange dauert. Wie viel kann die Ausführungszeit verkürzt werden? Im besten Fall – sie kann bis auf null reduziert werden, nicht weiter. Und wie kann man die Ausführungszeit auf null reduzieren? Antwort: Indem man die Ausführung vollständig ausschließt. Stattdessen – geben Sie sofort das Ergebnis zurück. Aber wie bekommt man das Ergebnis? Antwort: Entweder berechnen oder irgendwo nachsehen. Berechnen ist zeitaufwändig. Nachsehen hingegen bedeutet zum Beispiel, das Ergebnis zu speichern, das die Funktion beim letzten Aufruf mit denselben Parametern geliefert hat.
Das bedeutet, dass die Implementierung der Funktion für uns nicht entscheidend ist. Es reicht aus, die Parameter zu kennen, von denen das Ergebnis abhängt. Wenn wir dann die Werte der Parameter in einem Objekt darstellen, das als Schlüssel in einem Speicher verwendet werden kann, können wir das Berechnungsergebnis speichern und bei der nächsten Abfrage abrufen. Wenn diese Speicherung und Abfrage schneller erfolgt als die Ausführung der Funktion, erzielen wir einen Geschwindigkeitsvorteil. Der Vorteil kann bis zu 100, 1000 oder sogar 100.000-fach (10^5 – dies ist eher die Ausnahme, aber im Fall einer stark verzögerten Datenbank durchaus möglich) betragen.
Die grundlegenden Anforderungen an ein Caching-System
Die erste Anforderung an ein Caching-System ist die schnelle Lesegeschwindigkeit, und in etwas geringerem Maße die Schreibgeschwindigkeit. Das ist so, aber nur bis wir das System in die Produktion bringen.
Lassen Sie uns einen solchen Fall durchspielen.
Angenommen, wir haben die aktuelle Belastung mit entsprechender Hardware gedeckt und führen nun schrittweise Caching ein. Die Nutzerzahl steigt allmählich, die Last wächst – wir fügen einige Caches hinzu und integrieren sie hier und da. So verläuft es eine Zeit lang, und schon werden die ressourcenintensiven Funktionen kaum noch aufgerufen – die gesamte Hauptlast liegt auf dem Cache. In dieser Zeit ist die Nutzeranzahl um das N-Fache gestiegen.
Und wenn das anfängliche Hardware-Setup vielleicht das 2- bis 5-Fache ausmachen konnte, so konnten wir mit Hilfe des Caching die Leistung um das 10-Fache steigern oder im besten Fall sogar um das 100-Fache, in einigen Fällen möglicherweise sogar um das 1000-Fache. Das heißt, mit derselben Hardware verarbeiten wir 100-mal mehr Anfragen. Großartig, das haben wir verdient!
Doch nun, eines schönen Tages, gab das System zufällig den Geist auf und der Cache fiel aus. Nichts Außergewöhnliches – schließlich hatten wir den Cache mit dem Kriterium „hohe Lese- und Schreibgeschwindigkeit, alles andere ist unwichtig“ ausgewählt.
Im Hinblick auf die anfängliche Last verfügten wir über eine Hardwarereserve von 2-5 Mal, während die Last in der Zwischenzeit auf das 10- bis 100-Fache gestiegen ist. Mithilfe des Caches konnten wir die Aufrufe für rechenintensive Funktionen vermeiden, sodass alles reibungslos lief. Aber jetzt, ohne Cache – um wie viel wird unser System einbrechen? Was wird mit uns geschehen? Das System wird ausfallen.
Selbst wenn unser Cache nicht abgestürzt ist, sondern nur vorübergehend geleert wurde, muss er wieder aufgeheizt werden, und das wird einige Zeit in Anspruch nehmen. Während dieser Zeit wird die Hauptlast auf die Funktionalität fallen.
Fazit: Hochbelastete Projekte in der Produktion erfordern von einem Systemspeicher nicht nur hohe Lese- und Schreibgeschwindigkeiten, sondern auch Datensicherung und Ausfallsicherheit.
Die Qual der Wahl
Im Projekt mit dem Admin-Bereich stellte sich die Auswahl so dar: Zuerst setzten wir Hazelcast ein, da wir bereits durch die Erfahrungen mit der Hauptseite mit diesem Produkt vertraut waren. Doch diese Wahl stellte sich als nicht günstig heraus – unter unserem Lastprofil arbeitet Hazelcast nicht nur langsam, sondern schrecklich langsam. Zu diesem Zeitpunkt hatten wir bereits einen Termin für den Produktionsstart festgelegt.
Spoiler: Ich werde im zweiten Teil erzählen, wie es zu den Umständen kam, dass wir so eine Pleite erlebt haben und uns in eine schwierige und angespannte Situation gebracht haben – und wie wir da herausgekommen sind. Aber jetzt kann ich nur sagen, dass es ein großer Stress war, und ‚denken – geht irgendwie nicht, wir schütteln die Flasche‘. ‚Wir schütteln die Flasche‘ ist auch ein Spoiler, dazu später mehr.
Was wir gemacht haben:
- Wir erstellen eine Liste aller Systeme, die Google und StackOverflow vorschlagen. Etwas mehr als 30.
- Wir schreiben Tests mit der für die Produktion typischen Last. Dafür haben wir Daten erfasst, die im Produktionsumfeld durch das System laufen – eine Art Sniffer für Daten, die nicht im Netzwerk, sondern innerhalb des Systems sind. In die Tests haben wir genau diese Daten eingesetzt.
- Das gesamte Team wählt nacheinander das nächste System aus der Liste aus, konfiguriert es und führt die Tests durch. Wenn der Test nicht besteht und die Last nicht trägt – werfen wir es weg und gehen zum nächsten in der Reihe.
- Beim 17. System wurde klar, dass alles hoffnungslos war. Genug mit dem ‚Flasche schütteln‘, es ist Zeit, ernsthaft nachzudenken.
Aber das ist eine Option, wenn man ein System auswählen muss, das in bereits durchgeführten Tests hinsichtlich Geschwindigkeit "besteht". Und wenn es noch keine solchen Tests gibt und man möchte etwas Schnelleres wählen?
Lass uns dieses Szenario durchspielen (es ist schwer vorstellbar, dass ein mittelmäßiger Entwickler in einem Vakuum lebt und zu dem Zeitpunkt der Auswahl noch keine Präferenz geäußert hat, welches Produkt er als erstes ausprobieren möchte – daher handelt es sich bei den weiteren Überlegungen eher um theoretische Überlegungen/philosophische Betrachtungen über Junioren).
Sobald wir uns über die Anforderungen einig sind, beginnen wir mit der Auswahl einer fertigen Lösung. Warum das Rad neu erfinden: wir greifen auf ein bestehendes Caching-System zurück.
Wenn Sie gerade erst anfangen und googeln, wird es mehr oder weniger in dieser Reihenfolge sein, aber insgesamt werden die Anhaltspunkte wie folgt aussehen. Zunächst werden Sie auf Redis stoßen, das ist in aller Munde. Dann erfahren Sie, dass es EhCache gibt, das als eines der ältesten und bewährtesten Systeme gilt. Danach wird über Tarantool geschrieben – eine heimische Entwicklung, die einen einzigartigen Aspekt der Lösung bietet. Und auch Ignite, da es derzeit an Popularität gewinnt und von SberTech unterstützt wird. Am Ende kommt noch Hazelcast, da es in der Enterprise-Welt häufig in großen Unternehmen auftaucht.
Diese Liste ist nicht abschließend; es gibt Dutzende von Systemen. Wir betrachten lediglich eines davon. Nehmen wir die fünf ausgewählten Systeme zum „Schönheitswettbewerb“ und führen eine Auswahl durch. Wer wird der Gewinner sein?
Redis
Lassen Sie uns lesen, was auf der offiziellen Website steht.
— ein Open-Source-Projekt. Es bietet ein In-Memory-Datenbankspeicher, die Möglichkeit zum Speichern auf Festplatte, automatische Partitionierung, hohe Verfügbarkeit und Wiederherstellung nach Netzwerkunterbrechungen.
Scheint alles großartig zu sein, man könnte es einfach verwenden – es erfüllt alle Anforderungen. Aber lassen Sie uns der Vollständigkeit halber auch die anderen Kandidaten betrachten.
EhCache
— "der am häufigsten verwendete Cache für Java" (Übersetzung des Slogans von der offiziellen Website). Auch Open-Source. Hier erkennen wir, dass Redis nicht für Java gedacht ist, sondern allgemein, und zur Interaktion ein Wrapper erforderlich ist. EhCache ist dabei handlicher. Was verspricht dieses System noch? Zuverlässigkeit, Erprobtheit, volle Funktionalität. Und es ist das am weitesten verbreitete System. Es cached Terabytes an Daten.
Redis ist vergessen, ich bin bereit, EhCache zu wählen.
Aber mein Patriotismus drängt mich, zu schauen, was Tarantool zu bieten hat.
Tarantool
— wird mit dem Begriff „Echtzeit-Datenintegrationsplattform“ bezeichnet. Klingt komplex, also lesen wir die Seite gründlich und stoßen auf die kühne Behauptung: „Caching von 100 % der Daten im Arbeitsspeicher“. Das sollte Fragen aufwerfen — denn es könnte deutlich mehr Daten geben als Speicher. Die Interpretation hier ist, dass Tarantool beim Schreiben von Daten auf die Festplatte aus dem Speicher keine Serialisierung durchführt. Stattdessen nutzt es die niedrigstufigen Eigenschaften des Systems, bei denen der Speicher einfach auf das Dateisystem abgebildet wird, was hervorragende I/O-Leistungen bietet. Insgesamt haben sie das bemerkenswert und großartig gemacht.
Schauen wir uns die Implementierungen an: Mail.ru Unternehmensnetzwerk, Avito, Beeline, Megafon, Alfa-Bank, Gazprom…
Wenn ich noch irgendwelche Zweifel an Tarantool hatte, zerstreitet der Implementierungsfall bei Mastercard meine letzten Bedenken. Ich wähle Tarantool.
Aber letztendlich…
Ignite
… gibt es noch weitere , angegeben als „in-memory Rechenplattform… in-memory Geschwindigkeiten bei Petabytes von Daten“. Hier gibt es viele Vorteile: verteilte in-memory Caches, das schnellste Key-Value-Speichersystem und Cache, horizontale Skalierung, hohe Verfügbarkeit, strenge Konsistenz. Insgesamt ist Ignite also das schnellste.
Implementierungen: Sberbank, American Airlines, Yahoo! Japan. Und dann erfahre ich, dass Ignite nicht nur bei Sberbank implementiert ist, sondern dass das SberTech-Team eigene Leute in das Ignite-Team entsendet, um das Produkt weiterzuentwickeln. Das überzeugt mich vollkommen und ich bin bereit, Ignite zu wählen.
Ganz unklar, warum, schaue ich mir den fünften Punkt an.
Hazelcast
Ich besuche die Website , lese. Und es stellt sich heraus, dass die schnellste Lösung für verteiltes Caching – das ist Hazelcast. Es ist um ein Vielfaches schneller als alle anderen Lösungen und generell ist es der Marktführer im Bereich in-memory Data Grid. Vor diesem Hintergrund etwas anderes zu wählen – wäre sich nicht wertzuschätzen. Außerdem nutzt es redundante Datenspeicherung, um den Cluster kontinuierlich ohne Datenverluste zu betreiben.
Das war's, ich bin bereit, Hazelcast zu wählen.
Der Vergleich
Doch wenn man genau hinsieht, dann sind alle fünf Kandidaten so dargestellt, dass jeder von ihnen der Beste ist. Wie wählt man aus? Wir können schauen, welcher am beliebtesten ist, Vergleiche suchen, und der Kopfweh wird verschwinden.
Wir finden einen solchen , wählen unsere 5 Systeme aus.
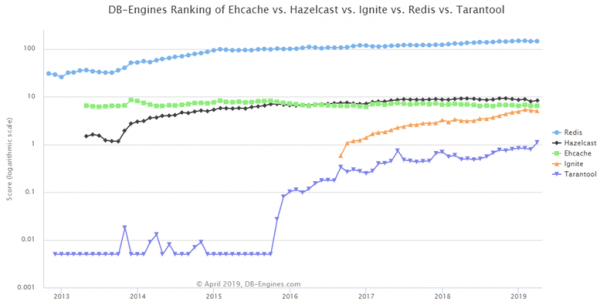
Hier sind sie sortiert: an erster Stelle Redis, an zweiter Stelle — Hazelcast, während Tarantool und Ignite an Popularität gewinnen, bleibt EhCache wie es war.
Aber schauen wir uns die : Links zu Websites, allgemeines Interesse an dem System, Stellenangebote — großartig! Das heißt, wenn mein System ausfällt, sage ich: „Nein, es ist doch zuverlässig! Da gibt es viele Stellenangebote...“. Ein so einfacher Vergleich eignet sich nicht.
All diese Systeme sind nicht nur Caching-Systeme. Sie haben auch viel mehr Funktionalität, einschließlich der Tatsache, dass nicht die Daten an den Kunden zur Verarbeitung übertragen werden, sondern umgekehrt: der Code, der auf den Daten ausgeführt werden muss, wird auf den Server übertragen, dort ausgeführt und das Ergebnis zurückgegeben. Und als separates Caching-System werden sie nicht allzu oft betrachtet.
Gut, wir geben nicht auf und suchen nach einem direkten Vergleich der Systeme. Wir nehmen die zwei besten Optionen — Redis und Hazelcast. Uns interessiert die Geschwindigkeit, nach diesem Kriterium vergleichen wir sie.
Hz vs Redis
Wir finden das Folgende heraus. :
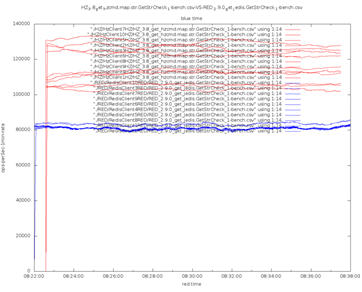
Blau steht für Redis, Rot für Hazelcast. Hazelcast hat in allen Aspekten die Nase vorn und hier gibt es einen guten Grund: Es ist Multithreading-fähig und hochoptimiert, wobei jeder Thread mit seiner eigenen Partition arbeitet, was zu keiner Blockierung führt. Redis hingegen ist ein Single-Thread-System und kann von modernen Mehrkern-CPUs nicht profitieren. Hazelcast nutzt asynchrones I/O, während Redis-Jedis blockierende Sockets verwendet. Außerdem verwendet Hazelcast ein binäres Protokoll, während Redis textbasiert ist, was es ineffizient macht.
Zur Sicherheit schauen wir uns eine weitere Vergleichsquelle an. Was wird uns das zeigen?
Redis vs Hz
Noch ein weiterer Vergleich. :
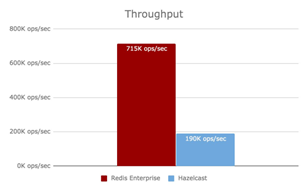
Hier ist es umgekehrt, Rot steht für Redis. Das bedeutet, dass Redis in Bezug auf die Leistung Hazelcast übertrifft. Im ersten Vergleich war Hazelcast überlegen, im zweiten hingegen Redis. Es stellt sich heraus, dass das Ergebnis des ersten Vergleichs praktisch manipuliert wurde: Redis wurde in der Basisversion getestet, während Hazelcast auf den Testfall optimiert wurde. Das führt uns zu der Erkenntnis: Erstens, niemandem kann man trauen, und zweitens, wenn wir uns schließlich für ein System entscheiden, müssen wir es richtig konfigurieren. Diese Einstellungen bestehen aus Dutzenden, fast Hunderten von Parametern.
Schütteln wir die Flasche.
Трясем бутылку
Und den gesamten Prozess, den wir gerade durchlaufen haben, kann ich mit der Metapher "Die Flasche schütteln" erklären. Das bedeutet, dass man jetzt nicht unbedingt programmieren muss; das Wichtigste ist, Stack Overflow lesen zu können. In meinem Team gibt es einen Profi, der genau so in kritischen Momenten arbeitet.
Was macht er? Er sieht ein defektes Gerät, erkennt den Stacktrace, nimmt einige Wörter daraus (welche genau – das ist seine Expertise in der Software), sucht bei Google und findet unter den Antworten Stack Overflow. Ohne zu lesen oder darüber nachzudenken, wählt er etwas, das dem Satz „Das und das tun“ am ähnlichsten ist (diese Auswahl ist sein Talent, denn es ist nicht immer die Antwort mit den meisten Likes), wendet es an und sieht: Wenn sich etwas geändert hat, ist das großartig. Wenn sich nichts geändert hat – zurücksetzen. Und wir wiederholen Start-Test-Suche. Auf diese intuitive Weise schafft er es, dass der Code nach einer Weile funktioniert. Er weiß nicht warum, er weiß nicht, was er gemacht hat, kann es nicht erklären. Aber! Das Ding funktioniert. Und „das Feuer ist gelöscht“. Jetzt klären wir, was wir gemacht haben. Wenn das Programm läuft, ist es um ein Vielfaches einfacher. Und es spart erheblich Zeit.
Diese Methode lässt sich sehr gut durch folgendes Beispiel erklären.
Es war einmal sehr populär, ein Segelschiff in einer Flasche zu bauen. Dabei ist das Segelschiff groß und zerbrechlich, während der Flaschenhals sehr schmal ist, man kann es nicht einfach reinstecken. Wie baut man es also zusammen?

Es gibt eine Methode, die sehr schnell und äußerst effektiv ist.
Ein Schiff besteht aus vielen kleinen Teilen: Sticks, Schnüren, Segeln und Kleber. All dies legen wir in eine Flasche.
Wir nehmen die Flasche mit beiden Händen und beginnen zu schütteln. Wir schütteln sie und schütteln sie. Und normalerweise – es wird natürlich nichts Gescheites dabei herauskommen. Aber manchmal. Manchmal wird es ein Schiff! Genauer gesagt, etwas, das wie ein Schiff aussieht.
Wir zeigen dieses Etwas jemandem: „Siehst du, Serjoga!?“. Und wirklich, aus der Ferne sieht es fast wie ein Schiff aus. Aber weiter darf man es nicht lassen.
Es gibt auch eine andere Möglichkeit. Es verwenden Leute, die fortgeschrittener sind, so genannte Hacker.
Habe einem Typen eine Aufgabe gegeben, er hat alles erledigt und ist gegangen. Und man sieht – es scheint erledigt zu sein. Aber nach einer Weile, wenn man den Code nachbessern muss – da fängt das Durcheinander wegen ihm an... Gut, dass er sich schon weit genug entfernt hat. Das sind solche Typen, die an einem Beispiel mit der Flasche Folgendes machen: Seht ihr, wo der Boden ist – das Glas biegt sich. Und es ist nicht ganz klar, ob es durchsichtig ist oder nicht. Dann schneiden die „Hacker“ diesen Boden ab, stecken das Schiff hinein, kleben den Boden wieder fest, und es sieht so aus, als wäre es so gedacht.
Aus der Sicht der Aufgabenstellung scheint alles korrekt zu sein. Doch nehmen wir als Beispiel Schiffe: Warum sollte man überhaupt dieses Schiff bauen, wer braucht es wirklich? Es hat keine Funktionalität. Solche Schiffe sind normalerweise Geschenke an hochrangige Persönlichkeiten, die es als ein Symbol, eine Art Zeichen, auf einem Regal ausstellen. Und wenn ein solcher Mensch, der Chef eines großen Unternehmens oder ein hochrangiger Beamter, ein solches Werk als Flaggschiff hat, bei dem der Hals abgeschnitten ist? Es wäre besser, wenn er niemals davon erfährt. Aber wie werden schließlich diese Schiffe hergestellt, die man einer wichtigen Person schenken kann?
Der einzige Punkt, mit dem man wirklich nichts anfangen kann, ist der Rumpf. Und der Rumpf des Schiffes passt genau durch den Flaschenhals. Während das Schiff außerhalb der Flasche zusammengebaut wird. Aber es ist nicht nur eine Frage des Zusammenbaus; es ist ein echtes Kunsthandwerk. In die einzelnen Teile werden spezielle Hebel integriert, die es ermöglichen, sie später anzuheben. Zum Beispiel werden die Segel zusammengelegt, sorgfältig hineingeschoben, und dann werden sie mit einer Pinzette äußerst präzise angehoben und positioniert. Am Ende entsteht ein Kunstwerk, das man mit reinem Gewissen und Stolz verschenken kann.
Und wenn wir wollen, dass das Projekt erfolgreich ist, sollte im Team mindestens eine Person wie ein Juwelier sein. Jemand, der sich um die Qualität des Produkts kümmert und alle Aspekte berücksichtigt, ohne in stressigen Momenten, in denen die Umstände dringendes Handeln erfordern, auf wichtige Dinge zu verzichten. Alle erfolgreichen Projekte, die Bestand haben und die Zeit überstehen, basieren auf diesem Prinzip. In ihnen gibt es etwas sehr Präzises und Einzigartiges, etwas, das alle verfügbaren Möglichkeiten nutzt. Im Beispiel des Schiffs in der Flasche wird illustriert, wie der Rumpf des Schiffs durch den Hals passt.
Zurück zu der Aufgabe, unseren Caching-Server auszuwählen: Wie könnte man diese Methode anwenden? Ich schlage vor, die Systeme, die es gibt, so auszuwählen, dass wir die Flasche nicht schütteln, sondern darauf achten, was prinzipiell darin vorhanden ist, worauf wir bei der Auswahl des Systems achten sollten.
Wo nach Engpässen suchen?
Wir versuchen, die Flasche nicht zu schütteln und alles der Reihe nach zu durchzugehen. Stattdessen schauen wir, welche Aufgaben sich ergeben, wenn wir eigenständig solch ein System entwerfen. Wir werden natürlich kein Fahrrad neu erfinden, sondern nutzen dieses Schema, um uns zu orientieren, auf welche Aspekte wir in den Produktbeschreibungen achten sollten. Lassen Sie uns so ein Schema entwerfen.
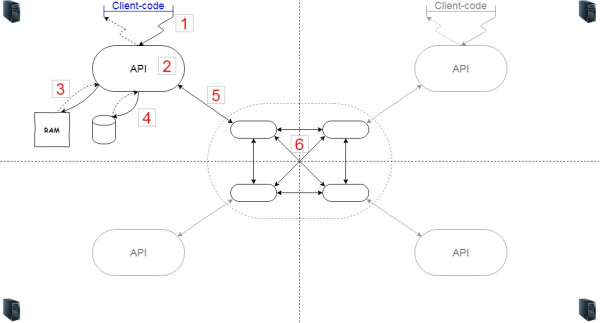
Wenn das System verteilt ist, bedeutet das, dass wir mehrere Server haben werden (6). Angenommen, wir haben vier (das lässt sich bequem auf dem Bild darstellen, aber es können natürlich beliebig viele sein). Wenn die Server auf verschiedenen Knoten sind, läuft auf ihnen allen ein gewisser Code, der sicherstellt, dass diese Knoten ein Cluster bilden und sich im Falle einer Unterbrechung wieder verbinden und einander erkennen.
Zusätzlich benötigen wir die Logik (2), die sich mit dem Caching befasst. Dieser Code interagiert über eine bestimmte API mit den Clients. Der Client-Code (1) kann sowohl innerhalb derselben JVM als auch über das Netzwerk darauf zugreifen. Die interne Logik besteht darin, zu entscheiden, welche Objekte im Cache bleiben und welche entfernt werden. Wir verwenden den Speicher (3) zur Speicherung des Caches, aber je nach Bedarf können wir auch einen Teil der Daten auf der Festplatte speichern (4).
Lassen Sie uns untersuchen, in welchen Bereichen die Last entstehen wird. Im Grunde genommen werden jede Verbindung und jeder Knoten belastet. Erstens kann es, wenn die Kommunikation zwischen dem Client-Code und der API erfolgt und wenn diese Netzwerkinteraktionen beinhaltet, zu merklichen Verzögerungen kommen. Zweitens, innerhalb der API selbst – wenn wir zu komplexe Logik implementieren, könnten wir an die CPU-Grenzen stoßen. Es wäre gut, wenn die Logik nicht unnötig auf den Arbeitsspeicher zugreift. Und schließlich bleibt die Interaktion mit dem Dateisystem – normalerweise bedeutet dies, dass wir Daten serialisieren/wiederherstellen und schreiben/lesen müssen.
Als Nächstes betrachten wir die Interaktion mit dem Cluster. Höchstwahrscheinlich wird er im selben System sein, es könnte aber auch separat sein. Auch hier muss die Datenübertragung zu ihm, die Geschwindigkeit der Datenserialisierung und die Interaktion zwischen dem Cluster berücksichtigt werden.
Jetzt können wir einerseits visualisieren, „welche Zahnräder sich im Cache-System drehen“ während die Anfragen von unserem Code verarbeitet werden, und andererseits können wir abschätzen, welche und wie viele Anfragen unser Code an dieses System generieren wird. Das ist ausreichend, um eine mehr oder weniger fundierte Entscheidung zu treffen – um ein System entsprechend unserem Anwendungsfall auszuwählen.
Hazelcast
Schauen wir uns an, wie diese Struktur auf unsere Liste angewendet werden kann. Zum Beispiel Hazelcast.
Um Daten in Hazelcast zu speichern oder abzurufen, greift der Client-Code (1) auf die API zu. Hz ermöglicht es, den Server als Embedded zu starten, und in diesem Fall ist der Zugriff auf die API ein Methodenausruf innerhalb der JVM, was als kostenlos betrachtet werden kann.
Damit die Logik in (2) funktioniert, stützt sich Hz auf den Hash des byte-Arrays des serialisierten Schlüssels – das heißt, die Serialisierung des Schlüssels findet in jedem Fall statt. Dies ist ein unvermeidlicher Overhead für Hz.
Die Eviction-Strategien sind gut implementiert, aber für spezielle Fälle können eigene Strategien hinzugefügt werden. Um diesen Teil muss man sich keine Sorgen machen.
Der Speicher (4) kann angeschlossen werden. Hervorragend. Die Interaktion (5) für Embedded kann als sofort betrachtet werden. Der Datenaustausch zwischen den Knoten im Cluster (6) – ja, der findet statt. Dies trägt zur Redundanz bei, jedoch auf Kosten der Geschwindigkeit. Die Hz-Funktion Near-cache ermöglicht es, dass Daten, die von anderen Knoten im Cluster erhalten werden, zwischengespeichert werden.
Was kann in solchen Situationen zur Geschwindigkeitssteigerung getan werden?
Um die Serialisierung des Schlüssels in (2) zu vermeiden, könnte man über Hazelcast einen weiteren Cache für die heißesten Daten anbringen. Bei Sportmaster haben wir dafür Caffeine ausgewählt.
Für die Anpassung auf Ebene (6) werden in Hz zwei Speichertypen angeboten: IMap und ReplicatedMap.
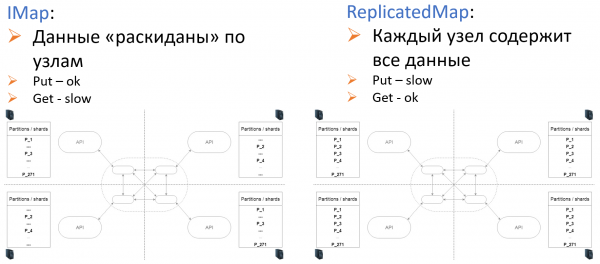
Es ist erwähnenswert, wie Hazelcast in den Technologie-Stack von Sportmaster integriert wurde.
Im Jahr 2012, als wir an dem ersten Prototyp der zukünftigen Website arbeiteten, war Hazelcast der erste Link, den die Suchmaschine anzeigte. Der Kontakt entstand 'auf Anhieb' – wir waren begeistert, dass es nur zwei Stunden dauerte, bis wir Hz ins System integriert hatten – es funktionierte. Und es funktionierte gut. Bis zum Ende des Tages schrieben wir einige Tests und waren zufrieden. Und dieser Schwung reichte aus, um die Herausforderungen zu meistern, die Hz im Laufe der Zeit brachte. Jetzt gibt es für das Sportmaster-Team keinen Grund, auf Hazelcast zu verzichten.
Aber Argumente wie 'der erste Link in der Suchmaschine' und 'schnell HelloWorld erstellt' sind natürlich Ausnahmen und besondere Umstände, die die Auswahl beeinflussten. Die wirklichen Prüfungen für das gewählte System beginnen mit der Markteinführung, und genau auf diese Phase sollte man achten, wenn man ein System, einschließlich Caches, wählt. In unserem Fall kann man sagen, dass wir Hazelcast zufällig ausgewählt haben, sich aber später herausstellte, dass die Wahl die richtige war.
Für Produktionsumgebungen sind folgende Punkte viel wichtiger: Monitoring, Fehlerbehandlung an einzelnen Knoten, Datenreplikation und Skalierungskosten. Es gilt, auf die Herausforderungen zu achten, die speziell bei der Systemwartung auftreten – wenn die Last um ein Vielfaches die geplante Belastung übersteigt, wenn versehentlich falsche Daten hochgeladen werden und wenn es notwendig ist, eine neue Version des Codes auszurollen, Daten zu ersetzen und dies unbemerkt für die Kunden zu erledigen.
Für all diese Anforderungen ist Hazelcast zweifellos geeignet.
Fortsetzung folgt
Aber Hazelcast ist keine Universallösung. Im Jahr 2017 wählten wir Hazelcast für den Cache im Admin-Bereich, einfach basierend auf unseren positiven Erfahrungen aus der Vergangenheit. Dies war entscheidend für einen sehr bösartigen Scherz, der uns in eine schwierige Lage brachte, aus der wir uns „heldenhaft“ in 60 Tagen herausarbeiteten. Doch mehr dazu im nächsten Teil.
Und bis dahin… Happy New Code!
Quelle: habr.com
