

Hallo zusammen, ich bin Alexander, arbeite als Ingenieur bei CIAN und beschäftige mich mit Systemadministration sowie der Automatisierung infrastruktureller Prozesse. In den Kommentaren zu einem unserer früheren Artikel wurden wir gebeten, zu erzählen, woher wir 4 TB Logs pro Tag beziehen und was wir damit machen. Ja, wir haben viele Logs, und um sie zu verarbeiten, wurde ein separater Infrastruktur-Cluster eingerichtet, der es uns ermöglicht, Probleme schnell zu lösen. In diesem Artikel werde ich erläutern, wie wir ihn im vergangenen Jahr an den ständig wachsenden Datenstrom angepasst haben.
Wie wir angefangen haben
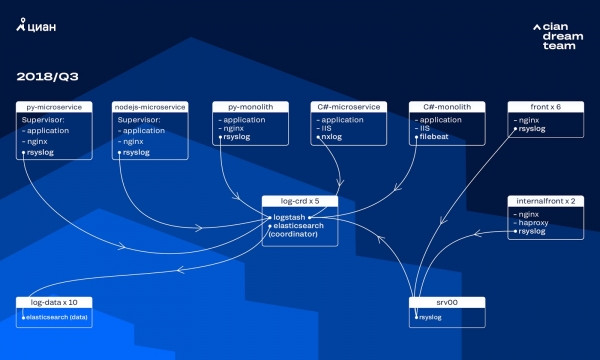
In den letzten Jahren ist die Last auf cian.ru sehr schnell gewachsen, und im dritten Quartal 2018 erreichte die Besucherzahl 11,2 Millionen eindeutige Nutzer pro Monat. In kritischen Momenten verloren wir damals bis zu 40% der Logs, wodurch wir bei Vorfällen nicht schnell reagieren konnten und sehr viel Zeit und Mühe aufwenden mussten, um sie zu lösen. Oft konnten wir auch die Ursache des Problems nicht finden, und es trat nach einiger Zeit erneut auf. Das war die Hölle, und wir mussten etwas dagegen unternehmen.
Zu diesem Zeitpunkt verwendeten wir zum Speichern der Protokolle einen Cluster aus 10 Datenknoten mit ElasticSearch Version 5.5.2 und Standardindizes. Dies wurde vor über einem Jahr als beliebte und kostengünstige Lösung implementiert: Zu diesem Zeitpunkt war das Protokollvolumen nicht besonders hoch, sodass es keinen Sinn machte, nicht Standardkonfigurationen zu entwickeln.
Die Verarbeitung der eingehenden Protokolle wurde von Logstash auf verschiedenen Ports auf fünf ElasticSearch-Koordinatoren durchgeführt. Ein Index bestand unabhängig von seiner Größe aus fünf Shards. Es wurde eine stündliche und tägliche Rotation organisiert, sodass stündlich etwa 100 neue Shards im Cluster hinzukamen. Solange die Protokolle nicht zu zahlreich waren, bewältigte der Cluster die Einstellungen problemlos, und niemand achtete darauf.
Probleme des schnellen Wachstums
Das Volumen der generierten Protokolle wuchs sehr schnell, da zwei Prozesse zusammenfielen. Einerseits wurden die Nutzer des Services immer mehr. Andererseits begannen wir aktiv, auf eine Microservices-Architektur umzusteigen, indem wir unsere alten Monolithen in C# und Python aufteilten. Mehrere Dutzend neuer Microservices, die Teile des Monolithen ersetzten, erzeugten deutlich mehr Protokolle für den Infrastruktur-Cluster.
Genau das Skalieren hat dazu geführt, dass der Cluster praktisch unmanagebar wurde. Als die Protokolle mit einer Geschwindigkeit von 20.000 Nachrichten pro Sekunde eintrafen, erhöhte häufige ineffektive Rotation die Anzahl der Shards auf 6.000, wobei auf einen Knoten mehr als 600 Shards entfielen.
Das führte zu Problemen mit der Zuweisung von Arbeitsspeicher, und beim Ausfall eines Knotens begann der gleichzeitige Umzug aller Shards, was den Traffic vervielfachte und die anderen Knoten belastete. Dadurch wurde es nahezu unmöglich, Daten in den Cluster zu schreiben. In dieser Zeit waren wir ohne Protokolle. Und bei einem Problem mit dem Server durch verloren wir praktisch 1/10 des Clusters. Die große Anzahl der kleinen Indizes stellte zusätzlich eine Herausforderung dar.
Ohne Protokolle konnten wir die Ursachen des Vorfalls nicht verstehen und liefen Gefahr, erneut in dieselben Fallen zu tappen. In unserer Teamideologie war dies unzulässig, da alle unsere Arbeitsmechanismen darauf ausgerichtet sind, niemals die gleichen Probleme zu wiederholen. Dafür benötigten wir eine vollständige Protokolldatenmenge und deren Lieferung praktisch in Echtzeit, da das Team der Ingenieure die Warnungen nicht nur von den Metriken, sondern auch von den Protokollen überwachte. Um das Ausmaß des Problems zu verstehen: Zu diesem Zeitpunkt betrug das gesamte Protokollvolumen etwa 2 TB pro Tag.
Wir hatten die Aufgabe gestellt, den Verlust von Protokollen vollständig auszuschließen und die Zeit für deren Lieferung in den ELK-Cluster auf maximal 15 Minuten während Notfällen zu reduzieren (auf diese Zahl stützten wir uns später als internes KPI).
Neuer Rotationsmechanismus und Hot-Warm-Knoten
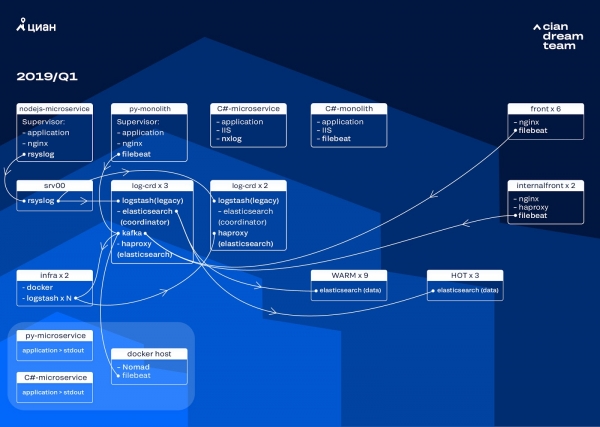
Wir begannen die Transformation des Clusters mit einem Upgrade der ElasticSearch-Version von 5.5.2 auf 6.4.3. Unser Cluster der Version 5 war erneut ausgefallen, und wir beschlossen, ihn abzuschalten und vollständig zu aktualisieren — schließlich hatten wir sowieso keine Protokolle. Daher vollzogen wir diesen Übergang in nur wenigen Stunden.
Das umfassendste Upgrade in dieser Phase war die Implementierung von Apache Kafka auf drei Knoten, wobei der Koordinator als Zwischenpuffer fungierte. Der Nachrichtenbroker verhinderte den Verlust von Logs während der Probleme mit ElasticSearch. Gleichzeitig haben wir dem Cluster zwei Knoten hinzugefügt und sind auf eine Hot-Warm-Architektur mit drei "heißen" Knoten umgestiegen, die in verschiedenen Racks des Rechenzentrums platziert sind. Auf diesen haben wir nach dem Muster Logs umgeleitet, deren Verlust auf keinen Fall akzeptabel ist — nginx sowie Anwendungsfehlerlogs. Auf die übrigen Knoten gingen geringfügige Logs — debug, warning usw., während „wichtige“ Logs nach 24 Stunden von den „heißen“ Knoten verschoben wurden.
Um die Anzahl der kleinen Indizes nicht zu erhöhen, sind wir von der zeitbasierten Rotation auf den Rollover-Mechanismus umgestiegen. In Foren gab es viele Informationen darüber, dass die Rotation nach der Größe des Index sehr unzuverlässig ist, weshalb wir uns entschieden haben, die Rotation nach der Anzahl der Dokumente im Index zu verwenden. Wir haben jeden Index analysiert und die Anzahl der Dokumente festgehalten, nach der die Rotation ausgelöst werden soll. So haben wir eine optimale Shard-Größe erreicht — nicht mehr als 50 GB.
Clusteroptimierung
Wir haben jedoch weiterhin Probleme. Leider tauchten immer noch kleine Indizes auf: Sie erreichten nicht das erforderliche Volumen, wurden nicht rotiert und durch die globale Bereinigung von Indizes, die älter als drei Tage waren, gelöscht, da wir die Rotation nach Datum entfernt hatten. Dies führte zu Datenverlust, weil der Index aus dem Cluster vollständig verschwand, und der Versuch, in einen nicht existierenden Index zu schreiben, brach die Logik des Curators, den wir zur Verwaltung verwendet haben. Der Alias zum Schreiben wurde in einen Index umgewandelt und störte die Logik des Rollover, was zu einem unkontrollierten Wachstum einiger Indizes auf bis zu 600 GB führte.
Zum Beispiel für die Rollover-Konfiguration:
curator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Ohne Rollover-Alias entstand ein Fehler:
ERROR Alias "nginx_write" nicht gefunden.
ERROR Aktion konnte nicht abgeschlossen werden: rollover. : Unable to perform index rollover with alias "nginx_write".
Wir haben die Lösung dieses Problems für die nächste Iteration zurückgestellt und uns mit einem anderen Thema beschäftigt: Wir sind zur Pull-Logik von Logstash gewechselt, das für die Verarbeitung eingehender Logs zuständig ist (Entfernung überflüssiger Informationen und Anreicherung). Wir haben es in Docker platziert, das wir über Docker-Compose starten, und dort auch den Logstash-Exporter integriert, der Metriken an Prometheus für die Echtzeitüberwachung des Logstroms übergibt. So haben wir uns die Möglichkeit gegeben, die Anzahl der Logstash-Instanzen, die für die Verarbeitung jeder Art von Logs zuständig sind, flexibel zu ändern.
Während wir den Cluster verbesserten, stieg die Besucherzahl von cian.ru auf 12,8 Millionen eindeutige Nutzer pro Monat. In der Folge stellte sich heraus, dass unsere Transformationen mit den Änderungen in der Produktion nicht ganz Schritt halten konnten, sodass wir mit dem Problem konfrontiert wurden, dass die 'warmen' Knoten mit der Last nicht zurechtkamen und die gesamte Logzustellung verlangsamt wurde. 'Heiße' Daten erhielten wir ohne Unterbrechungen, aber bei der Zustellung der anderen mussten wir eingreifen und ein manuelles Roll over durchführen, um die Indizes gleichmäßig zu verteilen.
Die Skalierung und Anpassung der Logstash-Instanzen im Cluster wurde dadurch erschwert, dass es sich um ein lokales Docker-Compose handelte und alle Aktionen manuell durchgeführt werden mussten (um neue Endpunkte hinzuzufügen, musste man manuell alle Server durchgehen und überall 'docker-compose up -d' ausführen).
Neuverteilung der Protokolle
Im September dieses Jahres setzten wir die Zerlegung des Monolithen fort, die Last auf dem Cluster stieg, und der Logstrom näherte sich 30.000 Nachrichten pro Sekunde.
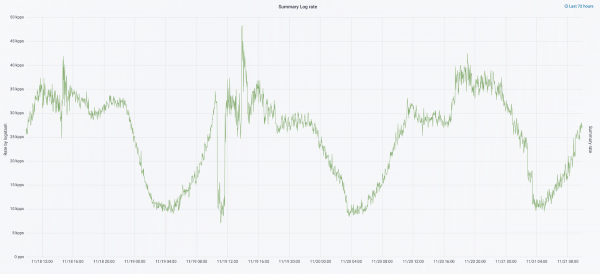
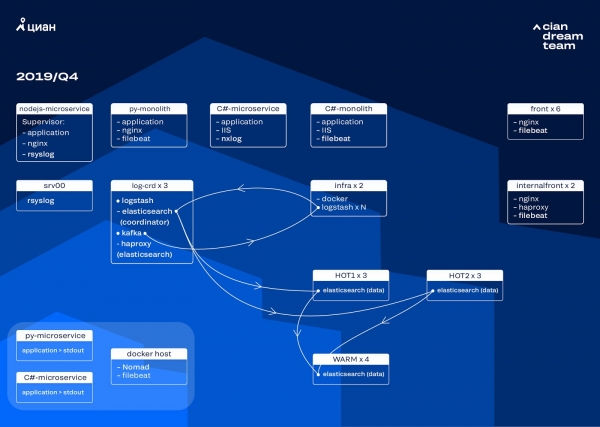
Die nächste Iteration begann mit einem Hardware-Update. Wir reduzierten die Anzahl der Koordinatoren von fünf auf drei, ersetzten die Datennodes und gewannen an Kosten und Speicherplatz. Für die Nodes verwenden wir zwei Konfigurationen:
- Für die "heißen" Nodes: E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3 für Hot1 und 3 für Hot2).
- Für die "warmen" Nodes: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
In dieser Iteration haben wir den Index mit den Access-Logs der Mikrodienste, der genauso viel Platz einnimmt wie die Logs der Frontend-Nginx, in die zweite Gruppe von drei "heißen" Nodes ausgelagert. Die Daten auf den "heißen" Nodes speichern wir jetzt 20 Stunden und übertragen sie dann zu den "warmen" Nodes zu den anderen Logs.
Wir haben das Problem des Verschwindens kleiner Indizes durch eine Neuanpassung ihrer Rotation gelöst. Jetzt rotieren die Indizes in jedem Fall alle 23 Stunden, auch wenn es dort nur wenige Daten gibt. Dies hat die Anzahl der Shards leicht erhöht (es gibt jetzt etwa 800), aber aus der Perspektive der Clusterleistung ist das akzeptabel.
Im Cluster gibt es nun sechs „heiße“ und nur vier „warme“ Knoten. Dies verursacht eine leichte Verzögerung bei Anfragen über längere Zeiträume, aber eine Erhöhung der Anzahl der Knoten in der Zukunft wird dieses Problem lösen.
In dieser Iteration haben wir auch das Problem des fehlenden halbautomatischen Skalierens behoben. Zu diesem Zweck haben wir ein infrastrukturelles Nomad-Cluster eingeführt — analog zu dem, das bereits in unserer Produktionsumgebung läuft. Während die Anzahl der Logstash-Instanzen derzeit noch nicht automatisch je nach Last angepasst wird, werden wir auch dieses Ziel erreichen.
Zukunftspläne
Die implementierte Konfiguration skaliert hervorragend, und derzeit speichern wir 13,3 TB Daten – alle Protokolle der letzten vier Tage, die für die schnelle Analyse von Alerts erforderlich sind. Einen Teil der Protokolle wandeln wir in Metriken um, die wir in Graphite speichern. Um die Arbeit der Ingenieure zu erleichtern, haben wir Metriken für den Infrastruktur-Cluster und Skripte zur halbautomatischen Behebung typischer Probleme. Nach der geplanten Erhöhung der Anzahl der Datenknoten im nächsten Jahr werden wir die Datenhaltung von vier auf sieben Tage verlängern. Das wird für die оперативní Arbeit ausreichen, da wir immer versuchen, Vorfälle so schnell wie möglich zu untersuchen, und für langfristige Ermittlungen stehen Telemetriedaten zur Verfügung.
Im Oktober 2019 wuchs die Besucherzahl von cian.ru bereits auf 15,3 Millionen unique Nutzer pro Monat. Dies war eine ernsthafte Prüfung der architektonischen Lösung zur Lieferung von Protokollen.
Derzeit bereiten wir das Update von ElasticSearch auf Version 7 vor. Allerdings müssen wir dafür das Mapping vieler Indizes in ElasticSearch aktualisieren, da sie von Version 5.5 umgezogen sind und in der Version 6 als veraltet gekennzeichnet wurden (in Version 7 gibt es sie einfach nicht mehr). Das bedeutet, dass es während des Updates zwangsläufig zu unerwarteten Problemen kommen wird, die uns vorübergehend ohne Protokolle lassen. Von Version 7 erwarten wir vor allem Kibana mit einer verbesserten Benutzeroberfläche und neuen Filtern.
Unser Hauptziel haben wir erreicht: Wir verlieren keine Protokolle mehr und haben die Ausfallzeiten unseres Infrastruktur-Clusters von 2-3 Ausfällen pro Woche auf ein paar Stunden Wartungsarbeiten pro Monat reduziert. All diese Maßnahmen haben im Produktionsbetrieb kaum sichtbare Auswirkungen. Dennoch können wir nun genau bestimmen, was mit unserem Dienst passiert, können dies schnell und ohne Stress in Ruhe durchführen, ohne Angst zu haben, dass Protokolle verloren gehen. Insgesamt sind wir zufrieden, glücklich und bereiten uns auf neue Herausforderungen vor, über die wir später berichten werden.
Quelle: habr.com
