


Wir alle lieben Geschichten. Es macht uns Freude, am Lagerfeuer von unseren früheren Siegen, Kämpfen oder einfach von unseren Erfahrungen zu erzählen.
Heute ist genau so ein Tag. Und auch wenn ihr gerade nicht am Lagerfeuer sitzt, haben wir eine Geschichte für euch. Eine Geschichte darüber, wie wir begannen, mit dem Tarantool-Speicher zu arbeiten.
Es war einmal in unserem Unternehmen, dass es einige 'Monolithen' gab und eine gemeinsame 'Decke', die diese Monolithen langsam, aber sicher näher kamen, und so den Flug unseres Unternehmens und unser Wachstum einschränkten. Es gab ein klares Verständnis: Eines Tages würden wir gegen diese Decke stoßen.
Heute herrscht bei uns die Ideologie der Trennung von allem, angefangen bei der Hardware bis hin zur Geschäftslogik. Infolgedessen haben wir beispielsweise zwei Rechenzentren, die auf Netzwerkebene praktisch unabhängig sind. Damals war alles ganz anders.
Heutzutage gibt es viele Werkzeuge und Mittel zur Implementierung von Änderungen in Form von CI/CD, K8S usw. In der 'Monolith-Zeit' benötigten wir so viele fremde Begriffe nicht. Es genügte, einfach die 'Datenbank' zu korrigieren.
Aber die Zeit verging, und die Anzahl der Anfragen wuchs mit ihr, wobei die RPS gelegentlich über unsere Möglichkeiten hinaus schoss. Mit dem Markteintritt in den GUS-Staaten fiel die CPU-Auslastung des ersten Monolithen nie unter 90 %, und die RPS lagen bei 2400. Und das waren keine einfachen Abfragen, sondern umfangreiche Anfragen mit zahlreichen Prüfungen und JOINs, die fast die Hälfte der Daten in einem großen IO durchsuchen konnten.
Als dann vollständige Rabatte am "Black Friday" auftraten – und Wildberries begann, diese als eines der ersten Unternehmen in Russland anzubieten – wurde die Situation wirklich trist. Denn die Last an solchen Tagen steigt dreimal an.
Ach, diese „monolithischen Zeiten“! Ich bin mir sicher, dass auch Sie damit konfrontiert waren und bis heute nicht verstehen können, wie so etwas Ihnen passieren konnte.
Was soll man tun – Mode gehört auch zu den Technologien. Vor etwa fünf Jahren mussten wir einen solchen Trend überdenken, in Form einer bestehenden Website auf .NET und MS SQL-Servern, die alle Logik der Website sorgfältig speicherte. So sorgfältig, dass es sich als langwierige und ziemlich unangenehme Aufgabe herausstellte, einen solchen Monolithen zu zerlegen.
Ein kleiner Einschub.
Bei verschiedenen Veranstaltungen sage ich: „Wenn Sie den Monolithen nicht aufteilen, sind Sie nicht gewachsen!“ Ich würde gerne Ihre Meinung dazu hören, bitte schreiben Sie sie in die Kommentare.
Und der Donner ging nieder
Kehren wir zu unserem „Monolithen“ zurück. Um die Last der „monolithischen“ Funktionalität zu verteilen, haben wir beschlossen, das System in Mikrodienste zu unterteilen, die auf Open-Source-Technologien basieren. Denn deren Skalierung ist mindestens kostengünstiger. Und wir wussten ganz genau, dass wir in der Lage sein würden zu skalieren (und das ziemlich stark). Schließlich hatten wir zu diesem Zeitpunkt bereits die Märkte der Nachbarländer erreicht, und die Anzahl der Registrierungen sowie die Anzahl der Bestellungen begannen noch stärker zu steigen.
Nachdem wir die ersten Kandidaten für den Wechsel von Monolithen zu Mikrodiensten analysiert hatten, verstanden wir, dass in 80 % der Fälle 99 % der Schreibvorgänge von Back-Office-Systemen stammen, während das Lesen von der Front kommt. Dies betraf zunächst zwei für uns wichtige Teilsysteme — Nutzerdaten und das System zur Berechnung des Endpreises von Waren auf Basis von Informationen über zusätzliche Kundenermäßigungen und Gutscheine.
In Anführungszeichen. Es ist schwer vorstellbar, aber neben den oben genannten Subsystemen wurden auch Produktkataloge, der Warenkorb, ein Produktsuchsystem, ein Filtersystem für Produktkataloge und verschiedene Empfehlungssysteme aus unserem Monolithen ausgegliedert. Für jeden von ihnen gibt es separate Klassen von spezialisierten Systemen, aber einst lebten sie alle in einem "Haus".
Die Daten über unsere Kunden sollten sofort in ein sharding-basiertes System ausgelagert werden. Die Auslagerung der Funktionalität zur Berechnung der Endpreise der Produkte erforderte jedoch eine gute Skalierbarkeit im Lesen, da diese die größte Last in Bezug auf RPS verursachte und für die Datenbank am kompliziertesten umzusetzen war (sehr viele Daten sind in den Berechnungsprozess involviert).
Infolgedessen entstand bei uns ein Schema, das gut mit Tarantool harmoniert.
Zu dieser Zeit wurden für den Betrieb der Mikrodienste Schemas mit mehreren Rechenzentren auf virtuellen und physischen Maschinen gewählt. Wie in den Abbildungen gezeigt, wurden sowohl Master-Master- als auch Master-Slave-Replikationsvarianten von Tarantool verwendet.
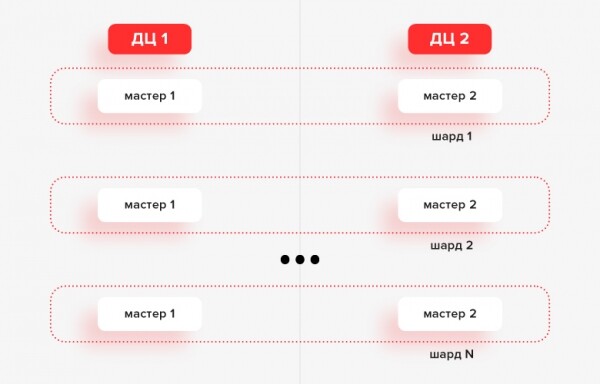
Architektur. Variante 1. Benutzerservice
Aktuell besteht dies aus 24 Shards, von denen jeder 2 Instanzen hat (eine für jedes Rechenzentrum), alle im Master-Master-Modus.
Über der Datenbank befinden sich Anwendungen, die auf die Replikate zugreifen. Die Anwendungen arbeiten mit Tarantool über unsere benutzerdefinierte Bibliothek, die die Schnittstelle des Go-Tarantool-Treibers implementiert. Sie sieht alle Replikate und kann mit dem Master lesen und schreiben. Im Wesentlichen implementiert sie ein Replica-Set-Modell, bei dem Logik für die Auswahl der Replikate, Wiederholungsversuche, Circuit Breaker und Rate Limiting hinzugefügt wurde.
Dabei gibt es die Möglichkeit, die Auswahlpolitik der Replikate auf Shard-Ebene zu konfigurieren. Zum Beispiel durch Round-Robin.

Architektur. Option 2. Dienst zur Berechnung der Endpreise von Waren.
Vor einigen Monaten ging der Großteil der Anfragen zur Berechnung der Endpreise von Waren an einen neuen Dienst, der grundsätzlich ohne Datenbanken funktioniert, aber vor einiger Zeit wurden alle 100% vom Dienst mit Tarantool im Hintergrund verarbeitet.
Die Datenbank des Dienstes besteht aus 4 Mastern, in denen der Synchronisierer Daten sammelt, und jeder dieser Master verteilt den Daten über readonly-Replikate. Jeder Master hat etwa 15 solcher Replikate.
Sowohl im ersten als auch im zweiten Schema kann die Anwendung bei Nichtverfügbarkeit eines Rechenzentrums Daten aus dem zweiten abrufen.
Es ist erwähnenswert, dass die Replikation in Tarantool ziemlich flexibel ist und zur Laufzeit konfiguriert werden kann. In anderen Systemen gab es diesbezüglich Schwierigkeiten. Zum Beispiel erfordert die Änderung der Parameter max_wal_senders und max_replication_slots in PostgreSQL einen Neustart des Masters, was in einigen Fällen zu Verbindungsabbrüchen zwischen der Anwendung und der Datenbank führen kann.
Suche und du wirst finden!
Warum haben wir nicht „wie normale Menschen“ gehandelt und einen typischen Weg gewählt? Es hängt davon ab, was man als normal ansieht. Viele erstellen überhaupt ein Cluster aus MongoDB und verteilen es über drei geo-redundante Rechenzentren.
Zu diesem Zeitpunkt hatten wir bereits zwei Projekte auf Redis. Das erste war ein Cache, das zweite diente als persistentes Speicher für nicht allzu kritische Daten. Damit hatten wir es ziemlich schwer, teilweise wegen unserer eigenen Fehler. Manchmal waren ziemlich große Datenmengen in einem Schlüssel gespeichert, und von Zeit zu Zeit hatte die Website Performance-Probleme. Dieses System nutzten wir im Master-Slave-Modus. Es gab viele Fälle, in denen etwas mit dem Master passierte und die Replikation unterbrochen wurde.
Das bedeutet, dass Redis gut für zustandslose Aufgaben ist, nicht für zustandsbehaftete. Im Grunde genommen konnte es die meisten Aufgaben erfüllen, aber nur, wenn es sich um Key-Value-Lösungen mit ein paar Indizes handelte. Zu diesem Zeitpunkt war die Persistenz und Replikation von Redis jedoch ziemlich enttäuschend. Außerdem gab es Bedenken hinsichtlich der Leistung.
Wir haben an MySQL und PostgreSQL gedacht. Aber MySQL hat sich irgendwie bei uns nicht durchgesetzt, während PostgreSQL ein sehr anspruchsvolles Produkt ist, und es wäre unrentabel, darauf einfache Dienste aufzubauen.
Wir haben RIAK, Cassandra und sogar eine graphbasierte Datenbank ausprobiert. All diese Lösungen sind ziemlich nischig und eigneten sich nicht als allgemeines, universelles Werkzeug zur Erstellung von Diensten.
Letztendlich entschieden wir uns für Tarantool.
Wir haben uns an es gewandt, als es sich in der Version 1.6 befand. Uns interessierte die Symbiose von Key-Value und der Funktionalität einer relationalen Datenbank. Es gibt sekundäre Indizes, Transaktionen und Spaces, das sind wie Tabellen, aber nicht einfach; man kann unterschiedliche Spaltenanzahlen darin speichern. Das Killer-Feature von Tarantool waren die sekundären Indizes in Kombination mit Key-Value und Transaktionsfähigkeit.
Ein ebenso wichtiger Faktor war die hilfsbereite russischsprachige Gemeinschaft, die bereit war, im Chat Unterstützung zu leisten. Wir haben das aktiv genutzt und lebten praktisch im Chat. Und nicht zu vergessen ist die anständige kontinuierliche Leistung ohne offensichtliche Fehler und Pannen. Wenn wir auf unsere Geschichte mit Tarantool zurückblicken, hatten wir viele Herausforderungen und Probleme mit der Replikation, aber wir haben dank seiner Zuverlässigkeit niemals Daten verloren!
Die Implementierung begann schwierig.
Zu diesem Zeitpunkt war unser Haupt-Entwicklungstechnologie-Stack .NET, für den es keinen Connector für Tarantool gab. Wir haben sofort angefangen, etwas in Go zu entwickeln. Auch mit Lua kamen wir ganz gut zurecht. Das Hauptproblem zu der Zeit war das Debugging: In .NET lief alles großartig, aber dann in die Welt von embedded Lua einzutauchen, in der du, abgesehen von den Logs, keine Debugging-Optionen hast, war ziemlich herausfordernd. Außerdem brach die Replikation aus irgendeinem Grund gelegentlich zusammen, was uns zwang, die Funktionsweise des Tarantool-Engines zu verstehen. Dabei half der Chat, die Dokumentation in geringerem Maße; manchmal schauten wir uns auch den Code an. Zu jener Zeit war die Dokumentation eher mittelmäßig.
So haben wir in den letzten Monaten viele Erfahrungen gesammelt und anständige Ergebnisse bei der Arbeit mit Tarantool erzielt. Wir haben im Git Referenzarbeiten erstellt, die bei der Entwicklung neuer Mikrodienste hilfreich waren. Zum Beispiel, wenn die Aufgabe entstand, einen weiteren Mikrodienst zu erstellen, schaute der Entwickler auf den Quellcode der Referenzlösung im Repository, und die Erstellung eines neuen dauerte nicht länger als eine Woche.
Das waren besondere Zeiten. Man konnte damals einfach zum Admin am Nachbartisch gehen und fragen: „Gib mir eine Virtual Machine“. Nach etwa dreißig Minuten war die Maschine schon bei dir. Du hast dich selbst verbunden, alles installiert und dir wurde Traffic darauf eingeleitet.
Heute ist das nicht mehr möglich: Man muss das Monitoring und Logging für den Dienst einrichten, die Funktionalität mit Tests abdecken, eine Virtual Machine oder eine Bereitstellung in Kubernetes bestellen usw. Insgesamt wird es so besser sein, obwohl es länger dauert und aufwändiger ist.
Teilen und herrschen. Wie steht es um Lua?
Es gab ein ernstes Dilemma: Einige Teams hatten Schwierigkeiten, Änderungen an einem Dienst mit einer großen Menge an Logik in Lua zuverlässig auszurollen. Oft ging dies mit der Unbrauchbarkeit des Dienstes einher.
Das heißt, die Entwickler bereiten eine Änderung vor. Tarantool beginnt mit der Migration, während die Replikation noch mit dem alten Code arbeitet; dabei wird über die Replikation irgendein DDL empfangen, etwas anderes, und der Code bricht einfach zusammen, weil das nicht berücksichtigt wurde. Infolgedessen war der Aktualisierungsprozess für die Admins auf ein A4-Blatt geschrieben: Replikation stoppen, das aktualisieren, Replikation einschalten, hier ausschalten, dort aktualisieren. Ein Albtraum!
Letztendlich versuchen wir heutzutage meistens, in Lua nichts zu machen. Einfach über iproto (ein Binärprotokoll zur Kommunikation mit dem Server), und das war's. Möglicherweise ist das ein Wissensmangel der Entwickler, aber aus dieser Perspektive ist das System kompliziert.
Wir folgen diesem Szenario nicht immer blind. Heute gibt es bei uns kein Schwarz und Weiß: entweder alles in Lua oder alles in Go. Wir verstehen bereits, wie wir kombinieren können, um später keine Probleme mit der Migration zu bekommen.
Wo ist Tarantool jetzt?
Tarantool wird im Dienst zur Berechnung des Endpreises von Produkten unter Berücksichtigung von Rabattcoupons verwendet, bekannt als "Promotizer". Wie bereits erwähnt, wird er jetzt eingestellt: Ein neuer Katalogdienst mit vorab berechneten Preisen ersetzt ihn. Vor einem halben Jahr wurden alle Berechnungen im "Promotizer" durchgeführt. Zuvor war die Hälfte seiner Logik in Lua geschrieben. Vor zwei Jahren wurde der Dienst in ein Speicher-System umgewandelt und die Logik auf Go neu geschrieben, da sich die Mechanik der Rabatte etwas verändert hat und dem Dienst die Leistung fehlte.
Einer der kritischsten Dienste ist das Benutzerprofil. Das bedeutet, dass alle Wildberries-Nutzer in Tarantool gespeichert sind, etwa 50 Millionen. Ein nach Benutzer-ID shardiertes System, verteilt über mehrere Rechenzentren mit einer Anbindung an Go-Services.
Früher war "Promotaiser" der Marktführer in Bezug auf RPS, mit bis zu 6.000 Anfragen. Zu einem bestimmten Zeitpunkt hatten wir 50-60 Instanzen. Jetzt ist der Marktführer bei RPS die Benutzerprofile, mit etwa 12.000. Dieser Dienst verwendet eine benutzerdefinierte Shardierung, die auf Benutzer-ID-Bereichen basiert. Der Dienst betreut mehr als 20 Maschinen, aber das ist zu viel; wir planen, die zugewiesenen Ressourcen zu reduzieren, da 4-5 Maschinen ausreichend Kapazitäten bieten.
Der Session-Dienst ist unser erster Dienst auf vshard und Cartridge. Die Einrichtung von vshard und das Update von Cartridge erforderten einen gewissen Arbeitsaufwand, aber letztendlich hat alles gut geklappt.
Der Dienst zur Anzeige verschiedener Banner auf der Website und in der mobilen Anwendung gehörte zu den ersten, die sofort auf Tarantool veröffentlicht wurden. Dieser Dienst ist bemerkenswert, da er etwa 6-7 Jahre alt ist, immer noch in Betrieb ist und noch nie neu gestartet wurde. Es wurde eine Master-Master-Replikation verwendet. Es ist nie etwas kaputt gegangen.
Es gibt ein Beispiel für die Verwendung von Tarantool zur Funktionalität schneller Nachschlagewerke in einem Lagersystem, um Informationen in bestimmten Fällen schnell zu überprüfen. Wir haben versucht, dafür Redis zu verwenden, aber die Datenschichtung im Speicher nahm mehr Platz ein als bei Tarantool.
Die Dienste für Wartelisten, Kundenabonnements, die derzeit beliebten Stories und vorgemerkte Produkte funktionieren ebenfalls mit Tarantool. Der letzte Dienst benötigt im Speicher etwa 120 GB. Dies ist der größte Dienst aus den oben genannten.
Fazit
Dank der sekundären Indizes in Kombination mit Key-Value und Transaktionsfähigkeit eignet sich Tarantool hervorragend für architektonische Lösungen basierend auf Microservices. Wir hatten jedoch Schwierigkeiten beim Einspielen von Änderungen in Dienste mit viel Logik in Lua – die Dienste hörten oft auf zu funktionieren. Das haben wir nicht überwunden, und im Laufe der Zeit sind wir zu verschiedenen Kombinationen von Lua und Go gekommen: Wir wissen, wann wir die eine Sprache und wann wir die andere nutzen sollten.
Weitere Lesetipps zu diesem Thema
- Wir erstellen von Grund auf eine hochbelastete Anwendung auf Tarantool
- Zuverlässige Wahl des Marktführers in Tarantool Cartridge
- Telegram-Kanal Tarantool mit Produktneuigkeiten
- Diskutieren Sie Tarantool im Community-Chat
Quelle: habr.com
