

Ich kenne viele Data Scientists – ich zähle mich wahrscheinlich auch dazu – die mit GPU-Maschinen arbeiten, sei es lokal oder virtuell in der Cloud, entweder über Jupyter Notebook oder in einer Python-Entwicklungsumgebung. In meinen 2 Jahren als AI/ML-Entwickler habe ich genau so gearbeitet, wobei ich die Daten auf einem normalen Server oder einer Workstation aufbereitet habe und das Training auf einer virtuellen Maschine mit GPU in Azure ausgeführt habe.
Natürlich haben wir alle von gehört – einer speziellen Cloud-Plattform für maschinelles Lernen. Nach dem ersten Blick auf die hat man jedoch den Eindruck, dass Azure ML Ihnen mehr Probleme bereiten wird, als es löst. Zum Beispiel wird im oben genannten Trainingsbeispiel das Training in Azure ML aus Jupyter Notebook gestartet, wobei das eigentliche Skript als Textdatei in einer der Zellen erstellt und bearbeitet werden soll – dabei wird auf Funktionen wie Autovervollständigung, Syntax-Highlighting und andere Vorteile einer normalen Entwicklungsumgebung verzichtet. Aus diesem Grund haben wir Azure ML lange Zeit nicht ernsthaft in unserer Arbeit eingesetzt.
Ich habe kürzlich eine Möglichkeit entdeckt, wie ich Azure ML effektiv in meiner Arbeit nutzen kann! Interessiert an den Details?

Das Hauptgeheimnis ist . Sie ermöglicht es Ihnen, Trainingsskripte direkt in VS Code zu entwickeln und dabei alle Vorteile der Umgebung zu nutzen – Sie können das Skript sogar lokal ausführen und es dann mit nur wenigen Klicks für das Training in den Azure ML Cluster senden. Praktisch, oder?
Durch die Nutzung von Azure ML profitieren Sie von folgenden Vorteilen:
- Sie können die meiste Zeit lokal auf Ihrem eigenen Rechner in einer komfortablen IDE arbeiten und GPU nur zum Trainieren des Modells nutzen. Dabei kann sich der Pool an Trainingsressourcen automatisch an die erforderliche Last anpassen, und durch das Einstellen der minimalen Anzahl an Knoten auf 0 können Sie die virtuelle Maschine "nach Bedarf" starten, wenn Trainingsaufgaben anstehen.
- können Sie alle Trainingsergebnisse an einem Ort speichern, einschließlich der erreichten Metriken und der erhaltenen Modelle – es ist keine eigene Systematik oder Ordnung für die Speicherung aller Ergebnisse erforderlich.
- Dabei An einem Projekt können mehrere Personen arbeiten — sie können denselben Rechencluster nutzen, alle Experimente werden dabei in eine Warteschlange eingereiht, und sie können die Ergebnisse ihrer Experimente untereinander einsehen. Ein solches Szenario ist die Nutzung von Azure ML im Unterricht über Deep Learning, wenn Sie anstelle von virtuellen Maschinen mit GPU für jeden Studenten einen zentralen Cluster erstellen, der von allen genutzt werden kann. Zudem kann eine gemeinsame Ergebnistabelle mit der Modellgenauigkeit einen guten Wettbewerbsaspekt darstellen.
- Mit Azure ML können Sie problemlos eine Reihe von Experimenten durchführen, beispielsweise zur Optimierung von Hyperparametern — das kann mit nur wenigen Codezeilen erfolgen, sodass Sie keine Serien von Experimenten manuell durchführen müssen.
Ich hoffe, ich konnte Sie überzeugen, Azure ML auszuprobieren! So können Sie starten:
- Stellen Sie sicher, dass Sie installiert haben, sowie die Erweiterungen und
- Klone das Repository — es enthält einen Beispielcode zur Schulung eines Modells zur Erkennung handgeschriebener Ziffern mit dem MNIST-Datensatz.
- Öffnen Sie das geklonte Repository in Visual Studio Code.
- Lesen Sie weiter!
Azure ML-Arbeitsbereich und Azure ML-Portal
Azure ML basiert auf dem Konzept eines Arbeitsbereichs — Workspace. Im Arbeitsbereich können Daten gespeichert werden, Experimente zur Schulung werden hier eingereicht, sowie die Ergebnisse des Trainings – die ermittelten Metriken und Modelle. Um zu sehen, was sich im Arbeitsbereich befindet, können Sie den aufrufen – und von dort aus können zahlreiche Operationen durchgeführt werden, von der Datenverarbeitung bis hin zur Überwachung von Experimenten und dem Deployment von Modellen.
Einen Arbeitsbereich können Sie über die Web-Oberfläche erstellen (siehe ), oder mithilfe der Azure CLI ():
az extension add -n azure-cli-ml
az group create -n meineazml -l nordeuropa
az ml workspace create -w meinarbeitsbereich -g meineazmlEinige Rechenressourcen (Compute). Nachdem Sie ein Skript zum Training eines Modells erstellt haben, können Sie das Experiment zur Ausführung im Arbeitsbereich senden und das Compute-Ziel angeben – dabei wird das Skript gepackt, in der benötigten Rechenumgebung gestartet, und alle Ergebnisse des Experiments werden im Arbeitsbereich für weitere Analysen und Nutzung gespeichert.
Trainingsszenario für MNIST
Betrachten wir das klassische Problem unter Verwendung des MNIST-Datensatzes. Ebenso können Sie später Ihre eigenen Trainingsskripte ausführen.
In unserem Repository finden Sie ein Skript train_local.py, das ein einfaches Modell der linearen Regression mit der SkLearn-Bibliothek trainiert. Natürlich verstehe ich, dass dies nicht der beste Weg ist, um das Problem zu lösen — wir verwenden es nur als Beispiel, weil es am einfachsten ist.
Das Skript lädt zunächst die MNIST-Daten von OpenML herunter und verwendet dann die Klasse LogisticRegression , um das Modell zu trainieren, und druckt anschließend die erreichte Genauigkeit:
mnist = fetch_openml('mnist_784')
mnist['target'] = np.array([int(x) for x in mnist['target']])
shuffle_index = np.random.permutation(len(mnist['data']))
X, y = mnist['data'][shuffle_index], mnist['target'][shuffle_index]
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size = 0.3, random_state = 42)
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_hat = lr.predict(X_test)
acc = np.average(np.int32(y_hat == y_test))
print('Gesamtgenauigkeit:', acc)Sie können das Skript auf Ihrem Computer ausführen und innerhalb von Sekunden ein Ergebnis erhalten.
Das Skript in Azure ML ausführen
Wenn wir das Trainingsskript über Azure ML ausführen, haben wir zwei Hauptvorteile:
- Starten Sie das Training auf einer leistungsfähigeren Rechenressource als auf einem lokalen Computer. Azure ML kümmert sich dabei automatisch um das Verpacken unseres Skripts mit allen Dateien aus dem aktuellen Verzeichnis in einen Docker-Container, installiert die erforderlichen Abhängigkeiten und sendet es zur Ausführung.
- Aufzeichnung der Ergebnisse in ein zentrales Register innerhalb des Azure ML-Arbeitsbereichs. Um diese Funktion zu nutzen, müssen wir ein paar Zeilen Code zu unserem Skript hinzufügen, um die resultierende Genauigkeit aufzuzeichnen:
from azureml.core.run import Run
...
try:
run = Run.get_submitted_run()
run.log('accuracy', acc)
except:
passDie entsprechende Version des Skripts wird bezeichnet als train_universal.py (es ist etwas komplexer strukturiert als oben beschrieben, aber nicht wesentlich). Dieses Skript kann sowohl lokal als auch auf einer entfernten Rechenressource ausgeführt werden.
Um es in Azure ML aus VS Code auszuführen, gehen Sie folgendermaßen vor:
Stellen Sie sicher, dass die Azure-Erweiterung mit Ihrem Abonnement verbunden ist. Wählen Sie das Azure-Symbol im linken Menü. Wenn Sie nicht verbunden sind, wird in der unteren rechten Ecke eine Benachrichtigung angezeigt (), auf die Sie klicken können, um sich über den Browser anzumelden. Alternativ können Sie auch drücken Ctrl-Shift-P Um die Kommandozeile von VS Code aufzurufen, geben Sie ein Azure Sign In.
Anschließend finden Sie im Abschnitt Azure (Symbol links) den Bereich MASCHINENLERNEN:
Hier sollten Sie verschiedene Objektgruppen innerhalb des Arbeitsbereichs sehen: Rechenressourcen, Experimente usw.
- Gehen Sie zur Dateiliste, klicken Sie mit der rechten Maustaste auf das Skript
train_universal.pyund wählen Sie Azure ML: Als Experiment in Azure ausführen.
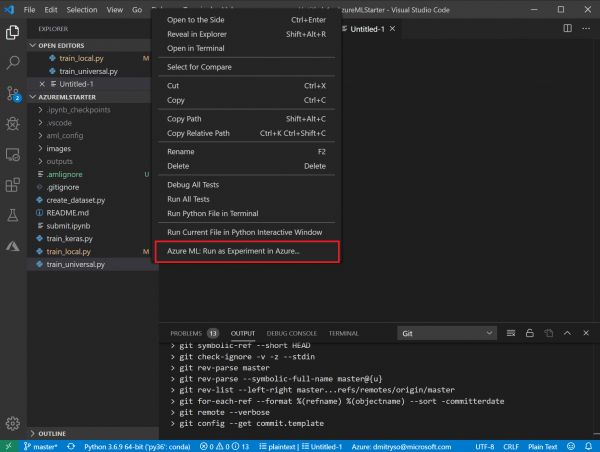
- Es folgt eine Reihe von Dialogen in der Kommandozeile von VS Code: Bestätigen Sie das verwendete Abonnement und den Azure ML-Arbeitsbereich und wählen Sie Neues Experiment erstellen:



Wählen Sie die Erstellung neuer Rechenressourcen Neue Rechenressource erstellen:
- Compute bestimmt die Rechenressource, auf der das Training stattfinden soll. Sie können entweder einen lokalen Computer oder einen AmlCompute-Cloud-Cluster wählen. Ich empfehle, einen skalierbaren Maschinencluster zu erstellen
STANDARD_DS3_v2, mit einer minimalen Anzahl von Maschinen 0 (maximal können es 1 oder mehr sein, je nach Ihren Bedürfnissen). Dies kann über die VS Code-Oberfläche oder zuvor über .

- Compute bestimmt die Rechenressource, auf der das Training stattfinden soll. Sie können entweder einen lokalen Computer oder einen AmlCompute-Cloud-Cluster wählen. Ich empfehle, einen skalierbaren Maschinencluster zu erstellen
Als nächstes müssen Sie die Konfiguration auswählen Rechenkonfiguration, das die Parameter des zu erstellenden Trainingscontainers definiert, insbesondere alle erforderlichen Bibliotheken. In unserem Fall wählen wir, da wir Scikit Learn verwenden, SkLearn, und bestätigen dann einfach die vorgeschlagene Liste der Bibliotheken mit der Eingabetaste. Wenn Sie zusätzliche Bibliotheken verwenden, müssen diese hier angegeben werden.


Nach diesem Schritt öffnet sich ein Fenster mit einer JSON-Datei, die das Experiment beschreibt. Dort können einige Parameter geändert werden, beispielsweise der Name des Experiments. Danach klicken Sie auf den Link Experiment einreichen , direkt innerhalb dieser Datei:


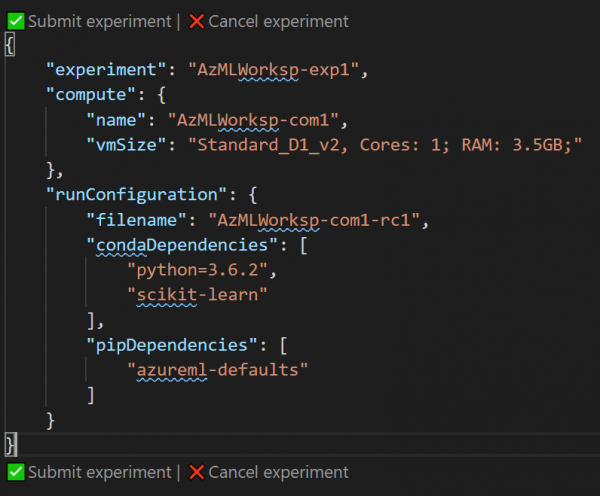
- Nach erfolgreicher Einreichung des Experiments über VS Code sehen Sie rechts im Benachrichtigungsbereich einen Link zu , wo Sie den Status und die Ergebnisse des Experiments verfolgen können.
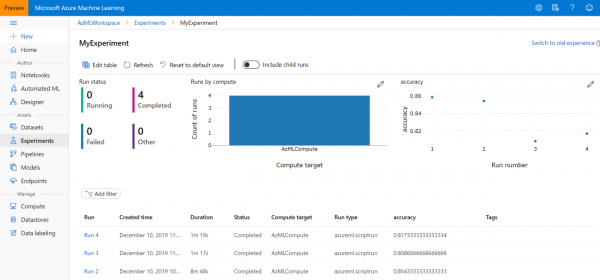
Später finden Sie es jederzeit im Abschnitt Experimente , oder im Abschnitt Azure Machine Learning in der Liste der Experimente:
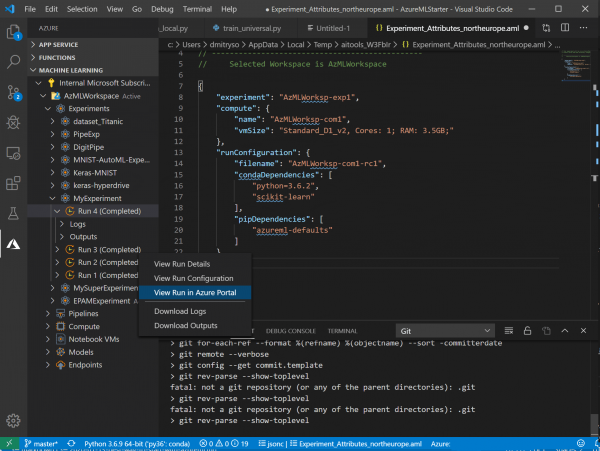
- Wenn Sie nachträglich Änderungen im Code vorgenommen oder Parameter verändert haben, wird der erneute Start des Experiments viel schneller und einfacher sein. Wenn Sie mit der rechten Maustaste auf die Datei klicken, sehen Sie den neuen Menüpunkt Letzten Lauf wiederholen – wählen Sie einfach diesen aus, und das Experiment wird sofort gestartet:
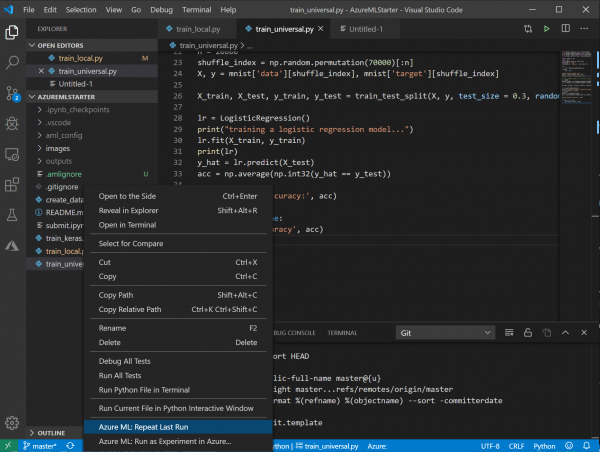
Die Ergebnisse der Metriken aus allen Durchläufen finden Sie jederzeit im Azure ML Portal, eine Notierung ist nicht erforderlich.
Jetzt wissen Sie, dass es einfach und schmerzfrei ist, Experimente mit Azure ML durchzuführen, und dabei erhalten Sie eine Reihe angenehmer Vorteile.
Sie könnten jedoch auch Nachteile bemerkt haben. Zum Beispiel benötigte das Ausführen des Skripts erheblich mehr Zeit. Natürlich braucht es Zeit, das Skript in einen Container zu verpacken und auf dem Server bereitzustellen. Wenn der Cluster zudem auf 0 Knoten reduziert wurde, verlängert sich die Zeit zum Starten der virtuellen Maschine, und das wird besonders deutlich, wenn wir mit einfachen Aufgaben wie MNIST experimentieren, die in wenigen Sekunden gelöst werden. In der realen Welt, wenn das Training Stunden, Tage oder sogar Wochen dauert, wird diese zusätzliche Zeit jedoch irrelevant, insbesondere angesichts der erheblich höheren Leistung, die ein Rechencluster bieten kann.
Wie geht es weiter?
Ich hoffe, dass Sie nach dem Lesen dieses Artikels in der Lage sein werden, Azure ML in Ihrer Arbeit zu nutzen, um Skripte auszuführen, Rechenressourcen zu verwalten und Ergebnisse zentral zu speichern. Doch Azure ML kann Ihnen noch größere Vorteile bieten!
Innerhalb des Arbeitsbereichs können Sie Daten speichern und so ein zentrales Repository für all Ihre Aufgaben schaffen, auf das Sie leicht zugreifen können. Darüber hinaus können Sie Experimente nicht nur aus Visual Studio Code, sondern auch über die API ausführen — dies kann besonders nützlich sein, wenn Sie Hyperparameter optimieren müssen und das Skript mehrfach mit unterschiedlichen Parametern ausführen wollen. Außerdem verfügt Azure ML über eine spezielle Technologie , die eine raffiniertere Suche und Optimierung von Hyperparametern ermöglicht. Über diese Möglichkeiten werde ich in meinem nächsten Beitrag berichten.
Nützliche Ressourcen
Für eine vertiefte Auseinandersetzung mit Azure ML können Ihnen die folgenden Kurse von Microsoft Learn hilfreich sein:
Quelle: habr.com
