

JPEG-Bilder sind in unserem digitalen Leben allgegenwärtig, doch hinter diesem Schleier des Bewusstseins verbergen sich Algorithmen, die Details entfernen, die das menschliche Auge nicht sehen kann. Das Ergebnis ist höchste visuelle Qualität bei kleinster Dateigröße – doch wie genau funktioniert das Ganze? Mal sehen, was genau unsere Augen nicht sehen!

Es ist leicht, die Möglichkeit, einem Freund ein Foto zu senden, als selbstverständlich anzusehen, ohne sich Gedanken darüber zu machen, welches Gerät, welchen Browser oder welches Betriebssystem er verwendet – aber das war nicht immer so. In den frühen 1980er Jahren konnten Computer digitale Bilder speichern und anzeigen, doch es gab viele konkurrierende Vorstellungen darüber, wie dies am besten zu bewerkstelligen sei. Sie können nicht einfach ein Bild von einem Computer an einen anderen senden und hoffen, dass es funktioniert.
Um dieses Problem zu lösen, wurde 1986 ein Expertengremium aus aller Welt unter dem Namen „” (Joint Photographic Experts Group, JPEG), gegründet als Teil der gemeinsamen Arbeit der International Organization for Standardization (ISO) und der International Electrotechnical Commission (IEC), zwei internationalen Normungsorganisationen mit Sitz in Genf (Schweiz).
Eine Gruppe von Leuten namens JPEG schuf 1992 den JPEG-Standard für die digitale Bildkomprimierung. Jeder, der das Internet genutzt hat, ist wahrscheinlich auf JPEG-kodierte Bilder gestoßen. Dies ist die gebräuchlichste Methode zum Kodieren, Senden und Speichern von Bildern. Von Webseiten über E-Mails bis hin zu sozialen Medien wird JPEG täglich milliardenfach verwendet – fast jedes Mal, wenn wir ein Bild online ansehen oder versenden. Ohne JPEGs wäre das Internet weniger hell, langsamer und hätte wahrscheinlich weniger Katzenbilder!
In diesem Artikel geht es darum, wie man ein JPEG-Bild dekodiert. Mit anderen Worten, was erforderlich ist, um komprimierte Daten, die auf einem Computer gespeichert sind, in ein Bild umzuwandeln, das auf dem Bildschirm erscheint. Das ist wissenswert, nicht nur, weil es für das Verständnis der Technologie, die wir täglich verwenden, wichtig ist, sondern auch, weil wir durch die Offenlegung der Komprimierungsgrade die Wahrnehmung und das Sehen sowie die Details, die unsere Augen am meisten erfassen, besser kennen empfindlich gegenüber.
Außerdem ist es sehr interessant, auf diese Weise mit Bildern zu spielen.

Blick in ein JPEG
Auf einem Computer wird alles als Folge binärer Zahlen gespeichert. Normalerweise sind diese Bits, Nullen und Einsen, in Achtern gruppiert und bilden Bytes. Wenn Sie ein JPEG-Bild auf Ihrem Computer öffnen, muss etwas (Browser, Betriebssystem, was auch immer) die Bytes dekodieren und das Originalbild als Liste anzeigbarer Farben wiederherstellen.
Wenn Sie dieses süße herunterladen und öffnen Sie es in einem Texteditor. Sie werden eine Menge durcheinandergebrachter Zeichen sehen.

Hier verwende ich Notepad++, um den Dateiinhalt zu untersuchen, da herkömmliche Texteditoren wie Notepad nicht ausreichen. WindowsDadurch wird die Binärdatei nach dem Speichern beschädigt und entspricht nicht mehr dem JPEG-Format.
Das Öffnen eines Bildes in einem Texteditor verwirrt Ihren Computer, genauso wie Sie Ihr Gehirn verwirren, wenn Sie sich die Augen reiben und farbige Flecken sehen!
Diese Stellen, die Sie sehen, werden als bezeichnet und sind nicht das Ergebnis der Einwirkung eines Lichtreizes oder von Halluzinationen, die vom Geist erzeugt werden. Sie entstehen, weil Ihr Gehirn davon ausgeht, dass alle elektrischen Signale in den Sehnerven Informationen über Licht übertragen. Das Gehirn muss solche Annahmen treffen, denn es gibt keine Möglichkeit zu wissen, ob es sich bei dem Signal um einen Ton, eine Vision oder etwas anderes handelt. Alle Nerven im Körper übertragen exakt die gleichen elektrischen Impulse. Wenn Sie Druck auf Ihre Augen ausüben, senden Sie Signale, die nicht visuell sind, sondern Rezeptoren im Auge aktivieren, die Ihr Gehirn – in diesem Fall fälschlicherweise – als etwas Visuelles interpretiert. Man kann den Druck förmlich sehen!
Es ist lustig, darüber nachzudenken, wie ähnlich Computer dem Gehirn sind, aber es ist auch eine nützliche Analogie, die zeigt, wie sehr die Bedeutung von Daten – ob sie über Nerven durch den Körper transportiert oder in einem Computer gespeichert werden – davon abhängt, wie sie interpretiert werden. Alle Binärdaten bestehen aus Nullen und Einsen, Grundbestandteilen, die jede Art von Information übermitteln können. Ihr Computer errät oft anhand von Hinweisen wie Dateierweiterungen, wie sie zu interpretieren sind. Jetzt lassen wir sie als Text interpretieren, denn das erwartet der Texteditor.
Um zu verstehen, wie man ein JPEG dekodiert, müssen wir die Originalsignale selbst sehen – die Binärdaten. Dies kann mit einem Hex-Editor oder direkt erfolgen ! Es gibt ein Bild, neben dem im Textfeld alle seine Bytes (außer der Kopfzeile) in Dezimalform dargestellt werden. Sie können sie ändern und das Skript wird im Handumdrehen neu codieren und ein neues Bild erstellen.

Sie können viel lernen, indem Sie einfach mit diesem Editor herumspielen. Können Sie beispielsweise erkennen, in welcher Reihenfolge die Pixel gespeichert sind?
Das Merkwürdige an diesem Beispiel ist, dass sich die Änderung einiger Zahlen überhaupt nicht auf das Bild auswirkt. Wenn Sie beispielsweise in der ersten Zeile die Zahl 17 durch 0 ersetzen, wird das Foto völlig ruiniert!

Andere Änderungen, beispielsweise die Änderung der 7 in Zeile 1988 in 254, ändern die Farbe, jedoch nur die nachfolgenden Pixel.

Das Seltsamste ist vielleicht, dass einige Zahlen nicht nur die Farbe, sondern auch die Form des Bildes ändern. Ändern Sie 70 in Zeile 12 in 2 und schauen Sie sich die obere Zeile des Bildes an, um zu sehen, was ich meine.

Und egal welches JPEG-Bild Sie verwenden, beim Bearbeiten von Bytes werden Sie immer auf diese kryptischen Schachmuster stoßen.
Wenn man mit dem Editor experimentiert, ist es schwer herauszufinden, wie man aus diesen Bytes ein Foto neu erstellen kann, da die JPEG-Komprimierung aus drei verschiedenen Technologien besteht, die nacheinander in Stufen angewendet werden. Wir werden jeden von ihnen einzeln untersuchen, um das mysteriöse Verhalten aufzudecken, das wir beobachten.
Drei Ebenen der JPEG-Komprimierung:
- .
- .
- , и
Um Ihnen eine Vorstellung vom Ausmaß der Komprimierung zu geben, beachten Sie, dass das obige Bild 79 Zahlen darstellt, was etwa 819 KB entspricht. Würden wir es ohne Komprimierung speichern, bräuchten wir für jedes Pixel drei Zahlen – für den Rot-, Grün- und Blauanteil. Das wären 79 Nummern, also ca. 917 KB. Durch die JPEG-Komprimierung ist die endgültige Dateigröße um mehr als das Zehnfache geschrumpft!
Tatsächlich kann dieses Bild viel stärker komprimiert werden. Unten sind zwei Bilder nebeneinander – das Foto rechts wurde auf 16 KB komprimiert, also 57-mal weniger als die unkomprimierte Version!

Wenn Sie genau hinschauen, werden Sie feststellen, dass diese Bilder nicht identisch sind. Bei beiden handelt es sich um Bilder mit JPEG-Komprimierung, das rechte ist jedoch deutlich kleiner im Volumen. Es sieht auch etwas schlechter aus (siehe Hintergrundfarbquadrate). Daher wird JPEG auch als verlustbehaftete Komprimierung bezeichnet; Während des Komprimierungsvorgangs verändert sich das Bild und es gehen einige Details verloren.
1. Farbunterabtastung
Hier ist ein Bild, bei dem nur die erste Komprimierungsstufe angewendet wurde.

(Interaktive Version in Artikel). Das Entfernen einer Zahl zerstört alle Farben. Wenn jedoch genau sechs Zahlen entfernt werden, hat dies kaum oder gar keine Auswirkungen auf das Bild.
Jetzt sind die Zahlen etwas einfacher zu entziffern. Dies ist fast eine einfache Liste von Farben, jedes Byte ändert genau ein Pixel, aber es ist bereits halb so groß wie ein unkomprimiertes Bild (das in einer so reduzierten Größe ca. 300 KB beanspruchen würde). Rate mal, warum?
Sie können sehen, dass diese Zahlen nicht die Standardkomponenten Rot, Grün und Blau darstellen, denn wenn wir alle Zahlen durch Nullen ersetzen, erhalten wir ein grünes Bild (kein weißes).

Dies liegt daran, dass diese Bytes für Y (Helligkeit) stehen.

Cb (relatives Blau),

und Cr-Bilder (relative Rötung).

Warum nicht RGB verwenden? Schließlich funktionieren die meisten modernen Bildschirme so. Ihr Monitor kann jede Farbe, einschließlich Rot, Grün und Blau, in unterschiedlichen Intensitäten für jedes Pixel anzeigen. Weiß erhält man, indem man alle drei mit voller Helligkeit einschaltet, und Schwarz, indem man sie ausschaltet.
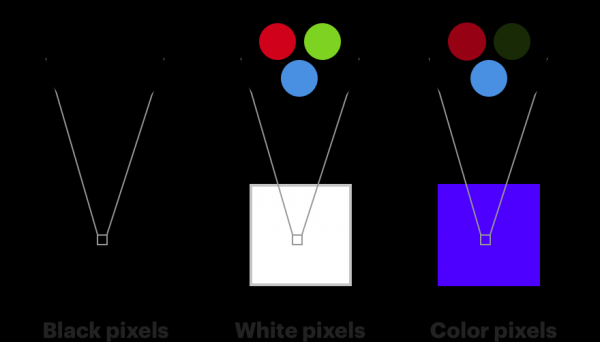
Es ist auch der Funktionsweise des menschlichen Auges sehr ähnlich. Die Farbrezeptoren in unseren Augen heißen „„und sind in drei Typen unterteilt, von denen jeder empfindlicher auf entweder rote, grüne oder blaue Farben reagiert [Zapfen vom Typ S reagieren empfindlich auf Violett-Blau (S aus dem Englischen. Kurz – kurzwelliges Spektrum), M-Typ - in grün-gelben (M aus dem Englischen. Medium - Mittelwelle) und L-Typ - in gelb-roten (L aus dem Englischen. Long - langwelligen) Teilen des Spektrums. Das Vorhandensein dieser drei Arten von Zapfen (und Stäbchen, die im smaragdgrünen Teil des Spektrums empfindlich sind) verleiht einem Menschen Farbsehen. / ca. übersetzt]. , der andere Photorezeptortyp in unseren Augen, kann Helligkeitsänderungen erkennen, reagiert jedoch viel empfindlicher auf Farben. Unsere Augen haben etwa 120 Millionen Stäbchen und nur 6 Millionen Zapfen.
Deshalb nehmen unsere Augen Veränderungen in der Helligkeit viel besser wahr als Veränderungen in der Farbe. Wenn Sie die Farbe von der Helligkeit trennen, können Sie ein wenig Farbe entfernen, und niemand wird etwas bemerken. Bei der Chroma-Unterabtastung werden die Farbkomponenten eines Bildes mit einer niedrigeren Auflösung als die Luminanzkomponenten dargestellt. Im obigen Beispiel hat jedes Pixel genau eine Y-Komponente und jede einzelne Gruppe von vier Pixeln hat genau eine Cb- und eine Cr-Komponente. Daher enthält das Bild viermal weniger Farbinformationen als das Original.
Der YCbCr-Farbraum wird nicht nur in JPEGs verwendet. Es wurde ursprünglich 1938 für Fernsehübertragungen erfunden. Nicht jeder verfügt über einen Farbfernseher. Durch die Trennung von Farbe und Helligkeit konnte jeder das gleiche Signal empfangen, und Fernseher ohne Farbe nutzten nur die Helligkeitskomponente.
Daher werden durch das Entfernen einer Zahl aus dem Editor alle Farben vollständig zerstört. Die Komponenten werden in der Form YYYY Cb Cr gespeichert (eigentlich nicht unbedingt in dieser Reihenfolge – die Speicherreihenfolge wird im Dateikopf angegeben). Das Entfernen der ersten Zahl führt dazu, dass der erste Wert von Cb als Y und Cr als Cb wahrgenommen wird, und im Allgemeinen wird ein Dominoeffekt erzielt, der alle Farben des Bildes vertauscht.
Die JPEG-Spezifikation erfordert nicht die Verwendung von YCbCr. Aber die meisten Dateien verwenden es, weil es nach dem Downsampling im Vergleich zu RGB eine bessere Bildqualität liefert. Aber Sie müssen sich nicht auf mein Wort verlassen. Sehen Sie selbst in der Tabelle unten, wie die Unterabtastung jeder einzelnen Komponente sowohl in RGB als auch in YCbCr aussehen würde.

(Interaktive Version in Artikel).
Die Entfernung von Blau ist nicht so auffällig wie bei Rot oder Grün. Das liegt an den sechs Millionen Zapfen in Ihren Augen. Etwa 64 % reagieren empfindlich auf Rot, 32 % auf Grün und 2 % auf Blau.
Am besten ist die Unterabtastung der Y-Komponente (unten links) zu erkennen. Schon eine kleine Veränderung macht sich bemerkbar.
Durch das Konvertieren eines Bilds von RGB in YCbCr wird die Dateigröße nicht verringert, aber es erleichtert das Auffinden weniger auffälliger Details, die entfernt werden können. In der zweiten Stufe erfolgt die verlustbehaftete Komprimierung. Es basiert auf der Idee, Daten in einer komprimierbareren Form darzustellen.
2. Diskrete Kosinustransformation und Diskretisierung
Diese Komprimierungsstufe definiert größtenteils das Wesen von JPEG. Nach der Konvertierung der Farben in YCbCr werden die Komponenten einzeln komprimiert, sodass wir uns von nun an nur noch auf die Y-Komponente konzentrieren können. Und so sehen die Bytes der Y-Komponente nach Anwendung dieser Ebene aus.
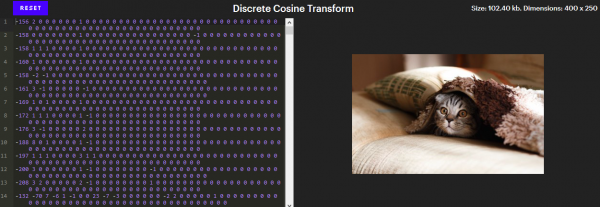
(Interaktive Version in Artikel). In der interaktiven Version scrollt der Editor durch Klicken auf ein Pixel zu der Zeile, die es darstellt. Versuchen Sie, Zahlen am Ende zu entfernen oder ein paar Nullen zu einer bestimmten Zahl hinzuzufügen.
Auf den ersten Blick sieht es nach einer sehr schlechten Komprimierung aus. Es gibt 100 Pixel in einem Bild, und es braucht 000 Zahlen, um ihre Helligkeit (Y-Komponenten) anzugeben – das ist schlimmer, als überhaupt nichts zu komprimieren!
Beachten Sie jedoch, dass die meisten dieser Zahlen Null sind. Darüber hinaus können alle diese Nullen am Ende der Zeilen entfernt werden, ohne das Bild zu verändern. Es sind noch etwa 26 Nummern übrig, also fast viermal weniger!
Dieses Level enthält das Geheimnis der Schachmuster. Im Gegensatz zu anderen Effekten, die wir gesehen haben, ist das Auftreten dieser Muster kein Fehler. Sie sind die Bausteine des Gesamtbildes. Jede Zeile des Editors enthält genau 64 Zahlen, Koeffizienten der diskreten Kosinustransformation (DCT), die den Intensitäten von 64 einzigartigen Mustern entsprechen.
Diese Muster werden basierend auf dem Kosinusdiagramm gebildet. So sehen einige davon aus:

8 von 64 Quoten
Unten sehen Sie ein Bild, das alle 64 Muster zeigt.
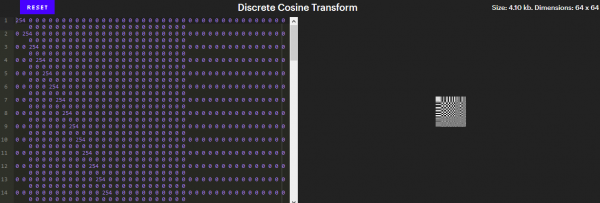
(Interaktive Version in Artikel).
Diese Muster sind von besonderer Bedeutung, da sie die Grundlage der 8x8-Bilder bilden. Wenn Sie mit linearer Algebra nicht vertraut sind, bedeutet dies, dass aus diesen 8 Mustern jedes 8x64-Bild erhalten werden kann. Bei der DCT werden Bilder in 8x8-Blöcke aufgeteilt und jeder Block in eine Kombination dieser 64 Koeffizienten umgewandelt.
Die Tatsache, dass jedes Bild aus 64 spezifischen Mustern bestehen kann, scheint magisch. Dies ist jedoch dasselbe, als würde man sagen, dass jeder Ort auf der Erde durch zwei Zahlen beschrieben werden kann – Breitengrad und Längengrad [die Hemisphären angeben / ca. übersetzt]. Wir stellen uns die Erdoberfläche oft als zweidimensional vor, daher brauchen wir nur zwei Zahlen. Ein 8x8-Bild hat 64 Dimensionen, wir brauchen also 64 Zahlen.
Es ist noch nicht klar, wie uns dies in Bezug auf die Komprimierung hilft. Wenn wir 64 Zahlen benötigen, um ein 8x8-Bild darzustellen, warum sollte dies dann besser sein, als nur 64 Luminanzkomponenten zu speichern? Wir tun dies aus demselben Grund, aus dem wir drei RGB-Zahlen in drei YCbCr-Zahlen umgewandelt haben: Dadurch können wir subtile Details entfernen.
Es ist schwer zu erkennen, welche Details zu diesem Zeitpunkt genau entfernt werden, da JPEG DCT auf 8x8-Blöcke anwendet. Allerdings verbietet uns niemand, es auf das Gesamtbild anzuwenden. So sieht die DCT für die Y-Komponente aus, wenn sie auf das gesamte Bild angewendet wird:

Mehr als 60 Zahlen können am Ende entfernt werden, ohne dass sich im Foto erkennbare Veränderungen ergeben.

Beachten Sie jedoch, dass der Unterschied offensichtlich ist, wenn wir die ersten fünf Zahlen auf Null setzen.

Die Zahlen am Anfang stellen niederfrequente Veränderungen im Bild dar und werden von unserem Auge am besten wahrgenommen. Zahlen gegen Ende weisen auf hochfrequente Veränderungen hin, die schwerer zu bemerken sind. Um „zu sehen, was das Auge nicht sehen kann“, können wir diese hochfrequenten Details isolieren, indem wir die ersten 5000 Zahlen auf Null setzen.

Wir sehen alle Bereiche des Bildes, in denen von Pixel zu Pixel die größte Veränderung auftritt. Hervorzuheben sind die Augen der Katze, ihr Schnurrbart, die Frotteedecke und die Schatten in der unteren linken Ecke. Sie können noch weiter gehen, indem Sie die ersten 10 Zahlen auf Null setzen:

20 000:

40 000:

60 000:

Diese hochfrequenten Details werden von JPEG während der Komprimierungsphase entfernt. Die Konvertierung von Farben in DCT-Koeffizienten erfolgt verlustfrei. Verluste entstehen im Sampling-Schritt, bei dem Werte mit hoher Frequenz oder nahe Null entfernt werden. Wenn Sie die Qualität der JPEG-Speicherung verringern, erhöht das Programm den Schwellenwert für die Anzahl der zu entfernenden Werte, wodurch sich die Dateigröße verringert, das Bild jedoch pixeliger wird. Das Bild im ersten Abschnitt, das 57-mal kleiner war, sah also so aus. Jeder 8x8-Block repräsentierte eine viel kleinere Anzahl von DCT-Koeffizienten im Vergleich zur Version mit höherer Qualität.
Sie können etwas so Cooles tun wie das schrittweise Streamen von Bildern. Sie können ein verschwommenes Bild anzeigen, das immer detaillierter wird, je mehr Koeffizienten heruntergeladen werden.
Hier, nur zum Spaß, was passiert, wenn nur 24 Zahlen verwendet werden:

Oder einfach 5000:

Sehr verschwommen, aber erkennbar!
3. Codierung von Lauflängen, Delta und Huffman
Bisher waren alle Komprimierungsstufen verlustbehaftet. Die letzte Stufe hingegen verläuft ohne Verlust. Es entfernt keine Informationen, reduziert jedoch die Dateigröße erheblich.
Wie kann man etwas komprimieren, ohne Informationen zu verwerfen? Stellen Sie sich vor, wie wir ein einfaches schwarzes Rechteck mit den Maßen 700 x 437 beschreiben würden.
JPEG verwendet hierfür 5000 Zahlen, es lassen sich jedoch deutlich bessere Ergebnisse erzielen. Können Sie sich ein Codierungsschema vorstellen, das ein solches Bild in möglichst wenigen Bytes beschreibt?
Das minimale Schema, das ich mir ausdenken könnte, verwendet vier: drei für die Farbe und ein viertes für die Anzahl der Pixel, die diese Farbe hat. Die Idee, wiederholte Werte auf eine solche komprimierte Weise darzustellen, wird als Lauflängencodierung bezeichnet. Es ist verlustfrei, da wir die codierten Daten in ihrer ursprünglichen Form wiederherstellen können.
Die Größe einer JPEG-Datei mit einem schwarzen Rechteck ist viel größer als 4 Bytes – denken Sie daran, dass auf der DCT-Ebene die Komprimierung auf Blöcke von 8x8 Pixeln angewendet wird. Daher benötigen wir mindestens einen DCT-Koeffizienten pro 64 Pixel. Wir brauchen einen, denn statt einen einzelnen DCT-Koeffizienten gefolgt von 63 Nullen zu speichern, ermöglicht uns die Lauflängenkodierung, eine einzelne Zahl zu speichern und anzugeben, „alle anderen sind Nullen“.
Bei der Delta-Kodierung handelt es sich um eine Technik, bei der jedes Byte eine Differenz zu einem bestimmten Wert und nicht einen absoluten Wert enthält. Daher ändert die Bearbeitung bestimmter Bytes die Farbe aller anderen Pixel. Zum Beispiel statt zu lagern
12 13 14 14 14 13 13 14
Wir könnten mit 12 beginnen und dann einfach aufschreiben, wie viel wir addieren oder subtrahieren müssen, um die nächste Zahl zu erhalten. Und diese Sequenz in der Delta-Codierung hat die Form:
12 1 1 0 0 -1 0 1
Die konvertierten Daten sind nicht kleiner als die Originaldaten, lassen sich aber leichter komprimieren. Die Anwendung der Delta-Kodierung vor der Lauflängenkodierung kann bei gleichzeitiger verlustfreier Komprimierung sehr hilfreich sein.
Die Delta-Kodierung ist eine der wenigen Techniken, die außerhalb von 8x8-Blöcken verwendet werden. Einer der 64 DCT-Koeffizienten ist einfach eine konstante Wellenfunktion (durchgezogene Farbe). Es stellt die durchschnittliche Helligkeit jedes Blocks für die Luminanzkomponenten oder die durchschnittliche Blauheit für die Cb-Komponenten usw. dar. Der erste Wert jedes DCT-Blocks wird als DC-Wert bezeichnet, und jeder DC-Wert ist in Bezug auf die vorherigen deltacodiert. Daher wirkt sich eine Änderung der Helligkeit des ersten Blocks auf alle Blöcke aus.
Das letzte Rätsel bleibt bestehen: Wie kann eine Änderung der Singularzahl das Gesamtbild völlig verderben? Bisher verfügten Komprimierungsstufen nicht über solche Eigenschaften. Die Antwort liegt im JPEG-Header. Die ersten 500 Bytes enthalten Metadaten über das Bild – Breite, Höhe usw., und bisher haben wir noch nicht damit gearbeitet.
Ohne Header ist es fast unmöglich (naja, sehr schwierig), ein JPEG zu dekodieren. Es wird so aussehen, als würde ich versuchen, Ihnen ein Bild zu beschreiben, und ich fange an, Worte zu erfinden, um meinen Eindruck zu vermitteln. Die Beschreibung wird wahrscheinlich sehr prägnant sein, da ich Wörter mit genau der Bedeutung erfinden kann, die ich vermitteln möchte, aber für alle anderen werden sie keinen Sinn ergeben.
Klingt albern, aber so passiert es. Jedes JPEG-Bild wird mit spezifischen Codes komprimiert. Das Codewörterbuch wird im Header gespeichert. Diese Technik wird „Huffman-Code“ genannt und das Wörterbuch heißt Huffman-Tabelle. Im Header ist die Tabelle mit zwei Bytes gekennzeichnet – 255 und dann 196. Jede Farbkomponente kann eine eigene Tabelle haben.
Tabellenänderungen wirken sich drastisch auf jedes Bild aus. Ein gutes Beispiel ist die Änderung von 15 in 1 in der 12. Zeile.

Denn die Tabellen legen fest, wie einzelne Bits gelesen werden sollen. Bisher haben wir nur mit Binärzahlen in Dezimalform gearbeitet. Dies verbirgt uns jedoch die Tatsache, dass, wenn Sie die Zahl 1 in einem Byte speichern möchten, diese wie 00000001 aussieht, da jedes Byte genau acht Bits haben muss, auch wenn nur eines davon benötigt wird.
Dies stellt möglicherweise eine große Platzverschwendung dar, wenn Sie viele kleine Zahlen haben. Der Huffman-Code ist eine Technik, die es uns ermöglicht, die Anforderung, dass jede Zahl acht Bits belegen muss, zu lockern. Das bedeutet, wenn Sie zwei Bytes sehen:
234 115
Dann können es je nach Huffman-Tabelle drei Zahlen sein. Um sie zu extrahieren, müssen Sie sie zunächst in einzelne Bits aufteilen:
11101010 01110011
Dann wenden wir uns der Tabelle zu, um zu verstehen, wie man sie gruppiert. Beispielsweise könnten es die ersten sechs Bits (111010) oder 58 in Dezimalzahl sein, gefolgt von fünf Bits (10011) oder 19 und schließlich die letzten vier Bits (0011) oder 3.
Daher ist es in dieser Komprimierungsstufe sehr schwierig, die Bytes zu verstehen. Die Bytes repräsentieren nicht das, was sie scheinen. Ich werde in diesem Artikel nicht näher auf die Arbeit mit der Tabelle eingehen, aber zu diesem Thema online .
Einer der coolen Tricks, die Sie mit diesem Wissen machen können, besteht darin, den Header vom JPEG zu trennen und separat zu speichern. Tatsächlich stellt sich heraus, dass nur Sie die Datei lesen können. Facebook tut dies, um die Dateien weiter zu reduzieren.
Was man sonst noch tun kann, ist, die Huffman-Tabelle erheblich zu verändern. Für andere wird es wie ein verdorbenes Bild aussehen. Und nur Sie kennen die magische Möglichkeit, das Problem zu beheben.
Zusammenfassend: Was wird also benötigt, um ein JPEG zu dekodieren? Notwendig:
- Extrahieren Sie die Huffman-Tabelle(n) aus dem Header und dekodieren Sie die Bits.
- Extrahieren Sie die Koeffizienten der diskreten Kosinustransformation für jede Farb- und Luminanzkomponente für jeden 8x8-Block, indem Sie Lauflängenkodierung und Delta invers transformieren.
- Kombinieren Sie Kosinuswerte basierend auf Koeffizienten, um Pixelwerte für jeden 8x8-Block zu erhalten.
- Farbkomponenten skalieren, wenn eine Unterabtastung durchgeführt wurde (diese Informationen finden Sie in der Kopfzeile).
- Konvertieren Sie die resultierenden YCbCr-Werte für jedes Pixel in RGB.
- Bringen Sie das Bild auf die Leinwand!
Schon allein das Betrachten eines Fotos mit einer Katze ist eine ernsthafte Arbeit! Was mir jedoch daran gefällt, ist, dass es zeigt, wie menschenzentriert die JPEG-Technologie ist. Es basiert auf den Merkmalen unserer Wahrnehmung, wodurch wir eine deutlich bessere Komprimierung als herkömmliche Technologien erreichen können. Wenn Sie nun verstehen, wie JPEG funktioniert, können Sie sich vorstellen, wie diese Technologien auf andere Bereiche übertragen werden können. Beispielsweise kann die Delta-Kodierung in Videos zu einer erheblichen Reduzierung der Dateigröße führen, da sich häufig ganze Bereiche von Bild zu Bild nicht ändern (z. B. der Hintergrund).
, ist geöffnet und enthält Anweisungen zum Ersetzen der Bilder durch Ihre eigenen.
Source: habr.com
