

Viele sind mit der Datenbank PostgreSQL vertraut, und sie hat sich bei kleinen Installationen hervorragend bewährt. Der Trend zur Nutzung von Open Source wird jedoch immer deutlicher, selbst bei großen Unternehmen und deren Anforderungen. In diesem Artikel erklären wir, wie man Postgres in eine Unternehmensumgebung integriert, und teilen unsere Erfahrungen beim Aufbau eines Backup-Systems (SRK) für diese Datenbank anhand des Beispiel-Backup-Systems Commvault.

PostgreSQL hat bereits ihre Leistungsfähigkeit bewiesen — die Datenbank funktioniert hervorragend, wird von angesagten digitalen Unternehmen wie Alibaba und TripAdvisor genutzt, und das Fehlen von Lizenzgebühren macht sie zu einer verlockenden Alternative zu Giganten wie MS SQL oder Oracle DB. Doch sobald wir über PostgreSQL im Unternehmenskontext nachdenken, stoßen wir sofort auf strenge Anforderungen: "Wie sieht es mit der Ausfallsicherheit der Konfiguration aus? Katastrophensicherheit? Wo bleibt das umfassende Monitoring? Und das automatisierte Backup? Wie steht es um den Einsatz von Bandbibliotheken, sowohl direkt als auch für sekundäre Speicherlösungen?"
Einerseits verfügt PostgreSQL nicht über die integrierten Backup-Tools, wie sie bei "erwachsenen" DBMS wie RMAN in Oracle DB oder SAP Database Backup zu finden sind. Andererseits unterstützen Anbieter von Unternehmensbackup-Lösungen (Veeam, Veritas, Commvault) zwar PostgreSQL, arbeiten jedoch tatsächlich nur mit bestimmten (meist standalone) Konfigurationen und einer Reihe unterschiedlicher Einschränkungen.
Speziell für PostgreSQL entwickelte Backup-Systeme wie Barman, Wal-g und pg_probackup sind äußerst beliebt in kleinen PostgreSQL-Installationen oder dort, wo umfangreiche Backups anderer IT-Landschaftselemente nicht erforderlich sind. Zum Beispiel kann neben PostgreSQL die Infrastruktur physische und virtuelle Server, OpenShift, Oracle, MariaDB, Cassandra usw. umfassen. All dies sollte idealerweise mit einem gemeinsamen Tool gesichert werden. Eine separate Lösung ausschließlich für PostgreSQL zu implementieren, ist eine ungünstige Idee: Die Daten werden irgendwo auf eine Festplatte kopiert und müssen dann auf ein Band verschoben werden. Diese Doppelung der Backups erhöht die Backup-Zeit und, was noch kritischer ist, die Wiederherstellungszeit.
In der Enterprise-Lösung erfolgt die Sicherung der Installation mit einer bestimmten Anzahl an Knoten eines dedizierten Clusters. Dabei kann beispielsweise Commvault nur mit einem Zweiknoten-Cluster arbeiten, bei dem Primary und Secondary fest bestimmten Knoten zugeordnet sind. Eine Sicherung macht auch nur mit dem Primary Sinn, da das Backup vom Secondary seine eigenen Einschränkungen hat. Aufgrund der Besonderheiten des DBMS wird kein Dump auf dem Secondary erstellt, weshalb nur die Möglichkeit eines Datei-Backups bleibt.
Um die Risiken von Ausfallzeiten zu minimieren, wird beim Aufbau eines ausfallsicheren Systems eine "lebendige" Cluster-Konfiguration erstellt, und der Primary kann schrittweise zwischen verschiedenen Servern migrieren. Zum Beispiel startet die Software Patroni den Primary selbst auf einem zufällig gewählten Knoten des Clusters. Der SRK hat keine Möglichkeit, dies "out of the box" zu verfolgen, und wenn sich die Konfiguration ändert, brechen die Prozesse zusammen. Das heißt, die Einführung eines externen Managements behindert den SRK in seiner effektiven Arbeit, da der verwaltende Server einfach nicht versteht, woher und welche Daten kopiert werden müssen.
Ein weiteres Problem ist die Durchführung von Backups in Postgres. Dies ist über Dumps möglich, und bei kleinen Datenbanken funktioniert es. Bei großen Datenbanken dauert der Dump jedoch lange, benötigt viele Ressourcen und kann zu einem Ausfall der Datenbankinstanz führen.
Dateibackups verbessern die Situation, aber bei großen Datenbanken sind sie langsam, da sie im Einzelthreadbetrieb arbeiten. Außerdem treten bei den Anbietern eine Reihe zusätzlicher Einschränkungen auf. Zum Beispiel kann man nicht gleichzeitig Datei- und Dump-Backups verwenden, oder es wird keine Deduplikation unterstützt. Es gibt viele Probleme, und oft ist es einfacher, anstelle von Postgres eine teure, aber bewährte DBMS zu wählen.
Es gibt kein Zurück! Hinter uns liegt Moskau, Entwickler!
Kürzlich stand unser Team jedoch vor einer schwierigen Herausforderung: Im Projekt zur Erstellung von AIS OSAGO 2.0, für das wir die IT-Infrastruktur entwickelten, wählten die Entwickler für das neue System PostgreSQL.
Großen Softwareentwicklern fällt es viel leichter, «modische» Open-Source-Lösungen zu nutzen. Im Team von Facebook gibt es genügend Fachleute, die den Betrieb dieser DBS unterstützen. Bei RSA lagen jedoch alle „Second-Day“-Aufgaben auf unseren Schultern. Wir mussten die Ausfallsicherheit gewährleisten, einen Cluster aufbauen und natürlich das Backup einrichten. Die Vorgehensweise war wie folgt:
- Wir mussten den SRK darauf trainieren, Backups von der Primary-Node des Clusters zu erstellen. Dazu muss der SRK diese finden – das bedeutet, dass eine Integration mit einer bestimmten Lösung zur Verwaltung des PostgreSQL-Clusters erforderlich ist. Im Fall von RSA wurde dafür die Software Patroni verwendet.
- Es ist notwendig, den Typ des Backups basierend auf den Datenmengen und den Wiederherstellungsanforderungen zu bestimmen. Beispielsweise, wenn Seiten granular wiederhergestellt werden müssen, sollte ein Dump verwendet werden. Bei großen Datenbanken, bei denen kein granularer Wiederherstellung erforderlich ist, sollte auf Dateiebene gearbeitet werden.
- Die Lösung sollte die Möglichkeit eines Block-Backups integrieren, um gleichzeitig ein Backup im Multithreading-Modus zu erstellen.
Unser Ziel war es, ein effektives und einfaches System zu schaffen, ohne eine monströse Verkettung zusätzlicher Komponenten. Je weniger Stützen vorhanden sind, desto geringer ist die Belastung des Personals und das Risiko eines Ausfalls des SRK. Ansätze, die Veeam und RMAN verwendeten, wurden sofort ausgeschlossen, da das Set aus zwei Lösungen bereits auf eine Unzuverlässigkeit des Systems hinweist.
Ein wenig Magie für Enterprise
Wir mussten also zuverlässige Backups für 10 Cluster mit jeweils 3 Knoten garantieren, wobei im Backup-Rechenzentrum eine identische Infrastruktur vorhanden ist. Die Rechenzentren arbeiten im Hinblick auf PostgreSQL nach dem Prinzip aktiv-passiv. Das gesamte Datenbankvolumen betrug 50 TB. Damit kommt jede Unternehmens-SRK problemlos zurecht. Der Haken ist jedoch, dass PostgreSQL von Anfang an keine Ansatzpunkte für volle und tiefe Kompatibilität mit Backup-Systemen bietet. Daher mussten wir nach einer Lösung suchen, die von Anfang an maximal funktional in Verbindung mit PostgreSQL ist und das System weiterentwickeln.
Wir haben 3 interne Hackathons durchgeführt – mehr als fünfzig Entwicklungen gesichtet, sie getestet, Anpassungen basierend auf unseren Hypothesen vorgenommen und wieder überprüft. Nach einer Analyse der verfügbaren Optionen haben wir uns für Commvault entschieden. Dieses Produkt konnte schon „out of the box“ mit einer einfachen Cluster-Installation von PostgreSQL arbeiten, und seine offene Architektur weckte die Hoffnung (die sich bewahrheitete) auf erfolgreiche Anpassungen und Integration. Commvault kann auch PostgreSQL-Logs sichern. Zum Beispiel kann Veritas NetBackup im Zusammenhang mit PostgreSQL nur vollständige Backups durchführen.
Mehr zur Architektur. Die Commvault-Managementserver wurden in beiden Rechenzentren in der Konfiguration CommServ HA installiert. Das System ist spiegelt, wird über eine Konsole verwaltet und erfüllt aus der Sicht von HA alle Anforderungen an Unternehmen.
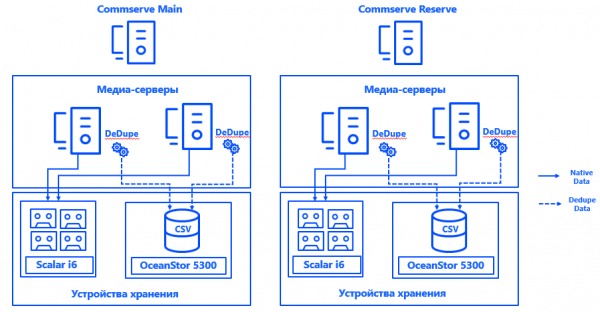
In jedem Rechenzentrum haben wir zwei physische Mediendisserven eingerichtet, die über SAN via Fibre Channel an spezielle Backup-Speichersysteme und Bandbibliotheken angeschlossen sind. Die verteilten Deduplizierungsdatenbanken gewährleisten die Fehlertoleranz der Mediendisserver, während die Anbindung jedes Servers an jeden CSV die kontinuierliche Betriebsfähigkeit bei Ausfall eines beliebigen Komponenten ermöglicht. Die Systemarchitektur erlaubt es, das Backup fortzusetzen, selbst wenn eines der Rechenzentren ausfällt.
Patroni bestimmt die Primary-Node für jeden Cluster. Diese kann jede freie Node im Rechenzentrum sein – jedoch nur in der Hauptgruppe. In der Backup-Gruppe sind alle Nodes Secondary.
Damit Commvault erkennen kann, welche Node des Clusters die Primary ist, haben wir das System (danke der offenen Architektur der Lösung) mit Postgres integriert. Hierfür wurde ein Skript erstellt, das den aktuellen Standort der Primary-Node dem Manager mitteilt. Server Commvault.
Insgesamt sieht der Prozess folgendermaßen aus:
Patroni wählt die Primary → Keepalived richtet die IP-Cluster ein und startet das Skript → Der Commvault-Agent auf der gewählten Node des Clusters erhält die Benachrichtigung, dass dies die Primary ist → Commvault konfiguriert das Backup automatisch innerhalb des Pseudoklienten neu.
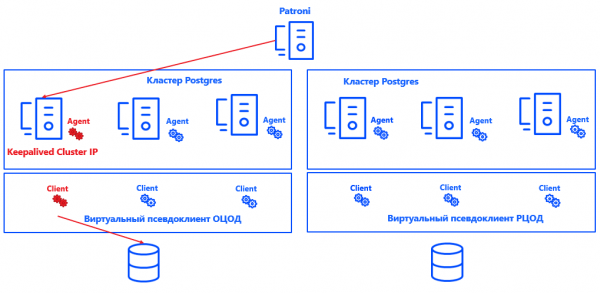
Der Vorteil dieses Ansatzes liegt darin, dass die Lösung weder die Konsistenz noch die Genauigkeit der Protokolle oder die Wiederherstellung einer Postgres-Instanz beeinträchtigt. Sie lässt sich außerdem leicht skalieren, da es nicht mehr erforderlich ist, sich auf Commvault Primary- und Secondary-Knoten festzulegen. Es reicht aus, dass das System versteht, wo sich der Primary-Knoten befindet, und die Anzahl der Knoten kann praktisch auf jeden Wert erhöht werden.
Die Lösung erhebt keinen Anspruch auf Perfektion und hat ihre eigenen Nuancen. Commvault kann nur die gesamte Instanz sichern, nicht einzelne Datenbanken. Daher wurde für jede DB eine separate Instanz erstellt. Echte Kunden werden in virtuelle Pseudo-Kunden zusammengefasst. Jeder Pseudo-Kunde von Commvault stellt einen UNIX-Cluster dar. In diesen werden die Knoten des Clusters hinzugefügt, auf denen der Commvault-Agent für Postgres installiert ist. Infolgedessen werden alle virtuellen Knoten des Pseudo-Kunden als eine einzige Instanz gesichert.
In jedem Pseudokunden ist der aktive Knoten des Clusters angegeben. Genau dieser wird durch unsere Integration für Commvault bestimmt. Das Prinzip ist recht einfach: Wenn auf dem Knoten eine Cluster-IP hochgefahren wird, setzt das Skript im Binärformat des Commvault-Agenten den Parameter „aktiver Knoten“ — im Grunde genommen setzt das Skript „1“ im entsprechenden Teil des Speichers. Der Agent überträgt diese Daten an CommServe, und Commvault führt das Backup vom gewünschten Knoten durch. Außerdem wird im Skript die Richtigkeit der Konfiguration überprüft, um Fehler beim Starten der Datensicherung zu vermeiden.
Dabei werden große Datenbanken blockweise in mehreren Streams gesichert, sodass die Anforderungen an RPO und das Backup-Fenster erfüllt werden. Die Systemlast ist gering: Vollbackups kommen nicht so häufig vor, an anderen Tagen werden nur Protokolle gesammelt, und zwar in Zeiten geringer Belastung.
Übrigens haben wir separate Richtlinien für die Sicherung von Archivprotokollen in PostgreSQL angewendet — diese werden nach anderen Regeln aufbewahrt, nach einem anderen Zeitplan gesichert und die Deduplizierung ist für sie nicht aktiviert, da diese Protokolle einzigartige Daten enthalten.
Um die Konsistenz der gesamten IT-Infrastruktur zu gewährleisten, sind separate Commvault-File-Clients auf jedem Knoten des Clusters installiert. Diese schließen Dateien von Postgres aus den Sicherungen aus und sind nur für das Backup des Betriebssystems und der Anwendungsanwendungen gedacht. Für diesen Datenteil gibt es auch eine eigene Richtlinie und eine spezifische Aufbewahrungsfrist.

Aktuell hat das SRK keinen Einfluss auf die produktiven Dienste, aber falls sich die Situation ändert, kann in Commvault ein Lastbegrenzungssystem aktiviert werden.
Passt das? Passt!
So haben wir nicht nur ein funktionierendes, sondern auch ein vollständig automatisiertes Backup für die Cluster-Installation von PostgreSQL erhalten, das allen Anforderungen des Enterprise-Umfeldes entspricht.
Die RPO- und RTO-Werte von 1 Stunde und 2 Stunden sind großzügig abgedeckt, was bedeutet, dass das System diese auch bei signifikantem Anstieg des gespeicherten Datenvolumens erfüllen wird. Trotz vieler Zweifel haben sich PostgreSQL und die Unternehmensumgebung als durchaus kompatibel erwiesen. Und nun wissen wir aus eigener Erfahrung, dass Backups für solche DBMS in den unterschiedlichsten Konfigurationen möglich sind.
Natürlich mussten wir auf diesem Weg sieben Paar eiserne Stiefel abnutzen, eine Reihe von Schwierigkeiten überwinden, auf einige Rechen treten und eine Menge Fehler korrigieren. Aber jetzt ist der Ansatz erprobt und kann für die Implementierung von Open Source anstelle von proprietären DBMS in rauen Unternehmensbedingungen verwendet werden.
Haben Sie schon einmal mit PostgreSQL in einer Unternehmensumgebung gearbeitet?
Autoren:
Oleg Lavrenov, Systemarchitekt für Speicherlösungen bei «Infosysteme Jet»
Dmitry Yerykin, Systemarchitekt für Rechenkomplexe bei «Infosysteme Jet»
Quelle: habr.com
