

Hallo, Habr-Nutzer. Heute beginnen die Kurse der ersten Gruppe. . In diesem Zusammenhang möchten wir Ihnen von unserem offenen Webinar zu diesem Kurs berichten.

In haben wir darüber gesprochen, mit welchen Herausforderungen SQL-Datenbanken in der Ära von Cloud und Kubernetes konfrontiert sind. Gleichzeitig haben wir uns angesehen, wie sich SQL-Datenbanken unter dem Einfluss dieser Herausforderungen anpassen und verändern.
Das Webinar wurde gehalten von , Google Cloud Practice Delivery Manager bei EPAM Systems.
Als die Bäume noch klein waren…
Lassen Sie uns zunächst daran erinnern, wie die Auswahl von Datenbankmanagementsystemen (DBMS) Ende des letzten Jahrhunderts begann. Das sollte nicht schwerfallen, denn die Auswahl der DBMS damals begann und endete Oracle.

In den späten 90er und frühen 2000er Jahren gab es im Grunde genommen nicht viel Auswahl, wenn es um industrielle, skalierbare Datenbanken ging. Ja, es gab IBM DB2, Sybase und ein paar andere Datenbanken, die auftauchten und verschwanden, aber insgesamt waren sie im Vergleich zu Oracle nicht so auffällig. Entsprechend waren die Fähigkeiten der Ingenieure dieser Zeit irgendwie an die einzige Option gebunden, die es gab.
Ein Oracle DBA musste folgende Fähigkeiten besitzen:
- Oracle Server aus dem Distributionspaket installieren;
- Oracle Server konfigurieren:
- init.ora;
- listener.ora;
— erstellen:
- Tabellenräume;
- Schemas;
- Benutzer;
— Backup und Wiederherstellung durchführen;
— Monitoring durchführen;
— mit suboptimalen Abfragen umgehen.
Dabei wurde von einem Oracle DBA nicht unbedingt verlangt:
- die optimale Datenbank oder eine andere Technologie zur Speicherung und Verarbeitung von Daten auszuwählen;
- hohe Verfügbarkeit und horizontale Skalierbarkeit zu gewährleisten (das war nicht immer eine Frage für den DBA);
- die Fachdomäne, Infrastruktur, Anwendungsarchitektur und das Betriebssystem gut zu kennen;
- Daten zu importieren und zu exportieren sowie Migrationen zwischen verschiedenen Datenbanken durchzuführen.
Im Großen und Ganzen, wenn man von der Auswahl in jenen Zeiten spricht, ähnelt sie der Auswahl in einem sowjetischen Geschäft Ende der 80er Jahre:

Unsere Zeit
Seitdem sind die Bäume natürlich gewachsen, die Welt hat sich verändert, und es sieht irgendwie so aus:

Der Markt der Datenbanken hat sich ebenfalls verändert, was in den aktuellen Berichten von Gartner gut zu erkennen ist:
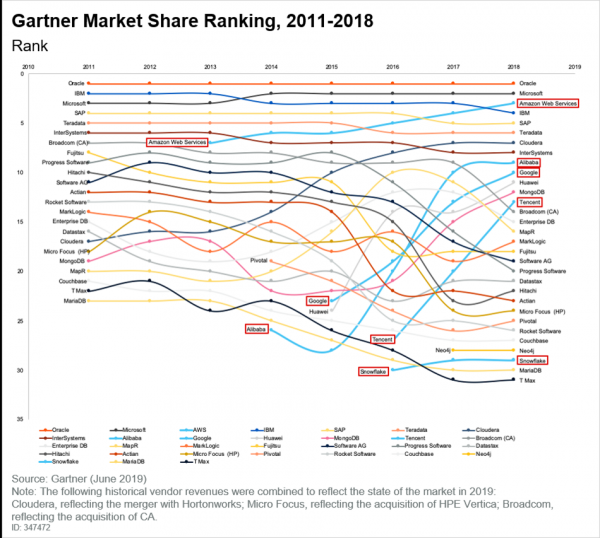
Hier ist zudem zu erwähnen, dass Clouds ihren Platz eingenommen haben, deren Beliebtheit wächst. Wenn man denselben Gartner-Bericht liest, sieht man die folgenden Schlussfolgerungen:
- Viele Kunden befinden sich auf dem Weg, ihre Anwendungen in die Cloud zu migrieren.
- Neue Technologien erscheinen zuerst in der Cloud, und es ist ungewiss, ob sie jemals in eine nicht-cloudbasierte Infrastruktur überführt werden.
- Das Preismodell nach dem Prinzip 'pay-as-you-go' ist zur Norm geworden. Alle wollen nur für das bezahlen, was sie tatsächlich nutzen, und das ist nicht mehr nur ein Trend, sondern eine grundlegende Tatsache.
Was passiert jetzt?
Heute sind wir alle in der Cloud. Die Fragen, die wir haben, betreffen die Auswahl. Und die Möglichkeiten sind riesig, selbst wenn wir nur über die Auswahl von DB-Technologien im On-Premises-Format sprechen. Zudem gibt es Managed Services und SaaS. So wird die Entscheidungsfindung mit jedem Jahr komplexer.
Neben den Auswahlfragen gibt es auch einschränkende Faktoren:
- Preis. Viele Technologien kosten nach wie vor Geld;
- Fähigkeiten. Wenn wir über Open Source sprechen, stellt sich die Frage nach den Fähigkeiten, da kostenlose Software von den Personen, die sie einrichten und betreiben, ein gewisses Maß an Kompetenz verlangt;
- Funktionalität. Nicht alle Dienstleistungen, die in der Cloud verfügbar sind und beispielsweise auf der gleichen Basis wie Postgres basieren, weisen die gleichen Funktionen auf wie Postgres vor Ort. Dies ist ein wesentlicher Faktor, den man kennen und verstehen sollte. Darüber hinaus gewinnt dieser Faktor an Bedeutung gegenüber dem Wissen über bestimmte versteckte Funktionen einer einzelnen Datenbank.
Was man jetzt von DA/DE erwartet:
- ein gutes Verständnis des Fachgebiets und der Anwendungsarchitektur;
- die Fähigkeit, die geeignete Datenbanktechnologie unter Berücksichtigung der gestellten Aufgabe korrekt auszuwählen;
- die Fähigkeit, die optimale Methode zur Umsetzung der gewählten Technologie im Kontext vorhandener Einschränkungen auszuwählen;
- die Fähigkeit, Datenübertragungen und Migrationen durchzuführen;
- die Fähigkeit, die gewählten Lösungen zu implementieren und zu betreiben.
Das folgende Beispiel auf Basis von GCP zeigt, wie die Wahl der jeweiligen Technologie zur Datenverarbeitung von deren Struktur abhängt:
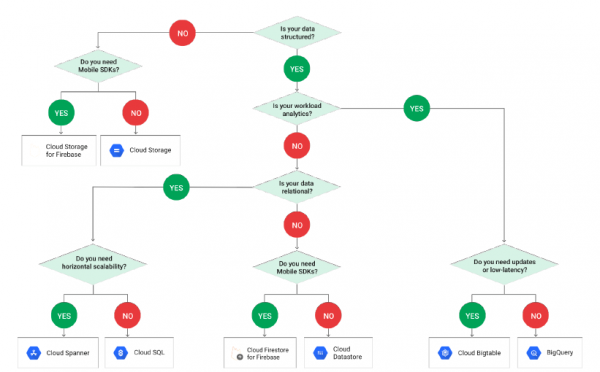
Bitte beachten Sie, dass PostgreSQL im Schema nicht vorhanden ist, da es unter dem Begriff Cloud SQLverborgen ist. Und wenn wir in Cloud SQL gelangen, müssen wir erneut eine Wahl treffen:
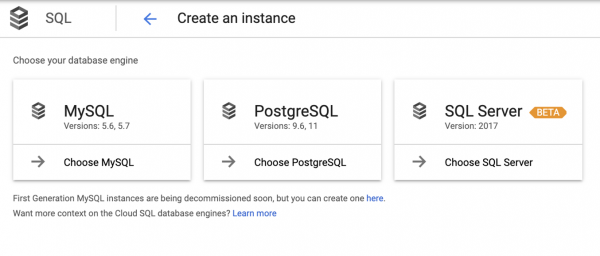
Es sollte beachtet werden, dass diese Wahl nicht immer offensichtlich ist, sodass die App-Entwickler oft auf ihr Bauchgefühl hören.
Insgesamt:
- Je weiter man geht, desto relevanter wird die Wahlfrage. Sogar wenn man nur die GCP betrachtet, erscheinen verwaltete Dienste und SaaS im vierten Schritt zum ersten Mal, und dort ist Spanner gleich dabei. Zudem wird die Wahl von PostgreSQL erst im fünften Schritt erwähnt, wo auch MySQL und SQL Server stehen, das heißt es gibt viel Auswahl, aber die Entscheidung muss getroffen werden..
- Man darf die Einschränkungen nicht vergessen, die den Versuchungen gegenüberstehen. Im Grunde wollen alle Spanner, aber er ist teuer. Letztlich sieht eine typische Anfrage etwa so aus: „Bitte realisieren Sie uns Spanner, aber zum Preis von Cloud SQL, Sie sind doch Profis!“

Und was soll man tun?
Ohne den Anspruch auf endgültige Wahrheit zu erheben, sagen wir folgendes:
Es ist an der Zeit, den Ansatz für das Training zu ändern:
- Es macht keinen Sinn, die DBA früher so zu schulen, wie man es gewohnt war;
- die Kenntnis eines einzelnen Produkts ist jetzt nicht mehr ausreichend;
- und es ist unmöglich, Dutzende auf dem Niveau eines einzigen zu beherrschen.
Man muss nicht nur das Produkt kennen, sondern auch:
- die Anwendungsfälle;
- die verschiedenen Bereitstellungsmethoden;
- die Vor- und Nachteile jeder Methode;
- vergleichbare und alternative Produkte, um eine informierte und optimale Entscheidung zu treffen, und nicht immer zugunsten des bekannten Produkts.
Außerdem ist es wichtig, Daten migrieren zu können und die grundlegenden Prinzipien der Integration mit ETL zu verstehen.
Ein praktisches Beispiel
In der jüngeren Vergangenheit war es erforderlich, das Backend für eine mobile Anwendung zu entwickeln. Zu Beginn der Arbeit an diesem Projekt war das Backend bereits entwickelt und bereit für die Implementierung, und das Entwicklerteam hatte etwa zwei Jahre für dieses Projekt aufgewendet. Dabei wurden folgende Aufgaben gestellt:
- CI/CD aufzubauen;
- eine Architektur-Überprüfung durchzuführen;
- alles in Betrieb zu nehmen.
Die Anwendung selbst war mikrodienstbasiert, und der Code in Python/Django wurde von Grund auf neu und direkt in GCP entwickelt. Was die Zielgruppe angeht, so wurde angenommen, dass es zwei Regionen geben würde — die USA und die EU, und der Datenverkehr wurde über den Global Load Balancer verteilt. Alle Workloads und die Rechenlast liefen in Google Kubernetes Engine.
Was die Daten betrifft, so gab es 3 Strukturen:
- Cloud Storage;
- Datastore;
- Cloud SQL (PostgreSQL).
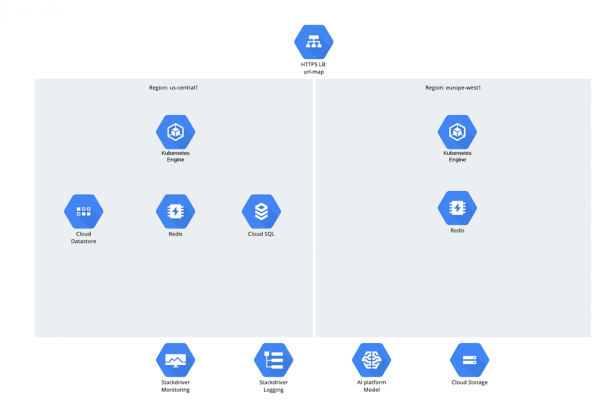
Es stellt sich vielleicht die Frage, warum Cloud SQL gewählt wurde. Ehrlich gesagt, verursacht diese Frage in den letzten Jahren eine gewisse Verlegenheit – es scheint, als hätten die Leute eine Abneigung gegen relationale Datenbanken entwickelt, aber dennoch setzen sie sie aktiv ein ;-).
In unserem Fall wurde Cloud SQL aus folgenden Gründen gewählt:
- Wie bereits erwähnt, wurde die Anwendung mit Django entwickelt, und darin gibt es ein Modell, das permanente Daten aus der SQL-Datenbank in Python-Objekte (Django ORM) abbildet.
- Das Framework unterstützte eine ausreichend begrenzte Liste an DBMS:
- PostgreSQL;
- MariaDB;
- MySQL;
- Oracle;
- SQLite.
Daher wurde PostgreSQL eher intuitiv aus dieser Liste ausgewählt (nun, Oracle wollte man wirklich nicht wählen).
Was fehlte:
- Die Anwendung wurde nur in 2 Regionen bereitgestellt, und es war geplant, eine dritte (Asien) hinzuzufügen;
- Die Datenbank befand sich in der nordamerikanischen Region (Iowa);
- Von Seiten des Kunden gab es Bedenken hinsichtlich möglicher Zugriffsverzögerungen aus Europa und Asien und Unterbrechungen im Dienst im Falle eines Ausfalls der DBMS.
Obwohl Django mehrere Datenbanken parallel verwalten und diese nach Lese- und Schreiboperationen aufteilen kann, war die Anzahl der Schreibvorgänge in der Anwendung nicht besonders hoch (über 90 % – Lesevorgänge). Insgesamt wäre es, wenn möglich, eine kompromissbereite Lösung gewesen. Eine Read-Replica der Hauptdatenbank in Europa und Asien, wäre eine solche Lösung. Was ist daran so kompliziert?
Die Schwierigkeit lag darin, dass der Kunde nicht auf die Nutzung von Managed Services und Cloud SQL verzichten wollte. Die Möglichkeiten von Cloud SQL sind derzeit jedoch eingeschränkt. Cloud SQL unterstützt hohe Verfügbarkeit (HA) und Read Replicas (RR), aber die RR wird nur in einer Region unterstützt. Wird eine Datenbank in der amerikanischen Region erstellt, kann eine Read-Replica in der europäischen Region mit den Mitteln von Cloud SQL nicht eingerichtet werden, obwohl PostgreSQL das nicht einschränkt. Der Austausch mit den Mitarbeitern von Google brachte nichts und endete mit Versprechungen wie "Wir kennen das Problem und arbeiten daran, irgendwann wird das Problem gelöst sein."
Wenn man die Möglichkeiten von Cloud SQL stichpunktartig auflistet, würde das ungefähr so aussehen:
1. Hohe Verfügbarkeit (HA):
- innerhalb einer Region;
- durch Festplattenreplikation;
- ohne Verwendung der PostgreSQL-Mechanismen;
- Es sind automatische und manuelle Steuerungen möglich – Failover/Fallback;
- bei der Umschaltung ist die DBMS für einige Minuten nicht verfügbar.
2. Read Replica (RR):
- innerhalb einer Region;
- Hot Standby;
- PostgreSQL Streaming-Replikation.
Außerdem stößt man bei der Auswahl von Technologien immer auf irgendwelche Einschränkungen.:
- Der Kunde wollte keine Entitäten schaffen und IaaS nur über GKE nutzen;
- der Kunde wollte keinen Self-Service für PostgreSQL/MySQL bereitstellen;
- und überhaupt wäre Google Spanner eine gute Lösung, wäre da nicht der Preis; allerdings kann Django ORM damit nicht arbeiten, aber im Prinzip ist es ein gutes Produkt.
Angesichts der Situation stellte der Kunde eine Herausforderung: „Könnten Sie etwas Ähnliches machen, das wie Google Spanner funktioniert, aber auch mit Django ORM arbeitet?“
Lösungsoption Nr. 0
Das Erste, was mir in den Sinn kam:
- bei CloudSQL bleiben;
- es wird keine integrierte Replikation zwischen Regionen in irgendeiner Form geben;
- versuchen, eine Replikation an die bestehende Cloud SQL by PostgreSQL anzuhängen;
- irgendwo und irgendwie eine PostgreSQL-Instanz starten, aber zumindest den Master nicht anfassen.
Leider stellte sich heraus, dass dies nicht möglich ist, da kein Zugriff auf den Host besteht (er befindet sich in einem anderen Projekt) – pg_hba usw. sind nicht verfügbar und es gibt keinen Zugang als Superuser.
Lösungsoption Nr. 1
Nach weiteren Überlegungen und unter Berücksichtigung der vorherigen Umstände hat sich unser Denkansatz etwas geändert:
- Wir versuchen nach wie vor, im Rahmen von CloudSQL zu bleiben, wechseln jedoch zu MySQL, da Cloud SQL von MySQL einen externen Master hat, der:
— als Proxy für MySQL dient;
— wie eine MySQL-Instanz aussieht;
— für die Migration von Daten aus anderen Clouds oder von On-Premises konzipiert wurde.
Da die Konfiguration der MySQL-Replikation keinen Zugriff auf den Host erfordert, funktionierte im Prinzip alles, aber es war sehr instabil und unbequem. Und als wir weitergingen, wurde es richtig beängstigend, da wir die gesamte Struktur mit Terraform ausrollten und plötzlich herausfanden, dass der externe Master von Terraform nicht unterstützt wird. Ja, Google hat eine CLI, aber irgendwie funktionierte alles nur sporadisch – manchmal wird es erstellt, manchmal nicht. Vielleicht, weil die CLI zur Migration von Daten von außen gedacht ist und nicht für Replikate.
Da wurde klar, dass Cloud SQL ganz und gar nicht geeignet ist. Wie man so schön sagt, wir haben alles versucht, was wir konnten.
Lösungsoption Nr. 2
Da es nicht möglich war, im Rahmen von Cloud SQL zu bleiben, versuchten wir, die Anforderungen an eine Kompromisslösung zu formulieren. Die Anforderungen waren folgende:
- Arbeiten mit Kubernetes, Maximierung der Ressourcen und Möglichkeiten von Kubernetes (DCS, …) und GCP (LB, …);
- keine Ballaststoffe durch eine Vielzahl unnötiger cloud-basierter Elemente wie HA Proxy;
- die Möglichkeit, in der Hauptregion HA PostgreSQL oder MySQL zu starten; in anderen Regionen – HA aus der Hauptregion plus einer Kopie (zur Zuverlässigkeit);
- Multi-Master (sich damit zu verbinden, war nicht unbedingt gewünscht, aber auch nicht völlig unbedeutend)
.
Infolge dieser Anforderungen sind endlich geeignete Optionen für Datenbanksysteme und ihre Anbindung in SichtMySQL Galera;:
- CockroachDB;
- PostgreSQL-Tools
- — pgpool-II;
:
— Patroni.
— Patronen.
MySQL Galera
Die MySQL Galera-Technologie wurde von Codership entwickelt und ist ein Plugin für InnoDB. Eigenschaften:
- Multi-Master;
- synchronisierte Replikation;
- lesen von jedem Knoten;
- schreiben auf jeden Knoten;
- eingebauter HA-Mechanismus;
- es gibt ein Helm-Chart von Bitnami.
CockroachDB
Das beschriebene Produkt ist wirklich beeindruckend und stellt ein Open-Source-Projekt dar, das in Go entwickelt wurde. Der Hauptakteur ist Cockroach Labs (gegründet von ehemaligen Google-Mitarbeitern). Diese relationale Datenbank wurde ursprünglich als verteilte Lösung mit horizontaler Skalierbarkeit „out of the box“ und Hochverfügbarkeit entwickelt. Ihre Entwickler haben sich zum Ziel gesetzt, die Funktionalität von SQL mit der horizontalen Verfügbarkeit, die man von NoSQL-Lösungen gewohnt ist, zu kombinieren.
Ein netter Bonus ist die Unterstützung des PostgreSQL-Anschlussprotokolls.
Pgpool
Dies ist eine Erweiterung für PostgreSQL, die im Grunde eine neue Entität ist, die alle Verbindungen übernimmt und bearbeitet. Sie verfügt über einen eigenen Lastenausgleich und Parser und ist unter der BSD-Lizenz lizenziert. Sie bietet umfangreiche Möglichkeiten, sieht jedoch etwas einschüchternd aus, da das Vorhandensein einer neuen Entität einige zusätzliche Herausforderungen mit sich bringen könnte.
Patroni
Das ist das letzte, was ins Auge fiel, und es war nicht umsonst. Patroni ist ein Open-Source-Tool, das im Grunde ein Python-Daemon ist, der es ermöglicht, PostgreSQL-Cluster mit verschiedenen Replikationsarten und automatischem Failover zu verwalten. Es ist äußerst interessant, da es sich gut in Kubernetes integriert und keine neuen Entitäten mit sich bringt.
Was schließlich ausgewählt wurde
Die Entscheidung fiel nicht leicht:
- CockroachDB — spannend, aber riskant;
- MySQL Galera — ebenfalls nicht schlecht, wird häufig verwendet, aber MySQL;
- Pgpool — viele überflüssige Entitäten, mittelmäßige Integration mit der Cloud und K8s;
- Patroni — hervorragende Integration mit K8s, keine überflüssigen Entitäten, gut integriert mit GCP LB.
Somit fiel die Wahl auf Patroni.
Fazit
Es ist an der Zeit, eine kurze Zusammenfassung zu ziehen. Ja, die Welt der IT-Infrastruktur hat sich erheblich verändert, und das ist erst der Anfang. Früher waren Clouds lediglich eine andere Art von Infrastruktur, aber jetzt ist alles anders. Zudem erscheinen ständig Innovationen in den Clouds, und möglicherweise werden diese nur in Cloud-Umgebungen entwickelt, um später durch Startups in On-Premises-Umgebungen übertragen zu werden.
Was SQL betrifft, so ist SQL nach wie vor relevant. Das bedeutet, dass man PostgreSQL und MySQL kennen und damit umgehen können muss, aber es ist noch wichtiger, sie richtig anzuwenden.
Quelle: habr.com
