


Viele stehen vor Elasticsearch. Aber was passiert, wenn Sie damit „in besonders großem Umfang“ Protokolle speichern möchten? Und das ganz ohne Probleme bei einem Ausfall eines der mehreren Rechenzentren? Welche Architektur ist erforderlich und auf welche Fallstricke müssen Sie achten?
Wir bei Odnoklassniki haben uns entschieden, mit Elasticsearch das Log-Management zu optimieren und teilen nun unsere Erfahrungen mit Habr: sowohl zur Architektur als auch zu den Fallstricken.
Ich bin Peter Zaitsev, arbeite als Systemadministrator bei Odnoklassniki. Zuvor war ich auch Administrator und habe mit Manticore Search, Sphinx Search und Elasticsearch gearbeitet. Wenn es ein weiteres ...search gibt, werde ich wahrscheinlich auch damit arbeiten. Ich beteilige mich auch freiwillig an verschiedenen Open-Source-Projekten.
Als ich zu Odnoklassniki kam, sagte ich in meinem Vorstellungsgespräch unvorsichtigerweise, dass ich mit Elasticsearch umgehen kann. Nachdem ich mich eingearbeitet und einige einfache Aufgaben erledigt hatte, wurde mir eine große Aufgabe zur Reformierung des zu diesem Zeitpunkt bestehenden Log-Management-Systems übertragen.
Anforderungen
Die Anforderungen an das System wurden wie folgt formuliert:
- Als Frontend sollte Graylog verwendet werden. Das Unternehmen hatte bereits Erfahrung mit diesem Produkt, die Entwickler und Tester kannten es gut, es war ihnen vertraut und bequem.
- Datenvolumen: durchschnittlich 50-80 tausend Nachrichten pro Sekunde, aber wenn etwas kaputt geht, ist der Verkehr unbeschränkt, es können 2-3 Millionen Zeilen pro Sekunde sein.
- Nach Diskussion der Anforderungen mit den Kunden bezüglich der Geschwindigkeit der Verarbeitung von Suchanfragen erkannten wir, dass das typische Nutzungsmuster eines solchen Systems darin besteht, dass die Nutzer nach den Logs ihrer Anwendung der letzten zwei Tage suchen und nicht länger als eine Sekunde auf das Ergebnis ihrer Anfrage warten möchten.
- Die Administratoren bestanden darauf, dass das System bei Bedarf einfach skalierbar sein sollte, ohne dass sie tiefes Verständnis dafür aufbringen mussten, wie es aufgebaut ist.
- Das einzig notwendige Wartungsaufgaben für diese Systeme sollte gelegentlich das Austauschen von Hardware sein.
- Darüber hinaus gibt es bei Odnoklassniki eine großartige technische Tradition: Jeder Dienst, den wir starten, muss einen Ausfall des Rechenzentrums überstehen können (plötzlich, unvorhergesehen und zu jeder Zeit).
Die letzte Anforderung für die Umsetzung dieses Projekts hat uns am meisten zu schaffen gemacht, über die ich noch genauer berichten werde.
Umgebung
Wir arbeiten mit vier Rechenzentren, wobei die Elasticsearch-Datenknoten nur in dreien untergebracht werden können (aus verschiedenen nicht-technischen Gründen).
In diesen vier Rechenzentren befinden sich ungefähr 18.000 verschiedene Logquellen – Hardware, Container, virtuelle Maschinen.
Ein wichtiges Merkmal: Der Cluster wird in Containern gestartet nicht auf physischen Maschinen, sondern auf . Den Containern sind 2 Kerne garantiert, vergleichbar mit 2,0 GHz v4, wobei die restlichen Kerne bei Leerlauf genutzt werden können.
Anders ausgedrückt:

Topologie
Das Gesamtbild der Lösung erschien mir ursprünglich folgendermaßen:
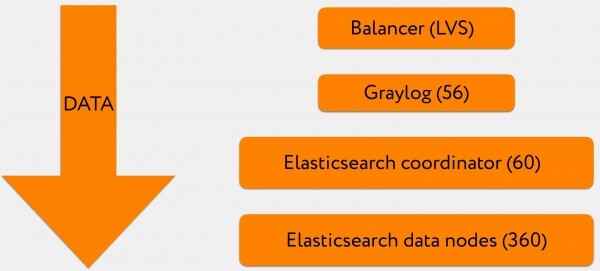
- 3-4 VIPs stehen hinter dem A-Record der Domain Graylog, das ist die Adresse, an die die Logs gesendet werden.
- Jeder VIP fungiert als LVS-Lastverteiler.
- Danach gelangen die Logs zu einem Graylog-Cluster, wobei ein Teil der Daten im GELF-Format und ein Teil im syslog-Format vorliegt.
- Anschließend wird alles in großen Batches an einen Cluster von Elasticsearch-Koordinatoren geschrieben.
- Diese wiederum senden Lese- und Schreibanfragen an die entsprechenden Datenknoten.
Terminologie
Vielleicht sind nicht alle mit der Terminologie vertraut, daher möchten wir etwas darauf eingehen.
In Elasticsearch gibt es mehrere Knotentypen – Master, Koordinator und Datenknoten. Es gibt noch zwei weitere Typen für unterschiedliche Log-Transformationen und die Verbindung zwischen verschiedenen Clustern, aber wir haben nur die genannten verwendet.
Master
Pinged alle Knoten im Cluster, hält die aktuelle Clusterkarte und verbreitet sie zwischen den Knoten, verarbeitet die Ereignislogik und kümmert sich um verschiedene clusterweite Wartungsaufgaben.
Koordinator
Führt eine einzige Aufgabe aus: nimmt Lese- oder Schreibanfragen von Clients entgegen und leitet diesen Traffic weiter. Wenn es sich um eine Schreibanfrage handelt, wird er wahrscheinlich den Master fragen, in welchen Shard des relevanten Indexes er diese platzieren soll, und die Anfrage weiterleiten.
Datenknoten
Speichert Daten, führt Suchanfragen und Operationen auf den Shards, die sich auf ihm befinden, aus.
Graylog
Es ist eine Art Kombination aus Kibana und Logstash im ELK-Stack. Graylog vereint sowohl die Benutzeroberfläche als auch die Pipeline zur Verarbeitung von Logs. Im Hintergrund arbeiten Kafka und Zookeeper in Graylog, die die Kohärenz von Graylog als Cluster sicherstellen. Graylog ist in der Lage, Logs (Kafka) zwischenzuspeichern, falls Elasticsearch nicht verfügbar ist, und gescheiterte Lese- und Schreibanforderungen zu wiederholen sowie Logs nach vordefinierten Regeln zu gruppieren und zu kennzeichnen. Ähnlich wie Logstash bietet Graylog Funktionen zur Bearbeitung von Zeilen, bevor diese in Elasticsearch geschrieben werden.
Außerdem bietet Graylog eine integrierte Service Discovery, die es ermöglicht, basierend auf einer verfügbaren Elasticsearch-Node die gesamte Cluster-Karte zu erhalten und nach einem bestimmten Tag zu filtern, was die Möglichkeit gibt, Anfragen an bestimmte Container zu richten.
Visuell sieht das ungefähr so aus:

Dies ist ein Screenshot von einer bestimmten Instanz. Hier erstellen wir ein Histogramm basierend auf der Suchanfrage und zeigen relevante Zeilen an.
Indizes
Wenn wir zur Architektur des Systems zurückkehren, möchte ich genauer darauf eingehen, wie wir das Modell der Indizes aufgebaut haben, damit alles korrekt funktioniert.
Auf dem zuvor gezeigten Diagramm ist dies die unterste Ebene: Elasticsearch-Datenknoten.
Ein Index ist eine umfassende virtuelle Entität, die aus Elasticsearch-Shards besteht. Jeder dieser Shards ist nichts anderes als ein Lucene-Index. Und jeder Lucene-Index setzt sich wiederum aus einem oder mehreren Segmenten zusammen.
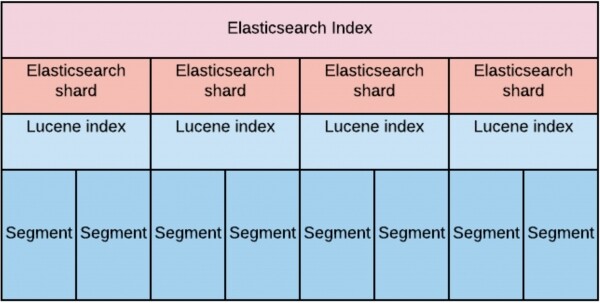
Bei der Planung haben wir berücksichtigt, dass wir, um die Anforderungen an die Lesegeschwindigkeit bei großen Datenmengen zu erfüllen, diese Daten gleichmäßig über die Datenknoten verteilen müssen.
Das führte dazu, dass die Anzahl der Shards pro Index (mit Replikaten) strikt der Anzahl der Datenknoten entsprechen muss. Erstens, um einen Replikationsfaktor von zwei zu gewährleisten (das heißt, wir können die Hälfte des Clusters verlieren). Zweitens, um die Lese- und Schreibanfragen mindestens auf der Hälfte des Clusters bearbeiten zu können.
Die Speicherdauer haben wir zunächst auf 30 Tage festgelegt.
Die Verteilung der Shards kann grafisch wie folgt dargestellt werden:

Das gesamte dunkelgraue Rechteck ist der Index. Das linke rote Quadrat darin ist der Primary-Shard, der erste im Index. Das blaue Quadrat ist der Replica-Shard. Sie befinden sich in verschiedenen Rechenzentren.
Wenn wir einen weiteren Shard hinzufügen, gelangt dieser ins dritte Rechenzentrum. Am Ende erhalten wir eine Struktur, die einen Verlust des Rechenzentrums ermöglicht, ohne dass die Konsistenz der Daten verloren geht.

Wir haben die Rotationszeit der Indizes, also die Erstellung eines neuen Index und das Löschen des ältesten, auf 48 Stunden festgelegt (basierend auf dem Nutzungsmuster des Index: Die letzten 48 Stunden werden am häufigsten abgefragt).
Dieser Rotationsintervall der Indizes hängt mit folgenden Gründen zusammen:
Wenn eine Suchanfrage an einen bestimmten Datenknoten gesendet wird, ist es aus Performance-Sicht vorteilhafter, wenn nur ein Shard befragt wird, sofern dessen Größe mit der Größe des Heap des Knotens vergleichbar ist. Das ermöglicht es, den "heißen" Teil des Index im Heap zu halten und schnell darauf zuzugreifen. Wenn es zu vielen "heißen Teilen" kommt, verschlechtert sich die Suchgeschwindigkeit im Index.
Wenn ein Knoten mit der Ausführung einer Suchanfrage auf einem Shard beginnt, weist er eine Anzahl an Threads zu, die der Anzahl der hyperthreading-fähigen Kerne der physischen Maschine entspricht. Wenn die Suchanfrage eine große Anzahl von Shards betrifft, steigt die Anzahl der Threads proportional an. Dies wirkt sich negativ auf die Suchgeschwindigkeit aus und beeinträchtigt die Indizierung neuer Daten.
Um die erforderliche Suchlatenz zu gewährleisten, haben wir uns entschieden, SSDs zu verwenden. Für eine schnelle Bearbeitung der Anfragen mussten die Maschinen, auf denen diese Container gehostet wurden, mindestens 56 Kerne besitzen. Die Zahl 56 wurde als ausreichend angesehen, um die Anzahl der Threads zu definieren, die Elasticsearch während des Betriebs erzeugt. In Elasticsearch hängen viele Parameter des Thread-Pools direkt von der Anzahl der verfügbaren Kerne ab, was wiederum direkt die erforderliche Anzahl an Knoten im Cluster beeinflusst nach dem Prinzip "weniger Kerne — mehr Knoten".
Insgesamt haben wir herausgefunden, dass ein Shard durchschnittlich etwa 20 Gigabyte wiegt und auf 1 Index 360 Shards entfallen. Wenn wir diese alle alle 48 Stunden rotieren, haben wir 15 davon. Jeder Index speichert die Daten für 2 Tage.
Datenspeicher- und -leseschemata
Lassen Sie uns klären, wie in diesem System Daten gespeichert werden.
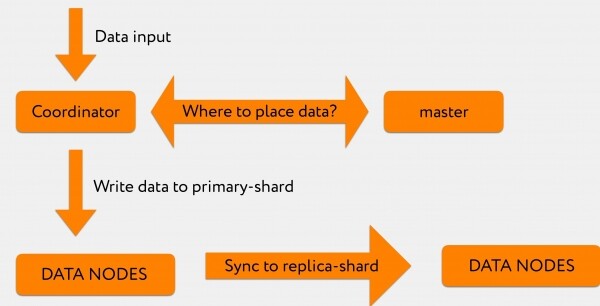
Angenommen, wir erhalten eine Anfrage von Graylog an den Koordinator. Zum Beispiel möchten wir 2.000 bis 3.000 Zeilen indizieren.
Der Koordinator fragt den Master: „In der Anfrage zur Indizierung haben wir spezifisch den Index angegeben, aber nicht, in welchen Shard dies geschrieben werden soll.“
Der Master antwortet: „Speichere diese Informationen im Shard Nummer 71“, woraufhin sie direkt an den relevanten Datenknoten gesendet wird, wo sich der primäre Shard Nummer 71 befindet.
Anschließend wird das Transaktionsprotokoll auf den Replica-Shard repliziert, der sich bereits in einem anderen Rechenzentrum befindet.
Von Graylog kommt eine Suchanfrage an den Koordinator. Der Koordinator leitet sie anhand des Index weiter, wobei Elasticsearch grundsätzlich im Round-Robin-Verfahren Anfragen zwischen dem primären Shard und dem Replica-Shard verteilt.
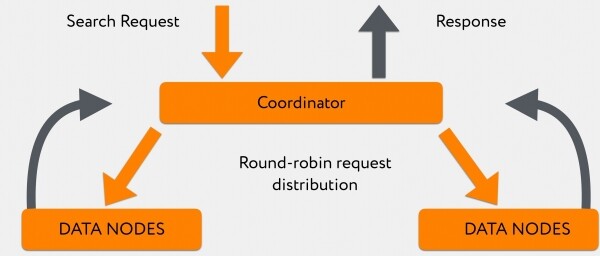
Die 180 Knoten antworten ungleichmäßig, und während sie antworten, sammelt der Koordinator die Informationen, die bereits von schnelleren Datenknoten „ausgespuckt“ wurden. Danach, wenn entweder alle Informationen eingegangen sind oder bei Erreichen eines Timeouts, liefert er alles direkt an den Kunden aus.
Das gesamte System bearbeitet im Durchschnitt Suchanfragen der letzten 48 Stunden in 300-400 ms, abgesehen von jenen Anfragen mit einem führenden Platzhalter.
„Blümchen“ mit Elasticsearch: Java-Konfiguration

Um sicherzustellen, dass alles so funktioniert, wie wir es ursprünglich wollten, haben wir unterschiedlichste Aspekte im Cluster intensiv getestet.
Ein Teil der entdeckten Probleme hing mit der standardmäßigen Java-Konfiguration in Elasticsearch zusammen.
Problem eins
Wir haben eine große Anzahl an Meldungen erhalten, dass auf Lucene-Ebene, während Hintergrundjobs ausgeführt werden, Lucene-Segment-Merges mit einem Fehler abschließen. In den Logs war zu sehen, dass es sich um einen OutOfMemoryError handelte. Laut Telemetriedaten war der Heap jedoch frei, sodass unklar blieb, warum diese Operation fehlschlug.
Es stellte sich heraus, dass die Merges der Lucene-Indizes außerhalb des Heaps stattfanden. Die Container waren in ihrem Ressourcenverbrauch stark limitiert. Nur der Heap passte in diese Ressourcen (der Wert heap.size war etwa gleich der RAM-Größe), während einige Off-Heap-Operationen mit einem Allocationsfehler abstürzten, wenn sie aus irgendwelchen Gründen die verbleibenden ~500 MB vor dem Limit nicht einhielten.
Die Lösung war ziemlich trivial: Der für den Container verfügbare RAM wurde erhöht, und danach haben wir vergessen, dass wir überhaupt solche Probleme hatten.
Das zweite Problem
Nach etwa 4-5 Tagen nach dem Start des Clusters bemerkten wir, dass die Datenknoten anfingen, sporadisch aus dem Cluster auszutreten und nach etwa 10-20 Sekunden wieder einzutreten.
Als wir anfingen, das Problem zu untersuchen, stellte sich heraus, dass der sogenannte Off-Heap-Speicher in Elasticsearch nahezu unkontrolliert bleibt. Als wir dem Container mehr Speicher gaben, erhielten wir die Möglichkeit, die Direct Buffer Pools mit unterschiedlichen Informationen zu füllen, die nur dann geleert wurden, wenn ein expliziter GC von Elasticsearch ausgelöst wurde.
In einigen Fällen dauerte dieser Vorgang ziemlich lange, und in der Zwischenzeit konnte der Cluster diesen Knoten bereits als ausgefallen markieren. Dieses Problem ist gut beschrieben .
Die Lösung war wie folgt: Wir beschränkten die Java-Möglichkeit, den größten Teil des Speichers außerhalb des Heaps für diese Operationen zu verwenden. Wir limitierten ihn auf 16 Gigabyte (-XX:MaxDirectMemorySize=16g), wodurch der explizite GC deutlich häufiger aufgerufen wurde und schneller ablief, wodurch er den Cluster nicht mehr destabilisierte.
Das dritte Problem
Wenn Sie denken, dass die Probleme mit "Knoten, die den Cluster im ungelegensten Moment verlassen" damit beseitigt sind, irren Sie sich.
Als wir die Arbeit mit Indizes konfigurierten, entschieden wir uns für mmapfs, um bei neuen Shards mit hoher Segmentierung. Das war ein ziemlicher grober Fehler, denn bei der Verwendung von mmapfs wird die Datei in den Arbeitsspeicher gemappt, und anschließend arbeiten wir mit der gemappten Datei. Dadurch ergibt sich, dass wir beim Versuch, den GC zu stoppen, sehr lange zum Safepoint brauchen, und auf dem Weg dorthin hört die Anwendung auf, auf die Anfragen des Masters zu antworten, ob sie noch aktiv ist. In der Folge geht der Master davon aus, dass der Knoten nicht mehr im Cluster vorhanden ist. Nach etwa 5–10 Sekunden wird der Garbage Collector aktiv, der Knoten erwacht, tritt wieder in den Cluster ein und beginnt mit der Initialisierung der Shards. All dies erinnerte stark an "die Produktion, die wir verdient haben" und war für etwas Ernsthaftes nicht geeignet.
Um dieses Verhalten zu vermeiden, sind wir zunächst auf den Standard niofs umgestiegen. Als wir dann von der fünften auf die sechste Version von Elastic migrierten, haben wir hybridfs ausprobiert, bei dem dieses Problem nicht auftrat. Details zu den Speichertypen finden Sie hier. .
Das vierte Problem
Dann gab es ein weiteres sehr interessantes Problem, das wir außergewöhnlich lange beheben mussten. Wir haben es über 2-3 Monate hinweg verfolgt, da das Muster völlig unklar war.
Manchmal gingen unsere Koordinatoren in den Full GC, normalerweise nachmittags, und kehrten nicht mehr zurück. Bei der Protokollierung der GC-Verzögerungen sah das so aus: Alles lief gut, gut, gut, und dann plötzlich — und alles war schlagartig schlecht.
Zunächst dachten wir, dass wir einen bösartigen Benutzer haben, der eine Anfrage ausführt, die den Koordinator aus dem Betriebsmodus wirft. Wir haben sehr lange die Anfragen protokolliert, um herauszufinden, was vor sich geht.
Am Ende stellte sich heraus, dass in dem Moment, in dem ein Benutzer eine sehr große Anfrage auslöst und diese auf einen bestimmten Elasticsearch-Koordinator gelangt, einige Knoten langsamer antworten als andere.
Während der Koordinator auf die Antworten aller Knoten wartet, speichert er die Ergebnisse, die von den bereits antwortenden Knoten gesendet wurden. Für die GC bedeutet das, dass sich unser Nutzungsmuster des Heaps sehr schnell ändert. Der GC, den wir verwendet haben, konnte mit dieser Aufgabe nicht umgehen.
Die einzige Lösung, die wir gefunden haben, um das Verhalten des Clusters in einer solchen Situation zu ändern, ist die Migration auf JDK13 und die Nutzung des Garbage Collectors Shenandoah. Das hat das Problem gelöst, unsere Koordinatoren hören auf abzustürzen.
Damit endeten die Probleme mit Java und es begannen die Probleme mit der Durchsatzrate.
Die ‚Kirschen‘ mit Elasticsearch: Durchsatzrate

Durchsatzprobleme bedeuten, dass unser Cluster stabil läuft, aber während der Spitzenzeiten der zu indexierenden Dokumente und bei Manövern die Leistung unzureichend ist.
Das erste bemerkte Symptom: Bei bestimmten ‚Ausbrüchen‘ in der Produktion, wenn eine sehr große Anzahl von Protokollen schnell generiert wird, erscheint in Graylog oft der Fehler der Indizierung es_rejected_execution.
Dies geschah, weil der thread_pool.write.queue auf einem Datenknoten standardmäßig nur 200 Anfragen zwischenspeichern kann, bevor Elasticsearch in der Lage ist, eine Indizierungsanfrage zu verarbeiten und die Informationen auf die Festplatte in einen Shard zu übertragen. Und in wird sehr wenig über diesen Parameter gesagt. Es wird lediglich die maximale Anzahl an Threads und die Standardgröße angegeben.
Natürlich haben wir diesen Wert angepasst und Folgendes herausgefunden: Speziell in unserem Setup können bis zu 300 Anfragen ziemlich gut zwischengespeichert werden, während höhere Werte dazu führen, dass wir erneut in eine Full GC-Phase geraten.
Darüber hinaus mussten wir auch Graylog anpassen, sodass es nicht häufig in kleinen Batch-Größen, sondern in großen Batches oder alle 3 Sekunden schreibt, falls der Batch noch nicht voll ist. In diesem Fall wird die Information, die wir in Elasticsearch schreiben, nicht nach zwei Sekunden, sondern nach fünf Sekunden verfügbar, was für uns vollkommen in Ordnung ist, während die Anzahl der Retries, die erforderlich sind, um ein großes Informationspaket durchzudrücken, verringert wird.
Dies ist besonders wichtig in den Momenten, in denen wir hier oder dort einen Ausfall haben, und dies mit Nachdruck meldet, um zu vermeiden, dass das Elastic komplett zugespammt wird und nach einer gewissen Zeit die Knoten von Graylog aufgrund überfüllter Puffer nicht mehr funktionieren.
Außerdem erhielten wir Beschwerden von Programmierern und Testern, wenn in der Produktion diese Explosionsprobleme auftraten: In dem Moment, in dem sie wirklich auf diese Logs angewiesen waren, wurden sie ihnen sehr langsam bereitgestellt.
Wir begannen zu analysieren. Einerseits war klar, dass sowohl die Suchanfragen als auch die Indexierungsanfragen im Grunde auf denselben physischen Maschinen verarbeitet werden, und dass es daher zu bestimmten Einbrüchen kommen würde.
Aber dies konnte teilweise umgangen werden, da in den sechsten Versionen von Elasticsearch ein Algorithmus eingeführt wurde, der es ermöglicht, Anfragen nicht zufällig im Round-Robin-Verfahren zwischen relevanten Datenknoten zu verteilen (ein Container, der mit der Indexierung beschäftigt ist und den Primary-Shard hält, kann sehr beschäftigt sein, sodass er nicht schnell antworten kann), sondern diese Anfrage an einen weniger belasteten Container mit Replica-Shard zu richten, der wesentlich schneller antwortet. Mit anderen Worten, wir haben uns für use_adaptive_replica_selection: true entschieden.
Das Bild des Lesens sieht nun so aus:
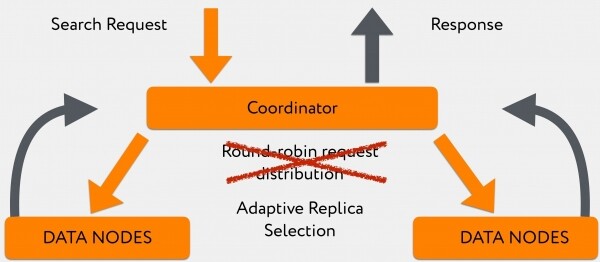
Der Übergang zu diesem Algorithmus hat die Abfragezeit erheblich verbessert, insbesondere wenn wir einen hohen Log-Schreibstrom hatten.
Das Hauptproblem bestand schließlich darin, das Datenzentrum schmerzfrei außer Betrieb zu nehmen.
Was wir von dem Cluster erwarteten, nachdem die Verbindung zu einem Rechenzentrum verloren ging:
- Wenn sich im ausgefallenen Rechenzentrum der aktuelle Master befindet, wird er ausgewählt und wechselt seine Rolle zu einem anderen Knoten in einem anderen Rechenzentrum.
- Der Master wird schnell alle nicht erreichbaren Knoten aus dem Cluster entfernen.
- Auf der Grundlage der verbleibenden Knoten wird er verstehen: Im verlorenen Rechenzentrum hatten wir bestimmte Primär-Shards, wird schnell die komplementären Replica-Shards in den verbleibenden Rechenzentren befördern, und die Datenindizierung wird fortgesetzt.
- Infolgedessen wird die Durchsatzleistung des Clusters für Schreiben und Lesen allmählich abnehmen, jedoch insgesamt wird alles, auch wenn es langsam, stabil funktionieren.
Wie sich herausstellte, wollten wir etwas in dieser Richtung:

Und erhielten Folgendes:

Wie ist das passiert?
Im Moment des Ausfalls des Rechenzentrums wurde der Master zu unserem Engpass.
Warum?
Der Master enthält einen TaskBatcher, der für die Verteilung bestimmter Aufgaben und Ereignisse im Cluster verantwortlich ist. Jeder Knotenabgang, jede Förderung eines Shards von Replica zu Primary und jede Aufgabe zur Erstellung eines Shards — all dies gelangt zunächst zum TaskBatcher, wo es sequenziell und in einem einzigen Prozess verarbeitet wird.
Beim Ausfall eines Rechenzentrums stellten alle verbleibenden Datenknoten in den überlebenden Rechenzentren fest, dass es ihre Pflicht war, dem Master zu berichten: "Wir haben bestimmte Shards und Datenknoten verloren."
Die überlebenden Datenknoten übermittelten diese Informationen an den aktuellen Master und warteten auf die Bestätigung, dass er sie erhalten hatte. Diese warteten jedoch vergebens, da der Master die Aufgaben schneller erhielt, als er antworten konnte. Die Knoten wiederholten die Anfragen nach Ablauf der Zeit, während der Master in der Zwischenzeit nicht mehr versuchte zu antworten, sondern vollständig mit der Sortierung der Anfragen nach Priorität beschäftigt war.
Im Terminaldaten führte es dazu, dass die Datennodes den Master so stark spammten, dass er in einen vollständigen Garbage Collection (GC) überging. Danach wechselte die Rolle des Masters zu einem anderen Node, wobei dasselbe Problem auftrat, und letztendlich fiel der Cluster komplett auseinander.
Wir führten Messungen durch und bis zur Version 6.4.0, in der dieses Problem behoben wurde, genügte es, gleichzeitig nur 10 von 360 Datennodes abzuschalten, um den gesamten Cluster zum Absturz zu bringen.
So sah das ungefähr aus:

Nach Version 6.4.0, in der dieser nervige Fehler behoben wurde, hörten die Datennodes auf, den Master zu töten. Aber klüger ist er dadurch nicht geworden. Konkret: Wenn wir 2, 3 oder 10 (jede Anzahl außer eins) Datennodes abschalten, erhält der Master eine erste Nachricht, die ihm mitteilt, dass Node A ausgefallen ist, und versucht, dies Node B, Node C und Node D zu erzählen.
Aktuell kann man nur mit einem Timeout für die Versuche, jemandem etwas zu berichten, kämpfen, der irgendwo zwischen 20 und 30 Sekunden liegt, und somit die Geschwindigkeit des Ausfalls des Datencenters aus dem Cluster steuern.
Im Prinzip erfüllt dies die Anforderungen, die ursprünglich an das Endprodukt im Rahmen des Projekts gestellt wurden, aber aus der Sicht der 'reinen Wissenschaft' handelt es sich um einen Bug. Dieser wurde übrigens erfolgreich von den Entwicklern in Version 7.2 behoben.
Wenn ein Datenknoten ausfiel, stellte sich heraus, dass es wichtiger war, die Informationen über seinen Ausfall zu verbreiten, als dem gesamten Cluster zu berichten, dass sich auf ihm bestimmte Primary-Shards befanden (um Replica-Shards in einem anderen Rechenzentrum auf Primary zu promoten, wo dann Informationen geschrieben werden konnten).
Deshalb werden die ausgefallenen Datenknoten nach dem 'Sturm' nicht sofort als stale markiert. Folglich müssen wir warten, bis alle Pings zu den ausgefallenen Datenknoten timeouten, und erst danach beginnt unser Cluster zu berichten, wo die Fortsetzung der Informationsaufzeichnung erforderlich ist. Weitere Details können hier gelesen werden. .
Letztendlich dauert der Ausfall eines Datenzentrums heute in der Hauptsaison etwa 5 Minuten. Für so eine große und unbewegliche Maschine ist das ein recht gutes Ergebnis.
Daher sind wir zu folgender Lösung gekommen:
- Wir haben 360 Datenknoten mit 700 Gigabyte Festplatten.
- 60 Koordinatoren für das Routing des Traffics über diese Datenknoten.
- 40 Master, die wir als Erbe aus Zeiten vor Version 6.4.0 behalten haben – um den Ausfall des Rechenzentrums zu überstehen, waren wir moralisch darauf vorbereitet, einige Maschinen zu verlieren, um selbst im schlimmsten Fall einen Master-Quorum zu haben.
- Jede Versuche, Rollen in einem Container zu kombinieren, scheiterten daran, dass irgendwann der Knoten unter der Last zerbrach.
- Im gesamten Cluster wird eine Heap-Größe von 31 Gigabyte verwendet: Alle Versuche, die Größe zu reduzieren, führten dazu, dass bei schweren Suchanfragen mit einem führenden Wildcard entweder Knoten abgestürzt sind oder der Circuit Breaker in Elasticsearch ausgelöst wurde.
- Darüber hinaus haben wir zur Sicherstellung der Suchleistung versucht, die Anzahl der Objekte im Cluster so gering wie möglich zu halten, um so wenig Ereignisse wie möglich an dem engsten Punkt, den wir im Master hatten, zu verarbeiten.
Zuletzt noch zur Überwachung.
Damit all dies so funktioniert, wie es gedacht war, überwachen wir Folgendes:
- Jeder Datenknoten meldet unserem Cloud-System, dass er vorhanden ist und welche Shards sich darauf befinden. Wenn wir irgendwo einen Knoten abschalten, berichtet das Cluster nach 2-3 Sekunden, dass wir in Rechenzentrum A die Knoten 2, 3 und 4 abgeschaltet haben – das bedeutet, dass wir in anderen Rechenzentren auf keinen Fall die Knoten abschalten können, auf denen sich Shards im Einzelnen befinden.
- Da wir das Verhalten des Masters genau kennen, achten wir sehr sorgfältig auf die Anzahl der ausstehenden Aufgaben. Selbst eine einzige hängende Aufgabe, die nicht rechtzeitig Zeitüberschreitung erhält, kann theoretisch in einer Notfallsituation der Grund sein, weshalb wir beispielsweise die Promotion des Replica-Shards in den Primary nicht umsetzen können, was zur Stilllegung der Indizierung führen würde.
- Wir achten auch sehr genau auf die Verzögerungen des Garbage Collectors, da wir damit bereits erhebliche Schwierigkeiten bei der Optimierung hatten.
- Rejects in den Threads, um im Voraus zu verstehen, wo das „Flaschenhals“ liegt.
- Und die Standardmetriken wie Heap, RAM und I/O.
Beim Aufbau des Monitorings müssen unbedingt die Besonderheiten des Thread Pools in Elasticsearch berücksichtigt werden. beschreibt die Konfigurationsmöglichkeiten und Standardwerte für Suche, Indizierung, erwähnt jedoch nicht das thread_pool.management. Diese Threads verarbeiten unter anderem Abfragen wie _cat/shards und ähnliche, die sich gut für das Monitoring eignen. Je größer der Cluster, desto mehr solcher Abfragen werden in einer bestimmten Zeit ausgeführt, und der erwähnte thread_pool.management ist nicht nur in der offiziellen Dokumentation nicht enthalten, sondern ist außerdem standardmäßig auf 5 Threads limitiert, was sehr schnell erschöpft ist und dazu führt, dass das Monitoring nicht mehr korrekt funktioniert.
Was ich abschließend sagen möchte: Wir haben es geschafft! Wir konnten unseren Programmierern und Entwicklern ein Werkzeug an die Hand geben, das in nahezu jeder Situation schnell und zuverlässig Informationen über das Geschehen in der Produktion bereitstellen kann.
Ja, es war ziemlich komplex, aber dennoch ist es uns gelungen, unsere Anforderungen in die bereits bestehenden Produkte zu integrieren, ohne diese patchen oder neu schreiben zu müssen.

Quelle: habr.com
