

Vor einiger Zeit standen wir vor der Herausforderung, ein ETL-Tool für die Arbeit mit Big Data auszuwählen. Die zuvor verwendete Lösung Informatica BDM entsprach nicht unseren Anforderungen aufgrund ihrer begrenzten Funktionalität. Ihre Nutzung reduzierte sich auf ein Framework zur Ausführung von spark-submit-Befehlen. Auf dem Markt gab es nicht viele Alternativen, die prinzipiell dazu in der Lage waren, mit dem Datenvolumen zu arbeiten, das wir täglich bearbeiten. Schließlich haben wir uns für Ab Initio entschieden. Bei den Pilotdemonstrationen zeigte das Produkt eine sehr hohe Datenverarbeitungsgeschwindigkeit. Informationen über Ab Initio in deutscher Sprache sind kaum verfügbar, daher haben wir beschlossen, unsere Erfahrungen auf Hub zu teilen.
Ab Initio verfügt über eine Vielzahl klassischer und außergewöhnlicher Transformationen, deren Code durch die eigene Sprache PDL erweitert werden kann. Für kleine Unternehmen könnte dieses mächtige Werkzeug wahrscheinlich überdimensioniert sein, und viele seiner Funktionen könnten teuer und ungenutzt bleiben. Wenn Ihr Maßstab jedoch den Größen der Sberbank nahekommt, könnte Ab Initio für Sie von Interesse sein.
Es hilft Unternehmen weltweit, Wissen zu sammeln und ein Ökosystem zu entwickeln, während es Entwicklern ermöglicht, ihre Fähigkeiten in ETL zu verbessern, ihre Shell-Kenntnisse zu vertiefen und die Möglichkeit bietet, die PDL-Sprache zu erlernen. Es bietet außerdem eine visuelle Darstellung der Ladeprozesse und vereinfacht die Entwicklung durch eine Fülle von funktionalen Komponenten.
In diesem Beitrag werde ich die Möglichkeiten von Ab Initio beschreiben und vergleichende Leistungsmerkmale im Umgang mit Hive und GreenPlum darlegen.
- Beschreibung des MDW-Frameworks und der Arbeiten zu seiner Feinabstimmung für GreenPlum.
- Vergleichende Leistungsmerkmale von Ab Initio im Umgang mit Hive und GreenPlum.
- Ab Initio im Einsatz mit GreenPlum im Near Real Time-Modus.
Die Funktionalität dieses Produkts ist sehr umfangreich und erfordert einiges an Zeit für das Studium. Mit den richtigen Fähigkeiten und optimalen Leistungsanpassungen können jedoch beeindruckende Verarbeitungsergebnisse erzielt werden. Die Verwendung von Ab Initio kann Entwicklern spannende Erfahrungen bieten. Es eröffnet einen neuen Blick auf die ETL-Entwicklung, eine Hybridlösung zwischen einer visuellen Umgebung und dem Schreiben von Ladeprozessen in einer scriptähnlichen Sprache.
Unternehmen entwickeln ihre Ökosysteme, und dieses Werkzeug kommt ihnen mehr denn je gelegen. Mit Ab Initio können sie Wissen über ihr aktuelles Geschäft ansammeln und dieses Wissen nutzen, um bestehende Geschäfte zu erweitern und neue zu eröffnen. Alternativen zu Ab Initio sind unter den visuellen Entwicklungsumgebungen Informatica BDM und unter den nicht-visuellen Umgebungen Apache Spark.
Beschreibung von Ab Initio
Ab Initio ist, wie andere ETL-Tools, eine Sammlung von Produkten.

Ab Initio GDE (Graphical Development Environment) ist eine Umgebung für Entwickler, in der sie Datenübertragungen konfigurieren und diese in Form von Pfeilverbindungen verbinden. Ein solches Set von Transformationen wird als Graph bezeichnet:
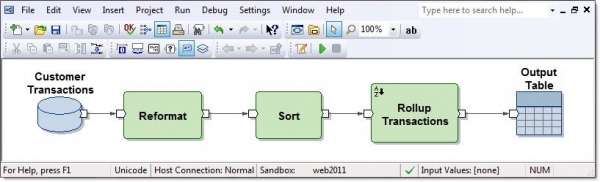
Die Eingangs- und Ausgangsverbindungen der funktionalen Komponenten sind Ports und enthalten Felder, die innerhalb der Transformationen berechnet werden. Mehrere Graphen, die durch Pfeilverbindungen in der Reihenfolge ihrer Ausführung verbunden sind, werden als Plan bezeichnet.
Es stehen mehrere Hundert funktionale Komponenten zur Verfügung, was eine beträchtliche Anzahl darstellt. Viele davon sind hochspezialisiert. Die Möglichkeiten der klassischen Transformationen in Ab Initio sind umfassender als in anderen ETL-Tools. Beispielsweise hat der Join mehrere Ausgaben. Neben dem Ergebnis des Join-Objekts können auch Einträge der Eingangsdaten, deren Schlüssel nicht verknüpft werden konnten, ausgegeben werden. Außerdem sind Rejects, Fehler und ein Protokoll der Transformation verfügbar, das in der gleichen Graphik als Textdatei gelesen und von anderen Transformationen verarbeitet werden kann.
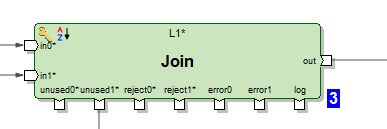
Oder man kann beispielsweise einen Datenempfänger in Form einer Tabelle materialisieren und in dieser Graphik Daten daraus lesen.
Es gibt originelle Transformationen. Zum Beispiel fungiert die Transformation Scan ähnlich wie analytische Funktionen. Es gibt Transformationen mit beschreibenden Namen: Create Data, Read Excel, Normalize, Sort within Groups, Run Program, Run SQL, Join with DB usw. Die Graphen können während der Ausführung Parameter verwenden, darunter auch die Möglichkeit, Parameter aus dem Betriebssystem zu übergeben oder in das Betriebssystem zu übermitteln. Dateien mit einem vorbereiteten Satz von übergebenen Parametern für die Graphik werden als Parameter Sets (psets) bezeichnet.
Wie es sich gehört, verfügt Ab Initio GDE über ein eigenes Repository, das als EME (Enterprise Meta Environment) bekannt ist. Entwickler haben die Möglichkeit, mit lokalen Codeversionen zu arbeiten und ihre Entwicklungen im zentralen Repository einzuchecken.
Es besteht die Möglichkeit, während oder nach der Ausführung des Graphen auf jeden verbindenden Transformationsfluss zu klicken und die Daten anzusehen, die zwischen diesen Transformationen übertragen wurden:
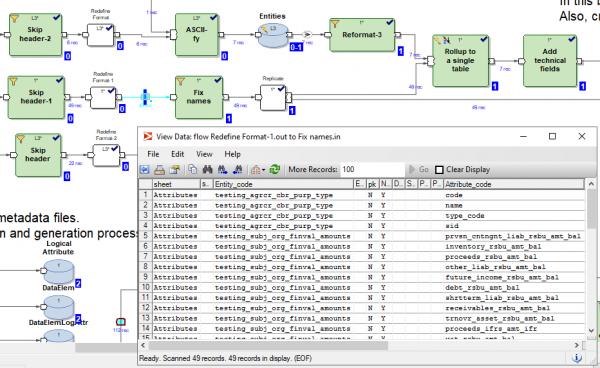
Zudem können Sie auf jeden Fluss klicken und die Tracking-Details einsehen – wie viele Parallelvorgänge die Transformation ausgeführt hat, wie viele Zeilen und Bytes in welcher der Parallelitäten geladen wurden:
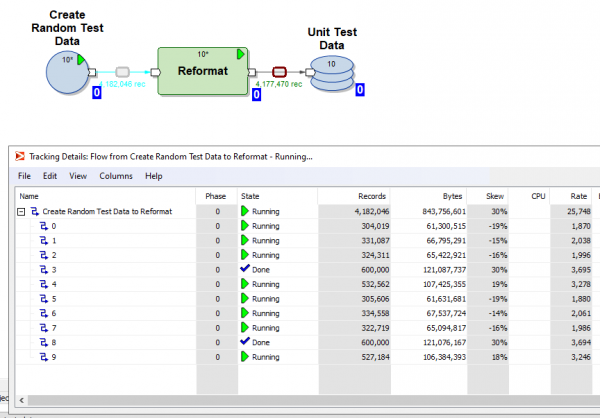
Es ist möglich, die Ausführung des Graphen in Phasen zu unterteilen und festzulegen, dass bestimmte Transformationen zuerst (in der Null-Phase) und die folgenden in der ersten Phase, dann in der zweiten Phase usw. ausgeführt werden müssen.
Für jede Transformation kann ein sogenannter Layout gewählt werden (wo sie ausgeführt wird): ohne Parallelität oder in parallelen Flüssen, deren Anzahl festgelegt werden kann. Dabei können temporäre Dateien, die Ab Initio während der Ausführung der Transformationen erstellt, sowohl im Dateisystem Serverals auch im HDFS abgelegt werden.
In jeder Transformation basierend auf der Standardvorlage kann ein eigenes Skript in der PDL-Sprache erstellt werden, das ein wenig an Shell erinnert.
Mit der PDL-Sprache können Sie die Funktionalität von Transformationen erweitern und insbesondere können Sie zur Laufzeit beliebige Codeausschnitte dynamisch generieren, abhängig von den Laufzeitparametern.
Darüber hinaus ist die Integration mit dem Betriebssystem über die Shell in Ab Initio gut ausgebaut. Konkret wird im Sberbank Linux ksh verwendet. Es ist möglich, Variablen mit der Shell auszutauschen und sie als Parameter für die Graphen zu verwenden. Sie können aus der Shell die Ausführung von Ab Initio-Graphen anstoßen und Ab Initio verwalten.
Neben Ab Initio GDE umfasst die Lieferung viele andere Produkte. Es gibt ein eigenes Co>Operation System, das den Anspruch erhebt, ein Betriebssystem zu sein. Es gibt das Control>Center, in dem Sie Zeitpläne für die Ladeflüsse erstellen und diese überwachen können. Es gibt Produkte für die Entwicklung auf einer primitiveren Ebene als das, was Ab Initio GDE ermöglicht.
Beschreibung des MDW-Frameworks und der Arbeiten zu seiner Feinabstimmung für GreenPlum.
Zusammen mit seinen Produkten bietet der Anbieter das Produkt MDW (Metadata Driven Warehouse) an, einen Graph-Configurator, der entwickelt wurde, um bei typischen Aufgaben zur Befüllung von Data Warehouses oder Data Vaults zu unterstützen.
Es enthält benutzerdefinierte (projektspezifische) Metadaten-Parser und vorkonfigurierte Code-Generatoren „out of the box“.
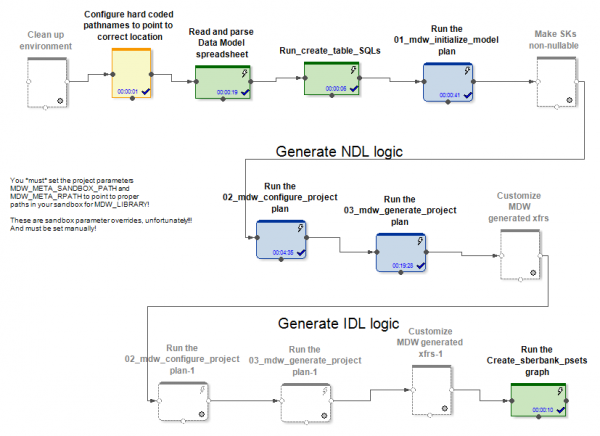
MDW erhält als Eingabe ein Datenmodell, eine Konfigurationsdatei zur Einrichtung der Datenbankverbindung (Oracle, Teradata oder Hive) sowie einige weitere Einstellungen. Der projektspezifische Teil kümmert sich beispielsweise um die Bereitstellung des Modells in der Datenbank. Der Standardteil des Produkts generiert Graphen und Konfigurationsdateien für die Datenladung in die Modelltabelle. Dabei werden Graphen (und psets) für verschiedene Modi der initialen und inkrementellen Aktualisierung von Entitäten erstellt.
In den Fällen von Hive und RDBMS werden unterschiedliche Graphen für die initiale und inkrementelle Datenaktualisierung generiert.
Im Fall von Hive werden die eingegangenen Delta-Daten mithilfe des Ab Initio Join mit den Daten verbunden, die vor dem Update in der Tabelle vorhanden waren. Die Datenladeprozesse in MDW (sowohl in Hive als auch in RDBMS) fügen nicht nur neue Daten aus dem Delta hinzu, sondern schließen auch die Gültigkeitszeiträume der Daten ab, für die das Delta eingegangen ist. Zudem muss der unveränderte Teil der Daten neu geschrieben werden. Dies ist notwendig, da es in Hive keine Delete- oder Update-Operationen gibt.
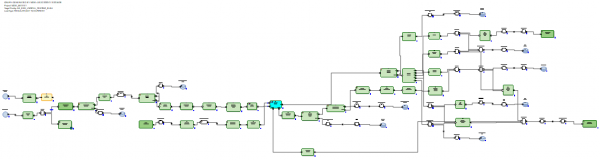
Im Fall von RDBMS hingegen sieht die graphische Darstellung der inkrementellen Datenaktualisierung optimierter aus, da RDBMS über echte Aktualisierungsmöglichkeiten verfügen.
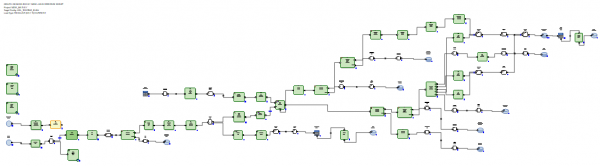
Das eingegangene Delta wird in eine Zwischentabelle in der Datenbank geladen. Anschließend erfolgt die Verbindung des Deltas mit den Daten, die vor dem Update in der Tabelle waren. Dies geschieht mittels SQL über eine generierte SQL-Abfrage. Danach erfolgt durch die SQL-Befehle Delete+Insert die Einspeisung neuer Daten aus dem Delta in die Zieltabelle und das Schließen der Gültigkeitszeiträume der Daten, für die das Delta eingegangen ist.
Es ist nicht notwendig, die unveränderten Daten neu zu schreiben.
Somit sind wir zu dem Schluss gekommen, dass im Falle von Hive MDW die gesamte Tabelle neu geschrieben werden muss, da Hive keine Update-Funktion hat. Eine vollständige Neukodierung der Daten ist beim Aktualisieren schlichtweg die beste Lösung. Bei RDBMS hingegen hielten es die Produktentwickler für notwendig, die Verbindung und Aktualisierung der Tabellen SQL zu überlassen.
Für das Projekt bei Sberbank haben wir eine neue wiederverwendbare Implementierung des Datenbank-Loaders für GreenPlum entwickelt. Diese basiert auf der Version, die MDW für Teradata generiert. Teradata war dafür besser geeignet und am nächsten dran, da es ebenfalls ein MPP-System ist. Die Arbeitsweise sowie die Syntax von Teradata und GreenPlum erwiesen sich als ähnlich.
Beispiele für kritische Unterschiede zwischen verschiedenen RDBMS, die für MDW relevant sind, sind wie folgt. In GreenPlum muss im Gegensatz zu Teradata beim Erstellen von Tabellen die Klausel
distributed byin Teradata verwendet man
löschen <table> all, während in GreenPlum geschrieben wird
löschen von <table>. In Oracle zur Optimierung schreibt man
delete from t where rowid in (), während man in Teradata und GreenPlum schreibt
delete from t where exists (select * from delta where delta.pk=t.pk)Außerdem ist zu beachten, dass für den Betrieb von Ab Initio mit GreenPlum der GreenPlum-Client auf allen Knoten des Ab Initio-Clusters installiert werden musste. Dies ist erforderlich, da wir uns von allen Knoten unseres Clusters gleichzeitig mit GreenPlum verbunden haben. Um die parallele Leseoperation aus GreenPlum zu gewährleisten und sicherzustellen, dass jeder parallele Ab Initio-Thread seinen eigenen Datensatz aus GreenPlum liest, musste eine für Ab Initio verständliche Konstruktion in den Abschnitt „where“ der SQL-Abfragen eingebaut werden.
where ABLOCAL()und der Wert dieser Konstruktion musste angegeben werden, indem der lesenden Transformation aus der Datenbank der Parameter zugewiesen wurde
ablocal_expr="string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))", die in etwas wie
mod(sk,10)=3kompiliert, was bedeutet, dass für jede Partition ein expliziter Filter für GreenPlum angegeben werden muss. Für andere Datenbanken (Teradata, Oracle) kann Ab Initio diese Parallelisierung automatisch durchführen.
Vergleichende Leistungsmerkmale von Ab Initio im Umgang mit Hive und GreenPlum.
Im Sberbank wurde ein Experiment zur Vergleichsanalyse der Leistung generierter MDW-Diagramme in Bezug auf Hive und GreenPlum durchgeführt. Im Rahmen des Experiments verfügte Hive über 5 Nodes im selben Cluster wie Ab Initio, während GreenPlum über 4 Nodes in einem separaten Cluster verfügte. Das bedeutet, dass Hive in Bezug auf die Hardware einen gewissen Vorteil gegenüber GreenPlum hatte.
Es wurden zwei Paare von Diagrammen betrachtet, die dieselbe Aufgabe für das Datenupdate in Hive und GreenPlum ausführen. Dabei wurden die Diagramme eingesetzt, die von dem MDW-Konfigurator generiert wurden:
- initiale Datenladung + inkrementelle Ladung zufällig generierter Daten in eine Hive-Tabelle
- initiale Datenladung + inkrementelle Ladung zufällig generierter Daten in eine entsprechende GreenPlum-Tabelle
In beiden Fällen (Hive und GreenPlum) wurden die Ladevorgänge in 10 parallelen Strömen im selben Cluster von Ab Initio ausgeführt. Die Zwischendaten für die Berechnungen wurden von Ab Initio in HDFS gespeichert (in Ab Initio-Begriffen wurde ein MFS-Layout unter Verwendung von HDFS genutzt). Eine Zeile zufällig generierter Daten belegte in beiden Fällen 200 Bytes.
Das Ergebnis war folgendes:
Hive:
Initiale Datenladung in Hive
Zeilen eingefügt
6 000 000
60 000 000
600 000 000
Dauer der Initialisierung
Ladezeiten in Sekunden
41
203
1 601
Inkrementelles Laden in Hive
Anzahl der Zeilen, die zu Beginn des Experiments in
der Ziel-Tabelle vorhanden waren
6 000 000
60 000 000
600 000 000
Anzahl der Delta-Zeilen, die während des Experiments auf
die Ziel-Tabelle angewendet wurden
6 000 000
6 000 000
6 000 000
Dauer des inkrementellen
Ladezeiten in Sekunden
88
299
2 541
GreenPlum:
Initiales Laden in GreenPlum
Zeilen eingefügt
6 000 000
60 000 000
600 000 000
Dauer der Initialisierung
Ladezeiten in Sekunden
72
360
3 631
Inkrementelles Laden in GreenPlum
Anzahl der Zeilen, die zu Beginn des Experiments in
der Ziel-Tabelle vorhanden waren
6 000 000
60 000 000
600 000 000
Anzahl der Delta-Zeilen, die während des Experiments auf
die Ziel-Tabelle angewendet wurden
6 000 000
6 000 000
6 000 000
Dauer des inkrementellen
Ladezeiten in Sekunden
159
199
321
Wir sehen, dass die Geschwindigkeit des initialen Ladevorgangs sowohl in Hive als auch in GreenPlum linear vom Datenvolumen abhängt und aufgrund besserer Hardware etwas schneller für Hive ist als für GreenPlum.
Das inkrementelle Laden in Hive hängt ebenfalls linear vom Volumen der zuvor geladenen Daten in der Ziel-Tabelle ab und verläuft mit steigendem Volumen relativ langsam. Dies liegt daran, dass die gesamte Ziel-Tabelle neu geschrieben werden muss. Das bedeutet, dass die Anwendung kleiner Änderungen auf große Tabellen für Hive nicht besonders sinnvoll ist.
Die inkrementelle Ladegeschwindigkeit in GreenPlum ist nur schwach vom Volumen der zuvor in der Zieltabelle geladenen Daten abhängig und verläuft relativ schnell. Dies wurde durch SQL Joins und die Architektur von GreenPlum ermöglicht, die die Löschoperation unterstützt.
GreenPlum speist daher die Delta-Daten durch delete+insert ein, während es in Hive keine delete- oder update-Operationen gibt. Deshalb musste der gesamte Datensatz bei inkrementellen Updates vollständig neu geschrieben werden. Besonders aussagekräftig ist der Vergleich der fett hervorgehobenen Zellen, da sie dem häufigsten Nutzungsszenario ressourcenintensiver Ladevorgänge entsprechen. Wir sehen, dass GreenPlum in diesem Test in einem Verhältnis von 1 zu 8 gegenüber Hive gewonnen hat.
Ab Initio im Einsatz mit GreenPlum im Near Real Time-Modus.
In diesem Experiment überprüfen wir die Möglichkeit von Ab Initio, die Tabelle GreenPlum mit zufällig generierten Datenportionen in einem nahezu Echtzeitmodus zu aktualisieren. Wir betrachten die Tabelle GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, mit der wir arbeiten werden.
Wir werden drei Ab Initio-Diagramme für die Arbeit mit dieser Tabelle verwenden:
1) Das Diagramm Create_test_data.mp – erstellt in 10 parallelen Strömen Dateien mit Daten in HDFS mit 6.000.000 Zeilen. Die Daten sind zufällig, ihre Struktur ist so organisiert, dass sie in unsere Tabelle eingefügt werden können.
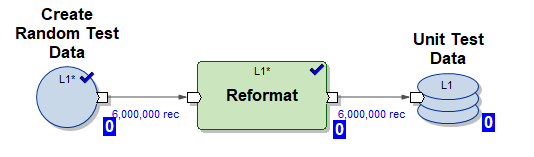

2) Grafik mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset – generierte MDW-Grafik für das initiale Einfügen von Daten in unsere Tabelle in 10 parallelen Streams (es werden Testdaten verwendet, die von der Grafik (1) generiert wurden)

3) Grafik mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset – generierte MDW-Grafik für das inkrementelle Update unserer Tabelle in 10 parallelen Streams unter Verwendung einer neuen Chargen von eingegangenen Daten (Deltas), die von der Grafik (1) generiert wurden
Wir führen das untenstehende Szenario im NRT-Modus aus:
- 6.000.000 Testzeilen generieren
- eine initiale Ladeoperation durchführen, um 6.000.000 Testzeilen in eine leere Tabelle einzufügen
- 5 Mal das inkrementelle Laden wiederholen
- 6.000.000 Testzeilen generieren
- eine inkrementelle Einfügung von 6.000.000 Testzeilen in die Tabelle vornehmen (wobei alten Daten die Gültigkeit valid_to_ts entzogen und frischere Daten mit demselben Primärschlüssel eingefügt werden)
Ein solches Szenario emuliert den Echtzeitbetrieb eines bestimmten Geschäftssystems – in Echtzeit tritt eine erhebliche Menge neuer Daten auf, die sofort in GreenPlum eingebracht wird.
Lassen Sie uns nun das Protokoll der Arbeit des Szenarios ansehen:
Start Create_test_data.input.pset am 2020-06-04 11:49:11
Finish Create_test_data.input.pset am 2020-06-04 11:49:37
Start mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:49:37
Finish mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:50:42
Start Create_test_data.input.pset am 2020-06-04 11:50:42
Finish Create_test_data.input.pset am 2020-06-04 11:51:06
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:51:06
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:53:41
Start Create_test_data.input.pset am 2020-06-04 11:53:41
Finish Create_test_data.input.pset am 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:56:51
Start Create_test_data.input.pset am 2020-06-04 11:56:51
Finish Create_test_data.input.pset am 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:59:55
Start Create_test_data.input.pset am 2020-06-04 11:59:55
Finish Create_test_data.input.pset am 2020-06-04 12:00:23
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 12:00:23
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 12:03:23
Start Create_test_data.input.pset am 2020-06-04 12:03:23
Finish Create_test_data.input.pset am 2020-06-04 12:03:49
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 12:03:49
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 12:06:46
Das ergibt folgendes Bild:
Grafik
Startzeit
Endzeit
Dauer
Create_test_data.input.pset
04.06.2020 11:49:11
04.06.2020 11:49:37
00:00:26
mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11:49:37
04.06.2020 11:50:42
00:01:05
Create_test_data.input.pset
04.06.2020 11:50:42
04.06.2020 11:51:06
00:00:24
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11:51:06
04.06.2020 11:53:41
00:02:35
Create_test_data.input.pset
04.06.2020 11:53:41
04.06.2020 11:54:04
00:00:23
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11:54:04
04.06.2020 11:56:51
00:02:47
Create_test_data.input.pset
04.06.2020 11:56:51
04.06.2020 11:57:14
00:00:23
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11:57:14
04.06.2020 11:59:55
00:02:41
Create_test_data.input.pset
04.06.2020 11:59:55
04.06.2020 12:00:23
00:00:28
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 12:00:23
04.06.2020 12:03:23
00:03:00
Create_test_data.input.pset
04.06.2020 12:03:23
04.06.2020 12:03:49
00:00:26
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 12:03:49
04.06.2020 12:06:46
00:02:57
Wir sehen, dass 6.000.000 inkrementeller Zeilen in 3 Minuten verarbeitet werden, was ziemlich schnell ist.
Die Daten in der Zieltabelle wurden wie folgt verteilt:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2; 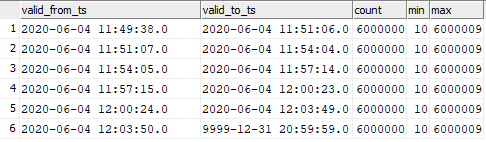
Es ist möglich, die Übereinstimmung der eingefügten Daten zum Zeitpunkt des Starts der Graphen zu erkennen.
Das bedeutet, dass die inkrementelle Datenladung in GreenPlum mit sehr hoher Frequenz in Ab Initio gestartet werden kann und wir eine hohe Geschwindigkeit beim Einfügen dieser Daten in GreenPlum beobachten können. Natürlich wird es nicht möglich sein, jede Sekunde zu starten, da Ab Initio, wie jedes ETL-Tool, beim Start Zeit zur "Eingewöhnung" benötigt.
Fazit
Aktuell wird Ab Initio von Sberbank zur Erstellung einer einheitlichen semantischen Datenschicht (ESS) verwendet. Dieses Projekt zielt darauf ab, eine konsolidierte Version des Zustands verschiedener bankenspezifischer Geschäftsobjekte zu schaffen. Die Informationen stammen aus unterschiedlichen Quellen, deren Replikate auf Hadoop vorbereitet werden. Auf Basis der geschäftlichen Anforderungen wird ein Datenmodell erstellt und die Daten-Transformationen werden beschrieben. Ab Initio lädt die Informationen in die ESS, und die geladenen Daten sind nicht nur von Interesse für das Geschäft selbst, sondern dienen auch als Quelle für die Erstellung von Datenvisualisierungen. Die Funktionalität des Produkts ermöglicht es, verschiedene Systeme (Hive, Greenplum, Teradata, Oracle) als Ziel zu nutzen, was es ermöglicht, die Daten ohne großen Aufwand in den benötigten Formaten für das Geschäft vorzubereiten.
Die Möglichkeiten von Ab Initio sind vielfältig. Beispielsweise ermöglicht das integrierte MDW-Framework, Datenhistorien für technische und geschäftliche Zwecke "out of the box" zu erstellen. Entwicklern bietet Ab Initio die Chance, "das Rad nicht neu zu erfinden" und aus einer Vielzahl von verfügbaren Funktionalitäten zu schöpfen, die im Wesentlichen als Bibliotheken zur Arbeit mit Daten dienen.
Autor – Experte der professionellen Gemeinschaft von Sberbank SberProfi DWH/BigData. Die SberProfi DWH/BigData-Gemeinschaft ist verantwortlich für die Entwicklung von Kompetenzen in Bereichen wie der Hadoop-Ökosystem, Teradata, Oracle DB, GreenPlum sowie BI-Tools wie Qlik, SAP BO, Tableau und weitere.
Quelle: habr.com
