


Zunehmend kommen solche Anfragen von Kunden: „Wir wollen es wie Amazon RDS, aber günstiger“; „Wir wollen es wie RDS, aber überall, in jeder Infrastruktur.“ Um eine solche verwaltete Lösung auf Kubernetes zu implementieren, haben wir uns den aktuellen Stand der beliebtesten Operatoren für PostgreSQL (Stolon, Operatoren von Crunchy Data und Zalando) angesehen und unsere Wahl getroffen.
Dieser Artikel stellt unsere Erfahrungen dar, sowohl aus theoretischer Sicht (ein Überblick über Lösungen) als auch aus praktischer Sicht (was wurde ausgewählt und was dabei herauskam). Aber zunächst definieren wir die allgemeinen Anforderungen an einen möglichen Ersatz für RDS ...
Was ist RDS?
Wenn man von RDS spricht, meint man unserer Erfahrung nach einen verwalteten DBMS-Dienst, der:
- einfach einzurichten;
- verfügt über die Fähigkeit, mit Snapshots zu arbeiten und diese wiederherzustellen (vorzugsweise mit Unterstützung für );
- ermöglicht die Erstellung von Master-Slave-Topologien;
- verfügt über eine umfangreiche Liste an Erweiterungen;
- Bietet Auditing und Benutzer-/Zugriffsverwaltung.
Im Allgemeinen können die Ansätze zur Umsetzung der Aufgabe sehr unterschiedlich sein, aber der Weg mit dem bedingten Ansible liegt uns nicht nahe. (Kollegen von 2GIS kamen zu einem ähnlichen Ergebnis.) Erstellen Sie ein „Postgres-basiertes Failover-Cluster-Rapid-Deployment-Tool“.)
Es sind die Operatoren, die den allgemein akzeptierten Ansatz zur Lösung solcher Probleme im Kubernetes-Ökosystem darstellen. Der technische Direktor von Flant hat bereits ausführlicher darüber in Bezug auf Datenbanken gesprochen, die in Kubernetes ausgeführt werden: In .
NB: Um schnell einfache Operatoren zu erstellen, empfehlen wir Ihnen, auf unser Open-Source-Dienstprogramm zu achten . Damit können Sie dies ohne Go-Kenntnisse tun, aber auf für Systemadministratoren vertrautere Weise: in Bash, Python usw.
Es gibt mehrere beliebte K8s-Operatoren für PostgreSQL:
- Stolon;
- Crunchy Data PostgreSQL-Operator;
- Zalando Postgres-Betreiber.
Schauen wir sie uns genauer an.
Betreiberauswahl
Zusätzlich zu den oben bereits genannten wichtigen Features haben wir – als Infrastrukturingenieure in Kubernetes – von den Betreibern auch Folgendes erwartet:
- Bereitstellen von Git und mit ;
- Pod-Anti-Affinitätsunterstützung;
- Knotenaffinität oder Knotenselektor installieren;
- Toleranzen festlegen;
- Verfügbarkeit von Tuning-Optionen;
- verständliche Technologien und sogar Befehle.
Ohne auf die einzelnen Punkte näher einzugehen (fragen Sie in den Kommentaren, wenn Sie nach dem Lesen des gesamten Artikels noch Fragen dazu haben), möchte ich im Allgemeinen darauf hinweisen, dass diese Parameter für eine subtilere Beschreibung der Spezialisierung von Clusterknoten in benötigt werden um sie für bestimmte Anwendungen zu bestellen. So erreichen wir die optimale Balance zwischen Leistung und Kosten.
Nun zu den PostgreSQL-Operatoren selbst.
1. Stolon
von der italienischen Firma Sorint.lab in galt unter den Betreibern als eine Art Standard für das DBMS. Dies ist ein ziemlich altes Projekt: Die erste öffentliche Veröffentlichung fand bereits im November 2015 (!) statt und das GitHub-Repository verfügt über fast 3000 Sterne und über 40 Mitwirkende.
Tatsächlich ist Stolon ein großartiges Beispiel für durchdachte Architektur:
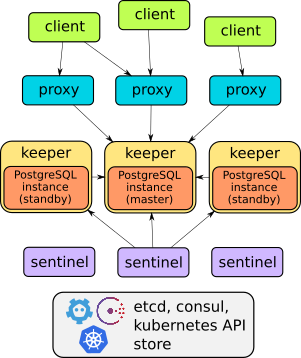
Das Gerät dieses Betreibers finden Sie im Detail im Bericht bzw . Im Allgemeinen genügt es zu sagen, dass es alles kann, was beschrieben wird: Failover, Proxy für transparenten Client-Zugriff, Backups ... Darüber hinaus ermöglichen Proxys den Zugriff über einen Endpunktdienst – im Gegensatz zu den beiden anderen unten diskutierten Lösungen (sie verfügen über zwei Dienste für den Zugriff). Base).
Allerdings Stolon , weshalb es nicht so bereitgestellt werden kann, dass es einfach und schnell – „wie warme Semmeln“ – ist, DBMS-Instanzen in Kubernetes zu erstellen. Die Verwaltung erfolgt über das Dienstprogramm stolonctl, Bereitstellung – über das Helm-Diagramm, und benutzerdefinierte werden in ConfigMap definiert.
Einerseits stellt sich heraus, dass der Operator nicht wirklich ein Operator ist (weil CRD nicht verwendet wird). Andererseits handelt es sich um ein flexibles System, mit dem Sie die Ressourcen in K8s nach Ihren Wünschen konfigurieren können.
Zusammenfassend lässt sich sagen, dass es für uns persönlich nicht der beste Weg zu sein schien, für jede Datenbank ein eigenes Diagramm zu erstellen. Also machten wir uns auf die Suche nach Alternativen.
2. Crunchy Data PostgreSQL-Operator
, ein junges amerikanisches Startup, schien eine logische Alternative zu sein. Seine öffentliche Geschichte beginnt mit der ersten Veröffentlichung im März 2017, seitdem hat das GitHub-Repository knapp 1300 Sterne und über 50 Mitwirkende erhalten. Die neueste Version vom September wurde auf die Zusammenarbeit mit Kubernetes 1.15-1.18, OpenShift 3.11+ und 4.4+, GKE und VMware Enterprise PKS 1.3+ getestet.
Die Crunchy Data PostgreSQL Operator-Architektur erfüllt auch die genannten Anforderungen:
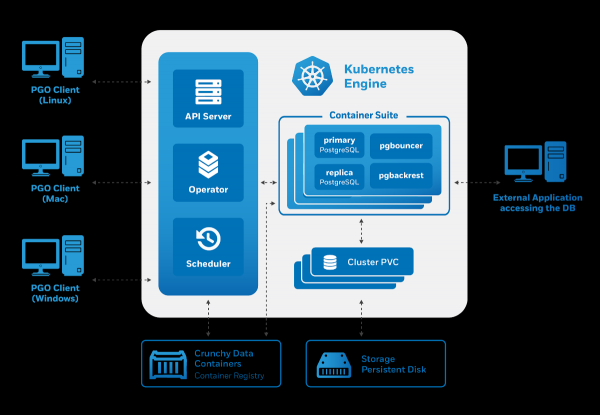
Die Verwaltung erfolgt über das Dienstprogramm pgoEs generiert jedoch wiederum benutzerdefinierte Ressourcen für Kubernetes. Deshalb hat uns der Betreiber als potenzielle Nutzer gefallen:
- es gibt Kontrolle durch CRD;
- komfortable Benutzerverwaltung (auch über CRD);
- Integration mit anderen Komponenten - eine spezielle Sammlung von Container-Images für PostgreSQL und Dienstprogramme für die Arbeit damit (einschließlich pgBackRest, pgAudit, Erweiterungen von contrib usw.).
Versuche, den Operator von Crunchy Data zu verwenden, zeigten jedoch mehrere Probleme:
- Es gab keine Möglichkeit von Toleranzen – es wird nur nodeSelector bereitgestellt.
- Die erstellten Pods waren Teil der Bereitstellung, obwohl wir eine zustandsbehaftete Anwendung bereitgestellt haben. Im Gegensatz zu StatefulSets können Deployments keine Festplatten erstellen.
Der letzte Fehler führt zu lustigen Momenten: In der Testumgebung ist es uns gelungen, 3 Replikate mit einer Festplatte auszuführen lokaler Speicher, woraufhin der Betreiber meldete, dass 3 Replikate funktionierten (obwohl dies nicht der Fall war).
Ein weiteres Merkmal dieses Operators ist seine vorgefertigte Integration mit verschiedenen Hilfssystemen. Es ist beispielsweise einfach, pgAdmin und pgBounce zu installieren Berücksichtigt werden vorkonfigurierte Grafana und Prometheus. In einem aktuellen Gesondert erwähnt wurde die verbesserte Integration in das Projekt , wodurch der Betreiber sofort eine visuelle Visualisierung der PgSQL-Metriken bietet.
Die seltsame Auswahl der von Kubernetes generierten Ressourcen veranlasste uns jedoch, eine andere Lösung zu finden.
3. Zalando Postgres-Betreiber
Zalando-Produkte sind uns schon lange bekannt: Wir haben Erfahrung mit Zalenium und natürlich haben wir es ausprobiert ist ihre beliebte HA-Lösung für PostgreSQL. Über den Schaffensansatz des Unternehmens erzählte einer seiner Autoren – Alexei Klyukin – in der Luft und es hat uns gefallen.
Dies ist die jüngste im Artikel besprochene Lösung: Die erste Veröffentlichung erfolgte im August 2018. Doch trotz der geringen Anzahl offizieller Veröffentlichungen hat das Projekt einen langen Weg zurückgelegt und übertrifft bereits jetzt die Popularität der Lösung von Crunchy Data mit 1300+ Sternen auf GitHub und der maximalen Anzahl an Mitwirkenden (70+).
„Unter der Haube“ dieses Betreibers kommen bewährte Lösungen zum Einsatz:
- Patroni und Zum Fahren,
- - für Backups,
- - als Verbindungspool.
So stellt sich die Betreiberarchitektur von Zalando vor:
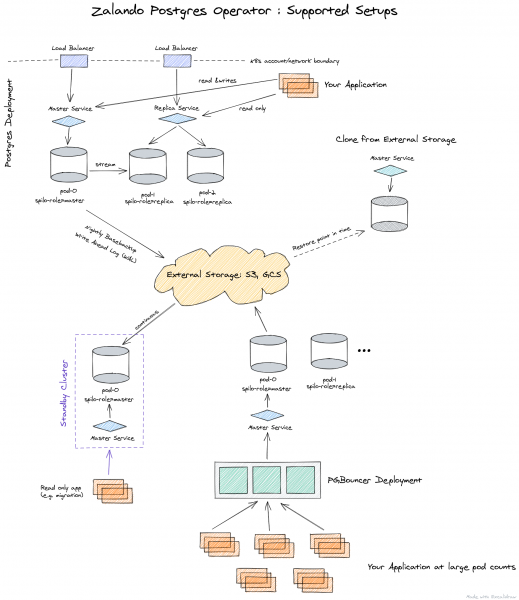
Der Operator wird vollständig über benutzerdefinierte Ressourcen verwaltet und erstellt automatisch ein StatefulSet aus Containern, das dann durch Hinzufügen verschiedener Sidecars zum Pod angepasst werden kann. All dies ist ein deutliches Plus im Vergleich zum Betreiber von Crunchy Data.
Da wir uns unter den drei in Betracht gezogenen Optionen für die Lösung von Zalando entschieden haben, wird im Folgenden eine weitere Beschreibung ihrer Fähigkeiten sowie unmittelbar die praktische Anwendung vorgestellt.
Üben Sie mit Postgres Operator von Zalando
Die Betreiberbereitstellung ist sehr einfach: Laden Sie einfach die neueste Version von GitHub herunter und wenden Sie YAML-Dateien aus dem Verzeichnis an . Alternativ können Sie auch verwenden .
Nach der Installation sollten Sie sich um die Einstellungen kümmern . Dies erfolgt über ConfigMap postgres-operator im Namespace, in dem Sie den Operator festlegen. Wenn die Repositorys konfiguriert sind, können Sie Ihren ersten PostgreSQL-Cluster bereitstellen.
Unsere Standardbereitstellung sieht beispielsweise so aus:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
Dieses Manifest stellt einen Cluster aus drei Instanzen mit einem Sidecar des Formulars bereit , von dem wir Anwendungsmetriken sammeln. Wie Sie sehen, ist alles sehr einfach und Sie können auf Wunsch eine buchstäblich unbegrenzte Anzahl von Clustern erstellen.
Es lohnt sich, darauf zu achten Webpanel für die Verwaltung - . Es wird mit dem Operator geliefert und ermöglicht Ihnen das Erstellen und Löschen von Clustern sowie die Arbeit mit Backups, die der Operator erstellt.
Liste der PostgreSQL-Cluster
Backup-Management
Ein weiteres interessantes Feature ist der Support . Dieser Mechanismus erstellt automatisch Rollen in PostgreSQL, basierend auf der resultierenden Liste von Benutzernamen. Anschließend können Sie über die API eine Liste von Benutzern zurückgeben, für die automatisch Rollen erstellt werden.
Probleme und Lösungen
Der Einsatz des Operators offenbarte jedoch bald mehrere erhebliche Nachteile:
- fehlende NodeSelector-Unterstützung;
- Unfähigkeit, Backups zu deaktivieren;
- Bei Verwendung der Funktion „Basen erstellen“ werden die Standardberechtigungen nicht angezeigt.
- In regelmäßigen Abständen ist die Dokumentation nicht ausreichend oder veraltet.
Glücklicherweise können viele davon gelöst werden. Fangen wir am Ende an – Probleme mit Dokumentation.
Höchstwahrscheinlich werden Sie feststellen, dass nicht immer klar ist, wie ein Backup registriert und ein Backup-Bucket mit der Operator-Benutzeroberfläche verbunden wird. Dies wird in der Dokumentation am Rande erwähnt, die eigentliche Beschreibung findet sich jedoch hier :
- du musst ein Geheimnis machen;
- Übergeben Sie es als Parameter an den Operator
pod_environment_secret_namein CRD mit Operatoreinstellungen oder in ConfigMap (je nachdem, wie Sie den Operator installieren möchten).
Wie sich jedoch herausstellte, ist dies derzeit nicht möglich. Deshalb haben wir gesammelt mit einigen zusätzlichen Drittentwicklungen. Mehr dazu – siehe unten.
Wenn Sie Parameter zur Sicherung an den Operator übergeben, nämlich - wal_s3_bucket und Zugriffsschlüssel in AWS S3, dann werde alles sichern: nicht nur in der Produktion, sondern auch in der Inszenierung. Es hat uns nicht gepasst.
In der Beschreibung der Parameter für Spilo, dem grundlegenden Docker-Wrapper für PgSQL bei Verwendung des Operators, stellte sich heraus, dass man einen Parameter übergeben kann WAL_S3_BUCKET leer, wodurch Backups deaktiviert werden. Darüber hinaus fand ich es zu großer Freude , was wir sofort in unseren Fork aufgenommen haben. Jetzt ist das Hinzufügen ganz einfach enableWALArchiving: false zu einer PostgreSQL-Clusterressource.
Ja, es war möglich, es anders zu machen, indem zwei Operatoren ausgeführt wurden: einer für die Bereitstellung (ohne Backups) und der zweite für die Produktion. Aber wir konnten mit einem auskommen.
Ok, wir haben gelernt, wie man den Zugriff für S3 auf die Datenbanken überträgt und Backups in den Speicher gelangen. Wie funktionieren Sicherungsseiten in der Operator-Benutzeroberfläche?

In der Operator-Benutzeroberfläche müssen Sie drei Variablen hinzufügen:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
Danach wird die Backup-Verwaltung verfügbar, die in unserem Fall die Arbeit mit dem Staging vereinfacht und es Ihnen ermöglicht, Slices aus der Produktion ohne zusätzliche Skripte dorthin zu liefern.
Als weiteres Plus wurden die Arbeit mit der Teams-API und umfangreiche Möglichkeiten zum Erstellen von Datenbanken und Rollen mithilfe der Tools des Betreibers genannt. Allerdings im Entstehen Rollen hatten standardmäßig keine Rechte. Dementsprechend konnte ein Benutzer mit Leserechten keine neuen Tabellen lesen.
Warum so? Obwohl im Code notwendig GRANTSie werden nicht immer angewendet. Es gibt 2 Methoden: syncPreparedDatabases и syncDatabases. In syncPreparedDatabases - trotz der Tatsache, dass in der Sektion preparedDatabases Es gibt eine Bedingung defaultRoles и defaultUsers Zum Erstellen von Rollen werden keine Standardrechte angewendet. Wir bereiten gerade einen Patch vor, damit diese Rechte automatisch angewendet werden.
Und der letzte Moment der für uns relevanten Verbesserungen - A, das dem generierten StatefulSet eine Knotenaffinität hinzufügt. Unsere Kunden ziehen es häufig vor, Kosten durch den Einsatz von Spot-Instanzen zu senken, für die es sich eindeutig nicht lohnt, Datenbankdienste zu hosten. Dieses Problem könnte durch Toleranzen gelöst werden, aber das Vorhandensein von Node Affinity gibt mehr Vertrauen.
Was ist passiert?
Als Ergebnis der Lösung der oben genannten Probleme haben wir den Postgres-Operator von Zalando übernommen Wohin geht es mit so nützlichen Patches? Und der Einfachheit halber haben wir auch gesammelt .
Liste der in den Fork aufgenommenen PRs:
- ;
- ;
- ;
- .
Es wäre großartig, wenn die Community diese PRs unterstützen würde, damit sie mit der nächsten Version des Betreibers (1.6) upstream werden.
Bonus! Erfolgsgeschichte der Produktionsmigration
Wenn Sie Patroni nutzen, kann die Live-Produktion mit minimaler Ausfallzeit zum Betreiber migriert werden.
Mit Spilo können Sie Standby-Cluster über S3-Speicher erstellen wenn das PgSQL-Binärprotokoll zuerst in S3 gespeichert und dann vom Replikat ausgegeben wird. Aber was ist, wenn ja? nicht Wird von Wal-E in alter Infrastruktur verwendet? Die Lösung für dieses Problem gibt es bereits auf der Nabe.
Abhilfe schafft die logische PostgreSQL-Replikation. Wir gehen jedoch nicht näher auf die Erstellung von Publikationen und Abonnements ein, da ... unser Plan gescheitert ist.
Tatsache ist, dass die Datenbank über mehrere geladene Tabellen mit Millionen von Zeilen verfügte, die zudem ständig aufgefüllt und gelöscht wurden. с copy_dataWenn das neue Replikat den gesamten Inhalt vom Master kopiert, kann es einfach nicht mit dem Master mithalten. Das Kopieren von Inhalten funktionierte eine Woche lang, holte aber nie den Meister ein. Letztendlich hat es geholfen, das Problem zu lösen Kollegen von Avito: Sie können Daten mit übertragen pg_dump. Ich werde unsere (leicht modifizierte) Version dieses Algorithmus beschreiben.
Die Idee besteht darin, dass Sie ein deaktiviertes Abonnement an einen bestimmten Replikationsslot binden und dann die Transaktionsnummer festlegen können. Es gab Nachbildungen für Produktionsarbeiten. Dies ist wichtig, da das Replikat dazu beiträgt, einen konsistenten Dump zu erstellen und weiterhin Änderungen vom Master zu erhalten.
Nachfolgende Befehle, die den Migrationsprozess beschreiben, verwenden die folgende Notation für Hosts:
- führen zu — Quellserver;
- Replikat1 - Streaming-Nachbildung der alten Produktion;
- Replikat2 - eine neue logische Replik.
Migrationsplan
1. Erstellen Sie im Assistenten ein Abonnement für alle Tabellen im Schema public zu erhalten. dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Erstellen Sie einen Replikationsslot auf dem Master:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Stoppen Sie die Replikation auf dem alten Replikat:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Holen Sie sich die Transaktionsnummer vom Master:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Entsorgen Sie die alte Replik. Wir werden dies in mehreren Threads tun, um den Prozess zu beschleunigen:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Laden Sie den Dump auf den neuen Server hoch:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. Nachdem Sie den Dump heruntergeladen haben, können Sie die Replikation auf dem Streaming-Replikat starten:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Erstellen Sie ein Abonnement für ein neues logisches Replikat:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Holen oid Abonnements:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Nehmen wir an, es wurde empfangen oid=1000. Wenden wir die Transaktionsnummer auf das Abonnement an:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Beginnen wir mit der Replikation:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Überprüfen Sie den Abonnementstatus. Die Replikation sollte funktionieren:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. Nachdem die Replikation gestartet und die Datenbanken synchronisiert sind, können Sie wechseln.
13. Nachdem Sie die Replikation deaktiviert haben, müssen Sie die Sequenzen korrigieren. Es ist gut beschrieben .
Dank dieses Plans verlief die Umstellung mit minimalen Verzögerungen.
Fazit
Mit Kubernetes-Operatoren können Sie verschiedene Aktionen vereinfachen, indem Sie sie auf die Erstellung von K8s-Ressourcen reduzieren. Da mit ihrer Hilfe jedoch eine bemerkenswerte Automatisierung erreicht wurde, sollte man bedenken, dass sie auch eine Reihe unerwarteter Nuancen mit sich bringen kann. Wählen Sie Ihre Operatoren daher mit Bedacht aus.
Nachdem wir die drei beliebtesten Kubernetes-Operatoren für PostgreSQL überprüft hatten, entschieden wir uns für das Projekt von Zalando. Wir mussten einige Schwierigkeiten damit überwinden, aber das Ergebnis war wirklich erfreulich, weshalb wir planen, diese Erfahrung auf einige andere Installationen von PgSQL auszudehnen. Wenn Sie Erfahrung mit ähnlichen Lösungen haben, freuen wir uns über die Details in den Kommentaren!
PS
Lesen Sie auch auf unserem Blog:
- «";
- «";
- «".
Source: habr.com
