

Hallo, ich bin Dmitrij Krasnov. Seit über fünf Jahren beschäftige ich mich mit der Administration von Kubernetes-Clustern und dem Aufbau komplexer Microservices-Architekturen. Zu Beginn dieses Jahres haben wir einen Service zur Verwaltung von Kubernetes-Clustern auf Basis von Containerum gestartet. Ich möchte die Gelegenheit nutzen, um zu erklären, was Kubernetes ist und wie sich die Integration mit einem Anbieter von Open Source unterscheidet.
Zunächst, was ist ? Es handelt sich um ein System zur Verwaltung von Containern auf einer Vielzahl von Hosts. Interessanterweise bedeutet das Wort aus dem Griechischen „Steuermann“ oder „Fahrer“. Ursprünglich von Google entwickelt, wurde es als technologischer Beitrag an die Cloud Native Computing Foundation übergeben, eine internationale Non-Profit-Organisation, die führende Entwickler, Endbenutzer und Anbieter von Containotechnologien vereint.

Die Steuerung einer großen Anzahl von Containern
Lassen Sie uns nun klären, was diese Container eigentlich sind. Es handelt sich um Anwendungen zusammen mit ihrer gesamten Umgebung – hauptsächlich die Bibliotheken, von denen die Funktionalität des Programms abhängt. All dies ist in Archiven verpackt und liegt als Image vor, das unabhängig vom Betriebssystem gestartet und getestet werden kann. Doch es gibt ein Problem – die Verwaltung von Containern auf einer großen Anzahl von Hosts gestaltet sich als sehr kompliziert. Daher wurde Kubernetes entwickelt.
Ein Container-Image umfasst die Anwendung sowie ihre Abhängigkeiten. Die Anwendung, ihre Abhängigkeiten und das Dateisystem-Image des Betriebssystems befinden sich in verschiedenen Teilen des Images, den sogenannten Schichten. Diese Schichten können für unterschiedliche Container wiederverwendet werden. Zum Beispiel kann für alle Anwendungen im Unternehmen eine Basis-Schicht von Ubuntu verwendet werden. Bei der Ausführung von Containern besteht nicht die Notwendigkeit, viele Kopien einer Basis-Schicht auf dem Host zu speichern. Dies trägt zur Optimierung der Speicherung und Lieferung von Images bei.
Wenn wir eine Anwendung aus einem Container starten möchten, werden die benötigten Schichten übereinandergelegt und es entsteht ein Overlay-Dateisystem. Oben wird eine Schreibschicht hinzugefügt, die beim Stoppen des Containers gelöscht wird. Dies stellt sicher, dass beim Start des Containers die Anwendung immer die gleiche Umgebung hat, die nicht verändert werden kann. Damit wird die Reproduzierbarkeit der Umgebung auf verschiedenen Host-OS gewährleistet. Egal ob Ubuntu oder CentOS – die Umgebung bleibt immer gleich. Zudem ist der Container durch die im Linux-Kernel integrierten Mechanismen vom Host isoliert. Anwendungen im Container sehen die Dateien und Prozesse des Hosts sowie angrenzender Container nicht. Eine solche Isolation der Anwendungen vom Host-OS bietet eine zusätzliche Sicherheitsebene.
Für die Verwaltung von Containern auf dem Host gibt es eine Vielzahl von Werkzeugen. Das bekannteste unter ihnen ist Docker. Es ermöglicht den vollständigen Lebenszyklus von Containern. Allerdings funktioniert es nur auf einem einzelnen Host. Bei der Notwendigkeit, Container auf mehreren Hosts zu verwalten, kann Docker das Leben der Ingenieure zur Hölle machen. Daher wurde Kubernetes entwickelt.
Die Nachfrage nach Kubernetes beruht gerade auf der Fähigkeit, Containergruppen über mehrere Hosts hinweg als einheitliche Entitäten zu steuern. Die Beliebtheit des Systems ermöglicht den Aufbau von DevOps oder Development Operations, bei denen Kubernetes zur Durchführung von Prozessen innerhalb von DevOps eingesetzt wird.
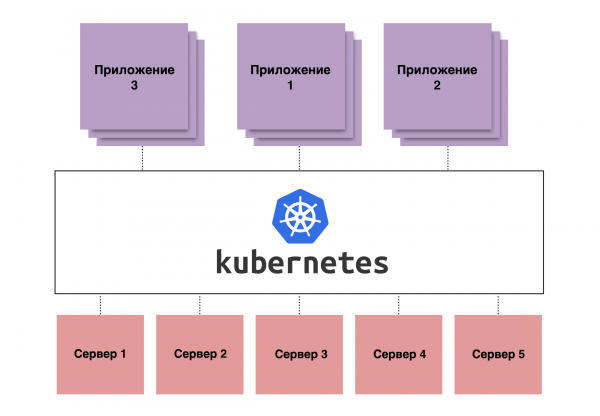
Abbildung 1. Schematische Darstellung des Funktionsprinzips von Kubernetes
Vollständige Automatisierung
DevOps stellt im Grunde die Automatisierung des Entwicklungsprozesses dar. Vereinfacht gesagt, schreiben Entwickler Code, der in ein Repository hochgeladen wird. Anschließend kann dieser Code automatisch in einen Container mit allen Bibliotheken gebaut, getestet und in die nächste Phase – Staging – überführt werden, bevor er schließlich in die Produktion geht.
Kubernetes ermöglicht in Verbindung mit DevOps die Automatisierung dieses Prozesses, sodass er nahezu ohne Eingriff der Entwickler abläuft. Dadurch wird der Build-Prozess erheblich beschleunigt, da der Entwickler sich nicht mehr um die Ausführung auf seinem Computer kümmern muss. Er schreibt einfach einen Codeabschnitt, pusht diesen in das Repository, woraufhin ein Pipeline-Prozess gestartet wird, der den Build, Tests und das Deployen umfassen kann. Dies geschieht mit jedem Commit, was bedeutet, dass die Tests kontinuierlich erfolgen.
Die Nutzung von Containern sorgt zudem dafür, dass die gesamte Umgebung dieser Anwendung genau in der Version in die Produktion überführt wird, in der sie auch getestet wurde. Probleme wie "im Test gab es andere Versionen als in der Produktion" werden so vermieden, da alles konsistent bleibt. Angesichts des aktuellen Trends zu mikrodienstearchitektur, bei dem statt einer einzigen großen Anwendung Hunderte kleinerer Anwendungen betrieben werden, wäre es unpraktikabel, diese manuell zu verwalten, da dies einen riesigen Personalaufwand erfordern würde. Aus diesem Grund setzen wir auf Kubernetes.
Vorteile, Vorteile, Vorteile
Wenn es um die Vorteile von Kubernetes als Plattform geht, hat es erhebliche Pluspunkte in Bezug auf die Verwaltung einer Microservices-Architektur.
- Verwaltung mehrerer Replikate. Das Wichtigste ist die Verwaltung von Containern über mehrere Hosts hinweg. Und noch wichtiger ist die Verwaltung vieler Replikate von Anwendungen in Containern als eine einzige Einheit. Dadurch müssen sich die Ingenieure nicht um jeden einzelnen Container kümmern. Wenn ein Container ausfällt, erkennt Kubernetes dies und startet ihn erneut.
- Cluster-Netzwerk. Kubernetes verfügt auch über ein sogenanntes Cluster-Netzwerk mit einem eigenen Adressraum. Dadurch hat jedes Pod seine eigene Adresse. Ein Pod ist die kleinste strukturelle Einheit im Cluster, in der Container direkt ausgeführt werden. Außerdem bietet Kubernetes Funktionen, die Lastenausgleich und Service Discovery kombinieren. Dies ermöglicht es, die manuelle Verwaltung von IP-Adressen zu vermeiden und diese Aufgabe Kubernetes zu übertragen. Automatische Health-Checks helfen, Probleme zu erkennen und den Verkehr auf funktionierende Pods umzuleiten.
- Verwaltung von Konfigurationen. Bei der Verwaltung einer Vielzahl von Anwendungen wird es schwierig, die Anwendungs Konfiguration zu steuern. Dafür bietet Kubernetes spezielle Ressourcen, die ConfigMaps. Sie ermöglichen die zentrale Speicherung von Konfigurationen und deren Einbindung in Pods beim Starten von Anwendungen. Dieses System gewährleistet die Konsistenz der Konfiguration, egal ob bei zehn oder hundert Replikaten von Anwendungen.
- Persistente Volumes. Container sind von Natur aus unveränderlich, und wenn ein Container gestoppt wird, werden alle auf dem Dateisystem gespeicherten Daten gelöscht. Einige Anwendungen speichern jedoch Daten direkt auf der Festplatte. Um dieses Problem zu lösen, bietet Kubernetes Funktionen zur Verwaltung des Speichers — persistente Volumes. Dieser Mechanismus verwendet externen Speicher für Daten und kann Containern persistente, block- oder dateibasierte Speicherressourcen bereitstellen. Diese Lösung ermöglicht es, Daten getrennt von den Workern zu speichern, was sie im Fall eines Ausfalls der Worker schützt.
- Lastenverteilung. Obwohl wir in Kubernetes mit abstrakten Entitäten wie Deployment, StatefulSet usw. arbeiten, werden letztendlich die Container auf normaler Hardware ausgeführt. virtuellen Maschinen wurde vereinfacht. oder physische Server. Sie sind nicht perfekt und können jederzeit ausfallen. Kubernetes erkennt das und leitet den internen Verkehr an andere Replikate weiter. Doch was ist mit dem Verkehr, der von außen kommt? Wenn der Verkehr einfach an einen der Worker geleitet wird, wird der Service im Falle eines Ausfalls nicht verfügbar sein. Um dieses Problem zu lösen, verfügt Kubernetes über Dienste wie Load Balancer. Diese sind für die automatische Konfiguration eines externen Cloud-Balancers auf alle Worker im Cluster vorgesehen. Dieser externe Balancer leitet den externen Verkehr zu den Workern weiter und überwacht ihren Status. Wenn einer oder mehrere Worker nicht mehr verfügbar sind, wird der Verkehr auf andere umgeleitet. So können hochverfügbare Dienste mit Kubernetes erstellt werden.
Kubernetes zeigt seine Stärke am besten bei der Bereitstellung von Mikrodiensten. Es ist möglich, das System in eine klassische Architektur zu implementieren, aber es wäre ineffektiv. Wenn eine Anwendung nicht in mehreren Replikaten betrieben werden kann, was bringt dann der Einsatz von Kubernetes?
Open Source Kubernetes
Open-Source Kubernetes – eine großartige Lösung: einfach installieren und loslegen. Es lässt sich auf eigener Hardware und Infrastruktur bereitstellen, mit einem Master und Nodes, auf denen alle Anwendungen laufen. Und das Beste daran: Es ist völlig kostenlos. Es gibt jedoch einige wichtige Punkte zu beachten.
- Erstens – der hohe Wissens- und Erfahrungshorizont, den Administratoren und Ingenieuren erforderlich ist, die alles einrichten und betreuen. Da der Kunde vollständige Kontrolle über den Cluster hat, trägt er selbst die Verantwortung für dessen Funktionsfähigkeit. Und es ist sehr einfach, alles zu ruinieren.
- Zweitens – das Fehlen von Integrationen. Wenn Sie Kubernetes ohne eine gängige Virtualisierungsplattform starten, erhalten Sie nicht alle Vorteile des Programms, wie z.B. die Nutzung von Persistent Volumes und Load Balancer-Diensten.
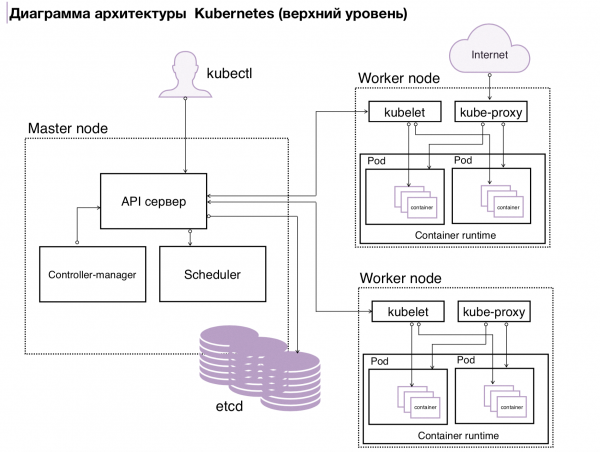
Abbildung 2. k8s-Architektur
Kubernetes vom Anbieter
Die Integration mit einem Cloud-Anbieter bietet zwei Möglichkeiten:
- Erstens, der Benutzer kann einfach auf die Schaltfläche „Cluster erstellen“ klicken und einen bereits konfigurierten, einsatzbereiten Cluster erhalten.
- Zweitens, der Anbieter installiert selbst den Cluster und konfiguriert die Integration mit der Cloud.
So funktioniert es bei uns. Ein Ingenieur, der einen Cluster einrichtet, gibt an, wie viele Worker er benötigt und mit welchen Spezifikationen (zum Beispiel 5 Worker, jeweils mit 10 CPU, 16 GB RAM und sagen wir, 100 GB Speicherplatz). Danach erhält er Zugang zum bereits konfigurierten Cluster. Die Worker, auf denen die Last ausgeführt wird, stehen dabei vollständig dem Kunden zur Verfügung, jedoch bleibt die gesamte Management-Ebene in der Verantwortung des Anbieters (sofern der Service im Rahmen eines Managed Service bereitgestellt wird).
Diese Struktur hat jedoch ihre Nachteile. Da die Management-Ebene beim Anbieter bleibt, gewährt dieser dem Kunden keinen vollständigen Zugriff, was die Flexibilität bei der Arbeit mit Kubernetes einschränkt. Manchmal möchte der Kunde spezifische Funktionen wie LDAP-Authentifizierung in Kubernetes integrieren, aber die Konfiguration der Management-Ebene erlaubt das nicht.
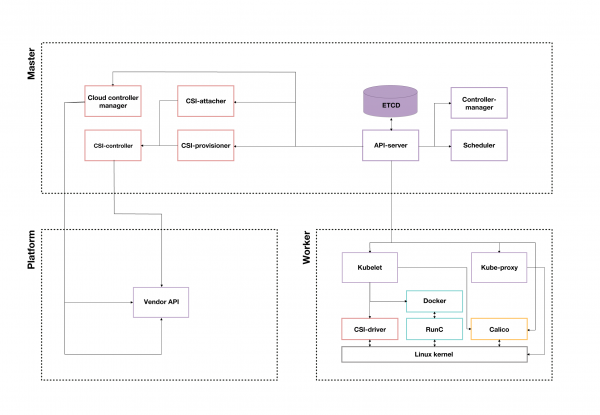
Abbildung 3. Beispiel eines Kubernetes-Clusters von einem Cloud-Anbieter
Was wählen: Open Source oder Anbieter-Lösung?
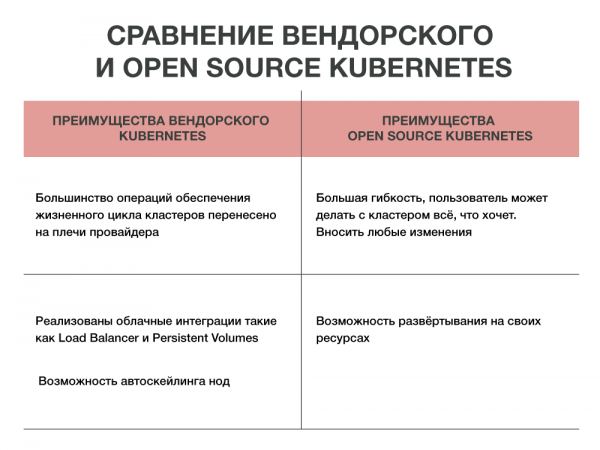
Also, Open Source Kubernetes oder vendor-basiert? Wenn man Open Source Kubernetes wählt, kann der Benutzer damit machen, was er will. Doch dabei besteht die Gefahr, sich selbst ins Bein zu schießen. Bei der vendor-basierten Lösung ist das komplizierter, da alles im Unternehmen durchdacht und eingerichtet ist. Der größte Nachteil von Open Source Kubernetes ist der Bedarf an Fachkräften. Mit einer Vendor-Lösung entfällt dieser Kopfzer brechende Aspekt, aber das Unternehmen muss entscheiden: Soll es seine eigenen Spezialisten bezahlen oder den Anbieter?
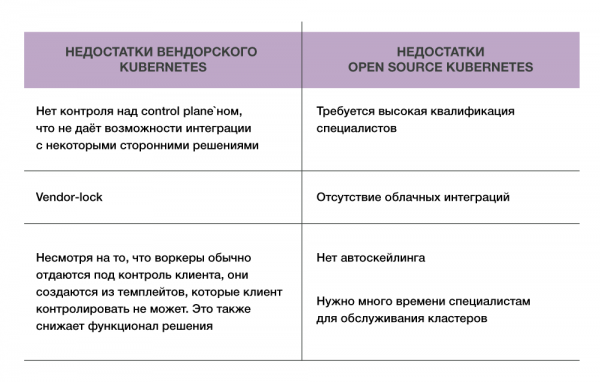
Nun, die Vorteile sind offensichtlich, die Nachteile ebenfalls bekannt. Eines bleibt unverändert: Kubernetes löst zahlreiche Probleme, indem es das Management vieler Container automatisiert. Welche Lösung man wählt, ob Open Source oder vendor-basiert, entscheidet jeder für sich selbst.
Der Artikel wurde von Dmitry Krasnov, dem leitenden Architekten des Containerum-Dienstes der Anbieter #CloudMTS, verfasst.
Quelle: habr.com
