

Hinweis.: Dieser Artikel, geschrieben von Galo Navarro, der die Position des Principal Software Engineer bei dem europäischen Unternehmen Adevinta innehat, ist eine faszinierende und lehrreiche „Untersuchung“ im Bereich der Infrastrukturnutzung. Der ursprüngliche Titel wurde im Übersetzungsprozess leicht erweitert, aus Gründen, die der Autor zu Beginn erklärt.
Anmerkung des Autors: Diese Veröffentlichung scheint Viel mehr Aufmerksamkeit, als erwartet. Ich erhalte immer noch wütende Kommentare darüber, dass der Titel des Artikels irreführend ist und dass einige Leser enttäuscht sind. Ich verstehe die Gründe dafür, weshalb ich, trotz des Risikos, die gesamte Spannung zu verderben, gleich zu Beginn erzählen möchte, worum es in diesem Artikel geht. Bei der Umstellung von Teams auf Kubernetes beobachte ich eine interessante Sache: Jedes Mal, wenn ein Problem auftritt (zum Beispiel steigende Latenzen nach der Migration), wird Kubernetes als erstes beschuldigt, doch später stellt sich heraus, dass der Orchestrator nicht schuld ist. Dieser Artikel erzählt von einem solchen Fall. Sein Titel wiederholt den Ausruf eines unserer Entwickler (später werden Sie sehen, dass Kubernetes hier wirklich nichts damit zu tun hat). Sie werden darin keine unerwarteten Offenbarungen über Kubernetes finden, aber Sie können sich auf ein paar gute Lektionen über komplexe Systeme freuen.
Vor einigen Wochen war mein Team mit der Migration eines Mikrodienstes auf die Hauptplattform beschäftigt, die CI/CD, eine Kubernetes-basierte Arbeitsumgebung, Metriken und andere nützliche Funktionen umfasst. Der Umzug war als Testlauf gedacht: wir planten, ihn als Ausgangspunkt zu verwenden und in den kommenden Monaten etwa 150 weitere Dienste zu migrieren. Diese sind alle für den Betrieb einiger der größten Online-Plattformen in Spanien verantwortlich (Infojobs, Fotocasa usw.).
Nachdem wir die Anwendung in Kubernetes bereitgestellt und einen Teil des Traffics darauf umgeleitet hatten, erwartete uns eine besorgniserregende Überraschung. Die Verzögerung (Latenz) von Anfragen in Kubernetes war zehnmal höher als in EC2. Insgesamt mussten wir entweder eine Lösung für dieses Problem finden oder die Migration des Mikrodienstes aufgeben (und möglicherweise das gesamte Projekt).
Warum ist die Verzögerung in Kubernetes so viel höher als in EC2?
Um den Flaschenhals zu finden, haben wir Metriken entlang des gesamten Anfragewegs gesammelt. Unsere Architektur ist einfach: Ein API-Gateway (Zuul) proxied Anfragen zu den Instanzen des Mikrodienstes in EC2 oder Kubernetes. In Kubernetes verwenden wir den NGINX Ingress Controller, und die Backends bestehen aus gewöhnlichen Objekten des Typs mit einer JVM-Anwendung auf der Spring-Plattform.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Es schien, dass das Problem mit der Verzögerung in der Anfangsphase der Backend-Arbeit zusammenhing (ich habe den problematischen Bereich im Diagramm als „xx“ markiert). In EC2 betrug die Antwortzeit der Anwendung etwa 20 ms. In Kubernetes stieg die Verzögerung auf 100–200 ms.
Wir schlossen schnell wahrscheinliche Verdächtige im Zusammenhang mit dem Wechsel der Laufzeit aus. Die JVM-Version blieb gleich. Containerisierungsprobleme waren ebenfalls nicht entscheidend: Die Anwendung lief bereits erfolgreich in Containern in EC2. Last? Aber wir beobachteten hohe Verzögerungen selbst bei 1 Anfrage pro Sekunde. Pausen für die Müllsammlung konnten ebenfalls vernachlässigt werden.
Einer unserer Kubernetes-Administratoren erkundigte sich, ob es externe Abhängigkeiten der Anwendung gibt, da frühere DNS-Anfragen ähnliche Probleme verursacht haben.
Hypothese 1: DNS-Namensauflösung
Bei jeder Anfrage greift unsere Anwendung ein- bis dreimal auf eine AWS Elasticsearch-Instanz in einer Domain wie elastic.spain.adevinta.com. Innerhalb der Container haben wir , daher können wir überprüfen, ob die Domänensuche wirklich viel Zeit in Anspruch nimmt.
DNS-Anfragen aus dem Container:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Abfragezeit: 22 msec
;; Abfragezeit: 22 msec
;; Abfragezeit: 29 msec
;; Abfragezeit: 21 msec
;; Abfragezeit: 28 msec
;; Abfragezeit: 43 msec
;; Abfragezeit: 39 msecÄhnliche Anfragen von einer der EC2-Instanzen, auf der die Anwendung läuft:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Abfragezeit: 77 msec
;; Abfragezeit: 0 msec
;; Abfragezeit: 0 msec
;; Abfragezeit: 0 msec
;; Abfragezeit: 0 msecAngesichts der Tatsache, dass die Suche etwa 30 ms dauert, wird deutlich, dass die DNS-Auflösung beim Zugriff auf Elasticsearch tatsächlich zur Erhöhung der Latenz beiträgt.
Das war jedoch aus zwei Gründen seltsam:
- Wir haben bereits zahlreiche Anwendungen in Kubernetes, die mit AWS-Ressourcen interagieren, ohne unter hohen Latenzen zu leiden. Egal aus welchem Grund, es hat direkt mit diesem Fall zu tun.
- Wir wissen, dass die JVM DNS im Arbeitsspeicher cached. In unseren Images ist der TTL-Wert festgelegt auf
$JAVA_HOME/jre/lib/security/java.securityund auf 10 Sekunden eingestellt:networkaddress.cache.ttl = 10. Mit anderen Worten, die JVM sollte alle DNS-Anfragen für 10 Sekunden cachen.
Um die erste Hypothese zu bestätigen, haben wir entschieden, vorübergehend auf DNS-Anfragen zu verzichten und zu beobachten, ob das Problem verschwindet. Zunächst haben wir beschlossen, die Anwendung so umzustellen, dass sie sich direkt über die IP-Adresse mit Elasticsearch verbindet, anstatt über den Domainnamen. Das hätte Codeänderungen und ein neues Deployment erfordert, also haben wir einfach die Domain mit ihrer IP-Adresse in /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comverknüpft. Jetzt erhielt der Container die IP fast sofort. Das führte zu einigen Verbesserungen, aber wir waren nur wenig näher am erwarteten Latenzniveau. Obwohl die DNS-Auflösung viel Zeit in Anspruch nahm, blieb die wahre Ursache uns weiterhin verborgen.
Diagnose mittels Netzwerk
Wir haben beschlossen, den Datenverkehr aus dem Container zu analysieren mit tcpdump, um nachzuvollziehen, was genau im Netzwerk passiert:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Dann haben wir einige Anfragen gesendet und deren Capture heruntergeladen (kubectl cp my-service:/capture.pcap capture.pcap) für eine weitere Analyse in .
Es gab nichts Verdächtiges in den DNS-Anfragen (außer einer Kleinigkeit, über die ich später sprechen werde). Aber es gab bestimmte Eigenheiten, wie unser Dienst jede Anfrage bearbeitet hat. Unten sehen Sie einen Screenshot des Captures, der die Annahme der Anfrage vor Beginn der Antwort zeigt:
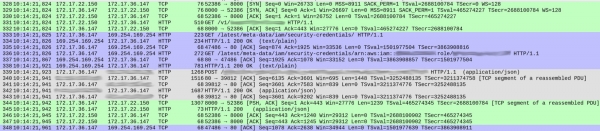
Die Paketnummern sind in der ersten Spalte aufgeführt. Zur Klarheit habe ich verschiedene TCP-Streams farblich hervorgehoben.
Der grüne Stream, der mit dem 328. Paket beginnt, zeigt, wie der Client (172.17.22.150) eine TCP-Verbindung zum Container (172.17.36.147) herstellt. Nach dem anfänglichen Handshake (328-330) brachte das Paket 331 HTTP GET /v1/.. — die eingehende Anfrage an unseren Dienst. Der gesamte Prozess dauerte 1 ms.
Der graue Stream (ab Paket 339) zeigt, dass unser Dienst eine HTTP-Anfrage an die Elasticsearch-Instanz gesendet hat (TCP-Handshake fehlt, da die bestehende Verbindung genutzt wird). Dies dauerte 18 ms.
Bisher läuft alles gut, und die Zeiten entsprechen ungefähr den erwarteten Verzögerungen (20–30 ms bei Messungen vom Client).
Die blaue Sektion benötigt jedoch 86 ms. Was passiert dort? Mit Paket 333 hat unser Dienst eine HTTP GET-Anfrage an /latest/meta-data/iam/security-credentials, und gleich danach, über dieselbe TCP-Verbindung, eine weitere GET-Anfrage an /latest/meta-data/iam/security-credentials/arn:...
Wir haben festgestellt, dass dies bei jeder Anfrage in der gesamten Traceroute wiederholt wird. Die DNS-Auflösung dauert in unseren Containern tatsächlich etwas länger (die Erklärung für dieses Phänomen ist sehr interessant, aber ich behalte sie mir für einen separaten Artikel vor). Es stellte sich heraus, dass die Ursache für die hohen Verzögerungen die Zugriffe auf den AWS Instance Metadata-Service bei jeder Anfrage sind.
Hypothese 2: unnötige Zugriffe auf AWS
Beide Endpoints gehören zu . Unser Mikrodienst nutzt diesen Dienst beim Arbeiten mit Elasticsearch. Beide Aufrufe sind Teil des Basis-Autorisierungsprozesses. Der Endpoint, auf den bei der ersten Anfrage zugegriffen wird, gibt die IAM-Rolle zurück, die mit der Instanz verknüpft ist.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleDie zweite Anfrage fragt beim zweiten Endpoint nach temporären Berechtigungen für diese Instanz:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Der Kunde kann sie für eine kurze Zeit nutzen und muss regelmäßig neue Zertifikate erhalten (bis zu ihrem Ablauf). Das Modell ist einfach: AWS rotiert temporäre Schlüssel häufig aus Sicherheitsgründen, aber die Kunden können sie für einige Minuten cachen, um die Leistungseinbußen bei der Erlangung neuer Zertifikate auszugleichen.
Das AWS Java SDK sollte die Verantwortung für die Organisation dieses Prozesses übernehmen, jedoch geschieht dies aus irgendeinem Grund nicht.
Durch die Suche nach Problemen auf GitHub sind wir auf ein Problem gestoßen . Dieses hat uns geholfen, die Richtung zu bestimmen, in die wir weiter "graben" sollten.
AWS SDK aktualisiert Zertifikate, wenn eine der folgenden Bedingungen eintritt:
- Das Ablaufdatum (
Ablauf) fällt aufEXPIRATION_THRESHOLD, das fest im Code auf 15 Minuten gesetzt ist. - Seit dem letzten Versuch, die Zertifikate zu aktualisieren, ist mehr Zeit vergangen als
REFRESH_THRESHOLD, das auf 60 Minuten festgelegt ist.
Um die tatsächliche Gültigkeitsdauer der von uns erhaltenen Zertifikate zu überprüfen, haben wir die oben genannten cURL-Befehle sowohl aus dem Container als auch aus einer EC2-Instanz ausgeführt. Die Gültigkeitsdauer des Zertifikats, das aus dem Container erhalten wurde, war deutlich kürzer: genau 15 Minuten.
Jetzt ist alles klar: Für die erste Anfrage erhielt unser Dienst temporäre Zertifikate. Da ihre Gültigkeit 15 Minuten nicht überschritt, entschied sich das AWS SDK bei der nächsten Anfrage, diese zu erneuern. Und das geschah bei jeder Anfrage.
Warum wurde die Gültigkeitsdauer der Zertifikate kürzer?
Der AWS Instance Metadata Service ist für die Arbeit mit EC2-Instanzen gedacht, nicht für Kubernetes. Andererseits wollten wir die Anwendungsoberfläche nicht ändern. Dazu haben wir — ein Tool, das es Benutzern (Ingenieuren, die Anwendungen in einem Cluster bereitstellen) ermöglicht, IAM-Rollen Container in Pods zuzuweisen, als wären sie EC2-Instanzen, mithilfe von Agenten auf jedem Kubernetes-Knoten. KIAM fängt Aufrufe an den AWS Instance Metadata Service ab und verarbeitet diese aus seinem Cache, nachdem es sie zuvor von AWS bezogen hat. Aus der Sicht der Anwendung ändert sich nichts.
KIAM stellt kurzfristige Zertifikate für Pods bereit. Das ist sinnvoll, wenn man bedenkt, dass die durchschnittliche Lebensdauer eines Pods kürzer ist als die eines EC2-Instances. Standardmäßig hat das Zertifikat eine Gültigkeitsdauer von .
Wenn man also beide Standardwerte übereinanderlegt, ergibt sich ein Problem. Jedes Zertifikat, das der Anwendung bereitgestellt wird, läuft nach 15 Minuten ab. Das AWS Java SDK zwingt ein Update jedes Zertifikats, wenn weniger als 15 Minuten bis zum Ablauf verbleiben.
Infolgedessen wird das temporäre Zertifikat mit jeder Anfrage aktualisiert, was mehrere API-Aufrufe bei AWS nach sich zieht und die Latenz erheblich erhöht. Im AWS Java SDK haben wir festgestellt, , in dem ein ähnliches Problem erwähnt wird.
Die Lösung war einfach. Wir haben KIAM einfach so konfiguriert, dass Zertifikate mit einer längeren Gültigkeitsdauer angefordert werden. Sobald das geschah, wurden die Anfragen ohne den AWS Metadata-Service verarbeitet, und die Latenz sank sogar auf ein niedrigeres Niveau als bei EC2.
Fazit
Basierend auf unserer Erfahrung mit Migrationen lässt sich sagen, dass eine der häufigsten Ursachen für Probleme nicht Fehler in Kubernetes oder anderen Plattformkomponenten sind. Auch ist es nicht mit grundlegenden Mängeln in den Mikrodiensten verbunden, die wir übertragen. Probleme entstehen häufig einfach, weil wir verschiedene Elemente zusammenfügen.
Wir mischen komplexe Systeme, die zuvor nie interagiert haben, in der Erwartung, dass sie zusammen ein größeres, einheitliches System bilden. Leider gilt: Je mehr Elemente, desto mehr Raum für Fehler, desto höher die Entropie.
In unserem Fall war die hohe Latenz nicht das Ergebnis von Fehlern oder schlechten Entscheidungen in Kubernetes, KIAM, dem AWS Java SDK oder unserem Mikrodienst. Sie war das Resultat der Kombination von zwei unabhängigen, standardmäßig festgelegten Parametern: einem in KIAM und einem im AWS Java SDK. Für sich genommen sind beide Parameter sinnvoll: sowohl die aktive Zertifikataktualisierungspolitik im AWS Java SDK als auch die kurze Gültigkeitsdauer der Zertifikate in KIAM. Doch wenn man sie zusammenführt, werden die Ergebnisse unvorhersehbar. Zwei unabhängige und logische Lösungen müssen nicht zwangsläufig Sinn ergeben, wenn sie kombiniert werden.
P.S. vom Übersetzer
Erfahren Sie mehr über die Architektur des KIAM-Tools zur Integration von AWS IAM mit Kubernetes in von den Erstellern.
Lesen Sie auch in unserem Blog:
- «»;
- «»;
- «»;
- «».
Quelle: habr.com
