


Wir haben bereits über , das die Entwicklung verteilter Anwendungen und deren Packung ermöglicht, berichtet. Nun fehlt nur noch eins: zu lernen, wie man diese Anwendungen bereitstellt und verwaltet. Keine Sorge, wir haben an alles gedacht! Wir haben alle Best Practices zum Arbeiten mit Tarantool Cartridge gesammelt und eine geschrieben, die das Paket auf den Servern verteilt, Instanzen startet, sie zu einem Cluster zusammenführt, die Autorisierung konfiguriert, vshard bootstrapped, automatischen Failover aktiviert und die Clusterkonfiguration patched.
Interessiert? Dann lade ich Sie ein, alles im Detail zu erfahren.
Lassen Sie uns mit einem Beispiel beginnen.
Wir werden nur einen Teil der Funktionen unserer Rolle betrachten. Eine vollständige Beschreibung aller Möglichkeiten und Eingabeparameter finden Sie immer in . Aber besser einmal ausprobieren, als hundertmal sehen, also lassen Sie uns eine kleine Anwendung bereitstellen.
Tarantool Cartridge bietet zum Erstellen einer kleinen Cartridge-Anwendung, die Informationen über Bankkunden und deren Konten speichert und eine API für die Datenverwaltung über HTTP bereitstellt. Dafür werden im Anwendung zwei mögliche Rollen beschrieben: api und storage, die den Instanzen zugewiesen werden können.
Die Tarantool Cartridge selbst gibt keine Hinweise darauf, wie Prozesse gestartet werden. Sie ermöglicht lediglich die Anpassung bereits gestarteter Instanzen. Den Rest muss der Benutzer selbst erledigen: Konfigurationsdateien ablegen, Dienste starten und die Topologie einrichten. Aber damit wollen wir uns nicht belasten, das übernimmt für uns Ansible.
Von Worten zu Taten
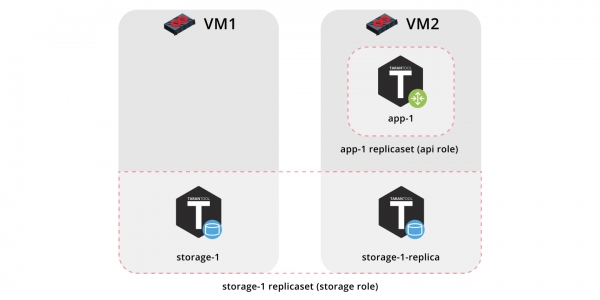
Lassen Sie uns also unsere Anwendung auf zwei virtuellen Maschinen bereitstellen und eine einfache Topologie einrichten:
- Replikatset
app-1wird die Rolle implementierenapi, die die Rollevshard-routerbeinhaltet. Hier wird es nur eine Instanz geben. - Replikatset
storage-1implementiert die Rollestorage(und gleichzeitigvshard-storage), hier fügen wir zwei Instanzen von verschiedenen Maschinen hinzu.
Für das Beispiel benötigen wir und (Versionen 2.8 oder älter).
Die Rolle selbst befindet sich in . Dies ist ein Repository, das es ermöglicht, eigene Entwicklungen zu teilen und fertige Rollen zu nutzen.
Klonen wir das Repository mit dem Beispiel:
$ git clone https://github.com/dokshina/deploy-tarantool-cartridge-app.git
$ cd deploy-tarantool-cartridge-app && git checkout 1.0.0Starten Sie die virtuellen Maschinen:
$ vagrant upInstallieren Sie die Ansible-Rolle Tarantool Cartridge:
$ ansible-galaxy install tarantool.cartridge,1.0.1Führen Sie die installierte Rolle aus:
$ ansible-playbook -i hosts.yml playbook.ymlWir warten, bis das Playbook abgeschlossen ist, und wechseln zu und genießen das Ergebnis:
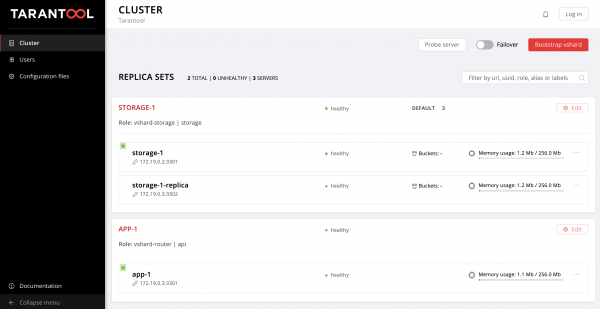
Daten können jetzt übertragen werden. Cool, oder?
Lass uns jetzt herausfinden, wie man damit arbeitet und gleichzeitig ein weiteres Replikatset zur Topologie hinzufügen.
Beginnen wir mit der Erklärung
Was ist also passiert?
Wir haben zwei virtuelle Maschinen hochgefahren und ein Ansible-Playbook ausgeführt, das unseren Cluster eingerichtet hat. Schauen wir uns den Inhalt der Datei an playbook.yml:
---
- name: Deploy my Tarantool Cartridge app
hosts: all
become: true
become_user: root
tasks:
- name: Import Tarantool Cartridge role
import_role:
name: tarantool.cartridgeHier passiert nichts Interessantes, wir führen die Ansible-Rolle aus, die genannt wird tarantool.cartridge.
Alles Wichtige (nämlich die Clusterkonfiguration) befindet sich in der -Datei hosts.yml:
---
all:
vars:
# allgemeine Cluster-Variablen
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # Pfad zum Paket
cartridge_cluster_cookie: app-default-cookie # Cluster-Cookie
# allgemeine SSH-Optionen
ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key
ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no'
# INSTANZEN
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
app-1:
config:
advertise_uri: '172.19.0.3:3301'
http_port: 8182
storage-1-replica:
config:
advertise_uri: '172.19.0.3:3302'
http_port: 8183
children:
# GRUPPIERE INSTANZEN NACH MASCHINEN
host1:
vars:
# Optionen für die Verbindung zur ersten Maschine
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # Instanzen, die auf der ersten Maschine gestartet werden
storage-1:
host2:
vars:
# Optionen für die Verbindung zur zweiten Maschine
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # Instanzen, die auf der zweiten Maschine gestartet werden
app-1:
storage-1-replica:
# GRUPPIERE INSTANZEN NACH REPLIKATSETZEN
replicaset_app_1:
vars: # Konfiguration des Replikatsatzes
replicaset_alias: app-1
failover_priority:
- app-1 # Leiter
roles:
- 'api'
hosts: # Instanzen des Replikatsatzes
app-1:
replicaset_storage_1:
vars: # Konfiguration des Replikatsatzes
replicaset_alias: storage-1
weight: 3
failover_priority:
- storage-1 # Leiter
- storage-1-replica
roles:
- 'storage'
hosts: # Instanzen des Replikatsatzes
storage-1:
storage-1-replica:Alles, was wir benötigen, ist, zu lernen, wie man Instanzen und Replica-Sets verwaltet, indem wir den Inhalt dieser Datei ändern. Im Folgenden werden wir neue Abschnitte hinzufügen. Um nicht durcheinander zu kommen, wo sie hinzugefügt werden sollen, können Sie die finale Version dieser Datei zurate ziehen, hosts.updated.yml, die im Repository mit dem Beispiel zu finden ist.
Instanzen verwalten
In den Begriffen von Ansible ist jede Instanz ein Host (nicht zu verwechseln mit einem physischen Server), d.h. ein Infrastrukturknoten, den Ansible verwalten wird. Für jeden Host können wir Verbindungsparameter angeben (wie z.B. ansible_host und ansible_user), sowie die Konfiguration der Instanz. Die Beschreibung der Instanzen befindet sich im Abschnitt hosts.
Betrachten wir die Konfiguration der Instanz storage-1:
all:
vars:
...
# INSTANZEN
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
...In der Variablen config wir haben die Parameter der Instanz angegeben — advertise URI und HTTP-Port.
Im Folgenden finden Sie die Parameter der Instanzen app-1 und storage-1-replica.
Wir müssen Ansible die Verbindungsparameter für jede Instanz mitteilen. Es erscheint sinnvoll, die Instanzen in Gruppen nach virtuellen Maschinen zu gruppieren. Deshalb sind die Instanzen in Gruppen zusammengefasst, host1 und host2, und in jeder Gruppe sind im Abschnitt vars die Werte ansible_host und ansible_user für eine virtuelle Maschine angegeben. Im Abschnitt hosts — Hosts (auch Instanzen genannt), die zu dieser Gruppe gehören:
all:
vars:
...
hosts:
...
children:
# INSTANZEN NACH MASCHINEN GRUPPIEREN
host1:
vars:
# Optionen für die Verbindung zur ersten Maschine
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # Instanzen, die auf der ersten Maschine gestartet werden sollen
storage-1:
host2:
vars:
# Optionen für die Verbindung zur zweiten Maschine
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # Instanzen, die auf der zweiten Maschine gestartet werden sollen
app-1:
storage-1-replica:Lass uns Änderungen vornehmen hosts.yml. Wir fügen noch zwei Instanzen hinzu, storage-2-replica auf der ersten virtuellen Maschine und storage-2 auf der zweiten:
all:
vars:
...
# INSTANZEN
hosts:
...
storage-2: # <==
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
storage-2-replica: # <==
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
children:
# INSTANZEN NACH MASCHINEN GRUPPIEREN
host1:
vars:
...
hosts: # Instanzen, die auf der ersten Maschine gestartet werden sollen
storage-1:
storage-2-replica: # <==
host2:
vars:
...
hosts: # Instanzen, die auf der zweiten Maschine gestartet werden sollen
app-1:
storage-1-replica:
storage-2: # <==
...Wir führen das Ansible-Playbook aus:
$ ansible-playbook -i hosts.yml
--limit storage-2,storage-2-replica
playbook.ymlBeachte die Option --limit. Da jede Instanz des Clusters in Ansible als Host betrachtet wird, können wir spezifisch angeben, welche Instanzen beim Ausführen des Playbooks konfiguriert werden sollen.
Wir loggen uns erneut in die Web-Oberfläche ein und beobachten unsere neuen Instanzen:
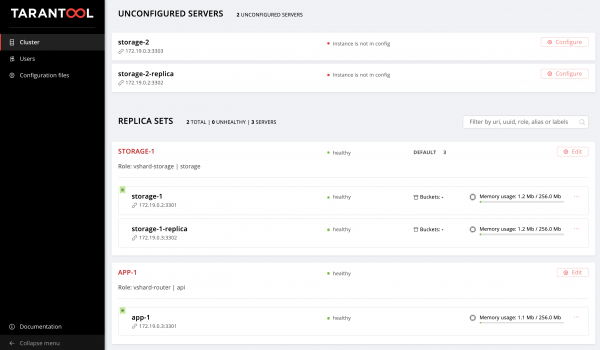
Wir werden nicht stehen bleiben und uns mit der Verwaltung der Topologie vertraut machen.
Verwaltung der Topologie
Verbinden wir unsere neuen Instanzen in einem Replikationssatz storage-2. Fügen wir eine neue Gruppe hinzu replicaset_storage_2 und beschreiben die Parameter des Replikationssatzes in ihren Variablen analog zu replicaset_storage_1. In dem Abschnitt hosts geben wir an, welche Instanzen zu dieser Gruppe gehören (also zu unserem Replikationssatz):
---
all:
vars:
...
hosts:
...
children:
...
# INSTANZEN NACH REPLIKATIONSÄTZEN GRUPPIEREN
...
replicaset_storage_2: # <==
vars: # Konfiguration des Replikationssatzes
replicaset_alias: storage-2
weight: 2
failover_priority:
- storage-2
- storage-2-replica
roles:
- 'storage'
hosts: # Instanzen des Replikationssatzes
storage-2:
storage-2-replica:Führen wir das Playbook erneut aus:
$ ansible-playbook -i hosts.yml
--limit replicaset_storage_2
--tags cartridge-replicasets
playbook.ymlIm Parameter --limit haben wir dieses Mal den Gruppennamen übergeben, der unserem Replikationssatz entspricht.
Schauen wir uns die Option an tags.
Unsere Rolle führt nacheinander verschiedene Aufgaben aus, die mit den folgenden Tags gekennzeichnet sind:
cartridge-instances: Verwaltung der Instanzen (Konfiguration, Anschluss an Membership);cartridge-replicasets: Verwaltung der Topologie (Verwaltung der Replikationssätze und unwiderrufliches Entfernen (expel) von Instanzen aus dem Cluster);cartridge-config: Verwaltung der anderen Clusterparameter (vshard-Bootstrapping, automatischer Failover-Modus, Autorisierungsparameter und Anwendungsconfiguration).
Wir können ausdrücklich angeben, welchen Teil der Arbeit wir erledigen möchten, sodass die Rolle die Ausführung der anderen Aufgaben überspringt. In unserem Fall möchten wir nur mit der Topologie arbeiten, daher haben wir angegeben, cartridge-replicasets.
Lassen Sie uns das Ergebnis unserer Bemühungen bewerten. Wir finden ein neues Replikaset unter .
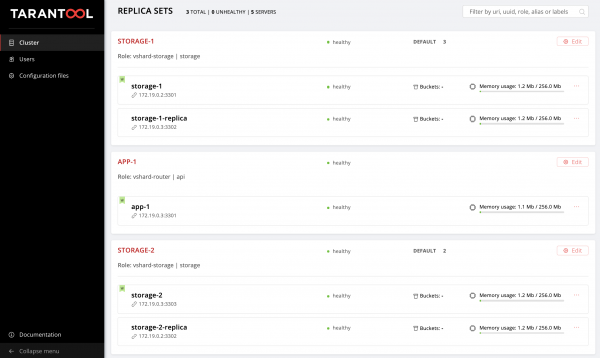
Hurra!
Experimentieren Sie mit der Änderung der Konfiguration von Instanzen und Replikasets und beobachten Sie, wie sich die Cluster-Topologie ändert. Sie können verschiedene Betriebsszenarien ausprobieren, wie zum Beispiel oder Erhöhung von memtx_memory. Die Rolle wird versuchen, dies ohne Neustart der Instanz zu tun, um mögliche Ausfallzeiten Ihrer Anwendung zu minimieren.
Vergessen Sie nicht zu starten vagrant halt, um die virtuellen Maschinen zu stoppen, wenn Sie mit ihnen fertig sind.
Und was steckt dahinter?
Hier werde ich näher darauf eingehen, was während unserer Experimente unter der Haube der Ansible-Rolle geschah.
Betrachten wir die Schritte zum Deployment der Cartridge-Anwendung.
Installation des Pakets und Start der Instanzen
Zuerst müssen wir das Paket auf den Server bringen und installieren. Die Rolle kann jetzt mit RPM- und DEB-Paketen arbeiten.
Als Nächstes starten wir die Instanzen. Das ist ganz einfach: jede Instanz ist ein separater systemd-Dienste. Ich erkläre es am Beispiel:
$ systemctl start myapp@storage-1Dieser Befehl startet die Instanz storage-1 der Anwendung myapp. Die gestartete Instanz wird nach ihrer in /etc/tarantool/conf.d/. Die Protokolle der Instanz können mit journald.
Die Unit-Datei /etc/systemd/system/myapp@.sevice für den systemd-Dienst wird zusammen mit dem Paket bereitgestellt.
In Ansible gibt es eingebaute Module für die Paketinstallation und das Management von systemd-Diensten, hier haben wir nichts Neues erfunden.
Konfiguration der Cluster-Topologie
Hier beginnt das Interessante. Es wäre doch seltsam, eine spezielle Ansible-Rolle für die Installation von Paketen und den Start von systemd-Diensten zu erstellen.
Den Cluster kann man auch manuell einrichten:
- Erste Option: Wir öffnen die Web-Oberfläche und klicken auf die Buttons. Für den einmaligen Start mehrerer Instanzen ist das durchaus ausreichend.
- Zweite Option: Man könnte die GraphQL-API verwenden. Hier kann man etwas automatisieren, zum Beispiel ein Python-Skript schreiben.
- Dritte Option (für die Mutigen): Wir loggen uns auf dem Server ein, verbinden uns mit einer der Instanzen über
tarantoolctl verbindenund alle notwendigen Manipulationen mit dem Lua-Modul durchführencartridge.
Die Hauptaufgabe unserer Erfindung ist es, diesen schwierigsten Teil der Arbeit für Sie zu übernehmen.
Ansible ermöglicht es, ein eigenes Modul zu schreiben und es in Rollen zu verwenden. Unsere Rolle nutzt solche Module zur Verwaltung verschiedener Cluster-Komponenten.
Wie funktioniert das? Sie beschreiben den gewünschten Zustand des Clusters in einer deklarativen Konfiguration, und die Rolle übergibt jedem Modul seinen Konfigurationsabschnitt. Das Modul erhält den aktuellen Zustand des Clusters und vergleicht ihn mit dem, was angekommen ist. Dann wird über den Socket einer der Instanzen der Code gestartet, der den Cluster in den gewünschten Zustand versetzt.
Ergebnisse
Heute haben wir erläutert und demonstriert, wie Sie Ihre Anwendung auf Tarantool Cartridge bereitstellen und eine einfache Topologie einrichten. Dazu haben wir Ansible verwendet – ein leistungsfähiges Werkzeug, das sich durch Benutzerfreundlichkeit auszeichnet und es ermöglicht, gleichzeitig viele Infrastrukturknoten zu konfigurieren (in unserem Fall handelt es sich um Cluster-Instanzen).
Oben haben wir einen der vielen Ansätze zur Beschreibung der Clusterkonfiguration mit Ansible behandelt. Sobald Sie bereit sind, weiterzugehen, schauen Sie sich für das Schreiben von Playbooks an. Es könnte einfacher sein, die Topologie mithilfe von group_vars und host_vars.
Bald werden wir Ihnen zeigen, wie Sie Instanzen endgültig aus der Topologie entfernen, vshard bootstrapen, den automatischen Failover verwalten, die Autorisierung einrichten und die Clusterkonfiguration patchen können. In der Zwischenzeit können Sie selbst die Clusterparameter erkunden und experimentieren.
Wenn etwas nicht funktioniert, zögern Sie nicht, uns über das Problem. Wir kümmern uns schnell um alles!
Quelle: habr.com
