

Abschrift des Berichts von Ilya Kosmodemyansky aus dem Jahr 2015Linux Optimierung zur Verbesserung der PostgreSQL-Performance
Hinweis: Dieser Vortrag stammt vom November 2015 – seitdem sind über vier Jahre vergangen. Die im Vortrag besprochene Version 9.4 wird nicht mehr unterstützt. In den letzten vier Jahren wurden fünf neue PostgreSQL-Versionen sowie 15 Kernel-Versionen veröffentlicht. LinuxWenn Sie diese Abschnitte überarbeiten, erhalten Sie einen anderen Bericht. Hier behandeln wir jedoch die grundlegende Abstimmung. Linux für PostgreSQL, das auch heute noch relevant ist.


Mein Name ist Ilya Kosmodemyansky. Ich arbeite bei PostgreSQL-Consulting. Und jetzt erkläre ich Ihnen kurz, was Sie tun sollten mit Linux in Bezug auf Datenbanken im Allgemeinen und PostgreSQL im Besonderen, da die Prinzipien recht ähnlich sind.
Was bringt das? Wer mit PostgreSQL arbeitet, benötigt gewisse UNIX-Administratorkenntnisse. Was bedeutet das konkret? Im Vergleich zu Oracle erfordert PostgreSQL zu 80 % Datenbankadministrator-/DBA-Kenntnisse und zu 20 % Administratorkenntnisse. Linux.
Bei PostgreSQL ist es etwas komplizierter. Man benötigt ein deutlich besseres Verständnis für die Funktionsweise von PostgreSQL. LinuxGleichzeitig ist es ein regelrechter Wettlauf, mit der Zeit zu gehen, denn in letzter Zeit hat sich alles rasant weiterentwickelt. Neue Kerne werden veröffentlicht, neue Funktionen hinzugefügt, die Leistung verbessert sich und so weiter.
Warum sprechen wir über LinuxNein, überhaupt nicht, denn wir sind auf einer Konferenz. Linux Peter, denn unter den heutigen Bedingungen ist eines der am besten gerechtfertigten Betriebssysteme für die Verwendung mit Datenbanken im Allgemeinen und mit PostgreSQL im Besonderen LinuxDenn FreeBSD entwickelt sich leider in eine sehr seltsame Richtung. Und das wird zu Problemen mit der Leistung und vielen anderen Dingen führen. PostgreSQL-Performance auf Windows Dies ist ein völlig separates und ernstes Thema, das auf der Tatsache beruht, dass Windows Es gibt keinen gemeinsamen Speicher wie bei UNIX, aber PostgreSQL ist vollständig darauf angewiesen, da es ein Mehrprozesssystem ist.
Und Exoten wie Solaris sind meiner Meinung nach weniger interessant für alle, also lasst uns gehen.

Die moderne Distribution hat Linux Es gibt über 1000 syctl-Parameter, abhängig von der Kernel-Kompilierung. Darüber hinaus bieten die verschiedenen Konfigurationen zahlreiche weitere Anpassungsmöglichkeiten. Dazu gehören Dateisystemparameter wie Mount-Optionen. Bei Fragen zur Kernel-Ausführung, zu BIOS-Einstellungen, zur Hardwarekonfiguration usw. wenden Sie sich bitte an uns.
Das ist ein sehr umfangreiches Thema, das mehrere Tage füllen könnte und nicht in einem kurzen Bericht behandelt werden kann. Ich werde mich nun aber auf die wichtigen Punkte konzentrieren: Wie man die Fehler vermeidet, die die korrekte Nutzung der Datenbank mit Sicherheit verhindern. LinuxSofern Sie diese nicht anpassen. Wichtig ist auch, dass viele Standardparameter in den korrekten Datenbankeinstellungen nicht enthalten sind. Das bedeutet, dass sie standardmäßig nur unzureichend oder gar nicht funktionieren.

Welche traditionellen Tuningziele gibt es? LinuxIch denke, da Sie sich alle mit der Verwaltung befassen, … LinuxWas Ziele sind, bedarf eigentlich keiner weiteren Erklärung.
Sie können Folgendes einstellen:
- ZENTRALPROZESSOR.
- Erinnerung.
- Lagerung.
- andere. Darüber werden wir am Ende bei einem Snack sprechen. Selbst beispielsweise Einstellungen wie die Energiesparrichtlinie können die Leistung auf sehr unvorhersehbare und nicht sehr angenehme Weise beeinträchtigen.

Was sind die Besonderheiten von PostgreSQL und der Datenbank im Allgemeinen? Das Problem ist, dass man nicht an einer bestimmten Schraube drehen und sehen kann, dass sich unsere Leistung erheblich verbessert hat.
Ja, es gibt solche Gadgets, aber die Datenbank ist eine komplizierte Sache. Sie interagiert mit allen Ressourcen, über die der Server verfügt, und bevorzugt die vollständige Interaktion. Wenn man sich die aktuellen Richtlinien von Oracle zur Verwendung eines Host-Betriebssystems ansieht, kommt einem der mongolische Astronautenwitz vor: Füttern Sie den Hund und fassen Sie nichts an. Geben wir der Datenbank alle Ressourcen, die Datenbank selbst wird alles zerstören.
Prinzipiell ist die Situation bei PostgreSQL bis zu einem gewissen Grad genau dieselbe. Der Unterschied besteht darin, dass die Datenbank selbst noch nicht alle Ressourcen zuweisen kann, was bedeutet, dass die Zuweisung auf Datenbankebene erfolgen muss. Linux Ich muss das alles selbst regeln.
Die Hauptidee besteht nicht darin, ein einzelnes Ziel auszuwählen und mit der Optimierung zu beginnen, zum Beispiel Speicher, CPU oder ähnliches, sondern die Arbeitslast zu analysieren und zu versuchen, den Durchsatz so weit wie möglich zu verbessern, damit er der Last entspricht, für die gute Programmierer geschaffen haben uns, einschließlich unserer Nutzer.
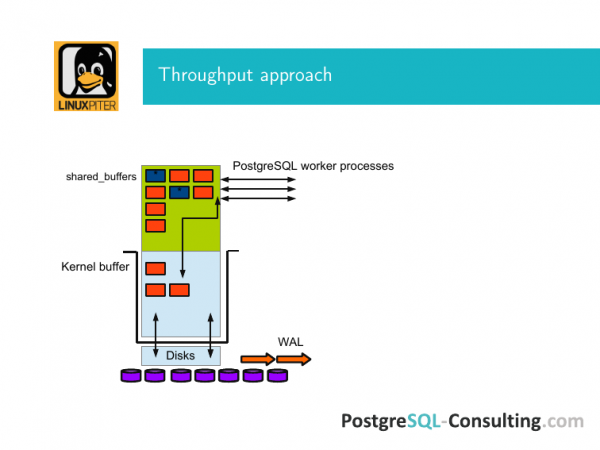
Hier ist ein Bild zur Veranschaulichung. Es handelt sich um einen Betriebssystempuffer. Linux Es gibt gemeinsam genutzten Speicher und es gibt gemeinsam genutzte Puffer in PostgreSQL. Im Gegensatz zu Oracle arbeitet PostgreSQL direkt über den Kernel-Puffer. Das bedeutet, dass eine Seite, um von der Festplatte in den gemeinsam genutzten Speicher zu gelangen, den Kernel-Puffer durchlaufen und wieder zurückkommen muss – die gleiche Situation gilt auch hier.
Festplatten leben unter diesem System. Ich habe es als Scheiben gezeichnet. Tatsächlich kann es einen RAID-Controller usw. geben.
Und dieser Input-Output geschieht auf die eine oder andere Weise durch diesen Fall.
PostgreSQL ist eine klassische Datenbank. Es befindet sich auf der Seite. Und die gesamte Eingabe/Ausgabe erfolgt mit Hilfe von Seiten. Wir erhöhen Blöcke im Speicher seitenweise. Und wenn nichts passiert, lesen wir sie einfach, dann verschwinden sie nach und nach aus diesem Cache, aus gemeinsam genutzten Puffern und gelangen zurück auf die Festplatte.
Wenn wir irgendwo etwas ausgetauscht haben, wird unsere gesamte Seite als schmutzig markiert. Ich habe sie hier blau markiert. Und das bedeutet, dass diese Seite mit dem Blockspeicher synchronisiert werden muss. Das heißt, als wir es schmutzig machten, machten wir einen Eintrag in WAL. Und irgendwann kam ein Phänomen namens Checkpoint. Und dieses Protokoll zeichnete die Information auf, dass er gekommen war. Und das bedeutet, dass alle schmutzigen Seiten, die sich zu diesem Zeitpunkt in diesen gemeinsam genutzten Puffern befanden, mithilfe von fsync über den Kernel-Puffer mit der Speicherplatte synchronisiert wurden.
Wofür ist das? Wenn wir die Spannung verloren haben, sind nicht alle Daten verloren gegangen. Persistentes Gedächtnis, von dem uns alle erzählt haben, ist in der Datenbanktheorie bisher eine glänzende Zukunft, die wir natürlich anstreben und die uns gefällt, aber bisher leben sie noch in minus 20 Jahren. Und natürlich muss all dies überwacht werden.
Und die Aufgabe zur Maximierung des Durchsatzes besteht darin, alle diese Phasen so abzustimmen, dass alles schnell hin und her geht. Shared Memory ist im Grunde ein Seitencache. In PostgreSQL haben wir eine Select-Etwas-There-Anfrage gesendet, diese Daten wurden von der Festplatte abgerufen. Sie gelangten in gemeinsame Puffer. Damit dies besser funktioniert, muss dementsprechend viel Speicher vorhanden sein.
Damit das alles gut und schnell funktioniert, müssen Sie das Betriebssystem in allen Phasen richtig konfigurieren. Und wählen Sie ausgewogenes Eisen, denn wenn Sie an einer Stelle ein Ungleichgewicht haben, können Sie zwar viel Speicher herstellen, dieser wird jedoch mit unzureichender Geschwindigkeit bedient.
Gehen wir jeden dieser Punkte durch.

Damit diese Seiten schneller hin und her gelangen, müssen Sie Folgendes erreichen:
- Erstens müssen Sie effizienter mit dem Gedächtnis arbeiten.
- Zweitens sollte dieser Übergang effizienter sein, wenn Seiten aus dem Speicher auf die Festplatte verschoben werden.
- Und drittens müssen gute Scheiben vorhanden sein.
Wenn Sie 512 GB RAM haben in Server Und wenn das alles auf einer SATA-Festplatte ohne Cache landet, wird der gesamte Datenbankserver nicht nur zu einem nutzlosen Krümel, sondern zu einem Krümel mit SATA-Schnittstelle. Dann sitzen Sie in der Falle. Und nichts kann Sie mehr retten.

Was den ersten Punkt mit dem Gedächtnis betrifft, gibt es drei Dinge, die das Leben sehr schwer machen können.
Der erste ist NUMA. NUMA dient der Verbesserung der Leistung. Je nach Auslastung können Sie unterschiedliche Dinge optimieren. Und in seiner neuen aktuellen Form eignet es sich nicht besonders gut für Anwendungen wie Datenbanken, die gemeinsam genutzte Seitencache-Puffer intensiv nutzen.

Kurzgesagt. Wie kann man verstehen, dass mit NUMA etwas nicht stimmt? Sie haben ein unangenehmes Klopfen, plötzlich ist eine CPU überlastet. Gleichzeitig analysieren Sie Abfragen in PostgreSQL und stellen fest, dass es dort nichts Vergleichbares gibt. Diese Anfragen sollten nicht so CPU-intensiv sein. Man kann es lange fangen. Es ist einfacher, von Anfang an die richtigen Ratschläge zum Einrichten von NUMA für PostgreSQL zu nutzen.

Was ist wirklich los? NUMA steht für Non-Uniform Memory Access. Was ist der Sinn? Sie haben eine CPU, daneben befindet sich ihr lokaler Speicher. Und diese Speicherverbindungen können Speicher von anderen CPUs beziehen.
Wenn du läufst numactl --hardware, dann bekommst du so ein großes Blatt. Unter anderem wird es ein Entfernungsfeld geben. Es wird Zahlen geben – 10-20, so etwas in der Art. Diese Zahlen sind nichts anderes als die Anzahl der Hops, um diesen Remote-Speicher aufzunehmen und lokal zu verwenden. Im Grunde eine gute Idee. Dies verbessert die Leistung bei einer Reihe von Workloads deutlich.
Stellen Sie sich nun vor, dass eine CPU zunächst versucht, ihren lokalen Speicher zu nutzen, und dann versucht, über die Verbindung einen anderen Speicher für etwas abzurufen. Und Ihr gesamter PostgreSQL-Seitencache gelangt zu dieser CPU – das ist es, wie viele Gigabyte sind da. Sie erhalten immer den schlimmsten Fall, da direkt in diesem Modul normalerweise nur wenig Speicher auf der CPU vorhanden ist. Und der gesamte Speicher, der bereitgestellt wird, läuft über diese Verbindungen. Es stellt sich langsam und traurig heraus. Und Sie haben einen Prozessor, der diesen Knoten bedient, der ständig überlastet ist. Und die Zugriffszeit auf diesen Speicher ist schlecht, langsam. Dies ist die Art von Situation, die Sie nicht möchten, wenn Sie diesen Fall für eine Datenbank verwenden.
Daher ist die korrektere Option für die Datenbank die für das Betriebssystem. Linux Ich wusste gar nicht, was da vor sich ging. Sie konnte also auf ihre Erinnerungen zugreifen, so wie sie es tut.
Warum so? Es scheint, dass es umgekehrt sein sollte. Dies geschieht aus einem einfachen Grund: Wir benötigen viel Speicher für den Seiten-Cache – Dutzende, Hunderte von Gigabyte.
Und wenn wir das alles zuordnen und unsere Daten dort zwischenspeichern, dann wird der Gewinn durch die Nutzung des Caches deutlich größer sein als der Gewinn durch einen so raffinierten Speicherzugriff. Und auf diese Weise werden wir unvergleichlich gewinnen, verglichen mit der Tatsache, dass wir mit NUMA effizienter auf den Speicher zugreifen.
Daher gibt es derzeit zwei Ansätze, bis eine glänzende Zukunft bevorsteht und die Datenbank selbst nicht herausfinden kann, auf welchen CPUs sie arbeitet und woher sie etwas beziehen muss.

Daher besteht der richtige Ansatz darin, NUMA vollständig zu deaktivierenz.B. beim Neustart. In den meisten Fällen liegen die Gewinne in einer solchen Reihenfolge, dass es überhaupt keine Frage gibt, was besser ist.
Es gibt noch eine andere Möglichkeit. Wir verwenden es häufiger als das erste, denn wenn ein Kunde zu uns kommt, um Unterstützung zu erhalten, ist es für ihn eine große Sache, den Server neu zu starten. Er hat dort ein Geschäft. Und sie haben Probleme wegen NUMA. Daher versuchen wir, es auf weniger invasive Weise als durch einen Neustart zu deaktivieren. Achten Sie hier jedoch darauf, zu überprüfen, ob es deaktiviert ist. Da die Erfahrung zeigt, dass wir NUMA im übergeordneten Prozess von PostgreSQL deaktivieren, ist das gut, aber es ist überhaupt nicht notwendig, dass dies funktioniert. Wir müssen nachsehen, ob sie wirklich ausgeschaltet ist.
Es gibt einen guten Beitrag von Robert Haas. Dies ist einer der PostgreSQL-Committer. Einer der wichtigsten Entwickler aller Low-Level-Innereien. Und wenn Sie den Links in diesem Beitrag folgen, werden darin mehrere farbenfrohe Geschichten darüber beschrieben, wie NUMA den Menschen das Leben schwer gemacht hat. Schauen Sie sich die Checkliste des Systemadministrators an und erfahren Sie, was auf dem Server konfiguriert werden muss, damit unsere Datenbank ordnungsgemäß funktioniert. Diese Einstellungen müssen aufgezeichnet und überprüft werden, da sie sonst nicht sehr gut sind.
Ich mache Sie darauf aufmerksam, dass dies für alle Einstellungen gilt, über die ich sprechen werde. Normalerweise werden Datenbanken jedoch aus Gründen der Fehlertoleranz im Master-Slave-Modus zusammengestellt. Vergessen Sie nicht, diese Einstellungen am Slave vorzunehmen, denn eines Tages wird es zu einem Unfall kommen und Sie wechseln zum Slave und dieser wird zum Master.
Im Notfall, wenn alles ganz schlimm ist, Ihr Telefon ständig klingelt und Ihr Chef mit einem großen Stock angerannt kommt, haben Sie keine Zeit, über eine Überprüfung nachzudenken. Und die Ergebnisse können sehr katastrophal sein.
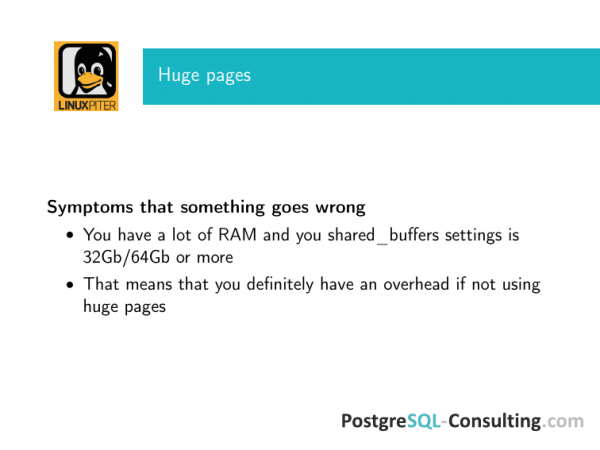
Der nächste Moment sind riesige Seiten. Es ist schwierig, große Seiten separat zu testen, und das hat keinen Sinn, obwohl es Benchmarks gibt, die das können. Sie lassen sich leicht googeln.
Was ist der Punkt? Sie haben einen nicht sehr teuren Server, der über viel RAM verfügt, beispielsweise über 30 GB. Sie verwenden keine großen Seiten. Dies bedeutet, dass Sie definitiv einen Overhead bei der Speichernutzung haben. Und dieser Aufwand ist bei weitem nicht der angenehmste.

Warum so? Und was geht ab? Das Betriebssystem weist Speicher in kleinen Blöcken zu. So praktisch, so historisch. Und wenn Sie ins Detail gehen, muss das Betriebssystem virtuelle Adressen in physische Adressen übersetzen. Da dieser Vorgang nicht der einfachste ist, speichert das Betriebssystem das Ergebnis dieses Vorgangs im Translation Lookaside Buffer (TLB) zwischen.
Und da es sich beim TLB um einen Cache handelt, treten in dieser Situation alle dem Cache innewohnenden Probleme auf. Erstens: Wenn Sie über viel RAM verfügen und alles in kleinen Blöcken zugewiesen ist, wird dieser Puffer sehr groß. Und wenn der Cache groß ist, ist die Suche langsamer. Der Overhead ist in Ordnung und nimmt selbst Platz ein, d. h. ein Fehler verbraucht RAM. Diesmal.
Zweitens: Je größer der Cache in dieser Situation wird, desto wahrscheinlicher treten Cache-Fehler auf. Die Effektivität des Caches nimmt mit zunehmender Größe rapide ab. Daher haben Betriebssysteme einen einfachen Ansatz entwickelt. Linux Es ist schon lange im Einsatz. Es tauchte erst vor Kurzem in FreeBSD auf. Aber wir sprechen hier von LinuxDas sind riesige Seiten.
Und hier ist anzumerken, dass die Idee der riesigen Seiten zunächst von Communities wie Oracle und IBM durchgesetzt wurde, d. h. Datenbankhersteller dachten intensiv darüber nach, dass dies auch für Datenbanken nützlich sein würde.

Und wie kann man sich mit PostgreSQL anfreunden? Zunächst müssen große Seiten im Linux-Kernel aktiviert werden.
Zweitens müssen sie explizit durch den sysctl-Parameter angegeben werden – wie viele es sind. Die Zahlen hier stammen von einem alten Server. Sie können ungefähr berechnen, wie viele gemeinsame Puffer Sie haben, sodass große Seiten dort hineinpassen.
Und wenn Sie den gesamten Server für PostgreSQL reserviert haben, ist es ein guter Ausgangspunkt, entweder 25 % des RAM für gemeinsam genutzte Puffer bereitzustellen, oder 75 %, wenn Sie sicher sind, dass Ihre Datenbank definitiv in diese 75 % passt. Ausgangspunkt zuerst. Und bedenken Sie: Wenn Sie über 256 GB RAM verfügen, stehen Ihnen entsprechend 64 GB Sherd-Puffer zur Verfügung. Berechnen Sie ungefähr mit etwas Spielraum, worauf Sie diesen Wert einstellen sollten.
Vor Version 9.2 (wenn ich mich nicht irre, seit Version 8.2) war es möglich, mithilfe einer Bibliothek eines Drittanbieters mit riesigen Seiten PostgreSQL anzufreunden. Und das sollte immer getan werden. Zunächst muss der Kernel große Seiten korrekt zuordnen können. Und zweitens, damit die Anwendung, die mit ihnen arbeitet, sie nutzen kann. Es wird einfach nicht so verwendet. Da PostgreSQL Speicher im System-5-Stil zugewiesen hat, könnte dies mit libhugetlbfs erfolgen – dies ist der vollständige Name der Bibliothek.
9.3 verbesserte die PostgreSQL-Speicherleistung und ließ die Speicherzuweisungsmethode von System 5 fallen. Alle waren sehr zufrieden, denn sonst würde man versuchen, zwei PostgreSQL-Instanzen auf demselben Rechner laufen zu lassen, und er sagt, dass ich nicht genug Shared Memory habe. Und er sagt, dass Sie sysctl reparieren müssen. Und es gibt so ein System, dass man noch neu starten muss usw. Im Allgemeinen waren alle begeistert. Aber die MMAP-Speicherzuweisung ist bei großen Seiten kaputt gegangen. Die meisten unserer Kunden verwenden große gemeinsame Puffer. Und wir empfehlen dringend, nicht auf 9.3 umzusteigen, da dort der Overhead in guten Prozentsätzen berechnet wird.
Aber andererseits hat die Community auf dieses Problem aufmerksam gemacht und in 9.4 dieses Ereignis sehr gut überarbeitet. Und in 9.4 erschien in postgresql.conf ein Parameter, in dem Sie „try“ ein- oder ausschalten können.
Versuchen ist die sicherste Option. Wenn PostgreSQL startet und gemeinsam genutzten Speicher zuweist, versucht es, diesen Speicher von großen Seiten abzurufen. Und wenn es nicht funktioniert, wird auf die übliche Auswahl zurückgesetzt. Und wenn Sie FreeBSD oder Solaris haben, können Sie es ausprobieren, es ist immer sicher.
Wenn „on“ aktiviert ist, startet das Programm einfach nicht, falls kein Speicherplatz von großen Seiten zugewiesen werden kann. Das ist Geschmackssache. Wenn Sie jedoch „try“ aktiviert haben, überprüfen Sie unbedingt, ob Sie tatsächlich den benötigten Speicherplatz zugewiesen haben, da hier Fehler leicht passieren können. Aktuell funktioniert diese Funktion nur auf Linux.
Noch eine kleine Anmerkung, bevor wir weitermachen. Bei transparenten riesigen Seiten geht es noch nicht um PostgreSQL. Er kann sie nicht normal verwenden. Und wenn Sie bei einer solchen Arbeitslast große transparente Seiten benötigen, sind die Vorteile nur bei sehr großen Volumina gegeben, wenn Sie einen großen Teil des gemeinsam genutzten Speichers benötigen. Wenn Sie über Terabytes an Arbeitsspeicher verfügen, kann dies eine Rolle spielen. Wenn es um alltäglichere Anwendungen geht und Sie 32, 64, 128, 256 GB Arbeitsspeicher auf dem Gerät haben, dann sind die üblichen großen Seiten in Ordnung, und wir schalten einfach „Transparent“ aus.

Und das Letzte an der Erinnerung hängt nicht direkt mit der Frucht zusammen, sie kann das Leben sehr ruinieren. Der gesamte Durchsatz wird stark durch die Tatsache beeinträchtigt, dass der Server ständig austauscht.
Und das wird in vielerlei Hinsicht sehr ärgerlich sein. Das Hauptproblem besteht darin, dass sich moderne Kernel etwas anders verhalten als ältere Kernel. LinuxUnd das ist eine äußerst unangenehme Situation, denn wenn es um Swap-Operationen geht, endet das meist mit einem unerwarteten OOM-Killer. Und ein solcher OOM-Killer, der PostgreSQL zum Absturz bringt, ist äußerst ärgerlich. Jeder, bis hin zum letzten Benutzer, wird es zu spüren bekommen.

Was ist los? Sie haben dort viel RAM, alles funktioniert gut. Aber aus irgendeinem Grund hängt der Server im Swap und wird dadurch langsamer. Es scheint, dass es viel Speicher gibt, aber es passiert.

Zuvor haben wir empfohlen, vm.swappiness auf Null zu setzen, d. h. Swap zu deaktivieren. Bisher schien es, dass 32 GB RAM und die entsprechenden gemeinsam genutzten Puffer eine riesige Menge seien. Der Hauptzweck des Tauschs besteht darin, eine Stelle zu haben, an der wir eine Kruste werfen können, wenn wir herunterfallen. Und es wurde nicht sehr gut gemacht. Und was machen Sie dann mit dieser Kruste? Dies ist bereits eine solche Aufgabe, wenn nicht ganz klar ist, warum ein Austausch erforderlich ist, insbesondere bei einer solchen Größe.
Aber in moderneren, also dritten Versionen des Kernels hat sich das Verhalten geändert. Und wenn Sie Swap auf Null setzen, also ausschalten, wird früher oder später, selbst wenn noch etwas RAM übrig ist, ein OOM-Killer auf Sie zukommen, um die intensivsten Verbraucher zu töten. Denn er wird bedenken, dass wir bei einer solchen Arbeitsbelastung noch etwas übrig haben und herausspringen, das heißt nicht den Systemprozess töten, sondern etwas weniger Wichtiges töten. Dieser weniger wichtige wird der starke Verbraucher des gemeinsam genutzten Speichers sein, nämlich der Postmaster. Und danach ist es gut, wenn die Basis nicht wiederhergestellt werden muss.
Daher ist die Standardeinstellung, soweit ich mich erinnere, bei den meisten Distributionen bei etwa 6, d. h. ab welchem Punkt mit der Verwendung von Swap begonnen werden soll, abhängig davon, wie viel Speicher noch übrig ist. Wir empfehlen jetzt, vm.swappiness = 1 zu setzen, da dies es praktisch ausschaltet, aber nicht zu solchen Effekten führt wie bei einem unerwarteten OOM-Killer, der kam und das Ganze zerstörte.

Was weiter? Wenn wir über die Leistung von Datenbanken sprechen und wir nach und nach wie Festplatten sind, fängt jeder an, sich den Kopf zu schnappen. Denn die Tatsache, dass die Festplatte langsam und der Speicher schnell ist, ist jedem seit seiner Kindheit bekannt. Und jeder weiß, dass es Probleme mit der Festplattenleistung in der Datenbank geben wird.
Das Hauptproblem der PostgreSQL-Leistung bei Checkpoint-Spitzen liegt nicht darin, dass die Festplatte langsam ist. Dies ist wahrscheinlicher darauf zurückzuführen, dass die Speicher- und Festplattenbandbreite nicht ausgeglichen sind. Es kann jedoch sein, dass sie an verschiedenen Orten nicht ausgeglichen sind. PostgreSQL ist nicht konfiguriert, das Betriebssystem ist nicht konfiguriert, die Hardware ist nicht konfiguriert und die Hardware ist falsch. Und dieses Problem tritt nicht nur dann auf, wenn alles so läuft, wie es soll, also entweder keine Last vorhanden ist oder die Einstellungen und Hardware gut gewählt sind.
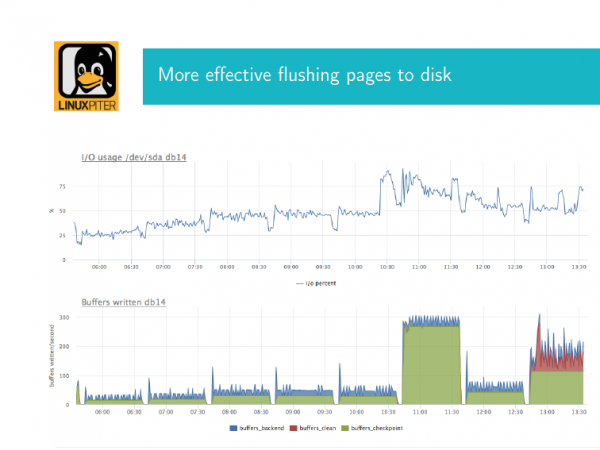
Was ist das und wie sieht es aus? Normalerweise sind Leute, die mit PostgreSQL arbeiten, mehr als einmal in dieses Geschäft eingestiegen. Ich erkläre es. Wie ich bereits sagte, führt PostgreSQL regelmäßig Prüfpunkte durch, um fehlerhafte Seiten im gemeinsam genutzten Speicher auf die Festplatte zu übertragen. Wenn wir über eine große Menge gemeinsam genutzten Speichers verfügen, wirkt sich der Checkpoint stark auf die Festplatte aus, da fsync diese Seiten ausgibt. Es kommt im Kernel-Puffer an und wird mit fsync auf die Festplatte geschrieben. Und wenn das Volumen dieses Gehäuses groß ist, können wir einen unangenehmen Effekt beobachten, nämlich eine sehr hohe Festplattenauslastung.
Hier habe ich zwei Bilder. Ich werde jetzt erklären, was es ist. Dies sind zwei zeitkorrelierte Diagramme. Das erste Diagramm zeigt die Festplattenauslastung. Hier erreicht sie zu diesem Zeitpunkt fast 90 %. Wenn bei physischen Festplatten ein Datenbankausfall auftritt und der RAID-Controller zu weniger als 90 % ausgelastet ist, sind das schlechte Nachrichten. Das bedeutet, dass etwas mehr und 100 kommen und die Ein-/Ausgabe stoppt.
Wenn Sie über ein Festplatten-Array verfügen, sieht die Sache etwas anders aus. Da kommt es darauf an, wie es konfiguriert ist, was für ein Array usw.
Und parallel dazu wird hier aus der internen Postgres-Ansicht ein Diagramm konfiguriert, das zeigt, wie der Checkpoint abläuft. Und die grüne Farbe zeigt hier, wie viele Puffer dieser schmutzigen Seiten zu diesem Zeitpunkt zur Synchronisierung an diesem Kontrollpunkt angekommen sind. Und das ist hier das Wichtigste, was man wissen sollte. Wir sehen, dass wir hier viele Seiten haben und irgendwann sind wir auf eine Gebühr gestoßen, das heißt, wir haben geschrieben und geschrieben, hier ist das Plattensystem offensichtlich sehr ausgelastet. Und unser Checkpoint hat einen sehr starken Einfluss auf die Festplatte. Im Idealfall sollte die Situation eher so aussehen, d. h. wir hatten hier weniger Rekord. Und wir können es mit Einstellungen beheben, sodass es so weitergeht. Das heißt, das Recycling ist gering, aber irgendwo schreiben wir hier etwas.
Was muss getan werden, um dieses Problem zu überwinden? Wenn Sie E/A unter der Datenbank gestoppt haben, bedeutet dies, dass alle Benutzer, die zur Ausführung ihrer Anforderungen gekommen sind, warten.

Wenn man es aus folgendem Blickwinkel betrachtet LinuxWenn Sie über gute Hardware verfügen, diese korrekt konfiguriert haben und PostgreSQL so eingerichtet ist, dass diese Prüfpunkte seltener und über einen längeren Zeitraum verteilt werden, dann erreichen Sie die Standardparameter. DebianFür die meisten Verteilungen Linux Hier das Bild: vm.dirty_ratio=20, vm.dirty_background_ratio=10.
Was bedeutet das? Seit Kernel 2.6 ist ein Demon Flushing aufgetaucht. Abhängig davon, wer was verwendet, ist Pdglush damit beschäftigt, im Hintergrund schmutzige Seiten aus dem Kernel-Puffer zu entfernen und schmutzige Seiten zu entfernen, wenn es nötig ist, egal was passiert, wenn das Hintergrundwerfen nicht hilft.
Wann kommt der Hintergrund? Wenn 10 % des gesamten RAM des Servers durch Dirty Pages im Kernel-Puffer belegt sind, wird im Hintergrund eine spezielle Cheat-Funktion aufgerufen. Warum ist sie Hintergrund? Als Parameter wird verwendet, wie viele Seiten abgeschrieben werden sollen. Und sagen wir mal, er schreibt N Seiten ab. Und für eine Weile schläft dieses Ding ein. Und dann kommt sie zurück und schreibt noch ein paar Seiten ab.
Das ist eine äußerst einfache Geschichte. Hier ist die Aufgabe wie bei einem Pool: Wenn es in ein Rohr fließt, fließt es in ein anderes. Unser Checkpoint kam und wenn er ein paar schmutzige Seiten zum Verwerfen gesendet hat, wird das Ganze nach und nach aus dem Kernel-Puffer pgflush sauber gelöst.
Wenn sich diese schmutzigen Seiten weiterhin ansammeln, sammeln sie sich bis zu 20 % an. Danach besteht die Priorität des Betriebssystems darin, das Ganze auf die Festplatte zu schreiben, da der Strom ausfällt und alles für uns schlecht wird. Wir werden beispielsweise diese Daten verlieren.
Was ist der Trick? Der Trick besteht darin, dass diese Parameter in der modernen Welt 20 und 10 % des gesamten RAM auf der Maschine ausmachen, was im Hinblick auf den Durchsatz jedes Festplattensystems, das Sie haben, absolut ungeheuerlich ist.
Stellen Sie sich vor, Sie hätten 128 GB RAM. Es kommen 12,8 GB auf Ihr Festplattensystem. Und egal welchen Cache Sie dort haben, egal welches Array Sie dort haben, sie werden nicht so viel aushalten.

Wir empfehlen daher, diese Zahlen je nach Leistungsfähigkeit Ihres RAID-Controllers umgehend anzupassen. Ich habe hier sofort eine Empfehlung für einen Controller ausgesprochen, der über 512 MB Cache verfügt.
Alles gilt als sehr einfach. Sie können vm.dirty_background in Bytes angeben. Und diese Einstellungen überschreiben die beiden vorherigen. Entweder ist das Verhältnis standardmäßig eingestellt, oder diejenigen mit Bytes sind aktiviert, dann funktionieren diejenigen mit Bytes. Aber da ich DBA-Berater bin und mit verschiedenen Kunden arbeite, versuche ich, Strohhalme zu legen, und zwar wenn in Bytes, dann in Bytes. Niemand gab eine Garantie dafür, dass ein guter Administrator dem Server keinen Speicher hinzufügen würde, ihn nicht neu starten würde und die Zahl gleich bleiben würde. Berechnen Sie diese Zahlen einfach so, dass dort garantiert alles passt.
Was passiert, wenn man nicht reinpasst? Ich habe geschrieben, dass das effektiv jede Rötung stoppt, aber in Wirklichkeit ist es eine Redewendung. Das Betriebssystem hat ein großes Problem – es hat viele schmutzige Seiten, sodass die E/A, die Ihre Clients generieren, effektiv stoppt, d. h. die Anwendung ist gekommen, um eine SQL-Abfrage an die Datenbank zu senden, sie wartet. Alle E/A-Vorgänge haben die niedrigste Priorität, da die Basis vom Prüfpunkt belegt ist. Und als sie fertig ist, ist es völlig unverständlich. Und wenn Sie das Non-Background-Non-Background-Flushing erreicht haben, bedeutet das, dass Ihre gesamte E/A davon belegt ist. Und bis es zu Ende ist, wirst du nichts tun.
Es gibt zwei weitere wichtige Punkte, die den Rahmen dieses Berichts sprengen würden. Diese Einstellungen sollten mit den Einstellungen in postgresql.conf übereinstimmen, d. h. den Checkpoints-Einstellungen. Und Ihr Festplattensystem muss entsprechend konfiguriert sein. Wenn Sie einen Cache auf dem RAID haben, muss dieser über eine Batterie verfügen. Die Leute kaufen RAID mit gutem Cache ohne Batterie. Wenn Sie eine SSD im RAID haben, muss es sich um eine Server-SSD handeln, es müssen Kondensatoren vorhanden sein. Hier ist die erweiterte Checkliste. Unter diesem Link gibt es meinen Bericht zum Einrichten der Festplattenleistung in PostgreSQL. Alle diese Checklisten sind da.

Was kann das Leben noch sehr schwer machen? Dies sind zwei Optionen. Sie sind relativ neu. Standardmäßig können sie in verschiedene Anwendungen eingebunden werden. Und sie können das Leben genauso kompliziert machen, wenn sie falsch eingeschaltet werden.

Es gibt zwei relativ neue Stücke. Sie sind bereits in den dritten Kernen aufgetaucht. Dies sind sched_migration_cost in Nanosekunden und sched_autogroup_enabled, was standardmäßig eins ist.
Und wie zerstören sie Leben? Was ist sched_migration_cost? Linux Der Scheduler kann einen Prozess von einer CPU auf eine andere verschieben. Und für PostgreSQL, das Abfragen ausführt, ist völlig unklar, warum eine Verschiebung auf eine andere CPU notwendig sein sollte. Aus Sicht des Betriebssystems mag dies beim Wechseln zwischen OpenOffice-Fenstern und dem Terminal unproblematisch sein, aber für die Datenbank - es ist sehr schlecht. Daher besteht eine vernünftige Strategie darin, migration_cost auf einen großen Wert festzulegen, mindestens einige tausend Nanosekunden.
Was bedeutet das für den Planer? Es wird davon ausgegangen, dass dieser Prozess während dieser Zeit noch heiß ist. Das heißt, wenn eine lange Transaktion über einen längeren Zeitraum ausgeführt wird, wird der Planer dies verstehen. Er geht davon aus, dass dieser Prozess bis zum Ablauf dieser Zeitüberschreitung nirgendwo migriert werden muss. Wenn der Prozess gleichzeitig etwas tut, wird er nirgendwohin migriert, sondern wird ruhig auf der ihm zugewiesenen CPU beendet. Und das Ergebnis ist ausgezeichnet.
Der zweite Punkt ist die automatische Gruppe. Für bestimmte Arbeitslasten, die nicht mit modernen Datenbanken in Zusammenhang stehen, gibt es eine gute Idee: Prozesse nach dem virtuellen Terminal zu gruppieren, von dem aus sie gestartet werden. Für einige Aufgaben ist es praktisch. In der Praxis handelt es sich bei PostgreSQL um ein Prefork-Multiprozesssystem, das von einem einzigen Terminal aus ausgeführt wird. Sie verfügen über einen Sperrenschreiber und einen Prüfpunkt, und alle Ihre Clientanforderungen werden pro CPU in einem Planer gruppiert. Und sie werden dort gemeinsam warten, wenn er frei ist, um sich gegenseitig zu stören und ihn länger zu beschäftigen. Dies ist eine Geschichte, die bei einer solchen Belastung völlig unnötig ist und daher ausgeschaltet werden sollte.

Mein Kollege Alexey Lesovsky führte Tests mit einem einfachen pgbench durch, bei dem er migration_cost um eine Größenordnung erhöhte und die automatische Gruppe deaktivierte. Es stellte sich heraus, dass der Unterschied bei einem schlechten Stück Eisen fast 10 % betrug.. Auf der Postgres-Mailingliste gibt es eine Diskussion, in der Leute über Ergebnisse wie ähnliche Änderungen der Abfragegeschwindigkeit berichten 50 % beeinflusst. Es gibt viele solcher Geschichten.

Und schließlich noch zur Energiesparpolitik. Es ist gut, dass jetzt Linux Man kann es auf einem Laptop verwenden. Und es soll angeblich den Akku gut entladen. Es stellt sich aber heraus, dass dasselbe auch auf einem Server passieren kann.
Wenn Sie Server von einem beliebigen Hosting-Anbieter mieten, dann ist das „gut“. Gastgeber Ihnen ist Ihre Leistung egal. Ihre Aufgabe ist es, die Hardware so effizient wie möglich zu nutzen. Deshalb können sie im Betriebssystem standardmäßig einen laptopähnlichen Energiesparmodus aktivieren.
Wenn Sie dies auf einem stark ausgelasteten Datenbankserver verwenden, wählen Sie acpi_cpufreq + permormance. Selbst bei OnDemand wird es bereits Probleme geben.
Intel_pstate ist ein etwas anderer Treiber. Und jetzt wird diesem der Vorzug gegeben, statt einem späteren und besser funktionierenden.
Und dementsprechend ist der Gouverneur nur Leistung. On-Demand, Powersave und alles andere – hier geht es nicht um Sie.
Die Ergebnisse der EXPLAIN-Analyse von PostgreSQL können um mehrere Größenordnungen abweichen, wenn Sie den Energiesparmodus aktivieren, da es in der Praxis zu einem völlig unvorhersehbaren CPU-Verlust unter der Datenbank kommen wird.
Diese Dinge können standardmäßig aktiviert werden. Schauen Sie genau nach, ob sie standardmäßig aktiviert sind. Das kann ein wirklich großes Problem sein.

Und am Ende möchte ich mich bei den Jungs aus unserem PosgreSQL-Consulting DBA-Team bedanken, nämlich Max Boguk und Alexey Lesovsky, die jeden Tag Unebenheiten in diesem Geschäft füllen. Und für unsere Kunden versuchen wir das Beste zu geben, damit alles für sie funktioniert. Es ist wie bei Flugsicherheitsanweisungen. Hier ist alles mit Blut geschrieben. Jede dieser Nüsse wird im Laufe eines Problems entdeckt. Gerne teile ich sie mit Ihnen.
Fragen:
Danke! Wenn ein Unternehmen beispielsweise Geld sparen möchte und die Datenbank- und Anwendungslogik auf demselben Server hosten möchte oder wenn das Unternehmen dem Modetrend von Microservice-Architekturen folgt, bei denen PostgreSQL in einem Container läuft. Was ist der Punkt? Sysctl wirkt sich global auf den gesamten Kernel aus. Ich habe nicht gehört, dass Sysctls irgendwie virtualisiert sind, sodass sie separat im Container arbeiten. Es gibt nur eine cgroup und nur ein Teil davon hat die Kontrolle. Wie kann man damit leben? Oder wenn Sie Leistung wünschen, dann PostgreSQL auf einem separaten Eisenserver ausführen und optimieren?
Wir haben Ihre Frage auf etwa drei Arten beantwortet. Wenn es sich nicht um einen einstellbaren Eisenserver usw. handelt, dann seien Sie beruhigt, ohne diese Einstellungen wird alles gut funktionieren. Wenn Sie eine solche Auslastung haben, dass Sie diese Einstellungen vornehmen müssen, werden Sie früher als diese Einstellungen zum Iron-Server gelangen.
Was ist das Problem? Wenn es sich um eine virtuelle Maschine handelt, werden Sie höchstwahrscheinlich viele Probleme haben, zum Beispiel aufgrund der Tatsache, dass die meisten virtuellen Maschinen eine ziemlich inkonsistente Festplattenlatenz haben. Selbst wenn der Festplattendurchsatz gut ist, wird die Datenbank durch eine einzelne fehlgeschlagene E/A-Transaktion, die den durchschnittlichen Durchsatz zum Zeitpunkt des Prüfpunkts oder zum Zeitpunkt des Schreibens in WAL nicht wesentlich beeinträchtigt, erheblich beeinträchtigt. Und Sie werden dies bemerken, bevor Sie auf diese Probleme stoßen.
Wenn Sie NGINX auf demselben Server haben, treten auch Sie vor dem gleichen Problem auf. Er wird für die gemeinsame Erinnerung kämpfen. Und Sie werden nicht auf die hier beschriebenen Probleme stoßen.
Andererseits werden einige dieser Parameter dennoch für Sie relevant sein. Stellen Sie beispielsweise mit sysctl dirty_ratio so ein, dass es nicht so verrückt ist – das wird auf jeden Fall helfen. Auf die eine oder andere Weise werden Sie mit der Festplatte interagieren. Und es wird falsch sein. Dies ist im Allgemeinen die Standardeinstellung der von mir angezeigten Parameter. Und auf jeden Fall ist es besser, sie zu ändern.
Und mit NUMA kann es Probleme geben. VmWare funktioniert beispielsweise gut mit NUMA mit genau den entgegengesetzten Einstellungen. Und hier müssen Sie sich entscheiden – einen Server aus Eisen oder einen ohne Eisen.
Ich habe eine Frage zu Amazon AWS. Sie haben Bilder vorkonfiguriert. Einer davon heißt Amazon RDS. Gibt es benutzerdefinierte Einstellungen für ihr Betriebssystem?
Es gibt Einstellungen, aber es sind unterschiedliche Einstellungen. Hier konfigurieren wir das Betriebssystem im Hinblick darauf, wie die Datenbank dieses Geschäft nutzen wird. Und es gibt Parameter, die bestimmen, wohin wir jetzt gehen sollen, eine solche Gestaltung. Das heißt, wir brauchen so viele Ressourcen, dass wir sie jetzt auffressen werden. Danach beschleunigt Amazon RDS diese Ressourcen und es kommt zu Leistungseinbußen. Es gibt verschiedene Geschichten darüber, wie Menschen anfangen, mit dieser Angelegenheit zu harmonieren. Teilweise sogar recht erfolgreich. Aber es hat nichts mit den Betriebssystemeinstellungen zu tun. Es ist wie Cloud-Hacking. Es ist eine andere Geschichte.
Warum haben transparente riesige Seiten im Vergleich zu riesigen TLB keine Auswirkung?
Gib nicht. Dies kann auf viele Arten erklärt werden. Aber in Wirklichkeit geben sie es einfach nicht. Was ist die Geschichte von PostgreSQL? Beim Start wird ein großer Teil des gemeinsam genutzten Speichers zugewiesen. Transparent sind sie gleichzeitig oder nicht transparent – das spielt überhaupt keine Rolle. Die Tatsache, dass sie am Anfang auffallen, erklärt alles. Und wenn viel Speicher vorhanden ist und Sie das Shared_Memory-Segment neu erstellen müssen, sind transparente große Seiten relevant. In PostgreSQL wird es am Anfang einfach mit einem großen Stück hervorgehoben und das wars, und dann passiert dort nichts Besonderes. Sie können es natürlich verwenden, aber es besteht die Möglichkeit, dass es zu einer Unterbrechung des shared_memory kommt, wenn etwas neu zugewiesen wird. PostgreSQL weiß davon nichts.
Source: habr.com
