


Wir schreiben das Jahr 2019 und wir haben immer noch keine standardisierte Lösung zur Protokollaggregation in Kubernetes. In diesem Artikel möchten wir anhand praktischer Beispiele unsere Herausforderungen, aufgetretenen Probleme und deren Lösungen teilen.
Um jedoch zu beginnen, möchte ich anmerken, dass verschiedene Auftraggeber beim Thema Log-Sammlung ganz unterschiedliche Vorstellungen haben:
- manche möchten Security- und Audit-Logs sehen;
- andere wünschen sich ein zentrales Logging für die gesamte Infrastruktur;
- während einige es vorziehen, nur die Anwendungslogs zu sammeln und beispielsweise Load-Balancer auszuschließen.
Wie wir verschiedene "Wünsche" umgesetzt haben und mit welchen Schwierigkeiten wir konfrontiert wurden, finden Sie im weiteren Verlauf.
Theorie: Über Tools zur Protokollierung
Hintergrund über die Komponenten eines Log-Systems
Die Protokollierung hat einen langen Weg hinter sich, auf dem sich Methoden zur Sammlung und Analyse von Logs entwickelt haben, die wir heute anwenden. Bereits in den 1950er Jahren gab es in Fortran einen Äquivalent zu den standardisierten Ein- und Ausgabeströmen, die Programmierern bei der Fehlersuche halfen. Dies waren die ersten Computer-Logs, die das Leben der Programmierer jener Zeit erleichterten. Heute erkennen wir darin die erste Komponente eines Protokollierungssystems. Quelle oder „Hersteller“ (producer) von Protokollen.
Die Informatik hat sich weiterentwickelt: Computernetzwerke und die ersten Cluster wurden eingeführt... Komplexe Systeme, die aus mehreren Computern bestehen, beginnen zu arbeiten. Systemadministratoren mussten nun Protokolle von mehreren Maschinen sammeln und konnten in bestimmten Fällen sogar Kernelmeldungen des Betriebssystems hinzufügen, um mögliche Systemfehler zu untersuchen. Um die Systeme der zentralisierten Protokollsammlung zu beschreiben, wurde zu Beginn der 2000er Jahre , veröffentlicht, der remote_syslog standardisierte. So entstand ein weiterer wichtiger Bestandteil: Protokollsammler und deren Speicher.
Mit dem Anstieg des Protokollvolumens und der weitverbreiteten Einführung von Webtechnologien stellte sich die Frage, wie Protokolle den Benutzern übersichtlich präsentiert werden können. Anstelle einfacher Konsolenwerkzeuge (awk/sed/grep) kamen fortschrittlichere Protokollbetrachter — der dritte Bestandteil.
Mit dem Anstieg des Logvolumens wurde deutlich, dass Logs wichtig sind, aber nicht alle gleichwertig. Außerdem erfordern unterschiedliche Logs verschiedene Aufbewahrungsstufen: Einige können nach einem Tag verloren gehen, während andere fünf Jahre lang aufbewahrt werden müssen. Daher wurde ein Filter- und Routing-Komponenten zu unserem Logging-System hinzugefügt – nennen wir ihn Filter.
Auch die Speichersysteme haben einen erheblichen Sprung gemacht: Von normalen Dateien wechselten wir zu relationalen Datenbanken und schließlich zu dokumentenorientierten Speichern (zum Beispiel Elasticsearch). So hat sich das Speichersystem vom Collector getrennt.
Letztendlich hat sich das gesamte Konzept des Logs zu einem abstrakten Ereignisstrom erweitert, den wir für die Historie aufbewahren möchten. Genauer gesagt – für den Fall, dass eine Untersuchung durchgeführt oder ein analytischer Bericht erstellt werden muss …
Infolgedessen hat sich die Logsammlung in einem relativ kurzen Zeitraum zu einem wichtigen Teilsystem entwickelt, das zu Recht als eines der Unterbereiche von Big Data bezeichnet werden kann.
Wenn früher einfache prints für ein „Logging-System“ ausreichend sein konnten, hat sich die Situation nun erheblich verändert.
Kubernetes und Logs
Als Kubernetes in die Infrastruktur eintrat, wurde das bereits bestehende Problem der Protokollerfassung auch hier relevant. In gewissem Sinne wurde es sogar komplexer: Das Management der Infrastrukturplattform wurde zwar vereinfacht, aber gleichzeitig auch komplizierter. Viele ältere Dienstleistungen begannen, auf microservices-basierte Strukturen umzustellen. Im Kontext der Protokolle äußerte sich dies in einer zunehmenden Anzahl von Protokollquellen, ihrem besonderen Lebenszyklus und der Notwendigkeit, über die Protokolle die Beziehungen aller Systemkomponenten zu überwachen…
Um es vorwegzunehmen: Leider gibt es derzeit keine standardisierte Logging-Lösung für Kubernetes, die sich signifikant von anderen abheben würde. Die beliebtesten im Community sind folgende Ansätze:
- einige implementieren einen Stack EFK (Elasticsearch, Fluentd, Kibana);
- andere - experimentieren mit dem neu veröffentlichten oder verwenden ;
- uns (und vielleicht nicht nur uns? ..) in vielen Fällen sind wir mit unserer eigenen Entwicklung zufrieden - …
In der Regel verwenden wir solche Kombinationen in K8s-Clustern (für self-hosted Lösungen):
- ;
- .
Ich werde jedoch nicht auf die Anleitungen zur Installation und Konfiguration eingehen. Stattdessen konzentriere ich mich auf die Nachteile und umfassenderen Schlussfolgerungen zur Situation mit Protokollen im Allgemeinen.
Praxis mit Protokollen in K8s

„Alltägliche Protokolle“, wie viele von euch gibt es?
Die zentrale Erfassung von Protokollen aus einer vergleichsweise großen Infrastruktur erfordert beträchtliche Ressourcen, die für die Erfassung, Speicherung und Verarbeitung der Protokolle benötigt werden. Im Verlauf der Nutzung verschiedener Projekte sind wir auf unterschiedliche Anforderungen und die damit verbundenen Probleme gestoßen.
Lass uns ClickHouse ausprobieren
Betrachten wir ein zentrales Speicherprojekt mit einer Anwendung, die recht aktiv Protokolle generiert: über 5000 Zeilen pro Sekunde. Wir beginnen mit der Arbeit an seinen Protokollen und speichern sie in ClickHouse.
Sobald maximale Echtzeit erforderlich ist, wird ein 4-Kern-Server mit ClickHouse bereits durch das Speichersystem überlastet sein:
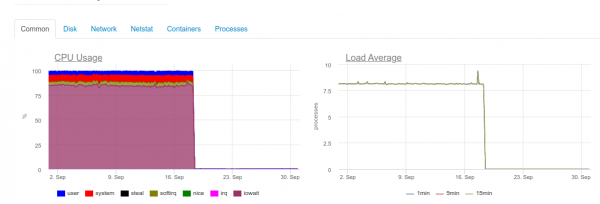
Dieser Belastungstyp hängt damit zusammen, dass wir versuchen, so schnell wie möglich in ClickHouse zu schreiben. Die Datenbank reagiert darauf mit einer erhöhten Belastung des Speichers, was zu solchen Fehlern führen kann:
DB::Exception: Zu viele Teile (300). Zusammenführungen verlaufen deutlich langsamer als Einfügungen.
Das Problem ist, dass in ClickHouse (die Logdaten sind dort gespeichert) bringen ihre eigenen Herausforderungen bei Schreibvorgängen mit sich. Eingefügte Daten erzeugen eine temporäre Partition, die anschließend mit der Haupttabelle zusammengeführt wird. Das Ergebnis ist, dass der Schreibvorgang sehr diskintensiv ist und unter einer Einschränkung leidet, über die wir oben informiert wurden: Es können pro Sekunde nicht mehr als 300 Subpartitionen zusammengeführt werden (tatsächlich entspricht das 300 Inserts pro Sekunde).
Um ein solches Verhalten zu vermeiden, so große Datenmengen wie möglich und nicht öfter als einmal alle 2 Sekunden schreiben. Jedoch setzt das Schreiben in großen Paketen voraus, dass wir seltener in ClickHouse schreiben. Dies kann wiederum zu einem Überlauf des Puffers und zum Verlust von Logs führen. Die Lösung besteht darin, den Buffer von Fluentd zu vergrößern, aber das erhöht auch den Speicherverbrauch.
Hinweis: Ein weiteres problematisches Element unserer Lösung mit ClickHouse war, dass die Partitionierung in unserem Fall (loghouse) über externe Tabellen umgesetzt wurde, die mit der . Dies führt dazu, dass beim Abfragen großer Zeitintervalle übermäßig viel Arbeitsspeicher benötigt wird, da die Metatabelle alle Partitionen durchläuft – selbst die, die keine relevanten Daten enthalten. Diese Vorgehensweise kann jedoch für die aktuellen Versionen von ClickHouse als überholt angesehen werden. ).
Folglich wird klar, dass nicht jedes Projekt über ausreichende Ressourcen verfügt, um Echtzeitprotokolle in ClickHouse zu sammeln (genauer gesagt, deren Verteilung ist nicht sinnvoll). Zusätzlich wird es notwendig sein, einen Puffer, auf den wir später noch zurückkommen werden. Der oben beschriebene Fall ist real. Zu diesem Zeitpunkt konnten wir keine zuverlässige und stabile Lösung anbieten, die den Anforderungen des Kunden gerecht wurde und die Protokolle mit minimaler Verzögerung sammeln konnte…
Und Elasticsearch?
Es ist bekannt, dass Elasticsearch mit hohen Lasten umgehen kann. Lassen Sie uns es im selben Projekt ausprobieren. Nun sieht die Last wie folgt aus:
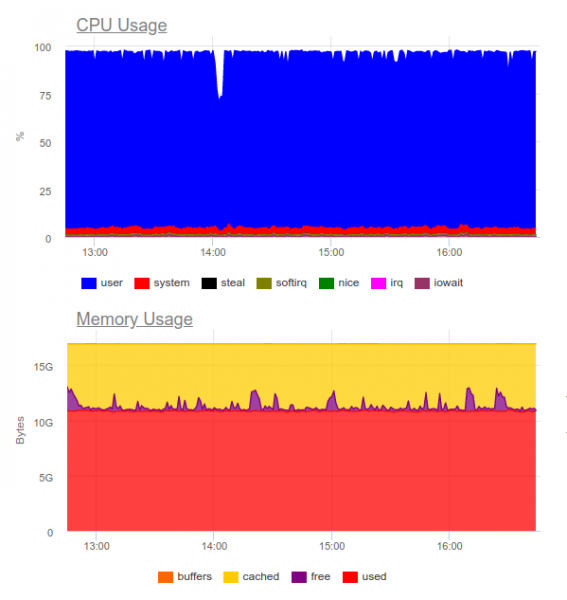
Elasticsearch kann den Datenstrom verarbeiten, allerdings beansprucht das Speichern solcher Volumina stark die CPU. Dies lässt sich durch die Organisation eines Clusters lösen. Technisch gesehen ist das kein Problem, jedoch bedeutet das, dass wir allein für den Betrieb des Log-Sammelsystems bereits etwa 8 Kerne nutzen und ein zusätzliches hochbelastetes Element im System haben...
Fazit: Diese Variante kann gerechtfertigt sein, aber nur, wenn das Projekt groß ist und dessen Leitung bereit ist, erhebliche Ressourcen in ein zentrales Logging-System zu investieren.
Dann stellt sich die naheliegende Frage:
Welche Logs sind wirklich notwendig?
 Versuchen wir, den Ansatz zu ändern: Logs sollten gleichzeitig informativ sein und nicht jedes Ereignis im System abdecken.
Versuchen wir, den Ansatz zu ändern: Logs sollten gleichzeitig informativ sein und nicht jedes Ereignis im System abdecken.
Nehmen wir an, wir haben einen erfolgreichen Online-Shop. Welche Logs sind wichtig? So viele Informationen wie möglich vom Zahlungs-Gateway zu sammeln – eine ausgezeichnete Idee. Bei dem Service zur Bildbearbeitung im Produktkatalog hingegen sind nicht alle Logs kritisch für uns: Fehlermeldungen und eine erweiterte Überwachung (zum Beispiel den Anteil der 500er-Fehler, die dieses Element erzeugt) genügen.
Damit kommen wir zu dem Punkt, dass Zentralisiertes Logging ist nicht immer gerechtfertigt.Sehr oft möchte der Kunde alle Protokolle an einem Ort sammeln, obwohl tatsächlich nur etwa 5% der Nachrichten aus dem gesamten Protokoll geschäftskritisch sind.
- Manchmal reicht es aus, beispielsweise nur die Größe des Container-Logs und den Fehlercollector (z. B. Sentry) zu konfigurieren.
- Für die Untersuchung von Vorfällen kann oft bereits eine Fehlermeldung zusammen mit einem großen lokalen Log ausreichen.
- Wir hatten Projekte, die sich ausschließlich auf funktionale Tests und Fehlererfassungssysteme stützten. Die Entwickler benötigten keine Logs, da sie alles über die Fehler-Tracebacks sehen konnten.
Ein Beispiel aus der Praxis
Ein gutes Beispiel kann eine andere Geschichte sein. Wir erhielten eine Anfrage vom Sicherheitsteam eines unserer Kunden, das bereits eine kommerzielle Lösung verwendete, die lange vor der Einführung von Kubernetes entwickelt wurde.
Es war notwendig, das zentrale Log-Sammelsystem mit dem Unternehmenssensor zur Problemidentifizierung – QRadar – zu integrieren. Dieses System kann Logs über das Syslog-Protokoll empfangen und über FTP abrufen. Die Integration mit dem Remote-Syslog-Plugin für Fluentd klappte jedoch nicht auf Anhieb. (wie sich herausstellte, ). Die Probleme bei der Konfiguration von QRadar lagen im Bereich des Sicherheitsteams des Kunden.
Daher wurden einige Logs, die für das Geschäft kritisch waren, auf den FTP-Server von QRadar übertragen, während andere direkt von den Knoten über Remote Syslog umgeleitet wurden. Zu diesem Zweck haben wir sogar einen geschrieben – möglicherweise hilft er jemandem, ein ähnliches Problem zu lösen... Dank des entstandenen Schemas konnte der Kunde die kritischen Logs erhalten und analysieren (mit seinem bevorzugten Werkzeug) und wir konnten die Kosten für das Logging-System reduzieren, indem wir nur den letzten Monat speicherten.
Ein weiteres Beispiel zeigt deutlich, wie es nicht gemacht werden sollte. Einer unserer Kunden hatte für die Verarbeitung jede von Ereignissen, die vom Benutzer eingingen, eine mehrzeilige unstrukturierte Ausgabe erstellt. Informationen im Log. Wie leicht zu erraten, war es äußerst unpraktisch, solche Protokolle zu lesen und zu speichern.
Kriterien für Logs
Solche Beispiele führen zu der Erkenntnis, dass neben der Auswahl des Systems zur Protokollsammlung auch die Protokolle selbst entworfen werden müssen.! Welche Anforderungen gibt es hier?
- Die Logs müssen in einem maschinenlesbaren Format vorliegen (zum Beispiel JSON).
- Die Logs sollten kompakt sein und die Möglichkeit bieten, das Protokollierungsniveau zu ändern, um mögliche Probleme zu debuggen. In Produktionsumgebungen sollten Systeme mit einem Protokollierungsgrad wie Warnung oder Fehler.
- Die Logs sollten normalisiert sein, das heißt, alle Felder im Log-Objekt müssen vom gleichen Typ sein.
Unstrukturierte Logs können zu Problemen beim Laden der Logs in den Speicher und einem vollständigen Halt ihrer Verarbeitung führen. Zum Beispiel ein Beispiel für einen 400-Fehler, dem viele sicher in den Logs von fluentd begegnet sind:
2019-10-29 13:10:43 +0000 [warn]: einen Fehlerereignis dumpen: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Von Elasticsearch abgelehnt"
Der Fehler bedeutet, dass Sie ein Feld mit einem vorbereiteten Mapping in den Index senden, dessen Typ instabil ist. Ein einfaches Beispiel ist ein Feld im Nginx-Log mit der Variable $upstream_status. Es kann sowohl eine Zahl als auch eine Zeichenkette enthalten. Zum Beispiel:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Okt/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Okt/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}
In den Logs ist zu sehen, dass der Server 10.100.0.10 mit einem 404-Fehler geantwortet hat und die Anfrage an ein anderes Content-Storage weitergeleitet wurde. Infolgedessen hat sich der Wert in den Logs zu folgendem geändert:
"upstream_response_time": "0.001, 0.007"
Diese Situation ist so verbreitet, dass sie sogar eine eigene .
Und wie steht es um die Zuverlässigkeit?
Es gibt Fälle, in denen es lebenswichtig ist, alle Logs ohne Ausnahme zu haben. Und damit haben die typischen Log-Sammelschemata für K8s, die oben vorgeschlagen/erörtert wurden, Probleme.
Zum Beispiel kann fluentd keine Logs von kurzlebigen Containern sammeln. In einem unserer Projekte lebte ein Container mit einer Datenbankmigration weniger als 4 Sekunden und wurde dann entfernt — gemäß der entsprechenden Annotation:
"helm.sh/hook-delete-policy": hook-succeeded
Aufgrund dessen gelangte das Log der Migration nicht in den Speicher. In diesem Fall kann die Politik before-hook-creation.
Ein weiteres Beispiel ist die Rotation von Docker-Logs. Angenommen, es gibt eine Anwendung, die aktiv Protokolle schreibt. Unter normalen Umständen schaffen wir es, alle Logs zu verarbeiten, aber sobald ein Problem auftritt – wie oben beschrieben mit dem falschen Format – stoppt die Verarbeitung, und Docker rotiert die Datei. Das Ergebnis ist, dass geschäftskritische Logs verloren gehen können.
Deshalb Es ist wichtig, die Logströme zu trennen, indem man die wertvollsten Informationen direkt in die Anwendung sendet, um deren Sicherheit zu gewährleisten. Darüber hinaus ist die Schaffung eines „Log-Akkumulators“, der eine kurzfristige Nichtverfügbarkeit des Speichers überstehen kann, während kritische Nachrichten erhalten bleiben.
Schließlich sollte nicht vergessen werden, dass jede Teilsystem qualitativ überwacht werden muss. Andernfalls kann man leicht in eine Situation geraten, in der fluentd sich in einem Zustand befindet CrashLoopBackOff und nichts sendet, was den Verlust wichtiger Informationen zur Folge hätte.
Fazit
In diesem Artikel behandeln wir keine SaaS-Lösungen wie Datadog. Viele der hier beschriebenen Probleme wurden bereits von kommerziellen Unternehmen, die sich auf das Sammeln von Logs spezialisiert haben, gelöst, jedoch können nicht alle aus verschiedenen Gründen SaaS nutzen. (die Hauptaspekte sind die Kosten und die Einhaltung des Gesetzes 152-FZ).
Die zentralisierte Protokollierung scheint zunächst eine einfache Aufgabe zu sein, ist jedoch alles andere als das. Es ist wichtig zu beachten, dass:
- Nur kritische Komponenten sollten detailliert protokolliert werden, während für andere Systeme eine Überwachung und Sammlung von Fehlern eingerichtet werden kann.
- Protokolle im Produktionsumfeld sollten minimal gehalten werden, um unnötige Belastung zu vermeiden.
- Protokolle müssen maschinenlesbar, normalisiert und in einem strengen Format vorliegen.
- Wirklich kritische Protokolle sollten in einem separaten Strom gesendet werden, der von den Hauptprotokollen getrennt ist.
- Es ist ratsam, einen Protokollspeicher zu planen, der vor plötzlichen Lastspitzen schützt und die Belastung des Speichers gleichmäßiger verteilt.

Diese einfachen Regeln, wenn sie überall beachtet werden, würden den oben beschriebenen Schemen ermöglichen zu funktionieren – auch wenn wichtige Komponenten (wie ein Speicher) fehlen. Wenn man sich jedoch nicht an solche Prinzipien hält, wird die Aufgabe leicht dazu führen, dass Sie und die Infrastruktur ein weiteres hochbelastetes (und gleichzeitig ineffizientes) Systemkomponente erreichen.
P.S.
Lesen Sie auch in unserem Blog:
- «»;
- «»;
- «».
Quelle: habr.com
