


TL;DR
- Um eine hohe Sichtbarkeit von Containern und Mikroservices, Protokollen und primären Kennzahlen zu erreichen, ist eine einfache Protokollierung unzureichend.
- Für eine schnellere Wiederherstellung und erhöhte Fehlertoleranz sollten Anwendungen das Prinzip der hohen Sichtbarkeit (HOP, High Observability Principle) anwenden.
- Auf Anwendungsebene erfordert die HOP: angemessene Protokollierung, sorgfältige Überwachung, Verfügbarkeitsprüfungen und Leistungs- / Übergangs-Trace.
- Nutzen Sie Prüfungen als Teil der HOP. readinessProbe und livenessProbe Kubernetes.
Was ist das Prüfungsprobenmuster?
Bei der Planung einer kritischen und hochverfügbaren Anwendung ist es wichtig, Aspekte wie Fehlertoleranz zu berücksichtigen. Eine Anwendung gilt als fehlertolerant, wenn sie sich schnell nach einem Ausfall erholt. Typische Cloud-Anwendungen verwenden eine Microservices-Architektur, bei der jede Komponente in einem separaten Container untergebracht ist. Um sicherzustellen, dass eine Anwendung auf Kubernetes hochverfügbar ist, sollten beim Entwurf des Clusters bestimmte Muster beachtet werden. Zu diesen gehört das Muster zur Überprüfung der Funktionsfähigkeit. Dieses definiert, wie die Anwendung Kubernetes über ihren Zustand informiert. Es geht dabei nicht nur um die Information, ob ein Pod funktioniert, sondern auch darum, wie er Anfragen akzeptiert und darauf reagiert. Je mehr Kubernetes über die Funktionsfähigkeit eines Pods weiß, desto intelligenter kann es Entscheidungen über den Datenverkehr und die Lastenverteilung treffen. So sorgt das Prinzip hoher Observabilität dafür, dass die Anwendung zeitnah auf Anfragen reagiert.
Prinzip der hohen Observabilität (PHO)
Das Prinzip der hohen Observabilität ist eines der . In der Mikroservice-Architektur spielt es für die Dienste keine Rolle, wie ihre Anfrage verarbeitet wird (und das ist auch richtig), sondern wichtig ist, wie Antworten von den empfangenden Diensten erhalten werden. Zum Beispiel sendet ein Container für die Benutzerauthentifizierung eine HTTP-Anfrage an einen anderen Container und erwartet eine Antwort in einem bestimmten Format – das ist alles. Die Anfrage kann in PythonJS bearbeitet werden, während die Antwort von Python Flask kommen kann. Container sind füreinander wie schwarze Kisten mit verborgenem Inhalt. Allerdings verlangt das NORN-Prinzip, dass jeder Dienst mehrere API-Endpunkte offenlegt, die zeigen, wie funktionsfähig er ist, sowie seinen Zustand der Bereitschaft und Ausfallsicherheit. Diese Kennzahlen werden von Kubernetes angefordert, um die nächsten Schritte für das Routing und das Load-Balancing zu planen.
Eine gut gestaltete Cloud-Anwendung protokolliert ihre Hauptereignisse über die Standard-Eingabe-/Ausgabe-Streams STDERR und STDOUT. Anschließend wird ein unterstützender Dienst, wie zum Beispiel Filebeat, Logstash oder Fluentd, eingesetzt, um die Protokolle in ein zentrales Monitoring-System (wie Prometheus) und ein Protokollsammelsystem (ELK-Stack) zu überführen. Die nachfolgende Abbildung zeigt, wie die Cloud-Anwendung gemäß dem Verfügbarkeitsmuster und dem Prinzip hoher Beobachtbarkeit funktioniert.
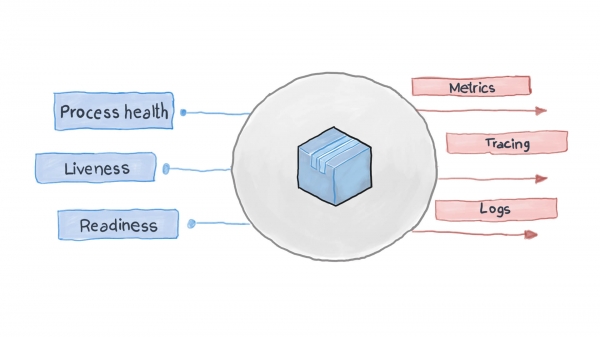
Wie kann das Verfügbarkeitsmuster in Kubernetes angewendet werden?
Kubernetes überwacht standardmäßig den Status von Pods mit einem der Controller (, , , Wenn ein Pod aus irgendeinem Grund ausgefallen ist, versucht der Controller, ihn neu zu starten oder auf einen anderen Knoten zu verschieben. Allerdings kann es sein, dass der Pod meldet, er sei aktiv und funktionsfähig, während er tatsächlich nicht funktioniert. Nehmen wir an, Ihre Anwendung verwendet Apache als Webserver und Sie haben das Modul auf mehrere Pods im Cluster installiert. Da die Bibliothek falsch konfiguriert wurde, antworten alle Anfragen an die Anwendung mit dem Code 500 (interner Serverfehler). Bei einer Überprüfung stellt sich heraus, dass der Zustand der Pods als erfolgreich gilt, doch die Kunden berichten etwas anderes. Diese unerwünschte Situation lässt sich wie folgt beschreiben:
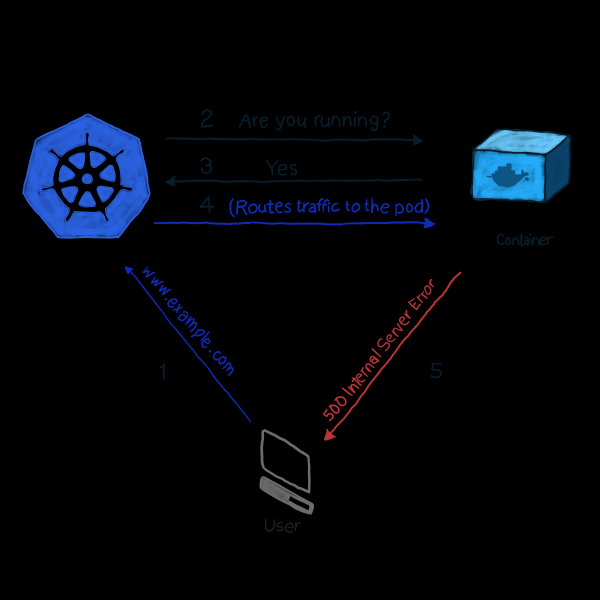
In unserem Beispiel führt k8s eine Funktionsprüfung durch. In dieser Art der Überprüfung überwacht der Kubelet kontinuierlich den Zustand des Prozesses im Container. Sobald er feststellt, dass der Prozess gestoppt ist, wird er neu gestartet. Wenn ein einfacher Neustart der Anwendung den Fehler behebt und das Programm so konzipiert ist, dass es bei jedem Fehler heruntergefahren wird, dann genügt es für die Einhaltung der NORM und des Lebensprüfungsmodells, die Funktionsfähigkeit des Prozesses zu überprüfen. Schade nur, dass nicht alle Fehler durch einen Neustart behoben werden. In diesem Fall bietet k8s zwei tiefere Methoden zur Fehlersuche im Pod an: und .
LivenessProbe
Während livenessProbe der Kubelet drei Arten von Überprüfungen durchführt: Er stellt nicht nur fest, ob der Pod funktioniert, sondern auch, ob er bereit ist, Anfragen zu empfangen und angemessen darauf zu reagieren:
- Stellen Sie eine HTTP-Anfrage an den Pod. Die Antwort sollte einen HTTP-Statuscode im Bereich von 200 bis 399 enthalten. Somit signalisierten Codes 5xx und 4xx, dass der Pod Probleme hat, selbst wenn der Prozess läuft.
- Für die Überprüfung von Pods mit Nicht-HTTP-Diensten (z. B. dem Mailserver Postfix) muss eine TCP-Verbindung hergestellt werden.
- Ausführung eines beliebigen Kommandos für den Pod (intern). Die Überprüfung gilt als erfolgreich, wenn der Exit-Code des Kommandos 0 ist.
Ein Beispiel, wie das funktioniert. Die Definition des nächsten Pods enthält eine NodeJS-Anwendung, die bei HTTP-Anfragen einen Fehler 500 zurückgibt. Um sicherzustellen, dass der Container neu gestartet wird, wenn dieser Fehler auftritt, verwenden wir den Parameter livenessProbe:
apiVersion: v1
kind: Pod
metadata:
name: node500
spec:
containers:
- image: magalix/node500
name: node500
ports:
- containerPort: 3000
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 3000
initialDelaySeconds: 5Das unterscheidet sich nicht von der Definition eines anderen Pods, aber wir fügen das Objekt .spec.containers.livenessProbe. Parameter httpGet hinzu, das den Pfad akzeptiert, zu dem die HTTP GET-Anfrage gesendet wird (in unserem Beispiel ist das /, in realen Szenarien könnte es jedoch auch etwas wie /api/v1/status). Außerdem akzeptiert livenessProbe den Parameter initialDelaySeconds, der angibt, dass die Überprüfungsoperationen eine bestimmte Anzahl von Sekunden warten sollen. Die Verzögerung ist nötig, da der Container Zeit für den Start benötigt, und nach dem Neustart vorübergehend nicht verfügbar sein wird.
Um diese Einstellung auf den Cluster anzuwenden, verwenden Sie:
kubectl apply -f pod.yamlNach einigen Sekunden können Sie den Inhalt des Pods mit folgendem Befehl überprüfen:
kubectl describe pods node500Suchen Sie am Ende der Ausgabe nach .
Wie Sie sehen können, hat der livenessProbe eine HTTP GET-Anfrage ausgelöst, der Container hat einen Fehler 500 ausgegeben (was so programmiert war), und kubelet hat ihn neu gestartet.
Falls Sie neugierig sind, wie die NideJS-Anwendung programmiert wurde, hier sind die Dateien app.js und Dockerfile, die verwendet wurden:
app.js
var http = require('http');
var server = http.createServer(function(req, res) {
res.writeHead(500, { "Content-type": "text/plain" });
res.end("Wir sind auf einen Fehler gestoßen\n");
});
server.listen(3000, function() {
console.log('Server läuft auf Port 3000')
})Dockerfile
FROM node
COPY app.js /
EXPOSE 3000
ENTRYPOINT [ "node", "/app.js" ]Es ist wichtig, folgendes zu beachten: Der livenessProbe wird den Container nur bei einem Ausfall neu starten. Wenn der Neustart den Fehler, der den Betrieb des Containers verhindert, nicht behoben hat, kann kubelet keine Maßnahmen zur Fehlersuche ergreifen.
readinessProbe
Die readinessProbe funktioniert ähnlich wie livenessProbes (GET-Anfragen, TCP-Verbindungen und Kommandausführung), mit Ausnahme der Fehlerbehebungsmaßnahmen. Ein Container, der ausgefallen ist, wird nicht neu gestartet, sondern vom eingehenden Verkehr isoliert. Stellen Sie sich vor, einer der Container führt viele Berechnungen durch oder ist stark belastet, was zu einer erhöhten Antwortzeit auf Anfragen führt. Bei livenessProbe wird die Verfügbarkeit der Antwort überprüft (über den Parameter timeoutSeconds), woraufhin der Kubelet den Container neu startet. Sobald der Container startet, beginnt er ressourcenintensive Aufgaben auszuführen und wird erneut neu gestartet. Dies kann kritisch für Anwendungen sein, die eine schnelle Reaktionszeit erfordern. Zum Beispiel wartet ein Fahrzeug unterwegs auf eine Antwort vom Server, die Antwort verzögert sich – und das Fahrzeug kommt zu einem Unfall.
Lassen Sie uns eine Definition für readinessProbe schreiben, die die Antwortzeit auf GET-Anfragen auf maximal zwei Sekunden festlegt, während die Anwendung auf eine GET-Anfrage nach fünf Sekunden antwortet. Die Datei pod.yaml sollte folgendermaßen aussehen:
apiVersion: v1
kind: Pod
metadata:
name: nodedelayed
spec:
containers:
- image: afakharany/node_delayed
name: nodedelayed
ports:
- containerPort: 3000
protocol: TCP
readinessProbe:
httpGet:
path: /
port: 3000
timeoutSeconds: 2Wir werden den Pod mit kubectl bereitstellen:
kubectl apply -f pod.yamlWarten wir ein paar Sekunden und schauen uns dann an, wie die readinessProbe funktioniert hat:
kubectl describe pods nodedelayedAm Ende der Ausgabe können wir sehen, dass einige Ereignisse ähnlich sind .
Wie Sie sehen, hat kubectl den Pod nicht neu gestartet, als die Überprüfungszeit 2 Sekunden überschritt. Stattdessen hat er die Anfrage abgebrochen. Eingehende Verbindungen werden an andere, funktionsfähige Pods weitergeleitet.
Beachten Sie: Jetzt, wo die zusätzliche Last vom Pod genommen wurde, leitet kubectl die Anfragen erneut an ihn weiter: Die Antworten auf die GET-Anfragen werden nicht länger verzögert.
Zum Vergleich: hier ist die geänderte Datei app.js:
var http = require('http');
var server = http.createServer(function(req, res) {
const sleep = (milliseconds) => {
return new Promise(resolve => setTimeout(resolve, milliseconds))
}
sleep(5000).then(() => {
res.writeHead(200, { "Content-type": "text/plain" });
res.end("Hellon");
})
});
server.listen(3000, function() {
console.log('Der Server läuft auf Port 3000')
})TL;DR
Vor der Einführung von Cloud-Anwendungen waren Logs das Hauptmittel zur Überwachung und Überprüfung des Status von Anwendungen. Es gab jedoch kein Werkzeug, um Maßnahmen zur Behebung von Problemen zu ergreifen. Logs sind auch heute noch nützlich; sie sollten gesammelt und an ein Log-Management-System zur Analyse von Vorfällen und zur Entscheidungsfindung übertragen werden. [All dies hätte auch ohne Cloud-Anwendungen mit Tools wie Monit getan werden können, aber mit K8s ist es deutlich einfacher geworden 🙂 – Anmerkung der Redaktion. ]
Heute müssen Anpassungen nahezu in Echtzeit vorgenommen werden, weshalb Anwendungen nicht mehr als Black Boxes fungieren sollten. Nein, sie sollten Endpunkte anzeigen, die es Monitoring-Systemen ermöglichen, wertvolle Daten über den Zustand von Prozessen abzufragen und zu sammeln, sodass im Bedarfsfall sofort reagiert werden kann. Dies wird als Designmuster zur Überprüfung der Funktionsfähigkeit bezeichnet und folgt dem Prinzip der hohen Beobachtbarkeit (HOP).
Kubernetes bietet standardmäßig zwei Arten von Gesundheitsprüfungen an: readinessProbe und livenessProbe. Beide verwenden die gleichen Prüfungsarten (HTTP GET-Anfragen, TCP-Verbindungen und die Ausführung von Befehlen). Sie unterscheiden sich darin, welche Maßnahmen bei Problemen mit den Pods ergriffen werden. livenessProbe startet den Container neu in der Hoffnung, dass der Fehler nicht erneut auftritt, während readinessProbe den Pod vom eingehenden Traffic isoliert – bis die Ursache des Problems behoben ist.
Ein richtiges Anwendungsdesign sollte beide Arten von Prüfungen beinhalten und sicherstellen, dass sie ausreichend Daten sammeln, insbesondere in außergewöhnlichen Situationen. Es sollte auch die erforderlichen API-Endpunkte bereitstellen, um dem Überwachungssystem (wie Prometheus) wichtige Metriken zur Betriebsbereitschaft zu übermitteln.
Quelle: habr.com
