


Ein wichtiger Aspekt im Betrieb verteilter Systeme ist die Fehlertoleranz. Kubernetes unterstützt dabei, indem es Controller verwendet, die den Zustand Ihres Systems überwachen und ausgefallene Dienste neu starten. Allerdings kann Kubernetes auch Ihre Anwendungen zwangsweise stoppen, um die allgemeine Betriebsfähigkeit des Systems sicherzustellen. In dieser Reihe werden wir untersuchen, wie Sie Kubernetes helfen können, seine Aufgaben effizienter zu erfüllen und die Ausfallzeiten von Anwendungen zu minimieren.
Vor der Einführung von Containern liefen die meisten Anwendungen auf virtuellen oder physischen Maschinen. Wenn eine Anwendung abstürzte oder einfrohr, konnte es viel Zeit in Anspruch nehmen, die laufende Aufgabe zu stoppen und das Programm erneut zu laden. Im schlimmsten Fall musste jemand dieses Problem manuell in der Nacht lösen, zur ungünstigsten Zeit. Wenn eine wichtige Aufgabe nur von 1-2 Arbeitsmaschinen ausgeführt wurde, war ein solcher Ausfall völlig inakzeptabel.
Daher begann man anstelle eines manuellen Neustarts mit der Überwachung auf Prozessebene, um Anwendungen automatisch neu zu starten, falls sie unerwartet beendet wurden. Wenn das Programm abstürzt, erfasst der Überwachungsprozess den Exit-Code und startet den Server neu. Mit der Einführung von Systemen wie Kubernetes wurde diese Art der Fehlerreaktion einfach in die Infrastruktur integriert.
Kubernetes verwendet eine Ereignisschleife „Beobachtung – Abweichungen erfassen – Maßnahmen ergreifen“, um sicherzustellen, dass die Ressourcen von den Containern zu den Knoten funktionsfähig bleiben.

Das bedeutet, dass Sie die Überwachung der Prozesse nicht mehr manuell starten müssen. Wenn eine Ressource den Health Check nicht besteht, stellt Kubernetes einfach automatisch einen Ersatz bereit. Dabei leistet Kubernetes weit mehr, als nur die Ausfälle Ihrer Anwendungen zu überwachen. Es kann zusätzliche Kopien der Anwendung erstellen, um auf mehreren Maschinen zu arbeiten, die Anwendung aktualisieren oder mehrere Versionen Ihrer Anwendung gleichzeitig ausführen.
Es gibt viele Gründe, warum Kubernetes einen vollkommen gesunden Container anhalten könnte. Wenn Sie beispielsweise Ihr Deployment aktualisieren, wird Kubernetes schrittweise alte Pods stoppen und gleichzeitig neue starten. Wenn Sie einen Knoten deaktivieren, stoppt Kubernetes alle Pods auf diesem Knoten. Schließlich, wenn einem Knoten die Ressourcen ausgehen, schaltet Kubernetes alle Pods aus, um diese Ressourcen freizugeben.
Deshalb ist es äußerst wichtig, dass Ihre Anwendung herunterfährt, ohne die Benutzeroberfläche des Endanwenders wesentlich zu beeinflussen und mit minimalen Wiederherstellungszeiten. Das bedeutet, dass sie vor der Deaktivierung alle erforderlichen Daten speichern, alle Netzwerkverbindungen schließen, verbleibende Aufgaben abschließen und andere dringend benötigte Arbeiten erledigen sollte.
In der Praxis bedeutet dies, dass Ihre Anwendung in der Lage sein muss, die SIGTERM-Nachricht zu verarbeiten – ein Prozessbeendigungssignal, das das Standard-Signal für das kill-Utility in Unix-basierten Betriebssystemen darstellt. Nach dem Erhalt dieses Signals sollte sich die Anwendung ordnungsgemäß herunterfahren.
Nachdem Kubernetes beschlossen hat, einen Pod zu beenden, läuft eine Vielzahl von Ereignissen ab. Lassen Sie uns jeden Schritt ansehen, den Kubernetes beim Herunterfahren eines Containers oder Pods durchführt.
Angenommen, wir möchten einen der Pods beenden. In diesem Moment wird er keine neuen Datenströme mehr empfangen – die laufenden Container im Pod sind davon nicht betroffen, jedoch wird sämtlicher neuer Datenverkehr blockiert.
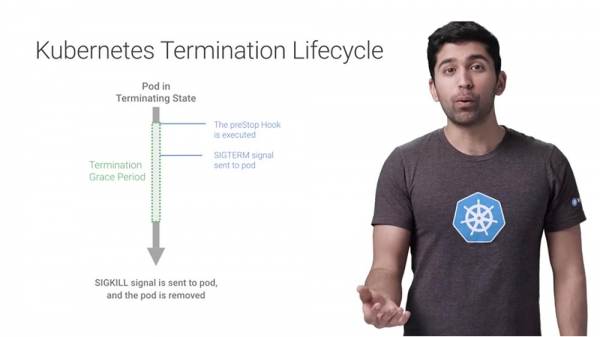
Lassen Sie uns den preStop-Hook betrachten – dies ist ein spezieller Befehl oder HTTP-Request, der an die Container in einem Pod gesendet wird. Wenn Ihre Anwendung auf ein SIGTERM-Signal nicht korrekt reagiert, können Sie den preStop-Hook verwenden, um einen ordnungsgemäßen Shutdown durchzuführen.

Die meisten Programme beenden ihren Prozess korrekt, wenn sie ein SIGTERM-Signal erhalten. Falls Sie jedoch Drittanbieter-Code oder ein System verwenden, das Sie nicht vollständig kontrollieren können, bietet der preStop-Hook eine ausgezeichnete Möglichkeit, einen eleganten Shutdown auszulösen, ohne das ganze Programm zu ändern.
Nach der Ausführung dieses Hooks sendet Kubernetes an die Container im Pod ein SIGTERM-Signal, das ihnen mitteilt, dass sie bald heruntergefahren werden. Nach Erhalt dieses Signals geht Ihr Code in den Shutdown-Prozess über. Dieser Prozess kann das Beenden von langlebigen Verbindungen, wie z.B. einer Datenbankverbindung oder einem WebSocket-Stream, das Speichern des aktuellen Zustands und Ähnliches umfassen.
Selbst wenn Sie einen preStop-Hook verwenden, ist es entscheidend zu überprüfen, was genau mit Ihrer Anwendung passiert, wenn Sie das SIGTERM-Signal senden, und wie sie sich dabei verhält, damit Ereignisse oder Änderungen im Systembetrieb, die durch das Ausschalten des Pods verursacht werden, Sie nicht überraschen.
In diesem Moment, bevor weitere Schritte unternommen werden, wird Kubernetes für einen bestimmten Zeitraum warten, der als terminationGracePeriodSecond bezeichnet wird, oder als Zeit für eine ordnungsgemäße Abschaltung beim Erhalt des SIGTERM-Signals.

Standardmäßig beträgt dieser Zeitraum 30 Sekunden. Es ist wichtig zu beachten, dass er parallel zum preStop-Hook und dem SIGTERM-Signal läuft. Kubernetes wartet nicht, bis der preStop-Hook und SIGTERM abgeschlossen sind – wenn Ihre Anwendung vor Ende des TerminationGracePeriod heruntergefahren wird, springt Kubernetes sofort zum nächsten Schritt über. Daher sollten Sie sicherstellen, dass dieser Zeitraum in Sekunden nicht kürzer ist als die Zeit, die für die ordnungsgemäße Abschaltung des Pods erforderlich ist. Wenn er mehr als 30 Sekunden beträgt, erhöhen Sie den Zeitraum im YAML auf die erforderliche Größe. In dem angegebenen Beispiel beträgt er 60 Sekunden.
Und schließlich der letzte Schritt — wenn die Container nach Ablauf des terminationGracePeriod weiterhin aktiv sind, senden sie ein SIGKILL-Signal und werden zwangsweise entfernt. Zu diesem Zeitpunkt bereinigt Kubernetes auch alle anderen Pod-Objekte.
Kubernetes beendet Pods aus verschiedenen Gründen. Stellen Sie daher sicher, dass Ihre Anwendung in jedem Fall ordnungsgemäß abgeschlossen wird, um einen stabilen Betrieb des Dienstes zu gewährleisten.

Ein wenig Werbung 🙂
Danke, dass Sie bei uns bleiben. Gefallen Ihnen unsere Artikel? Möchten Sie mehr interessante Inhalte sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder uns Ihren Freunden empfehlen. , eine einzigartige Alternative zu Einsteiger-Servern, die wir für Sie entwickelt haben: (Verfügbar sind Optionen mit RAID1 und RAID10, bis zu 24 Kerne und bis zu 40GB DDR4).
Dell R730xd im Equinix Tier IV Rechenzentrum in Amsterdam zum halben Preis? Nur bei uns in den Niederlanden! Dell R420 — 2x E5-2430 2.2GHz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — ab 99 $! Lesen Sie darüber
Quelle: habr.com
