

Die Klassifikation von Daten basierend auf Inhalten ist eine offene Fragestellung. Traditionelle Systeme zur Verhinderung von Datenverlust (DLP) gehen dieses Problem an, indem sie Fingerabdrücke relevanter Daten erstellen und Endpunkte überwachen, um diese Fingerabdrücke zu erkennen. Angesichts der Vielzahl ständig wechselnder Datenressourcen auf Facebook ist dieser Ansatz nicht nur nicht skalierbar, sondern auch ineffektiv bei der Bestimmung des Standorts der Daten. Dieser Artikel widmet sich einem durchgehenden System, das darauf ausgelegt ist, sensible semantische Typen auf Facebook in großem Maßstab zu erkennen und eine automatisierte Datenspeicherung sowie Zugriffskontrolle zu gewährleisten.
Der hier beschriebene Ansatz ist unser erstes ganzheitliches Datenschutzsystem, das versucht, dieses Problem zu lösen, indem es Datensignale, maschinelles Lernen und traditionelle Methoden zur Fingerabdruckerfassung kombiniert, um alle Daten auf Facebook darzustellen und zu klassifizieren. Das beschriebene System wird in einer Produktionsumgebung betrieben und erreicht einen durchschnittlichen F2-Score von über 0,9 in verschiedenen Datenschutzkategorien, während es große Datenressourcen in Dutzenden von Speichern verarbeitet. Hier präsentieren wir die Übersetzung der Facebook-Veröffentlichung auf ArXiv über skalierbare Datenklassifikation zur Gewährleistung von Sicherheit und Datenschutz auf Basis von maschinellem Lernen.
Einführung
Heute sammeln und speichern Organisationen große Datenmengen in unterschiedlichen Formaten und an verschiedenen Orten [1]. Diese Daten werden an vielen Stellen abgerufen und manchmal mehrfach kopiert oder zwischengespeichert, wodurch wertvolle und vertrauliche Geschäftsinformationen über viele Unternehmensdatenbanken verstreut werden. Wenn eine Organisation gesetzliche oder regulatorische Anforderungen erfüllen muss, wie beispielsweise die Einhaltung von Bestimmungen im Rahmen eines Zivilverfahrens, entsteht die Notwendigkeit, die Standorte der benötigten Daten zu ermitteln. Wenn in einer Datenschutzanordnung festgelegt wird, dass eine Organisation alle Sozialversicherungsnummern (SSN) bei der Übermittlung personenbezogener Daten an unbefugte Dritte maskieren muss, ist der natürliche erste Schritt die Auffindung aller SSN in den Datenbanken der gesamten Organisation. In solchen Fällen wird die Datenklassifizierung entscheidend [1]. Ein Klassifizierungssystem ermöglicht es Organisationen, die Einhaltung von Datenschutz- und Sicherheitsrichtlinien automatisch sicherzustellen, wie beispielsweise die Implementierung von Zugriffskontrollrichtlinien und Datenaufbewahrung. Facebook stellt ein System vor, das wir bei Facebook entwickelt haben, welches eine Vielzahl von Datensignalen, eine skalierbare Systemarchitektur und maschinelles Lernen nutzt, um sensible semantische Datentypen zu erkennen.
Die Entdeckung und Klassifizierung von Daten bedeutet, sie so zu suchen und zu kennzeichnen, dass die entsprechenden Informationen bei Bedarf schnell und effizient abgerufen werden können. Der aktuelle Prozess ist eher manuell und umfasst das Studium relevanter Gesetze oder Vorschriften, die Bestimmung, welche Arten von Informationen als sensibel gelten sollen, und die Festlegung der verschiedenen Sensitivitätsstufen, gefolgt von der Entwicklung entsprechender Klassen und Klassifizierungspolitiken [1]. Nach den Datenverlustschutzsystemen (DLP) werden Datenabdrucke erfasst und Endpunkte downstream überwacht, um Abdrücke zu erhalten. Bei der Arbeit mit einem Speicher, der eine große Anzahl von Assets und Petabyte an Daten enthält, ist dieser Ansatz einfach nicht skalierbar.
Unser Ziel ist es, ein Datenklassifizierungssystem zu entwickeln, das sowohl für stabile als auch für instabile Benutzerdaten skalierbar ist, ohne zusätzliche Einschränkungen hinsichtlich des Typs oder Formats der Daten. Dies ist ein ehrgeiziges Ziel und bringt natürlich Herausforderungen mit sich. Jede Datenspeicherung kann Tausende von Zeichen umfassen.
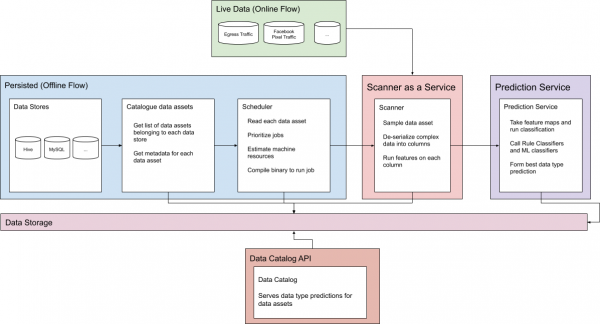
Abbildung 1. Strömungen der Online- und Offline-Prognosen
Daher müssen wir sie effizient darstellen, indem wir einen gemeinsamen Satz von Merkmalen verwenden, die später kombiniert und einfach verschoben werden können. Diese Merkmale sollten nicht nur eine genaue Klassifizierung gewährleisten, sondern auch Flexibilität und Erweiterbarkeit bieten, um die einfache Hinzufügung und Entdeckung neuer Datentypen in der Zukunft zu ermöglichen. Zweitens müssen wir uns mit großen autonomen Tabellen befassen. Stabile Daten können in Tabellen gespeichert werden, die mehrere Petabyte groß sind. Dies kann die Scan-Geschwindigkeit verringern. Drittens müssen wir eine strenge SLA-Klassifizierung für instabile Daten einhalten. Dies zwingt das System, hochgradig effizient, schnell und genau zu sein. Schließlich müssen wir eine latenzarme Klassifizierung für instabile Daten sicherstellen, um die Klassifizierung in Echtzeit durchzuführen, sowie für Internet-Anwendungsfälle.
In diesem Artikel beschreiben wir, wie wir Herausforderungen gemeistert haben, und präsentieren ein schnelles sowie skalierbares Klassifizierungssystem, das Datenelemente aller Art, Formate und Quellen anhand eines gemeinsamen Merkmalsatzes klassifiziert. Wir haben die Systemarchitektur weiterentwickelt und ein spezielles Machine-Learning-Modell für die rasche Klassifizierung von Offline- und Online-Daten erstellt. Der Artikel ist wie folgt strukturiert: In Abschnitt 2 wird das Gesamtdesign des Systems vorgestellt. Abschnitt 3 behandelt die Bestandteile des Machine-Learning-Systems. In den Abschnitten 4 und 5 wird die zugehörige Arbeit erörtert und zukünftige Arbeitsrichtungen skizziert.
Architektur von
Um die Herausforderungen stabiler Daten und Online-Daten im Maßstab von Facebook zu bewältigen, verfügt das Klassifizierungssystem über zwei separate Stränge, die wir ausführlich besprechen werden.
Stabile Daten
Zunächst muss das System zahlreiche Informationswerte von Facebook erfassen. Für jedes Speichergerät wird grundlegende Informationen gesammelt, wie das Rechenzentrum, in dem diese Daten gespeichert sind, das System, das mit diesen Daten arbeitet, und die Vermögenswerte, die in dem jeweiligen Datenspeicher zu finden sind. Dies bildet ein Metadatenverzeichnis, das es dem System ermöglicht, Daten effizient abzurufen, ohne die Kunden und die von anderen Ingenieuren genutzten Ressourcen zu überlasten.
Dieses Metadatenverzeichnis bietet eine verlässliche Quelle für alle gescannten Vermögenswerte und ermöglicht die Überwachung des Status verschiedener Werte. Anhand dieser Informationen wird eine Priorisierung der Planung festgelegt, basierend auf den gesammelten Daten und internen Informationen aus dem System, wie zum Beispiel dem Zeitpunkt des letzten erfolgreichen Scans eines Vermögenswerts, dem Zeitpunkt seiner Erstellung sowie früheren Anforderungen an Speicher und Prozessor für diesen Vermögenswert, falls er zuvor gescannt wurde. Anschließend wird für jede Datenressource (sobald diese verfügbar ist) der Scanvorgang des jeweiligen Ressourcen angefordert.
Jede Aufgabe ist eine kompilierte Binärdatei, die eine Bernoulli-Stichprobe auf der Grundlage der neuesten verfügbaren Daten für jedes Asset durchführt. Das Asset wird in separate Spalten zerlegt, wobei das Klassifizierungsergebnis jeder Spalte unabhängig verarbeitet wird. Darüber hinaus scannt das System alle strukturierten Daten innerhalb der Spalten. JSON, Arrays, kodierte Strukturen, URLs, serialisierte Base64-Daten und vieles mehr – all dies wird gescannt. Dies kann die Scanzeit erheblich verlängern, da eine Tabelle Tausende von verschachtelten Spalten in einem großen Binärobjekt enthalten kann. json.
Für jede Zeile, die im Datensatz ausgewählt wird, extrahiert das Klassifizierungssystem schwebende und textuelle Objekte aus dem Inhalt und verknüpft jedes Objekt zurück mit der Spalte, aus der es entnommen wurde. Das Ergebnis der Objektübernahme ist eine Karte aller Objekte für jede im Datensatz gefundene Spalte.
Wofür werden Merkmale benötigt?
Das Konzept der Merkmale ist entscheidend. Anstelle der Merkmale float und text können wir unverarbeitete Beispieldaten übergeben, die direkt aus jeder Datenressource extrahiert wurden. Darüber hinaus können maschinelle Lernmodelle direkt auf jedem Datensatz trainiert werden, anstatt auf hunderten von berechneten Merkmalen, die nur versuchen, die Stichprobe zu approximieren. Dies hat mehrere Gründe:
- Datenschutz hat oberste Priorität: Das Wichtigste ist, dass uns das Konzept der Merkmale ermöglicht, nur die Datenmuster im Gedächtnis zu behalten, die wir extrahieren. Das gewährleistet, dass wir Muster nur für den vorgesehenen Zweck speichern und sie niemals eigenständig protokollieren. Dies ist besonders wichtig für instabile Daten, da der Dienst einen gewissen Klassifizierungszustand aufrechterhalten muss, bevor eine Vorhersage bereitgestellt wird.
- Speicher: Einige Muster können Tausende von Zeichen lang sein. Das Speichern solcher Daten und deren Übertragung an Teile des Systems ohne Notwendigkeit verbraucht viele zusätzliche Bytes. Zwei Faktoren können sich im Laufe der Zeit summieren, da es viele Datenressourcen mit Tausenden von Spalten gibt.
- Aggregierung von Merkmalen: Durch Merkmale wird die Auswertung jedes Scans klar dargestellt, sodass das System die Ergebnisse vorheriger Scans derselben Datenquelle auf bequeme Weise zusammenfassen kann. Dies kann nützlich sein, um die Ergebnisse mehrerer Scans einer einzigen Datenressource zu agreggieren.
Anschließend werden die Merkmale an den Prognoseservice gesendet, wo wir Regelbasierte Klassifikation und maschinelles Lernen nutzen, um die Datenetiketten jeder Spalte vorherzusagen. Der Service stützt sich sowohl auf Regelklassifikatoren als auch auf maschinelles Lernen und wählt die beste Vorhersage aus, die jedem Prognoseobjekt gegeben wird.
Regelklassifikatoren sind manuelle Heuristiken; sie verwenden Berechnungen und Koeffizienten zur Normalisierung des Objekts im Bereich von 0 bis 100. Sobald ein solcher Ausgangswert für jeden Datentyp und den Namen der Spalte, die mit diesen Daten verbunden ist, generiert wird und nicht in irgendwelche "Blocklisten" fällt, wählt der Regelklassifikator den höchsten normalisierten Wert aus allen Datentypen aus.
Aufgrund der Komplexität der Klassifizierung führt die ausschließliche Verwendung manueller Heuristiken zu einer geringen Klassifizierungsgenauigkeit, insbesondere bei unstrukturierten Daten. Aus diesem Grund haben wir ein maschinelles Lernsystem entwickelt, das sich mit der Klassifizierung unstrukturierter Daten wie Benutzerdaten und Adressen befasst. Maschinelles Lernen hat es uns ermöglicht, von manuellen Heuristiken abzukehren und zusätzliche Datensignale (z. B. Spaltennamen und Herkunft der Daten) anzuwenden, was die Erkennungsgenauigkeit erheblich erhöht. Später werden wir eingehender auf unsere Architektur im Bereich maschinelles Lernen eingehen.
Der Prognosendienst speichert die Ergebnisse für jede Spalte zusammen mit Metadaten über die Zeit und den Status des Scans. Alle Verbraucher und nachgelagerten Prozesse, die von diesen Daten abhängen, können sie aus den täglich veröffentlichten Datensätzen abrufen. Dieser Datensatz aggregiert die Ergebnisse aller Scan-Jobs oder das Echtzeit-API des Datenkatalogs. Die veröffentlichten Prognosen sind die Grundlage für die automatische Anwendung von Datenschutz- und Sicherheitsrichtlinien.
Nachdem der Prognoseservice endlich alle Daten erfasst und alle Prognosen gespeichert wurden, kann unsere Datenkatalog-API alle Prognosen der Datentypen für die Ressource in Echtzeit zurückgeben. Täglich veröffentlicht das System einen Datensatz, der alle aktuellen Prognosen für jedes Asset enthält.
Instabile Daten
Während der oben beschriebene Prozess für gespeicherte Assets konzipiert ist, wird auch nicht gespeicherter Verkehr als Teil der Organisationsdaten betrachtet und kann von Bedeutung sein. Aus diesem Grund bietet das System eine Online-API zur Echtzeit-Prognosegenerierung für jeglichen instabilen Verkehr. Das Echtzeit-Prognosesystem wird häufig verwendet, um ausgehenden und eingehenden Verkehr in Modellen des maschinellen Lernens sowie bei Daten von Werbetreibenden zu klassifizieren.
Hier empfängt die API zwei Hauptargumente: den Gruppierungsschlüssel und die Rohdaten, die prognostiziert werden sollen. Der Dienst führt die gleiche Objektextraktion durch, wie oben beschrieben, und gruppiert die Objekte anhand desselben Schlüssels. Diese Merkmale werden ebenfalls im zwischengespeicherten Speicher unterstützt, um eine Wiederherstellung nach einem Ausfall zu gewährleisten. Der Dienst garantiert für jeden Gruppierungsschlüssel, dass er vor dem Aufruf des Prognoseservices ausreichend Proben gemäß dem oben beschriebenen Prozess gesehen hat.
Optimierung
Für das Scannen bestimmter Speichersysteme verwenden wir Bibliotheken und Methoden zur Optimierung des Lesevorgangs aus Hot-Speichern [2] und gewährleisten, dass es keine Ausfälle von anderen Benutzern gibt, die auf dasselbe Speichersystem zugreifen.
Für extrem große Tabellen (über 50 Petabyte) kann das System, trotz aller Optimierungen und Speichereffizienz, nicht alle Daten im Speicher verarbeiten, bevor der Speicher erschöpft ist. Letztendlich wird die gesamte Abfrage im Speicher gerechnet und nicht während des Scanvorgangs gespeichert. Sollte eine große Tabelle Tausende von Spalten mit unstrukturierten Datenblöcken enthalten, kann die Aufgabe aufgrund unzureichender Speicherressourcen bei der Durchführung von Vorhersagen auf der gesamten Tabelle fehlschlagen. Dies führt zu einer reduzierten Abdeckung. Um dem entgegenzuwirken, haben wir das System optimiert, um die Scan-Geschwindigkeit als Indikator dafür zu verwenden, wie gut das System mit der aktuellen Last zurechtkommt. Wir nutzen die Geschwindigkeit als prognostischen Mechanismus, um Speicherprobleme frühzeitig zu erkennen und im Vorfeld Objektkarten zu berechnen. Dabei verwenden wir weniger Daten als üblich.
Datensignale
Das Klassifizierungssystem ist nur so gut wie die Signale, die es von den Daten erhält. Hier betrachten wir alle Signale, die im Klassifizierungssystem verwendet werden.
- Inhalt als Signal: Der Inhalt ist der erste und wichtigste Signalgeber. Für jedes Datenobjekt, das wir scannen, führen wir eine Bernoulli-Auswahl durch und extrahieren Merkmale basierend auf den Dateninhalten. Viele dieser Merkmale stammen aus dem Inhalt. Es können beliebig viele fließende Objekte vorhanden sein, die Berechnungen darüber repräsentieren, wie oft ein bestimmter Mustertyp erkannt wurde. Zum Beispiel können wir Zähler für die Anzahl der in der Auswahl sichtbaren E-Mails haben oder Hinweise darauf, wie viele Emojis in der Auswahl wahrgenommen wurden. Diese Merkmalberechnungen können normalisiert und über verschiedene Scans aggregiert werden.
- Datenherkunft: Ein wichtiges Signal, das helfen kann, wenn sich der Inhalt aus der übergeordneten Tabelle geändert hat. Ein häufiges Beispiel sind gehashte Daten. Wenn Daten in einer untergeordneten Tabelle gehasht werden, stammen sie oft von der übergeordneten Tabelle, in der sie unverschlüsselt bleiben. Die Informationen zur Herkunft helfen dabei, bestimmte Datentypen zu klassifizieren, wenn sie nicht klar lesbar sind oder aus einer Tabelle upstream umgewandelt wurden.
- Annotation: Ein weiterer hochwertiger Signal, der bei der Identifizierung unstrukturierter Daten hilft. Tatsächlich können Annotationen und Herkunftsdaten zusammenarbeiten, um Attribute zwischen verschiedenen Datenressourcen zu verbreiten. Annotationen helfen, die Quelle unstrukturierter Daten zu identifizieren, während Herkunftsdaten dabei unterstützen können, den Fluss dieser Daten im gesamten Speicher zu verfolgen.
- Dateninjektion ist eine Methode, bei der absichtlich spezielle, unlesbare Zeichen in bekannte Quellen mit bekannten Datentypen eingefügt werden. Jedes Mal, wenn wir den Inhalt mit derselben unlesbaren Zeichenfolge scannen, kann geschlossen werden, dass der Inhalt aus diesem bekannten Datentyp stammt. Dies ist ein weiteres qualitatives Datensignal, ähnlich den Annotationen. Der Unterschied besteht darin, dass die entdeckte inhaltsbasierte Erkennung bei der Identifizierung der eingegebenen Daten hilft.
Metriken messen
Ein wesentlicher Bestandteil ist eine strenge Methodologie zur Messung von Metriken. Die Hauptmetriken zur Iteration der Klassifizierungsverbesserung sind die Genauigkeit und der Rückruf jeder Kennzeichnung, wobei die F2-Bewertung die wichtigste ist.
Für die Berechnung dieser Kennzahlen ist eine unabhängige Methodologie zur Kennzeichnung von Datenassets erforderlich, die nicht vom System selbst abhängt, aber für den direkten Vergleich mit diesem verwendet werden kann. Im Folgenden erläutern wir, wie wir die grundlegende Wahrheit aus Facebook extrahieren und sie zur Schulung unseres Klassifizierungssystems nutzen.
Zuverlässige Datensammlung
Wir sammeln zuverlässige Daten aus jeder der unten aufgeführten Quellen in einer eigenen Tabelle. Jede Tabelle ist verantwortlich für die Aggregation der zuletzt beobachteten Werte aus dieser speziellen Quelle. Jede Quelle hat eine Datenqualitätsprüfung, um sicherzustellen, dass die beobachteten Werte für jede Quelle von hoher Qualität sind und die aktuellsten Typenlabels enthalten.
- Konfigurationen der Logging-Plattform: Bestimmte Felder in den Tabellen werden mit Daten gefüllt, die zu einem bestimmten Typ gehören. Die Nutzung und Verbreitung dieser Daten dient als verlässliche Quelle für zuverlässige Daten.
- Manuelle Kennzeichnung: Entwickler, die das System unterstützen, sowie externe Kennzeichner sind darauf trainiert, Spalten zu kennzeichnen. Dies funktioniert in der Regel gut für alle Datentypen im Speicher und kann eine Hauptquelle für die Verlässlichkeit einiger unstrukturierter Daten, wie etwa Nachrichtendaten oder Benutzerdaten, darstellen.
- Spalten aus übergeordneten Tabellen können als enthaltene bestimmte Daten markiert oder annotiert werden, und wir können diese Daten in den nachgelagerten Tabellen nachverfolgen.
- Sampling von Ausführungsströmen: Ausführungsströme in Facebook tragen Daten eines bestimmten Typs. Durch die Verwendung unseres Scanners als Service-Architektur können wir Ströme mit bekannten Datentypen auswählen und sie durch das System senden. Das System verspricht, diese Daten nicht zu speichern.
- Abfrage-Tabellen: Große Datenschichten, die als vollständig bekannte Datenbanken fungieren, können ebenfalls als Trainingsdaten verwendet und über einen Scanner als Dienst bereitgestellt werden. Dies eignet sich hervorragend für Tabellen mit einem vollständigen Spektrum an Datentypen, sodass die zufällige Abfrage einer Spalte im Wesentlichen der Abfrage der gesamten Menge dieses Datentyps entspricht.
- Synthesedaten: Wir können sogar Bibliotheken verwenden, die Daten in Echtzeit generieren. Dies funktioniert gut für einfache, öffentliche Datentypen wie Adressen oder GPS-Koordinaten.
- Data Stewards: Datenschutzprogramme nutzen in der Regel Data Stewards, um manuell Richtlinien mit bestimmten Datenbereichen zu verbinden. Dies dient als hochpräzise Quelle der Verlässlichkeit.
Wir bündeln jede primäre Datenquelle in einem Korpus mit all diesen Daten. Das größte Problem bei der Zuverlässigkeit besteht darin, sicherzustellen, dass sie im Data Warehouse repräsentativ ist. Andernfalls könnten die Klassifizierungsalgorithmen überantrainiert werden. Um dem entgegenzuwirken, werden alle oben genannten Quellen genutzt, um beim Training der Modelle oder der Berechnung von Metriken ein ausgewogenes Verhältnis zu gewährleisten. Darüber hinaus wählen Menschenschnelle gleichmäßig verschiedene Spalten im Data Warehouse aus und kennzeichnen die Daten entsprechend, damit die Sammlung zuverlässiger Werte unvoreingenommen bleibt.
Kontinuierliche Integration
Um schnelle Iterationen und Verbesserungen zu gewährleisten, ist es wichtig, die Leistung des Systems in Echtzeit zu messen. Wir können jede Verbesserung der Klassifizierung im Vergleich zum heutigen System messen, sodass wir taktisch auf die Daten für zukünftige Verbesserungen abzielen können. Hier betrachten wir, wie das System den Feedbackzyklus abschließt, der durch zuverlässige Daten gewährleistet wird.
Wenn das Planungssystem auf ein Asset mit einem Label von einer vertrauenswürdigen Quelle trifft, planen wir zwei Aufgaben. Die erste nutzt unseren Produktionsscanner und damit unsere Produktionskapazitäten. Die zweite Aufgabe verwendet den Scanner der letzten Version mit den aktuellsten Merkmalen. Jede Aufgabe schreibt ihre Ausgaben in eine eigene Tabelle und markiert die Versionen zusammen mit den Klassifizierungsergebnissen.
So vergleichen wir die Klassifizierungsergebnisse des Release Candidates und des Produktionsmodells in Echtzeit.
Während die Datensätze die Merkmale von RC und PROD vergleichen, werden viele Variationen des ML-Klassifizierungs-Engines des Prognoseservices protokolliert. Das neueste entwickelte Modell des maschinellen Lernens, das aktuelle Modell in der Produktion sowie alle experimentellen Modelle. Der gleiche Ansatz ermöglicht es uns, verschiedene Versionen des Modells zu „schneiden“ (agnostisch gegenüber unseren Regelklassifizierern) und die Metriken in Echtzeit zu vergleichen. So lässt sich leicht feststellen, wann ein ML-Experiment bereit ist, in die Produktion überführt zu werden.
Jede Nacht werden die für diesen Tag berechneten RC-Zeichen an die ML-Trainingspipeline gesendet, wo das Modell auf den neuesten RC-Zeichen trainiert wird und seine Leistung im Vergleich zu einem verlässlichen Datensatz bewertet.
Jeden Morgen schließt das Modell das Training ab und wird automatisch als experimentell veröffentlicht. Es wird automatisch in die Liste der Experimente aufgenommen.
Einige Ergebnisse
Über 100 verschiedene Datentypen werden mit hoher Genauigkeit markiert. Gut strukturierte Typen wie E-Mails und Telefonnummern werden mit einem F2-Score von über 0,95 klassifiziert. Unstrukturierte Datentypen wie benutzergenerierte Inhalte und Namen erzielen ebenfalls sehr gute Ergebnisse, mit F2-Werten über 0,85.
Täglich wird eine große Menge an Einzelsäulen stabiler und instabiler Daten in allen Speichern klassifiziert. Über 500 Terabyte werden täglich in mehr als 10 Datenspeichern gescannt. Der Umfang der meisten dieser Speicher beträgt über 98 %.
Im Laufe der Zeit hat sich die Klassifikation als sehr effizient erwiesen, da die Klassifizierungsaufgaben im gespeicherten autonomen Stream im Durchschnitt 35 Sekunden vom Scannen des Assets bis zur Berechnung der Prognosen für jede Spalte in Anspruch nehmen.
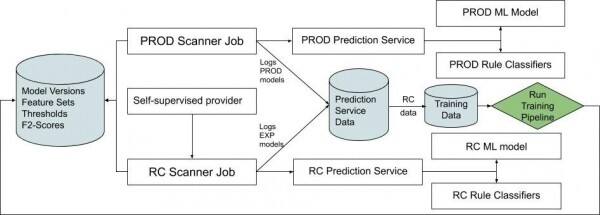
Abb. 2. Diagramm, das den kontinuierlichen Integrationsfluss beschreibt, um zu verstehen, wie RC-Objekte generiert und an das Modell gesendet werden.
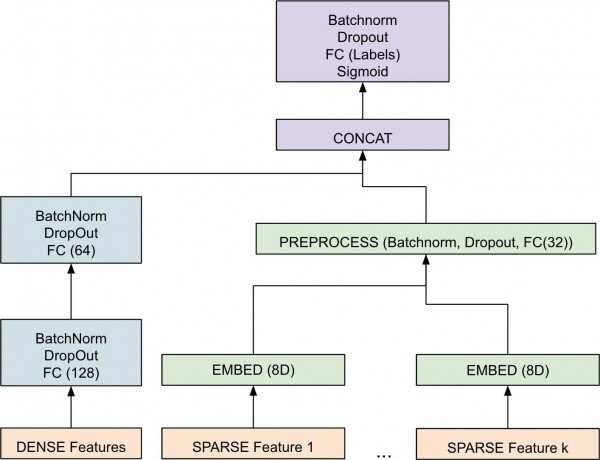
Abbildung 3. Hochrangiges Diagramm der Komponenten des maschinellen Lernens.
Komponente des maschinellen Lernsystems
Im vorherigen Abschnitt haben wir uns intensiv mit der Architektur des gesamten Systems beschäftigt und dabei den Umfang, die Optimierung und die Datenströme im autonomen und Online-Modus hervorgehoben. In diesem Abschnitt konzentrieren wir uns auf den Vorhersagedienst und beschreiben das maschinelle Lernsystem, das die Funktionalität des Vorhersagedienstes unterstützt.
Mit über 100 Datentypen sowie unstrukturierten Inhalten wie Messaging-Daten und Benutzerinhalten führt die ausschließliche Verwendung manueller Heuristiken zu suboptimaler Klassifizierungsgenauigkeit, insbesondere bei unstrukturierten Daten. Aus diesem Grund haben wir auch ein maschinelles Lernsystem entwickelt, das die Herausforderungen unstrukturierter Daten bewältigt. Der Einsatz von maschinellem Lernen ermöglicht es, sich von manuellen Heuristiken zu lösen und mit Merkmalen sowie zusätzlichen Datensignalen (z.B. Spaltennamen, Herkunft der Daten) zu arbeiten, um die Genauigkeit zu erhöhen.
Das implementierte Modell untersucht die Vektorrepresentationen [3] von dichten und spärlichen Objekten separat. Anschließend werden diese kombiniert, um einen Vektor zu bilden, der eine Reihe von Phasen der Batchnormalisierung [4] und Nichtlinearität durchläuft, um das Endergebnis zu erzielen. Das Endergebnis ist eine Fließkommazahl zwischen [0-1] für jede Marke, die die Wahrscheinlichkeit angibt, dass ein Beispiel zu diesem Sensitivitätstyp gehört. Der Einsatz von PyTorch für das Modell hat es uns ermöglicht, schneller voranzukommen und den Entwicklern außerhalb des Teams die Möglichkeit gegeben, Änderungen schnell vorzunehmen und zu testen.
Bei der Planung der Architektur war es wichtig, spärliche (z. B. Text) und dichte (z. B. numerische) Objekte aufgrund ihrer internen Unterschiede separat zu modellieren. Für die endgültige Architektur war es ebenfalls entscheidend, die Parameter zu entfalten, um optimale Werte für die Lernrate, die Batchgröße und andere Hyperparameter zu finden. Die Wahl des Optimierers war ebenfalls ein wichtiger Hyperparameter. Wir fanden heraus, dass der beliebte Optimierer Adamhäufig zu Überanpassung führt, während das Modell mit SGD stabiler. Es gab zusätzliche Nuancen, die wir direkt in das Modell integrieren mussten. Zum Beispiel statische Regeln, die sicherstellen, dass das Modell eine deterministische Vorhersage trifft, wenn ein Merkmal einen bestimmten Wert hat. Diese statischen Regeln werden von unseren Kunden definiert. Wir haben festgestellt, dass ihre direkte Einbeziehung in das Modell zu einer eigenständigeren und zuverlässigeren Architektur führt, im Gegensatz zur Implementierung eines Nachbearbeitungsschrittes zur Handhabung dieser speziellen Grenzfälle. Beachten Sie auch, dass während des Trainings diese Regeln deaktiviert sind, um den Trainingsprozess des Gradientenabstiegs nicht zu stören.
Die Probleme
Eine der Herausforderungen war die Beschaffung qualitativ hochwertiger und verlässlicher Daten. Das Modell benötigt eine Verlässlichkeit für jede Klasse, um Assoziationen zwischen Objekten und Labels zu lernen. Im vorherigen Abschnitt haben wir Methoden zur Datensammlung sowohl für die Systemmessung als auch für das Training von Modellen diskutiert. Die Analyse ergab, dass bestimmte Datentypen, wie Kreditkartennummern und Bankkontonummern, in unserem Speicher nicht sehr verbreitet sind. Dies erschwert die Erfassung großer Mengen verlässlicher Daten für das Training der Modelle. Um dieses Problem zu lösen, haben wir Prozesse zur Generierung synthetischer verlässlicher Daten für diese Klassen entwickelt. Wir generieren solche Daten für sensible Typen, einschließlich SSN, Kreditkartennummern und IBAN-Nummern, für die das Modell zuvor keine Prognosen abgeben konnte. Dieser Ansatz ermöglicht die Verarbeitung sensibler Datentypen, ohne das Risiko der Vertraulichkeit im Zusammenhang mit dem Verbergung realer sensibler Daten.
Neben den Herausforderungen der Verlässlichkeit gibt es offene architektonische Probleme, an denen wir arbeiten, wie Isolierung von Änderungen und frühe Stopp. Die Isolierung von Änderungen ist wichtig, damit verschiedene Anpassungen in den verschiedenen Teilen des Netzwerks isoliert werden und nicht erheblichen Einfluss auf die Gesamtleistung der Prognose haben. Eine Verbesserung der Kriterien für das frühe Stoppen ist ebenfalls entscheidend, damit wir den Trainingsprozess an einem stabilen Punkt für alle Klassen beenden können, und nicht an einem Punkt, an dem einige Klassen übertrainiert werden und andere nicht.
Die Bedeutung eines Merkmals
Wenn ein neues Merkmal in das Modell eingeführt wird, möchten wir dessen Gesamteinfluss auf das Modell verstehen. Außerdem möchten wir sicherstellen, dass die Vorhersagen für den Menschen nachvollziehbar sind, sodass genau verstanden werden kann, welche Merkmale für jeden Datentyp verwendet werden. Zu diesem Zweck haben wir entwickelt und implementiert klassenweise Die Bedeutung von Merkmalen für das PyTorch-Modell. Bitte beachten Sie, dass dies sich von der allgemeinen Merkmalsbedeutung unterscheidet, da sie uns nicht sagt, welche Merkmale für eine bestimmte Klasse wichtig sind. Wir messen die Bedeutung eines Objekts, indem wir den Anstieg des Vorhersagefehlers nach der Permutation des Objekts berechnen. Ein Merkmal ist "wichtig", wenn die Permutation der Werte den Fehler des Modells erhöht, da das Modell in diesem Fall bei der Vorhersage auf das Merkmal angewiesen war. Ein Merkmal ist "unwichtig", wenn die Permutation seiner Werte den Fehler des Modells unverändert lässt, da das Modell in diesem Fall das Merkmal ignoriert hat [5].
Die Bedeutung des Merkmals für jede Klasse macht das Modell interpretierbar, sodass wir sehen können, worauf das Modell bei der Vorhersage des Labels achtet. Zum Beispiel, wenn wir analysieren ADDR, stellen wir sicher, dass das mit der Adresse verbundene Merkmal, wie zum Beispiel AddressLinesCount, in der Tabelle der Merkmalsbedeutung für jede Klasse hoch platziert ist, damit unsere menschliche Intuition gut mit dem übereinstimmt, was das Modell gelernt hat.
Bewertung
Es ist wichtig, eine einheitliche Erfolgsmetrik zu definieren. Wir haben uns für F2 — ein Gleichgewicht zwischen Rückmeldung und Genauigkeit (die Rückmeldung ist etwas wichtiger). Die Rückmeldung ist für den Datenschutz wichtiger als die Genauigkeit, da es für das Team entscheidend ist, keine sensiblen Daten zu übersehen (während gleichzeitig eine angemessene Genauigkeit gewährleistet wird). Die tatsächlichen Leistungsbewertungsdaten F2 unseres Modells gehen über den Rahmen dieses Artikels hinaus. Bei sorgfältiger Feinabstimmung können wir jedoch einen hohen F2-Wert (0,9+) für die kritischsten sensitiven Klassen erreichen.
Zugehörige Arbeiten
Es gibt zahlreiche Algorithmen zur automatisierten Klassifizierung unstrukturierter Dokumente, die verschiedene Methoden verwenden, wie Musterabgleich, Dokumentenähnlichkeitsvergleich und unterschiedliche maschinelle Lernmethoden (Bayessche, Entscheidungsbäume, k-nächste Nachbarn und viele andere) [6]. Jeder von ihnen kann als Teil der Klassifizierung eingesetzt werden. Das Problem liegt jedoch in der Skalierbarkeit. Der Klassifizierungsansatz in diesem Artikel ist auf Flexibilität und Leistung ausgerichtet. Dies ermöglicht es uns, zukünftige Klassen zu unterstützen und gleichzeitig eine niedrige Latenz aufrechtzuerhalten.
Es gibt auch zahlreiche Arbeiten zur Extraktion von Fingerabdrücken aus Daten. Zum Beispiel beschreiben die Autoren in [7] eine Lösung, die auf das Problem der Erfassung von Lecks vertraulicher Daten fokussiert. Die Grundannahme besteht darin, dass der Fingerabdruck aus den Daten dazu verwendet werden kann, ihn mit einer Sammlung bekannter vertraulicher Daten abzugleichen. Die Autoren in [8] beschreiben ein ähnliches Problem bezüglich der Privatsphäre, aber ihre Lösung basiert auf einer bestimmten Android-Architektur und wird nur dann klassifiziert, wenn die Nutzeraktionen zur Übermittlung persönlicher Informationen führen oder wenn im grundlegenden App-Datenlecks auf Nutzerinformationen vorhanden sind. Die Situation ist hier etwas anders, da Nutzerdaten auch stark unstrukturiert sein können. Daher benötigen wir eine komplexere Technik als nur das Erstellen von Fingerabdrücken.
Um der Datenknappheit für bestimmte Arten sensibler Daten zu begegnen, haben wir synthetische Daten eingeführt. Es gibt umfangreiche Literatur zur Datenanreicherung, beispielsweise untersuchten die Autoren in [9] die Rolle der Rauschinjektion während des Trainings und beobachteten positive Ergebnisse im überwachten Lernen. Unser Ansatz zur Datenprivatsphäre ist anders, da die Einführung von verrauschten Daten kontraproduktiv sein kann; stattdessen konzentrieren wir uns auf hochwertige synthetische Daten.
Fazit
In diesem Artikel haben wir ein System vorgestellt, das in der Lage ist, Datenschnipsel zu klassifizieren. Dies ermöglicht es uns, Systeme zur Durchsetzung von Datenschutz- und Sicherheitsrichtlinien zu entwickeln. Wir haben gezeigt, dass skalierbare Infrastruktur, kontinuierliche Integration, maschinelles Lernen und hochwertige Daten zur Datenverlässlichkeit eine entscheidende Rolle für den Erfolg vieler unserer Initiativen im Bereich Datenschutz spielen.
Es gibt viele Bereiche für zukünftige Arbeiten. Dazu kann die Unterstützung nicht schematisierter Daten (Dateien), die Klassifizierung nicht nur des Datentyps, sondern auch des Sensitivitätsgrads sowie die Verwendung von selbstüberwachendem Lernen während des Trainings durch die Generierung präziser synthetischer Beispiele gehören. Diese helfen der Modellübertragung, die Verluste auf ein Minimum zu reduzieren. Zukünftige Arbeiten könnten sich auch auf den Arbeitsablauf bei Ermittlungen konzentrieren, bei dem wir über die Entdeckung hinausgehen und eine Ursachenanalyse verschiedener Datenschutzverletzungen bereitstellen. Dies wird in Fällen helfen, wie der Sensitivitätsanalyse (d.h. ob die Sensitivität des Datenschutztyps hoch ist (z.B. IP des Nutzers) oder niedrig (z.B. interne IP von Facebook)).
Bibliographie
- David Ben-David, Tamar Domany und Abigail Tarem. Unternehmensdatenklassifikation unter Verwendung von Technologien des semantischen Webs. In Peter F. Patel-Schneider, Yue Pan, Pascal Hitzler, Peter Mika, Lei Zhang, Jeff Z. Pan, Ian Horrocks und Birte Glimm, Herausgeber, Das Semantische Web – ISWC 2010, Seiten 66–81, Berlin, Heidelberg, 2010. Springer Berlin Heidelberg.
- Subramanian Muralidhar, Wyatt Lloyd, Sabyasachi Roy, Cory Hill, Ernest Lin, Weiwen Liu, Satadru Pan, Shiva Shankar, Viswanath Sivakumar, Linpeng Tang und Sanjeev Kumar. f4: Facebooks warmes BLOB-Speichersystem. In 11. USENIX Symposium zur Gestaltung und Implementierung von Betriebssystemen (OSDI 14), Seiten 383–398, Broomfield, CO, Oktober 2014. USENIX-Vereinigung.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado und Jeff Dean. Verteilte Repräsentationen von Wörtern und Phrasen und deren Zusammensetzung. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani und K. Q. Weinberger, Herausgeber, Fortschritte in den Neuronalen Informationsverarbeitungssystemen 26, Seiten 3111–3119. Curran Associates, Inc., 2013.
- Sergey Ioffe und Christian Szegedy. Batch-Normalisierung: Beschleunigung des Trainings tiefer Netzwerke durch Reduzierung der internen Kovariatenverschiebung. In Francis Bach und David Blei, Herausgeber, Tagungsband der 32. Internationalen Konferenz über maschinelles Lernen, Band 37 von Tagungsberichten der Forschungsgruppe für maschinelles Lernen, Seiten 448–456, Lille, Frankreich, 07.–09. Juli 2015. PMLR.
- Leo Breiman. Random Forests. Maschinenlernen., 45(1):5–32, Oktober 2001.
- Thair Nu Phyu. Umfrage zu Klassifikationstechniken im Data Mining.
- X. Shu, D. Yao und E. Bertino. Datenschutzfreundliche Erkennung der Sensiblen Datenexposition. IEEE Transactions on Information Forensics and Security, 10(5):1092–1103, 2015.
- Zhemin Yang, Min Yang, Yuan Zhang, Guofei Gu, Peng Ning und Xiaoyang Wang. Appintent: Analyse der Übertragung sensibler Daten in Android zur Erkennung von Datenschutzverletzungen. Seiten 1043–1054, 11 2013.
- Qizhe Xie, Zihang Dai, Eduard H. Hovy, Minh-Thang Luong und Quoc V. Le. Unsupervised Data Augmentation.
Erfahren Sie, wie Sie eine gefragte Berufsausbildung von Grund auf erwerben oder Ihre Fähigkeiten und Ihr Gehalt mit den Online-Kursen von SkillFactory auf ein neues Level bringen können:
- (12 Monate)
- (12 Wochen)
- (20 Wochen)
- (20 Wochen)
Weitere Kurse
- (9 Monate)
- (8 Monate)
- (9 Monate)
- (12 Monate)
- (18 Monate)
- (12 Monate)
- (9 Monate)
- (7 Monate)

Quelle: habr.com
