

Im Vortrag werden einige Ansätze vorgestellt, die es ermöglichen, die Leistung von SQL-Abfragen zu überwachen, wenn täglich Millionen ausgeführt werden,, während die kontrollierten PostgreSQL-Server in Hunderten zählen.
Welche technischen Lösungen ermöglichen es uns, solch ein Informationsvolumen effizient zu verarbeiten, und wie erleichtert dies das Leben der normalen Entwickler?

Interessiert an der Analyse spezifischer Probleme und verschiedenen Techniken der Optimierung von SQL-Abfragen sowie der Lösung typischer DBA-Aufgaben in PostgreSQL — Sie können sich auch zu diesem Thema informieren.
Mein Name ist Kirill Borovikov, ich vertrete . Ich spezialisiere mich konkret auf die Arbeit mit Datenbanken in unserem Unternehmen.
Heute werde ich Ihnen erzählen, wie wir die Abfragen optimieren, wenn es nicht darum geht, die Leistung einer einzigen Abfrage zu steigern, sondern ein Problem massenhaft zu lösen. Wenn es Millionen von Abfragen gibt, und Sie Ansätze zur Lösung finden müssen für dieses große Problem. Im Grunde genommen ist „Tensor“ für unsere Millionen von Kunden — das
SBIS — unsere Anwendung : ein soziales Unternehmensnetzwerk, Lösungen für Videokommunikation, für den internen und externen Dokumentenaustausch, Buchhaltungssysteme und Lagerverwaltung,... Das heißt, eine Art „Mega-Tool“ für das umfassende Management von Unternehmen, das über 100 verschiedene interne Projekte umfasst.
Damit all diese Projekte reibungslos funktionieren und sich weiterentwickeln können, haben wir 10 Entwicklungszentren im ganzen Land mit mehr als 1000 Entwicklern..
Wir arbeiten seit 2008 mit PostgreSQL und haben eine umfangreiche Datenbasis aufgebaut – das umfasst Kundendaten, statistische Informationen, Analysen und Daten aus externen Informationssystemen – über 400 TB.Allein in der Produktionsumgebung betreiben wir etwa 250 Server, und insgesamt überwachen wir rund 1000 Datenbankserver.

SQL ist eine deklarative Sprache. Sie beschreiben nicht, „wie“ etwas funktionieren soll, sondern „was“ Sie erreichen möchten. Die Datenbank weiß am besten, wie man einen JOIN macht – wie man Ihre Tabellen verbindet, welche Bedingungen anzuwenden sind, was über den Index geht und was nicht...
Einige Datenbanken akzeptieren Hinweise: „Nein, verbinde diese beiden Tabellen in dieser Reihenfolge“, aber PostgreSQL kann das nicht. Dies ist eine bewusste Entscheidung der Hauptentwickler: „Lieber verbessern wir den Abfrageoptimierer, als Entwicklern zu erlauben, irgendwelche Hinweise zu verwenden.“
Aber trotz der Tatsache, dass PostgreSQL nicht „von außen“ gesteuert werden kann, erlaubt es hervorragend, zu sehen, was „innen“ passiert,wenn Sie Ihre Abfrage ausführen und wo es Probleme gibt.

Generell, mit welchen klassischen Problemen kommt ein Entwickler [zum DBA] üblicherweise? „Wir haben diese Abfrage ausgeführt und es ist alles langsam,alles hängt, irgendetwas passiert… Irgendwas stimmt nicht!“
Die Gründe sind fast immer die gleichen:
- ineffizienter Abfragealgorithmus.
Entwickler: „Jetzt verbinde ich in SQL 10 Tabellen über JOIN…“ – und erwartet, dass seine Bedingungen auf wundersame Weise effizient „gelöst“ werden und er alles schnell erhält. Aber Wunder gibt es nicht, und jedes System gibt bei solch einer Variabilität (10 Tabellen in einem FROM) immer irgendeine Ungenauigkeit. [] - veraltete Statistiken.
Der Moment ist besonders relevant für PostgreSQL, wenn Sie ein großes Dataset auf den Server geladen haben, eine Abfrage durchführen – und es Ihnen "sequential scan" über die Tabelle macht. Denn gestern waren dort 10 Datensätze, heute sind es 10 Millionen, aber PostgreSQL hat das noch nicht mitbekommen und benötigt einen Hinweis darauf.] - "Engpass" bei den Ressourcen
Sie haben eine große und stark belastete Datenbank auf einen schwachen Server gestellt, der nicht über genügend Speicherplatz, RAM oder die notwendige Prozessorleistung verfügt. Und das war's… Irgendwo gibt es eine Leistungsobergrenze, die Sie nicht überschreiten können. - Sperrung
Ein komplexer Punkt, aber er ist besonders relevant für verschiedene modifizierende Abfragen (INSERT, UPDATE, DELETE) – das ist ein ganz eigenes großes Thema.
Abrufen des Plans
… Und für alles andere benötigen wir einen Plan! Wir müssen sehen, was im Inneren des Servers vor sich geht.

Der Ausführungsplan einer Abfrage für PostgreSQL ist ein Baum, der den Algorithmus zur Ausführung der Abfrage in textlicher Form darstellt. Dieser Algorithmus wurde im Ergebnis der Analyse vom Planner als der effizienteste erkannt.
Jeder Knoten des Baumes stellt eine Operation dar: das Abrufen von Daten aus einer Tabelle oder einem Index, den Aufbau einer Bitmaske, das Verknüpfen zweier Tabellen, das Zusammenführen, den Schnitt oder das Ausschließen von Auswahlmöglichkeiten. Die Ausführung einer Anfrage entspricht dem Durchlaufen der Knoten dieses Baumes.
Um einen Abfrageplan zu erhalten, ist der einfachste Weg, den Befehl EXPLAINauszuführen. Um alle tatsächlichen Attribute zu erhalten, also tatsächlich die Anfrage auf der Datenbank auszuführen, verwenden Sie: EXPLAIN (ANALYZE, BUFFERS) SELECT ....
Ein unangenehmer Punkt: Wenn Sie ihn ausführen, geschieht dies ‚hier und jetzt‘, was nur für lokale Debugging-Zwecke geeignet ist. Wenn Sie jedoch einen stark belasteten Server haben, der unter einem hohen Datenänderungsstrom steht, und Sie sehen: ‚Oh! Hier lief die Anfrage langsam,‘während Sie die Anfrage aus den Logs gezogen und wieder auf den Server gebracht haben, haben sich Ihre gesamten Datensätze und Statistiken geändert. Sie führen es zur Debugging-Zwecken aus – und es läuft schnell! Und Sie können nicht verstehen, „warum“, warum es langsam war.

Um herauszufinden, was genau zu dem Zeitpunkt war, als die Anfrage auf dem Server ausgeführt wurde, haben kluge Menschen das . Es ist in fast allen gängigen PostgreSQL-Distributionen vorhanden und kann einfach in der Konfigurationsdatei aktiviert werden.
Wenn es erkennt, dass eine Anfrage länger dauert als die von Ihnen festgelegte Grenze, macht es eine "Momentaufnahme" des Plans dieser Anfrage und dokumentiert diese zusammen im Protokoll..

Soweit sieht alles gut aus, wir gehen ins Protokoll und sehen dort… [портянка текста]. Aber wir können nichts darüber sagen, außer der Tatsache, dass es ein hervorragender Plan war, denn er wurde in 11 ms ausgeführt.
Es sieht also alles gut aus – aber wir verstehen nicht, was wirklich passiert ist. Abgesehen von der Gesamtzeit sehen wir nicht viel. Denn auf solche "Rohtexte" in klarem Text zu schauen, ist überhaupt nicht anschaulich.
Aber selbst wenn es nicht anschaulich und unbequem ist, gibt es gravierendere Probleme:
- Im Knoten wird angegeben die Summe der Ressourcen des gesamten Unterbaums darunter. Das heißt, wir können nicht einfach herausfinden, wie viel Zeit konkret bei diesem Index-Scan aufgewendet wurde, wenn es darunter eine eingefügte Bedingung gibt. Wir müssen dynamisch prüfen, ob es innerhalb "Kinder" und bedingte Variablen, CTE gibt – und das alles "im Kopf" subtrahieren.
- Ein zweiter Punkt: die Zeit, die im Knoten angegeben wird, ist Ausführungszeit eines Knotens. Wenn dieser Knoten zum Beispiel als Teil einer Schleife über Datensatztabellen mehrfach ausgeführt wurde, erhöht sich im Plan die Anzahl der Schleifen — also die Zyklen dieses Knotens. Die atomare Ausführungszeit bleibt jedoch im Plan unverändert. Um herauszufinden, wie oft dieser Knoten insgesamt ausgeführt wurde, sollte man das eine mit dem anderen multiplizieren — wieder einmal „im Kopf“.
Unter diesen Umständen ist es praktisch unmöglich zu verstehen, „Wer ist das schwächste Glied?“. Daher schreiben sogar die Entwickler in ihrem „Handbuch“, dass „Das Verständnis des Plans ist eine Kunst, die man erlernen muss, Erfahrung…“.
Aber wir haben 1000 Entwickler, und es ist unmöglich, jedem von ihnen diese Erfahrung im Kopf zu vermitteln. Ich, du, er — wir wissen es, aber der da drüben — vielleicht nicht. Möglicherweise lernt er es, vielleicht auch nicht, aber er muss jetzt schon arbeiten — und wo soll er diese Erfahrung hernehmen?
Visualisierung des Plans
Deshalb haben wir erkannt — um mit diesen Problemen umzugehen, benötigen wir eine gute Visualisierung des Plans.
Wir haben zunächst „den Markt“ erkundet — lass uns im Internet nachsehen, was es überhaupt gibt.
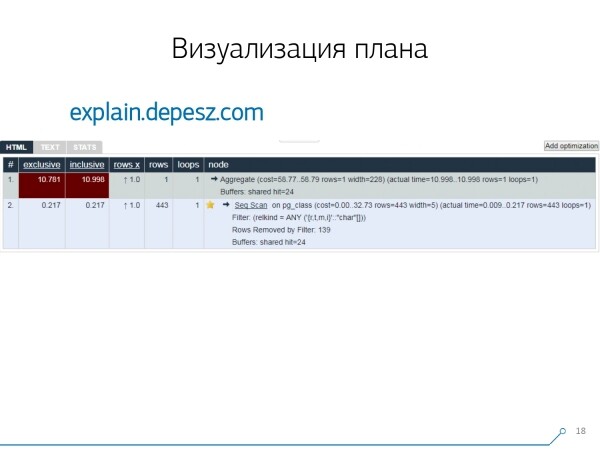
Es stellte sich jedoch heraus, dass es nur sehr wenige „lebendige“ Lösungen gibt, die sich mehr oder weniger weiterentwickeln – tatsächlich nur eine: von Hubert Lubaczewski. In das Eingabefeld geben Sie die Textdarstellung des Plans ein, und es zeigt Ihnen eine Tabelle mit den aufgeschlüsselten Daten an:
- eigene Bearbeitungszeit des Knotens
- Gesamtzeit über den gesamten Unterbaum
- die Anzahl der Datensätze, die extrahiert wurden und die statistisch erwartet wurden
- der eigentliche Knoteninhalt
Dieser Dienst bietet auch die Möglichkeit, ein Archiv von Links zu teilen. Sie haben Ihren Plan dort eingetragen und sagen: „Hey, Vasja, hier ist der Link, da stimmt etwas nicht.“

Es gibt jedoch auch einige kleinere Probleme.
Erstens handelt es sich um eine enorme Menge an „Copy-Paste“. Sie nehmen einen Teil des Protokolls, fügen ihn ein, und immer wieder.
Zweitens, gibt es keine Analyse der Menge der gelesenen Daten – denjenigen Buffern, die ausgegeben werden durch EXPLAIN (ANALYZE, BUFFERS), hier sehen wir das nicht. Es kann sie einfach nicht aufschlüsseln, verstehen und damit arbeiten. Wenn Sie viele Daten lesen und verstehen, dass Sie möglicherweise nicht korrekt auf der Festplatte und im Cache im Speicher „aufgeschlüsselt“ werden, ist diese Information sehr wichtig.
Der dritte negative Punkt ist die sehr schwache Entwicklung dieses Projekts. Die Commits sind sehr klein, gut, wenn es einmal im halben Jahr welche gibt, und der Code ist in Perl.
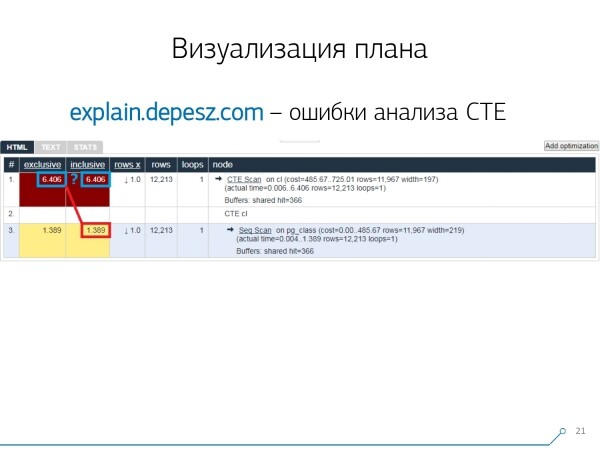
Aber das sind alles „Randbemerkungen“, damit könnten wir irgendwie leben, doch es gibt eine Sache, die uns stark von diesem Dienst abgebracht hat. Das sind die Fehler bei der Analyse von Common Table Expressions (CTE) und verschiedenen dynamischen Knoten wie InitPlan/SubPlan.
Wenn man diesem Bild glauben schenken darf, dann ist die Gesamtausführungszeit jedes einzelnen Knotens größer als die Gesamtzeit für die gesamte Abfrage. Es ist ganz einfach — im Knoten CTE Scan wurde die Zeit für die Generierung dieser CTE nicht abgezogen.. Daher wissen wir nicht mehr, wie viel Zeit das Scannen der CTE in Anspruch genommen hat.

Hier kamen wir zu dem Schluss, dass es Zeit war, unser eigenes Ding zu schreiben — hurra! Jeder Entwickler sagt: „Jetzt schreiben wir unser eigenes, das wird super einfach!“
Wir nahmen einen typischen Stack für Webdienste: Kern auf Node.js + Express, fügten Bootstrap hinzu und für schöne Diagramme — D3.js. Und unsere Erwartungen wurden durchaus erfüllt — den ersten Prototypen erhielten wir in 2 Wochen:
- einen eigenen Plan-Parser
Das heißt, wir können jetzt jeden beliebigen Plan analysieren, den PostgreSQL generiert. - eine korrekte Analyse dynamischer Knoten — CTE Scan, InitPlan, SubPlan
- Analyse der Verteilung von Buffern — wo Datenseiten aus dem Speicher gelesen werden, wo aus dem lokalen Cache, wo von der Festplatte
- Wir haben eine Übersicht erhalten
Um nicht alles im Log zu "graben", sondern das "schwächste Glied" sofort auf einem Bild zu sehen.
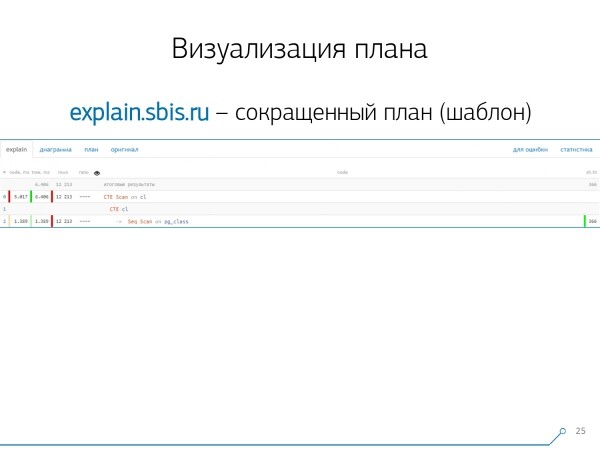
Wir haben ungefähr so eine Ansicht erhalten – sofort mit Syntax-Highlighting. Normalerweise arbeiten unsere Entwickler jedoch nicht mit einer vollständigen Darstellung des Plans, sondern mit einer verkürzten Version. Denn alle Zahlen haben wir bereits analysiert und zur Seite geschoben, während wir in der Mitte nur die erste Zeile gelassen haben, um anzuzeigen, was das für ein Knoten ist: CTE Scan, Generierung von CTE oder Seq Scan für eine bestimmte Tabelle.
Diese verkürzte Darstellung nennen wir Planvorlage.
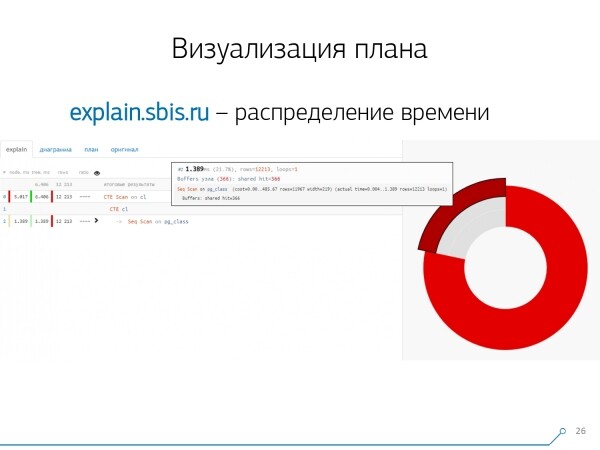
Was wäre noch hilfreich? Es wäre nützlich zu sehen, welcher Anteil an welcher Knoten von der Gesamtzeit verteilt ist – und einfach "nebenan" angeheftet. Tortendiagramm.
Wir bewegen den Cursor über den Knoten und sehen – anscheinend hat Seq Scan weniger als ein Viertel der gesamten Zeit in Anspruch genommen, während die restlichen 3/4 durch CTE Scan in Anspruch genommen wurden. Schrecklich! Das ist eine kleine Anmerkung zur "Geschwindigkeit" von CTE Scan, wenn Sie diese aktiv in Ihren Abfragen verwenden. Sie sind nicht sehr schnell – sie sind sogar langsamer als ein normales Tabellenscanning.
Normalerweise sind solche Diagramme interessanter und komplexer, wenn wir gezielt auf ein Segment zeigen und beispielsweise sehen, dass mehr als die Hälfte der gesamten Zeit von einem bestimmten Seq Scan «verbraucht» wurde. Und innerhalb davon gab es einen Filter, durch den eine Menge von Datensätzen verworfen wurde… Dieses Bild kann direkt an den Entwickler gesendet werden mit der Aufforderung: «Vasya, hier stimmt etwas nicht! Schau dir das an, da ist was faul!»

Natürlich gab es einige Stolpersteine.
Das erste Hindernis war das Problem der Rundung. Die Zeit jedes einzelnen Knotens im Plan wird mit einer Genauigkeit von 1µs angegeben. Wenn die Anzahl der Knotenzyklen 1000 überschreitet, teilt PostgreSQL nach der Ausführung «bis zur Genauigkeit», sodass wir bei der Rückrechnung eine Gesamtzeit von «etwa zwischen 0,95 ms und 1,05 ms» erhalten. Wenn es um Mikrosekunden geht, ist das noch in Ordnung, aber wenn es bereits um [Millisekunden] geht, müssen wir bei der «Aufschlüsselung» der Ressourcen pro Knoten im Plan berücksichtigen, «wer wie viel verbraucht hat».

Der zweite, kompliziertere Punkt ist die Verteilung der Ressourcen (diese Puffer) auf die dynamischen Knoten. Das hat uns in den ersten zwei Wochen des Prototyps zusätzlich etwa vier Wochen gekostet.
Ein solches Problem tritt recht häufig auf – wir erstellen ein CTE und lesen angeblich etwas daraus. In Wirklichkeit ist PostgreSQL „intelligent“ und wird dort nichts direkt lesen. Dann nehmen wir den ersten Datensatz, und zu ihm die einhundertste aus demselben CTE.
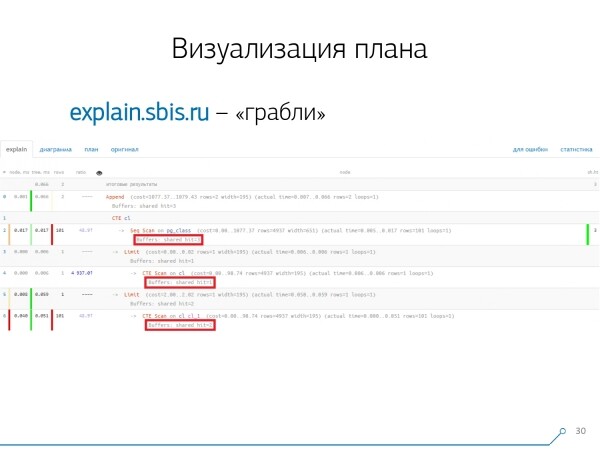
Wir betrachten den Plan und merken – seltsam, wir hatten 3 Buffer (Datenblätter), die beim Seq Scan „genutzt“ wurden, noch 1 beim CTE Scan und nochmals 2 beim zweiten CTE Scan. Wenn man alles einfach zusammenzählt, hätte man 6, aber aus der Tabelle haben wir insgesamt nur 3 gelesen! Der CTE Scan liest schließlich nichts von extern, sondern arbeitet direkt mit dem Prozessspeicher. Hier scheint also etwas nicht zu stimmen!
Tatsächlich ergibt sich hier, dass alle 3 Datenblätter, die beim Seq Scan angefordert wurden, zuerst vom 1. CTE Scan angefordert wurden und dann vom 2. CTE Scan, der zusätzlich 2 weitere gelesen hat. Das bedeutet, insgesamt wurden nur 3 Datenblätter gelesen und nicht 6.
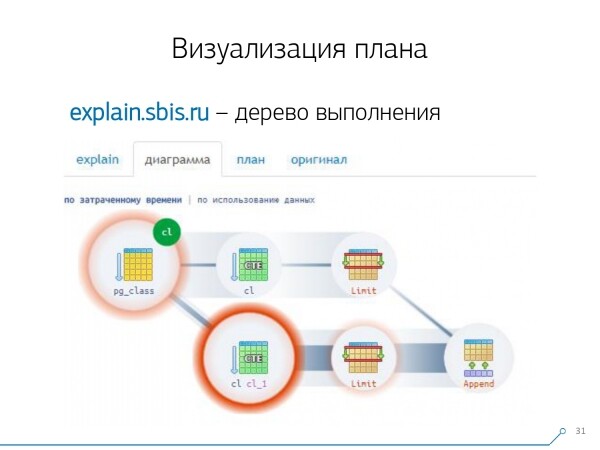
Dieses Bild hat uns die Erkenntnis gebracht, dass die Ausführung des Plans kein Baum mehr ist, sondern einfach ein azyklischer Graph. Wir haben eine Übersicht in Form eines Diagramms erstellt, damit wir verstehen, woher alles kommt. Hier haben wir eine CTE aus pg_class erstellt, die wir zweimal angefordert haben. Fast die gesamte Zeit haben wir im ersten Durchlauf mit der zweiten Anfrage verbracht. Es ist klar, dass das Lesen des 101. Eintrags wesentlich teurer ist als nur den ersten aus der Tabelle abzurufen.

Wir atmeten erleichtert auf und sagten: „Jetzt, Neo, weißt du Kung-Fu! Jetzt ist unsere Erfahrung direkt auf deinem Bildschirm. Du kannst sie jetzt nutzen.“
Konsolidierung der Logs
Unsere 1000 Entwickler atmeten erleichtert auf. Aber wir wussten, dass wir nur Hunderte von »Produktions«-Servern haben und dass dieses Kopieren seitens der Entwickler alles andere als praktisch war. Wir erkannten, dass wir das selbst zusammenbauen mussten.

Es gibt tatsächlich ein Standardmodul, das Statistiken sammeln kann, das allerdings ebenfalls im Konfigurationsfile aktiviert werden muss — es ist . Aber das hat uns nicht überzeugt.
Erstens weist es den gleichen Anfragen in unterschiedlichen Schemata innerhalb derselben Datenbank verschiedene QueryIds zu.Das bedeutet, wenn man zuerst SET search_path = '01'; SELECT * FROM user LIMIT 1;, und dann SET search_path = '02'; und bei einer ähnlichen Anfrage werden in der Statistik dieses Moduls unterschiedliche Einträge angezeigt, und ich kann keine allgemeine Statistik genau für dieses Abfragemuster ohne Berücksichtigung der Schemata erstellen.
Ein weiterer Punkt, der uns daran hinderte, es zu verwenden - fehlende Pläne. Das heißt, es gibt keinen Plan, nur die Anfrage selbst. Wir sehen, was langsamer war, aber verstehen nicht, warum. Und hier kommen wir zurück zum Problem des sich schnell ändernden Datensatzes.
Und der letzte Punkt - mangelnde „Fakten“. Das heißt, man kann sich nicht auf einen bestimmten Instanz der Ausführung der Anfrage beziehen - sie existiert nicht, es gibt nur aggregierte Statistiken. Damit kann man zwar arbeiten, aber es ist sehr schwierig.
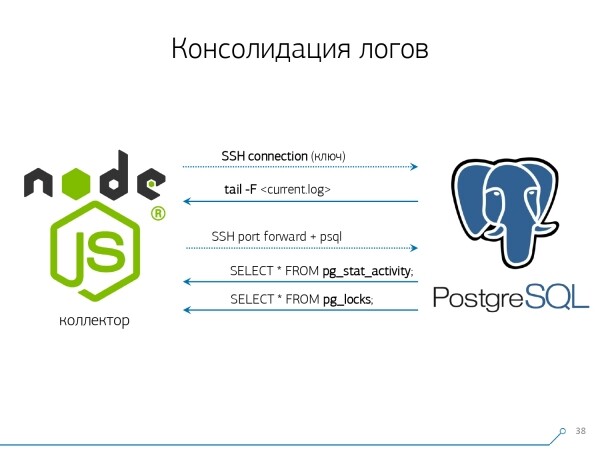
Deshalb haben wir beschlossen, gegen „Copy-Paste“ vorzugehen und begannen, einen Collector.
zu schreiben, der sich über SSH verbindet, über ein Zertifikat eine sichere Verbindung zum Server mit der Datenbank herstellt und tail -F sich an das Logfile anhängt. So erhalten wir in dieser Sitzung ein vollständiges „Spiegelbild“ der gesamten Logdatei , die der Server generiert. Die Belastung des Servers bleibt dabei minimal, denn wir parsen dort nichts, sondern spiegeln nur den Verkehr., der einen Server generiert. Die Belastung des Servers bleibt dabei minimal, da wir dort nichts parsen, sondern lediglich den Verkehr spiegeln.
Da wir bereits mit der Entwicklung des Interfaces in Node.js begonnen haben, setzen wir die Entwicklung des Collectors ebenfalls in dieser Technologie fort. Diese Wahl hat sich bewährt, da JavaScript sehr gut für die Arbeit mit schwach strukturierten Textdaten, wie sie in Logs vorkommen, geeignet ist. Die Node.js-Infrastruktur als Backend-Plattform ermöglicht zudem eine einfache und komfortable Handhabung von Netzwerkverbindungen und Datenströmen insgesamt.
In diesem Zusammenhang „ziehen“ wir zwei Verbindungen auf: die erste, um das Log zu „abhören“ und es abzuholen, und die zweite, um regelmäßig bei der Datenbank nachzufragen. „Im Log wurde gemeldet, dass die Tabelle mit der OID 123 gesperrt ist“, was dem Entwickler an dieser Stelle jedoch nicht viel sagt. Es wäre sinnvoll, die Datenbank zu fragen: „Was genau bedeutet OID = 123?“ So stellen wir regelmäßig Nachfragen bei der Datenbank, um Informationen zu erhalten, die uns noch nicht bekannt sind.

„Einen Aspekt hast du jedoch übersehen: Es gibt eine Art von elefantenartigen Bienen!“ Wir haben mit der Entwicklung dieses Systems begonnen, als wir 10 Server überwachen wollten. Die kritischsten aus unserer Sicht, bei denen einige Probleme auftraten, die schwer zu lösen waren. Doch bereits im ersten Quartal erhielten wir die Überwachung für hundert Server – denn das System wurde angenommen; alle wollten es nutzen, es war für alle bequem.
All dies muss zusammengeführt werden; die Datenströme sind groß und aktiv. Im Grunde genommen verwenden wir das, was wir überwachen und mit dem wir umgehen können. Wir nutzen PostgreSQL auch als Datenspeicher. Und es gibt nichts Schnelleres, um Daten in es hineinzuleiten als den Operator. COPY Im Moment noch nicht.
Aber einfach Daten „einzugießen“ ist nicht ganz unser Ansatz. Denn wenn auf hundert Servern ungefähr 50.000 Anfragen pro Sekunde stattfinden, dann erzeugt das täglich 100-150 GB Logs. Daher mussten wir die Datenbank sorgfältig „zusammenstellen“.
Zunächst haben wir die Partitionierung nach Tagenvorgenommen, denn im Grunde genommen interessiert niemanden die Korrelation zwischen den Tagen. Was spielt es für eine Rolle, was du gestern hattest, wenn du heute Nacht eine neue Version der Anwendung ausgerollt hast – und bereits neue Statistiken vorliegen.
Zweitens haben wir gelernt (wir mussten), sehr, sehr schnell zu schreiben mit Hilfe von COPY. Das bedeutet nicht nur, COPY, weil es schneller ist als INSERT, sondern sogar noch schneller.

Der dritte Punkt ist, dass wir auf Trigger und entsprechend auch auf Foreign Keys verzichten mussten.. Das heißt, wir haben überhaupt keine referenzielle Integrität mehr. Denn wenn Sie eine Tabelle haben, auf der es ein paar FKs gibt, und Sie in der Datenbankstruktur sagen, dass „der Datensatz aus dem Protokoll auf eine Gruppe von Datensätzen über den FK verweist“, dann bleibt PostgreSQL nichts anderes übrig, als einfach zu nehmen und ehrlich auszuführen, SELECT 1 FROM master_fk1_table WHERE ... mit der ID, die Sie einzufügen versuchen - einfach um zu überprüfen, dass dieser Datensatz dort vorhanden ist, damit Sie nicht mit Ihrem Insert diesen Foreign Key „brechen“.
Wir erhalten anstelle eines Datensatzes in der Zieltabelle und deren Indizes zusätzlich noch das Lesen aus allen Tabellen, auf die er verweist. Und das brauchen wir überhaupt nicht – unsere Aufgabe ist es, so viel wie möglich und so schnell wie möglich mit minimaler Belastung zu speichern. Also, FK – ade!
Der nächste Punkt ist die Aggregation und Hashbildung. Ursprünglich hatten wir das in der Datenbank implementiert – es ist einfach praktisch, wenn ein Datensatz ankommt, dies direkt in einer Tabelle zu tun. Ein „Plus eins“ direkt im Trigger.Das ist gut, praktisch, aber auch problematisch – Sie fügen einen Datensatz ein, müssen aber gleichzeitig noch etwas aus einer anderen Tabelle lesen und schreiben. Zudem müssen Sie nicht nur lesen und schreiben, sondern das auch jedes Mal tun.
Stellen Sie sich vor, Sie haben eine Tabelle, in der Sie einfach die Anzahl der Anfragen zählen, die über einen bestimmten Host laufen: +1, +1, +1, ..., +1Das ist für Sie im Grunde nicht notwendig – das Ganze kann man im Collector im Speicher summieren und die Daten einmalig in die Datenbank senden. +10.
Ja, im Falle von Problemen kann die logische Integrität verloren gehen, aber das ist praktisch ein unrealistisches Szenario – denn Sie haben einen stabilen Server, eine Batterie im Controller, ein Transaktionsprotokoll, ein Protokoll im Dateisystem… Insgesamt ist es das nicht wert. Die Leistungseinbußen, die Sie durch die Nutzung von Triggern / FK erleiden, sind den Aufwand nicht wert.
Das gleiche gilt für das Hashing. Ein Anfrage kommt zu Ihnen, Sie berechnen in der Datenbank eine bestimmte ID, speichern sie und teilen sie dann allen mit. Das funktioniert gut, bis ein zweiter Wunsch kommt, um die gleiche ID zu speichern – dann gibt es eine Blockierung, und das ist problematisch. Deshalb sollten Sie, wenn möglich, die Generierung von IDs auf den Client auslagern (im Verhältnis zur Datenbank).
Für uns war es ideal, MD5 vom Text – Anfrage, Plan, Template,… zu verwenden. Wir berechnen es auf der Seite des Collectors und speichern dann bereits die fertige ID in der Datenbank. Die Länge von MD5 und die tägliche Partitionierung ermöglichen es uns, uns keine Sorgen über mögliche Kollisionen zu machen.
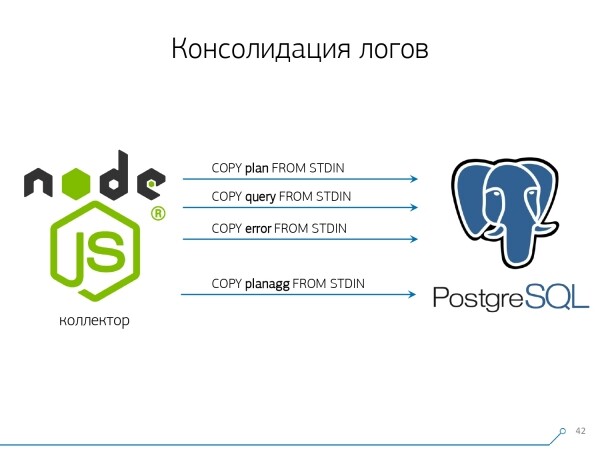
Um all das schnell zu speichern, mussten wir die Speicherprozedur selbst modifizieren.
Wie werden normalerweise Daten geschrieben? Wir haben einen Datensatz, den wir auf mehrere Tabellen aufteilen und dann COPY – zuerst in die erste, dann in die zweite, in die dritte… Es ist unpraktisch, weil wir anscheinend einen Datenstrom in drei Schritten sequenziell schreiben. Unangenehm. Kann es schneller gemacht werden? Ja!
Dafür genügt es, diese Ströme einfach parallel zueinander anzuordnen. So haben wir in separaten Strömen Fehler, Anfragen, Vorlagen, Sperren,… und wir schreiben das alles parallel. Dafür ist es ausreichend, einen COPY-Kanal für jede einzelne Ziel-Tabelle ständig offen zu halten..

Das bedeutet, dass der Collector immer einen Stream hat,in den ich die benötigten Daten schreiben kann. Damit die Daten von der Datenbank erkannt werden, darf jedoch niemand in einer Sperre hängen, während diese Daten geschrieben werden. Der COPY-Vorgang muss in bestimmten Intervallen unterbrochen werden.Für uns hat sich ein Intervall von etwa 100 ms als die effizienteste Lösung ergeben – wir schließen und öffnen sofort wieder zur gleichen Tabelle. Und wenn ein Strom bei bestimmten Spitzen nicht ausreicht, dann machen wir ein Polling bis zu einem bestimmten Limit.
Zusätzlich haben wir festgestellt, dass für dieses Lastprofil jede Aggregation, bei der Einträge in Paketen gesammelt werden, problematisch ist. Das klassische Problem ist INSERT ... VALUES und dann 1000 Einträge. Denn in diesem Moment entsteht ein Spitzenwert beim Schreiben auf das Medium, und alle anderen, die versuchen, etwas auf die Festplatte zu schreiben, müssen warten.
Um solche Anomalien zu vermeiden, aggregieren Sie einfach nichts, puffernd gar nicht. Und wenn es dennoch zu einer Pufferung auf die Festplatte kommt (zum Glück erlaubt das Stream API in Node.js, dies zu ermitteln) — verzögern Sie diese Verbindung. Sobald Sie das Signal erhalten, dass sie wieder frei ist — schreiben Sie den Inhalt aus der angesammelten Warteschlange hinein. Solange sie beschäftigt ist — nehmen Sie die nächste verfügbare aus dem Pool und schreiben Sie in sie.
Vor der Implementierung dieses Ansatzes hatten wir etwa 4K Schreibvorgänge, und auf diese Weise haben wir die Last um das Vierfache reduziert. Jetzt sind wir durch die neuen beobachtbaren Datenbanken noch einmal um das Sechsfache gewachsen — bis zu 100 MB/s. Und nun speichern wir die Logs der letzten 3 Monate mit einem Volumen von etwa 10-15 TB, in der Hoffnung, dass jeder Entwickler innerhalb von drei Monaten jedes Problem lösen kann.
Wir verstehen die Probleme
Aber alle diese Daten einfach zu sammeln — das ist gut, nützlich und angemessen, aber zu wenig — man muss sie verstehen. Denn es sind Millionen verschiedener Pläne pro Tag.

Aber Millionen sind nicht handhabbar, man muss zuerst "weniger" schaffen. Und zunächst muss entschieden werden, wie dieses "weniger" organisiert werden soll.
Wir haben drei Schlüsselthemen identifiziert:
- wer diese Anfrage wurde gesendet
Das heißt, aus welcher Anwendung es gekommen ist: Web-Interface, Backend, Zahlungssystem oder etwas anderes. - wobei es ist passiert
Auf welchem spezifischen Server. Denn wenn Sie mehrere Server für eine Anwendung haben und plötzlich einer davon 'stottert' (weil die 'Festplatte beschädigt' ist, 'Speicherfehler' aufgetreten ist oder ein anderes Problem vorliegt), müssen Sie genau den Server ansprechen. - als wo genau das Problem in der einen oder anderen Hinsicht aufgetreten ist
Um herauszufinden, 'wer' die Anfrage gesendet hat, verwenden wir ein internes Mittel – die Einrichtung einer Sessionsvariable: SET application_name = '{bl-host}:{bl-method}'; - wir speichern den Hostnamen der Business-Logik, von dem die Anfrage kommt, sowie den Namen der Methode oder Anwendung, die sie initiiert hat.
Nachdem wir den 'Absender' der Anfrage übermittelt haben, müssen wir ihn im Log ausgeben – dafür konfigurieren wir die Variable log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Wer interessiert ist, kann , was das alles bedeutet. Das bedeutet, dass wir im Log sehen:
- die Zeit
- die Identifikatoren von Prozess und Transaktion
- den Namen der Datenbank
- den IP desjenigen, der diese Anfrage gesendet hat
- und den Namen der Methode
Es war uns schnell klar, dass es nicht besonders spannend ist, die Korrelation einer einzelnen Anfrage zwischen verschiedenen Servern zu betrachten. Es kommt nicht oft vor, dass eine Anwendung sowohl hier als auch dort die gleiche Fehlfunktion aufweist. Selbst wenn sie gleich ist – schauen Sie sich jeden dieser Server an.
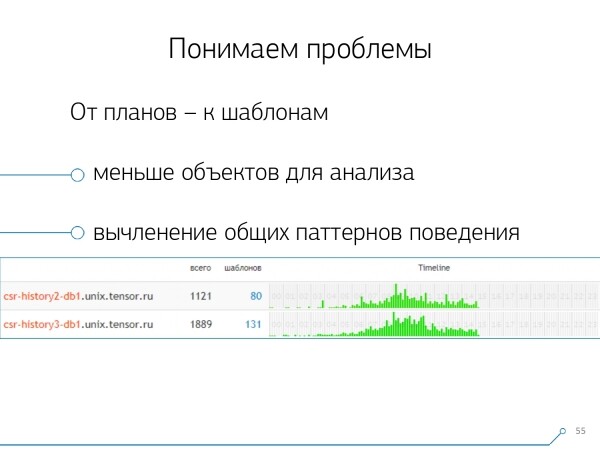
Nun, der Schnitt „ein Server – ein Tag“ hatte sich für jede Analyse als ausreichend erwiesen.
Der erste Analyseschnitt ist der bekannte „Template“ – eine verkürzte Darstellung des Plans, die von allen numerischen Werten bereinigt wurde. Der zweite Schnitt – Anwendung oder Methode, und der dritte – ist ein spezifischer Knoten im Plan, der uns Probleme bereitet hat.
Als wir von spezifischen Instanzen zu Templates übergingen, erhielten wir sofort zwei Vorteile:
- eine signifikante Reduktion der zu analysierenden Objekte
Sie müssen das Problem nicht mehr anhand von Tausenden von Anfragen oder Plänen analysieren, sondern nur noch anhand von Dutzenden von Templates. - Zeitleiste
Das heißt, durch die Zusammenfassung von „Fakten“ in einem bestimmten Kontext kann man deren Auftreten im Laufe des Tages darstellen. Hierbei wird deutlich, dass wenn ein bestimmtes Muster beispielsweise einmal pro Stunde auftritt, während es eigentlich einmal täglich sein sollte, es an der Zeit ist, darüber nachzudenken, was schiefgelaufen ist — wer es ausgelöst hat und warum, vielleicht sollte es hier gar nicht sein. Dies ist eine weitere nicht-numerische, rein visuelle Analyseweise.

Die anderen Methoden basieren auf den Kennzahlen, die wir aus dem Plan ableiten: wie oft ein solches Muster aufgetreten ist, die Gesamt- und Durchschnittszeit, wie viele Daten vom Disk gelesen wurden und wie viele aus dem Speicher…
Weil Sie beispielsweise auf die Analytics-Seite des Hosts kommen und sehen — da wird plötzlich zu viel vom Disk gelesen. Der Disk im Server kommt nicht mehr mit — aber wer liest von ihm?
Und Sie können nach jeder Spalte sortieren und entscheiden, mit was Sie sich jetzt direkt auseinandersetzen möchten — mit der CPU- oder Disk-Auslastung oder der Gesamtanzahl an Anfragen… Sortiert, die „Top-Fälle“ angeschaut, behoben — eine neue Version der Anwendung bereitgestellt.
Und sofort sehen Sie verschiedene Anwendungen, die mit demselben Template aus einem Abfragetyp arbeiten. SELECT * FROM users WHERE login = 'Vasya'. Frontend, Backend, Processing… Und man fragt sich, warum das Processing den Benutzer lesen sollte, wenn er nicht mit ihm interagiert.
Der umgekehrte Ansatz ist, dass man direkt sieht, was die Anwendung tut. Zum Beispiel, das Frontend – das, das, das hier, und noch zusätzlich das einmal pro Stunde (genau hier hilft die Timeline). Und sofort stellt sich die Frage – eigentlich ist es nicht die Aufgabe des Frontends, das einmal pro Stunde zu tun…

Nach einer Weile haben wir gemerkt, dass uns aggregierte Statistiken im Hinblick auf die Knoten des Plans fehlen.. Wir haben aus den Plänen nur die Knoten herausgefiltert, die etwas mit den Daten der Tabellen machen (lesen/schreiben, ob sie nach Index arbeiten oder nicht). Im Wesentlichen wird im Vergleich zum vorherigen Bild nur ein Aspekt hinzugefügt – wie viele Datensätze dieser Knoten uns gebracht hat, und wie viele herausgefiltert wurden (Rows Removed by Filter).
Sie haben keinen passenden Index auf der Tabelle, Sie machen eine Abfrage, sie fliegt am Index vorbei und fällt in Seq Scan… Sie haben alle Datensätze, außer einem, herausgefiltert. Warum benötigen Sie erschienen 100M herausgefilterte Datensätze pro Tag, wäre es da nicht besser, einen Index zu erstellen?

Nachdem wir alle Pläne für die Knoten durchgesehen haben, haben wir festgestellt, dass es einige gängige Strukturen in den Plänen gibt, die mit sehr großer Wahrscheinlichkeit verdächtig aussehen. Es wäre hilfreich, dem Entwickler zu sagen: „Freund, hier liest du zuerst nach dem Index, dann sortierst du und schneidest danach“ – normalerweise gibt es dort nur einen Eintrag.
Alle, die solche Anfragen gestellt haben, sind sicher auf folgendes Muster gestoßen: „Gib mir die letzte Bestellung von Vase, sein Datum.“ Und wenn du keinen Index nach Datum hast oder im verwendeten Index kein Datum enthalten ist, dann wirst du genau auf solche ‚Hindernisse‘ stoßen.
Aber wir wissen doch, dass es sich um ‚Hindernisse‘ handelt – warum sollte man dem Entwickler nicht gleich sagen, was er tun sollte? Wenn unser Entwickler jetzt den Plan öffnet, sieht er sofort ein übersichtliches Bild mit Hinweisen, die ihm sagen: „Hier und hier hast du Probleme, und sie werden so und so gelöst.“
Infolgedessen ist das Volumen der Erfahrung, die erforderlich war, um zu Beginn und jetzt Probleme zu lösen, drastisch gesunken. So ist unser Instrument entstanden.

Quelle: habr.com
