

Hallo.
Ich möchte meine Entdeckung teilen – das Ergebnis von Überlegungen, Experimenten und Fehlern.
Im Grunde genommen ist es natürlich keine echte Entdeckung – das sollte jedem, der sich mit angewandter Datenverarbeitung und der Optimierung von Systemen, nicht unbedingt nur Datenbanken, beschäftigt, wohl bekannt sein.
Und ja, sie wissen das, schreiben interessante Artikel über ihre Forschung, (UPD: In den Kommentaren wurde auf ein sehr interessantes Projekt hingewiesen: )
Auf der anderen Seite sehe ich spontan keine weit verbreitete Erwähnung oder Verbreitung dieses Ansatzes im Internet unter IT-Experten und DBAs.
Kommen wir also zur Sache.
Nehmen wir an, wir haben die Aufgabe, ein bestimmtes Servicesystem für die Durchführung irgendeiner Arbeit zu konfigurieren.
Über diese Arbeit ist bekannt, wie sie aussieht, wie die Qualität dieser Arbeit gemessen wird und welcher Kriterien zur Messung dieser Qualität angewendet werden.
Lassen Sie uns auch annehmen, dass es mehr oder weniger klar und verständlich ist, wie die Arbeit in (oder mit) diesem Servicesystem ausgeführt wird.
"Mehr oder weniger" bedeutet, dass die Möglichkeit besteht, ein gewisses Werkzeug, eine Dienstleistung oder einen Service vorzubereiten oder zu besorgen, mit dem man einen Testlast auf die Systeme erzeugen kann, die ausreichend realistisch für das ist, was in der Produktivumgebung sein wird, und unter Bedingungen, die für den Betrieb in der Produktion akzeptabel sind.
Nehmen wir an, dass die Reihe von Einstellungsmöglichkeiten für dieses Service-System bekannt ist, mit denen man das System hinsichtlich seiner Produktivität einstellen kann.
Das Problem ist, dass es kein ausreichendes Verständnis für dieses Service-System gibt, das es ermöglicht, die Einstellungen dieser Systemkonfiguration für die zukünftige Last auf dieser Plattform expertenmäßig festzulegen und die benötigte Produktivität zu erreichen.
Nun, so läuft es fast immer.
Was kann man hier tun?
Nun, das Erste, was mir in den Sinn kommt, ist, die Dokumentation zu diesem System zu konsultieren. Zu verstehen, welche zulässigen Bereiche für die Werte der Einstellungsmöglichkeiten vorhanden sind. Und beispielsweise mithilfe des Gradientenabstiegs die Werte für die Systemeinstellungen in den Tests anzupassen.
Das heißt, dem System eine bestimmte Konfiguration in Form eines konkreten Satzes von Einstellungen zuzuweisen.
Testlasten mit diesem Tool, einem Lastgenerator, erzeugen.
Und die Reaktionszeit oder eine Metrik zur Qualität der Systemleistung beobachten.
Ein weiterer Gedanke könnte sein, dass das sehr lange dauert.
Das bedeutet: Wenn es viele Konfigurationsparameter gibt, die Bereiche ihrer Werte groß sind und jeder einzelne Lasttest lange dauert, dann kann das alles in der Tat viel Zeit in Anspruch nehmen.
Hier gibt es etwas, das man verstehen und im Gedächtnis behalten kann.
Man kann herausfinden, dass im Satz von Werten der Konfigurationsparameter des Dienstes ein Vektor ist, der eine Folge bestimmter Werte beschreibt.
Jeder solche Vektor hat, unter ansonsten gleichen Bedingungen (wenn dieser Vektor nicht betroffen ist), einen bestimmten Wert einer Metrik — einem Qualitätsindikator der Systemleistung unter Last.
Das heißt,
Bezeichnen wir den Konfigurationsvektor des Systems als  , wobei
, wobei  ; wobei
; wobei  die Anzahl der Konfigurationsparameter des Systems ist, also wie viele dieser Parameter es gibt.
die Anzahl der Konfigurationsparameter des Systems ist, also wie viele dieser Parameter es gibt.
Den Wert der Metrik, der diesem  entspricht, bezeichnen wir als
entspricht, bezeichnen wir als
 , das ergibt eine Funktion:
, das ergibt eine Funktion: 
Nun, dann reduziert sich alles sofort auf die fast vergessenen Extremwertsuche-Algorithmen aus meiner Studienzeit.
Das ist gut, aber hier stellt sich eine organisatorisch-anwendungsorientierte Frage: Welchen Algorithmus genau soll man verwenden?
- Das heißt — um selbst weniger händisch zu coden.
- Und damit es funktioniert, d.h. den Extremwert findet (falls vorhanden), zumindest schneller als der Koordinatenabstieg.
Der erste Punkt deutet darauf hin, dass man sich nach irgendwelchen Umgebungen umsehen sollte, in denen solche Algorithmen bereits implementiert sind und in irgendeiner Form codebereit verfügbar sind.
Nun, bekannt sind mir Python und cran-r
Der zweite Punkt bedeutet, dass man etwas über die Algorithmen selbst lesen sollte, welche es gibt, welche Anforderungen sie haben und welche Besonderheiten in der Anwendung.
Und was sie einem geben, können nützliche Nebeneffekte oder Ergebnisse sein, entweder direkt vom Algorithmus selbst.
Oder man kann sie aus den Ergebnissen der Algorithmusarbeit erhalten.
Hier hängt viel von den Eingangsvoraussetzungen ab.
Wenn man beispielsweise aus irgendeinem Grund schneller Ergebnisse benötigt, sollte man die Algorithmen des Gradientenabstiegs in Betracht ziehen und eine davon auswählen.
Oder, wenn die Zeit nicht so wichtig ist, könnten wir beispielsweise stochastische Optimierungsmethoden wie genetische Algorithmen verwenden.
Ich schlage vor, die Funktionsweise eines solchen Ansatzes zur Konfiguration von Systemen mithilfe eines genetischen Algorithmus in der nächsten, sozusagen: Laborarbeit zu betrachten.
Ausgangsdaten:
- Nehmen wir an, es handelt sich um ein Servicersystem:
oracle xe 18c - Nehmen wir an, es verwaltet die Transaktionsaktivitäten, mit dem Ziel: eine möglichst hohe Durchsatzrate der Datenbank in Transaktionen/Sekunde zu erreichen.
- Transaktionen können sehr unterschiedlich sein, hinsichtlich ihrer Art der Datenverarbeitung und des Arbeitskontexts.
Lassen Sie uns festlegen, dass dies Transaktionen sind, die keine großen Mengen an Tabellen Daten verarbeiten.
Im Sinne, dass sie nicht mehr Undo-Daten generieren als Redo-Daten und keine großen Prozentsätze von Zeilen in großen Tabellen bearbeiten.
Es handelt sich um Transaktionen, die eine Zeile in einer mehr oder weniger großen Tabelle ändern, mit einer geringen Anzahl von Indizes über dieser Tabelle.
In einem solchen Szenario wird die Produktivität der Datenbank bei der Verarbeitung von Transaktionen, mit der Vorbehalt, durch die Qualität der Verarbeitung der Redo-Daten bestimmt.
Vorbehalt – wenn wir speziell über die Einstellungen der Datenbanken sprechen.
Denn im Allgemeinen kann es beispielsweise zu transaktionalen Sperren zwischen den SQL-Sitzungen kommen, aufgrund des Designs der Benutzerinteraktion mit tabellarischen Daten und/oder der tabellarischen Datenmodellierung.
Diese werden natürlich die TPS-Metrik negativ beeinflussen und stellen einen exogenen Faktor in Bezug auf die Datenbank dar: Das Design des Datenmodells und der Datenverarbeitung hat solche Sperren zur Folge.
Deshalb wollen wir zu Experimentierzwecken diesen Faktor ausschließen, ich werde später erläutern, wie genau.
- Nehmen wir zur Klarheit an, dass 100% der an die Datenbank gesendeten SQL-Befehle DML-Befehle sind.
Gehen wir davon aus, dass die Eigenschaften der Benutzerinteraktion mit der Datenbank in den Tests identisch sind.
Das heißt: Anzahl der SQL-Sitzungen, tabellarische Daten und wie die SQL-Sitzungen mit diesen Daten arbeiten. - Die Datenbank arbeitet in
FORCE LOGGING,ARCHIVELOGModi. Der Flashback-Datenbankmodus ist auf Ebene der Datenbank deaktiviert. - Redo-Logs: befinden sich in einem separaten Dateisystem auf einer separaten "Festplatte";
Der gesamte restliche Teil der physischen Komponente der Datenbank: in einem anderen, separaten Dateisystem auf einer separaten "Festplatte":
Mehr Informationen zur Struktur der physischen Komponente der Labor-Datenbank
SQL> select status||' '||name from v$controlfile;
/db/u14/oradata/XE/control01.ctl
SQL> select GROUP#||' '||MEMBER from v$logfile;
1 /db/u02/oradata/XE/redo01_01.log
2 /db/u02/oradata/XE/redo02_01.log
SQL> select FILE_ID||' '||TABLESPACE_NAME||' '||round(BYTES/1024/1024,2)||' '||FILE_NAME as col from dba_data_files;
4 UNDOTBS1 2208 /db/u14/oradata/XE/undotbs1_01.dbf
2 SLOB 128 /db/u14/oradata/XE/slob01.dbf
7 USERS 5 /db/u14/oradata/XE/users01.dbf
1 SYSTEM 860 /db/u14/oradata/XE/system01.dbf
3 SYSAUX 550 /db/u14/oradata/XE/sysaux01.dbf
5 MONITOR 128 /db/u14/oradata/XE/monitor.dbf
SQL> !cat /proc/mounts | egrep "/db/u[0-2]"
/dev/vda1 /db/u14 ext4 rw,noatime,nodiratime,data=ordered 0 0
/dev/mapper/vgsys-ora_redo /db/u02 xfs rw,noatime,nodiratime,attr2,nobarrier,inode64,logbsize=256k,noquota 0 0Ursprünglich wollte ich unter diesen Lastbedingungen ein Transaktions-Datenbanksystem verwenden.
Es hat eine bemerkenswerte Eigenschaft, die ich hier zitiere:
Im Kern von SLOB steht die "SLOB-Methode." Die SLOB-Methode zielt darauf ab, Plattformen zu testen
ohne Anwendungsbeeinträchtigungen. Man kann die maximale Hardwareleistung nicht ausschöpfen,
wenn der Anwendungscode beispielsweise durch Anwendungs-locking oder sogar
das Teilen von Oracle-Datenbankblöcken gebunden ist. Richtig – es gibt Overhead beim Teilen von Daten
in Datenblöcken! Aber SLOB ist – in seinem Standard-Deployment – immun gegen solche Konflikte.
Diese Erklärung: stimmt überein, das ist so.
Es ist praktisch, den Grad der Parallelität der SCL-Sessions zu regulieren, das ist der Schlüssel -t zum Start der Utility runit.sh aus dem SLOB-Paket.
Es wird der Prozentsatz der DML-Befehle reguliert, in der Anzahl der SCLs, die an das DBMS gesendet werden; jede SCL-Session, der Parameter UPDATE_PCT
Separat und äußerst praktisch: SLOB bereitet Statspak oder AWR-Snapshots (was angegeben ist) vor, sowohl während als auch nach der Lastsitzung.
Es stellte sich jedoch heraus, dass SLOB Sitzungen mit einer Dauer von weniger als 30 Sekunden nicht unterstützt werden.
Deshalb habe ich zunächst meine eigene, arbeitsfreundliche Version des Lastgenerators programmiert, die sich dann als funktional erwies.
Ich möchte zum Lastgenerator etwas klarstellen – was er tut und wie er es macht.
Im Grunde sieht der Lastgenerator so aus:
Code des Workers
function dotx()
{
local v_period="$2"
[ -z "v_period" ] && v_period="0"
source "/home/oracle/testingredotracе/config.conf"
$ORACLE_HOME/bin/sqlplus -S system/${v_system_pwd} << __EOF__
whenever sqlerror exit failure
set verify off
set echo off
set feedback off
define wnum="$1"
define period="$v_period"
set appinfo worker_&&wnum
declare
v_upto number;
v_key number;
v_tots number;
v_cts number;
begin
select max(col1) into v_upto from system.testtab_&&wnum;
SELECT (( SYSDATE - DATE '1970-01-01' ) * 86400 ) into v_cts FROM DUAL;
v_tots := &&period + v_cts;
while v_cts <= v_tots
loop
v_key:=abs(mod(dbms_random.random,v_upto));
if v_key=0 then
v_key:=1;
end if;
update system.testtab_&&wnum t
set t.object_name=translate(dbms_random.string('a', 120), 'abcXYZ', '158249')
where t.col1=v_key
;
commit;
SELECT (( SYSDATE - DATE '1970-01-01' ) * 86400 ) into v_cts FROM DUAL;
end loop;
end;
/
exit
__EOF__
}
export -f dotxWorkers werden wie folgt gestartet:
Start des Workers
echo "Teststart, Dauer: ${TEST_DURATION}" >> "$v_logfile"
for((i=1;i> "$v_logfile"
dotx "$i" "${TEST_DURATION}" &
done
echo "Warten..." >> "$v_logfile"
waitDie Tabellen für die Worker werden folgendermaßen vorbereitet:
Tabellen erstellen
function createtable() {
source "/home/oracle/testingredotracе/config.conf"
$ORACLE_HOME/bin/sqlplus -S system/${v_system_pwd} << __EOF__
whenever sqlerror continue
set verify off
set echo off
set feedback off
define wnum="$1"
define ts_name="slob"
begin
execute immediate 'drop table system.testtab_&&wnum';
exception when others then null;
end;
/
create table system.testtab_&&wnum tablespace &&ts_name as
select rownum as col1, t.*
from sys.dba_objects t
where rownum> "$v_logfile"Das heißt, für jeden Worker (praktisch: eine separate SQL-Session in der Datenbank) wird eine separate Tabelle erstellt, mit der der Worker arbeitet.
So wird ein Fehlen von transaktionalen Sperren zwischen den SQL-Sitzungen der Worker erreicht.
Jeder Worker führt dasselbe auf seiner Tabelle aus, die Tabellen sind alle identisch.
Alle Worker führen die Arbeit über denselben Zeitraum aus.
Es dauerte eine beträchtliche Zeit, um beispielsweise festzustellen, dass es tatsächlich geschehen ist, und das nicht nur einmal, sondern mehrfach, dass es zu einem Log-Switching gekommen ist.
In diesem Zusammenhang entstanden dann auch damit verbundene Kosten und Effekte.
In meinem Fall habe ich die Laufzeit der Worker auf 8 Minuten konfiguriert.
Ein Ausschnitt aus dem Statspack-Bericht, der die Leistung der Datenbank unter Belastung beschreibt.
Datenbank DB-ID Instanz Inst-Nr. Startzeit Version RAC
~~~~~~~~ ------------ ------------ --------- --------------- ----------- ---
2929910313 XE 1 07-Sep-20 23:12 18.0.0.0.0 NEIN
Hostname Plattform CPUs Kerne Sockel Speicher (G)
~~~~ ---------------- ---------------------- ----- ----- ------- ------------
billing.izhevsk1 Linux x86 64-bit 2 2 1 15.6
Snapshot Snap-ID Snap-Zeit Sitzungen Curs/Sess Kommentar
~~~~~~~~ ---------- ------------------ -------- --------- ------------------
Beginne Snapshot: 1630 07-Sep-20 23:12:27 55 .7
End Snapshot: 1631 07-Sep-20 23:20:29 62 .6
Verstrichene Zeit: 8.03 (Min.) Durchschn. Aktive Sitzungen: 8.4
DB-Zeit: 67.31 (Min.) DB-CPU: 15.01 (Min.)
Cache-Größen Beginn Ende
~~~~~~~~~~~ ---------- ----------
Puffer-Cache: 1,392M Std. Blockgröße: 8K
Shared Pool: 288M Log-Puffer: 103,424K
Ladeprofil Pro Sekunde Pro Transaktion Pro Exec Pro Aufruf
~~~~~~~~~~~~ ------------------ ----------------- ----------- -----------
DB-Zeit(s): 8.4 0.0 0.00 0.20
DB-CPU(s): 1.9 0.0 0.00 0.04
Redo-Größe: 7,685,765.6 978.4
Logische Reads: 60,447.0 7.7
Blockänderungen: 47,167.3 6.0
Physische Reads: 8.3 0.0
Physische Writes: 253.4 0.0
Benutzeraufrufe: 42.6 0.0
Parses: 23.2 0.0
Harte Parses: 1.2 0.0
W/A MB verarbeitet: 1.0 0.0
Logins: 0.5 0.0
Ausführungen: 15,756.5 2.0
Rollbacks: 0.0 0.0
Transaktionen: 7,855.1Zurück zur Aufgabenstellung des Laborversuchs.
Wir werden, unter sonst gleichen Bedingungen, die Werte folgender Parameter des Labor-Datenbanksystems variieren:
- Größe der Log-Gruppe der Datenbank. Wertebereich: [32, 1024] MB;
- Anzahl der Log-Gruppen der Datenbank. Wertebereich: [2, 32];
log_archive_max_processesWertebereich: [1, 8];commit_logginges sind zwei Werte zulässig:batch|immediate;commit_waites sind zwei Werte zulässig:wait|nowait;log_bufferWertebereich: [2, 128] MB.log_checkpoint_timeoutWertebereich: [60, 1200] Sekundendb_writer_processesWertebereich: [1, 4]undo_retentionWertebereich: [30; 300] Sekundentransactions_per_rollback_segmentWertebereich: [1, 8]disk_asynch_ioes sind zwei Werte zulässig:true|false;filesystemio_optionszulässige Werte sind:none|setall|directIO|asynch;db_block_checkingzulässige Werte sind:OFF|LOW|MEDIUM|FULL;db_block_checksumzulässige Werte sind:OFF|TYPICAL|FULL;
Eine Person mit Erfahrung in der Betreuung von Oracle-Datenbanken kann sicherlich schon jetzt sagen, welche Werte für die angegebenen Parameter eingestellt werden sollten, um eine höhere Leistungsfähigkeit des Datenbanksystems für die hier oben angesprochene Datenbearbeitung zu erreichen.
Aber.
Der Sinn des Laborversuchs besteht darin, zu zeigen, dass der Optimierungsalgorithmus uns dies relativ schnell präzisieren wird.
Wir müssen lediglich in die Dokumentation schauen, um zu klären, wie die Parameter und in welchen Bereichen sie angepasst werden sollten.
Außerdem müssen wir den Code programmieren, der die Arbeit mit dem konfigurierbaren System des gewählten Optimierungsalgorithmus umsetzt.
Nun zurück zum Code.
Ich habe zuvor von cran-rgesprochen, d.h.: alle Manipulationen mit dem konfigurierbaren System werden in Form eines R-Skripts orchestriert.
Tatsächlich besteht die Aufgabe aus der Analyse und der Auswahl basierend auf dem Wert der Metrik sowie den Zustandsvektoren des Systems: das ist das Paket GA ()
In diesem Fall ist das Paket nicht besonders geeignet, da es Vektoren (Chromosomen, wenn wir von den Begriffen des Pakets sprechen) als Ganzzahlen mit Dezimalstellen erwartet.
Mein Vektor hingegen besteht aus 14 Größen – Ganzzahlen und String-Werten.
Das Problem kann natürlich leicht umgangen werden, indem man den String-Werten bestimmte Zahlen zuweist.
Somit sieht der Hauptteil des R-Skripts wie folgt aus:
Aufruf von GA::ga
cat( "", file=v_logfile, sep="n", append=F)
pSize = 10
elitism_value=1
pmutation_coef=0.8
pcrossover_coef=0.1
iterations=50
gam=GA::ga(type="real-valued", fitness=evaluate,
lower=c(32,2, 1,1,1,2,60,1,30,1,0,0, 0,0), upper=c(1024,32, 8,10,10,128,800,4,300,8,10,40, 40,30),
popSize=pSize,
pcrossover = pcrossover_coef,
pmutation = pmutation_coef,
maxiter=iterations,
run=4,
keepBest=T)
cat( "GA-Sitzung ist abgeschlossen" , file=v_logfile, sep="n", append=T)
gam@solutionHier, mit Hilfe von untere und obere Attributen der Unterroutine ga wird effektiv der Suchraum definiert, innerhalb dessen nach einem Vektor (oder Vektoren) gesucht wird, für den das maximale Fitnesswert erzielt wird.
Die ga-Unterroutine sucht, indem sie die Fitnessfunktion maximiert.
Das bedeutet, dass in diesem Fall die Fitnessfunktion, die den Vektor als eine Menge von Werten für bestimmte Parameter der Datenbank versteht, eine Metrik von der Datenbank erhält.
Das heißt: Wie viele Transaktionen pro Sekunde die Datenbank bei dieser Konfiguration und dieser Last verarbeitet.
Das heißt, es sollte innerhalb der Fitnessfunktion eine entsprechende Logik durchgeführt werden:
- Bearbeitung des Eingabewerts — Umwandlung in Werte für die Parameter der Datenbank.
- Versuch, die angegebene Anzahl von Redo-Gruppen mit der festgelegten Größe zu erstellen. Dabei kann der Versuch fehlschlagen.
Bereits vorhandene Protokollgruppen in der Datenbank, in einer bestimmten Anzahl und Größe, müssen zur Wahrung der Experimentreinheit gelöscht werden. - Im Erfolgsfall des vorherigen Punktes: Festlegung der Werte für die Konfigurationsparameter (auch hier kann ein Fehler auftreten).
- Im Erfolgsfall des vorherigen Punktes: Stoppen der Datenbank, um sie dann neu zu starten, damit die neuen Parameterwerte wirksam werden. (auch hier kann ein Fehler auftreten).
- Im Erfolgsfall des vorherigen Punktes: Durchführung eines Lasttests und Erfassung der Metrik von der Datenbank.
- Rückführung der Datenbank in den Ausgangszustand, d.h. Löschen zusätzlicher Protokollgruppen und Wiederherstellung der ursprünglichen Datenbankkonfiguration.
Code der Fitness-Funktion
evaluate=function(p_par) {
v_module="evaluate"
v_metric=0
opn=NULL
opn$rg_size=round(p_par[1],digit=0)
opn$rg_count=round(p_par[2],digit=0)
opn$log_archive_max_processes=round(p_par[3],digit=0)
opn$commit_logging="BATCH"
if ( round(p_par[4],digit=0) > 5 ) {
opn$commit_logging="IMMEDIATE"
}
opn$commit_logging=paste("'", opn$commit_logging, "'",sep="")
opn$commit_wait="WAIT"
if ( round(p_par[5],digit=0) > 5 ) {
opn$commit_wait="NOWAIT"
}
opn$commit_wait=paste("'", opn$commit_wait, "'",sep="")
opn$log_buffer=paste(round(p_par[6],digit=0),"m",sep="")
opn$log_checkpoint_timeout=round(p_par[7],digit=0)
opn$db_writer_processes=round(p_par[8],digit=0)
opn$undo_retention=round(p_par[9],digit=0)
opn$transactions_per_rollback_segment=round(p_par[10],digit=0)
opn$disk_asynch_io="true"
if ( round(p_par[11],digit=0) > 5 ) {
opn$disk_asynch_io="false"
}
opn$filesystemio_options="none"
if ( round(p_par[12],digit=0) > 10 && round(p_par[12],digit=0) 20 && round(p_par[12],digit=0) 30 ) {
opn$filesystemio_options="asynch"
}
opn$db_block_checking="OFF"
if ( round(p_par[13],digit=0) > 10 && round(p_par[13],digit=0) 20 && round(p_par[13],digit=0) 30 ) {
opn$db_block_checking="FULL"
}
opn$db_block_checksum="OFF"
if ( round(p_par[14],digit=0) > 10 && round(p_par[14],digit=0) 20 ) {
opn$db_block_checksum="FULL"
}
v_vector=paste(round(p_par[1],digit=0),round(p_par[2],digit=0),round(p_par[3],digit=0),round(p_par[4],digit=0),round(p_par[5],digit=0),round(p_par[6],digit=0),round(p_par[7],digit=0),round(p_par[8],digit=0),round(p_par[9],digit=0),round(p_par[10],digit=0),round(p_par[11],digit=0),round(p_par[12],digit=0),round(p_par[13],digit=0),round(p_par[14],digit=0),sep=";")
cat( paste(v_module," try to evaluate vector: ", v_vector,sep="") , file=v_logfile, sep="n", append=T)
rc=make_additional_rgroups(opn)
if ( rc!=0 ) {
cat( paste(v_module,"make_additional_rgroups failed",sep="") , file=v_logfile, sep="n", append=T)
return (0)
}
v_rc=0
rc=set_db_parameter("log_archive_max_processes", opn$log_archive_max_processes)
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("commit_logging", opn$commit_logging )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("commit_wait", opn$commit_wait )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("log_buffer", opn$log_buffer )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("log_checkpoint_timeout", opn$log_checkpoint_timeout )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_writer_processes", opn$db_writer_processes )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("undo_retention", opn$undo_retention )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("transactions_per_rollback_segment", opn$transactions_per_rollback_segment )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("disk_asynch_io", opn$disk_asynch_io )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("filesystemio_options", opn$filesystemio_options )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_block_checking", opn$db_block_checking )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_block_checksum", opn$db_block_checksum )
if ( rc != 0 ) { v_rc=1 }
if ( rc!=0 ) {
cat( paste(v_module," can not startup db with that vector of settings",sep="") , file=v_logfile, sep="n", append=T)
rc=stop_db("immediate")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
return (0)
}
rc=stop_db("immediate")
rc=start_db("")
if ( rc!=0 ) {
cat( paste(v_module," can not startup db with that vector of settings",sep="") , file=v_logfile, sep="n", append=T)
rc=stop_db("abort")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
return (0)
}
rc=run_test()
v_metric=getmetric()
rc=stop_db("immediate")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
cat( paste("result: ",v_metric," ",v_vector,sep="") , file=v_logfile, sep="n", append=T)
return (v_metric)
}Somit wird die gesamte Arbeit im Fitness-Funktionsprozess durchgeführt.
ga-Unterprogramm, das Vektorverarbeitung durchführt, oder besser gesagt – Chromosomen.
Dabei ist für uns am wichtigsten: die Selektion von Chromosomen mit Genen, bei denen die Fitness-Funktion hohe Werte ergibt.
Im Wesentlichen handelt es sich um den Prozess, den optimalen Satz von Chromosomen als Vektor in einem N-dimensionalen Suchraum zu finden.
Eine sehr klare, ausführliche , mit Beispielen von R-Code zur Funktionsweise des genetischen Algorithmus.
Ich möchte insbesondere auf zwei technische Aspekte hinweisen.
Hilfsaufrufe aus der Funktion evaluate, wie zum Beispiel Stop-Start, die Zuweisung des Wertes eines Parameters der Datenbank, werden basierend auf cran-r der Funktion system2
mit der bereits ein Bash-Skript oder ein Befehl aufgerufen wird.
Zum Beispiel:
set_db_parameter
set_db_parameter=function(p1, p2) {
v_module="set_db_parameter"
v_cmd="/home/oracle/testingredotracе/set_db_parameter.sh"
v_args=paste(p1," ",p2,sep="")
x=system2(v_cmd, args=v_args, stdout=T, stderr=T, wait=T)
if ( length(attributes(x)) > 0 ) {
cat(paste(v_module," failed with: ",attributes(x)$status," ",v_cmd," ",v_args,sep=""), file=v_logfile, sep="n", append=T)
return (attributes(x)$status)
}
else {
cat(paste(v_module," ok: ",v_cmd," ",v_args,sep=""), file=v_logfile, sep="n", append=T)
return (0)
}
}Der zweite Punkt ist die Zeile, evaluate Funktionen, die den spezifischen Wert der Metrik und den entsprechenden Einstellungsvektor in das Logfile speichern:
cat( paste("Ergebnis: ",v_metric," ",v_vector,sep="") , file=v_logfile, sep="n", append=T)Das ist wichtig, da aus diesem Datensatz zusätzliche Informationen darüber gewonnen werden können, welcher der Komponenten des Einstellungsvektors einen größeren oder kleineren Einfluss auf den Wert der Metrik hat.
Das bedeutet: Es kann eine Attribut-Wichtigkeitsanalyse durchgeführt werden.
So, was könnte dabei herauskommen.
In Form eines Diagramms, wenn man die Tests nach steigendem Wert der Metrik anordnet, sieht die Darstellung so aus:
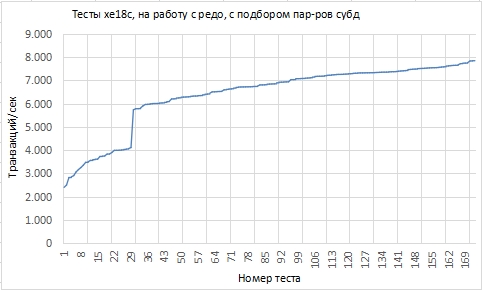
Einige Daten, die den extremen Werten der Metrik entsprechen:

Hier, auf dem Screenshot mit den Ergebnissen, möchte ich präzisieren: Die Werte des Einstellungsvektors sind in Bezug auf den Code der Fitnessfunktion angegeben, nicht in Bezug auf die Nummernliste von Parametern / Wertebereichen der Parameter, die ich weiter oben im Text formuliert habe.
Nun, ob das viel oder wenig ist, ~8000 tps: die Frage ist unabhängig.
Im Rahmen der Laborarbeit ist diese Zahl nicht von Bedeutung, wichtig ist die Dynamik, wie sich dieser Wert verändert.
Die Dynamik ist hier gut.
Offensichtlich hat mindestens ein Faktor, der signifikant auf den Wert der Metrik einwirkt, der GA-Algorithmus, der die Vektoren-Chromosomen durchläuft: abgedeckt.
Nach der recht lebhaften Dynamik der Wertekurve gibt es mindestens einen weiteren Faktor, der zwar erheblich kleiner ist, aber dennoch Einfluss hat.
Hier ist eine attribute-importance Analyse erforderlich, um zu verstehen, welche Attribute (in diesem Fall die Komponenten des Einstellungsvektors) und wie stark sie den Wert der Metrik beeinflussen.
Von diesen Informationen können wir verstehen, welche Faktoren durch Änderungen der signifikanten Attribute betroffen waren.
Ausführen attribute-importance Es gibt verschiedene Möglichkeiten.
Für diese Zwecke gefällt mir der Algorithmus randomForest des gleichnamigen R-Pakets (wie ich seine Funktionsweise insgesamt verstehe und seinen Ansatz zur Bewertung der Wichtigkeit von Attributen im Speziellen), der ein Modell der Abhängigkeit der Antwortvariablen von den Attributen aufbaut.)
randomForest, как я понимаю его работу вообще и его подход к оценке важности атрибутов в частности, строит некую модель зависимости переменной-отклика, от атрибутов.
In unserem Fall ist die Antwortvariable die Metrik, die aus Subdatenbanken in Lasttests erhalten wird: tps;
Und die Attribute sind die Komponenten des Einstellungsvektors.
So sind randomForest bewertet die Wichtigkeit jedes Attributs des Modells mit zwei Zahlen: %IncMSE – wie das Vorhandensein oder Fehlen dieses Attributs in dem Modell die MSE-Qualität dieses Modells (Mean Squared Error) verändert;
IncNodePurity ist eine Kennzahl, die anzeigt, wie gut der Datensatz basierend auf den Werten dieses Attributs aufgeteilt werden kann, sodass in einem Teil die Daten mit einem bestimmten Wert der erklärten Metrik und im anderen Teil die Daten mit einem anderen Wert der Metrik landen.
Das bedeutet also: Wie gut ist dieses Attribut zur Klassifikation geeignet (die klarste Erklärung dazu in russischer Sprache, die ich zu Random Forest gesehen habe). ).
Hier ist der Arbeitscode in R zur Verarbeitung des Datensatzes mit den Ergebnissen der Lasttests:
x=NULL
v_data_file=paste('/tmp/data1.dat',sep="")
x=read.table(v_data_file, header = TRUE, sep = ";", dec=",", quote = ""'", stringsAsFactors=FALSE)
colnames(x)=c('metric','rgsize','rgcount','lamp','cmtl','cmtw','lgbffr','lct','dbwrp','undo_retention','tprs','disk_async_io','filesystemio_options','db_block_checking','db_block_checksum')
idxTrain=sample(nrow(x),as.integer(nrow(x)*0.7))
idxNotTrain=which(! 1:nrow(x) %in% idxTrain )
TrainDS=x[idxTrain,]
ValidateDS=x[idxNotTrain,]
library(randomForest)
#mtry=as.integer( sqrt(dim(x)[2]-1) )
rf=randomForest(metric ~ ., data=TrainDS, ntree=40, mtry=3, replace=T, nodesize=2, importance=T, do.trace=10, localImp=F)
ValidateDS$predicted=predict(rf, newdata=ValidateDS[,colnames(ValidateDS)!="metric"], type="response")
sum((ValidateDS$metric-ValidateDS$predicted)^2)
rf$importanceMan kann direkt manuell die Hyperparameter des Algorithmus anpassen und, basierend auf der Qualität des Modells, ein genaueres Modell auswählen, das Vorhersagen auf dem Validierungsdatensatz trifft.
Man kann eine Funktion für diese Aufgabe schreiben (übrigens, wieder einmal, auf einem Optimierungsalgorithmus basierend).
Man kann das R-Paket nutzen caret, das spielt keine Rolle.
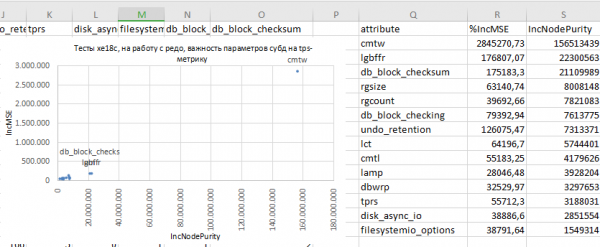
Infolgedessen ergibt sich in diesem Fall folgendes Ergebnis zur Einschätzung der Wichtigkeit der Attribute:
Nun, man kann zu den globalen Überlegungen übergehen:
- Das bedeutet, dass der Parameter unter den gegebenen Testbedingungen der signifikanteste ist.
commit_wait
Technisch betrachtet legt er den Modus für die Ausführung der I/O-Operation zum Schreiben von Redo-Daten aus dem Datenbank-Logpuffer in die aktuelle Journalgruppe fest: synchron oder asynchron.
Bedeutungnowaitunter dem die TPS-Metrik praktisch vertikal und exponentiell ansteigt: dies ist das Aktivieren des asynchronen I/O-Modus in den Redo-Gruppen.
Eine separate Frage ist, ob man das in der Produktionsdatenbank machen sollte oder nicht. Hier beschränke ich mich auf die Feststellung: dies ist ein signifikanter Faktor. - Es ist logisch, dass die Größe des Logpuffers der Datenbank ein signifikanter Faktor ist.
Je kleiner die Größe des Logpuffers ist, desto geringer ist seine Pufferspeicherfähigkeit, und desto häufiger treten Überläufe auf und/oder es ist nicht möglich, freien Speicher für neue Redo-Daten bereitzustellen.
Das bedeutet: Verzögerungen, die mit der Zuweisung von Speicher im Log-Buffer und/oder dem Zurücksetzen von Redo-Daten in die Redo-Gruppen verbunden sind.
Diese Verzögerungen sollten natürlich die Transaktionsdurchsatzrate des DBMS beeinflussen und tun es auch. - Parameter
db_block_checksum: Das ist ebenfalls nachvollziehbar – die Verarbeitung von Transaktionen führt zur Bildung von Dirty-Blocks im Cache des DBMS.
Diese müssen, bei aktivierter Prüfzellenüberprüfung der Datenblöcke, von der Datenbank verarbeitet werden – dabei werden diese Prüfzellen vom Datenblock-Inhalt berechnet und mit dem verglichen, was im Header des Datenblocks steht: ob übereinstimmt oder nicht.
Solche Arbeiten können auch nicht anders, als die Datenverarbeitung zu verzögern, und entsprechend sind der Parameter und der Mechanismus, der diesen Parameter festlegt, von Bedeutung.
Daher bietet der Anbieter in der Dokumentation zu diesem Parameter verschiedene Werte dafür an und weist darauf hin, dass – ja, es wird einen Einfluss geben, aber hier sind unterschiedliche Werte, bis hin zu "deaktiviert", und unterschiedliche Auswirkungen, die Sie auswählen können.
Und eine globale Schlussfolgerung.
Der Ansatz erweist sich insgesamt als durchaus praktikabel.
Es ermöglicht, dass man in den frühen Phasen der Lasttestung eines bestimmten Dienstes die optimale Konfiguration des Systems unter Last auswählen kann, ohne sich intensiv mit den Besonderheiten der Systemkonfiguration auseinanderzusetzen.
Es schließt jedoch nicht aus, dass man zumindest auf dem Niveau des Verständnisses wissen sollte, wie die "Regler" funktionieren und welche Drehbereiche für diese Regler zulässig sind.
In der Folge kann der Ansatz relativ schnell die optimale Systemkonfiguration finden.
Am Ende der Tests erhält man Informationen über die Beziehung zwischen den Qualitätsmetriken des Systems und den Werten der Einstellparameter.
Das sollte natürlich dazu beitragen, ein tieferes Verständnis des Systems und seiner Funktionsweise, zumindest unter dieser spezifischen Last, zu entwickeln.
Praktisch bedeutet dies: eine Abwägung der Kosten für das Verständnis des konfigurierbaren Systems und die Kosten für die Vorbereitung von solchen Systemtests.
Ich möchte außerdem betonen: In diesem Ansatz ist der Grad der Angemessenheit der Systemtests in Bezug auf die Bedingungen, unter denen es im produktiven Einsatz betrieben wird, entscheidend.
Vielen Dank für Ihre Aufmerksamkeit und Zeit.
Quelle: habr.com
