


Hallo zusammen! Ich bin CV-Entwickler bei KROK. Seit drei Jahren setzen wir Projekte im Bereich CV um. In dieser Zeit haben wir viele verschiedene Dinge gemacht, zum Beispiel: Wir haben die Fahrer überwacht, um sicherzustellen, dass sie während der Fahrt nicht trinken, rauchen, am Telefon sprechen oder in den Himmel starren; wir haben diejenigen erfasst, die in den Fahrstreifen fahren, sowie Parkplätze blockieren; wir haben darauf geachtet, dass die Mitarbeiter Helme, Handschuhe usw. tragen; wir haben Mitarbeiter identifiziert, die in ein Objekt einsteigen möchten; und wir haben alles gezählt, was nur möglich ist.
Worauf möchte ich hinaus?
Während der Umsetzung der Projekte haben wir viele Fehler gemacht, viele Fehler, mit denen Sie entweder bereits vertraut sind oder in Zukunft konfrontiert werden.
Modellieren wir eine Situation
Stellen wir uns vor, dass wir in einem jungen Unternehmen "N" arbeiten, das mit ML beschäftigt ist. Wir arbeiten an einem ML (DL, CV) Projekt, dann wechseln wir aus verschiedenen Gründen zu einer anderen Aufgabe, also machen wir eine Pause und kehren zu unserem oder einem anderen Netzwerk zurück.
- Der Moment der Wahrheit naht. Man muss sich irgendwie erinnern, wo man aufgehört hat, welche Hyperparameter man ausprobiert hat und, das Wichtigste, zu welchen Ergebnissen sie geführt haben. Es gibt viele Möglichkeiten, wie Informationen zu allen Läufen gespeichert wurden: im Kopf, in Konfigurationen, in Notizbüchern oder in der Arbeitsumgebung in der Cloud. Ich habe eine Variante gesehen, bei der Hyperparameter als kommentierte Zeilen im Code gespeichert wurden – eine ganz eigene Vorstellung. Stellen Sie sich nun vor, dass Sie nicht zu Ihrem eigenen Projekt zurückkehren, sondern zu dem eines Kollegen, der das Unternehmen verlassen hat, und Ihnen bleibt der Code und ein Modell mit dem Namen model_1.pb als Erbe. Um das Bild zu vervollständigen und den Schmerz nachzuvollziehen, stellen wir uns vor, dass Sie außerdem ein Anfänger sind.
- Lassen Sie uns weitermachen. Um den Code auszuführen, müssen wir und alle, die damit arbeiten werden, eine Umgebung schaffen. Oft ist es so, dass auch diese aus bestimmten Gründen nicht hinterlassen wurde. Das kann ebenfalls zu einer kniffligen Aufgabe werden. Möchte man dafür wirklich Zeit aufwenden, nicht wahr?
- Wir trainieren ein Modell (zum Beispiel einen Fahrzeugdetektor). Wir erreichen den Punkt, an dem es ziemlich gut funktioniert – jetzt ist es an der Zeit, das Ergebnis zu speichern. Wir nennen es car_detection_v1.pb. Dann trainieren wir ein weiteres Modell – car_detection_v2.pb. Nach einiger Zeit bilden wir mit unseren Kollegen oder alleine noch mehr Modelle aus, wobei wir verschiedene Architekturen verwenden. Am Ende entsteht eine Menge an Artefakten, über die wir sorgfältig Informationen sammeln müssen (aber das machen wir später, denn wir haben derzeit wichtigere Dinge zu erledigen).
- Das war's! Wir haben ein Modell! Wir können mit dem Training des nächsten Modells beginnen, die Architektur für das Lösen einer neuen Aufgabe entwickeln oder vielleicht erst einmal eine Tasse Tee trinken? Aber wer wird es deployen?
Probleme identifizieren
Die Arbeit an einem Projekt oder Produkt ist das Ergebnis vieler Menschen. Mit der Zeit kommen und gehen diese Personen, die Anzahl der Projekte wächst und die Projekte selbst werden komplexer. In gewisser Weise werden die aus diesem beschriebenen Zyklus resultierenden Situationen (und nicht nur diese) in verschiedenen Kombinationen von Iteration zu Iteration auftreten. All dies führt zu Zeitverlust, Verwirrung, Nervosität, möglicherweise zu Unzufriedenheit beim Kunden und letztendlich zu entgangenen finanziellen Mitteln. Obwohl wir alle oft die gleichen Fehler machen, möchte ich doch glauben, dass niemand diese Erfahrungen immer wieder durchleben möchte.

Jetzt sind wir durch einen Entwicklungszyklus gegangen und sehen, dass es Probleme gibt, die gelöst werden müssen. Dafür ist es notwendig:
- die Ergebnisse der Arbeit bequem zu speichern;
- den Prozess der Einbindung neuer Mitarbeiter zu vereinfachen;
- den Prozess der Bereitstellung der Entwicklungsumgebung zu erleichtern;
- den Prozess der Versionierung von Modellen zu konfigurieren;
- eine bequeme Möglichkeit zur Validierung der Modelle zu haben;
- ein Tool zur Verwaltung des Zustands der Modelle zu finden;
- einen Weg zu finden, um Modelle in die Produktion zu bringen.
Es scheint, als müsste man einen Workflow entwickeln, der eine einfache und komfortable Verwaltung dieses Lebenszyklus ermöglicht? Diese Praxis wird als MLOps bezeichnet.
MLOps, oder DevOps für maschinelles Lernen, erlaubt es Teams von Data Scientists und IT-Spezialisten, zusammenzuarbeiten und die Entwicklung sowie Bereitstellung von Modellen durch Überwachung, Validierung und Managementsysteme für maschinelles Lernen zu beschleunigen.
Sie können , was die Leute von Google darüber denken. Aus dem Artikel geht hervor, dass MLOps ein recht umfangreiches Thema ist.
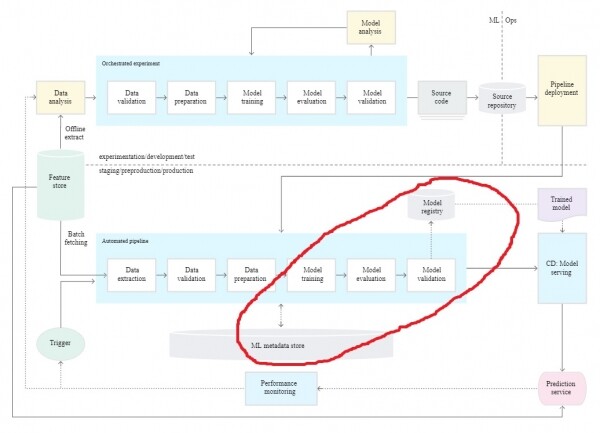
In meinem Artikel werde ich nur einen Teil des Prozesses beschreiben. Ich werde das Tool MLflow verwenden, da es sich um ein Open-Source-Projekt handelt, das nur einen kleinen Codeaufwand erfordert und eine Integration mit beliebten ML-Frameworks bietet. Sie können auch im Internet nach anderen Tools suchen, wie zum Beispiel Kubeflow, SageMaker, Trains usw., und vielleicht das passende für Ihre Anforderungen finden.
"Wir bauen" MLOps am Beispiel der Nutzung des Tools MLFlow
MLFlow ist eine Open-Source-Plattform zur Verwaltung des Lebenszyklus von ML-Modellen ().
MLflow umfasst vier Komponenten:
- MLflow Tracking — klärt Fragen zur Dokumentation von Ergebnissen und den Parametern, die zu diesen Ergebnissen führten;
- MLflow Project — ermöglicht es, Code zu verpacken und auf jeder Plattform wiederherzustellen;
- MLflow Models — ist zuständig für das Deployment von Modellen in die Produktion;
- MLflow Registry — erlaubt das Speichern von Modellen und die Verwaltung ihres Status in einem zentralen Speicher.
MLflow operiert mit zwei Entitäten:
- ein Run — ist der vollständige Trainingszyklus, einschließlich der Parameter und Metriken, die wir registrieren möchten;
- ein Experiment — ist das „Thema“, das die Runs verbindet.
Alle Schritte des Beispiels werden auf dem Betriebssystem Ubuntu 18.04 umgesetzt.
1. Server bereitstellen
Um unser Projekt einfach verwalten und alle benötigten Informationen erhalten zu können, stellen wir einen Server bereit. Der MLflow Tracking Server hat zwei Hauptkomponenten:
- Backend-Speicher — ist verantwortlich für die Speicherung von Informationen über registrierte Modelle (unterstützt 4 Datenbanken: mysql, mssql, sqlite und postgresql);
- Artifact Store — ist verantwortlich für die Speicherung von Artefakten (unterstützt 7 Speicheroptionen: Amazon S3, Azure Blob Storage, Google Cloud Storage, FTP-Server, SFTP-Server, NFS, HDFS).
Als Artifact Store Um es einfach zu halten, nehmen wir einen SFTP-Server.
- Gruppe erstellen
$ sudo groupadd sftpg - Einen Benutzer hinzufügen und ein Passwort festlegen
$ sudo useradd -g sftpg mlflowsftp $ sudo passwd mlflowsftp - Einige Zugriffsparameter anpassen
$ sudo mkdir -p /data/mlflowsftp/upload $ sudo chown -R root.sftpg /data/mlflowsftp $ sudo chown -R mlflowsftp.sftpg /data/mlflowsftp/upload - Einige Zeilen in /etc/ssh/sshd_config hinzufügen
Match Group sftpg ChrootDirectory /data/%u ForceCommand internal-sftp - Den Dienst neu starten
$ sudo systemctl restart sshd
Als Backend-Speicher Wir verwenden PostgreSQL.
$ sudo apt update
$ sudo apt-get install -y postgresql postgresql-contrib postgresql-server-dev-all
$ sudo apt install gcc
$ pip install psycopg2
$ sudo -u postgres -i
# Neuen Benutzer erstellen: mlflow_user
[postgres@user_name~]$ createuser --interactive -P
Benutzername für hinzuzufügenden Rolle: mlflow_user
Passwort für neue Rolle eingeben: mlflow
Erneut eingeben: mlflow
Soll die neue Rolle ein Superuser sein? (y/n) n
Soll die neue Rolle berechtigt sein, Datenbanken zu erstellen? (y/n) n
Soll die neue Rolle berechtigt sein, weitere Rollen zu erstellen? (y/n) n
# Datenbank mlflow_bd erstellen, die von mlflow_user verwaltet wird
$ createdb -O mlflow_user mlflow_dbFür den Betrieb des Servers müssen die folgenden Python-Pakete installiert werden (ich empfehle, eine separate virtuelle Umgebung zu erstellen):
pip install mlflow
pip install pysftpUnseren Server starten
$ mlflow server
--backend-store-uri postgresql://mlflow_user:mlflow@localhost/mlflow_db
--default-artifact-root sftp://mlflowsftp:mlflow@sftp_host/upload
--host server_host
--port server_port2. Tracking hinzufügen
Um sicherzustellen, dass die Ergebnisse unserer Trainings nicht verloren gehen, die zukünftigen Generationen von Entwicklern verstehen, was tatsächlich passiert ist, und die älteren Kollegen sowie Sie den Lernprozess entspannt analysieren können, müssen wir ein Tracking hinzufügen. Unter Tracking versteht man das Speichern von Parametern, Metriken, Artefakten und allen zusätzlichen Informationen zum Start des Trainings, in unserem Fall auf dem Server.
Als Beispiel habe ich ein kleines in Keras zur Segmentierung von allem, was im vorhanden ist, erstellt. Um das Tracking hinzuzufügen, habe ich die Datei mlflow_training.py erstellt.
Hier sind die Zeilen, in denen es am interessantesten wird:
def run(self, epochs, lr, experiment_name):
# Abrufen der ID des Experiments, Erstellen eines Experiments im Falle einer Abwesenheit
remote_experiment_id = self.remote_server.get_experiment_id(name=experiment_name)
# Ein "Run" erstellen und dessen ID abrufen
remote_run_id = self.remote_server.get_run_id(remote_experiment_id)
# Angeben, dass wir die Ergebnisse auf einem Remote-Server speichern möchten
mlflow.set_tracking_uri(self.tracking_uri)
mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_id=remote_run_id, nested=False):
mlflow.keras.autolog()
self.train_pipeline.train(lr=lr, epochs=epochs)
try:
self.log_tags_and_params(remote_run_id)
except mlflow.exceptions.RestException as e:
print(e)Hier ist self.remote_server eine kleine Wrapper-Funktion über die Methoden mlflow.tracking.MlflowClient (die ich zur Vereinfachung erstellt habe), mit denen ich Experimente und Ausführungen auf dem Server erstelle. Danach gebe ich an, wohin die Ergebnisse der Ausführung geleitet werden sollen (mlflow.set_tracking_uri(self.tracking_uri)). Ich aktiviere das automatische Logging mit mlflow.keras.autolog(). Aktuell unterstützt MLflow Tracking das automatische Logging für TensorFlow, Keras, Gluon XGBoost, LightGBM und Spark. Falls Ihr Framework oder Ihre Bibliothek nicht aufgeführt ist, können Sie immer noch explizit loggen. Wir starten das Training. Wir registrieren Tags und Eingabeparameter auf dem Remote-Server.
Ein paar Zeilen, und Sie haben, wie alle anderen, Zugang zu Informationen über alle Ausführungen. Cool, oder?
3. Projekt einrichten
Jetzt machen wir es ganz einfach, das Projekt zu starten. Dazu fügen wir die Datei MLproject und conda.yaml in das Wurzelverzeichnis des Projekts ein.
MLproject
name: flow_segmentation
conda_env: conda.yaml
entry_points:
main:
parameters:
categories: {help: 'Liste der Kategorien aus dem COCO-Datensatz'}
epochs: {type: int, help: 'Anzahl der Epochen im Training'}
lr: {type: float, default: 0.001, help: 'Lernrate'}
batch_size: {type: int, default: 8}
model_name: {type: str, default: 'Unet', help: 'Unet, PSPNet, Linknet, FPN'}
backbone_name: {type: str, default: 'resnet18', help: 'z.B. resnet18, resnet50, mobilenetv2 ...'}
tracking_uri: {type: str, help: 'die Serveradresse'}
experiment_name: {type: str, default: 'Mein_Experiment', help: 'Name des Remote- und Lokalen Experiments'}
command: "python mlflow_training.py
--epochs={epochs}
--categories={categories}
--lr={lr}
--tracking_uri={tracking_uri}
--model_name={model_name}
--backbone_name={backbone_name}
--batch_size={batch_size}
--experiment_name={experiment_name}"Das MLflow-Projekt hat mehrere Eigenschaften:
- Name — der Name Ihres Projekts;
- Umgebung — in meinem Fall weist conda_env darauf hin, dass Anaconda zum Ausführen verwendet wird und die Abhängigkeiten in der Datei conda.yaml beschrieben sind;
- Entry Points — gibt an, welche Dateien und mit welchen Parametern wir ausführen können (alle Parameter werden beim Start des Trainings automatisch protokolliert)
conda.yaml
name: flow_segmentation
channels:
- defaults
- anaconda
dependencies:
- python==3.7
- pip:
- mlflow==1.8.0
- pysftp==0.2.9
- Cython==0.29.19
- numpy==1.18.4
- pycocotools==2.0.0
- requests==2.23.0
- matplotlib==3.2.1
- segmentation-models==1.0.1
- Keras==2.3.1
- imgaug==0.4.0
- tqdm==4.46.0
- tensorflow-gpu==1.14.0Sie können Docker als Ausführungsumgebung verwenden. Weitere Informationen finden Sie bei .
4. Wir starten das Training
Klonen Sie das Projekt und wechseln Sie in das Projektverzeichnis:
git clone https://github.com/simbakot/mlflow_example.git
cd mlflow_example/Um das Programm zu starten, müssen Sie die Bibliotheken installieren.
pip install mlflow
pip install pysftpDa ich in diesem Beispiel conda_env verwende, sollte Anaconda auf Ihrem Computer installiert sein (dies kann jedoch umgangen werden, indem Sie alle notwendigen Pakete manuell installieren und mit den Startparametern experimentieren).
Alle vorbereitenden Schritte sind abgeschlossen und wir können mit dem Training beginnen. Vom Stammverzeichnis des Projekts:
$ mlflow run -P epochs=10 -P categories=cat,dog -P tracking_uri=http://server_host:server_port .Nach der Eingabe des Befehls wird automatisch eine conda-Umgebung erstellt und das Training gestartet.
Im obigen Beispiel habe ich die Anzahl der Epochen für das Training sowie die Kategorien, in die wir segmentieren möchten, übergeben (die vollständige Liste können Sie sehen ) und die Adresse unseres Remote-Servers.
Die vollständige Liste der verfügbaren Parameter finden Sie in der Datei MLproject.
5. Wir bewerten die Ergebnisse des Trainings
Nach Abschluss des Trainings können wir in unserem Browser auf die Adresse unseres Servers zugreifen
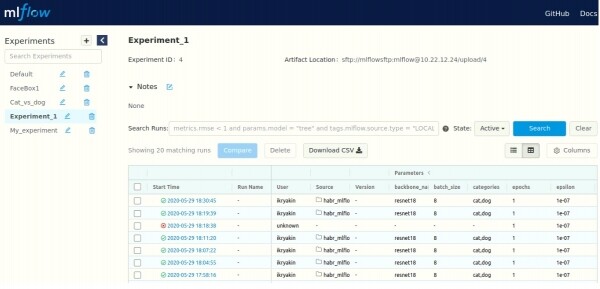
Hier sehen wir eine Liste aller Experimente (oben links) sowie Informationen zu den Läufen (in der Mitte). Wir können detailliertere Informationen (Parameter, Metriken, Artefakte und zusätzliche Informationen) für jeden Lauf einsehen.
Für jede Metrik können wir die Historie der Änderungen beobachten.
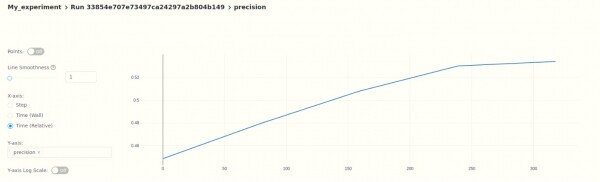
Das heißt, momentan können wir die Ergebnisse im "manuellen" Modus analysieren. Sie können auch die automatische Validierung mit der MLflow API einrichten.
6. Wir registrieren das Modell
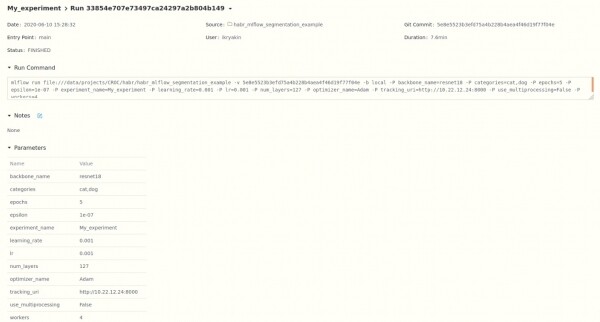
Nachdem wir unser Modell analysiert haben und sicher sind, dass es einsatzbereit ist, beginnen wir mit seiner Registrierung, indem wir den gewünschten Lauf (wie im vorherigen Punkt gezeigt) auswählen und nach unten scrollen.
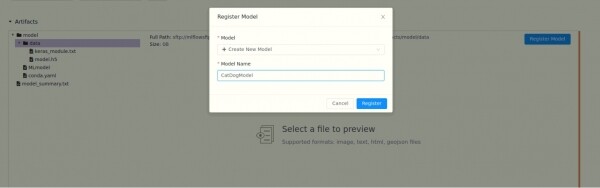
Nachdem wir unserer Modell einen Namen gegeben haben, erhält es eine Version. Bei der Speicherung eines anderen Modells mit diesem Namen wird die Version automatisch erhöht.
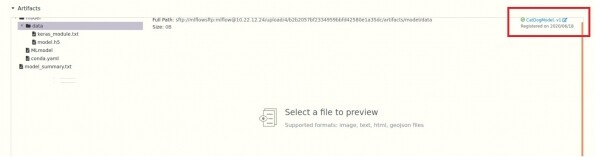
Für jedes Modell können wir eine Beschreibung hinzufügen und einen der drei Zustände (Staging, Production, Archived) auswählen. Anschließend können wir über die API auf diese Zustände zugreifen, was zusammen mit der Versionierung zusätzliche Flexibilität bietet.

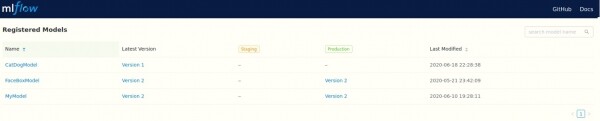
Wir haben auch einen einfachen Zugriff auf alle Modelle
und deren Versionen
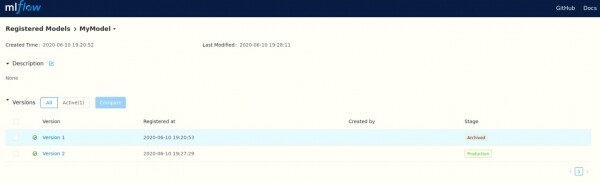
Wie im vorherigen Punkt können alle Operationen über die API ausgeführt werden.
7. Modell bereitstellen
In diesem Schritt haben wir bereits ein trainiertes (Keras) Modell. Hier ein Beispiel, wie man es nutzen kann:
class SegmentationModel:
def __init__(self, tracking_uri, model_name):
self.registry = RemoteRegistry(tracking_uri=tracking_uri)
self.model_name = model_name
self.model = self.build_model(model_name)
def get_latest_model(self, model_name):
registered_models = self.registry.get_registered_model(model_name)
last_model = self.registry.get_last_model(registered_models)
local_path = self.registry.download_artifact(last_model.run_id, 'model', './')
return local_path
def build_model(self, model_name):
local_path = self.get_latest_model(model_name)
return mlflow.keras.load_model(local_path)
def predict(self, image):
image = self.preprocess(image)
result = self.model.predict(image)
return self.postprocess(result)
def preprocess(self, image):
image = cv2.resize(image, (256, 256))
image = image / 255.
image = np.expand_dims(image, 0)
return image
def postprocess(self, result):
return resultHier ist self.registry erneut eine kleine Wrapper über mlflow.tracking.MlflowClient, um die Nutzung zu erleichtern. Das Ziel ist, dass ich auf einen entfernten Server zugreife und dort nach einem Modell mit dem angegebenen Namen suche, und zwar nach der neuesten Produktionsversion. Anschließend lade ich das Artefakt lokal in den Ordner ./model herunter und lade das Modell aus diesem Verzeichnis mit mlflow.keras.load_model(local_path). Jetzt können wir unser Modell nutzen. CV (ML) Entwickler können sich in Ruhe um die Verbesserung des Modells kümmern und neue Versionen veröffentlichen.
Zusammenfassung
Ich habe ein System entwickelt, das Folgendes ermöglicht:
- zentralisierte Speicherung von Informationen über ML-Modelle, Schulungsverlauf und -ergebnisse;
- schnelles Bereitstellen einer Entwicklungsumgebung;
- Überwachung und Analyse des Fortschritts bei der Modellarbeit;
- einfaches Versionieren und Verwalten des Modellausstands;
- müheloses Bereitstellen der erhaltenen Modelle.
Dieses Beispiel ist fiktiv und dient als Ausgangspunkt für den Aufbau Ihres eigenen Systems, das möglicherweise die Automatisierung der Ergebnisbewertung und die Registrierung von Modellen (Punkt 5 und Punkt 6) umfasst. Vielleicht integrieren Sie auch die Versionierung von Datensätzen oder noch andere Elemente? Ich wollte vermitteln, dass Sie im Allgemeinen MLOps benötigen; MLflow ist nur ein Mittel zum Zweck.
Welche Probleme habe ich nicht dargestellt, mit denen Sie konfrontiert waren?
Was würden Sie dem System hinzufügen, um Ihre Anforderungen zu erfüllen?
Welche Werkzeuge und Ansätze nutzen Sie, um alle oder einige Probleme zu lösen?
P.S. Hier sind ein paar Links:
GitHub-Projekt —
MLflow —
Meine Arbeits-E-Mail für Fragen — ikryakin@croc.ru
In unserem Unternehmen finden regelmäßig verschiedene Veranstaltungen für IT-Fachleute statt. Zum Beispiel wird am 8. Juli um 19:00 Uhr MESZ ein Meetup zu CV im Online-Format stattfinden. Wenn es Sie interessiert, können Sie teilnehmen, die Registrierung ist offen. .
Quelle: habr.com
