

Im Jahr 2018 trat das Konzept MLOps in Fachkreisen und auf Konferenzen zum Thema KI auf, das sich schnell in der Branche etablierte und mittlerweile als eigenständiges Feld weiterentwickelt. MLOps könnte in Zukunft eines der gefragtesten Bereiche in der IT werden. Was genau ist das und wie funktioniert es? Hier erfahren Sie mehr.

Was ist MLOps
MLOps (die Kombination von Technologien und Prozessen des maschinellen Lernens sowie Ansätzen zur Implementierung entwickelter Modelle in Geschäftsprozesse) ist eine neue Art der Zusammenarbeit zwischen Geschäftsvertretern, Wissenschaftlern, Mathematikern, Experten im Bereich maschinelles Lernen und IT-Ingenieuren bei der Schaffung von KI-Systemen.
Mit anderen Worten, es ist ein Weg, Methoden und Technologien des maschinellen Lernens in ein nützliches Werkzeug für die Lösung von Geschäftsproblemen umzuwandeln.
Es ist wichtig zu verstehen, dass die Produktivitätskette lange vor der Modellentwicklung beginnt. Der erste Schritt besteht darin, die Geschäftsziele zu definieren, Hypothesen über den Wert zu formulieren, den man aus den Daten ziehen kann, sowie Geschäftsideen zu entwickeln, wie dieser Wert angewendet werden kann.
Der Begriff MLOps entstand als Analogie zum Konzept von DevOps, angewendet auf Modelle und Technologien des maschinellen Lernens. DevOps ist ein Ansatz für die Softwareentwicklung, der es ermöglicht, die Geschwindigkeit der Implementierung einzelner Änderungen zu erhöhen, während Flexibilität und Zuverlässigkeit durch verschiedene Methoden erhalten bleiben. Dazu gehören kontinuierliche Entwicklung, Aufteilung von Funktionen in unabhängige Mikrodienste, automatisierte Tests und Deployment einzelner Änderungen, globales Monitoring der Betriebsbereitschaft sowie ein System zur schnellen Reaktion auf identifizierte Ausfälle.
DevOps hat den Lebenszyklus der Softwareentwicklung definiert, und in der Community von Fachleuten entstand die Idee, dieselbe Methode auf Big Data anzuwenden. DataOps ist der Versuch, diese Methodik anzupassen und zu erweitern, um den Besonderheiten der Speicherung, Übertragung und Verarbeitung großer Datenmengen in verschiedenen, miteinander interagierenden Plattformen Rechnung zu tragen.
Mit der wachsenden kritischen Masse an Machine-Learning-Modellen, die in die Geschäftsprozesse von Unternehmen integriert wurden, zeigt sich eine starke Ähnlichkeit zwischen dem Lebenszyklus von mathematischen Modellen des maschinellen Lernens und dem Lebenszyklus von Software. Der einzige Unterschied besteht darin, dass die Algorithmen der Modelle mithilfe von Werkzeugen und Methoden des maschinellen Lernens erstellt werden. Daher entstand natürlich die Idee, bereits bekannte Ansätze der Softwareentwicklung auf Machine-Learning-Modelle anzuwenden und anzupassen. Im Lebenszyklus von Modellen des maschinellen Lernens können folgende Schlüsselphasen unterschieden werden:
- Definition der Geschäftsidee;
- Modelltraining;
- Testen und Implementieren des Modells in den Geschäftsprozess;
- Betrieb des Modells.
Wenn während des Betriebs die Notwendigkeit besteht, das Modell mit neuen Daten zu ändern oder nachzutrainieren, beginnt der Zyklus von neuem – das Modell wird überarbeitet, getestet und eine neue Version wird bereitgestellt.
Abschweifung. Warum neu trainieren, statt umtrainieren? Der Begriff "Modell-Neutrainierung" hat zwei Bedeutungen: Unter Fachleuten beschreibt er einen Mangel des Modells, bei dem das Modell gut vorhersagen kann, tatsächlich den prognostizierten Parameter in der Trainingsdatenmenge wiederholt, jedoch viel schlechter bei externen Datensätzen funktioniert. Natürlich ist ein solches Modell fehlerhaft, da dieser Mangel seine Anwendung einschränkt.
Im Lebenszyklus erscheint der Einsatz von DevOps-Tools sinnvoll: automatisiertes Testen, Deployment und Monitoring sowie die Gestaltung der Modellerstellung in Form von separaten Mikrodiensten. Es gibt jedoch auch eine Reihe von Besonderheiten, die die direkte Anwendung dieser Tools ohne zusätzliche ML-Integrationen behindern.
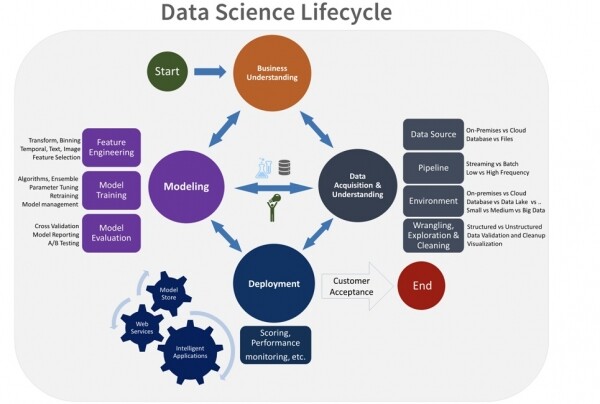
Wie man Modelle zum Laufen bringt und Gewinn generiert
Als Beispiel, an dem wir den MLOps-Ansatz demonstrieren, nehmen wir die klassische Aufgabe der Automatisierung eines Support-Chats für Bank- (oder jedes andere) Produkt. Normalerweise sieht der Geschäftsprozess im Support-Chat folgendermaßen aus: Der Kunde gibt eine Nachricht mit einer Frage ein und erhält eine Antwort von einem Spezialisten auf Basis eines zuvor definierten Dialogbaums. Die Aufgabe der Automatisierung eines solchen Chats wird in der Regel durch fachlich festgelegte Regelsets gelöst, die sehr aufwendig in der Entwicklung und Wartung sind. Die Effizienz einer solchen Automatisierung kann, abhängig von der Komplexität der Aufgabe, 20–30 % betragen. Natürlich kommt die Idee auf, dass die Implementierung eines Moduls für künstliche Intelligenz — ein Modell, das mithilfe von maschinellem Lernen entwickelt wurde — vorteilhafter ist, das:
- in der Lage ist, ohne die Beteiligung eines Operators eine größere Anzahl von Anfragen zu bearbeiten (je nach Thema kann die Effizienz in einigen Fällen 70–80 % erreichen);
- Sie passt besser an nicht standardisierte Formulierungen im Dialog an – sie kann die Absicht erkennen und das tatsächliche Bedürfnis des Nutzers bei unscharfen Anfragen bestimmen;
- sie kann erkennen, wann die Antwort des Modells angemessen ist und wann es Zweifel an dieser "Bewusstheit" der Antwort gibt, sodass zusätzliche Klarstellungsfragen gestellt oder auf einen Operator umgeschaltet werden müssen;
- kann automatisiert weitergebildet werden (anstatt dass eine Gruppe von Entwicklern ständig Szenarien für Antworten anpasst und korrigiert, wird das Modell von einem Data-Science-Spezialisten unter Verwendung entsprechender Machine-Learning-Bibliotheken weitergebildet).
Wie bringt man ein so fortschrittliches Modell zum Laufen?
Wie bei jeder anderen Aufgabe auch, muss man vor der Entwicklung eines solchen Moduls den Geschäftsprozess bestimmen und die genaue Aufgabe formell beschreiben, die wir mit der Methode des maschinellen Lernens lösen wollen. An diesem Punkt beginnt der Operationalisierungsprozess, der in der Abkürzung Ops dargestellt wird.
Im nächsten Schritt überprüft ein Data Science-Spezialist in Zusammenarbeit mit einem Datentechniker die Verfügbarkeit und Angemessenheit der Daten sowie die Geschäftshypothese zur Funktionalität der Geschäftsidee. Hierbei wird ein Prototyp des Modells entwickelt und dessen tatsächliche Wirksamkeit getestet. Erst nach Bestätigung durch das Unternehmen kann der Übergang von der Modellentwicklung zur Integration in die Systeme, die spezifische Geschäftsprozesse ausführen, begonnen werden. Eine durchgängige Planung der Implementierung und ein tiefes Verständnis darüber, wie das Modell in jedem Schritt genutzt werden wird und welcher wirtschaftliche Nutzen daraus gezogen werden kann, sind entscheidende Faktoren bei der Einführung von MLOps-Ansätzen in die technologische Landschaft des Unternehmens.
Mit der Entwicklung der KI-Technologien wächst die Anzahl und Vielfalt von Aufgaben, die durch maschinelles Lernen gelöst werden können, exponentiell. Jeder dieser Geschäftsprozesse führt zu Einsparungen für Unternehmen durch die Automatisierung von Arbeitsplätzen in Massenschnittstellen (Callcenter, Überprüfung und Sortierung von Dokumenten usw.), zur Erweiterung der Kundenbasis durch die Einführung neuer attraktiver und benutzerfreundlicher Funktionen, zur Einsparung von Ressourcen durch deren optimale Nutzung und Umverteilung sowie zu vielen weiteren Vorteilen. Letztendlich ist jeder Prozess darauf ausgerichtet, Werte zu schaffen und sollte entsprechend einen bestimmten wirtschaftlichen Nutzen generieren. Dabei ist es äußerst wichtig, die Geschäftsidee klar zu formulieren und den voraussichtlichen Gewinn aus der Implementierung des Modells im Rahmen der Wertschöpfungsstruktur des Unternehmens zu berechnen. Es gibt Situationen, in denen die Implementierung eines Modells sich nicht rentiert und die Zeit, die von Machine Learning-Experten aufgewendet wird, wesentlich teurer ist als das Gehalt eines Operators, der diese Aufgabe bearbeitet. Daher ist es notwendig, solche Fälle frühzeitig bei der Erstellung von KI-Systemen zu identifizieren.
Profitabel wird das Modell erst, wenn die Geschäftsziele im MLOps-Prozess klar formuliert, Prioritäten gesetzt und der Implementierungsprozess der Modelle in das System bereits in den frühen Entwicklungsphasen definiert wurde.
Neuer Prozess – neue Herausforderungen
Eine umfassende Antwort auf die grundlegende Frage, wie gut ML-Modelle zur Lösung geschäftlicher Herausforderungen geeignet sind, und die weit verbreitete Vertrauensfrage gegenüber KI sind wesentliche Herausforderungen bei der Entwicklung und Einführung von MLOps-Ansätzen. Zunächst ist die Geschäftswelt skeptisch gegenüber der Implementierung von maschinellem Lernen in Prozesse – es ist schwierig, sich auf Modelle zu verlassen, wenn zuvor in der Regel menschliche Arbeit geleistet wurde. Für Unternehmen erscheinen diese Programme als "Black Box", deren Relevanz noch nachgewiesen werden muss. Darüber hinaus gelten in der Bankenbranche, im Telekommunikationsgeschäft und in anderen Bereichen strenge Anforderungen der staatlichen Aufsichtsbehörden. Alle Systeme und Algorithmen, die in Bankprozesse integriert sind, unterliegen einer Prüfung. Um diese Herausforderung zu meistern und sowohl dem Geschäft als auch den Behörden die Angemessenheit und Richtigkeit der Antworten der KI nachzuweisen, werden Monitoring-Tools zusammen mit dem Modell implementiert. Zudem gibt es ein Verfahren zur unabhängigen Validierung, das für regulatorische Modelle obligatorisch ist und den Anforderungen der Zentralbank entspricht. Eine unabhängige Expertengruppe führt eine Prüfung der Ergebnisse durch, die das Modell unter Berücksichtigung der Eingangsdaten erzielt hat.
Der zweite Schritt besteht darin, die Modellrisiken bei der Implementierung von Machine-Learning-Modellen zu bewerten und zu berücksichtigen. Wenn selbst ein Mensch nicht mit absoluter Sicherheit sagen kann, ob das Kleid weiß oder blau war, dann hat auch Künstliche Intelligenz das Recht auf Fehler. Zudem sollte man beachten, dass sich die Daten im Laufe der Zeit ändern können und die Modelle kontinuierlich weitertrainiert werden müssen, um ausreichend präzise Ergebnisse zu liefern. Um sicherzustellen, dass der Geschäftsprozess nicht leidet, ist es notwendig, die Modellrisiken zu steuern und die Leistung des Modells regelmäßig zu überwachen, indem man es mit neuen Daten weitertrainiert.

Nach der ersten Phase des Misstrauens zeigt sich jedoch ein gegenteiliger Effekt. Je mehr Modelle erfolgreich in Prozesse integriert werden, desto größer wird das Interesse des Unternehmens an der Nutzung von Künstlicher Intelligenz – es ergeben sich immer wieder neue Herausforderungen, die mit Methoden des maschinellen Lernens gelöst werden können. Jede Herausforderung löst einen umfangreichen Prozess aus, der verschiedene Kompetenzen erfordert:
- Dateningenieure bereiten Daten vor und verarbeiten sie;
- Datenwissenschaftler wenden Machine-Learning-Tools an und entwickeln das Modell;
- IT integriert das Modell in das System;
- Der ML-Ingenieur bestimmt, wie dieses Modell korrekt in den Prozess integriert werden kann, welche IT-Tools je nach Anforderungen an den Einsatzmodus unter Berücksichtigung des Anfragevolumens, der Antwortzeiten usw. verwendet werden sollten.
- Der ML-Architekt plant, wie das Softwareprodukt physisch in einem industriellen System umgesetzt werden kann.
Der gesamte Prozess erfordert eine große Anzahl hochqualifizierter Fachkräfte. Zu einem bestimmten Zeitpunkt in der Entwicklung und dem Einsatz von ML-Modellen in Geschäftsprozesse wird offensichtlich, dass es kostspielig und ineffizient ist, die Anzahl der Spezialisten linear im Verhältnis zum Anstieg der Aufgaben zu skalieren. Daher stellt sich die Frage der Automatisierung des MLOps-Prozesses – die Definition von mehreren Standardklassen von Aufgaben im maschinellen Lernen, die Entwicklung standardisierter Datenverarbeitungs-Pipelines und das Fein-Tuning von Modellen. Um solche Aufgaben ideal zu lösen, sind Fachleute erforderlich, die sowohl in den Bereichen Big Data, Data Science, DevOps als auch IT gleich gut kompetent sind. Daher ist das größte Problem in der Data Science-Branche und die größte Herausforderung bei der Organisation von MLOps-Prozessen der Mangel an dieser Kompetenz auf dem aktuellen Arbeitsmarkt. Fachkräfte, die diesen Anforderungen entsprechen, sind derzeit auf dem Arbeitsmarkt rar und werden hoch geschätzt.
Zu den Kompetenzen
In der Theorie können alle MLOps-Aufgaben mit klassischen DevOps-Tools gelöst werden, ohne auf eine spezialisierte Rollenmodell-Erweiterung zurückgreifen zu müssen. Wie bereits erwähnt, muss ein Data Scientist jedoch nicht nur Mathematiker und Datenanalyse-Experte sein, sondern auch ein echter Guru des gesamten Pipelines – er ist verantwortlich für die Entwicklung der Architektur, Programmierung von Modellen in mehreren Sprachen je nach Architektur, Datenaufbereitung und das Deployment der Anwendung selbst. Dennoch nimmt die Erstellung der technologischen Infrastruktur, die im durchgängigen MLOps-Prozess realisiert wird, bis zu 80 % des Arbeitsaufwands in Anspruch. Das bedeutet, dass ein qualifizierter Mathematiker, wie es ein guter Data Scientist ist, nur 20 % seiner Zeit seiner Spezialität widmen wird. Daher wird die klare Trennung der Rollen der Fachleute, die den Prozess der Implementierung von maschinellen Lernmodellen durchführen, zu einer lebenswichtigen Notwendigkeit.
Wie detailliert die Rollen abgegrenzt werden sollten, hängt von der Größe des Unternehmens ab. Es ist etwas anderes, wenn in einem Start-up ein Spezialist als Alleskönner agiert – vom Ingenieur über den Architekten bis hin zum DevOps-Profi. Ganz anders ist es, wenn in einem großen Unternehmen alle Entwicklungsprozesse auf mehrere hochqualifizierte Data Science Spezialisten konzentriert sind, während Programmierer oder Datenbankexperten – vielfach verbreitete und kostengünstigere Fachkräfte auf dem Arbeitsmarkt – einen Großteil der Routineaufgaben übernehmen können.
Daher hängt die Frage, wo die Grenze bei der Auswahl der Fachkräfte für die Sicherstellung des MLOps-Prozesses verläuft und wie der Prozess der Operationalisierung der entwickelten Modelle organisiert ist, direkt von der Geschwindigkeit und Qualität der entwickelten Modelle, der Produktivität des Teams und dem Mikroklima innerhalb des Teams ab.
Was unser Team bereits erreicht hat
Wir haben vor nicht allzu langer Zeit begonnen, Kompetenzen und Prozesse im Bereich MLOps aufzubauen. Doch bereits jetzt befinden sich unsere Projekte zum Lebenszyklusmanagement von Modellen und zur Bereitstellung von Modellen als Service in der MVP-Testphase.
Wir haben auch die optimale Kompetenzstruktur und organisatorische Struktur für große Unternehmen festgelegt, die die Interaktion zwischen allen Beteiligten des Prozesses regelt. Agile-Teams wurden eingerichtet, um Aufgaben für das gesamte Spektrum der Geschäftskunden zu lösen, und ein Prozess zur Zusammenarbeit mit den Projektteams zur Erstellung von Plattformen und Infrastruktur, die das Fundament des entstehenden MLOps-Gebäudes bilden, wurde organisiert.
Fragen für die Zukunft
MLOps ist ein sich entwickelndes Feld, das einen Mangel an Kompetenzen erlebt und in Zukunft an Bedeutung gewinnen wird. Bis dahin ist es am besten, von den Errungenschaften und Praktiken des DevOps auszugehen. Das Hauptziel von MLOps besteht darin, ML-Modelle effektiver zur Lösung von Geschäftsproblemen zu nutzen. Dabei treten jedoch zahlreiche Fragen auf:
- Wie kann die Zeit bis zur Einführung von Modellen in die Produktion verkürzt werden?
- Wie können bürokratische Reibungsverluste zwischen Teams mit unterschiedlichen Kompetenzen reduziert und die Zusammenarbeit gefördert werden?
- Wie lässt sich das Tracking von Modellen, das Versionsmanagement und ein effizientes Monitoring organisieren?
- Wie kann ein wirklich zirkulärer Lebenszyklus für moderne ML-Modelle geschaffen werden?
- Wie standardisiert man den Prozess des maschinellen Lernens?
Die Antworten auf diese Fragen werden entscheidend dafür sein, wie schnell MLOps sein volles Potenzial entfalten kann.
Quelle: habr.com
