

In diesem Artikel werde ich über eine Situation berichten, die kürzlich mit einem unserer VPS-Cloud-Server auftrat und mich mehrere Stunden lang ratlos machte. Ich beschäftige mich seit etwa 15 Jahren mit der Konfiguration und Fehlersuche von Linux-Servern, aber dieser Fall passt überhaupt nicht in meine Erfahrung – ich machte mehrere falsche Annahmen und verfiel leicht in Verzweiflung, bevor ich die Ursache des Problems korrekt identifizieren und lösen konnte.
Präambel
Wir betreiben eine mittelgroße Cloud, die auf Standard-Servern mit folgender Konfiguration aufgebaut ist – 32 Kerne, 256 GB RAM und einem NVMe-SSD Intel P4500 mit einer Größe von 4 TB. Wir schätzen diese Konfiguration sehr, da sie es uns ermöglicht, uns keine Gedanken über IO-Engpässe machen zu müssen und eine angemessene Beschränkung auf der Ebene der Instanztypen (VMs) zu gewährleisten. Da das NVMe Intel eine beeindruckende Leistung bietet, können wir gleichzeitig sowohl vollständige IOPS für die Maschinen bereitstellen als auch das Storage-Backup auf dem Backup-Server bei null IOWAIT durchführen.
Wir gehören zu den traditionellen Anbietern, die keine hyperkonvergenten SDNs und andere modischen, trendy Dinge für die Speicherung von VM-Volumes verwenden. Wir sind der Meinung, dass einfachere Systeme auch einfacher zu troubleshoot sind, wenn der 'Hauptguru in die Berge gefahren ist'. Daher speichern wir VM-Volumes im QCOW2-Format auf XFS oder EXT4, die über LVM2 bereitgestellt werden.
Die Verwendung von QCOW2 wird auch durch das Produkt erforderlich, das wir für die Orchestrierung nutzen — Apache CloudStack.
Für die Durchführung von Backups erstellen wir ein vollständiges Image des Volumes als Snapshot von LVM2 (ja, wir wissen, dass LVM2-Snapshots träge sind, aber Intel P4500 hilft uns hier). Wir führen lvmcreate -s .. und mit Hilfe von dd senden wir die Sicherung an einen Remote-Server mit ZFS-Speicher. Hier sind wir dennoch etwas progressiv — ZFS kann Daten komprimiert speichern, und wir können sie schnell mit D oder einzelne VM-Volumes mit mount -o loop ....
Natürlich könnte man auch kein vollständiges Image des LVM2-Volumes aufnehmen und das Dateisystem im
RO-Modus einhängen.und kopieren die QCOW2-Images selbst, jedoch haben wir festgestellt, dass XFS dadurch Probleme bekam, und zwar nicht sofort, sondern unvorhersehbar. Wir mögen es gar nicht, wenn Hypervisor-Hosts plötzlich an Wochenenden, nachts oder an Feiertagen wegen Fehlern "einfrieren", die unklar sind, wann sie auftreten werden. Daher verwenden wir für XFS keine Snapshot-Montage im ModusRO-Modus einhängen.zum Extrahieren von Volumes, sondern kopieren einfach das gesamte LVM2-Volume.
Die Backup-Geschwindigkeit auf dem Backup-Server wird in unserem Fall durch die Leistungsfähigkeit des Backup-Servers bestimmt, die etwa 600-800 MB/s für nicht komprimierbare Daten beträgt, der nächste Engpass ist die 10Gbit/s-Verbindung, mit der der Backup-Server an den Cluster angeschlossen ist.
Dabei werden auf einen Backup-Server gleichzeitig die Backups von 8 Server Hypervisoren hochgeladen. So verhindern die langsameren Disk- und Netzwerksysteme des Backup-Servers eine Überlastung der Disk-Systeme der Hypervisor-Hosts, da sie einfach nicht in der Lage sind, beispielsweise 8 GB/s zu verarbeiten, die die Hypervisor-Hosts problemlos liefern können.
Der oben beschriebene Kopiervorgang ist entscheidend für die weitere Erzählung, einschließlich Details wie der Verwendung des schnellen Intel P4500 Speichers, NFS und wahrscheinlich auch ZFS.
Die Geschichte über das Backup
Jeder Hypervisor-Knoten verfügt über eine kleine SWAP-Partition mit 8 GB, und der Hypervisor-Knoten wird mithilfe von D einem Basispunkt-Image bereitgestellt. Für den System-Volumes auf den Servern verwenden wir 2xSATA SSD RAID1 oder 2xSAS HDD RAID1 auf einem LSI- oder HP-Hardware-Controller. Im Grunde ist es uns egal, was darin ist, da das System-Volume im "fast readonly"-Modus arbeitet, außer für SWAP. Und da wir viel RAM auf dem Server haben, der zu 30-40 % frei ist, denken wir nicht an SWAP.
Der Prozess der Erstellung eines Backups. Diese Aufgabe sieht ungefähr so aus:
#!/bin/bash
mkdir -p /mnt/backups/volumes
DIR=/mnt/images-snap
VOL=images/volume
DATE=$(date "+%d")
HOSTNAME=$(hostname)
lvcreate -s -n $VOL-snap -l100%FREE $VOL
ionice -c3 dd iflag=direct if=/dev/$VOL-snap bs=1M of=/mnt/backups/volumes/$HOSTNAME-$DATE.raw
lvremove -f $VOL-snapBitte beachten Sie ionice -c3, tatsächlich ist dieses Tool für NVMe-Geräte völlig nutzlos, da der IO-Scheduler für sie festgelegt ist als:
cat /sys/block/nvme0n1/queue/scheduler
[none] Es gibt jedoch eine Reihe von Legacy-Knoten mit herkömmlichen SSD-RAIDs, für die dies relevant ist, und deshalb wird IST-Zustand. Im Grunde ist dies ein interessanter Stück Code, der die Vergeblichkeit erklärt ionice bei dieser Konfiguration.
Beachten Sie die Flagge iflag=direct für D. Wir verwenden Direct I/O, um den Puffer-Cache zu umgehen und um unnötige IO-Pufferspeicherwechsel während des Lesens zu vermeiden. Allerdings oflag=direct tun wir dies nicht, da wir auf Leistungsprobleme mit ZFS gestoßen sind, wenn es verwendet wird.
Dieses Schema nutzen wir seit mehreren Jahren erfolgreich ohne Probleme.
Und dann begann es… Wir entdeckten, dass für einen der Knoten das Backup nicht mehr durchgeführt wurde, während das vorherige mit monströsen IOWAIT von fast 50% ausgeführt wurde. Als wir versuchten zu verstehen, warum das Kopieren nicht funktionierte, stießen wir auf das Phänomen:
Volume-Gruppe "images" nicht gefundenWir fingen an, über das "Ende von Intel P4500" nachzudenken, aber bevor wir den Server zum Austausch des Speichermediums ausschalten konnten, mussten wir dennoch ein Backup durchführen. Wir haben LVM2 mithilfe der Wiederherstellung von Metadaten aus dem LVM2-Backup repariert:
vgcfgrestore imagesWir haben das Backup gestartet und sahen folgendes Bild:
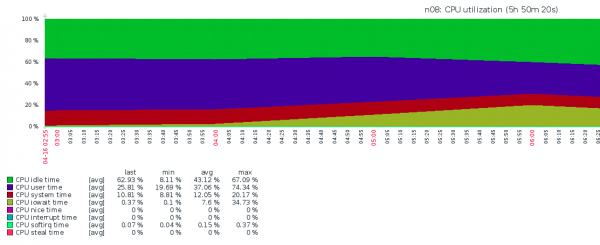
Wir waren wieder sehr traurig – es war klar, dass so nicht weitergemacht werden konnte, da alle VPS betroffen wären, was bedeutete, dass auch wir leiden würden. Was passiert war, war völlig unklar – iostat zeigte mickrige IOPS und extrem hohe IOWAIT. Es gab keine andere Idee als "Lass uns NVMe ersetzen", aber rechtzeitig kam die Erleuchtung.
Schritt-für-Schritt-Analyse der Situation
Historisches Protokoll. Einige Tage zuvor war es erforderlich, auf diesem Server eine große VPS mit 128 GB RAM zu erstellen. Der Speicher schien ausreichend, jedoch wurden zur Sicherheit weitere 32 GB für den Swap-Bereich bereitgestellt. Die VPS wurde erstellt, erfüllte erfolgreich ihre Aufgabe und der Vorfall wurde vergessen, während der SWAP-Bereich blieb.
Konfigurationsmerkmale. Für alle Cloud-Server wurde der Parameter vm.swappiness auf den Standardwert gesetzt 60. Der SWAP wurde auf einem SAS HDD RAID1 erstellt.
Was passierte (aus Sicht der Redaktion). Bei der Sicherung D wurden viele Schreibdaten erstellt, die in RAM-Puffern gespeichert wurden, bevor sie in NFS geschrieben wurden. Der Systemkernel, basierend auf der Politik swappiness, verschob zahlreiche Seiten des VPS-Arbeitspeichers in den Swap-Bereich, der sich auf dem langsamen HDD RAID1-Bereich befand. Dadurch stieg die IOWAIT erheblich, jedoch nicht aufgrund von IO NVMe, sondern aufgrund von IO HDD RAID1.
Wie das Problem gelöst wurde. Der Swap-Bereich von 32GB wurde deaktiviert. Dies dauerte 16 Stunden; näheres zu den Gründen, warum das SWAP so langsam abgeschaltet wurde, kann separat nachgelesen werden. Die Parameter wurden geändert. swappiness auf einen Wert gleich 5 im gesamten Cloud.
Wie konnte das geschehen?. Erstens, wenn das SWAP auf einem SSD RAID oder NVMe-Gerät gewesen wäre; zweitens, wenn kein NVMe-Gerät vorhanden gewesen wäre, sondern ein langsameres Gerät, das nicht so große Datenmengen verarbeiten kann – ironischerweise trat das Problem auf, weil das NVMe zu schnell war.
Nach dieser Änderung funktioniert alles wieder wie zuvor – mit null IOWAIT.
Quelle: habr.com
