

Einführung
Vor einiger Zeit wurde ich mit der Aufgabe betraut, ein ausfallsicheres Cluster zu entwickeln für , das in mehreren Rechenzentren betrieben wird, die durch Glasfaser innerhalb einer Stadt verbunden sind und in der Lage sind, einen Ausfall (z. B. Stromausfall) eines Rechenzentrums zu überstehen. Als Software, die für die Ausfallsicherheit verantwortlich ist, habe ich mich für entschieden, da es sich um die offizielle Lösung von RedHat zur Erstellung von ausfallsicheren Clustern handelt. Sie zeichnet sich dadurch aus, dass RedHat Unterstützung bietet und dass sie modular (universell) ist. Damit kann die Ausfallsicherheit nicht nur für PostgreSQL, sondern auch für andere Dienste gewährleistet werden, entweder durch die Verwendung standardmäßiger Module oder durch die Entwicklung spezifischer Module für besondere Anforderungen.
Zu dieser Lösung stellt sich die berechtigte Frage: Wie hoch ist die Ausfallsicherheit eines hochverfügbaren Clusters? Um dies zu erforschen, habe ich eine Testumgebung entwickelt, die verschiedene Ausfälle an den Knoten des Clusters simuliert, auf die Wiederherstellung der Funktionalität wartet, den ausgefallenen Knoten wiederherstellt und die Tests in einer Schleife fortsetzt. Ursprünglich nannte sich dieses Projekt hapgsql, aber mit der Zeit langweilte mich der Name, der nur einen Vokal enthält. Daher begann ich, hochverfügbare Datenbanken (und die darauf verweisenden Float-IPs) nach krogan (einem Charakter aus einem Videospiel, bei dem alle wichtigen Organe doppelt vorhanden sind), während ich die Knoten, Cluster und das Projekt selbst nach tuchanka (dem Planeten, auf dem die Kroganer leben) benannte.
Jetzt hat die Geschäftsführung erlaubt, Die README wird bald ins Englische übersetzt (da erwartet wird, dass die Hauptnutzer Entwickler von Pacemaker und PostgreSQL sind), und die alte russische Version der README habe ich beschlossen, (teilweise) in Form dieses Artikels zu gestalten.

Cluster werden auf virtuellen Maschinen . Es werden insgesamt 12 VMs (insgesamt 36GiB) bereitgestellt, die 4 hochverfügbare Cluster bilden (verschiedene Variationen). Die ersten beiden Cluster bestehen aus zwei PostgreSQL-Servern, die in verschiedenen Rechenzentren platziert sind, und einem gemeinsamen Server Witness c Quorum-Gerät (untergebracht auf einer kostengünstigen VM in einem dritten Rechenzentrum), das Unklarheiten auflöst 50%/50%, indem es seine Stimme einer der Seiten gibt. Das dritte Cluster verteilt sich auf drei Rechenzentren: ein Master, zwei Slave-Server, ohne Quorum-Gerät. Das vierte Cluster besteht aus vier PostgreSQL-Servern, zwei pro Rechenzentrum: ein Master, die anderen Replikate, und nutzt ebenfalls Witness c Quorum-Gerät. Das vierte kann den Ausfall von zwei Servern oder eines Rechenzentrums überstehen. Diese Lösung kann, wenn nötig, auf eine größere Anzahl von Replikaten skaliert werden.
Zeitdienst wurde ebenfalls für Hochverfügbarkeit neu konfiguriert, jedoch verwendet es die Methode des ntpd (Orphan-Modus). Der gemeinsame Server Witness fungiert als zentraler NTP-Server, der seine Zeit an alle Cluster verteilt und somit alle Server synchronisiert. Wenn Witness ausfallen oder isoliert werden, dann wird einer der Cluster-Server (innerhalb des Clusters) die Zeit zur Verfügung stellen. Der unterstützende Cache HTTP-Proxy ist ebenfalls aktiviert auf Witness, wodurch die anderen virtuellen Maschinen Zugriff auf die Yum-Repositories haben. In der Praxis werden solche Dienste wie Zeitserver und Proxy wahrscheinlich auf dedizierten Servern gehostet, während sie in der Testumgebung auf Witness nur zur Einsparung von virtuellen Maschinen und Platz platziert sind.
Versionen
v0. Funktioniert mit CentOS 7 und PostgreSQL 11 auf VirtualBox 6.1.
Clusterstruktur
Alle Cluster sind für die Bereitstellung in mehreren Rechenzentren konzipiert, in einem flachen Netzwerk verbunden und müssen den Ausfall oder die Netzwerkisolierung eines Rechenzentrums überstehen. Daher nicht erstellt werden kann wird zur Abwehr von Split-Brain die standardmäßige Pacemaker-Technologie verwendet, die als STONITH („Shoot The Other Node In The Head“) oder Fencing. Das Prinzip: Wenn Knoten in einem Cluster den Verdacht haben, dass bei einem Knoten etwas nicht stimmt, dieser nicht antwortet oder sich fehlerhaft verhält, dann schalten sie ihn über externe Geräte, wie beispielsweise die IPMI-Management-Karte oder eine USV, zwangsweise ab. Dies funktioniert jedoch nur, wenn im Falle eines Einzelserverausfalls IPMI oder die USV weiterhin betriebsbereit sind. Hier wird ein Schutz gegen einen viel katastrophaleren Ausfall geplant, bei dem das gesamte Rechenzentrum ausfällt (zum Beispiel durch Stromausfall). Bei solch einem Ausfall funktionieren auch die stonith-Geräte (IPMI, USV usw.) nicht mehr.
Stattdessen basiert das System auf der Idee des Quorums. Alle Knoten haben eine Stimme, und nur die Knoten, die mehr als die Hälfte aller Knoten sehen, können arbeiten. Diese Anzahl, die „Hälfte+1“ genannt wird, ist das Quorum. Wenn das Quorum nicht erreicht wird, entscheidet der Knoten, dass er in einer Netzwerkisolierung ist und seine Ressourcen abschalten muss, d.h. dies ist eine Schutzmaßnahme gegen Split-Brain. Wenn die Software, die für solch ein Verhalten verantwortlich ist, nicht funktioniert, wird ein Watchdog eingreifen, beispielsweise auf Basis von IPMI.
Wenn die Anzahl der Knoten gerade ist (Cluster in zwei Rechenzentren), kann die sogenannte Unbestimmtheit auftreten 50%/50% (fifty-fifty), wenn die Netzwerkisolierung das Cluster genau in zwei Hälften teilt. Daher wird bei einer geraden Anzahl von Knoten hinzugefügt Quorum-Gerät — ein unauffälliger Daemon, der auf der günstigsten virtuellen Maschine im dritten Rechenzentrum gestartet werden kann. Er gibt seine Stimme einem der Segmente (das er sieht) und löst damit die 50%/50% Unbestimmtheit auf. Der Server, auf dem das Quorum-Gerät laufen wird, habe ich genannt Witness (Terminologie aus repmgr, hat mir gefallen).
Ressourcen können von einem Ort zum anderen bewegt werden, zum Beispiel von defekten Servern zu funktionierenden, oder auf Befehl von Systemadministratoren. Damit die Kunden wissen, wo sich die benötigten Ressourcen befinden (wozu sie sich verbinden müssen?), werden schwebende IPs (float IP). Das sind IPs, die Pacemaker zwischen den Knoten verschieben kann (alles befindet sich im flachen Netzwerk). Jede von ihnen symbolisiert eine Ressource (Service) und wird dort platziert, wo man sich verbinden muss, um Zugang zu diesem Service zu erhalten (in unserem Fall zur DB).
Tuchanka1 (Schema mit Verdichtung)
Struktur
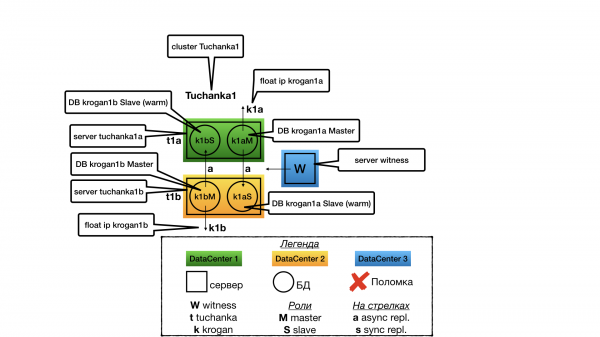
Die Idee war, dass wir viele kleine Datenbanken mit geringer Auslastung haben, für die es sich nicht lohnt, einen dedizierten Slave-Server im Hot-Standby-Modus für Read-Only-Transaktionen zu unterhalten (es besteht keine Notwendigkeit für eine solche Ressourcenverschwendung).
In jedem Rechenzentrum befindet sich ein Server. Auf jedem Server laufen zwei Instanzen von PostgreSQL (in der Terminologie von PostgreSQL werden sie als Cluster bezeichnet, um Verwirrung zu vermeiden, nenne ich sie Instanzen (analog zu anderen DBs), während ich Cluster nur für Pacemaker-Clustern verwenden werde). Eine Instanz arbeitet im Master-Modus und bietet ausschließlich Dienste an (auf sie verweist die Float-IP). Die zweite Instanz fungiert als Slave für das zweite Rechenzentrum und bietet Dienstleistungen nur an, wenn der Master ausfällt. Da die meisten Dienste (Anfragen) von nur einer der beiden Instanzen (dem Master) bereitgestellt werden, werden alle Serverressourcen auf den Master optimiert (Speicher wird für den Cache von shared_buffers bereitgestellt usw.), wobei jedoch auch genügend Ressourcen für die zweite Instanz (auch wenn sie nur suboptimal über den Cache des Dateisystems arbeitet) bereitgestellt werden, um einen Ausfall eines der Rechenzentren abzufangen. Der Slave bietet keine Dienste an (führt keine schreibgeschützten Anfragen aus), solange der Cluster normal arbeitet, um Ressourcenkonflikte mit dem Master auf demselben Server zu vermeiden.
Bei zwei Knoten ist Hochverfügbarkeit nur mit asynchroner Replikation möglich, da bei synchroner Replikation der Ausfall des Slave-Servers zum Stillstand des Masters führt.
Ausfall des Witness
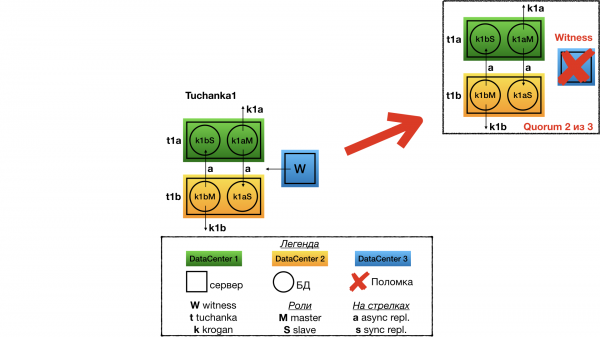
Ausfall des Witness (Quorum-Gerät) werde ich nur für das Cluster Tuchanka1 betrachten, bei allen anderen wird es die gleiche Geschichte sein. Bei einem Ausfall des Witness ändert sich in der Clusterstruktur nichts, alles funktioniert weiterhin wie gewohnt. Aber das Quorum wird 2 von 3 betragen, wodurch jeder weitere Ausfall fatal für das Cluster wird. Es muss dringend repariert werden.
Ausfall Tuchanka1
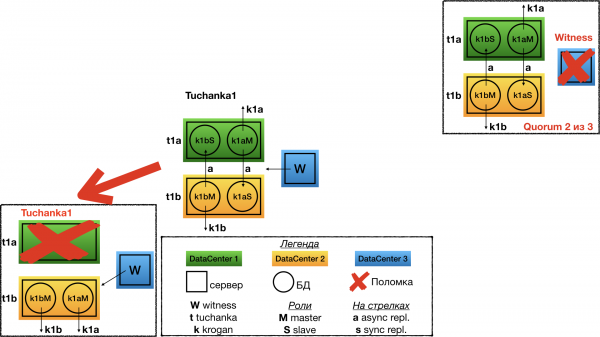
Der Ausfall eines der Rechenzentren für Tuchanka1. In diesem Fall Witness gibt seine Stimme dem zweiten Knoten im zweiten Rechenzentrum ab. Dort wird der vorherige Slave zum Master und somit arbeiten beide Master auf einem Server, auf den beide ihre Float-IP zeigen.
Tuchanka2 (klassisch)
Struktur
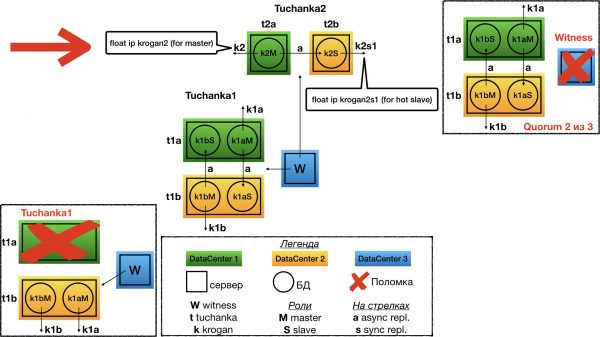
Klassisches Setup mit zwei Knoten. Auf einem arbeitet der Master, auf dem anderen der Slave. Beide können Anfragen bearbeiten (Slave nur read-only), daher zeigen beide auf ihre Float-IPs: krogan2 – auf den Master, krogan2s1 – auf den Slave. Die Hochverfügbarkeit gilt sowohl für den Master als auch für den Slave.
Bei zwei Knoten ist Ausfallsicherheit nur mit asynchroner Replikation möglich, da die synchronisierte Replikation zur Stilllegung des Masters führt, wenn ein Slave ausfällt.
Ausfall von Tuchanka2
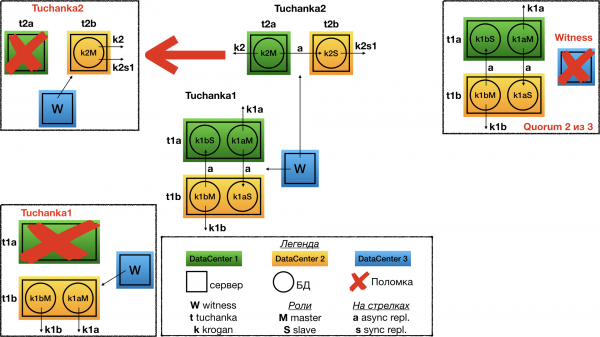
Bei einem Ausfall eines der Rechenzentren Witness wird für das zweite abgestimmt. Im einzigen betriebsbereiten Rechenzentrum wird der Master hochgefahren, und beide Float-IP-Adressen, die Master- und Slave-IP, zeigen darauf. Natürlich muss die Instanz so konfiguriert sein, dass sie über ausreichende Ressourcen (Limits für Verbindungen usw.) verfügt, um gleichzeitig alle Verbindungen und Anfragen von den Master- und Slave-Float-IP-Adressen zu akzeptieren. Das heißt, im Normalbetrieb sollte sie ausreichend Reserven bei den Limits haben.
Tuchanka4 (viele Slaves)
Struktur
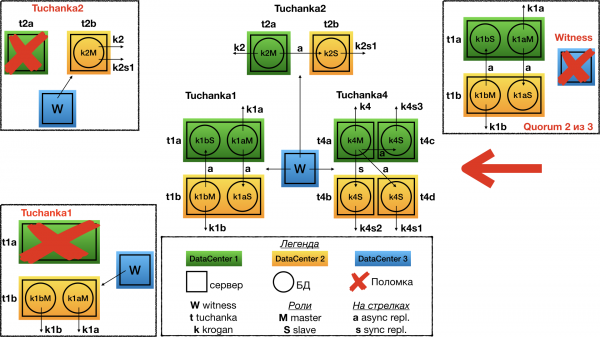
Das ist bereits eine andere Extremität. Es gibt Datenbanken, die viele Leseanfragen erhalten (typischer Fall bei stark frequentierten Websites). Tuchanka4 ist eine Situation, in der es drei oder mehr Slaves geben kann, um solche Anfragen zu bearbeiten, allerdings nicht zu viele. Bei einer sehr großen Anzahl von Slaves wäre es notwendig, ein hierarchisches Replikationssystem zu entwickeln. Im Minimalfall (wie auf dem Bild) befinden sich in jedem der beiden Rechenzentren zwei Server, auf denen jeweils eine PostgreSQL-Instanz läuft.
Eine weitere Besonderheit dieses Schemas besteht darin, dass hier bereits eine synchrone Replikation eingerichtet werden kann. Sie ist so konfiguriert, dass sie nach Möglichkeit in ein anderes Rechenzentrum repliziert, anstatt auf eine Replik im selben Rechenzentrum wie das Master zuzugreifen. Sowohl das Master als auch jeder Slave verwenden eine Float-IP. Ideal wäre es, zwischen den Slaves eine Lastverteilung für die Anfragen durchzuführen, beispielsweise SQL-Proxy, um verschiedenen Arten von Clients gerecht zu werden. Unterschiedliche Typen von Clients benötigen möglicherweise unterschiedliche Typen von SQL-Proxy, und nur die Entwickler der Clients wissen, welcher für wen erforderlich ist. Diese Funktionalität kann sowohl durch einen externen Daemon als auch durch eine Clientbibliothek (Connection Pool) usw. realisiert werden. All dies geht über das Thema des ausfallsicheren DB-Clusters hinaus (Ausfallsicherheit SQL-Proxy kann unabhängig umgesetzt werden, zusammen mit der Ausfallsicherheit des Clients).
Ausfall Tuchanka4
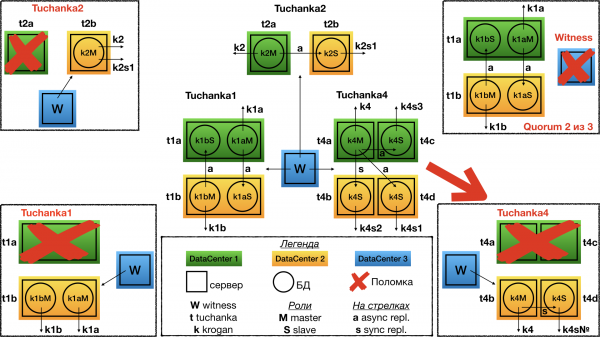
Wenn ein Rechenzentrum ausfällt (d.h. zwei Server), stimmt das Witness für den zweiten ab. Daraus ergibt sich, dass im zweiten Rechenzentrum zwei Server betrieben werden: auf einem läuft der Master, der durch die Master-Float-IP angezeigt wird (für die Annahme von Read-Write-Anfragen); und auf dem zweiten Server läuft ein Slave mit synchroner Replikation, der durch eine der Slave-Float-IPs angezeigt wird (für Read-Only-Anfragen).
Das Erste, was zu beachten ist: von den Slave-Float-IPs wird nicht jede arbeitsfähig sein, sondern nur eine. Und für die korrekte Funktion mit dieser muss sichergestellt sein, dass SQL-Proxy alle Anfragen auf die einzige verbleibende Float-IP weitergeleitet werden; und wenn SQL-Proxy nicht, kann die Auflistung aller Slave-Float-IPs durch Kommas im URL für die Verbindung erfolgen. In diesem Fall wird die libpq Verbindung zum ersten funktionierenden IP hergestellt, so ist es im System für automatische Tests implementiert. Möglicherweise funktioniert es in anderen Bibliotheken, z.B. JDBC, nicht so, und es ist notwendig SQL-Proxy. Dies geschieht, weil die Float-IPs für die Slaves das gleichzeitige Hochfahren auf einem Server untersagt ist, um eine gleichmäßige Verteilung auf die Slave-Server zu gewährleisten, wenn mehrere in Betrieb sind.
Zweitens: Selbst im Falle eines Ausfalls des Rechenzentrums bleibt die synchrone Replikation bestehen. Und selbst wenn es zu einem sekundären Ausfall kommt, das heißt, einer der beiden Server im verbleibenden Rechenzentrum ausfällt, wird der Cluster zwar seine Dienste einstellen, jedoch die Informationen über alle bestätigten Transaktionen, für die eine Bestätigung gegeben wurde, weiterhin speichern (es gibt keinen Informationsverlust bei einem sekundären Ausfall).
Tuchanka3 (3 Rechenzentren)
Struktur
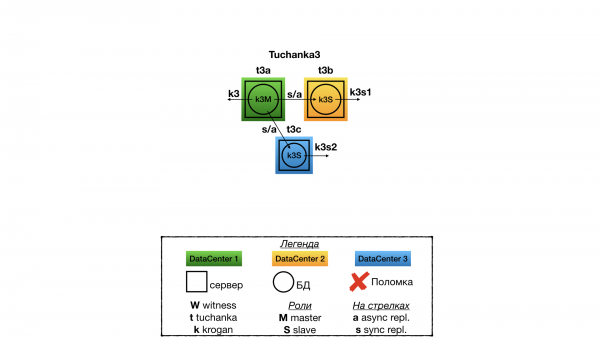
Dies ist ein Cluster für Situationen, in denen drei voll funktionsfähige Rechenzentren vorhanden sind, in denen jeweils ein vollständig funktionsfähiger Datenbankserver betrieben wird. In diesem Fall Quorum-Gerät ist nicht erforderlich. In einem Rechenzentrum arbeitet der Master, in zwei anderen die Slaves. Die Replikation ist synchron, Typ ANY (slave1, slave2), das bedeutet, dass der Kunde eine Committ-Bestätigung erhält, sobald einer der Slaves zuerst antwortet, dass er das Commit akzeptiert hat. Die Ressourcen werden durch eine einzelne Floating-IP für den Master und zwei für die Slaves angegeben. Im Gegensatz zu Tuchanka4 sind alle drei Floating-IPs fehlertolerant. Zur Lastverteilung von read-only SQL-Anfragen kann man SQL-Proxy (mit separater Fehlertoleranz) oder der Hälfte der Kunden einen Slave-Floating-IP zuweisen und der anderen Hälfte die zweite.
Ausfall von Tuchanka3
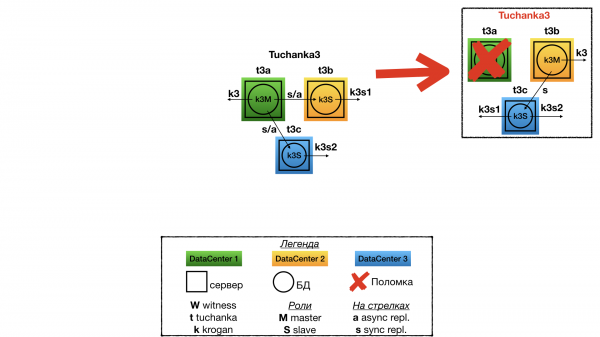
Wenn einer der Rechenzentren ausfällt, bleiben zwei übrig. In einem wird der Master und die Float-IP vom Master betrieben, im anderen der Slave und beide Slave-Float-IPs (auf der Instanz sollte eine doppelte Ressourcenvorhaltung vorhanden sein, um alle Verbindungen von beiden Slave-Float-IPs zu akzeptieren). Zwischen Master und Slave erfolgt eine synchrone Replikation. Das Cluster speichert auch Informationen über bestätigte und committierte Transaktionen (es wird keine Informationsverluste geben) im Falle der Zerstörung von zwei Rechenzentren (sofern diese nicht gleichzeitig zerstört werden).
Eine detaillierte Beschreibung der Dateistruktur und des Deployments habe ich entschieden nicht einzufügen. Wer experimentieren möchte, kann alles in der README nachlesen. Ich gebe nur eine Beschreibung der automatischen Tests an.
Das System für automatisierte Tests
Zur Überprüfung der Ausfallsicherheit von Clustern unter Simulation verschiedener Störungen wurde ein System für automatische Tests entwickelt. Es wird über ein Skript gestartet test/failure. Das Skript kann als Parameter die Nummern der Cluster annehmen, die getestet werden sollen. Zum Beispiel dieser Befehl:
test/failure 2 3Es werden nur der zweite und der dritte Cluster getestet. Wenn keine Parameter angegeben sind, werden alle Cluster getestet. Alle Cluster werden parallel getestet, und das Ergebnis wird im tmux Panel angezeigt. Tmux verwendet einen dedizierten tmux-Server, daher kann das Skript aus dem standardmäßigen tmux gestartet werden, was zu einem verschachtelten tmux führt. Ich empfehle, das Terminal in einem großen Fenster und mit kleiner Schriftgröße zu verwenden. Vor dem Teststart werden alle virtuellen Maschinen auf den Snapshot zum Zeitpunkt des Skriptschlusses zurückgesetzt. setup.
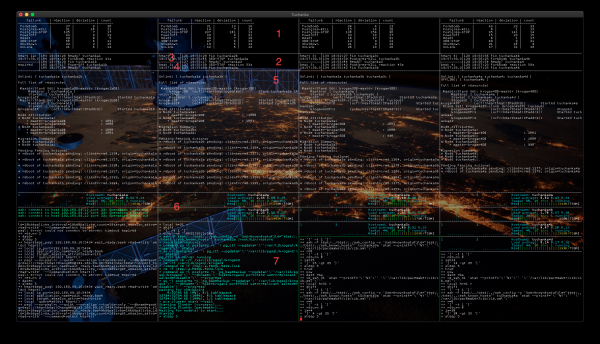
Das Terminal ist in Spalten unterteilt, je nach Anzahl der getesteten Cluster, standardmäßig (im Screenshot) sind es vier. Den Inhalt der Spalten werde ich am Beispiel von Tuchanka2 erläutern. Die Panels im Screenshot sind nummeriert:
- Hier wird die Statistik der Tests angezeigt. Spalten:
- failure — der Name des Tests (Funktionen im Skript), der einen Fehler simuliert.
- reaction — die durchschnittliche Zeit in Sekunden, die benötigt wird, um einen Cluster wieder in Betrieb zu nehmen. Gemessen wird die Zeit vom Start des Skripts, das einen Ausfall emuliert, bis zu dem Zeitpunkt, an dem der Cluster wieder betriebsbereit ist und weiterhin Dienstleistungen anbieten kann. Wenn die Zeit sehr kurz ist, beispielsweise sechs Sekunden (was in Clustern mit mehreren Slaves wie Tuchanka3 und Tuchanka4 vorkommen kann), bedeutet dies, dass der Ausfall auf einem asynchronen Slave aufgetreten ist und keine Auswirkungen auf die Betriebsfähigkeit hatte, ohne dass es zu Zustandswechseln des Clusters kam.
- Abweichung — zeigt die Streuung (Genauigkeit) des Wertes an reaction nach der Methode der „Standardabweichung“.
- Anzahl — wie oft dieser Test durchgeführt wurde.
- Das kurze Protokoll ermöglicht eine Einschätzung, was der Cluster gerade tut. Es wird die Iterationsnummer (Test), ein Zeitstempel und der Name der Operation ausgegeben. Eine zu lange Ausführungszeit (> 5 Minuten) deutet auf ein Problem hin.
- Herz (Herz) — die aktuelle Zeit. Zur visuellen Bewertung der Betriebsfähigkeit des Masters wird in seine Tabelle ständig die aktuelle Zeit unter Verwendung der float IP des Masters eingetragen. Bei Erfolg wird das Ergebnis in diesem Panel angezeigt.
- Heartbeat (Puls) — „aktuelle Zeit“, die zuvor von einem Skript aufgezeichnet wurde Herz in den Master, wird jetzt von Slave über dessen Float-IP gelesen. Ermöglicht eine visuelle Einschätzung der Funktionalität des Slaves und der Replikation. In Tuchanka1 gibt es keine Slaves mit Float-IP (keine Slaves, die Dienstleistungen anbieten), aber es gibt zwei Instanzen (DB), daher wird hier nicht Heartbeat, und Herz die zweite Instanz angezeigt.
- Überwachung des Clusterzustands mit dem Tool
pcs mon. Zeigt die Struktur, die Verteilung der Ressourcen auf den Knoten und andere nützliche Informationen an. - Hier wird das Systemmonitoring jeder virtuellen Maschine des Clusters ausgegeben. Es können mehrere solcher Panels vorhanden sein — so viele virtuelle Maschinen wie es im Cluster gibt. Zwei Grafiken CPU-Auslastung (in den virtuellen Maschinen mit zwei Prozessoren), Name der virtuellen Maschine, Systemauslastung (auch als Lastdurchschnitt bezeichnet, da sie über 5, 10 und 15 Minuten gemittelt wird), Daten zu Prozessen und der Speicherauslastung.
- Tracing des Skripts, das Tests durchführt. Im Falle eines Fehlers — plötzlicher Unterbrechung der Ausführung oder unendlichem Wartezyklus — kann hier die Ursache für solches Verhalten gesehen werden.
Die Tests werden in zwei Phasen durchgeführt. Zunächst durchläuft das Skript alle Testvarianten und wählt zufällig eine virtuelle Maschine aus, auf die dieser Test angewendet wird. Danach erfolgt eine Endlosschleife von Tests, wobei die virtuellen Maschinen und eventuelle Fehler jedes Mal zufällig gewählt werden. Ein unerwartetes Ende des Testskripts (untere Leiste) oder eine Endlosschleife, in der auf etwas gewartet wird (> 5 Minuten Ausführungszeit für eine Operation, sichtbar in der Trace) deutet darauf hin, dass einer der Tests in diesem Cluster gescheitert ist.
Jeder Test besteht aus den folgenden Operationen:
- Starten einer Funktion, die einen Fehler simuliert.
- Bereit? — Warten auf die Wiederherstellung des Clusters (wenn alle Dienste wieder bereitgestellt sind).
- Die Wartezeit auf die Wiederherstellung des Clusters wird angezeigt (reaction).
- Fix — der Cluster "wird repariert". Danach sollte er in den vollständig funktionsfähigen Zustand zurückkehren und bereit sein für den nächsten Fehler.
Hier ist die Liste der Tests mit einer Beschreibung, was sie tun:
- ForkBomb: erzeugt "Out of memory" mittels einer Fork-Bombe.
- OutOfSpace: die Festplatte ist voll. Der Test ist jedoch eher symbolisch, da die Belastung während des Tests minimal ist; bei einer vollen Festplatte kommt es normalerweise nicht zu einem Ausfall von PostgreSQL.
- Postgres-KILL: beendet PostgreSQL mit dem Befehl
killall -KILL postgres. - Postgres-STOP: hängt PostgreSQL mit dem Befehl
killall -STOP postgres. - PowerOff: „schaltet“ die Virtuelle Maschine mit dem Befehl
VBoxManage controlvm "virtuelle Maschine" poweroff. - Reset: startet die Virtuelle Maschine mit dem Befehl
VBoxManage controlvm "virtuelle Maschine" reset. - SBD-STOP: hängt den SBD-Dämon mit dem Befehl
killall -STOP sbd. - ShutDown: sendet über SSH den Befehl an die Virtuelle Maschine
systemctl poweroff, das System wird ordnungsgemäß heruntergefahren. - UnLink: Netzwerkisolierung, der Befehl
VBoxManage controlvm "virtuelle Maschine" setlinkstate1 off.
Der Test kann entweder mit dem Standardbefehl tmux "kill-window" beendet werden Ctrl-b &, oder mit dem Befehl "detach-client" Ctrl-b d: dabei wird der Test beendet, tmux wird geschlossen, die virtuellen Maschinen werden heruntergefahren.
Aufgedeckte Probleme während des Tests
Aktuell muss man entweder Audio oder Aussetzen/Wiederherstellen wählen. Wir warten darauf, dass der Autor des gesamten Moduls die Funktionalität verbessert. der watchdog-Dämon sbd verarbeitet das Stoppen der beobachteten Dämonen, jedoch nicht deren Hängenbleiben. Folglich werden Störungen, die nur zum Hängenbleiben führen, nicht korrekt verarbeitet. Corosync und Pacemaker, während sbd nicht aufhängt. . Zur ÜberprüfungPR#83 Corosync vorhanden ist, , принят в ветку master. Es wurde (in PR#83) versprochen, dass es auch für Pacemaker etwas Ähnliches geben wird, ich hoffe, dass bis dahin RedHat 8 das umgesetzt wird. Aber solche "Fehler" sind theoretischer Natur, sie können leicht künstlich erzeugt werden, beispielsweise durch
killall -STOP corosync, kommen jedoch in der Praxis niemals vor.U Pacemaker in der Version für CentOS 7 sync_timeout falsch eingestellt ist, was dazu führt, u Quorum-Gerätdass im Falle eines Ausfalls eines Knotens mit gewisser Wahrscheinlichkeit auch der zweite Knoten, während der Bereitstellung (im Skript falsch eingestellt ist, was dazu führt, u Quorum-Gerät setup/setup1
). Diese Korrektur wurde von den Entwicklern nicht angenommen, stattdessen haben sie versprochen, die Infrastruktur so zu überarbeiten, dass dieser Timeout automatisch berechnet wird (irgendwann in der unbestimmten Zukunft).Wenn bei der Konfiguration der Datenbank angegeben ist, dass in PacemakerLC_MESSAGES(Textnachrichten) Unicode verwendet werden kann, zum Beispiel
ru_RU.UTF-8, dann wird beim Startenin einer Umgebung, in der das Gebietsschema nicht UTF-8 ist, sagen wir in einer leeren Umgebung (hierpacemaker postgres pgsqlms (paf) startet+, im Log werden anstelle von UTF-8-Zeichen Fragezeichen angezeigt.Die Entwickler von PostgreSQL haben sich nicht darauf geeinigt, was in diesem Fall zu tun ist. Es kann umgangen werden, man muss postgres), dann . Разработчики PostgreSQL так и не договорились, что делать в этом случае. Это обходится, нужно ставитьLC_MESSAGES=en_US.UTF-8bei der Konfiguration (Erstellung) einer DB-Instanz.Wenn wal_receiver_timeout (standardmäßig 60s) eingestellt ist, tritt bei einem PostgreSQL-STOP-Test auf dem Master in den Clustern tuchanka3 und tuchanka4 Die Replikation ist dort synchron, weshalb nicht nur der Slave, sondern auch der neue Master stoppt. Dies kann behoben werden, indem wal_receiver_timeout=0 bei der PostgreSQL-Konfiguration gesetzt wird.
Gelegentlich habe ich ein Hängenbleiben der Replikation bei PostgreSQL im ForkBomb-Test (Speicherüberlauf) beobachtet. Ich habe dies nur in den Clustern tuchanka3 und tuchanka4 erlebt, wo der Master aufgrund der synchronen Replikation hängen blieb. Das Problem löste sich von selbst nach einer gewissen Zeit (ungefähr zwei Stunden). Weitere Untersuchungen sind erforderlich, um dies zu beheben. Die Symptome ähneln einem früheren Bug, der durch eine andere Ursache ausgelöst wird, aber die gleichen Folgen hat.
Das Krogan-Bild stammt von mit Erlaubnis des Autors:
Quelle: habr.com
